
PETSc on GPUs and MIC: Current Status and Future Directions · PETSc on GPUs and MIC: Current...
22
PETSc on GPUs and MIC: Current Status and Future Directions Karl Rupp Institute for Microelectronics Institute for Analysis and Scientific Computing TU Wien, Austria Celebrating 20 Years of Computational Science with PETSc
Transcript of PETSc on GPUs and MIC: Current Status and Future Directions · PETSc on GPUs and MIC: Current...

PETSc on GPUs and MIC:Current Status and Future Directions
Karl Rupp
Institute for MicroelectronicsInstitute for Analysis and Scientific Computing
TU Wien, Austria
Celebrating 20 Years of Computational Science withPETSc

2
Why bother?Why bother?
GFLOPs/Watt
10-1
100
101
2007 2008 2009 2010 2011 2012 2013 2014
GF
LO
P/s
ec p
er
Wa
tt
End of Year
Peak Floating Point Operations per Watt, Double Precision
CPUs, Intel
Xeon X5482Xeon X5492
Xeon W5590Xeon X5680
Xeon X5690
Xeon E5-2690Xeon E5-2697 v2
Xeon E5-2699 v3
GPUs, NVIDIA
GPUs, AMD
MIC, Intel
Tesla C1060
Tesla C1060
Tesla C2050 Tesla C2090
Radeon HD 7970 GHz Ed.
Radeon HD 8970Tesla K40
Radeon HD 3870Radeon HD 4870Radeon HD 5870
Radeon HD 6970
Radeon HD 6970Tesla K20
Tesla K20X
FirePro W9100
Xeon Phi X7120X
3
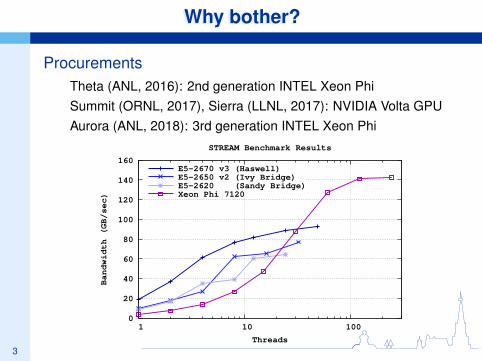
Why bother?Why bother?
ProcurementsTheta (ANL, 2016): 2nd generation INTEL Xeon PhiSummit (ORNL, 2017), Sierra (LLNL, 2017): NVIDIA Volta GPUAurora (ANL, 2018): 3rd generation INTEL Xeon Phi
0
20
40
60
80
100
120
140
160
1 10 100
Bandwidth (GB/sec)
Threads
STREAM Benchmark Results
E5-2670 v3 (Haswell) E5-2650 v2 (Ivy Bridge) E5-2620 (Sandy Bridge)Xeon Phi 7120

4
Current StatusCurrent Status
PETSc on GPUs and MIC:
Current Status

5
Available OptionsAvailable Options
Native on Xeon PhiCross-compile for Xeon Phi
CUDACUDA-support through CUSP-vec_type cusp -mat_type aijcusp
Only for NVIDIA GPUs
OpenCL
OpenCL-support through ViennaCL-vec_type viennacl -mat_type aijviennacl
OpenCL on Xeon Phi very poor

6
ConfigurationConfiguration
CUDA (CUSP)
CUDA-enabled configuration (minimum)
./configure [..] --with-cuda=1--with-cusp=1 --with-cusp-dir=/path/to/cusp
Customization:
--with-cudac=/path/to/cuda/bin/nvcc--with-cuda-arch=sm_20
OpenCL (ViennaCL)
OpenCL-enabled configuration
./configure [..] --download-viennacl--with-opencl-include=/path/to/OpenCL/include--with-opencl-lib=/path/to/libOpenCL.so

7
How Does It Work?How Does It Work?
Host and Device Datastruct _p_Vec {
...void *data; // host bufferPetscCUSPFlag valid_GPU_array; // flagvoid *spptr; // device buffer
};
Possible Flag States
typedef enum {PETSC_CUSP_UNALLOCATED,PETSC_CUSP_GPU,PETSC_CUSP_CPU,PETSC_CUSP_BOTH} PetscCUSPFlag;

8
How Does It Work?How Does It Work?
Fallback-Operations on Host
Data becomes valid on host (PETSC_CUSP_CPU)
PetscErrorCode VecSetRandom_SeqCUSP_Private(..) {VecGetArray(...);// some operation on host memoryVecRestoreArray(...);
}
Accelerated Operations on Device
Data becomes valid on device (PETSC_CUSP_GPU)
PetscErrorCode VecAYPX_SeqCUSP(..) {VecCUSPGetArrayReadWrite(...);// some operation on raw handles on deviceVecCUSPRestoreArrayReadWrite(...);
}

9
ExampleExample
KSP ex12 on Host
$> ./ex12-pc_type ilu -m 200 -n 200 -log_summary
KSPGMRESOrthog 228 1.0 6.2901e-01KSPSolve 1 1.0 2.7332e+00
KSP ex12 on Device
$> ./ex12 -vec_type cusp -mat_type aijcusp-pc_type ilu -m 200 -n 200 -log_summary
[0]PETSC ERROR: MatSolverPackage petsc does not supportmatrix type seqaijcusp

10
ExampleExample
KSP ex12 on Host
$> ./ex12-pc_type none -m 200 -n 200 -log_summary
KSPGMRESOrthog 1630 1.0 4.5866e+00KSPSolve 1 1.0 1.6361e+01
KSP ex12 on Device
$> ./ex12 -vec_type cusp -mat_type aijcusp-pc_type none -m 200 -n 200 -log_summary
MatCUSPCopyTo 1 1.0 5.6108e-02KSPGMRESOrthog 1630 1.0 5.5989e-01KSPSolve 1 1.0 1.0202e+00

11
PitfallsPitfalls
Pitfall: Repeated Host-Device Copies
PCI-Express transfers kill performanceComplete algorithm needs to run on deviceProblematic for explicit time-stepping, etc.
Pitfall: Wrong Data Sizes
Data too small: Kernel launch latencies dominateData too big: Out of memory
Pitfall: Function PointersImpossible to provide function pointers through library boundariesOpenCL: Pass kernel sources, user-data hard to passComposability?

12
Current GPU-Functionality in PETScCurrent GPU-Functionality in PETSc
Current GPU-Functionality in PETSc
CUSP ViennaCLProgramming Model CUDA OpenCLOperations Vector, MatMult Vector, MatMultMatrix Formats CSR, ELL, HYB CSRPreconditioners SA-AMG, BiCGStab -MPI-related Scatter -
Additional Functionality
MatMult via cuSPARSEOpenCL residual evaluation for PetscFE

13
Future DirectionsFuture Directions
PETSc on GPUs and MIC:
Future Directions

14
Future: CUDAFuture: CUDA
Split CUDA-buffers from CUSP
Vector operations by cuBLASMatMult by different packagesCUSP (and others) provides add-on functionality
CUDA buffers
CUSP ViennaCL
More CUSP Functionality in PETSc
Relaxations (Gauss-Seidel, SOR)Polynomial preconditionersApproximate inverses
15
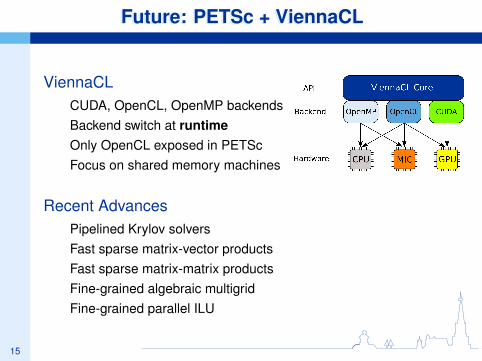
Future: PETSc + ViennaCLFuture: PETSc + ViennaCL
ViennaCLCUDA, OpenCL, OpenMP backendsBackend switch at runtimeOnly OpenCL exposed in PETScFocus on shared memory machines
Recent AdvancesPipelined Krylov solversFast sparse matrix-vector productsFast sparse matrix-matrix productsFine-grained algebraic multigridFine-grained parallel ILU

16
Future: PETSc + ViennaCLFuture: PETSc + ViennaCL
Current Use of ViennaCL in PETSc
$> ./ex12 -vec_type viennacl -mat_type aijviennacl ...
Executes on OpenCL device
Future Use of ViennaCL in PETSc
$> ./ex12 -vec_type viennacl -mat_type aijviennacl-viennacl_backend openmp,cuda ...
Pros and ConsUse CPU + GPU simultaneouslyNon-intrusive, use plugin-mechanismNon-optimal in strong-scaling limitGather experiences for best long-term solution

17
Upcoming PETSc+ViennaCL FeaturesUpcoming PETSc+ViennaCL Features
Pipelined CG Method, Exec. Time per Iteration
0
50
100
150
200
0
50
100
150
200
Rel. E
xecution T
ime (
%)
windtunnel ship spheres cantilever protein
1.4
2
1.8
7
3.3
3
2.5
2
1.2
0
1.4
6
1.1
3
1.8
8
0.8
2
0.9
2
0.9
4
1.4
9
0.6
1
0.7
9
0.6
9
1.2
6
0.7
9
0.7
0
0.9
8
1.4
1
NVIDIA Tesla K20m
0
50
100
150
200
0
50
100
150
200
Rel. E
xecution T
ime (
%)
1.1
4
2.0
7
N
A
N
A
0.9
7
1.3
3
N
A
N
A
0.6
8
1.1
1
N
A
N
A
0.4
6
0.8
6
N
A
N
A
0.7
9
0.8
7
N
A
N
A
AMD FirePro W9100
ViennaCL 1.6.2 PARALUTION 0.7.0 MAGMA 1.5.0 CUSP 0.4.0

18
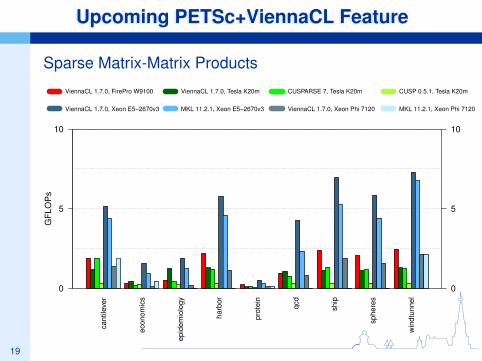
Upcoming PETSc+ViennaCL FeaturesUpcoming PETSc+ViennaCL Features
Sparse Matrix-Vector Multiplication
Tesla K20m
0
5
10
15
20
0
5
10
15
20
GF
LO
P/s
ec
cantile
ver
econom
ics
epid
em
iolo
gy
harb
or
pro
tein
qcd
ship
sphere
s
win
dtu
nnel
accele
rato
r
am
azon0312
ca−
CondM
at
cit−
Pate
nts
circuit
em
ail−
Enro
n
p2p−
Gnute
lla31
roadN
et−
CA
webbase1m
web−
wik
i−V
ote
13
.41
2.9
11
.8
8.9
6.4
5.4
11
.8 8
.51
1.0
12
.61
1.8
10
.1
14
.11
6.6
16
.2
12
.81
3.0
6.9
13
.21
3.4
11
.4
13
.71
5.8
12
.6
13
.01
3.8
11
.7
8.6
10
.2 5
.9
6.4
6.3
4.4
4.1
2.9
3.0
2.4
2.4
2.1
9.5
7.0
5.6
5.3
1.9
3.1
4.3
2.6
2.7
9.0
5.2
6.7
9.2
4.9
3.4
3.2
2.9
2.6
1.7
0.9
2.4
ViennaCL 1.7.0 CUSPARSE 7 CUSP 0.5.1
19
Upcoming PETSc+ViennaCL FeatureUpcoming PETSc+ViennaCL Feature
Sparse Matrix-Matrix Products
0
5
10
0
5
10
GF
LO
Ps
cantile
ver
econom
ics
epid
em
iolo
gy
harb
or
pro
tein
qcd
ship
sphere
s
win
dtu
nnel
ViennaCL 1.7.0, FirePro W9100 ViennaCL 1.7.0, Tesla K20m CUSPARSE 7, Tesla K20m CUSP 0.5.1, Tesla K20m
ViennaCL 1.7.0, Xeon E5−2670v3 MKL 11.2.1, Xeon E5−2670v3 ViennaCL 1.7.0, Xeon Phi 7120 MKL 11.2.1, Xeon Phi 7120

20
Upcoming PETSc+ViennaCL FeatureUpcoming PETSc+ViennaCL Feature
Algebraic Multigrid Preconditioners
10-2
10-1
100
101
102
103
104
105
106
107
Exe
cu
tio
n T
ime
(se
c)
Unknowns
Total Solver Execution Times, Poisson Equation in 2D
Dual INTEL Xeon E5-2670 v3, No PreconditionerDual INTEL Xeon E5-2670 v3, Smoothed AggregationAMD FirePro W9100, No PreconditionerAMD FirePro W9100, Smoothed AggregationNVIDIA Tesla K20m, No PreconditionerNVIDIA Tesla K20m, Smoothed AggregationINTEL Xeon Phi 7120, No PreconditionerINTEL Xeon Phi 7120, Smoothed Aggregation

21
Pipelined SolversPipelined Solvers
Fine-Grained Parallel ILU (Chow and Patel, SISC, 2015)
10-2
10-1
100
101
102
103
103
104
105
106
107
Exe
cu
tio
n T
ime
(se
c)
Unknowns
Total Solver Execution Times, Poisson Equation in 2D
Dual INTEL Xeon E5-2670 v3, No PreconditionerDual INTEL Xeon E5-2670 v3, Fine-Grained ILUAMD FirePro W9100, No PreconditionerAMD FirePro W9100, Fine-Grained ILUNVIDIA Tesla K20m, No PreconditionerNVIDIA Tesla K20m, Fine-Grained ILUINTEL Xeon Phi 7120, No PreconditionerINTEL Xeon Phi 7120, Fine-Grained ILU

22
Summary and ConclusionSummary and Conclusion
Currently Available
CUSP for CUDA, ViennaCL for OpenCLAutomatic use for vector operations and SpMVSmoothed Agg. AMG via CUSP
Next Steps
Use of cuBLAS and cuSPARSEBetter support for n > 1 processesViennaCL as CUDA/OpenCL/OpenMP-hydra





![An Inertia-Free Filter Line-Search Algorithm for Large ... · for graphics processing units (GPUs) and distributed-memory systems such as MAGMA, EL-EMENTAL, Trilinos, and PETSc [1,29,4];](https://static.fdocuments.in/doc/165x107/5fdb24ea5133280c4608aed0/an-inertia-free-filter-line-search-algorithm-for-large-for-graphics-processing.jpg)












