
Pixel Recovery via Minimization in the Wavelet Domain Ivan W. Selesnick, Richard Van Slyke, and Onur...
23
Pixel Recovery via Minimization in the Wavelet Domain Ivan W. Selesnick, Richard Van Slyke, and Onur G. Guleryuz 1 l *: Polytechnic University, Brooklyn, NY #: DoCoMo Communications Laboratories USA, Inc., San Jose, CA * * # presenting author
-
Upload
frances-infield -
Category
Documents
-
view
219 -
download
0
Transcript of Pixel Recovery via Minimization in the Wavelet Domain Ivan W. Selesnick, Richard Van Slyke, and Onur...

Pixel Recovery via Minimization in the Wavelet Domain
Ivan W. Selesnick, Richard Van Slyke, and
Onur G. Guleryuz
1l
*: Polytechnic University, Brooklyn, NY
#: DoCoMo Communications Laboratories USA, Inc., San Jose, CA
* *
#
presenting author

•Problem statement: Estimation/Recovery of missing data.
•Formulation as a linear expansion over overcomplete basis.
•Expansions that minimize the norm.
•Why do this?
•Connections to adaptive linear estimators and sparsity.
•Connections to recent results and statistics
•Simulation results and comparisons to our earlier work.
•Why not to do this: Analysis of what is going on.
•Conclusion and ways of modifying the solutions for better results.
Overview
( Presentation is much more detailed than the paper.)
( Some software available, please check the paper.)
1l

Problem Statement
Original
1
0
x
xx
available pixels
lost pixels(assume zero mean)
1.
LostBlock
Image
0
0x 0}n
1}n)( 10 Nnn 2.
1
0
x̂
xyDerive predicted3.

Formulation
i
M
iihcHcy
1
MhhhH ...21
)( 00 xyP
1. Take NxM matrix of overcomplete basis,
1
0
x̂
xy
2. Write y in terms of the basis
3. Find the expansion coefficients (two ways)
available data projection
NM

Find the expansion coefficients to minimize the norm
1l norm of expansion coefficients
Regularization Available data constraint
01
0 xhcPM
iii
M
iic
1
min subject to
1l

Why minimize the norm?1l
“Under i.i.d. Laplacian model for coefficient probabilities, ||
2)( ici ecp
),...,,(max 21 Mcccp 1l norm
Real reason: sparse decompositions.
min
01
0 xhcPM
iii
M
iic
1
min subject to
Bogus reason

What does sparsity have to do with estimation/recovery?
01
0 xhcPM
iii
i
M
iihcy
1
1
0
x̂
xy
1. Any such decomposition builds an adaptive linear estimate.
01ˆ Axx )( 0xAA
2. In fact “any” estimate can be written in this form.
Onur G. Guleryuz, ``Nonlinear Approximation Based Image Recovery Using Adaptive Sparse Reconstructions and Iterated Denoising: Part I - Theory,‘’ IEEE Tr. on IP, in review.
http://eeweb.poly.edu/~onur (google: onur guleryuz).
i
M
ii hxcy
1
0 )(

The recovered signal must be sparse
i
n
iigdx
xy
0
11
0
ˆ
3. The recovered becomes
Onur G. Guleryuz, ``Nonlinear Approximation Based Image Recovery Using Adaptive Sparse Reconstructions and Iterated Denoising: Part I - Theory,‘’ IEEE Tr. on IP, in review.
http://eeweb.poly.edu/~onur (google: onur guleryuz).
0
1x
Ay
Nn 0
A
1N null space of dimension 01 nNn
y has to be sparse

Who cares about y, what about the original x?
2|||| yx
Onur G. Guleryuz, ``Nonlinear Approximation Based Image Recovery Using Adaptive Sparse Reconstructions and Iterated Denoising: Part I - Theory,‘’ IEEE Tr. on IP, in review.
http://eeweb.poly.edu/~onur (google: onur guleryuz).
If successful prediction is possible x also has to be ~sparse
small, then x ~ sparse
1. Predictable sparse
2. Sparsity of x is not a bad leap of faith to make in estimation
i.e., if
If not sparse, cannot estimate well anyway. (caveat: the data may be sparse, but not in the given basis)

Why minimize the norm?1l
Under certain conditions the problem gives the solution to the problem:
D. Donoho, M. Elad, and V. Temlyakov, ``Stable Recovery of Sparse Overcomplete Representations in the Presence of Noise‘’.
http://www-stat.stanford.edu/~donoho/reports.html
))((min 0)( 0
xScardxS 0
)(0
0
xhcPxSi
ii
subject to
Find the “most predictable”/sparsest expansion that agrees with the data.
01
0 xhcPM
iii
M
iic
1
min subject to
1l0l
(solving convex, not combinatorial)1l

Why minimize the norm?1l
R. Tibshirani, ``Regression shrinkage and selection via the lasso’’. J. Royal. Statist. Soc B., Vol. 58, No. 1, pp. 267-288.
20)(
0 ||||min0
xhcPxSi
ii
subject to tcM
ii
1
Experience from statistics literature. The “lasso” is known to generate sparse expansions.

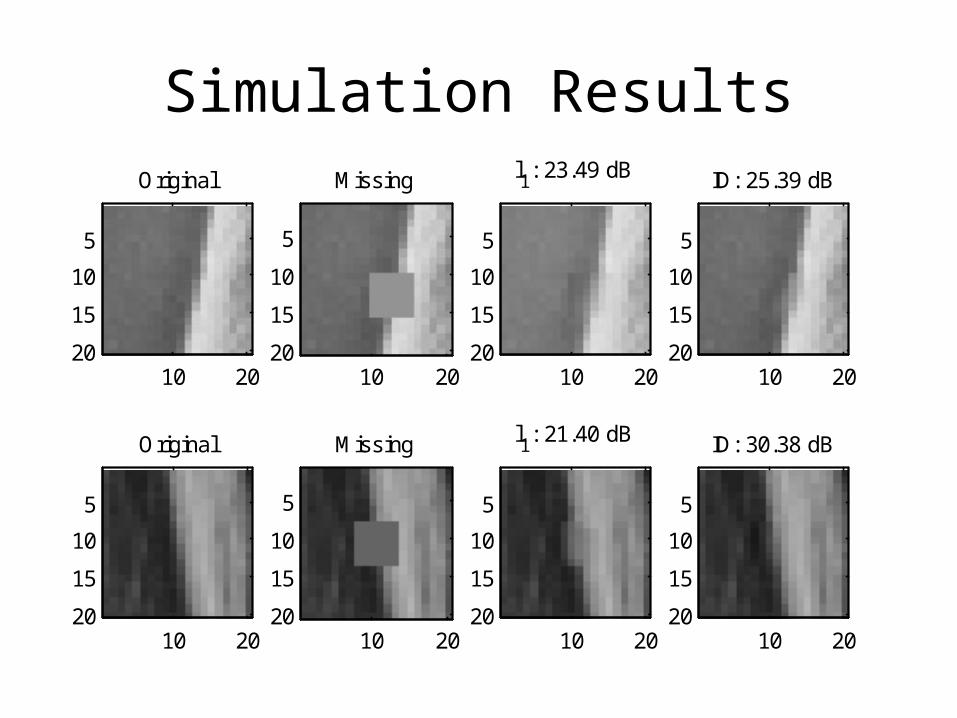
Simulation Results
01
0 xhcPM
iii
M
iic
1
min subject to
vs.
Onur G. Guleryuz, ``Nonlinear Approximation Based Image Recovery Using Adaptive Sparse Reconstructions and Iterated Denoising: Part II –Adaptive Algorithms,‘’ IEEE Tr. on IP, in review.
http://eeweb.poly.edu/~onur (google: onur guleryuz).
H: Two times expansive M=2N, real, dual-tree, DWT. Real part of:
N. G. Kingsbury, ``Complex wavelets for shift invariant analysis and filtering of signals,‘’ Appl. Comput. Harmon. Anal., 10(3):234-253, May 2002.
Iterated Denosing (ID) with no layering and no selective thresholding:
:1l
Original
10 20
5
10
15
20
Missing
10 20
5
10
15
20
l1: 21.40 dB
10 20
5
10
15
20
ID: 30.38 dB
10 20
5
10
15
20
Original
10 20
5
10
15
20
Missing
10 20
5
10
15
20
l1: 23.49 dB
10 20
5
10
15
20
ID: 25.39 dB
10 20
5
10
15
20
Simulation Results
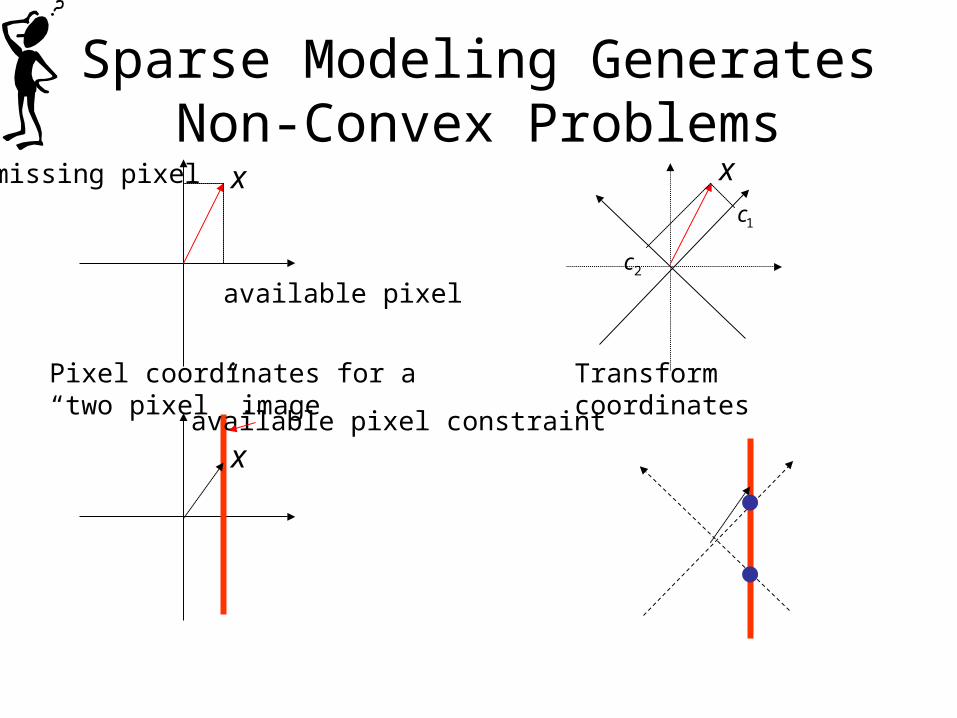
Sparse Modeling Generates Non-Convex Problems
Pixel coordinates for a “two pixel” image
x x
1c
2c
Transform coordinates
available pixel
missing pixel
xavailable pixel constraint

+ = )1(
“Sparse=non-convex”, who cares. What about reality, natural images?
x
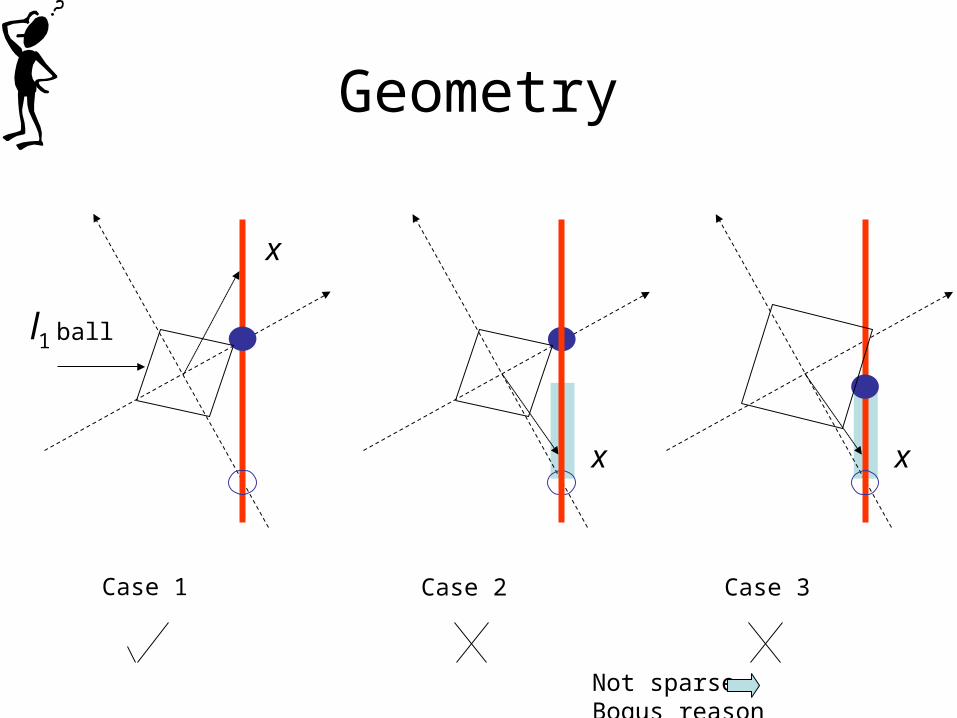
Geometry
x
ball1l
x
Case 1 Case 2 Case 3
Not sparse Bogus reason

Why not to minimize the norm1lWhat about all the optimality/sparsest results?
Results such as: D. Donoho et. al. ``Stable Recovery of Sparse Overcomplete Representations in the Presence of Noise‘’.
are very impressive, but they are tied closely to H providing the sparsest decomposition for x.
)( 2212 aNn
),(),( 211fyxmsel
1 2
yx
x
xxw
00
1
0
overwhelming noise:
modeling error error due to missing data

Why not to minimize the norm
01
0 xhcPM
iii
M
iic
1
min subject to
01
0 xhPcM
iii
MhhhH ...21
0
~...
~~21
0Mhhh
HP
“nice” basis, “decoherent”
“not nice” basis (due to cropping), may become very “coherent”
2(problem due to )
1l

Examples
6/12/13/1
6/203/1
6/12/13/1
H orthonormal, coherency=0
000
000
6/12/13/1
0HPunnormalized coherency= 6/1normalized coherency= 1(worst possible)
1. Optimal solution sometimes tries to make coefficients of scaling functions zero.
2. solution never sees the actual problem.1l

yx
xw
*0
...
Progression 2:
What does ID do?
yx
x
xxw
00
1
0
1 2
Uses correctly modeled components to reduce the overwhelming errors/”noise”
yxxw
00
11 22
Progression 1:
•Decomposes the big problem
into many progressions.•Arrives at the final complex
problem by solving much
simpler problems.• is conceptually a single
step, greedy version of ID.1l

ID is all about robustly selecting sparsity
•Tries to be sparse, not the sparsest.•Robust to model failures.•Other constraints easy to incorporate

Conclusion1. Have to be more agnostic than smoothest, sharpest, smallest, sparsest, *est.
minimum mse not necessarily = sparsest
2. Have to be more robust to modeling errors.When a convex approximation is possible to the underlying non-convex problem, great. But have to make sure assumptions are not violated.
3. Is it still possible to use , but with ID principles? Yes1lFor lasso/ fans:1l

TyhcM
iii
2
1
||||
M
iic
1
min subject to y
...But must ensure no case 3 problems (ID stays away from those).
1. It’s not about the lasso or how you tighten the lasso, it’s about what (plural) you tighten the lasso to.
01
0 xhcPM
iii
M
iic
1
min subject to
Tx
hcM
iii
2
0
1
||0
||
M
iic
1
min subject to
M
iiihc
1
availabledata
y
Do you think you reduced mse? No: you shouldn’t have done this. Yes: Do it again.
2. This is not “LASSO”, “LARS”, .... This is Iterated Denoising (use hard thresholding!).


















