
Pontificia Universidad Javeriana - econometriaavanzada.com · Existencia de heteroscedasticidad Por...
70
M. Misas A. 1 Econometría de Variable Dependiente Discreta Módulo 1 Pontificia Universidad Javeriana Cortes Transversales
Transcript of Pontificia Universidad Javeriana - econometriaavanzada.com · Existencia de heteroscedasticidad Por...

M. Misas A. 1
Econometría de Variable Dependiente DiscretaMódulo 1
Pontificia Universidad Javeriana
Cortes Transversales

M. Misas A. 2
Bibliografía
• Econometrics of Qualitative Dependent Variables:C. Gourieroux 2000, Cambridge University Press.• Limited-Dependent and Qualitative Variables in Econometrics:G. S. Maddala 1997, Cambridge University Press.• Econometric Analysis:W. Greene 2002, Fifth Edition, Prentice Hall • Advanced Econometrics:T. Amemiya 1989, Basil Blackwell.• A Companion to Theoretical EconometricsEdited by B. Baltagi 2001, Blackwell Publishers• Microeconometrics: Methods and ApplicationsC. Cameron and P. K. Trivedi• Econometric Analysis of Cross Section and Panel DataJ. M. Wooldridge• Econometric Methods with Application in Business and EconomicsC. Heij, P. Boer, P. Franses, T. Kloek and H. van Dijk.

M. Misas A. 3
http://www.la.utexas.edu/research/faculty/dpowers/book/ch3.html
http://www2.chass.ncsu.edu/garson/pa765/logistic.htm#LL
http://gulliver.trb.org/publications/nchrp/cd-22/v2chapter5.html
http://www.statsoft.com/textbook/stnonlin.html
http://www.cambridge.org/resources/0521815886/1208_default.pdf
http://www.sussex.ac.uk/Units/economics/Logistics/gss_lec1.doc
http://psfaculty.ucdavis.edu/scheiner/New_Folder/Democracy%20without%20Competition/Appendix/Appendix%208e,%20MNL%20and%20MNP%2010.1.04.pdf
http://socserv.socsci.mcmaster.ca/jfox/Courses/soc740/lecture-10.pdf
http://socserv.socsci.mcmaster.ca/jfox/Courses/soc740/lecture-10.pdf
http://www.math.aau.dk/~mbh/Teaching/MIKE04/l3.pdf
****

M. Misas A. 4
Usualmente los economistas trabajan con modelos que consideran variables dependientes continuas. Sin embargo, existen una variedad de problemas en los cuales el fenómeno quese trata de modelar es discreto.
Modelos con variable dependiente discreta
Modelos de selección discreta La variable dependiente iy
L,2,1,0
•Conteo: Años de escolaridad
•Respuesta cualitativa: Participación en la fuerza laboral
0
1
No
Si
•Ordenamiento: opiniones sobre una legislación
≡
≡
≡
≡
≡
favoraefuertement
favora
neutral
opuesto
totalopuesto
4
3
2
1
0

M. Misas A. 5
•Categorías: ocupación
≡
≡
≡
≡
≡
Arquitecto
Médico
oEstadístic
Economista
Ingeniero
4
3
2
1
0
En general, los valores en si mismos carecen de sentido. Estos se refieren a un código asociado a un evento cualitativo.
Modelos? Esquema que conecte dichos eventos Factores determinantes
BinarioMultinomial
binaria
con múltiples categoríasExplicar una variable dependiente

M. Misas A. 6
Modelo de selección binaria
Modelación de la selección de un individuo cuando dos alternativas están disponibles ysolo una de ellas es escogida
iy Variable aleatoria que representa la selección binaria del individuo sobreel evento
ésimoi −
iy
ocurrenoEsi
ocurreEsi
0
1
•La discusión debe ser abordada en términos de la probabilidad de ocurrencia del evento•La economía sugiere un conjunto de variables o factores que deben ser considerados cuandose va a tomar una decisión.•Individuos diferentes, bajo condiciones similares, podrían tomar diferentes decisiones de acuerdo a sus propia estructura de preferencias.
Ejemplo:Situación idéntica diferente decisión
•Aleatoriedad en el comportamiento humano•Cambios en factores omitidos
Variación en el comportamientode selección
E
E

M. Misas A. 7
Ejemplo:
Para un individuo, la utilidad media derivada de una selección se supone basada en:Atributos de la selecciónAtributos de los individuos
Un individuo tomador de decisiones debe decidir si para ir al trabajo se desplaza en:• carro • servicio de bus
Los atributos de la selección que son relevantes para un individuo incluyen:•El costo de usar el carro•El costo de viajar en bus•El tiempo del viaje en carro o en bus•El confort y la seguridad de cada uno de estos medios de transporte
Los atributos del individuo que pueden afectar la selección incluyen:•Ingreso•Ocupación•edad
No varían a través de las alternativas

M. Misas A. 8
( )( ) ( )01
1
==−
==
ii
ii
yprobP
yprobP
La función de densidad de probabilidad ( ) ( ) iiy
i
y
ii PPyf−−= 1
1
En economía se está interesado en examinar los factores que afectanla probabilidad de la selección iP
Distribución de Bernoulliiy ~
[ ]( ) ( )iii
ii
PPyVAR
PyE
−=
=
1
( )licativosfactoresdeconjuntofPi exp=
Objetivo econométrico: estimar los parámetros de la relaciónfuncional supuesta
El modelo estadístico más simple para describir una variable aleatoria binaria es la distribución de
Bernoulli

M. Misas A. 9
Modelo Lineal de probabilidad
iP Función lineal de un conjunto de variables explicativas
( ) β'iii XPyE ==
( )iii yEye −=
TieX
ePy
ii
iii
,,2,1'L=+=
+=
β
Interpretado como la probabilidad condicional a de que el evento ocurra
EiX
Primer problema: puede tomar cualquier valorhaciendo que las probabilidades asociadas a puedan ser mayores que 1 y menores que cero.
iyβ'iX
Acotado en el intervalo (0,1)
0,1,0,0,1,0,1,0,1
1,1,0,1,0,0,0,1,1
L
L⇒sseleccioneT
0
1
° ° ° °
° °° °
°
continuaX
discretay
i
i
β'
y
•.
• β'iX
Segundo problema:

M. Misas A. 10
( )iii eey Pr
ββ
ββ''
''
10
11
ii
ii
XX
XX
−−
−
Propiedades del término de perturbación
[ ] ( )
0
Pr2
1
=
=∑=i
iii eeeE
( ) ( )
( )[ ] [ ]( )ii
ii
i
iii
yEyE
XX
eeeVAR
−=
−=
=∑=
1
1
Pr
''
2
1
2
ββ
eXY += β( ) ( ) Ω== 'eeEeVAR Matriz diagonal
i
[ ] [ ]( )ii yEyE −1
Tercer problema:
Existencia de heteroscedasticidad
Por consiguiente, la estimación de los parámetros a través de OLS es ineficiente frente a GLSLa forma como GLS se implementa depende de la naturaleza de la información muestraldisponible.
Modelo en forma compacta

M. Misas A. 11
Caso 1 1=in
En este modelo, el número de resultados seleccionados observados para cada conjuntode variables explicatorias es . Es decir, solo se observa un valor de la variablealeatoria para cada diferente.
iy
iX 1=in
iX
La estimación puede realizarse a través de FGLS
i=Ω( ) ( )ββ ˆ1ˆˆ1ˆ ''
iiii XXyy −=−
2. Dado que la matriz es diagonal, FGLS coinciden con el procedimiento de mínimos cuadradosponderados. Cada observación de la variable dependiente como de las explicativas deben sermultiplicadas por:
Ω
( )ii yy ˆ1ˆ
1
−
3. Sobre las variables transformadas, la estimación puede llevarse a cabo a través de OLS
1. Estimación por OLS Tiiiiii eXePy ,,1'
L=∀+=+= βConsistenteIneficiente
¿Es posible utilizar métodos de regresión para analizar la relación entre y ?XY
Tamaño de muestra

M. Misas A. 12
Posibles dificultades:
β'iX Podría estar fuera del intervalo (0,1)
Ω Podría tener elementos negativos o no definidos en ladiagonal
Posibles soluciones: •Modificar borrando las observaciones asociadas al problema•Establecer dichos valores de entre 0.0001 y 0.9999
Ω
β'iXSi no afectan las propiedades
asintóticas de FGLS
βˆ '
ii XP = Podría estar fuera del intervalo (0,1)
Caso 2 1>in
Para cada vector de variables explicativas se encuentran disponibles observacionesrepetidas de . Es decir:
iX
iy 1>in
iy : Número de ocurrencias del evento en experimentos con el mismo vector devariables explicativas
E in
iX
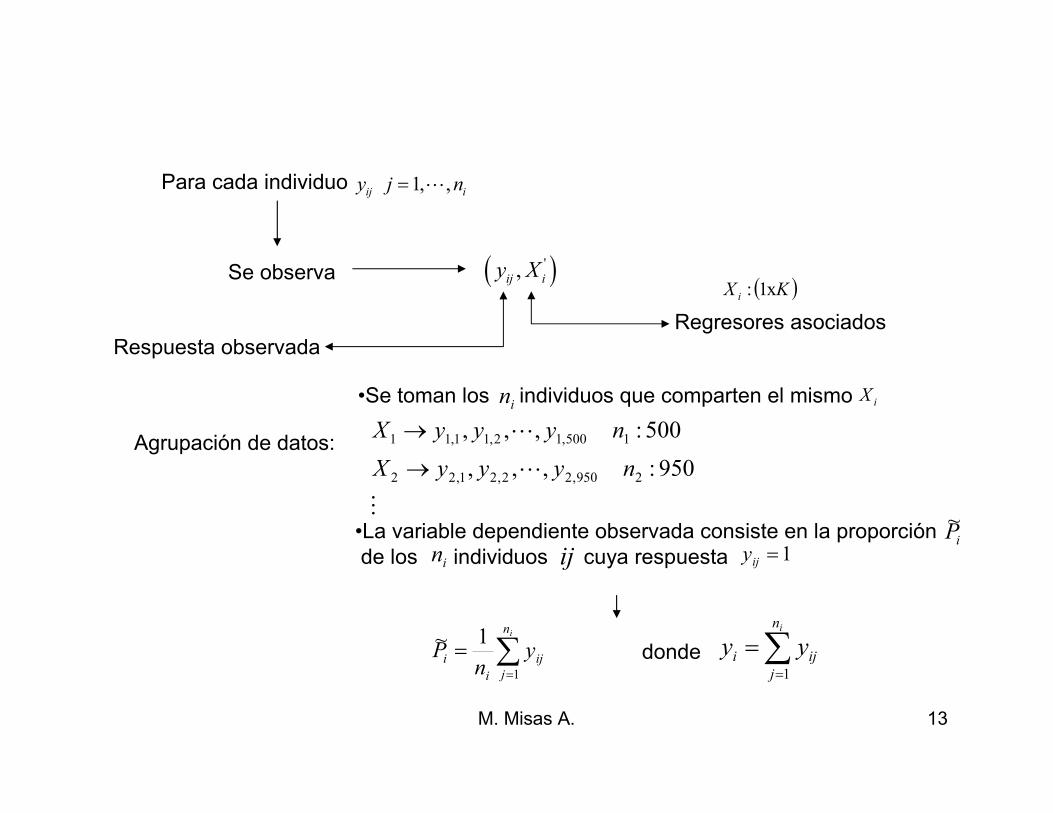
M. Misas A. 13
Se observa ( )',ij iy X
Para cada individuo 1, ,ij iy j n= L
( )KX i x1:
Regresores asociados
Agrupación de datos:
•Se toman los individuos que comparten el mismoin iX
•La variable dependiente observada consiste en la proporciónde los individuos cuya respuesta
iP~
in ij 1=ijy
∑=
=in
j
ij
i
i yn
P1
1~
M
L
L
950:,,,
500:,,,
2950,22,21,22
1500,12,11,11
nyyyX
nyyyX
→
→
Respuesta observada
∑=
=in
j
iji yy1
donde

M. Misas A. 14
[ ] β'~iii XPPE ==
TieX
ePP
ii
iii
,,1
~
'L=∀+=
+=
β
[ ]ii
iii
PP
PEPe
−=
−=~
~~
Propiedades del error:
Ti ,,1L=∀
[ ] 0=ieE
( ) ( )i
iii
n
PPeVAR
−=
1
i
ii
n
yP =~
Proporción muestral del número de ocurrencias del evento E
•La información consiste en la tripleta [ ] TiXPn iii ,,1~
L=

M. Misas A. 15
[ ] [ ] [ ]
0
~
=
−=
−=
ii
iii
PP
PEPEeE
( ) ( )
( )
( )
( )i
ii
ii
i
i
ji
i
i
ji
ii
n
PP
PPn
n
yVARn
n
y
VAR
PVAReVAR
j
j
−=
−=
=
=
=
∑
∑
1
1
1
~
2
2
Demostración
( ) [ ]
( )
( )
−
−
=Ω==−
T
TT
n
PP
n
PP
eeEe
1
1
covvar
1
11
'
O
O

M. Misas A. 16
El estimador apropiado para β ( ) PXXX~~ 1'11' −−− ΩΩ=β GLS
Si la verdadera proporción es no conocida iP ( ) PXXX~ˆˆ
~~ 1'11' −−− ΩΩ=β FGLS
i=Ω( )
i
ii
nPP ˆ1ˆ −
Estimador consistente de iPAlternativas
• Utilizar proporción muestralii PP
~ˆ = iP~ cae en el intervalo ( )10
•Considerar dondeβˆ '
ii XP = ( ) PXXX~ˆ '1' −
=β
•Basarse en donde es la estimación FGLS que considera βˆ '
ii XP = βiP
~
El predictor de FGLS podría caer fuera del intervalo ( )10
garantizar: 10 ' << βiX
in suficientemente grande para que la proporción sea una estimaciónconfiable de
iP~
iP
Dificultad:
En forma matricial eXP += β~
M. Misas A. 17
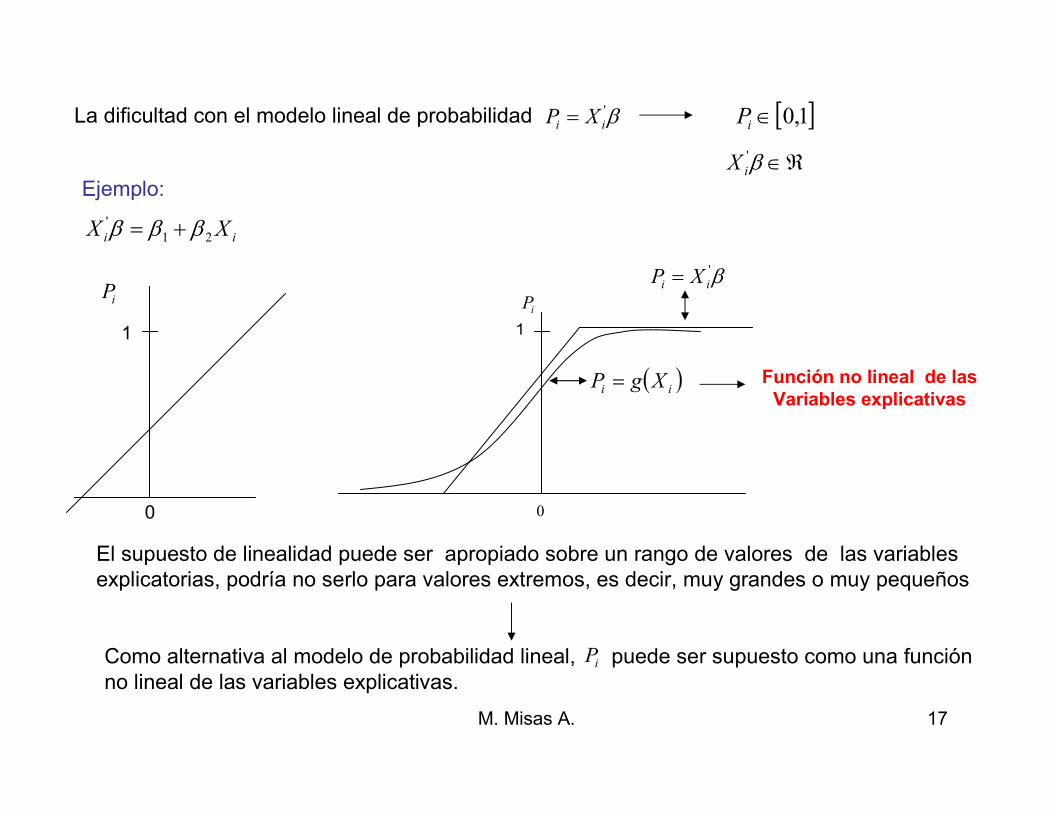
La dificultad con el modelo lineal de probabilidad β'ii XP = [ ]1,0∈iP
ℜ∈β'iX
Ejemplo:
ii XX 21
' βββ +=
El supuesto de linealidad puede ser apropiado sobre un rango de valores de las variablesexplicatorias, podría no serlo para valores extremos, es decir, muy grandes o muy pequeños
Función no lineal de las
Variables explicativas
iP
1
β'ii XP =
( )ii XgP =
0
Como alternativa al modelo de probabilidad lineal, puede ser supuesto como una funciónno lineal de las variables explicativas.
iP
iP
0
1

M. Misas A. 18
Se utilizan dos funciones no lineales : Funciones de densidad acumulada de variablesaleatorias normal y logística.
( )iXg
Normal estándar c.d.f. ( ) ( ) dxx
tF
t
−
=−
∞−∫ 2
exp222
1
π
Logística c.d.f. ( )( )[ ]t
tF−+
=exp1
1
SimétricasMedia ceroNormal estándar 12 =σ
3
22 π
σ =Logística
Normal estándar
Logística
Logística
Normal

M. Misas A. 19
Modelo Probit
Modelo LogitFunción de densidad acumulada
Normal
Logística
¿Cómo entender este tipo de modelos?
Una respuesta:
Supóngase que el evento es una acción tomada por un individuo si su utilidadesperada es suficientemente alta.
¿Qué tan suficientemente alta? depende de cada individuo.
E
β'iXiI =Sea una variable indicadora latente, lineal en . Mientras mayor sea lavariable indicadora mayor es la probabilidad de que el evento suceda.
β
E
Dado que la probabilidad debe caer en el intervalo [ ]1,0
iI [ ]iIEPrRelación monotónica
Debe asumir la forma general de unafunción de densidad acumulada

M. Misas A. 20
Suponemos
•Todos los individuos ponderan todos los factores explicativos de igual Forma. Es decir, es constante a través de los individuos.•De todos los individuos que consideran algunos elegirán a y otros no. La no selección se da tan sólo por preferencias personales.
iX β
Eβ'iX
Argumento para seleccionar la función de distribución acumulada:
Cada individuo hace una selección entre y no comparando el valor de con algún umbralE E iI *I
Si ocurreEII i ⇒> *
Para cada individuo el valor del umbral está determinado por un gran número de factores independientes
*I
Los cuales siguen una distribución normal con base en el Teorema Central del límite
[ ] [ ] ( ) ( )β'*PrPr iiiii XFIFIIIEP ==≤==
Con el modelo Logit se considera: [ ] ( ) ∞<<∞−−+
=≤= ββ
β '
'
'*
exp1
1Pr i
i
ii XX
XIP

M. Misas A. 21
La utilidad derivada de la selección
00
''
0000 iiiiii ewzeuu ++=+= γδ
11
''
1111 iiiiii ewzeuu ++=+= γδ
donde
1
0
i
i
u
uUtilidad de las dos selecciones
aleatorias
1
0
i
i
u
uUtilidad promedio de las dos selecciones
'
1
'
0
i
i
z
zCaracterísticas de las alternativas percibidas por el individuo i
iw Características socioeconómicas del individuo i
1
0
i
i
e
ePerturbaciones aleatorias
El individuo seleccionará la alternativa 1 si y solo si i 01 ii uu >

M. Misas A. 22
Es decir, si la variable latente 001
* >−= iii uuy
Los valores de la variable aleatoria observable
≤
>=
00
01*
*
i
i
iysi
ysiy
( ) ( ) ( )
( )[ ]*'
*
01
''
0
'
1
0101
''
0
'
1
*
ii
iiii
iiiiii
eX
ewzz
eewzzy
+=
+
−−=
−+−+−=
β
γγδ
γγδ
Modelo estadístico lineal
La probabilidad de que 1=iy
[ ] [ ] [ ]β'** 01 iiiii XeprobyprobyprobP −>=>===
Así, el modelo requiere de la distribución de probabilidad de *
ie
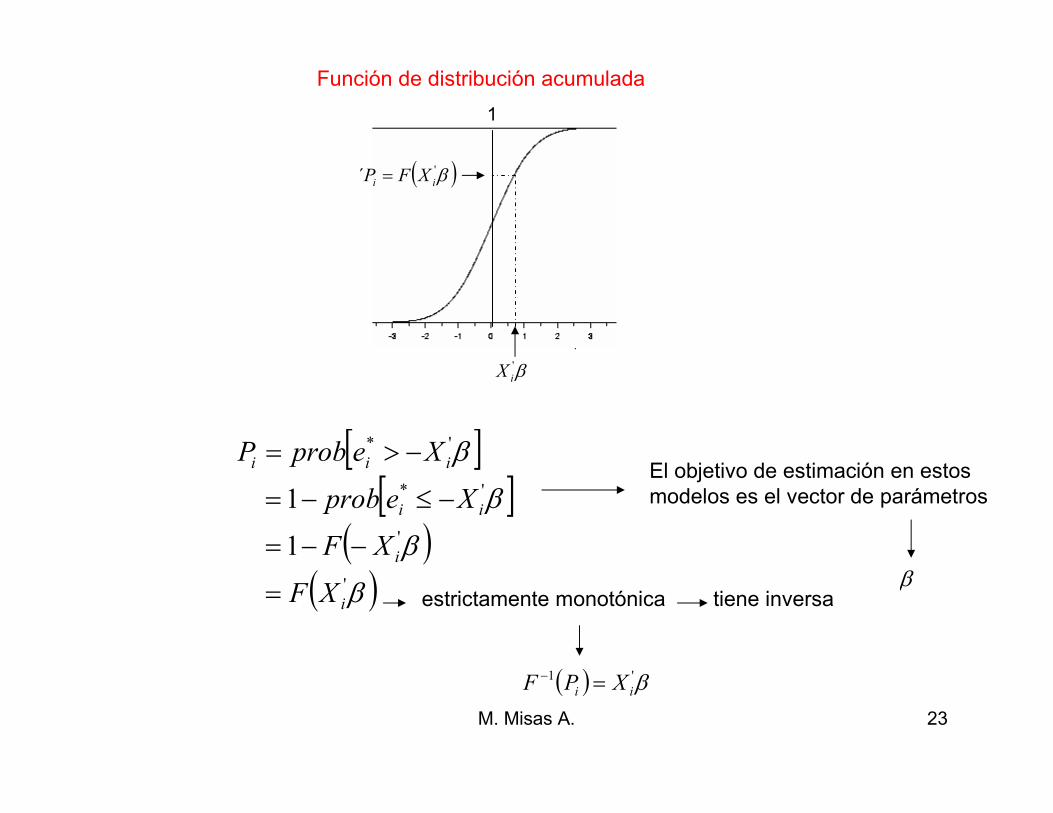
M. Misas A. 23
β'iX
( )β'´ ii XFP =
1
[ ][ ]
( )( )β
β
β
β
'
'
'*
'*
1
1
i
i
ii
iii
XF
XF
Xeprob
XeprobP
=
−−=
−≤−=
−>=El objetivo de estimación en estosmodelos es el vector de parámetros
β
Función de distribución acumulada
( ) β'1
ii XPF =−
estrictamente monotónica tiene inversa

M. Misas A. 24
Estimación FGLS del modelo Probit
Supóngase que para cada vector hay observaciones y de éstas resultan en elevento
iX iniy
E
La proporción muestral está relacionada con la verdadera proporción i
ii
n
yP =~
iii ePP +=~
[ ] 0=ieE
( ) ( )i
iii
n
PPeVAR
−=
1
[ ] ( )i
tI
ii IFdtePIEi ===
−
∞−∫2
2
2
1Pr
π ( ) ( )iii ePFPF += −− 11 ~
Inversa de la función de distribuciónacumulativa de la normal estándar
Expansión de Taylor de alrededor de ( )ii ePF +−1iP
( ) ( ) ( )ii
i
iiii Re
dP
PdFPFePF +
+=+
−−−
111
( ) ( )( )( )i
iii
PFf
ePFPF
1
11 ~−
−− +≅
Función de densidad de la normal estándar
( )β'ii XFP =
( ) ( ) ( )( ) ( )xRaxafafxf +−+≅ '
Tarea

M. Misas A. 25
( )ii
ii
uX
PFv
+=
= −
β'
1 ~Probit observado
Perturbación aleatoria
Propiedades del término de error
[ ]( )[ ]
( )[ ] [ ] 011
1
==
=
−
−
i
i
i
ii
eEPFf
PFf
eEuE
Ti ,,1L=∀
( )( )[ ]
( )( )[ ]( )211
1
ii
ii
i
ii
PFfn
PP
PFf
eVARuVAR
−−
−=
= Heterogeneidad en la varianza
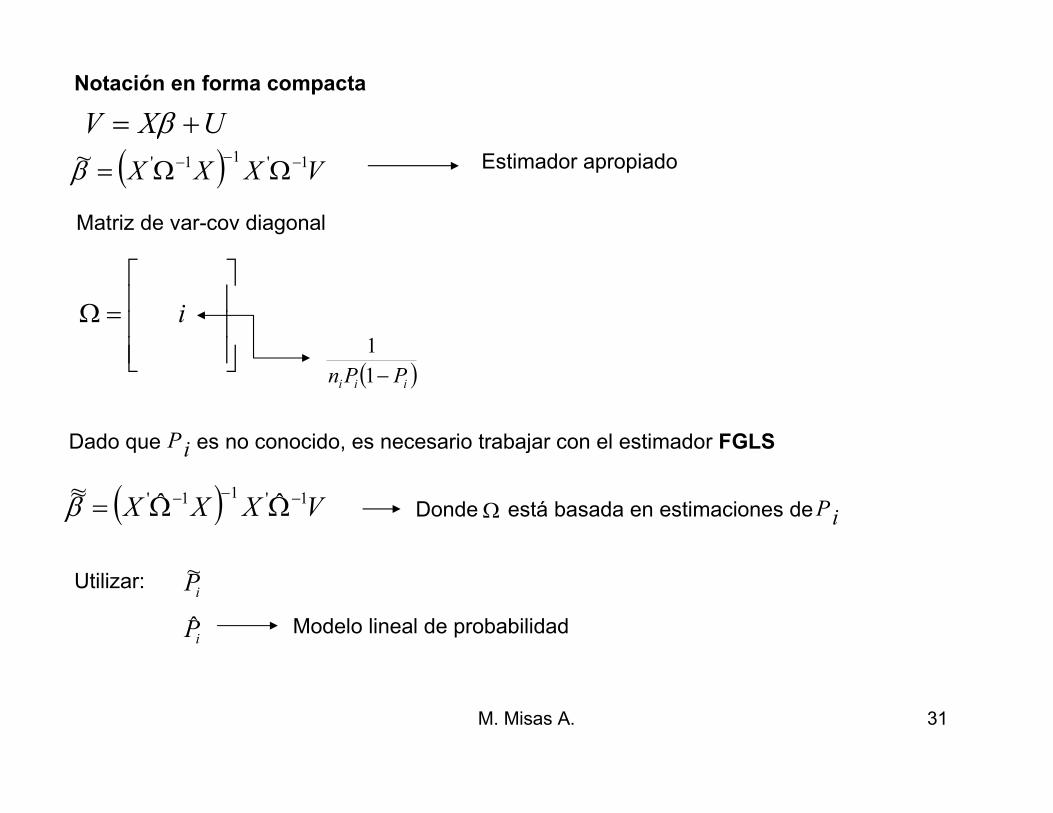
Notación en forma compacta
UXV += β
( ) VXXX 1'11'~ −−− ΩΩ=βEstimador apropiado

M. Misas A. 26
=Ω i
Matriz de var-cov diagonal
( )( )[ ]( )21
1
ii
ii
PFfn
PP−
−
Dado que es no conocido, es necesario trabajar con el estimador FGLS
( ) VXXX 1'11' ˆˆ~~ −−− ΩΩ=β
iP
Donde está basada en estimaciones de Ω iP
•Utilizar la proporción muestral
•Predicción OLS del modelo lineal de probabilidad
•Estimar:
iP~
( ) PXXXP~ˆ '1' −
=
( )
( )( ) ( )1,0
ˆ
ˆ
1''
ˆ
Ntf
VXXXv
dttfP
ii
v
i
i
−
∞−
=
= ∫

M. Misas A. 27
Estimación FGLS del modelo Logit
Las proporciones muestral y verdadera están relacionadas de la siguiente forma:
iii ePP +=~
“Odds ratio”
( )
−−
+
−=
−−+
=−
i
i
i
i
i
i
ii
ii
i
i
Pe
Pe
P
P
eP
eP
P
P
11
1
.11
~1
~
“Log- odds”
−−−
−+
−=
− i
i
i
i
i
i
i
i
P
e
P
e
P
P
P
P
11ln1ln
1ln~
1
~ln
Expansión de Taylor alrededor de:
i
i
i
i
P
e
P
e
−1;
En general:
( ) ( ) ( )( )axafafxf −+≅ '
i
i
i
i
i
i
i
i
P
e
P
e
P
P
P
P
−++
−≅
− 11ln~
1
~ln
?
TAREA: REVISAR LA SIGUIENTE DEMOSTRACIÓN:

M. Misas A. 28
( ) ( )i
iii
i
i
i
i
i
i
i
i
i
i
i
i
i
i
P
ePe
P
e
P
e
P
e
P
e
P
e
P
e
P
e
+−=
+
=
−++
≅
−
lnln
ln
1ln1ln
Demostración ?
( ) ( )i
iii
i
i
i
i
i
i
i
i
i
i
i
i
i
i
i
i
P
ePe
P
e
P
e
P
e
P
e
P
e
P
e
P
e
P
e
−−−−=
−+
−=
−−
−+
−+
−=
−+≅
−−
11lnln
11ln
111
11ln
11ln
11ln
( ) ( ) ( )( )i
iiiii
P
PPPPP
ln
1ln1ln
=
−−+≅−
( ) ( )i
iii
P
ePe
−−−=
1lnln

M. Misas A. 29
( ) ( ) ( ) ( )
i
i
i
i
i
i
i
iii
i
iii
i
i
i
i
P
e
P
e
P
P
P
ePe
P
ePe
P
P
P
P
−++
−=
−++−+−+
−≅
−
11ln
1lnlnlnln
1ln~
1
~ln
De esta forma se tiene:
Al reemplazar por la logística tenemos:
( )
( )
( )( )( )
( )( )
( )β
β
β
βββ
β
β
'
'
'
'
'
'
'
'
exp
1ln
exp1
exp
exp1
1
ln
exp1
11
exp1
1
ln1
ln
i
i
i
i
i
i
i
i
i
i
X
X
X
X
X
X
X
X
P
P
=
−−=
−=
−+−−+
=
−+−
−+≅
−

M. Misas A. 30
( )ii
ii
i
i
i
ii
i
i
PP
eX
P
e
P
eX
P
P
−+=
−++=
−
1
1~
1
~ln
'
'
β
β
Así, se tiene:
iii uXv += β' donde
−=
i
ii
P
Pv ~
1
~ln Logit observado
( )ii
ii
PP
eu
−=
1
Propiedades del término de error
[ ]( )
( )[ ] 0
1
1
1
=−
=
−=
i
ii
ii
ii
eEPP
PP
eEuE
Valor esperado Varianza
( )( )
( )( )[ ]
( )[ ]( )
( )iii
i
ii
ii
ii
i
ii
ii
PPn
n
PP
PP
PP
eVAR
PP
eVARuVAR
−=
−
−=
−=
−=
1
1
1
1
1
1
1
2
2
M. Misas A. 31
Notación en forma compacta
UXV += βEstimador apropiado( ) VXXX 1'11'~ −−− ΩΩ=β
=Ω i
Matriz de var-cov diagonal
Dado que es no conocido, es necesario trabajar con el estimador FGLS
( ) VXXX 1'11' ˆˆ~~ −−− ΩΩ=β
iP
Donde está basada en estimaciones de Ω iP
( )iii PPn −1
1
Utilizar:iP
~
iP Modelo lineal de probabilidad

Interpretación de coeficientes en los modelos probit y logit
β'iX Función indicadora: iX
βVariables explicatorias
Vector de parámetrosIndice escalar
( )xF Función de Transformación
( ) ( ) ( ) ( )0 , 1 ,0 >≡=∞=∞−
dx
xdFxfFF
•Propiedades de la CDF de una distribución deProbabilidad•Función no lineal
ℜ∈β'iX ( ) ( )1,0' ∈βiXF
cambios en el valor de afecta en forma no lineal
=
ik
i
i
i
X
X
X
XM
2
1
Si ijX [ ] ii PyE ==1
[ ] ( ) ( ) ji
ij
i
ij
i
ij
iiXf
X
XF
X
P
X
Xyββ
β '
'1Pr=
∂
∂=
∂
∂=
∂
=∂
j-ésimo elemento de β
Un punto de interés es la determinación del efecto marginal de un cambio en un regresor sobre la probabilidad condicional de que 1iy =

•El efecto marginal de un cambio en las variables explicativas depende del nivel de éstas
•La función de densidad tiene relativamente menos valores en las colas y más valores cercade la media el efecto es más pequeño para los individuos
Así, la magnitud de la derivada es proporcional a la función considerada ( )β'iXf
( )β'iXf En general alcanzan su máximo en y luego cae en la medida en que 0' =βiX
β'iX se incrementa
f[ ] 01 →=iyP
[ ] 11 →=iyP
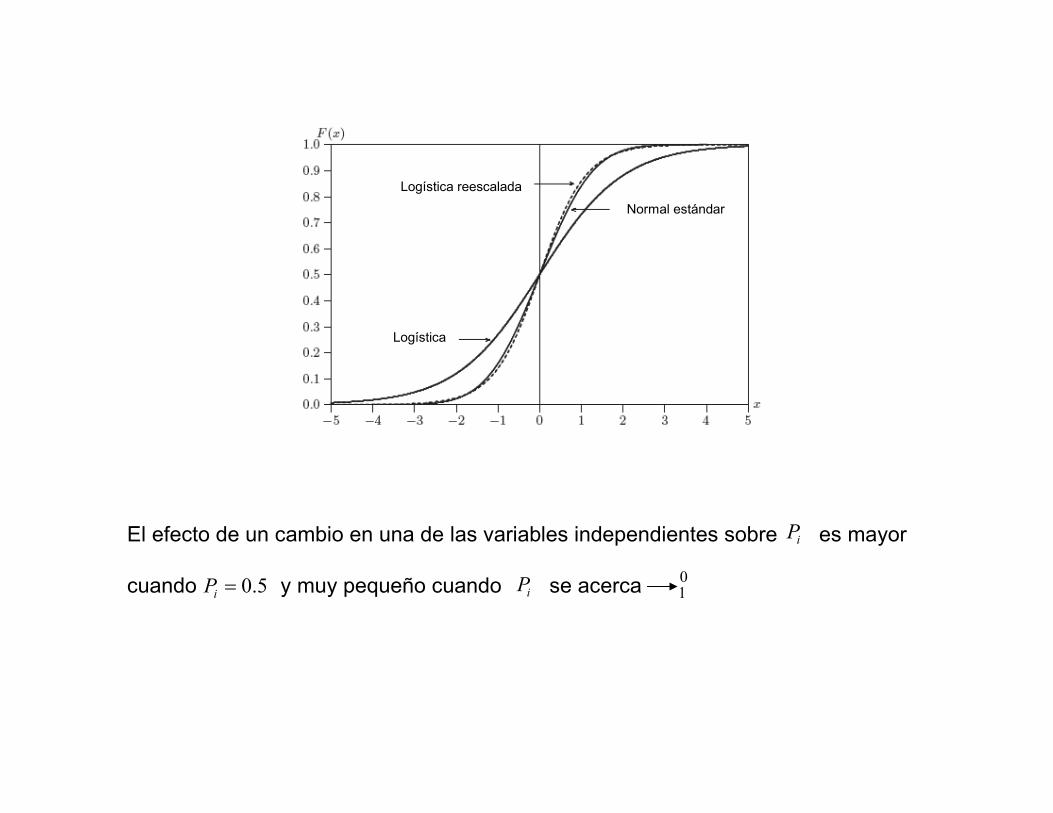
El efecto de un cambio en una de las variables independientes sobre es mayor
cuando y muy pequeño cuando se acerca
iP
5.0=iP iP 10
Normal estándar
Logística reescalada
Logística

Efectos marginales de las variables explicativas:
( ) ( ) j
ij
i
ij
i
iXf
X
XF
X
Pββ
β '=
∂∂
=∂∂
•Dado que el efecto marginal depende de los valores de varían a través de losindividuos
iX
•El efecto de la j-ésima variable explicativa puede ser resumido en el efecto marginal mediosobre los n individuos de la muestra
[ ] ( ) kjXfnX
yP
n
n
iij
n
i ij
i ,,2,1 111
1
'
1
L==∂
=∂∑∑==
ββ
[ ]ij
ii
x
XyE
∂
∂Efecto marginal del cambio de un regresor sobre la probabilidad condicional de que 1=iy
Recordar: Efectos marginales en modelos no lineales

M. Misas A. 36
•Los coeficientes estimados no indican el incremento en la probabilidad del evento ocurridodada una unidad de incremento en la correspondiente variable explicativa.
•En los dos modelos, la cantidad del incremento en la probabilidad depende de la probabilidad original y de los valores iniciales de todas las independientes y sus coeficientes.
( )β'ii XFP =
( )
ji
X
i
ji
i
i
X
dttX
XfX
P
i
j
j
ββπ
π
ββ
β
2
'
2
'
2
1exp
2
1
2
1exp
2
1'
−=
−∂∂
=
=∂∂
∫∞−
Función de densidad de probabilidad
Modelo Probit
( )( )[ ] j
i
i
i
i
X
X
X
P
j
ββ
β2'
'
exp1
exp
−+
−=
∂∂
Modelo Logit
Si( )β'exp1
1
i
iX
P+
=

M. Misas A. 37
Estimación Máximo verosímil de los modelos Probit y Logit
Cuando el número de observaciones repetidas en el experimento de selección es pequeño(uno o muy pocos) y no puede ser estimado con confianza utilizando la proporción de muestra,entonces la estimación máximo verosímil de los modelos Logit y Probit debe ser llevada acabo
in
iP
Si es la probabilidad de que el evento ocurra en la repetición del experimentoes una variable aleatoria que tiene la siguientes funciones de densidad de probabilidad:
iP E ésimai −
iy⇒
( )
−=
i
i
iPadprobabilid
Padprobabilidy
10
1
T observaciones
Función de verosimilitudFunción de densidad de probabilidad
( )( )iiy
i
T
i
y
i PPL−
=
−=∏ 1
1
1
•Los modelos Probit y Logit son no lineales en los parámetros y pueden ser estimados através de máxima verosimilitud. En general la estimación de este tipo de modelos se realizamediante la maximización de la función de verosimilitud
•En particular:
∑=i
inT
( )n Otra notación

M. Misas A. 38
Los modelos Logit o Probit se tienen cuando es dada por la función de distribución acumulativaLogística o normal evaluadas en
iP
( )ββ '' : ii XFX
( )[ ] ( )[ ]( )i
iy
i
yT
i
i XFXFL−
=
−=∏1'
1
' 1 ββ
( )[ ] ( )[ ]( )
( )[ ] ( ) ( )[ ]ββ
ββ
''
1
1'
1
'
1ln1ln
1lnln
iii
T
i
i
y
i
yT
i
i
XFyXFy
XFXFLi
i
−−+=
−=⇒
∑
∏
=
−
=
Cuando es la logística o la normal estándar acumulativa, las condiciones de primer ordenpara un máximo no son lineales. Así, las estimaciones máximo verosímiles deben de serobtenidas numéricamente.
F
Un algoritmo de optimización frecuentemente utilizado es el de Newton-Raphson:
kk
LLkk
βββββββ
ββ~
1
~'
2
1
lnln~~
=
−
=
+
∂∂
∂∂∂
−=
Tanto la matriz de segundas derivadas como el gradiente son evaluados en la iteraciónk

M. Misas A. 39
El estimador de máxima Verosimilitud es consistente:
( )
∂∂∂
−→−−1
'
2 ln,0
~
ββββ
LETNT
Asy
En muestras finitas, la distribución asintótica de puede ser aproximada por:β~
∂∂∂
−−
=
1
~'
2 ln,
ββββ
βL
N
Algunos resultados importantes para la construcción de la primera y segunda derivada:
Logit ( )β'ii XFP =
( )( )t
tF−+
=exp1
1
( ) ( )( )[ ]2exp1
exp
t
ttf
−+
−=
( ) ( )tFtF −=−1
( )( )
( )tFtF
tf−=1
( ) ( ) ( ) ( ) ttFtftf −−−= exp1'
Definida negativa

M. Misas A. 40
Para el modelo Logit se puede mostrar que:
( )[ ] ( ) ( )[ ]
( ) ( ) ( )
( )( )
( ) i
T
i i
i
i
i
i
T
i
iiii
iii
T
i
i
XX
y
X
y
XXFyXFy
XFyXFyL
∑
∑
∑
=
=
=
−+
−−
+=
−−−=
∂
−−+∂
=∂
∂
1''
1
''
''
1
exp1
1
exp1
1
1ln1lnln
ββ
ββ
β
ββ
β
( ) ( ) ( )
( )( )( )[ ]∑
∑
∑
=
=
=
−+
−−=
−=
−−−
∂∂
=∂∂
∂
T
i
ii
i
i
T
i
iii
i
T
i
iiii
XXX
X
XXXf
XXFyXFyL
1
'
2'
'1
''
1
''
'
2
exp1
exp
1ln
β
β
β
βββββ

Para el modelo Probit se puede mostrar que:
( )β'ii XFP =
( )
−= 2
2
1exp
2
1ttf
π ( ) ( )dvvftFt
∫ ∞−=
( ) ( )ttftf −='
En general:
( )( ) ( ) ( )
( )[ ] i
T
i i
ii
i
ii X
XF
Xfy
XF
Xfy
L∑=
−−−=
∂∂
1'
'
'
'
11
ln
ββ
ββ
β
( ) ( ) ( ) ( )( )
( ) ( ) ( ) ( )[ ]( )[ ]
'
12'
'''
2'
''''
'
2
1
11
lnii
T
i i
iiii
i
iiiii XX
XF
XFXXfy
XF
XFXXfyXf
L∑=
−
−−−+
+
−=∂∂
∂
β
βββ
β
ββββ
ββ
kk
LLkk
βββββββ
ββ~
1
~'
2
1
lnln~~
=
−
=
+
∂∂
∂∂∂
−=
M. Misas A.41

M. Misas A. 42
Los valores iniciales no son problema dado que Dhrymes muestra que la matriz de las segundasderivadas es definida negativa para todo valor de .
Por consiguiente:• El procedimiento de Newton-Raphson converge.
•La unicidad de la estimación de máxima Verosimilitud no depende del valor inicial.
β
Utilizando estas derivadas y la relación recursiva, los estimadores máximo verosímilespueden ser obtenidos partiendo de un valor inicial:
1~β
Se recomienda utilizar como valor inicial el estimador OLS de en la regresión β ( )ii Xfy =

Inferencia estadística
•Pruebas de hipótesis sobre coeficientes:
El método más sencillo para una restricción simple puede llevarse a cabo a través del esquema de la prueba usual utilizando los errores estándar que provienen dela matriz de información.
t
Dada la distribución normal del estimador, los valores críticos pueden ser obtenidosde la distribución normal estándar.
En el caso de múltiples restricciones:
1
~'
2 ln−
=
∂∂∂
−ββ
ββL
Máximo verosímil
1.
2. rR =β
( ) [ ] ( )rRRVarEstRrRW −−=−
βββ ~~Asint
~ 1'' ( )J2χTest de Wald
Lagrange Multiplier [ ]UR LLLR ˆlnˆln2 −−= ( )J2χ
M. Misas A.

M. Misas A.44
0: 20 === kH ββ L
Puede ser probada o verificada fácilmente a través de la razón de verosimilitud, dado queel valor de la función de verosimilitud bajo la hipótesis nula es obtenido analíticamente.
Si es el número de éxitos observados en la muestra de tamaño , entoncespara los modelos Probit y Logit, el valor máximo de la función de Verosimilitud bajo la hipótesis nula es:
n ( )1=iy T
Si la hipótesis es verdadera, asintóticamente se tiene:
( ) ( )[ ] ( )1~ˆlnˆln2 2 −Γ−− kLwL χ
Donde es el valor del logaritmo de la función de verosimilitud evaluada en ( )Γln L β~
Una verificación usual es probar que todos los coeficientes son iguales a cero, excepto laconstante no restringida.
3.
( ) ( )
−−+
=T
nTnT
T
nnwL lnlnˆln
El no rechazo de esta hipótesis debería implicar que las variables explicativas no tuvieranEfecto sobre la probabilidad de que el evento ocurra.E
En este caso la probabilidad de que es estimada por (proporción muestral)1=iyT
nPi =~

Diagnóstico
1. Bondad de Ajuste
•La significancia individual de las variables explicativas puede ser probada por el usual estadístico “t” basado en la matriz de varianza covarianza:
1
~'
2 ln−
=
∂∂∂
−ββ
ββL
Dado el tamaño de la muestra, suficientemente grande, el estadístico “t” puede aproximarse a la distribución normal estándar.
•Pseudo R2
Una medida en general reportada es el pseudo R2( )( )Γ
−=ˆln
ˆln12 w
ρ
Esta medida es 1 cuando el modelo es predictor perfecto, en el siguiente sentido:
( )
==
===
00ˆ
11~ˆ '
ii
iii
ysiP
ysiXFP β
es 0 cuando ( ) ( )wLL ˆlnˆln =Γ No tiene interpretación alguna entre estos dos valores
M. Misas A.

Calidad de la predicción
Las especificaciones alternativas de los modelos pueden ser comparadas evaluando si el modelo proporciona una buena clasificación de los datos en las dos categorías:
1 o 0i iy y= =
El modelo estimado permite encontrar como la probabilidad estimada de que el individuo ˆi
P
1iy =
Dicha probabilidad puede transformarse en una selección estimada ˆ 1iy =
ˆˆ 1 si
ˆˆ 0 si
i i
i i
y P c
y P c
= >
= ≤
•La selección de puede basarse en los costos de una equivocada clasificación. •En general, •Si la fracción de éxitos difiere del 50% se puede considerar
0.5c =c
P% c P= %
La tasa de ajuste se define como la fracción de predicciones correctas en la muestra:h
1
ˆ1 si 1
ˆ0 si
ni i i
i
ii i i
w y yh w
w y y n =
= =→ =
= ≠∑
Se genera una tabla de dos vías declasificación ii yy ˆ vs
Variable aleatoria indicadora
de la predicción correcta

•En la población la fracción de éxitos es P
• Si se lleva a cabo aleatoriamente la predicción de 1 con probabilidad y la de 0 conprobabilidad la predicción correcta tendrá probabilidad
P
( )P−1 ( )22 1 PP −+=υ
• Utilizando las propiedades de la distribución binomial para el número de prediccionesaleatorias correctas se define la tasa aleatoria de ajuste:
[ ]
( ) ( )n
hVAR
hEh
r
rr
υυ
υ
−=
=
1
:
La calidad predictiva del modelo puede ser evaluada comparando con hrh
Bajo la hipótesis nula de que las predicciones del modelo no son mejores que las llevadas acabo de forma aleatoria se tiene:
( )
−n
Nhυυ
υ1
,~
De tal forma que se puede construir el siguiente estadístico de prueba:

( ) ( )( )1,0~
11N
n
nnh
n
hz
υυυ
υυυ
−
−=
−
−=
nh Número total de predicciones correctas
υn Número total de predicciones correctas tomadas aleatoriamente
El rechazo de la hipótesis nula de predicciones aleatorias significa que el modelo considerado produce mejores predicciones que el aleatorio.

•Residuales estandarizados
Los residuales del modelo de respuesta binaria se definen como la diferencia entre el valorobservado y la probabilidad
ie
iyiP
La varianza de es iy ( )ii PP −1
Los residuales estandarizados se definen:
( )ii
iii
PP
Pye
ˆ1ˆ
ˆ*
−
−=
1. El histograma de los residuales estandarizados puede ser de interés para detectar valoresatípicos.
2. Scatter plot de dichos residuales vs. las variables explicatorias puede ayudar a determinarla presencia de heteroscedasticidad.
Existencia de heteroscedasticidad

•Test de multiplicadores de Lagrange
Un test formal para heteroscedasticidad puede basarse en un modelo indicador:
'
* '
~
i
i i i
i
i
Z
i
y X
F
eγ
β ε
εσ
σ
= +
= Siendo variables observadasiZ
1. Estime por ML el modelo sin heteroscedasticidad, 0 : 0H γ =
2. Regrese sobre el gradiente del modelo no lineal , tomando en cuenta la heteroscedasticidad
[ ] '
'
1i
ii Z
XP y F
eγ
β = =
Mínimos cuadrados ponderados
Nota: OLS después de dividir la observación por la desviación estándari ésima−
-Peso:( )1
ˆ ˆ1iP P−
[ ] ( )β'1 ii XFyP ==
( )ii
iii
PP
Pye
ˆ1ˆ
ˆ*
−
−= Residuales estandarizados
*
ie

-Gradiente de '
'
en 0i
iZ
XF
eγ
β γ =
( )
( )
'
'
'' '
'' '
i
i
ii iZ
ii i iZ
XF f X X
e
XF f X X Z
e
γ
γ
β ββ
β β βγ
∂ = ∂
∂ = − ∂
-Regresión auxiliar OLS
( )( )( )
( )( )
' '
* ' '
1 2
ˆ ˆˆˆ
ˆ ˆ ˆ ˆ ˆ ˆ1 1 1
i ii i
i i i i i
i i i
f X f Xy Pe X X Z
P P P P P P
β βδ β δ η
−= = + +
− − −
4. Bajo 0 : HomoscedasticidadH
( )2 2~ :ncLM nR g gχ= Número de variables explicativas en Z
donde
( )
( )
2*
2
2*
i
inc
i
i
e
Re
=∑
∑

M. Misas A. 52
Ejemplo: se participa en la fuerza laboral⇒=1iy
( ) ( )hijos de número educación, familiar, Ingreso, edad edad, c, 1 2FyprobP ii ===
568.0753
428~ ==P
Función de verosimilitud restringida: 87.514753
325ln x 325
753
428lnx 428 −=
+
Función de verosimilitud No restringida: -490.84
Estadística 02.482 =χ
( ) 07.1152 =χValor crítico
ivassignificat no conjuntoen Variables:0H
Evidencia para rechazar la hipótesis nula

Modelo de selección múltiple
El tomador de decisiones se enfrenta a múltiples alternativas
Cada individuo enfrenta alternativas, de las cuales una debe ser seleccionadaJ
ijP Probabilidad de que el individuo seleccione la alternativa ji
( )ijiii yyyy L21
' = donde solo un elemento será igual a 1 y 0 los restantes elementos
Si cada individuo es observado una sola vez
Tyy ,,1 LFunción de verosimilitud
∏=
=T
i
y
iJ
y
iiJi PPL
11
1 L
M. Misas A. 53
Selección del individuo i
[ ] ( ) JjXFjyP ijiij ,,1 Pr 'L==== β
( )
jFj
los sobre 1 Suma
1,0 intervalo elen Cae :
ijy
ij
J
j
T
i PL 11 == ΠΠ=
Densidad
Multinomial

M. Misas A.54
•El problema de interés es permitir que la selección de probabilidades dependa de lascaracterísticas de las alternativas disponibles y de los individuos tomadores de decisión
•Para modelar la decisión individual, se supone la existencia de un tomador de desicionespromedio. Supongase que el individuo promedio deriva una utilidad si la alternativa es seleccionada de tal forma que:
iijU ésimaj −
β'
ijij XU = i
•Vector de variables que son relacionadas con el individuo y la alternativa.
•Las variables son funciones de las características deltomador de decisiones individual y de las alternativasdisponibles
ésimaj −
•Se supone constante a través de toda la población
ésimoi −

M. Misas A. 55
Con el propósito de separar el individuo del promedio, una componente estocástica es adicionadaa la utilidad promedio tal que:
ijij
ijijij
eX
eUU
+=
+=
β'
Variable aleatoriaEfectos combinados de factores no observadosy comportamiento individual aleatorio
Por ejemplo, Si cada individuo es un maximizador de la utilidad, la probabilidad de que el individuoseleccione la primera alternativa:
i
[ ][ ]iJiiiJiiii
iJiiiiii
UUeeUUee
UUUUUUP
−<−−<−=
>>>=
112112
131211
^^Pr
^^^Pr
L
L
Dichas expresiones se tienen para todos los . ijP
ije •Independientes•Idénticamente distribuidos
WeibullNormal multivariada
Logit múltiple
Probit múltiple
Los modelos múltiples Logit y Probit suponen:
Funcionesde densidad

M. Misas A. 56
La formula para la función de densidad de probabilidad de la distribución Weibull
Donde es el parámetro de forma, es el parámetro de localizacióny es el parámetro de escalar.
El caso donde = 0 y = 1 Distribución Estándar Weibull

M. Misas A. 57
Función de distribución acumulativa de la distribución Weibull
http://www.itl.nist.gov/div898/handbook/eda/section3/eda3668.htm

M. Misas A. 58
Modelo Logit múltiple
McFadden (1974) muestra que el modelo de utilidad aleatoria conduce al modelo logitsii los errores siguen una distribución weibull.
La diferencia entre dos variables aleatorias con distribución weibull sigue una distribuciónLogística modelo logit múltiple.
Las probabilidades que provienen de este modelo:
( )( )∑
=
=J
jij
ij
ij
X
XP
1
'
'
exp
exp
β
βForma general de la distribución logística
( )1xkβ Parámetros desconocidos comunes a todos los miembros de la población
( )1xkX ij Variables: función de las características de las alternativas o de losindividuos tomadores de la decisión

M. Misas A. 59
Consecuencias de la especificación
1) Considere el efecto sobre la ventaja de seleccionar la alternativa 1 en vez de la alternativa 2,cuando las alternativas aumentan de a J *J
La razón de la alternativa 1 frente a la 2 cuando existen alternativas:J
( )( )
( )( )
( )( )β
β
β
β
β
β
'
2
'
1
1
'
'
2
1
'
'
1
2
1
exp
exp
exp
exp
exp
exp
i
i
J
jij
i
J
jij
i
i
i
X
X
X
X
X
X
P
P
=
=
∑
∑
=
=
Al existir posibilidades de selección:*J
( )( )β
β'
2
'
1
2
1
exp
exp
i
i
i
i
X
X
P
P=
La razón de una decisión particular frente aotra no se ve afectada por la presencia de alternativas adicionales
Debilidad del modelo Logit
Alternativas irrelevantes

M. Misas A. 60
2) En esta formulación ninguna de las variables representadas en puede ser constante através de todas las alternativas puesto que el parámetro asociado no podría ser identificado
k ijX
( )( )( )β
ββ
'
2
'
1
'
2
'
1
2
1
exp
exp
exp
ii
i
i
i
i
XX
X
X
P
P
−=
=
•Si algunos elementos correspondientes a son iguales en , la variable asociada notendría influencia en la razón.
1iX 2iX
•Si este es el caso para todas las alternativas la variable en cuestión no contribuyea la explicación del porqué una alternativa es seleccionada frente a otra y su parámetrono puede ser estimado
⇒
•Si el vector de parámetros permanece constante a través de todas las alternativas, solofactores que cambian de una alternativa a otra pueden ayudar a explicar el porqué se selecciona una alternativa y no otra
•Variables: sexoedadcondición socioeconómica
No aportan información al proceso deselección de este modelo
β

M. Misas A. 61
•Variables: Costo de la alternativa particularpara cada individuoRetorno para cada individuo de la alternativa particular
Factores que varían a través de las alternativas para cada
individuo
En general, no se cuenta con información que varíe a través de las alternativas vistas por el individuo y los individuos en la muestra
Información costosade recoger y difícilde caracterizar
Con frecuencia, la información varía a través de los individuos y no a través de la alternativas
Así:
iiJii XXXX ==== L21
Dado los puntos anteriores, el modelo debe ser modificado de alguna forma antes de quepueda ser utilizado para caracterizar el comportamiento de la selección

M. Misas A. 62
Posibles modificaciones
•Una posible modificación es permitir que las variables explicatorias tengan impactos diferentessobre el beneficio o “razón” de seleccionar una alternativa mas que otra
Así:( )( )∑
=
=J
jjij
jij
ij
X
XP
1
'
'
exp
exp
β
β
•La razón de la alternativa frente a la primera:ésimak −
( )( )( ) JkXX
X
X
P
P
ikik
i
kik
i
ik
,,2exp
exp
exp
1
'
1
'
1
'
1
'
1
L=−=
=
ββ
ββ
•Si los vectores y contiene variables que son constante a través de las alternativas:ik
X1i
X
•Un único resultado, exige normalización. Se supone y ecuaciones como **determinan de manera única que la probabilidad de seleccione sume 1 para cada
L,21 === kXXX iiik ( )( )
( )( )1
'
1
'
1
'
1
exp
exp
exp
ββ
ββ
−=
=
kik
i
kik
i
ik
X
X
X
P
P⇒**
01 =β ( )1−j
i⇒
Las variables explicatorias pueden tener impactos diferencialesdependiendo de las alternativas.

M. Misas A. 63
( )∑=
+=
J
jji
i
X
P
2
'1
exp1
1
β
( )( )
Jj
X
XP
J
jji
ji
ij ,,2
exp1
exp
2
'
'
L=+
=∑=
β
β
La estimación máximo verosímil de los parámetros puede ser obtenida como sigue:
( )( )
( )
( )( )
( )( )∏ ∏∏
∑
∏ ∏∏∑
∏ ∏∑∑
∏
= ==
=
= ==
=
= =
==
=
+=
+=
+
+=
=
T
i
J
j
y
ji
T
iJ
jji
T
i
J
j
y
ji
yT
iJ
jji
T
i
J
j
y
J
jji
ji
y
J
jji
y
iJ
T
i
y
i
ij
iji
iji
iJi
X
X
X
X
X
X
X
PPL
1 2
'
1
2
'
1 2
'
1
2
'
1 2
2
'
'
2
'
11
exp
exp1
1
exp1
exp1
1
exp1
exp
exp1
1
1
1
1
ββ
ββ
β
β
β
L

M. Misas A. 64
( ) ( )
( ) ( )∑ ∑ ∑
∑∑∑ ∑
= = =
= == =
+−=
+
+−=
T
i
J
j
J
jjijiij
T
i
J
jjiij
T
i
J
jji
XXy
XyXL
1 2 2
''
1 2
'
1 2
'
exp1ln
exp1lnln
ββ
ββ No lineal respecto a jβ
Igualmente sus condiciones de primer orden
Debe ser maximizado numéricamente
Se demuestra que es estrictamente cóncavo en los y de esta forma cualquier métodode optimización no lineal, como Newton Raphson converge en cualquier punto donde se tengala condición de primer orden
Lln jβ
( )( )
( )( )
∑∑
∑∑
=
=
=
=
+−=
=+
−=∂∂
T
iiJ
jji
ji
ij
T
iJ
jji
iji
iij
j
X
X
Xy
Jj
X
XXXy
L
1
2
'
'
1
2
'
'
exp1
exp
,,2
exp1
expln
β
β
β
β
βL
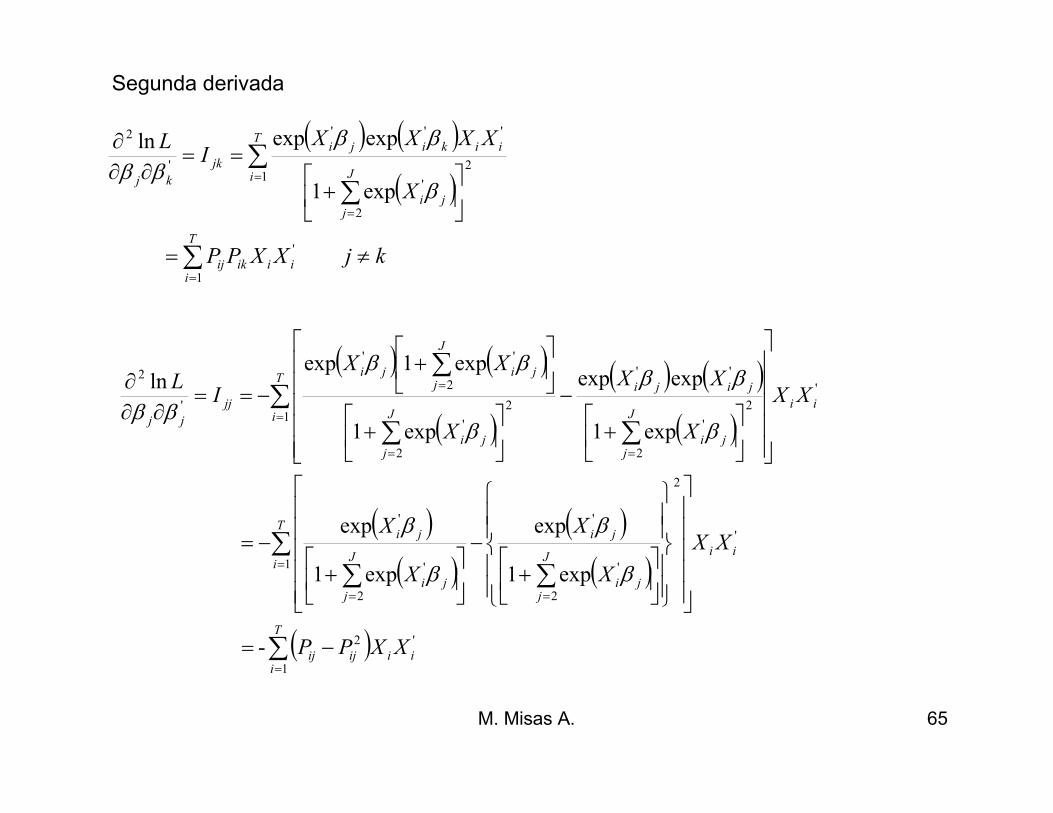
M. Misas A. 65
( ) ( )
( )
kjXXPP
X
XXXXI
L
T
iiiikij
T
i J
jji
iikiji
jk
kj
≠=
+
==∂∂
∂
∑
∑∑
=
=
=
1
'
12
2
'
'''
'
2
exp1
expexpln
β
ββ
ββ
Segunda derivada
( ) ( )
( )
( ) ( )
( )
( )( )
( )( )
( )∑
∑∑∑
∑∑∑
∑
=
=
==
=
==
=
−=
+
−
+
−=
+
−
+
+
−==∂∂
∂
T
iiiijij
ii
T
iJ
jji
ji
J
jji
ji
ii
T
i J
jji
jiji
J
jji
J
jjiji
jj
jj
XXPP
XX
X
X
X
X
XX
X
XX
X
XX
IL
1
'2
'
1
2
2
'
'
2
'
'
'
12
2
'
''
2
2
'
2
''
'
2
-
exp1
exp
exp1
exp
exp1
expexp
exp1
exp1expln
β
β
β
β
β
ββ
β
ββ
ββ

M. Misas A. 66
Si estimador de máxima verosimilitud:*β
Bajo condiciones generales:
( ) ( )[ ]( )1asintótico
* lim,0−
∞→→− βββ ITNT
T
( )
∂∂∂
−='
2 ln
βββ
LEI
En muestras finitas:
( )( )1** ,~−
βββ IN
−−
−−
=
JJJ
J
II
II
I
L
MMM
L
2
222
•Donde es reemplazado por sus estimaciones•La varianza puede ser calculada a partir del inverso de la matriz: I
ijP

Ejemplo y Tarea: selección de formas de pesca (Cameron and Trivedi, 2005)
y
1
2
3
4
Playa
Muelle de pesca
Bote privado
Bote charter
Alternativas excluyentes Logit multinomial
Regresores:Ingreso del individuo
Precio y tasa de pesca
Varía a través de los individuos
Varía a través de los individuosy de las formas de pesca
Muestra : 1182 personas y es realizada por Thomson and Crooke (1991)analizada por Herriges and Kling (1999)
Logit condicional : CL
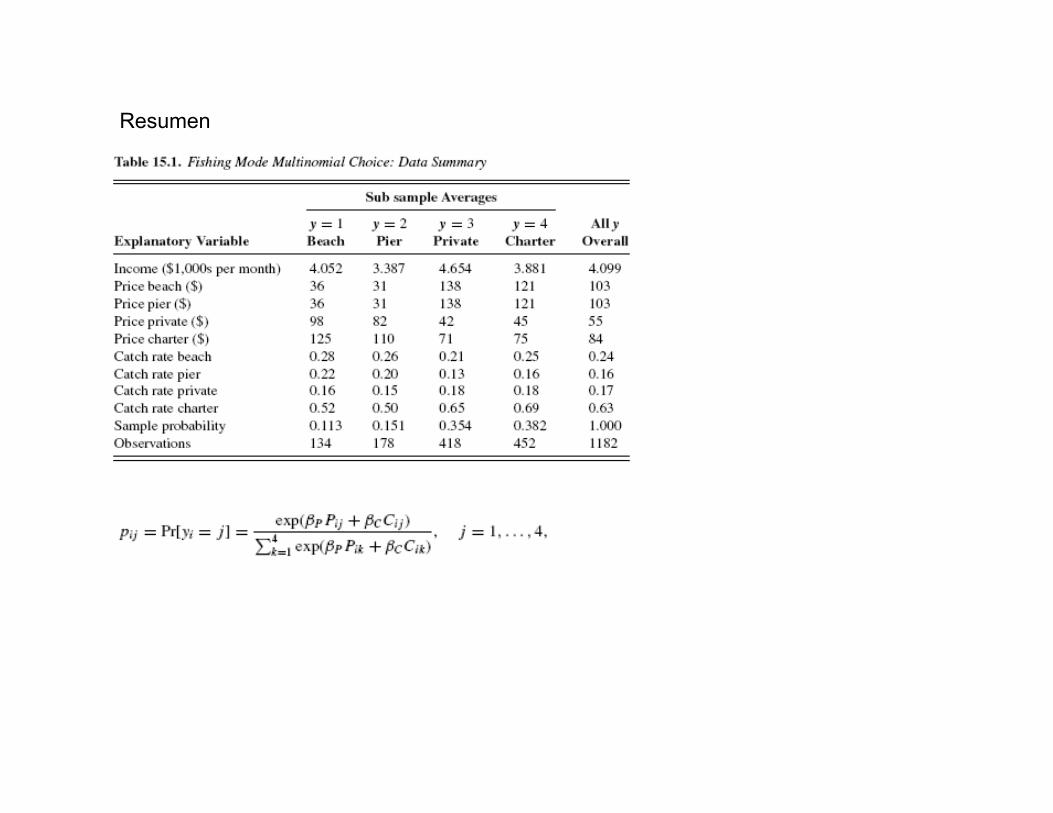
Resumen

Estimación:
Un aumento en el precio de una alternativa lleva a una disminución de la probabilidad de seleccionar
la alternativa en cuestión y a aumentar la probabilidad de selección de las otras alternativas
Un aumento en la tasa de pesca de una alternativa lleva a un aumento de la probabilidad de seleccionar la alternativa en cuestión y a la
disminución de la probabilidad de selección de las otras alternativas
Una medida estándar del impacto del cambio en los regresores es:
T
X
pT
i ikr
ij∑= ∂
∂
1
Respuesta marginal promedio de la probabilidad de seleccionar la alternativa cuandoel regresor se incrementa en una unidad para la alternativa y no se cambia en lasrestantes alternativas.
jr k
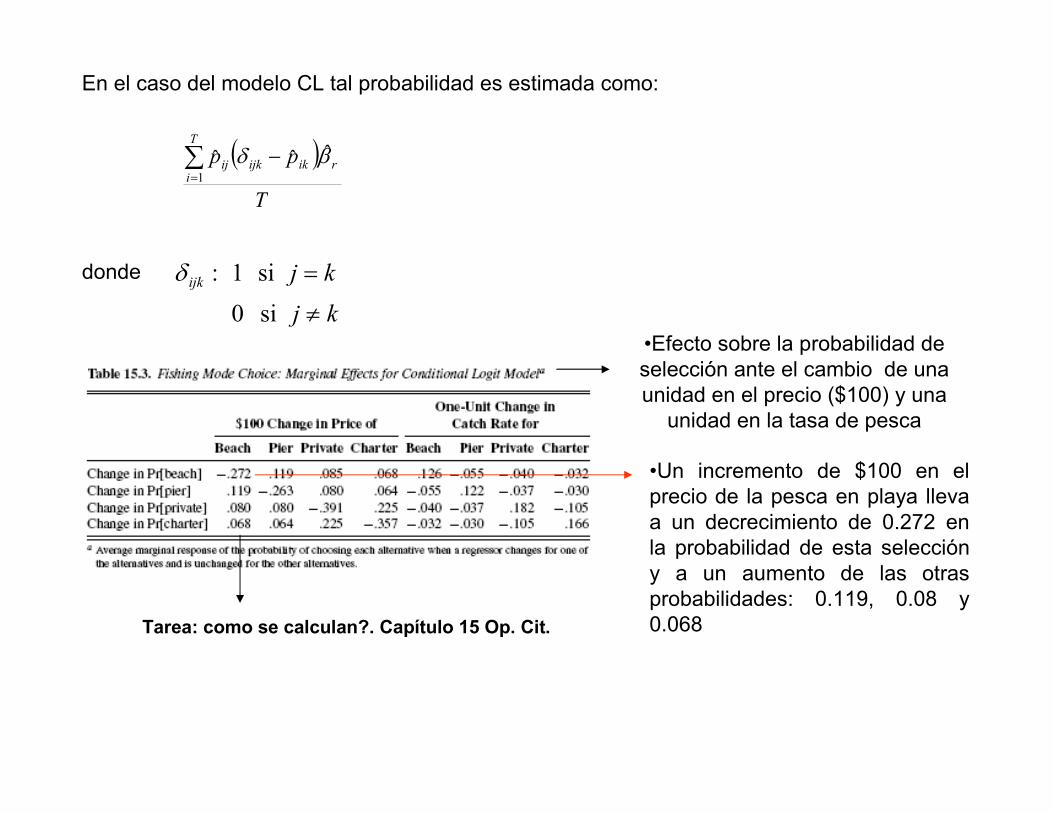
En el caso del modelo CL tal probabilidad es estimada como:
( )T
ppT
irikijkij∑
=
−1
ˆˆˆ βδ
si 0
si 1 :
kj
kjijk
≠
=δdonde
•Efecto sobre la probabilidad de selección ante el cambio de una unidad en el precio ($100) y una unidad en la tasa de pesca
•Un incremento de $100 en el precio de la pesca en playa lleva a un decrecimiento de 0.272 en la probabilidad de esta selección y a un aumento de las otras probabilidades: 0.119, 0.08 y 0.068Tarea: como se calculan?. Capítulo 15 Op. Cit.


















