

Predictive Business Process Monitoring with Structured and Unstructured Data
26
Predictive Business Process Monitoring with Structured and Unstructured Data Irene Teinemaa, Marlon Dumas, Fabrizio Maria Maggi, Chiara Di Francescomarino
-
Upload
marlon-dumas -
Category
Business
-
view
170 -
download
1
Transcript of Predictive Business Process Monitoring with Structured and Unstructured Data

Predictive Business Process Monitoring with Structured
and Unstructured Data
Irene Teinemaa, Marlon Dumas, Fabrizio Maria Maggi, Chiara Di Francescomarino

Predictive MonitoringExample: Debt recovery process
Debt repayment due Call the debtor Send a reminder Payment received

Predictive Monitoring
Debt repayment due Call the debtor Send a reminder Send a warning Call the debtor Call the debtor
Send to external debt collection agency
Example: Debt recovery process
Call the debtorSend a reminder Send a warning Call the debtor Call the debtorCall the debtor
Call the debtor
Call the debtor
Call the debtor
Call the debtor Call the debtor

Predictive Monitoring
Event log
Classifier
/Predictions
Attributes
Trac
es

Encoding the traces
Event1 Event2
Trace1 Call the debtor
Send a reminder
Call the debtor Send a reminder
Example: Debt recovery process

Encoding the traces
Event1 Event2 Resource1 Resource2 Debtor
Trace1 Call the debtor
Send a reminder
Sue Bob Mark
Call the debtor Send a reminder
Example: Debt recovery process
Debtor
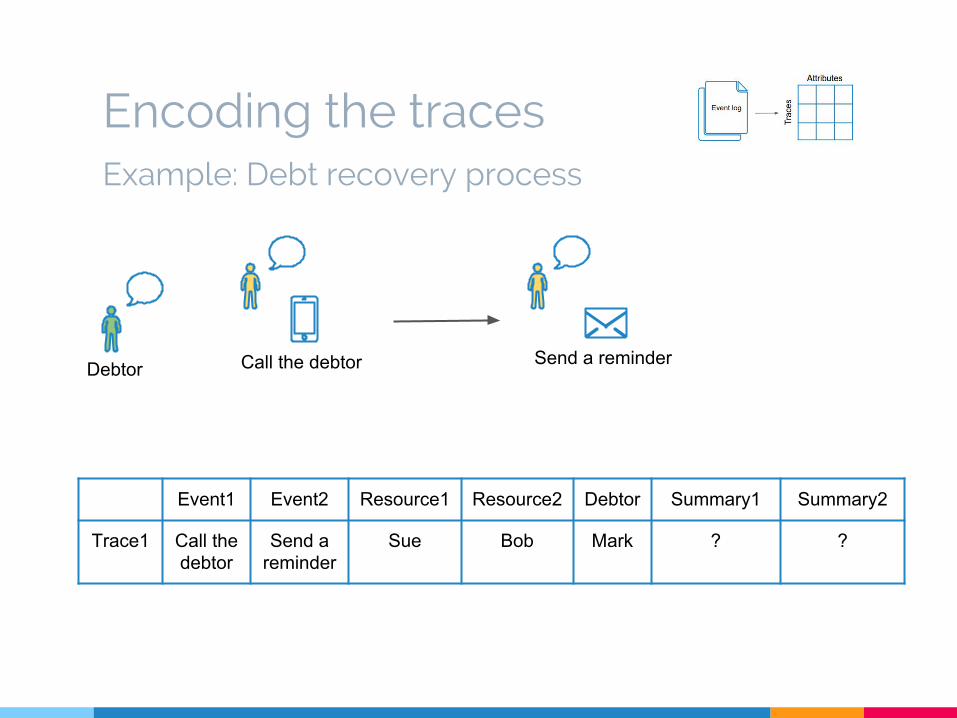
Encoding the traces
Event1 Event2 Resource1 Resource2 Debtor Summary1 Summary2
Trace1 Call the debtor
Send a reminder
Sue Bob Mark ? ?
Call the debtor Send a reminder
Example: Debt recovery process
Debtor

Text MiningThe last ten years has seen a surge of interest in design science research in information systems, organizations, process modelling and software engineering. In this talk I present a framework for design science that shows how in design science research, we iterate over designing new artifacts for a context, and empirically investigating these artifacts in this context. To be relevant, the artifacts should potentially contribute to organizational goals, and to be empirically sound, research to validate new artifacts should provide insight into the effects of using these artifacts in an organizational context. The logic of both of these activities, design and empirical research, is that of rational decision making. I show how this logic can be used to structure our technical and empirical research goals and questions, as well as how to structure reports about our technical or empirical research. This gives us checklists for the design cycle used in technical research and for the empirical cycle used in empirical research. Finally, I will discuss in more detail what the role of theories in design science research is, and how we use theory to state research questions and to generalize the research results.
The tutorial first introduces the PPM including its activities: problem understanding, method finding, modeling, reconciliation, and validation.
What is a good business process model and how do you get value from it? We have for many years worked with SEQUAL, a general framework for understanding the quality of models and modelling languages, which covers all main aspects relative to quality of models. The framework has been widely cited since the first version was presented in the nineties, and the tutorial will focus on the most recent version of the framework (2016), specialised for quality of business process models, with a focus on how to achieve value through long-term usage of business process models in organizations.
Business process models have gained significant importance due to their critical role for managing business processes. Process models not only play a fundamental role for obtaining a common understanding of an organization’s business processes, but are also important assets for improving business processes and to support the development of information systems. In this tutorial we will focus on the process of process modeling (PPM) and shed light on how process models are created.
0.2, 0.1, 0.8, 0.5, …, 0.1
0.4, 0.8, 1.0, 0.2, …, 0.4
0.9, 0.0, 0.4, 0.5, …, 0.2
0.2, 0.3, 0.7, 0.6, …, 0.6

Text Modelling Methods
▷ Bag-of-n-grams○ 1, 2, 3-grams
resend the invoice today pay
1 1 1 1 0
Example sentence: Resend the invoice today.

Text Modelling Methods
▷ Bag-of-n-grams○ 1, 2, 3-grams
▷ Weighted bag-of-n-grams○ Naive Bayes log count ratios
resend the invoice today pay
1 1 1 1 0
resend the invoice today pay
0.8 0.5 0.3 0.7 0
Example sentence: Resend the invoice today.

Text Modelling Methods
▷ Bag-of-n-grams○ 1, 2, 3-grams
▷ Weighted bag-of-n-grams○ Naive Bayes log count ratios
▷ Topic models ○ Latent Dirichlet Allocation
resend the invoice today pay
1 1 1 1 0
resend the invoice today pay
0.8 0.5 0.3 0.7 0
topic1 topic2 topic3
0.6 0.1 0.3
Example sentence: Resend the invoice today.

Text Modelling Methods
▷ Bag-of-n-grams○ 1, 2, 3-grams
▷ Weighted bag-of-n-grams○ Naive Bayes log count ratios
▷ Topic models ○ Latent Dirichlet Allocation
▷ Neural network○ Paragraph Vector
“Resend the invoice today” vs.
“Resend the bill today”
resend the invoice today pay
1 1 1 1 0
resend the invoice today pay
0.8 0.5 0.3 0.7 0
topic1 topic2 topic3
0.6 0.1 0.9
t1 t2 t3
0.3 0.6 0.1
Example sentence: Resend the invoice today.

Encoding the traces
Event1 Event2 Resource1 Resource2 Debtor t11 ... t1n t21 ... t2n
Trace1 Call the debtor
Send a reminder
Sue Bob Mark 0.2 ... 0.1 0.4 ... 0.4
Call the debtor Send a reminder
Example: Debt recovery process
Debtor

Proposed Framework
▷ Offline component○ Building a text model and classifier for
all historical prefixes of a given length
▷ Online component○ Producing predictions for a running case
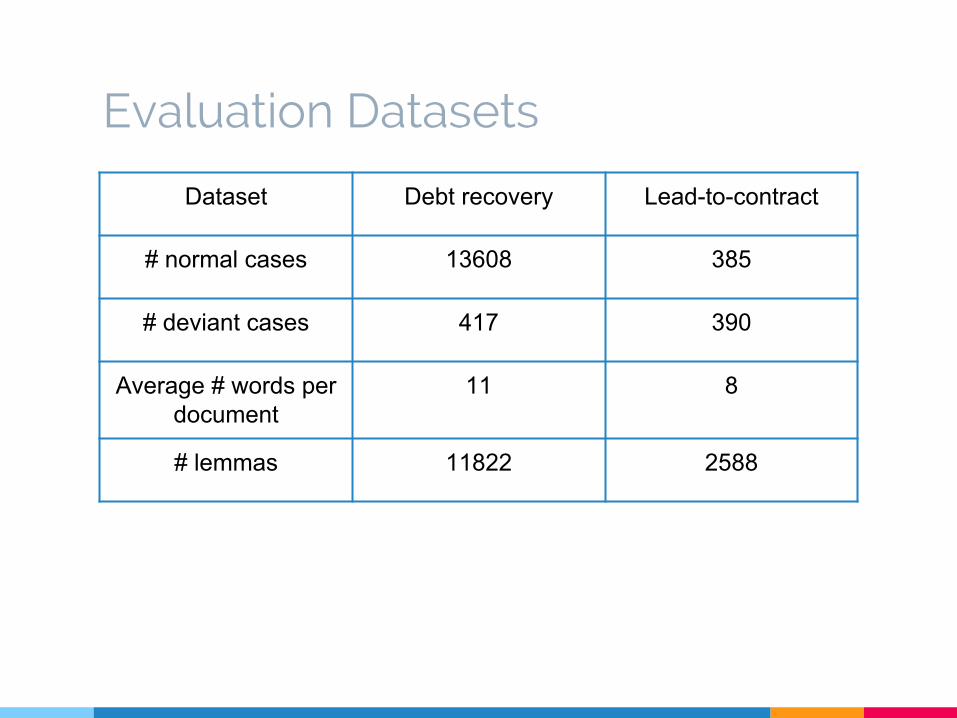
Evaluation Datasets
Dataset Debt recovery Lead-to-contract
# normal cases 13608 385
# deviant cases 417 390
Average # words per document
11 8
# lemmas 11822 2588

Experimental Set-up
▷ Data split: 80% train, 20% test (randomly)▷ Handling imbalance: oversampling▷ Classifiers: random forest and logistic regression▷ Evaluation metrics: F-Score and earliness▷ Parameter-tuning: grid search with 5-fold cross
validation on training set

Results
▷ Textual + structured features > structured▷ Bag-of-n-grams > topic models > NN▷ Topic models are better when only few
textual data available▷ Neural network based model requires more
heterogeneous textual data

Future Work
▷ Evaluation on additional datasets○ More heterogeneous textual data○ Longer documents
▷ Conversational interactions▷ Non-boolean predictions▷ Interpretable explanations


Encoding the traces
▷ Prefix length = 2
▷ Prefix length = 3
Event1 Event2 Resource1 Resource2
Trace1 Call the debtor
Send a reminder
Sue Bob
Event1 Event2 Event3 Resource1 Resource2 Resource3
Trace1 Call the debtor
Send a reminder
Call the debtor
Sue Bob Bob

Offline Component
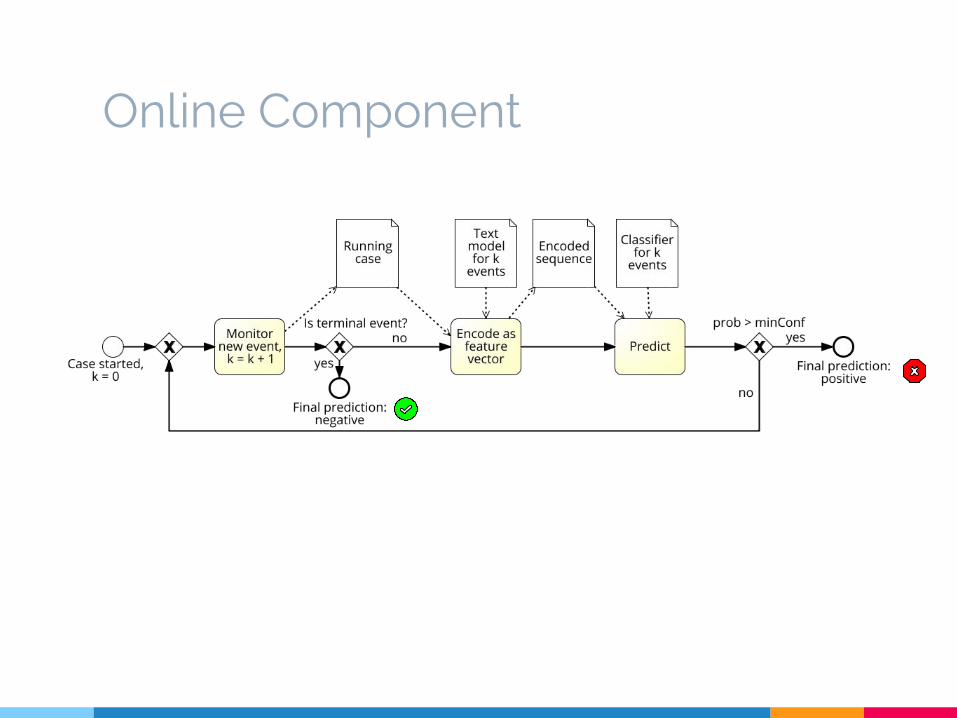
Online Component

Evaluation metrics
▷ Precision:
▷ Recall:
▷ F-Score:
▷ Earliness:
predicted
deviant normal
deviant TP FN
normal FP TN
actu
al

Results▷ Textual features improve
the predictions▷ Random forest
outperforms logit▷ Bag-of-words based
models outperform more complex ones
▷ Topic models perform relatively better when only few textual data available
▷ Neural network based model requires more heterogeneous textual data

Computation times
Offline pre-processing (s) Offline classifier training (s) Online (ms per event)
Data DR LtC
Base 0.5 0.5
BoNG 5.1 1.4
NB 54.0 1.7
LDA 262 28
PV 212 14.7
Data DR LtC
Base 41.3 28.1
BoNG 50 29.9
NB 53.9 35.2
LDA 83.6 24.5
PV 61.3 27.3
Data DR LtC
Base 0.1 0.3
BoNG 0.4 0.4
NB 2.9 0.5
LDA 7.0 0.7
PV 2 0.5


















