
Prabhat, and Frank Wood Etalumis: Bringing Probabilistic...
50
Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale Atılım Güneş Baydin, Lei Shao, Wahid Bhimji, Lukas Heinrich, Lawrence Meadows, Jialin Liu, Andreas Munk, Saeid Naderiparizi, Bradley Gram-Hansen, Gilles Louppe, Mingfei Ma, Xiaohui Zhao, Philip Torr, Victor Lee, Kyle Cranmer, Prabhat, and Frank Wood SC19, Denver, CO, United States 19 November 2019
Transcript of Prabhat, and Frank Wood Etalumis: Bringing Probabilistic...

Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale
Atılım Güneş Baydin, Lei Shao, Wahid Bhimji, Lukas Heinrich, Lawrence Meadows, Jialin Liu, Andreas Munk, Saeid Naderiparizi, Bradley Gram-Hansen, Gilles Louppe, Mingfei Ma, Xiaohui Zhao, Philip Torr, Victor Lee, Kyle Cranmer, Prabhat, and Frank Wood
SC19, Denver, CO, United States19 November 2019

Simulation and HPC
2
Computational models and simulation are key to scientific advance at all scales
Climate science CosmologyWeatherDrug discovery
Nuclear physics Material designParticle physics

Introducing a new way to use existing simulators
3
SimulationProbabilistic
programming (machine learning)
Supercomputing

Simulators
4
Parameters Outputs (data)
Simulator

Simulators
5
● Simulate forward evolution of the system● Generate samples of output
Prediction:
Parameters Outputs (data)
Simulator

Simulators
6
● Simulate forward evolution of the system● Generate samples of output
Prediction:
Parameters Outputs (data)
Simulator

Simulators
7
● Simulate forward evolution of the system● Generate samples of output
Prediction:
WE NEED THE INVERSE!
Parameters Outputs (data)
Simulator

Simulators
8
● Simulate forward evolution of the system● Generate samples of output
Prediction:
● Find parameters that can produce (explain) observed data● Inverse problem● Often a manual process
Inference:
Parameters Outputs (data)
Simulator

Simulators
9
Parameters Outputs (data)
SimulatorObserved data
Inferred parameters
Gene network Gene expression

Simulators
10
Parameters Outputs (data)
SimulatorObserved data
Inferred parameters
Earthquakelocation &
characteristics
Seismometerreadings
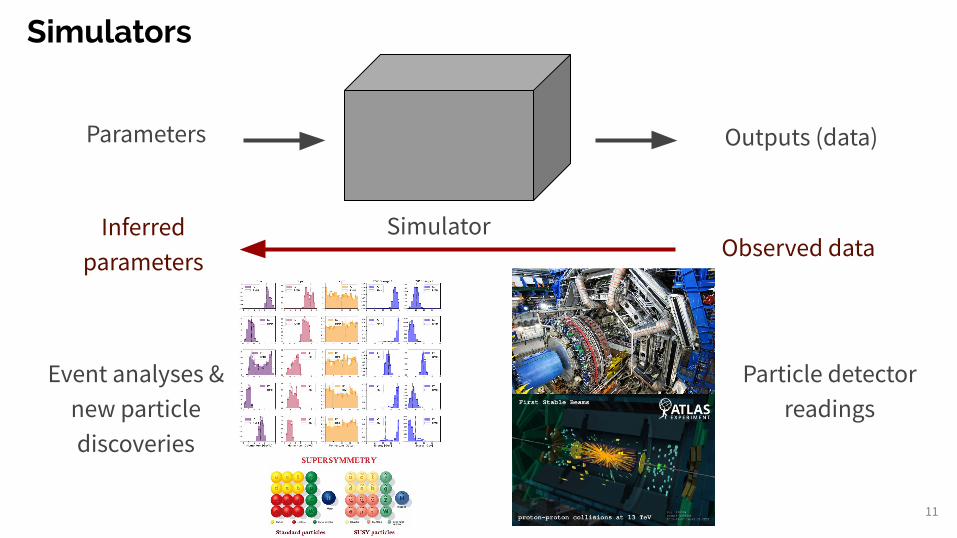
Simulators
11
Parameters Outputs (data)
SimulatorObserved data
Inferred parameters
Event analyses &new particle discoveries
Particle detector readings

Inverting a simulator
12
Probabilistic programming is a machine learning framework allowing us to● write programs that define probabilistic models● run automated Bayesian inference of parameters
conditioned on observed outputs (data)
Pyro Edward Stan
Parameters Outputs (data)
SimulatorObserved data
Inferred parameters

Inverting a simulator
13
Probabilistic programming is a machine learning framework allowing us to● write programs that define probabilistic models● run automated Bayesian inference of parameters
conditioned on observed outputs (data)
Pyro Edward Stan
Parameters Outputs (data)
SimulatorObserved data
Inferred parameters
● Has been limited to toy and small-scale problems● Normally requires one to implement a probabilistic
model from scratch in the chosen language/system

Inverting a simulator
14
Key idea:Many HPC simulators are stochastic and they define probabilistic modelsby sampling random numbers
Parameters Outputs (data)
SimulatorObserved data
Inferred parameters

Inverting a simulator
15
Key idea:Many HPC simulators are stochastic and they define probabilistic modelsby sampling random numbers
Simulators are probabilistic programs!
Parameters Outputs (data)
Simulator
Code
Observed dataInferred
parameters

Inverting a simulator
16
Key idea:Many HPC simulators are stochastic and they define probabilistic modelsby sampling random numbers
Simulators are probabilistic programs!We “just” need an infrastructure to execute them as such
Parameters Outputs (data)
Simulator
Code
Observed dataInferred
parameters

A new probabilistic programming system for simulators and HPC, based on PyTorch

18
Probabilistic execution
Parameters Outputs (data)
Simulator
Code
Observed dataInferred
parameters

19
Parameters Outputs (data)
Simulator
Code
Probabilistic execution
● Run forward & catch all random choices (“hijack” all calls to RNG)● Record an execution trace: a record of all parameters, random choices, outputs
Observed dataInferred
parameters

20
Parameters Outputs (data)
Simulator
Code
Probabilistic execution
● Run forward & catch all random choices (“hijack” all calls to RNG)● Record an execution trace: a record of all parameters, random choices, outputs
Observed dataInferred
parameters
Probabilistic Programming eXecution protocolC++, C#, Dart, Go, Java, JavaScript, Lua, Python, Rust and others

21
Parameters Outputs (data)
Simulator
Code
Probabilistic execution
● Run forward & catch all random choices (“hijack” all calls to RNG)● Record an execution trace: a record of all parameters, random choices, outputs
Observed dataInferred
parameters
Uniquely label each choiceat runtime by “addresses” ofstack traces

22
Parameters Outputs (data)
Simulator
Code
Probabilistic execution
● Run forward & catch all random choices (“hijack” all calls to RNG)● Record an execution trace: a record of all parameters, random choices, outputs
○ Conditioning: compare simulated output and observed data● Approximate the distribution of parameters that can produce (explain)
observed data, using inference engines like Markov-chain Monte Carlo (MCMC)
Observed dataInferred
parameters

23
Parameters Outputs (data)
Simulator
Code
Probabilistic execution
● Run forward & catch all random choices (“hijack” all calls to RNG)● Record an execution trace: a record of all parameters, random choices, outputs
○ Conditioning: compare simulated output and observed data● Approximate the distribution of parameters that can produce (explain)
observed data, using inference engines like Markov-chain Monte Carlo (MCMC)
Observed dataInferred
parameters
This is hard and computationally costly● Need to run simulator up to millions of times● Simulator execution and MCMC inference are sequential● MCMC has “burn-in period” and autocorrelation

24
Parameters Outputs (data)
Simulator
Code
Probabilistic execution
● Run forward & catch all random choices (“hijack” all calls to RNG)● Record an execution trace: a record of all parameters, random choices, outputs
○ Conditioning: compare simulated output and observed data● Approximate the distribution of parameters that can produce (explain)
observed data, using inference engines like Markov-chain Monte Carlo (MCMC)
Observed dataInferred
parameters
This is hard and computationally costly● Need to run simulator up to millions of times● Simulator execution and MCMC inference are sequential● MCMC has “burn-in period” and autocorrelation
But we can amortize the cost of inference using deep learning

Sim. Trace
Sim.
⋮
Distributeddata generation
Trace
Trace⋮
Training data(execution traces)
⋮
Distributedtraining
Sim.Trained NN
NN
NN
NNHPC HPC
Training (recording simulator behavior)● Deep recurrent neural network learns all random choices in simulator● Dynamic NN: grows with simulator complexity
○ Layers get created as we learn more of the simulator○ 100s of millions of parameters in particle physics simulation
● Costly, but amortized: we need to train only once per given model

Sim. Trace
Sim.
⋮
Distributeddata generation
Trace
Trace⋮
Training data(execution traces)
⋮
Distributedtraining
Sim.Trained NN
NN
NN
NN
Sim.
Sim.
⋮
Distributed inference
Sim.
Trained NN
⋮
NN
NN
NN
Observed data
Trace
Trace
Trace⋮
Traces reproducingobserved data
Inferredparameters
HPC
HPC HPC
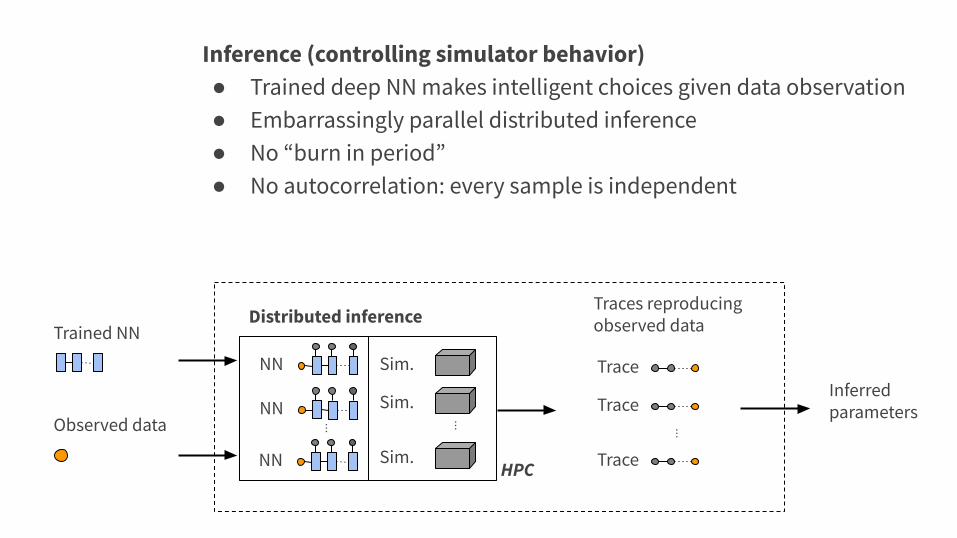
Sim.
Sim.
⋮
Distributed inference
Sim.
Trained NN
⋮
NN
NN
NN
Observed data
Trace
Trace
Trace⋮
Traces reproducingobserved data
HPC
Inference (controlling simulator behavior)● Trained deep NN makes intelligent choices given data observation● Embarrassingly parallel distributed inference● No “burn in period”● No autocorrelation: every sample is independent
Inferredparameters

Trained NN
Observed data
Inference (controlling simulator behavior)● Trained deep NN makes intelligent choices given data observation● Embarrassingly parallel distributed inference● No “burn in period”● No autocorrelation: every sample is independent
Inferredparameters

https://github.com/pyprob/pyprob
● Probabilistic programming system for simulators and HPC, based on PyTorchDistributed training and inference, efficient support for multi-TB distribution filesOptimized memory usage, parallel trace processing and combination
https://github.com/pyprob/ppx
● Probabilistic Programming eXecution protocolSimulator and inference/NN executed in separate processes and machines across networkUsing Google flatbuffers to support C++, C#, Dart, Go, Java, JavaScript, Lua, Python, Rust and othersProbabilistic programming analogue to Open Neural Network Exchange (ONNX) for deep learning
Pyprob_cpp, RNG front end for C++ simulators https://github.com/pyprob/pyprob_cpp
Probabilistic programming software designed for HPC
Containerized workflowDevelop locally, deploy to HPC on many nodes for experiments

30
etalumis → | ← simulateAtılım Güneş Baydin
Bradley Gram-Hansen
Lukas Heinrich
KyleCranmer
AndreasMunk
SaeidNaderiparizi
FrankWood
WahidBhimji
JialinLiu
Prabhat
GillesLouppe
LeiShao
VictorLee
PhilTorr
LawrenceMeadows
MingfeiMa
Xiaohui Zhao
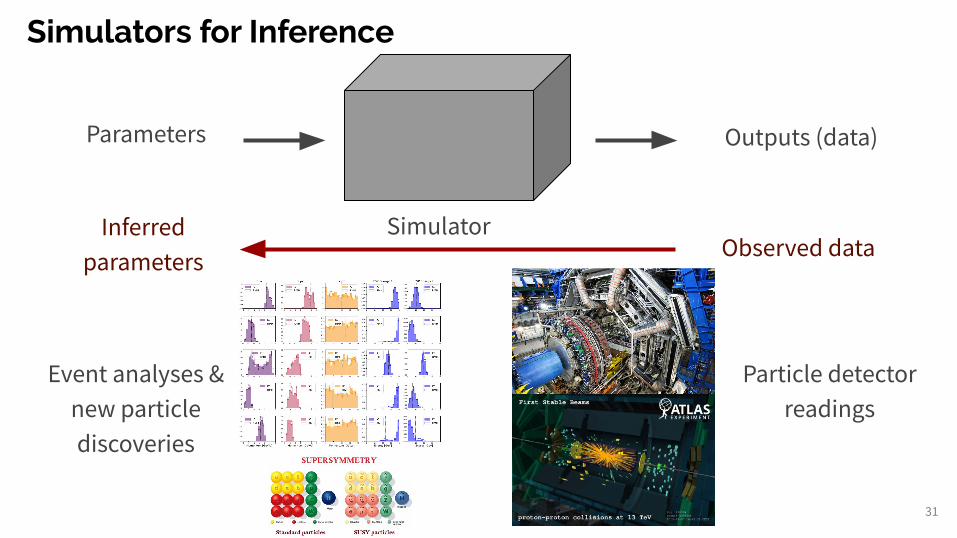
Simulators for Inference
31
Parameters Outputs (data)
SimulatorObserved data
Inferred parameters
Event analyses &new particle discoveries
Particle detector readings

● Seek to uncover secrets of the universe (new particles)○ Produced by the LHC and measured in detectors such as “ATLAS” and “CMS” ○ 100s of millions of channels 100s of Petabytes of collision data
Use case: Large Hadron Collider (LHC)
● Physicists compare observed data to detailed simulations○ Billions of CPU hours for scans of simulation parameters○ Currently compare, for example, histograms of summary statistics
■ Inefficient, labor-intensive, sometimes ad-hoc: not adaptive to observations
● Etalumis replaces this with automated, efficient inference; grounded in a statistical framework

Specific use case: tau lepton decay
● “Use the Higgs Boson as a new tool for discovery”: top science driver ○ One avenue is detailed study
of Higgs decay to tau leptons
https://www.usparticlephysics.org/brochure/science/
● Tau leptons decay to other particles observed in detector○ Rates for these ‘channels’ vary
over orders of magnitude○ Signs of new physics subtle,
need probabilistic approach

Physics expressed in simulator code
● We use popular existing Sherpa1 simulation (~1M lines of C++ code) and our own fast 3D detector simulation
● In this simulator the execution trace (record of all parameters, random choices, outputs) represents particle physics collisions and decays
● So etalumis enables interpretability by relating a detector observation to possible traces that can be related back to the physics○ These execution traces can be different length paths through the code ○ Different ‘trace types’ (same address sequence with different sampled
values) can occur at very different frequencies1https://gitlab.com/sherpa-team/sherpa

px
py
pz

Etalumis gives access to all latent variables: allows answering any model-based question

Reaching supercomputing scale

We are bringing together
38
● Need for using HPC resources and considerable optimization○ For all components but particularly NN training
SimulationProbabilistic programming
Supercomputing

● NERSC Cori Cray XC40 (Data partition)○ 16-core 2.3 GHz Intel® Xeon® Haswell (HSW)○ 1.8 PB Burst Buffer - (1.7 TB/s)○ 30PB Lustre filesystem (700 GB/s)
● NERSC Edison Cray XC30○ 12-core 2.4 GHz Intel® Xeon® Ivybridge (IVB)
● Intel Diamond Cluster○ 16-core 2.3 GHz Intel® Xeon® Broadwell
(BDW)○ 26-core 2.1 GHz Intel® Xeon® Skylake (SKL)○ 24-core 2.1 GHz Intel® Xeon® Cascade Lake
(CSL)
Platforms and experimental setup

Initial software release would take ~90 days to train one pass of 15M Trace Dataset!
Use dataset of 15M Sherpa execution traces (1.7 TB)
Challenging Neural Network and data structures:
Challenges to optimization and scaling of NN training
● Different ‘trace types’ can occur at very different frequencies ⇒ small effective batch size,
● Variation of execution trace length ⇒ load imbalance
● Dynamic NN - different architecture on different nodes ⇒ scaling challenge
● Data Loading initially took >50% of total runtime for single node training
● Non-optimized 3D Convolution for CPU in PyTorch

Single node performance
● PyTorch Improvements○ Enhancements for 3D CNN on CPU
with Intel MKL-DNN: 8x improvement ○ Sort/batch same trace types
together to improve parallelization and vectorization
● Data restructuring and parallel I/O○ I/O reduced from 50% of time to less
than 8%○ 40% reduction in memory
consumption
28XHaswell

● Optimization in application and PyTorch to minimize tensors communicated and allreduce calls: >4X improvement in allreduce time
Multi node performance
● Can reduce load-imbalance with multi-bucketing (inspired by NMT)
○ Up to 50% throughput increase - but trade-off with time to convergence

● Fully synchronous data parallel training on 1,024 nodes○ Adam-LARC optimizer with
polynomial decay (order=2) learning rate schedule
○ One of the largest-scale uses of builtin PyTorch-MPI
● 128k global mini-batchsize ○ Largest for this NN architecture
● Overall 14000x speedup:○ Months of training in minutes○ Ability to retrain model quickly is
transformative for research
Large scale training
500x
28XLogScale

REMINDER: we are doing all this to perform inference
44
Parameters Outputs (data)
SimulatorObserved data
Inferred parameters
Event analyses &new particle discoveries
Particle detector readings

● No current method in LHC physics analysis that gives full posterior
● So we compare amortized (inference compilation) approach to full MCMC○ Establish MCMC convergence
using Gelman-Rubin test● MCMC: single IVB node 115 hours● Inference Compilation: 30 mins on
64 HSW nodes (230x speedup)
Amortized - once trained - can be run on unseen collision data without the autocorrelation and ‘burn-in’ needed for independent samples in MCMC
Inference
230X

● Achieving MCMC “ground truth” is itself a new contribution in particle physics
● Amortized inference compilation (IC) closely matches MCMC (RMH)
● First tractable Bayesian inference for LHC physics○ Full posterior and
interpretability
Science results

More physics events

● Novel probabilistic software framework to execute & control existing HPC simulator code bases● HPC features: multi-TB data, distributed training and inference
● Synchronous data parallel training of a 3DCNN-LSTM neural network● 1,024 nodes (32,768 cores); 128k minibatch size (largest for this type of NN)● One of the largest-scale use of PyTorch built-in MPI
● Largest scale inference in a universal probabilistic programming language (one capable of handling complex science models)● LHC Physics use case: ~25,000 latents; Sherpa code base of ~1M lines of C++
Conclusions
Probabilistic programming is for the first time practical for large-scale, real-world science models

Simulation of composite materials(Munk et al. 2019, in sub. arXiv:1910.11950)
Simulation of epidemics(Gram-Hansen et al., 2019, in prep.)
This is just the beginning ...
Probabilistic programming is for the first time practical for large-scale, real-world science models

Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration.
No product or component can be absolutely secure.
Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. For more complete information about performance and benchmark results, visit http://www.intel.com/benchmarks .
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/benchmarks .
Intel Advanced Vector Extensions (Intel AVX)* provides higher throughput to certain processor operations. Due to varying processor power characteristics, utilizing AVX instructions may cause a) some parts to operate at less than the rated frequency and b) some parts with Intel Turbo Boost Technology 2.0 to not achieve any or maximum turbo frequencies. Performance varies depending on hardware, software, and system configuration and you can learn more at http://www.intel.com/go/turbo.
Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Cost reduction scenarios described are intended as examples of how a given Intel-based product, in the specified circumstances and configurations, may affect future costs and provide cost savings. Circumstances will vary. Intel does not guarantee any costs or cost reduction.
Intel does not control or audit third-party benchmark data or the web sites referenced in this document. You should visit the referenced web site and confirm whether referenced data are accurate.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Intel notices and disclaimers

![[SC19] Mapa FR](https://static.fdocuments.in/doc/165x107/568c4ab31a28ab49169941d0/sc19-mapa-fr.jpg)
















