
Practical Hidden Voice Attacks against Speech and Speaker ...
30
Practical Hidden Voice Attacks against Speech and Speaker Recognition Systems Hadi Abdullah, Washington Garcia, Christian Peeters, Patrick Traynor, Kevin R.B. Butler, and Joseph Wilson
Transcript of Practical Hidden Voice Attacks against Speech and Speaker ...

PracticalHiddenVoiceAttacksagainstSpeechandSpeakerRecognitionSystems
HadiAbdullah,WashingtonGarcia,ChristianPeeters,PatrickTraynor,KevinR.B.Butler,andJosephWilson

FloridaInstituteforCybersecurityResearch 2
VoiceasanInterface

3
InjectingCommands

4
InjectingCommands(Demonstration)

5
Youmightbethinking...
● Benign? ● Easy to Defend?

6
Is there a generic, transferrable way to produce audio that:
● sounds like noise to humans, ● sounds like a valid command to the system? ● works against both speech and speaker recognition
systems ● with Black-Box access to target system
OurWork!

7
Structure
Modern Speech Recognition Systems Feature Extraction
How the Attack Works
Demo
Takeaway

8
AudioSample InferencePreprocessing FeatureExtraction
ModernSpeechRecognitionSystems
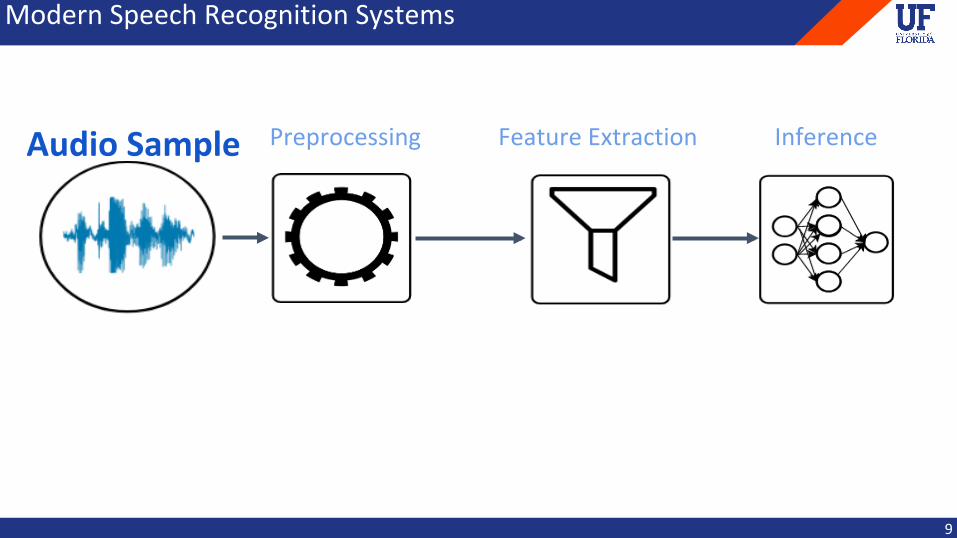
9
AudioSample Preprocessing FeatureExtraction Inference
ModernSpeechRecognitionSystems
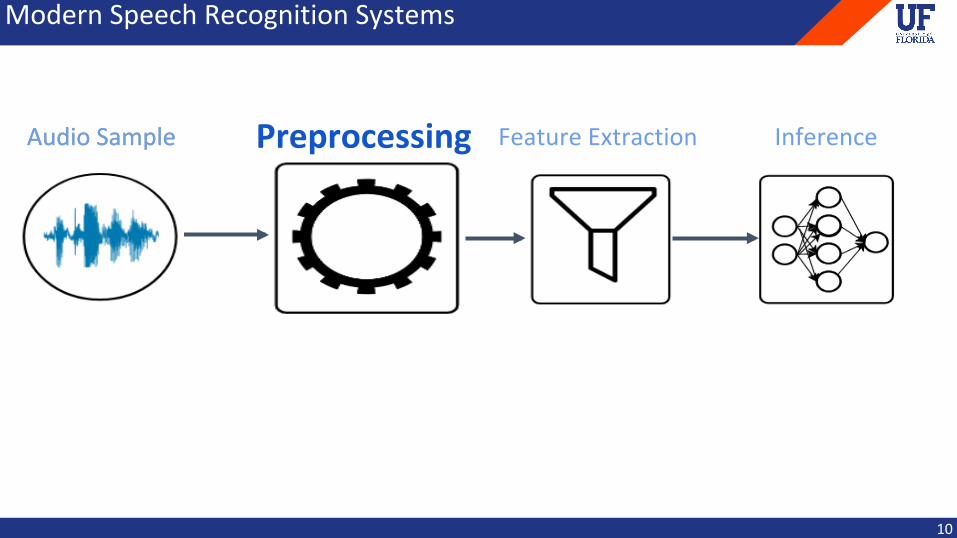
10
Preprocessing FeatureExtraction InferenceAudioSample
ModernSpeechRecognitionSystems
AudioSample

11
FeatureExtraction InferencePreprocessingAudioSample
ModernSpeechRecognitionSystems
AudioSample

12
FeatureExtraction InferencePreprocessing
ModernSpeechRecognitionSystems
AudioSample

13
FeatureExtraction InferencePreprocessing
MostAttacks**● N.CarliniandD.Wagner,“AudioAdversarialExamples:TargetedAttacksonSpeech-to-Text,”IEEEDeepLearningandSecurityWorkshop,2018● N.Carlini,P.Mishra,T.Vaidya,Y.Zhang,M.Sherr,C.Shields,D.Wagner,andW.Zhou,“Hiddenvoicecommands.”inUSENIXSecuritySymposium,2016● X.Yuan,Y.Chen,Y.Zhao,Y.Long,X.Liu,K.Chen,S.Zhang,H.Huang,X.Wang,andC.A.Gunter,“Commandersong:Asystematicapproachforpracticaladversarialvoice
recognition,”inProceedingsoftheUSENIXSecuritySymposium,2018.● M.Alzantot,B.Balaji,andM.Srivastava,“Didyouhearthat?Adversarialexamplesagainstautomaticspeechrecognition,”NIPS2017MachineDeceptionWorkshop
ModernSpeechRecognitionSystems
AudioSample
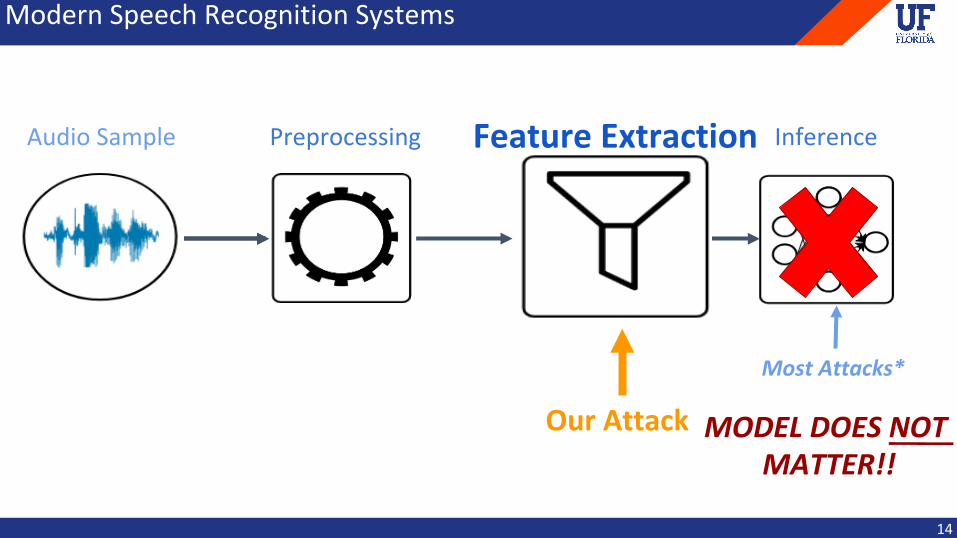
14
FeatureExtraction InferencePreprocessing
OurAttack
AudioSample
MostAttacks*
MODELDOESNOTMATTER!!
ModernSpeechRecognitionSystems

15
Modern Speech Recognition Systems
Feature Extraction How the Attack Works
Demo
Takeaway
Structure

16
● Designed to approximate the human ear ● Retains the most important features ● Magnitude Fast Fourier Transform (mFFT)
FeatureExtraction

17
● Converts time domain to frequency domain ● Multiple Inputs can have same output ● mFFT is lossy
FeatureExtraction(mFFT)

18
Modern Speech Recognition Systems
Feature Extraction
How the Attack Works Demo
Takeaway
Structure

19
● Grouped into 4 types
HowtheAttackWorks(Types)

20
● Intelligibility hard to measure ● Fundamentals of psychoacoustics ● Spread energy across spectrum
HowtheAttackWorks(Psychoacoustics)

21
Task Data
Queries
Models
> 20,000 successful attack samples 22 speakers
<10 queries to model (a few seconds!)
Noise -> text Noise -> user
x2
Speaker Speech
HowtheAttackWorks(Evaluation)

22
Modern Speech Recognition Systems
Feature Extraction
How the Attack Works
Demo Takeaway
Structure

23
Demo!(1/2)
Moreat:https://sites.google.com/view/practicalhiddenvoice/home

24
Demo!(2/2)
Moreat:https://sites.google.com/view/practicalhiddenvoice/home

25
Moreat:https://sites.google.com/view/practicalhiddenvoice/home
Demo!(2/2)

26
Modern Speech Recognition Systems
Feature Extraction
How the Attack Works
Demo
Takeaway
Structure

27
Takeaway
● Simple, efficient audio transformations yield “noise” that is understood as commands by speech systems
● The model is irrelevant ● All systems we tested are vulnerable ● Achieve the same goals as traditional Adversarial ML
hadiabdullah1
Projectwebpage:
sites.google.com/view/practicalhiddenvoice/home

28

29
VoiceBiometrics
● Easy to get around ● Artificially generate a target’s speech ○ LyreBird
● Capture and stitch together target’s speech

30
Defenses
● Must be implemented at or before feature extraction ● Adversarial Training? ● Voice Activity Detection? ● Environmental Noise ● Liveness Detection ○ Blue et al.*
* L. Blue, L. Vargas, and P. Traynor, “Hello, is it me you‘re looking for? Differentiating between human and electronic speakers for voice interface security,” in 11th ACM Conference on Security and Privacy in Wireless and Mobile Networks, 2018.



![Audio Adversarial Examples: Targeted Attacks on Speech-To …Hidden and inaudible voice commands [11, 39, 41] are targeted attacks, but require synthesizing new audio and can not modify](https://static.fdocuments.in/doc/165x107/609e155c1ba02c56b2519684/audio-adversarial-examples-targeted-attacks-on-speech-to-hidden-and-inaudible-voice.jpg)
![Speaker Stand with Hidden Storage - Wood Toolswoodtools.nov.ru/projects2/PlanPDF/[Woodworking Plans] American... · American Woodworker Sign up for FREE Home Improvement Newsletter:](https://static.fdocuments.in/doc/165x107/5b81af277f8b9a2b678ce27d/speaker-stand-with-hidden-storage-wood-woodworking-plans-american-american.jpg)
![Detection of Hidden Transformer Tap Change Command Attacks ... · of threats to smart grids called Coordinated Cyber-Physical Attacks (CCPA) have been considered in [26]. In [26],](https://static.fdocuments.in/doc/165x107/5f2c0d87b0c3733cb2797017/detection-of-hidden-transformer-tap-change-command-attacks-of-threats-to-smart.jpg)
![Who is Real Bob? Adversarial Attacks on Speaker ...website [35] which includes voice samples and source code. II. BACKGROUND In this section, we introduce the preliminaries of speaker](https://static.fdocuments.in/doc/165x107/6069848fe0d2e22f2f27abb7/who-is-real-bob-adversarial-attacks-on-speaker-website-35-which-includes.jpg)











![1 Understanding In-app Ads and Detecting Hidden Attacks ...pages.cs.wisc.edu/~vrastogi/static/papers/srcpgzr18.pdfindustry researchers are reporting [3] that some scams which traditionally](https://static.fdocuments.in/doc/165x107/60246b496e311c38de6beb45/1-understanding-in-app-ads-and-detecting-hidden-attacks-pagescswisceduvrastogistaticpapers.jpg)