
Enhancing Personalized Search by Mining and Modeling Task Behavior

Personalized Ontology Learning for
Enhancing Text Mining Effectiveness
Yan Shen
January 2013
Electrical Engineering, Computer Science
Science and Engineering Faculty
Queensland University of Technology
A final report submitted in partial fulfillment for the degree of Doctor of
Philosophy


Always with my family, best wishes with love and respect...


Statement of Original Authorship
The work contained in this thesis has not been previously submitted to meet
requirements for an award at this or any other higher education institution. To
the best of my knowledge and belief, the thesis contains no material previously
published or written by another person except where due reference in made.
Signature
Date 06/05/2013


Acknowledgements
I would like to express my sincere gratitude to the people who have assisted and
encouraged me during the research journey. In particular, first of all, I wish to
thank my supervisors - Professor Yuefeng Li, Associate Professor Yue Xu, and
Adjunct Professor Renato Ilannella. Without their consistent instructions and
strong supports, the research project could not be completed successfully. Beside
the research, Prof. Yuefeng Li as a well mentor demonstrates the positive attitude
and the spirit of being diligent in my life.
Queensland University of Technology deserves my honest gratitude for of-
fering an enjoyable working environment. Thanks to Science and Engineering
Faculty, and my school, Electrical Engineering and Computer Science, especially.
They have offered a number of training courses, and allowed me to attend the
conferences.
It is pleasure to acknowledge the great collaboration with the e-Discovery lab.
Special thanks to my previous colleagues, Dr. Daniel Tao, Dr. Susan Zhou, and
Dr. Abdulmohsen Algarni. Their advices and shared experience are significant
to solve the troubles during my study period.
vii

I owe a lot to my wife Lilly Xu, and dedicated to my parents and grandma.
Without their selfless loves and early education, the thesis would become an
impossible mission.
Many thanks to the blind thesis examiners, their valuable advices and con-
structive comments are important to refine the thesis and future work. Some of
the general concerns have not been realized before the examination.
Finally, thanks to Helen Whittle for the thesis proofreading, who made the
thesis more readable for native and non-native speakers alike.
Yan Shen
26 April 2013
viii

Abstract
Over the last decade, the majority of existing search techniques is either keyword-
based or category-based, resulting in unsatisfactory effectiveness. Meanwhile,
studies have illustrated that more than 80% of users preferred personalized search
results. As a result, many studies paid a great deal of efforts (referred to as col-
laborative filtering) investigating on personalized notions for enhancing retrieval
performance. One of the fundamental yet most challenging steps is to capture
precise user information needs. Most Web users are inexperienced or lack the
capability to express their needs properly, whereas the existent retrieval systems
are highly sensitive to vocabulary.
Researchers have increasingly proposed the utilization of ontology-based tech-
niques to improve current mining approaches. The related techniques are not only
able to refine search intentions among specific generic domains, but also to access
new knowledge by tracking semantic relations. In recent years, some researchers
have attempted to build ontological user profiles according to discovered user
background knowledge. The knowledge is considered to be both global and lo-
cal analyses, which aim to produce tailored ontologies by a group of concepts.
ix

However, a key problem here that has not been addressed is: how to accurately
match diverse local information to universal global knowledge.
This research conducts a theoretical study on the use of personalized ontolo-
gies to enhance text mining performance. The objective is to understand user
information needs by a “bag-of-concepts” rather than “words”. The concepts are
gathered from a general world knowledge base named the Library of Congress
Subject Headings. To return desirable search results, a novel ontology-based
mining approach is introduced to discover accurate search intentions and learn
personalized ontologies as user profiles. The approach can not only pinpoint
users’ individual intentions in a rough hierarchical structure, but can also in-
terpret their needs by a set of acknowledged concepts. Along with global and
local analyses, another solid concept matching approach is carried out to address
about the mismatch between local information and world knowledge. Relevance
features produced by the Relevance Feature Discovery model, are determined as
representatives of local information. These features have been proven as the best
alternative for user queries to avoid ambiguity and consistently outperform the
features extracted by other filtering models. The two attempt-to-proposed ap-
proaches are both evaluated by a scientific evaluation with the standard Reuters
Corpus Volume 1 testing set. A comprehensive comparison is made with a num-
ber of the state-of-the art baseline models, including TF-IDF, Rocchio, Okapi
BM25, the deploying Pattern Taxonomy Model, and an ontology-based model.
The gathered results indicate that the top precision can be improved remark-
x

ably with the proposed ontology mining approach, where the matching approach
is successful and achieves significant improvements in most information filtering
measurements.
This research contributes to the fields of ontological filtering, user profiling,
and knowledge representation. The related outputs are critical when systems are
expected to return proper mining results and provide personalized services. The
scientific findings have the potential to facilitate the design of advanced preference
mining models, where impact on people’s daily lives.
xi


Contents
Acknowledgements vii
Abstract ix
List of Figures xix
List of Tables xx
Notation, Terminology, and Abbreviations xxi
1 Introduction 1
1.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Questions and Motivations . . . . . . . . . . . . . . . . . . . . . . 5
1.3 Significance and Major Contributions . . . . . . . . . . . . . . . . 13
1.4 Publications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.5 Thesis Organization . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2 Literature Review 19
2.1 Classic Information Retrieval Models . . . . . . . . . . . . . . . . 21
xiii

2.2 Web Personalization . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.1 Explicit and Implicit Feedback . . . . . . . . . . . . . . . . 29
2.2.2 User Information Needs . . . . . . . . . . . . . . . . . . . 30
2.2.3 User Profiling . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.3 Knowledge Discovery and Pattern Mining . . . . . . . . . . . . . 34
2.3.1 Process of Knowledge Discovery . . . . . . . . . . . . . . . 35
2.3.2 Tasks of Data Mining . . . . . . . . . . . . . . . . . . . . . 36
2.3.3 Pattern Mining and Association Rules . . . . . . . . . . . 38
2.3.4 Association Rules and Frequent Itemsets Mining . . . . . . 40
2.3.5 Efficient Mining Algorithms . . . . . . . . . . . . . . . . . 41
2.3.6 Mining Diverse Patterns . . . . . . . . . . . . . . . . . . . 43
2.4 Ontology Learning . . . . . . . . . . . . . . . . . . . . . . . . . . 47
2.4.1 Ontology-Based Techniques . . . . . . . . . . . . . . . . . 47
2.4.2 Concept Mapping . . . . . . . . . . . . . . . . . . . . . . . 50
2.4.3 Semantic Relations . . . . . . . . . . . . . . . . . . . . . . 53
2.4.4 Specificity and Exhaustivity Ontology Mining . . . . . . . 54
2.4.5 Knowledge Base: LCSH and its Subject Headings . . . . . 55
2.4.6 Ontology Construction Language . . . . . . . . . . . . . . 59
2.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
3 Ontology-Based Technique for Search Intent Mining 71
3.1 Background and Overview of the Approach . . . . . . . . . . . . . 72
3.2 World Knowledge Base . . . . . . . . . . . . . . . . . . . . . . . . 75
xiv

3.3 Personalized Ontology Learning . . . . . . . . . . . . . . . . . . . 79
3.3.1 Subject-Based Model . . . . . . . . . . . . . . . . . . . . . 79
3.3.2 Semantic Extraction . . . . . . . . . . . . . . . . . . . . . 80
3.3.3 In-Level Ontology Mining Method . . . . . . . . . . . . . . 82
3.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
4 Relevance Feature Matching 91
4.1 Design and Definitions . . . . . . . . . . . . . . . . . . . . . . . . 92
4.1.1 Definitions of Patterns and Closed Patterns . . . . . . . . 94
Closed Sequential Patterns . . . . . . . . . . . . . . . . . . 95
4.1.2 Global Knowledge Base: the LCSH . . . . . . . . . . . . . 96
4.2 Relevance Feature Acquisition . . . . . . . . . . . . . . . . . . . . 97
4.2.1 Specificity of Low-Level Features . . . . . . . . . . . . . . 98
4.2.2 Term Weighting . . . . . . . . . . . . . . . . . . . . . . . . 100
4.3 Concept Matching Method . . . . . . . . . . . . . . . . . . . . . . 104
4.3.1 Limitations of Query-Based Method . . . . . . . . . . . . . 104
4.3.2 Concept Intension & Extension . . . . . . . . . . . . . . . 106
4.3.3 Distributed Matching . . . . . . . . . . . . . . . . . . . . . 110
4.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
5 Evaluation 115
5.1 Evaluation Environment . . . . . . . . . . . . . . . . . . . . . . . 116
5.1.1 Experimental Dataset . . . . . . . . . . . . . . . . . . . . 116
xv

5.1.2 Baseline Models . . . . . . . . . . . . . . . . . . . . . . . . 119
5.1.3 Experimental Measurements . . . . . . . . . . . . . . . . . 123
5.2 Experiment Design and Settings . . . . . . . . . . . . . . . . . . . 124
5.3 Experimental Results . . . . . . . . . . . . . . . . . . . . . . . . . 126
5.3.1 Evaluation of Ontology-Based Mining Approach . . . . . . 127
5.3.2 Evaluation of Distributed Matching . . . . . . . . . . . . . 131
5.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
6 Conclusion 137
6.1 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
Bibliography 143
xvi

List of Figures
1.1 An insight of the classic IR model [38] . . . . . . . . . . . . . . . 2
1.2 Global concepts and local information matching . . . . . . . . . . 10
2.1 The coverage of literature review . . . . . . . . . . . . . . . . . . 20
2.2 The steps of knowledge discovery in databases . . . . . . . . . . . 37
2.3 The constructed ontology with the proposed semantic relations . 54
2.4 The concept of Specificity and Exhaustivity . . . . . . . . . . . . . 55
2.5 Subclass relationships between OWL and RDF/RDFS [6] . . . . . 64
3.1 Overview of the ontology-based approach . . . . . . . . . . . . . . 74
3.2 Knowledge classification . . . . . . . . . . . . . . . . . . . . . . . 76
3.3 The screenshot of subject-based Model . . . . . . . . . . . . . . . 80
3.4 The extracted semantic relations . . . . . . . . . . . . . . . . . . 81
3.5 A Segment of the Subject Headings . . . . . . . . . . . . . . . . . 82
3.6 The backbone of in-levels hierarchy . . . . . . . . . . . . . . . . . 83
4.1 Overview of the relevance feature matching approach . . . . . . . 93
4.2 Occurrence of terms in the first 50 RCV1 topics . . . . . . . . . . 105
xvii

4.3 Difference between extension and intension . . . . . . . . . . . . . 110
5.1 RCV1 data structure . . . . . . . . . . . . . . . . . . . . . . . . . 118
5.2 Primary user interface of the coded pre-processing program . . . . 120
5.3 Experiment design for POM . . . . . . . . . . . . . . . . . . . . . 126
5.4 Top 20 precision for three stages . . . . . . . . . . . . . . . . . . . 129
5.5 Comparison of 11-points in first 50 topics . . . . . . . . . . . . . . 130
5.6 11 points result after matching . . . . . . . . . . . . . . . . . . . . 134
5.7 Original 11 points result . . . . . . . . . . . . . . . . . . . . . . . 135
xviii

List of Tables
2.1 An example of vertical format of database . . . . . . . . . . . . . 42
2.2 Types of subject headings . . . . . . . . . . . . . . . . . . . . . . 59
2.3 RDF schema constructors . . . . . . . . . . . . . . . . . . . . . . 62
2.4 Comparison between three species of OWL . . . . . . . . . . . . . 67
3.1 Examples for redefined relations . . . . . . . . . . . . . . . . . . . 77
4.1 Example of pattern mining . . . . . . . . . . . . . . . . . . . . . . 101
5.1 Comparison results for different parameter settings . . . . . . . . 126
5.2 Overall performance of first 50 topics . . . . . . . . . . . . . . . . 128
5.3 Number of terms extracted by all the models . . . . . . . . . . . . 131
5.4 Comparison results after matching . . . . . . . . . . . . . . . . . 132
5.5 Comparison of deploying results . . . . . . . . . . . . . . . . . . . 133
5.6 Comparison of original results . . . . . . . . . . . . . . . . . . . . 134
xix


Notation, Terminology, and
Abbreviations
Notation
Θ An ontology.
Terminology
Query The data structure given by a user to information
gathering systems for the expression of an information
need.
Abbreviations
WWW World Wide Web
IR Information Retrieval
HTML Hyper Text Markup Language
XML Extensible Markup Language
xxi

OWL Web Ontology Language
RDF Resource Description Framework
LC Library of Congress
LCC Library of Congress Classification
DDC Dewey Decimal Classification
LCSH Library Congress of Subject Headings
RCV1 Reuters Corpus Volume 1
RFD Relevance Feature Discovery model
SPE Positive Specific Group in RFD
PTM Pattern Taxonomy Model
PDS PTM model using deploying weighting
QUT Queensland University of Technology
NIST National Institute of Standards and Technology
xxii

Chapter 1
Introduction
1.1 Background
The Web is now considered to be an essential part of human life. It is seen
as a powerful tool for seeking and sharing information, and is widely used by
companies, universities, organizations, and individuals. Due to its popularity,
diverse resources are made available on the Web an exponential rate everyday [49].
Hence, the development of effective ways to retrieve the expected information is
a continuing and concern in the fields of Information Retrieval (IR) and Data
Mining (DM) [10,89].
Web searching is a significant remedy to alleviate retrieval problems. It can
be studied as Web mining, which utilizes data mining methodologies to extract
1

2 Chapter 1. Introduction
useful information or patterns from large amounts of Web documents and ser-
vices [10]. Hence, the combination of data mining and Web searching creates
the concept of Web mining. Its basic process is nearly the same as the classi-
cal IR process depicted in Figure 1.1. Existing search mechanisms have been
further developed by various sophisticated techniques in order to properly filter
irrelevant information. However, the majority of these techniques are mainly lim-
ited to keyword-based searches(e.g. Google search, AltaVista, InfoSeek, All the
Web) or category-based searches(Yahoo!, Google Directory) [21]. These search
techniques still suffer from two distinct problems: information overload and mis-
match [49,55,62,94]. The information overload occurs when one search returns a
large number of results, which users have to manually traverse to obtain valuable
information. It is time-consuming and frustrating for the users. The mismatch
problem means that such search models are inefficient to gather the appropriate
information to satisfy users’ needs. One main reason is that the techniques follow
the “bag-of-words” approach and primarily focus on the terms themselves rather
than their inter-relations and meanings [98].
Figure 1.1: An insight of the classic IR model [38]
Personalization is another challenge in Web searching. Current information
filtering systems lack intelligent capability to judge user preferences. To take a
classic example, when a user types “apple” for searching, a conventional search

1.1. Background 3
model will find the results for “apple” fruit and “apple” IT product at the same
time. The results are not tailored and applicable to individual users [49]. In other
words, the problem is referred to as ambiguity.
Studies have illustrated that more than 80% of users preferred personalized
result [25, 26]. To meet the users search expectations, user profiling has been
investigated for more than a decade. It plays an important role in personalized
searching because it can refine user search intentions by referring to their personal
data. This is especially the case with adaptive filtering models, which start with
user profiles or a limited number of feedback documents to generate user profiles,
and then operate filtering tasks [67,76,134]. Unlike the traditional search query,
user profiles are persistent, and tend to reflect long-term information needs. When
a user’s information need is stable over a long period of time, a filtering system can
gain sufficient feedback from which to create the satisfactory profile by interacting
with the user. As a result, the information delivered would be customized and
cater more closely to the user’s need [66,87].
In fact, extracting a user profile is a complicated and reiterative process for
collaborative filtering. Diverse sorts of data on click-through, scrolling frequency,
browsing history, and page staying time are usually required to collect in order
to describe users’ interests and behaviors [62]. It suffers from scalability [91]
and cold-start [92] problems. Another common component of user profile is feed-
back, namely: relevance feedback and pseudo feedback. Relevance feedback is
produced by interacting with users, whereas the pseudo feedback is generated

4 Chapter 1. Introduction
by systems [116], such as top ranking. With respect to the collections, different
types of user profiles can be established for understanding background informa-
tion so as to capture the user’s specific demands. Their significance has been
demonstrated by numerous information filtering models [13, 67, 85]. However,
these models encounter some distinct drawbacks. Their user profiles are either
expensive in extraction or inaccurate in description [10]. Meanwhile, they are
incompatible with new knowledge generation and acquisition.
To overcome these limitations, ontology-based techniques have been put for-
wards as a crucial portion of advanced searching in the last decade. Ontologies
constitute a formal conceptualization of a particular domain of interest that is
shared by a group of people [38,58,71]. Their components are primarily made up
of explicit concepts and their inter-relationships. In computer science, ontology-
based techniques are widely applied in sharing information among human or soft-
ware agents, reusing domain knowledge, and offering scientific classification [102].
In addition, they can help to disambiguate word senses in the form of a taxo-
nomic structure. For example, if the word “jaguar” is allocated in the taxonomy
of “jaguar - cat - animal”, it is easy to distinguish that the “jaguar” is not a
British car because it has a parent class of “cat”. This characteristic enables
a search to obtain hints towards resolving vague expressions (such as polysemy,
synonym, hypernym, and metonymy) [104].
More recently, researchers [105,109] have attempted to build ontological user
profiles. Their aim is to understand user background knowledge properly by a

1.2. Questions and Motivations 5
group of relevant on-topic concepts rather than features mined by the pure data
mining techniques. Some of the gathered knowledge is integrated from two sides,
namely: global analysis and local analysis [104, 105]. The global analysis is used
to employ a global knowledge base (ontlogies, thesauruses, or online knowledge
bases) that mirrors the content of the Web for common knowledge representa-
tion, whereas the local analysis investigates native information or observes user
behaviors from local instances [104]. According to the generated ontology-based
profiles, the related work outperforms previous techniques and shows encouraging
results in search effectiveness. However, some problems are not fully addressed,
and a theoretical support in the form of pre-conditions is urgently required for
the production of ontological profiles.
1.2 Questions and Motivations
The discussion in the previous section demonstrates that the existence and acqui-
sition of user profiles is important to achieve Web personalization. The identified
problems indicate an urgent need to conduct a comprehensive study of personal-
ized ontologies, especially in regard to the profiling aspect. This section lists all
questions arising from the conducted research. This section focuses on the three
essential questions that arose in the present thesis:
• Rather than user queries, what is the alternative to capturing user infor-
mation needs?;

6 Chapter 1. Introduction
• How can local information be associated with global knowledge in a world
ontology?; and
• How can weights be properly assigned to the terms in the concepts?.
The motivations to address the questions are also described in detail.
Imprecise and uncertain information, or so-called “noisy information, is mainly
caused by three factors while implementing an IR or DM system. These factors
are the representations of user queries, the representations of documents, and the
relevance indicants between user queries and documents [5,117]. User queries are
generally treated as containers to transfer information needs from the user side
to the system side. To guarantee search quality, offering a good query is impor-
tant. Thus, there exists a recognized hypothesis that if user information needs
can be captured and interpreted for retrieval models, more useful and meaningful
information can be gathered.
A search query consists of a short number of keywords. If a person is asked to
determine the correct keywords in participating documents, she/he would have to
rely upon some background knowledge accumulated over time from other docu-
ments and experiences [24,26]. In reality, this is also true for existing Web search
techniques. The majority of retrieval methods require a precise query upfront to
express search intentions, which is fairly difficult for any user who has no back-
ground knowledge or past experience. Another factor is that Web users formulate
their queries diversely because of different personal perspectives and terminologi-
cal habits and vocabularies [33,70]. As a result, capturing user information needs

1.2. Questions and Motivations 7
through a given query is challenging and unrealistic. It is difficult for Web users
to deliver perfect information at the beginning. The problem leads to the first
question arising in our study:
1. Rather than user queries, what is the alternative to capturing
user information needs?
Instead of user queries, relevance features can be adopted in order to capture
users’ information needs. These features are called “relevance features” because
they need to be extracted based on relevance feedback, where a user judges the
results from previous retrievals and tells the system whether the documents are
relevant or not [65]. The Reuters Corpus Volume 1 (RCV1) dataset contains two
types of user feedback. One is positive feedback which is used to indicate that a
document is relevant. The other feedback is negative feedback which is used to
point out the irrelevant documents. According to the feedback, a model called
the Relevance Feature Discovery (RFD) model [5, 65] classifies all features into
three subsets: positive specific, general, and negative specific respectively. Al-
though the RFD claims that negative documents are useful to revise user needs,
here we only adopt the positive specific partial features from positive documents
throughout the thesis since they are sufficient to reveal user needs straightfor-
wardly in an optimal amount of feature space. A preliminary analysis was made
to support the accuracy of this decision.
Due to the fact that feature selection can speed up computation [125], most
information retrieval and filtering models also extract different amount of features

8 Chapter 1. Introduction
before implementing a weighing algorithm. For traditional IR models (including
Boolean, vector space, and probabilistic models), their processes all begin by iden-
tifying each document through a set of representative keywords. Later, a feature
selection is carefully assigned to select optimal features [65, 69]. The selection is
usually dependant on a ranking algorithm or a threshold control which attempts
to establish a simple sequence of all the keywords [69]. The selected features
are almost all in the term-based format, and are often utilized in the remaining
steps, such as indexing, filtering and delivering information, and classifying [69].
In addition, the feature selection is a common technique for addressing overfit-
ting [125]. In a restricted sense, the representative terms have some meanings of
their own or correlations with other terms but both completely disregarded.
To overcome the limitations, the text mining research community began to
pay more attention to phases or patterns instead of terms because it was be-
lieved that phases or patterns would be more discriminative [65,119,133]. One of
the well-known pattern-based models the Pattern Taxonomy Model (PTM) [118]
was introduced by Wu et al. in 2006. It adopts not only the concept of closed
patterns to prune irrelevant patterns, but also combines sequential pattern min-
ing to discover useful patterns. Rather than directly working on terms, a set of
patterns {p1, p2, ..., pm} is extracted for candidate features. Eventually, the pat-
terns are deployed into terms which are weighted according to their appearances.
Similar to most information filtering models, the PTM only considers positive
feedback and ignores negative feedback. Yet, it has shown a certain improvement

1.2. Questions and Motivations 9
in effectiveness.
The RFD, term-based, and PTM models all contain a feature selection process
for their own purposes. It is difficult to identify which model can produce the
best features as the alternative to user queries. This problem motivated the
present research to conduct a comprehensive comparison of a number of well-
known models that generate features. Since all the features are term-based and
obtained through local RCV1 training documents, we recognize them as low-level
local information. In order to take advantage of ontology filtering to constrain
search spaces and interpret high-level concepts, the second question arises:
2. How can local information be associated with global knowledge
in a world ontology?
Ontologies are commonly considered to deal with expert knowledge repre-
sentations [102]. They cover adequate concepts and their explicit relationships
to describe the world, and hence are referred to as the world knowledge base.
The world knowledge base is a taxonomic specification of commonsense knowl-
edge acquired by people through their experience and education [104]. Due to
the fact that commonsense knowledge is the collection of facts and information
that an ordinary person is expected to know, the ontologies have been identified
as the suitable representations of global knowledge. In 2011, Tao et al. [106]
explored a way to produce personalized ontologies by analysing both local infor-
mation and global knowledge. The local instances were adopted from the real
library database at the Queensland University of Technology. The global knowl-

10 Chapter 1. Introduction
edge relied on concepts existing among an universal ontology named the Library
Congress of Subject Headings (LCSH). They assumed the information items in
the local repository had a connection to the concepts in the LCSH. However, the
assumption left an emerging issue about how to reasonable build the connection.
Figure 1.2 illustrates a picture of the matching scenario.
Figure 1.2: Global concepts and local information matching
Local information is based on individual characteristics and interests, it is
unique or informal. The information is usually factual, but unstructured, and
in many cases it is textual. Inversely, global knowledge is learned from relevant
education and experience, which is general or structured. Information scientists
consider taxonomies, subject headings, and classification schemes as represen-
tations of knowledge [71, 114, 132]. These differences may lead to information
mismatch and knowledge shortage. As a result, a goal of this thesis is to pro-
pose an appropriate approach to match local information to global knowledge.
Within the existing methods [104, 115, 131, 134], the basic idea is to use condi-

1.2. Questions and Motivations 11
tional probability to determine relevant concepts c for describing the themes of
the local instances, P (c|F ) = P (c∩F )/P (F ), where F is a set of features discov-
ered in the local instances. However, this technique usually achieves a low level of
performance because of the mismatch problem [80, 111]. Here in particular, the
mismatch means some relevant specific concepts have been omitted. The problem
occurs when the popular features (usefully very frequent features) match many
relevant but general concepts (usually appearing in the top of the ontology); but
do not match some relevant specific concepts (usually appearing at the bottom of
the ontology). This problem motivates us to develop an ontology-based mining
approach for distinguishing the concepts’ generality and specificity.
Personalized ontologies can be constructed by adopting the proposed auto-
matic matching method to discover relevant concepts from the common knowl-
edge base. As described before, the concepts are considered for capturing user
information needs, but the process to measure and evaluate the discovered con-
cepts remains unknown. Unlike other filtering systems [39, 98, 109], a number of
data sources are available (such as Web pages, documents, Extensible Markup
Language (XML) files) to rank documents according to term weights and simi-
larity measures. The research conducted by Tao et al. (2011) took into account
that the library database merely retains a huge amount of subjects. Each subject
is understood as a single concept, which consists of a few terms. In such a case,
applying traditional weighing schemes is not feasible because of the constrained
sources. However, in terms of the foundation of information filtering systems, a

12 Chapter 1. Introduction
term weight pair is generally required at first. Thus, the third question arises:
3. How can weights be properly assigned to the terms in the con-
cepts?
To answer this question, the thesis attempts to use two methods: the lan-
guage modelling and deploying method. Language modelling is a quite general
formal approach to IR, with many variant realizations [50, 76]. The original and
basic method for using language models in IR is the query likelihood model.
According to the similar theory, we construct from each subject si in the col-
lection of matched subjects SC, where SC = {s1, s2, ..., sn}. The low-level
relevance features are utilized as queries Q. Our goal is to rank subjects by
rel(si) = |si ∩ Q|/|Q|, where the probability of a subject is interpreted as the
likelihood that it is relevant to the query.
Regarding the deploying method [118], our evaluation of term supports (weights)
is different to the other term-based approaches. In the term-based approaches,
the evaluation of an assigned term weight is based on its appearance in docu-
ments. Within our model, terms are weighted according to their appearance in
matched concepts.
Due to the uncertainty, we cannot determine which method is better to weight
all the terms appearing for the matched concepts. Thus, an empirical comparison
of these two methods is conducted after gathering the results of the proposed
approach and all baseline models.

1.3. Significance and Major Contributions 13
In sum, this section has outlined the three important questions that motivate
us throughout the whole study. Some general information was also provided to
understand the context of the questions. The related discussions outlined the
concepts of the corresponding solutions.
1.3 Significance and Major Contributions
This research is particularly significant due to the nature and fast growing use
of the Web; Web users are demanding quality information rather than quan-
tity. The popular search engines are, however, struggling to deliver the desired
information. This has prompted the present study to explore a concept-based
filtering model that has the semantic scalability and adaptability to serve per-
sonalized content to individual users. This research contributes to the domains
of ontological user profiling, information filtering, and knowledge representation
and engineering. The related outputs are critical as filtering systems are expected
to return satisfactory retrieval results and offer customized services.
In this thesis, two approaches are proposed: 1) an ontology-based mining ap-
proach for producing personalized ontologies, and 2) a relevance feature matching
approach to link the local information represented by relevance features with the
global concepts allocated in a world knowledge base. Both approaches hold the
same objective which is to capture proper user information needs so as to im-
prove text mining effectiveness. A systematic scientific evaluation is conducted
to measure the performance of the approaches. Their relative contributions are

14 Chapter 1. Introduction
listed below:
• Ontology-Based Learning Approach
1. We propose an ontology-based learning approach to allocating personal
search intentions in a common ontology;
2. We introduce an innovative in-levels mining method in order to ensure
a certain level of user information needs among an abstract hierarchical
structure;
3. We develop a new tracking method for knowledge representation in a
two dimensional zoomable way.
• Relevance Features Matching Approach
1. We develop a solid matching approach for transferring low-level terms
to high-level concepts;
2. We provide a promising methodology for evaluating term weights based
on their distributions in subjects (concepts) and queries (features). The
method also demonstrates that the applied weighting algorithm performs
better than common deployment in evaluation;
3. We outline a method to connect local information with worldwide knowl-
edge for extracting personalized ontologies.

1.4. Publications 15
1.4 Publications
The section lists all published work.
• Yan Shen, Yuefeng Li, Yue Xu, Renato Iannella, Abdulmohsen Algarni, &
Xiaohui Tao. An ontology-based mining approach for user search intent dis-
covery. In Proceedings of the Sixteenth Australasian Document Computing
Symposium (ADCS’11), pp. 39-46, Canberra, Australia.
• Hang Jin, Yanming Feng, & Yan Shen. Accurate urban road model recon-
struction from high resolution remotely sensed imagery based on Support
Vector Machine and Gabor filters. In Joint Urban Remote Sensing Event
(JURSE 2011), 11-13 April 2011, Munich, Germany.
• Yan Shen, Yuefeng Li, Yue Xu, & Xiaohui Tao. Matching Relevance Fea-
tures with Ontological Concepts. Accepted by the International Workshop
on Web Personalization and Recommender Systems (WPRS2012) in con-
junction with the IEEE/WIC/ACM International Conference on Web In-
telligence (WI’12), 4-7 December, Macau, China.
• Xiaohui Tao, Yuefeng Li, Bin Liu, & Yan Shen. Semantic Labelling for Doc-
ument Feature Patterns Using Ontological Subjects. Accepted by the 2012
IEEE/WIC/ACM International Conference on Web Intelligence (WI’12),
Macau, China, 4-7 December 2012.
• Yan Shen, Yuefeng Li, & Yue Xu. Adopting Relevance Feature to Learn

16 Chapter 1. Introduction
Personalized Ontologies. Accepted by the Twenty-Fifth Australasian Joint
Conference on Artificial Intelligence (AI’12), 4-7 December, Sydney, Aus-
tralia.
1.5 Thesis Organization
This thesis is organized in six chapters.
Chapter 2 reviews a wide range of significant related works on useful pat-
tern discovery methods, ontology-based user profiling, and the similarity concept
matching procedure. The chapter also covers the necessary knowledge to under-
stand existing techniques regarding the basic information retrieval models, Web
personalization, and personalized ontologies.
Chapter 3 introduces an ontology-based mining approach. The model aims to
discover and define user search intentions in the in-levels hierarchical structure.
The chapter explains the entire approach step-by-step.
Chapter 4 outlines a distributed matching approach to address the problem of
local information and global knowledge mismatch. The matching approach incor-
porates data mining and ontology learning. The chapter begins with an overview
of feature acquisition based on pattern mining technique. Then, a primary con-
trol is developed on the learning side to involve the relevant concepts from large
scale ontology.
Chapter 5 discusses the evaluation for the approaches proposed in Chapter
3 and 4. The evaluation is based on a number of scientific experiments. To en-

1.5. Thesis Organization 17
sure scalability and reliability, different types of baseline are used for comparison
through a number of information filtering measurements. The gathered results
are displayed and discussed.
Chapter 6 brings the dissertation to a conclusion. The important points and
findings are summarized. Recommendations and plans for future investigation
are also outlined.

18 Chapter 1. Introduction

Chapter 2
Literature Review
This chapter presents a preliminary literature review of the present study. The
purposes are: 1) to identify our particular research questions; and 2) to under-
stand the current knowledge including substantive findings as well as theoretical
and methodological contributions to personalized ontologies.
As depicted in Figure 2.1, all the involved domains are outlined clearly. The
red circle represents the coverage of the conducted review. Some contents are
overlapping with multiple domains. We divided the whole review into two cat-
egories. The first category is in the view of computer-centered. It covers fun-
damental Web searching techniques in information retrieval, popular knowledge
discovery approaches in machine learning, and various filtering methods in data
mining. All relevant aspects including efficient indexing, useful feature selection,
19

20 Chapter 2. Literature Review
query processing, weighting algorithms, are mainly working on machine processes
to improve the “quality” of answer sets [1]. The other category concentrates on
Web personalization including user profile acquisition, user information needs
capturing, and the representative ontology-based methods. The specified factors
consider in the human-centered view, which commonly make uses of user prefer-
ences to understand user central needs, and then affect the operation of retrieval
models.
Figure 2.1: The coverage of literature review
The aforementioned classification is also based on different retrieval functions.
Known that a typical information retrieval system is to return potential valuable
documents from a large set of documents in accordance with criteria specified by
users. Yet, this function is named document search, or said ad-hoc, which can
be referred to the computer-centered view. It is the selection of documents from
a collection of documents. The other one is called document routing, or said

2.1. Classic Information Retrieval Models 21
filtering, which can be linked to the human-centered view. It is the dissemination
of incoming documents to correct users on the basis of user profiles.
2.1 Classic Information Retrieval Models
Over the last two decades, the mainstream of Web search models was limited
by either keyword-based [55,94] or category-based [95,98] technique. It is noted
that these models play an essential role for gathering statistically significant infor-
mation because they share common tasks and problems of information retrieval
and information filtering. This section chooses some representatives to expose
the core theories, approaches, and evaluation measurements. All of them can
be studied into boolean, vector, and probabilistic models. These classic models
consider that each document is described by a set of representative keywords at
the early stage. Regarding to indexed keywords, the Information Retrieval (IR)
models can process feature selections, and compute weights for all the keywords.
Finally, all the documents can be ranked according to the computed weights.
Generally speaking, the documents in the top position or with high similarity
scores will be considered as results for users. [76,107].
Term Frequency-Inverse Document Frequency
A traditional theory [55] used for Web searching firstly builds an index of all
documents. The index can be utilized to look up whether the indexed keywords
are appeared in the documents. Term Frequency-Inverse Document Frequency

22 Chapter 2. Literature Review
(TF-IDF) was designed to facilitate this process in the traditional Web searching
processes [52, 109]. To ensure search quality, a preliminary work is required to
specify the importance of each term in document. The importance of a term ti
within a document dj can be measured by considering its frequency, which simply
defined as below:
TFi,j =ni,j∑k ni,j
where numerator ni,j is the number of occurrences of ti in dj, and the denominator
is the sum of the occurrences of all terms in dj. The inverse document frequency
is a measure of the general importance of the term, define as below:
IDFi = log |D||{d : ti∈d}|
|D|refers to the total number of documents. | {d : ti ∈ d} | refers to the number
of documents that involves the term ti. Finally, the TF-IDF is generated as below
to measure the weight of term frequency.
(TF − IDF )i,j = TFi,j ∗ IDFi,j
Similarity Measurement
Cosine similarity is one of the most popular algorithms that is widely used by
many search mechanisms [29, 68, 94, 98, 105, 109]. The aim of using cosine simi-
larity is to know how similar between two vectors, and then their relations can
be inferred by thinking about the similarity value. The vectors could be diverse

2.1. Classic Information Retrieval Models 23
elements, like terms, documents, concepts, patterns, objects or subjects. The
cosine similarity can be also seen as a method of normalizing document length
during comparison. There are many variants, the basic formula is provided here
as follows:
Similarity Measure = cos(θ) = A·B‖A‖·‖B‖
The attribute vectors A and B are usually the term frequency vectors of two
documents.
Query Processing and Feature Selection
Web searching is becoming increasingly complex [33, 55]. The existing forms of
query are diverse including words, phrases, questions, passages, and even docu-
ments. Instead of a single document or answer, the returned result is frequently
an array of relevant information strengthened by precise navigation to related
information and topics that can help searchers to discover insightful results or
get more specific information. Query processing is a necessary step to retrieve
consistently superior results. Our proposed approach endeavours to know what
kinds of information is available on query, and how they can be extracted.
During searching, a success process comes from understanding what users are
expressing from their queries [24,70]. Some user queries are simply stated, while
others are stated in a boolean format (“apples AND iphone OR ipad”). Hence, a
searching platform must have a range of tools in order to accurately identify and
then reformulate what is information being required from the entered query [24].

24 Chapter 2. Literature Review
In order to obtain better performance in the text retrieval systems, many
attempts [15, 63] have been worked on another aspect - query expansion. The
query expansion with a generic ontology, like WordNet [78], has been shown to
potentially relevant to improve recall, as it permits matching a query to relevant
documents that do not contain any of the original query terms. Voorhees [113]
manually expanded 50 queries over a TREC collection using WordNet, and ob-
served that expansion was useful for short, incomplete queries, but not guaran-
teeing for complete topic statements. Further, for short queries, the automatic
expansion is not trivial since it may degrade rather than enhance retrieval per-
formance.
Feature selection is a fundamental stage for the majority of IR models. It
intends to remove non-informative features according to corpus statistics and to
improve the accuracy of classification by eliminating useless features. Usually, a
set of keywords is applied as elements in the vector of the feature space. The
bag of words can be obtained by diverse term selection approaches both in the
context of IR and data mining. Furthermore, the feature selection, i.e. selecting
a subset of features available for describing the data before applying a learning
algorithm, is a common technique for addressing over-fitting issue [69, 125]. It
has been widely observed that the feature selection can be an useful strategy to
simplify or speed up computations. In addition, it can lead to few loss in clas-
sification quality while employed appropriately. Nevertheless, general theoretical
performance guarantees are modest and it is often difficult to claim more than

2.1. Classic Information Retrieval Models 25
a vague intuitive understanding of why a particular feature selection algorithm
performs well when it does. Indeed, selecting an optimal set of features is in gen-
eral difficult, both theoretically and empirically; hardness results are known [10],
and in practice greedy heuristics are often employed [114,125].
For term-based feature selection approaches, they struggle against the prob-
lem of selecting appropriate number of features among an enormous set of terms
to guarantee the retrieval efficiency [133]. Like some information gain mod-
els [93, 123], they are restricted on term statistics in the entire collection, but
do not take relevance information (e.g. user feedback) into account. As an ex-
tension of the term-based approaches, pattern mining techniques are investigated
by data mining communities for many years. These techniques extract useful
patterns from large data collections instead of term-based features. Some stud-
ies categorize the extracted patterns into frequent, closed, and closed sequential
patterns [65]. Simultaneously, they measure the specificity of pattens explicitly
according to relevance feedback from human beings. Pattern taxonomy model
(PTM) was first introduced by Wu et al. [119] in 2004. It improves search perfor-
mance by using both frequent and closed sequential patterns. A more advanced
mining method of the PTM (PDS) for using frequent patterns in text was pro-
posed by Wu et al. [118] in 2006. This method focuses on addressing the difficul-
ties of using specific long patterns in text by using patterns to weight accurately
low-level terms based on their distributions in the patterns. Later on, it has been
further researched in [67] to develop a two-stage model for irrelevant information

26 Chapter 2. Literature Review
filtering. Li et al. [65] build the Relevance Feature Discovery (RFD) model by
mining patterns from positive and negative documents respectively. The related
output shows potentials for enhancing information filtering and user profiling.
Precision and Recall performance measuring schema
In the field of IR, the effectiveness is usually measured by using the precision
and recall performance measuring schema [55, 68, 98, 105]. The precision of a
set of results is the ratio of the number of relevant documents retrieved to the
total number of documents retrieved. It is an effective standard to measure how
well a system retrieves only relevant results. In contrast to the precision, recall
is used to measure all the relevant documents in terms of the entire collection.
Consequently, there is a strong argument with respect to the purpose of searching,
the recall is less important than precision, because users usually concern about
the top-K ranking results with high precision, they do not prefer that all the
retrieved documents are relevant to their queries.
Whilst Web searching has been recognized as a supplicated tool for IR, a
variety of limitations led by the existing techniques can still be discovered easily.
The tradition solution to the issue of precision and recall employs keyword-based
search techniques [10]. The results are only retrieved when they contain accurate
keywords specified by the user. Due to this reason, these techniques suffer from
two serious problems, resulting in the low precision.
Here, we summarises two main reasons to explain why the classic IR Models

2.2. Web Personalization 27
cause low performance:
• Users are usually unable to express their information needs accurately [49,
55].
• The keyword-based search techniques are too sensitive to vocabulary [7].
Many documents containing the desired semantics are disregarded.
2.2 Web Personalization
The volume of information on the Internet is increasing with unpredictable speed
every day. People often suffer from the issues of information mismatch and over-
load. To alleviate this problem, Shahabi and Chen [95] argued that personaliza-
tion is one of the effective remedies to customize the Web environment for users.
They [95] outlined two components within the domain of Web personalization.
One is the recommendation systems. The other is personalized Web search sys-
tems. Even though the existing Web search engines are considerably successful
and useful, the majority of them are not personalized Web search systems. They
are good at discovering pages relevant to a query (typically keyword-based) us-
ing the specific algorithms, but disregard who submits the query. As a result, no
matter who inputs a query, the search results would be exactly the same. Further-
more, how to acquire user information needs efficiently and effectively is another
essential research concern. Thus, this section focuses on reviewing the relevant
knowledge of personalized Web search systems, and comprehending some existing

28 Chapter 2. Literature Review
approaches to utilize both explicit and implicit information from user profiles.
In recent years, lack personalization is a common concern for most keyword-
based and category-based Web searches. Existing approaches cause users have to
spend a lot of time for searching and preliminary reviewing of a large amount of
listed information. The goal of personalized searching is to help user to optimize
the process of information retrieval according to their preferences [87]. However,
their processes are more complicated than traditional processes. Two basic re-
quirements are always needed for the personalized searching [126]: 1) user interest
is known and is well suitable for workplace setting. User profile is treated as a
common workplace , which usually utilizes to store user’s preference, and 2) the
mapping between user’s interest and search domain is existent. In essence, per-
sonalized searches [55] not only take few keywords to describe users’ information
needs, but also to consider the users’ individual information, such as behaviors,
communities, locations, browsing histories or glance time. There are many differ-
ent approaches to complete personalized notions. All these approaches have the
motivation of returning the most relevant results after filter irrelevant information
based on individual data. For example, Sieg et al. [98] utilized the user context
to personalize search results by re-ranking the results from a search engine for a
given query.

2.2. Web Personalization 29
2.2.1 Explicit and Implicit Feedback
A fundamental source of user information is relevance feedback. It can be pro-
vided by examined documents or agent actions explicitly or implicitly [57]. Its
goal is to overcome the problem of translating user information need into a
query [57]. A user gives explicit feedback by using one or more ordinal or qual-
itative scales, whereas implicit feedback is estimated by agents according to ob-
servation of a group of interest indicators.
A central issue of explicit feedback is that users have to examine items to
assign them a value on a rating scale or write comments about items. No doubt
that the explicit feedback is more reliable, however, its collection burdens the
users with an additional cognitive load caused by the necessity of evaluating each
information item [117]. As a result, the typical approaches for capturing explicit
feedback are based on either user interaction or observation. Consequently, the
users are required to complete a large set of questionnaires. Even though this
method can generate “perfect” training sets that can accurately reflect user in-
formation needs, it is considered as a pitfall that is the high cost of time, money
and patience. Therefore, lacking description is a vital problem existing from the
collected data.
Implicit feedback [116], on the other hand, is calculated on the base of one or
more implicit interest indicators, which act as surrogate measures for predicting
user interest on a given information item. In contrast, the definition of implicit
feedback, or named pseudo relevance feedback, is the retrieval system attempts

30 Chapter 2. Literature Review
to estimate which items the users may be interested in [35, 96]. Due to the fact
that with many retrieval tasks such as Web searching, the users are not willing
to provide the explicit feedback (clearly relevance feedback) to systems. Conse-
quently, the implicit feedback has became an active area of research, especially
for personalization processing [1]. As known that query expansion and user pro-
filing are two essential techniques for implicit feedback [55, 116]. For this study,
the user profiling is the main domain that we focus on. The production of user
profile can be simply understood by the following way: an information filtering
system firstly records user interaction data such as click through, scrolling fre-
quency, browsing history, and page staying time. Later on , the system infers the
user’s information need through the analysis of these interaction data. A new
query is then composed to re-rank documents. Finally, the re-ranked documents
are presented to the users. A number of experimental results proved that the im-
plicit feedback can infer the user’s information need and indicate user’s interest
intelligently through those implicit data provided in the profile. However, gener-
ating the implicit feedback is either expensive or time-consuming [96]. Also, it is
undesirable when the user’s interest is changeable.
2.2.2 User Information Needs
For user information need acquisition, many efforts have been undertaken to im-
prove the accuracy. Closely related to our work, a user ontology consisting of both
conceptual structure and semantic relations was presented by Jiang and Tan [52]

2.2. Web Personalization 31
in 2009. Their objective of building the ontology was to represent and capture
users’ interests in target domains. Subsequently, a method, they called spread-
ing activation theory, was employed for providing personalized services. Li and
Zhong [66] carried out a term-based ontology learning method for acquiring user
information needs. More recently, Tao et al. [106] developed an ontology-based
knowledge retrieval framework to capture user information needs by considering
user knowledge background and user’s local instance repository with the associ-
ation role and data mining algorithms.
Other works also reflect the importance of user information needs. They treat
user interests as implicit feedback and store in user profiles. Gauch et al. [39]
and Liu et al. [68] learned a user’s profile from her/ his browsing history. Sieg
et al. [98] utilized ontological user profile on the basis of the user’s interaction
with a concept hierarchy which captures domain knowledge. Tao et al. [105]
required users to specify their preferences manually for profiling. In short, the
discussed works aim to enhance search performance through directly asking the
users for explicit feedback or collecting implicit feedback automatically. Few of
them incorporated both the explicit and implicit feedback to assist their filtering
task.
2.2.3 User Profiling
As an “ideal” personalized search system [55], user profiling is required to ac-
complish the implementation of personalization. The profiling includes user data

32 Chapter 2. Literature Review
collection method, profile storage (client-side or server-side), profile construc-
tion, interface, and personalization method. Referring to our proposed research,
ontology modelling is considered as another potential notion to facilitate the per-
sonalized search. Therefore, a series of questions are then raised, such as how to
present the personalized results in ontological format? Is it possible to develop a
special-purpose or customized client application? In order to have the semantic
capability, is it possible to build ontological user profiles? We expect to answer
the questions after understanding the concept of user profiles precisely. This
section reviews the general knowledge of user profile and discusses some related
works that are useful to work out the relative solutions.
Gathering user profile is to better understand implicit user wants in searching.
In other words [134], this objective is related to search intention acquisition. Chau
et al. [20] required direct inputs about interesting phrases from users. However,
due to users expecting minimal involvement during search, the approach was un-
suitable. An approach proposed by Liu et al. [68] in 2004 learned a user’s favorite
categories from her/his search history, and then constructed a user profile based
on the search history. Simultaneously, a general profile was constructed based
on open directory project categories hierarchy. To improve Web search effective-
ness, the above discussed profiles are used to deduce appropriate categories for
each user query. Similar works were also done by Sendhilkumar and Geetha [94],
and Tao et al. [106], but their purposes were different. Especially with Tao et al’s
work, they built the general profile named world knowledge base (based on global

2.2. Web Personalization 33
analysis) and the instances of library collection named local instance repository
(base on local analysis). By reviewing the preview works, we realized that the
user profile can be built with diverse data sources. Its existing is to filter useless
information in accordance to the stored data.
Currently, there are two sorts of information that can be used to build user
profile: explicit or implicit information. In essence, input query is treated as
the explicit information, because it is a partial expression of user information
need [55, 95]. The collection of explicit information data is easy to obtain via
computing term frequency of the input query. On the other side, the implicit
information describes a user’s interest and behavior. In order to capture the
accurate implicit information, it is possible to represent with the minimal user
involvement [98]. This can be done by observing the related data, such as page
visiting frequency, page visiting time, and other actions including adding a page
to bookmark or setting a page to home page etc [55, 98].
An easy approach for constructing a user profile is to describe the profile
through a set of keywords and to require the user to provide the necessary key-
words for more adequate descriptions [10]. The reason that we think it is easy
because it contains many user involvements. In fact, if the user is not familiar
with the system, the user might find difficult to provide the keywords to describe
the preference appropriately. Furthermore, attempting to familiar with all the
vocabularies in documents is time consuming and a heavy burden for the user.
Therefore, a more elaborate alternative is expected to accomplish user profil-

34 Chapter 2. Literature Review
ing, which can not only precisely describe the user preference, but also probably
minimize user involvement. The ontological user profile is a possible solution to
address the previous concern because it is composed by a group of concepts, which
can benefit the preference inference and the study of user background knowledge.
2.3 Knowledge Discovery and Pattern Mining
Knowledge Discovery and Data Mining (KDD) [31] is an interdisciplinary area
focusing upon methodologies for extracting useful knowledge from data. The
ongoing rapid growth of online data due to the Internet and the widespread
use of databases have created an immense need for KDD methodologies. The
challenge of extracting knowledge from data draws upon research in statistics,
databases, pattern recognition, machine learning, data visualization, optimiza-
tion, and high-performance computing, to deliver advanced business intelligence
and web discovery solutions.
Knowledge discovery is the non-trivial process of extracting implicit, previ-
ously unknown, and potentially useful information or patterns in data [36]. Ac-
cording to [30], the knowledge discovery can be formally defined as follows: Given
a set of facts (data) F , and a language L, a pattern is an expression S ∈ L that
describes a subset of the data or a model applicable to the subset. A pattern is
called knowledge if it is interesting to some users or criteria. Hence, the process
of knowledge discovery is to extract interesting patterns from the set of facts in
a database.

2.3. Knowledge Discovery and Pattern Mining 35
2.3.1 Process of Knowledge Discovery
The knowledge discovery process typically involves numerous steps with many
decisions made by the user. As shown in Figure 2.2, the steps of knowledge
discovery may consist of the following: data selection, data preprocessing, data
transformation, pattern discovery and pattern evaluation. Moreover, Knowledge
discovery is “the overall process of discovering useful knowledge from data, while
data mining refers to a particular step in this process. Data mining is the appli-
cation of specific algorithms for extracting patterns from data... The additional
steps in the KDD process, such as data preparation, data selection, data clean-
ing, incorporation of appropriate prior knowledge, and proper interpretation of
the results of mining, are essential to ensure that useful knowledge is derived from
the data. Blind application of data-mining methods can be a dangerous activity,
easily leading to the discovery of meaningless and invalid patterns” [30]. These
steps are briefly described as follows:
• Data Selection: This process includes generating a target dataset and
selecting a dataset or a subset of large data sources where discovery is to be
performed. The input of this process is a database and output is a target
data.
• Preprocessing: This process involves basic operations for data clean-
ing and noise removing. It also includes collecting required information to
model or account for noise, providing appropriate strategies for dealing with

36 Chapter 2. Literature Review
missing data and accounting for redundant data.
• Transformation: The preprocessed data needs to be transformed into a
predefined format, depending on the data mining task. This process needs
to select an adequate type of features to represent data. In addition, feature
selection can be used at this stage for dimension reduction. As the end of
this process,a set of features is recognised as a data set.
• Data Mining: This process involves searching for patterns of interest in a
particular representational form or a set of such representations, including
classification rules, trees, and clustering. The user can aid the data-mining
method by correctly performing the preceding steps.
• Pattern Evaluation: The discovered patterns are evaluated if they are
valid, novel, and potentially useful for the users to meet their information
needs. Only those evaluated to be interesting in some manner are viewed
as useful knowledge. This process should decide whether a pattern is inter-
esting enough to form knowledge in the current context.
2.3.2 Tasks of Data Mining
According to the process of knowledge discovery, data mining methods are per-
formed for extracting patterns from data. These methods can have different goals.
It is possible that several methods that have different goals may be applied to
achieve a desired result. For example, to recommend a product (item) to a partic-

2.3. Knowledge Discovery and Pattern Mining 37
Figure 2.2: The steps of knowledge discovery in databases
ular user, a recommender system might need to group users who have the similar
taste with the user in the customer database, then predict a rate that would be
given to the product according to these users.
Generally, data mining goals fall under the following categories:
• Classification: Classification is the process of assigning data objects to
desired predefined categories or classes. It can be viewed as the process of
finding a proper method to distinguish data classes or concepts. Generally,
training data is required for concept learning before classification can be
proceeded.
• Clustering: Given a set of data objects, clustering is the task of partition-
ing the object set into a finite number of groups such that the objects in
the same group have similar characteristics. In other words, the principle of
clustering is to maximize the intra-class similarity and minimize the inter-
class similarity. The major difference between classification and clustering

38 Chapter 2. Literature Review
is that the latter analyses objects without consulting class labels, whereas
the former need such information in a supervised setting.
• Summarisation: This task is to analysis a set of data objects and de-
scribe their common or characteristic features. Redundant features are also
removed to generate a set of compact patterns, representing the concept of
these objects.
• Association Analysis: Given a set of data objects, the association task is
to find implicit relationships between features (items or attributes) in the
data set with respect to a given criterion. For example, these relations may
be associations between attributes within the data item (intra-patterns) or
associations between different data items (inter-patterns). The investigation
of relationships between items over a period of time is also often referred
to as sequential pattern analysis
2.3.3 Pattern Mining and Association Rules
Pattern discovery is a very useful tool for knowledge discovery tasks. However,
the growing popularity of pattern discovery is often obstructed by returning an
overwhelming number of patterns. The complete collection of patterns affects
not only efficiency performance, but also difficulty to be explored by human
or even machine. This is because they contain non-informative and redundant
patterns. There are several previous attempts proposed to solve the issue of too
large output, but all they fall into the two major approaches. The first approach

2.3. Knowledge Discovery and Pattern Mining 39
is to discover informative patterns with a certain significant measure and the
other but more widely is to eliminate redundant patterns with a given condensed
representation. With this method, large databases can be reduced to only a
few representative data entries. Among such condensed representations, closed
and maximal frequent patterns are two most commonly used for redundancy
reduction of a large collection of patterns. However, while closed patterns offer
the advantage of the recovery of support information, it have found that their
mining result is still too large to be effectively explored. On the other hand, the
mining result of maximal patterns is more concisely. However, they lose support
information. This leads to a recent approach, which balances the tread-off, named
pattern summarization. Due to the huge number of patterns generated by mining
processes, the objective of pattern summarization is to summarize a collection
of itemset patterns using only a few representatives, while a small number of
patterns that a user can handle easily.
With regard to text mining, pattern-based text mining models have recently
emerged as a novel approach for solving knowledge discovery in text. Based on our
survey, several studies have shown encouraging improvement of performance of
text mining tasks such as text classification, document clustering, and information
filtering. Nevertheless, we believe that effective performance of such systems have
been still limited with the number explosion of discovered patterns, which leads to
difficulty in doing the global analysis. To enhance this interpretability, it needs to
focus on a novel approach for concisely representing a large collection of frequent

40 Chapter 2. Literature Review
patterns extracted from text documents.
An association rule are implication statements that uncover interesting asso-
ciations among items in a set of data items. The association rules were originally
proposed by [2] for market basket analysis, searching for interesting relationships
between shoppers and items brought. Currently, association rule mining is one
of the most important and well studied technique for data mining [43].
2.3.4 Association Rules and Frequent Itemsets Mining
Let I = {I1, I2, . . . , Im} be a set of m distinct items (or attributes), T be a
transaction that consists of a set of items such that T ⊆ I, D be a database
with different transactions. An association rule is an implication in the form of
X ⇒ Y , where X, Y ⊂ I are sets of items called itemsets, and X ∩ Y = ∅. X is
called antecedent while Y is called consequent, the rule means X implies Y .
Since a large number of association rules can be generated, two important ba-
sic measures are applied to discover interesting ones:support and confidence. The
support reflects the generality of a rule discovered while the confidence reflects
the certainty or validity of the rule. Given an itemset AB ⊂ I ∈ D, the support
of rule A⇒ B can be calculated as the following equations.
support(A⇒ B) = P (A ∪B) (2.1)

2.3. Knowledge Discovery and Pattern Mining 41
The confidence of the rule can be defined as the following expression.
confidence(A⇒ B) =P (A ∪B)
P (A)(2.2)
Generally, an association rule is interesting if it meets both a pre-defined mini-
mum support threshold and a minimum confidence threshold. Currently, there
are various types of interesting association rules proposed based on different in-
terestingness measures [103].
To mine association rules from large databases, a variety of efficient mining
algorithms was proposed based on two-step approach, where frequent itemsets are
generated in the first step and association rules are generated based on frequent
itemsets in the second one.
2.3.5 Efficient Mining Algorithms
The first well-known efficient algorithm for finding frequent itemsets is Apriori [4].
This algorithm searches for all frequent itemsets with minimum support and
uses an anti-monotonic relation property to improve the efficiency. However, the
Apriori algorithm is computationally intensive due to the overhead of repeatedly
scanning the database for support counting of all candidates.
Another efficient algorithm for mining frequent itemsets is FP-growth [48].
the main advantage of the FP-growth algorithm is to mine all frequent itemsets
without generating any candidate. To achieve this, FP-tree, a tree-like structure,

42 Chapter 2. Literature Review
Table 2.1: An example of vertical format of databaseItem TID List Absolute Support
A 100, 200, 600, 1000 4B 300, 400, 500, 600, 700, 800 6C 200, 400, 500, 800, 900 5D 100, 200, 300, 400, 600, 700, 900, 1000 8E 200, 700, 800 3F 100, 900 2G 800 1
is designated for compressing a database. The FP-growth algorithm requires only
two database scans for finding all frequent itemsets. The first round is to discover
frequent itemsets of size 1 with minimum support and the second one is to sort
the frequent items in all transactions with the descending order of support values
for extracting the FP-tree.
Once the FP-tree was built, frequent itemsets is recursively extracted from
the FP-tree without consulting the original database.
A totally different algorithm for mining frequent itemsets was proposed in [128],
named Eclat. While the two previous algorithms mine frequent itemsets in the
original format of transactional database, Eclat first needs to transpose the orig-
inal database in order to mine frequent patterns with a different format, named
vertical data format. This format regards that an item transaction consists of a
list of transaction-ids. It can be seen in Table 2.1
Once the database was transposed, Eclat exploits the search space by inter-
secting the transaction-id lists between item transactions, where frequent (k +
1)−itemsets are identified by the resulting set of intersecting transaction-id lists

2.3. Knowledge Discovery and Pattern Mining 43
of frequent k−itemsets. For instance, given Supmin = 0.3, bd is obtained by in-
tersecting transaction-id lists of items b and d. Likewise FP-growth, Eclat does
not require database scans while it is easy to determine the support of itemset.
Further to the previous example, if Supmin = 0.3, both items f and g become
infrequent with the count of number of transactions which contain in their TID.
The main drawback of the Eclat algorithm is that it requires the large amount of
memory to fit the large part of database.
2.3.6 Mining Diverse Patterns
Sequential Patterns
There are many applications involving sequence data such as customer shopping
sequences, Web click-streams, text, and biological sequences. With these applica-
tions, databases are represented as sequences of items or events, recorded with or
without timestamps. Sequent pattern mining was first introduced by [3] to dis-
cover sequential patterns or itemsets from such databases. Here, the problem of
sequential pattern mining can be defined as follows: Given a sequence database,
D = {s1, s2, . . . , sn}, the support of a sequence α is the number of sequences in D
which contain α. If the support of a sequence α satisfies a pre-specified min sup
threshold, α is a frequent sequential pattern.
Since many sequence databases often consist of long sequences of items, this
results in quite time-consuming to efficient mine sequential patterns from such
databases. As a result, a variety of mining algorithms have been proposed to

44 Chapter 2. Literature Review
improve the mining efficiency such as GST [101], PrefixSpan [47], FreeSPAN [46],
ApproxMAP [61], and SPADE [129].
Frequent Patterns
Although frequent pattern mining is a very powerful paradigm, a major challenge
in mining frequent patterns from a large data set is the fact that a data mining
process may easily generate many thousands of patterns from a given set of data,
especially support threshold is very low. The large amount of generated patterns
often make it difficult for users to examine them easily. Moreover, many studies
have demonstrated that using all frequent patterns can reduce the performance
of knowledge discovery systems [23,43].
To overcome the challenge of pattern mining, data mining has developed sev-
eral pattern mining techniques to improve both the efficiency and effectiveness
of discovered frequent patterns. Generally, the pattern mining methods can be
divided into two main approaches: 1) mining interesting patterns and 2) mining
approximate patterns.
Interesting and Useful Patterns
Although frequent patterns provide highly detailed information in data, a partic-
ular user tends to be interested in only a small subset of them. A lot of studies in
data mining has contributed to mining interesting patterns or rules to meet user
interests, including constraint-based mining and using interestingness measures.
In constraint-based mining, the patterns that satisfy user-specified constraints

2.3. Knowledge Discovery and Pattern Mining 45
are reported as interesting patterns. A variety of constraints have been proposed
to mine particular patterns. Studies have analysed that these constraints can be
categorized into a finite number of categories according to how they are interact
with the mining process. For example [32],succinct constraints can be pushed
into the initial data selection process, anti-monotone constraints can be pushed
deeply into the mining process to improve the mining efficiency, and monotonic
constraints result in reducing the constraint checking. Currently, new constraints
for mining interesting patterns have been proposed such as pattern set mining as
well as constraints for mining complex patterns [83,135].
A lot of studies were conducted on discovering interesting patterns using in-
terestingness measures. Both objective and subjective measures have been widely
proposed to evaluate the interestingness of discovered patterns [99]. Objective
measures are based on data-driven, which determine the interestingness of a pat-
tern in terms of statistics. For example, both support and confidence are two
well-known measures for finding interesting rules. In [41], lift and χ2 have been
proposed as interesting measures for selecting correlation rules. Recently, the fo-
cus was more on the concepts of information theory to rank and select interesting
patterns such as information gain [23] and maximum entropy models [73,108].
Subjective measures mainly focus on finding interesting or unexpectedness
patterns compared with user’s priori knowledge. For example, in [51] user’s prior
knowledge is expressed by a Bayesian network. The interestingness of an itermset
is defined as the absolute difference between its support estimated from the data

46 Chapter 2. Literature Review
and from the Bayesian network. In [120], user’s interactive feedback can be
considered as user’s prior knowledge to guide the discovery of interesting patterns.
A data-driven approach to select rules for a particular user was proposed in [22].
Approximate Patterns
To reduce the huge set of frequent patterns generated in data mining, studies
have been focusing on mining an approximate set of frequent patterns. Many
approximate patterns try to reduce the redundancy, which can be referred to
pattern summarization in some senses. In general, they can be discussed into two
main categories: pattern compression and representative patterns.
Earlier approaches focus on pattern compression, aiming to eliminate redun-
dant patterns. For example, the concept of closed patterns proposed in [130],
aiming to find lossless compression of frequent patterns. More powerful compres-
sion usually relies on lossy compression using techniques like maximal pattern
mining [11] or clustering-based compression [121]. However, the results of pat-
tern compression are still too large for users to interpret and use them.
Recently, the focus was more on mining k representative patterns for the
whole collection of frequent ones such as top−k most frequent closed patterns
and k− covering set, and k−pattern profiles [121]. As many redundant patterns
generated, the result of top−k patterns are not often representative for the whole
set of patterns. Some studies have been proposed to combine both interestingness
and redundant measures to mine the top−k interesting patterns with very low

2.4. Ontology Learning 47
redundancy. In [60], a number of quality measures have been designated for
finding top−k patterns which regards the redundancy of patterns. Nevertheless,
the challenge issue of mining top−k patterns is how to determine the best value
of k, which is often non-trivial.
2.4 Ontology Learning
The most recent IT approaches suggest the use of systems that allow capture,
structure and retrieval of information through a structured and machine-readable
description of information due to increasing product complexity, globalization,
and visualization requirements. The significance of ontologies is growing in the
fields of knowledge management, information integration, cooperative informa-
tion systems, information retrieval, and electronic commerce [9]. In essence, an
ontology [98, 106] is an explicit specification of concepts and the relationships
between them. It is effective for knowledge sharing and reuse. The following
reviews cover important work of personalized ontology learning, the LCSH world
knowledge base, and the construction of ontology.
2.4.1 Ontology-Based Techniques
Generally speaking, an ontology-based technique is richer, more precise, less am-
biguous than a keyword-based model. It provides an adequate clustering for the
representation of conceptual user interests (e.g. interest for individual instances
such as a sports team, an actor, a stock value) in a hierarchical way, and can be

48 Chapter 2. Literature Review
a key factor to deal with the subtleties of user preferences.
The definition of ontology is a collection of concepts and their interrelation-
ships, which provide an abstract view of an application domain [58,132]. It is an
explicit specification of a conceptualization. Its learning [72] is recognized as a
sub task of information retrieval. The objective is to extract relevant concepts
and relations from a defined corpus or other kinds of data sets to facilitate the
construction of ontologies. One of the main purposes of using ontologies and
data mining technique is to achieve the automatic processes of search, retrieval,
storage, integration, and delivery of information [56].
Over the recent years, researchers have often held the hypothesis that ontology-
based approaches would perform better than the traditional data mining methods
since the ontologies are more discriminative and arguably carry more “semantics”.
As a result, many works were undertaken to take advantage of ontologies for en-
hancing retrieval effectiveness. In 2004, Staab and Studer [102] formally defined
an ontology as a tuple:
(C, R, I, A)
where C denotes a set of concepts; R is a set of relations; I is a set of instances and
A is a set of axioms. Maedche [29, 72] had another definition that differentiates
the relations to hierarchical and plain relations. They also proposed an ontology-
learning framework for the semantic Web. The framework extends typical on-
tology engineering environments by using semi-automatic ontology construction
tools with human intervention, and constructs ontologies adopting the paradigm

2.4. Ontology Learning 49
of balanced cooperative modelling. In Yang and Liu [122] 2009, the application of
ontologies was introduced in order to represent organizational memory metadata.
The kept information refers to the online support of a given client and ontologies
are used to facilitate the search, through information keywords for future use. A
blog has been developed in order to give online customer support. This blog was
a means of facilitating the storage, research, sharing and reuse in companies and
it is also used for its low cost if it is compared to the development of a Web page
defining all the flux required by a client.
Besides, ontology-based technique is also frequently employed to access com-
mon knowledge and to build user profiles. Zhong [132] proposed a learning ap-
proach for task (or domain-specific) ontology, which employs various mining tech-
niques and natural-language understanding methods. Li and Zhong [66] proposed
an automatic ontology learning method, in which a class is called a compound
concept, assembled by primitive classes that are the smallest concepts and cannot
be divided any further. Navigli et al. [79] built an ontology called OntoLearn to
mine the semantic relations among the concepts from Web documents. Gauch
et al. [39] used reference ontology based on the categorization of online portals
and proposed to learn personalized ontology for users. Developed by King et
al. [59], IntelliOnto is built based on the dewey decimal classification system and
attempts to describe the background knowledge. Sieg et al. [98] utilized the onto-
logical user profile on the basis of the user’s interaction with a concept hierarchy
which aims to extract the domain knowledge.

50 Chapter 2. Literature Review
The above ontology learning works cover a constrained number of concepts,
and only use “Is − A” (super-class, or sub-class) relation in the corresponding
backbone of the built ontology. To break through the limitation, the backbone
of the personalized ontology should include more relations to simulate the real
concept model.
More recently, Tao et al. [104] proposed an ontology-based knowledge retrieval
framework, namely ONTO model, to capture user information needs by analysing
general knowledge and local instance repository. However, they disregarded the
vital step of matching and assumed the local information could be ideally referred
to the proper concepts in a global knowledge base.
Of all these related work, the process in [104] seems the most similar to ours
but two differences are: 1) our study adopts relevance feedback as user infor-
mation needs rather than asking users to specify their needs manually, and 2)
provides a sound solution to cope with local information and global knowledge
mismatch.
2.4.2 Concept Mapping
Concept mapping has been formally defined in the domain of ontology engineer-
ing. Its propose is to map a set of concepts into a real (abstract) system view,
which can facilitate sense-making and meaningful learning. People consider use
the mapping for tacit knowledge discovery, ontology merging, semantic enrich-
ment, tag recommendation and et al. The concept mapping is commonly used

2.4. Ontology Learning 51
in scenarios of collaborative ontology learning. For example, the work of Gaines
and Shaw [37] describes a scenario where individual students have to develop con-
cept maps for a specific domain of interest and link them to associated materials.
Peers then assess these maps, modify and enhance them, and provide alternative
versions. While many of the tools and methods developed for concept mapping
might also be applied in the context of ontology development, there are limita-
tions of current approaches. Based on the example, we found that the concept
mapping often is performed as an isolated task, solely focusing on the explication
and negotiation of concepts without being embedded within a purposeful activity.
This might hinder people to see the mediating and dynamic nature of ontologies.
This section also includes the significant work of concept mapping similarity.
The authors expect to determine whether two concepts are relevant while they
occur in a same structure. Some methods were proposed with respect to concept
mapping because the similarity is usually required to specify which two concepts
should be merged.
Kalfoglou and Schorlemmer [54] explored a rational method to measure two
concepts’ similarity in a bidirectional hierarchy. Here, we give a belief explanation
because it is fairly closed to our thought for measuring concepts. The method
first makes sure two concepts C1 and C2, which have the same parent concept
UC(Ci, Hc), are existing in one button up hierarchy. This can be expressed as:
UC(Ci, Hc) := {Cj ∈ C|Hc(Ci, Cj) ∨ Cj = Ci}
Therefore, the similarity between the concepts C1 and C2 can be computed as:

52 Chapter 2. Literature Review
Sim(C1, C2) := |UC(C1,Hc)∩UC(C2,Hc)||UC(C1,Hc)∪UC(C2,Hc)|
Giunchiglia et al. [40] conducted a matching experiment between two large
scale knowledge organization systems (NALT & LCSH) to find significant cor-
respondences. They aim to test a prototype of a concept-based system after
applying their minimal mapping method. However, their work suffers from infor-
mation mismatch caused by the nature of bag of words. Around 50% concepts
are not presented in background knowledge. Wang et al. [114] proposed a method
using extracted features from training documents to represent documents, and
then map concepts in a concept hierarchy. They aim to solve drawbacks suffered
by text classification and feature selection algorithms. However, the method pro-
duces too many terms as candidates to represent training documents (e.g. 7,634
terms for 200 documents). In fact, only a small number of total features may be
heavily relevant, whereas using all the features may affect performance. Naphade
et al. [77] introduced a query to concept matching approach. The approach finds
appropriate concepts with right balance of specificity and generality in WordNet
to matches queries, which aims to break down the semantic space using a small
number of concepts. However, this approach does not provide a scientific evalu-
ation. More importantly, the matched concepts need to be manually judged by
human beings. All the related works discussed first apply the cosine similarity
theory to measure the relevance of two concepts but did not consider applying
relevance features discovered from data mining techniques.

2.4. Ontology Learning 53
2.4.3 Semantic Relations
Semantic relations are an important element in the construction of ontologies and
models of problem domains. The semantic relations of “Is−A” (generalization-
specialization), “Part−Of” (whole-part/aggregation), and “Related− To” (an
association among otherwise unrelated classes) were specified by [104] for a per-
sonalized ontology. In order to enrich the expressive capacity for the new concept
generated within the ontology instead of the previous expressions, Tao et al. [104]
purposed an approach to use specific semantic relations of “Is−A”, “PartOf”,
and “RelatedTo”. It also facilitates the construction to simulate the user’s con-
cept model in response to the user personalized ontologies. The “Is−A” relation
is a direct relation in which one subject is in different from another subject. Its
properties are transitivity and asymmetry. The “PartOf “ relation is a direct
relation used to describe the relationship held by a compound subject class and
its component class. Its properties are transitivity and asymmetry as well. The
“RelatedTo” relation is a non-taxonomic relation describing the relationship held
by two subjects that overlap in their semantic spaces. Its property is symmetry.
Figure 2.3 produced by Tao et al. [104] provides a precise overview of defined
semantic relations:

54 Chapter 2. Literature Review
Figure 2.3: The constructed ontology with the proposed semantic relations
2.4.4 Specificity and Exhaustivity Ontology Mining
For ontology mining, Tao et al. [105] raised an innovative method with two di-
mensions ontology mining, called Specificity and Exhaustivity. This method is
important to our research because it is proposed to achieve the zoomable effect.
Specificity describes the focus of a semantic subject’s meaning on a given topic,
whereas the extent of the semantic meaning covered by a subject corresponding
to the topic is restricted by Exhaustivity. This method [105] aims to analyse the
semantic relations held by the subjects existing in the ontology referring to a
topic, and the following Figure 2.4 is used for illustration:
Taking the topic of sports for an example, Figure 2.4 can help to explain
the internal relationships between the two dimensions. The extent of sports
involves soccer, whereas the US and UK soccer teams both belong to the field

2.4. Ontology Learning 55
Figure 2.4: The concept of Specificity and Exhaustivity
of soccer. Therefore, if the value of Exhaustivity is increasing, the preliminary
extent will become more general. On the other hand, Specificity has the inverse
function of Exhaustivity. With the increased Specificity value, the extent of the
topic will be more focused and specific. The idea is similar to the application
Google map (while zooming in, the location becomes more specific in the map,
the location would inversely be general once zooming out). It can be also referred
to the generalization-based data mining model [45]. The model constructs a set of
sophisticated generalization operators for generalization of complex data objects.
2.4.5 Knowledge Base: LCSH and its Subject Headings
LCSH comprise a thesaurus of subject headings covering subjects or topics in
world knowledge, and are applied to every information item within a library’s
collection. The LCSH classification facilitates a user’s access to items in the
library catalogue that pertain to similar subject matter, and can improve the
efficiency and efficacy of retrieving a useful information item from a library col-
lection [18]. Work on creating LCSH list was started from 1898, and the first

56 Chapter 2. Literature Review
edition was published in 1909. The latest edition (27th) was published in June,
2004, which is also the selected edition using for our research. It has over 270,000
usable headings, and over 490,000 headings that are used for cross referencing.
It had 7,200 new terms added to the lists. Originally, LCSH was designed as
a controlled vocabulary for representing the subject and form of the books and
serials in the Library of Congress (LC)∗ collection, with the purpose of provid-
ing subject access points to the bibliographic records contained in the Library
of Congress catalogues. As an increasing number of other libraries have adopted
the LCSH system, it has become a tool for subject indexing of library catalogues
in general. In recent years, it has also been used as a tool in a number of online
bibliographic databases outside of the LC.
With regard to LCSH specifically, library experts keep arguing its stability
and consistency over four decades. A basic question is whether a new controlled
vocabulary more suited to the requirements of electronic resources should be con-
structed [19]. Some authoritative subcommittee thought over and examined the
options, such as developing a new vocabulary and adopting more existing vo-
cabulary. The second is recommended, which means the use of LCSH normally
with modifications for a general controlled vocabulary covering all subjects. How-
ever, LCSH is still widely used for diverse research purposes. Some of the main
reasons [18] are:
• LCSH is a rich vocabulary using headings to cover all subjects areas , easily
∗http://www.loc.gov/index.html

2.4. Ontology Learning 57
for large general indexing vocabulary in English. It is a pre-coordinate
system that ensures precision in retrieval. More specified subjects can make
the classification more appropriate to present world knowledge.
• To indicate the subject’s relationship precisely, LCSH contains rich semantic
relations among terms.
Whilst we finished investigating and comparing with other library classification
(Library of Congress Classification, Dewey Decimal Classification), LCSH is more
than suitable for our research purposes. It provides the perfect elements for learn-
ing an ontology: the hierarchical system can provide a taxonomic backbone, and
the summarized information items can provide an expert specified information
set [8,71]. Taxonomic backbone refers to the hierarchical structure of the classes
forming an ontology. An ontology based on a taxonomic backbone formed by
subject headings.
Subject headings are a type of controlled vocabulary that is used to make
prediction of searching by using a single term to describe a subject [19]. For
example, the American Revolutionary War can be described using the following
association terms [75]:

58 Chapter 2. Literature Review
American Revolution
American Revolutionary War
Revolution, American
Revolutionary War, American
War of the American Revolution
American War of Independence
War of American Independence
War of Independence
By using a controlled vocabulary, all materials about the American Revolutionary
War are listed under one heading in LCSH:
United States – History – Revolution, 1775-1783
It also creates consistent subdivisions:
United States – History – Revolution, 1775-1783 – Battlefields
United States – History – Civil War, 1861-1865 – Battlefields
World War, 1914-1918 – Battlefields
Using a standardized controlled vocabulary allows searches to be done quickly and
with more accuracy. Also, since most library’s use the same controlled vocabulary
in their catalogs, only one vocabulary style needs to be learned.
In the LCSH, the types of subject heading are grouped by the number of words
that comprise the heading, and also by word order [17]. The following table 2.2 is
from the related works that can help to understand the type of subject headings:

2.4. Ontology Learning 59
Heading type Exampleone-word Animalstwo-word Domestic animalstwo-word, inverted Animals, Fossil
Animals–MortalityAdaptation (Biology)
three+ wordsAND express relationship Computers and college studentsAND combine similar headings Educational tests and measurementsPrep. phrases normal word order Education of princes in literaturePrep. phrases inverted Plants–Effect of pesticides on
Table 2.2: Types of subject headings
Most names (personal, corporate, events, etc.) are not listed in the LCSH. Geo-
graphical names are traditionally inverted to keep the generic terms from being
the main focus [75].
2.4.6 Ontology Construction Language
In order to know how to create a domain ontology, this section introduces a wide
range of knowledge regarding the fundamental ontology languages. At present,
the Web is primarily composed of documents written in semi-structured formats
like HTML (Hyper Text Markup Language) and XML (Extensible Markup Lan-
guage). HTML and XML are useful for visual
The next generation of the Web will combine existing Web technologies with
knowledge representation formalisms [42]. In terms of this statement, we can re-
alize that the information on the Web is not only defined for display purposes, but
also for enhancing the interoperability and integration between systems and appli-
cations. Various new approaches and principles regrading data structure, inter-

60 Chapter 2. Literature Review
operation between learning concepts, and domain modeling in terms of XML,
Resource Description Framework (RDF), and OWL have been developed and im-
plemented due to the progress of semantic Web. The semantic Web is the suitable
method to address the mentioned issues, because it contains the function to ex-
press the explicit meanings for interpretation. Another crucial element required
for the semantic Web is the Web ontology language (OWL), which a popular
World Wide Web Consortium (W3C)† ontology language standard. OWL can
formally describe the semantics of classes, properties and instances in a logic lan-
guage, so that detailed, accurate, consistent, sound, and meaningful ontologies
can be made in a logic language [6]. Therefore, a precise objective of the semantic
Web can be described as making possible the processing of Web information by
computers. Berners-Lee et al. [14] defined that
The Semantic Web is not a separate Web but an extension of the
current one, in which information is given well-defined meaning, better
enabling computer and people to work in cooperation.
For our research, we need to clearly identify the relations between classes and sub-
classes of the specific personalized ontology. A number of the specified relations
are expected to be presented, including the relations of “is-a”, “part-of”, and
“related-to”. In the semantic Web, ontologies play a key role in the consensual
and formal conceptualizations of domains, enabling knowledge sharing and reuse.
In contrast, the semantic Web has sufficient expressions to represent the logic
†http://www.w3.org/

2.4. Ontology Learning 61
relations of the ontologies [81]. In particular, OWL, which is in the family of the
semantic Web released by W3C (World Wide Web Consortium) in 2004, is de-
signed for describing ontologies by application [12]. As we mentioned previously,
the purposes of OWL are not only to present information to human, but also to
process the content of information in computers. The following section analyzes
completely why we adopt OWL as our proposed ontology description language af-
ter comparing it with XML and RDF (Resource Description Framework)/RDFS
(Resource Description Framework Schema).
The aims of this section are: 1) to outline the reasons why the proposed
research adopts OWL to describe the specified ontologies, 2) to compare the
expressive capability with XML and RDF, 3) to understate a range of constructors
and axioms of OWL, and 4) to discuss some related works have been done with
OWL for further study. Some relevant knowledge is also covered in this section
to make sense of construction of OWL.
Resource Description Framework Schema
RDF [74] is a defined language of W3C for describing resources, such as Web
pages. It can be used to make simple assertions about web resources or any other
entity that can be named [81]. A simple assertion is a statement that an entity has
a property with a specific value. For example, a university has an abbreviation
property with the value “QUT”. Due to this limitation, RDF is only used to
present the resources or portion of content in ontology. It is a well-defined syntax

62 Chapter 2. Literature Review
based on DAML+OIL, and some of syntax was extended to RDF Schema (RDFS)
and OWL. Along with the extensions of RDF, RDFS has adequate property and
class, which enables it to build up simple ontologies hierarchically. The main
constructors of RDF Schema are presented in Table 2.3:
Classes and
subclassesrdfs: Class
rdfs: subClassOf
Property rdfs: Domaindeclares the class of the subject in a triple using
this property as predicate
rdfs: rangedeclares the class or datatype of the object in a
triple using this property as predicate
Utility
Propertiesrdfs: seeAlso
indicate a resource that might provide additional
information about the subject resource
rdfs: isDefineBy indicate a resource defining the subject resource
Others rdfs: label
rdfs: comment
rdfs: Literal the class of literal values
rdfs: Datetype the class of datatypes
Table 2.3: RDF schema constructors
The bold contents in this table are need to be acknowledged before using OWL
since there are two properties in OWL, one is object property, the other is data
property. The way to define property in RDF is extremely different from OWL.
Both object property and data property will be discussed in detail later in this
review.
There is another major reason why we do not use RDF in our proposed re-
search. Various limitations of the expressive power are discovered in RDF Schema,
which Antoniou and Van Harmelen [6] outlined, are listed below. In terms of our

2.4. Ontology Learning 63
project, OWL is used to address these limitations gradually:
• Local scope of properties: e.g. cows eat only plants
• Disjointness of classes: e.g. Female is subclass of person
• Boolean combinations of classes: e.g. class person to be the disjoint union
of the classes male and female
• Cardinality restrictions: e.g. exactly, at least
• Special characteristics of properties: e.g. transitive(“greater than”), unique(“is
mother of”) or the inverse of another property(“eats” and “is eaten by”)
As we mentioned in the previous section, OWL is an extension of RDF/RDFS
based on the same syntax and semantic representations. The majority of their
constructions, applications, and implementations are similar. However, OWL is
more powerful on the expressive capability, because it has two kinds of proper-
ties for describing ontologies. This can provide an effective way to present the
ambiguous meanings precisely within ontologies. Firstly, object properties which
relate objects to other objects are able to describe the general logic conceptu-
alization. For example, a student is taught by her/his teacher. There are two
objects in this statement, one is student, and the other is teacher. The relation
or say property is “isTaughtBy”. Secondly, data properties which relate object
datatype values are some values from the objects themselves. For example, a
person has name, age, and gender. The values of them are the data properties of

64 Chapter 2. Literature Review
the object “person”. In this case, through defining various properties based on
these two types, the ontologies can be represented more accurately and precisely.
After detecting the Figure 2.5, the differences between RDF/RDFS and OWL
can be discovered:
Figure 2.5: Subclass relationships between OWL and RDF/RDFS [6]
Web Ontology Language
Baader et al. [9] argued that, without basic research in Description Logics (DLs)
over the last decade, the KR languages could not have played such an important
role in the field of ontology. Because of this, this part of the review treats the
description logics as a preliminary and fundamental aspect before starting to
study OWL. DLs can be used to represent the knowledge of an application domain
in a structured and formal way. Its approach is to utilize a range of employed
constructors and various kinds of specified expressions. For instance, if one want
to define the concept of “A female that has married to a professor has at least
two children.” The description logic is presented as below:

2.4. Ontology Learning 65
Human u Female u ∃married.Professor u (> 2hasChild)
Since DLs provide both the availability of a well-defined semantics and pow-
erful reasoning tools, they should be ideal candidates for ontology languages,
including the newly OWL. This reasoning supports them being used to check
the consistencies and intended logic relations of the ontology are based on DLs,
including RACER and FaCT++ [9]. Throughout the whole proposed research,
it is important to keep the basic concepts of the DLs processing with OWL con-
structors in mind.
Many efforts have also been done by W3C to develop an appropriate OWL,
resulting in the OWL as the current standard [6]. It is noted that the OWL is the
extensible vision of RDF. As the current standard of ontology language, OWL
allows users to express explicit, formal conceptualizations of domain models. An-
toniou & Van Harmelen [6] stated that a number of requirements were satisfied
by OWL, which is listed as follows:
• A well-defined syntax
• A well-defined semantics
• Efficient reasoning support
• Sufficient expressive power
• Convenience of expression
These satisfied requirements demonstrate the outperformed capability and the
benefits of using OWL. The importance of a well-defined syntax is clear, because

66 Chapter 2. Literature Review
this is the precondition for machine-processing of information. OWL is based on
DAML+OIL syntax that is the same syntax of RDF. A well-defined semantics re-
quirement is necessary to describe precisely the meaning of knowledge. Reasoning
support is required by semantics, a number of these supports can be utilized in
OWL, such as RACER and FaCT++. Antoniou & Van Harmelen [6] stated that
the aims of these supports are to check the consistency of the ontology and the
knowledge, to check the relationships between classes, and to classify instances
automatically in classes.
OWL is classified by W3C’s Web Ontology Working Group to fulfill different
requirements [110]. There are totally three species, which are OWL Full, OWL
DL, and OWL Lite respectively. OWL Full is the entire language, and uses all
the OWL language primitives. OWL DL is a sub language of OWL Full, but it
restricts the way in which the constructors from OWL and RDF can be used. The
advantage is that it permits efficient reasoning support. In this case, the specie
of OWL DL enables us to accomplish our proposed research. OWL Lite is a sub
language of OWL DL. Its restrictions are more than OWL DL. However, this one
is easier to implement. The detailed comparisons among these three species are
outlined by Table 2.4:
This section covers many fundamental knowledge about OWL. At the begin-
ning of this section, the review summarizes the context of OWL development
in the semantic Web. Then, as other existing Web resource description lan-

2.5. Summary 67
OWL Full OWL DLOWL
Lite
High Medium Low
Expressive
power
Uses all the OWL languages
primitives. It also allows the
combination of these
primitives in arbitrary ways
with RDF and RDF Schema.
Essentially application of OWL’s
constructor’s to each other is
disallowed, thus ensuring that the
language corresponds to a well
studied description logic.
Reasoning
supportLow Medium
Upward
compatibility
with RDF
Any legal RDF document is
also a legal OWL Full
document; Any valid
RDF/RDF Schema conclusion
is also a valid OWL Full
conclusion.
An RDF document will in general
have to be extended in some ways
and restricted in others. Before it
is a legal OWL DL document.
Every legal OWL DL document is
a legal RDF document.
Table 2.4: Comparison between three species of OWL
guages, XML and RDF/RDFS are analyzed critically. The objective is to find
out which language is suitable for representing personalized ontologies in our re-
search. Through the comprehensive and systematic comparisons, OWL is demon-
strated to be the most appropriate ontology language for this research. At last,
general knowledge of OWL is concluded completely, including language syntax,
description logics, constructors, reasoning supports, three types of specie (OWL
Full, OWL DL, and OWL Lite).
2.5 Summary
This chapter presented several key issues of the conducted literature review. The
literature review introduced the basic techniques of current information retrieval
models. The challenges of information mismatch and overload remained unsolved

68 Chapter 2. Literature Review
by current works. The literature review also pointed out that the key to gather
meaningful and useful information for Web users is to improve the Web informa-
tion gathering techniques from keyword-based to concept-based.
The literature review in this chapter also noted the issues in Web person-
alization, focusing on user profiling, feedback, and user information needs in
personalised Web information gathering. The related work confirmed that the
concept-based models using both user local instances and background knowledge
can help gather useful and meaningful information. However, the representation
and acquisition of user profiles need to be improved along with the effectiveness
of user information need capture.
The literature review presented the essential process and tasks of data mining,
especially the related methods and association rules to mine diverse patterns in
text mining.
Since the significance of ontologies is raising in the fields of IR and data min-
ing community, the literature review covered ontology-based techniques, ontology
learning, and semantic relations. The literature review indicated that ontologies
can provide a basis for the match of user information needs and the existing
concepts and relations. This helps to acquire conceptual user profiles. User back-
ground knowledge can be specified by using personalised ontologies. However, the
existing ontologies and ontology learning methods have limitations and need to
be solved by a matching approach for global concepts and local information. At
last, the OWL was been indicated as the best candidate to encode the ontologies

2.5. Summary 69
and fully described.

70 Chapter 2. Literature Review

Chapter 3
Ontology-Based Technique for
Search Intent Mining
This chapter presents an ontology-based approach to discover user search inten-
tions. We first hold the hypothesis that a user search intent should exist some-
where in an ontology. It is severed as user’s information need and is represented by
a specific range of knowledge, which can be discovered via a reasonable method.
In order to avoid extra burdens on the user, we attempt to minimize user involve-
ment so that only a query is required as the input for the proposed approach.
Then, a novel ontology-based mining approach is introduced to extract person-
alized ontologies by identifying adequate concept levels for potential user search
intentions. An iterative mining algorithm is designed for evaluating potential in-
71

72 Chapter 3. Ontology-Based Technique for Search Intent Mining
tents level by level until meeting the best result. Finally, the propose-to-attempt
approach is evaluated in a large volume RCV1 data set, and experimental re-
sults indicate a distinct improvement in top precision after comparison baseline
models.
3.1 Background and Overview of the Approach
For an effective search engine, the retrieval of the desired information for the
user is the primary objective and finding the optimal method for the informa-
tion retrieval has motivated researchers for many years. To improve the existing
search capabilities, a series of advanced algorithms and processes along, with the
solid experimental supports, have been developed [29]. Generally speaking, re-
searchers have directed their attention to the techniques associated with indexing,
matching, and re-ranking procedures [55]. The related contributions are helpful
and useful for enhancing search effectivenesses. However, a significant issue -
ambiguity [65] [68] continues to hinder the discovery of user search intentions.
User search intent is a significant aspect of the user’s motivation to obtain use-
ful information. No doubt it is a crucial expression of user information needs [97].
In terms of recent investigations [104,106,134], Web search intentions can be stud-
ied in two aspects, namely, the specificity and exhaustivity intent. Specificity de-
scribes the focusing extent of the topic, that is the user’s interests have a narrow
and focusing goal; whereas exhaustivity describes a different extent of the topic,
that is the user’s interests have a general/wider scope. However, a hard problem

3.1. Background and Overview of the Approach 73
is how to discover precise user intentions. Is there a feasible approach to main-
taining the two-dimensional intents above? An existing method is quantification,
that is using the relevance weight of a pattern [134]. Another possible solution
is to discover and characterize search intents in a concept hierarchy. Dakka and
Ipeirotis [28] evaluated a system to extract facets from documents, and then pop-
ulate into a hierarchy. In the faceted search, items are first classified into one
or many groups named facets (same as concepts of us), and the user may nar-
row or expand her/his search intent using those facets. The clustering algorithm
uses external online encyclopedias sources of knowledge to identify significant
words/phrases, which can enrich the clustering quality. Moreover, Fontoura et
al. [34] introduced a model of query relaxation along multiple hierarchical tax-
onomies. The authors focus on classifying documents into taxonomy nodes (we
name concepts) and employing the scoring function to implement the matching
work in practice. The related works indicate that the diverse hierarchies are
useful to locate user interesting items.
Similar idea to the closed works, our task is to propose a framework for re-
laxing user search intents over ontologies. The ontologies are more semantic that
that of taxonomies, and are entirely defined by the information need. A number
of levels are partitioned for storing different types of concepts. This information
might be related to other levels by tracking ontological references in a common
knowledge base. The user search intents are assumed in each of the levels. The
higher the level in the hierarchy, the broader extent it has. Conversely, the extents

74 Chapter 3. Ontology-Based Technique for Search Intent Mining
are more specific in the lower levels. The idea is similar to a zooming process.
The proposed approach aims to apply a group of relative concepts to describe
user information need. We believe that interpreting user information needs by a
set of concepts would be more discriminative than a short query.
Figure 3.1: Overview of the ontology-based approach
The general architecture of our ontology-based mining approach is illustrated
in Figure 3.1. To simulate search activities in the real world, users are first
required to translate their implicit search intents into explicit queries. To cope
with the produced queries, a subject-based search model is developed in order
to retrieve matched results from the enormous world knowledge database. The
function of the model is fairly similar to a keyword-based search except the type of
returned results is a list of subject headings in LCSH. For all matched subjects,

3.2. World Knowledge Base 75
a standard pre-processing method is conducted by following the mechanism of
Natural Language Processing (NLP) in IR. The pre-processing mainly consists of
stemming and the removal of stop-words to reduce bias. A particular semantic
extraction method is carried out for all the matched subjects in order to build
personalized ontologies. The reason to build the personalized ontologies is based
on our belief that using just one ontology for all the users is not appropriate,
and that it is better to construct the customized one based on the individual
user’s preferences. After that, all the terms occurring in the subjects are used
to do a query expansion, and then find semantically similar matches rather than
lexically dissimilar results by taking the extracted relations into account. The
related methods for definitions of a world knowledge base, learning a personalized
ontology, and the in-level ontology mining method are each explained in the
following subsections. Eventually, an objective experiment is designed to evaluate
the approach in the standard RCV1 testing set. A number of comparisons are
also made to highlight the precision improvement of search results.
3.2 World Knowledge Base
Understanding a user’s background information is significant for the retrieval
of accurate and personalized search results. Many research efforts have been
spent for gathering and analysing this information. However, current techniques
designed to address the issue are time-consuming and cumbersome, such as user
profiling and relevance feedback. In this section, an alternative is to simplify this

76 Chapter 3. Ontology-Based Technique for Search Intent Mining
process by taking advantage of a comprehensive world knowledge base. World
knowledge is the common-sense knowledge acquired by people based on their
experience and education. It can be considered as an exhaustive repository to
maintain the known knowledge by human beings [27, 127]. Based on a variety
of types of knowledge, we classify all the world knowledge into three categories:
inherent knowledge, implicit knowledge, and explicit knowledge. These specified
relationships among these knowledge types can be observed from Figure 3.2. In
the circle, the implicit knowledge is treated as the user background knowledge
of our proposed approach, which can be acquired through a particular mining
method as later described.
Figure 3.2: Knowledge classification
As illustrated in the diagram, different types of knowledge can be converted
though specified processes. The proposed approach is similar to the process of
inherent knowledge - implicit knowledge - explicit knowledge. Inherent knowl-
edge starts from the world knowledge side. Here, a universal ontology named the
Library of Congress Subject Headings (LCSH), is adopted to store and arrange
the world knowledge in a taxonomic and systematic structure. In addition to
the LCSH ontology, existing universal ontologies have different characteristics to
satisfy individual criteria. Tao et al. in 2007 [104, 105] provided a general com-
parison of the major world knowledge taxonomies applied in previous studies.

3.2. World Knowledge Base 77
Based on their comparative results, the LCSH is determined to be an ideal world
knowledge representation or said the world knowledge base, because it is a rich
vocabulary using headings to cover all subject areas. It indicates the subject’s
relationship precisely and contains more semantic relations among the terms. In
the LCSH, subject headings are basic semantic units for conveying domain knowl-
edge and concepts. They have four main types of references: broader term (BT),
narrower term (NT), used-for Term (UF), and related term (RT). A BT is a
hypernym that is a more general term, for example, “pressure” is a generaliza-
tion of “blood pressure”; a NT is a hyponym that is a more specific term, for
example, “economic crisis” is a specialization of “crisis”. These two references
are used in our model to indicate the is− a relation among subjects in the world
knowledge base. To facilitate the in-level ontology construction later in this ap-
proach, the references are redefined to ancestor and descendant lexical relations,
respectively. ancestor refers to the concept of BT, and descendant refers to NT.
More information about these terms can be found in Table 3.1. All the subjects
are formalized as:
Type Paraphrase ExampleAncestor is the general term for “profession is the general term for scientist”
=⇒ Ancestor(profession, scientist)Descendant is-a “scientist is a profession”
=⇒ Descendant(scientist, profession)
Table 3.1: Examples for redefined relations
Definition 1 (Subject): Let S denote a set of subject headings in LCSH, a
subject s ∈ S is formalized a triple (label, ancestor, descendant), where

78 Chapter 3. Ontology-Based Technique for Search Intent Mining
• label is the heading of s in LCSH thesaurus;
• accestor is a function regarding the subjects that are more general and
located a higher level than s in the world knowledge base;
• descendant is a function regarding the subjects that are more specific and
located a lower level than s in the world knowledge base.
Definition 2 (is− a relation): An is− a semantic relation is formally repre-
sented in the LCSH by the reciprocal references accestor and descendant, which
provides a hierarchic parent-child relationship between two subjects.
Definition 3 (Attribute): Let Pij be the binary predicate, “i is-a j”, hence
we can define the following axioms on P :
• Reflexivity: Pxx;
• Transitivity: Pxy ∧ Pyz ⇒ Pxz;
• Anti-symmetry: Pxy ∧ Pyx ⇒ x = y.
The anti-symmetry implies that said the is−a relation is unidirectional. The
transitivity axiom in Definition 3 is crucial in acknowledging that the part− of
(referred to UF terms before) relation is also hierarchic in nature. Note that
is − a and part − of are similar insofar as they both “involve membership of
individuals in a larger set”, however, “meronymic relationships...are determined
on the basis of characteristics that are extrinsic to the individual members them-
selves”, whereas parent-child relationships are “determined by similarity to other

3.3. Personalized Ontology Learning 79
members based on intrinsic characteristics” [112]. At this stage, there is only one
relation r = (is − a) considered by our approach and the world knowledge base
can be formalized as:
Definition 4 (World Knowledge Base): A world knowledge base ontology is
a directed acyclic graph structure defined as a pair Θ := (S, r), consisting of
• S is a set of subjects in LCSH S = {s1, s2, ..., sn};
• r is the semantic relation r = (is− a) existing among the subjects in S;
3.3 Personalized Ontology Learning
3.3.1 Subject-Based Model
As seen in Figure 3.1, a subject-based search model is developed by the JAVA
programming language to serve the preliminary study. The purpose of this model
is to retrieve relevant subjects and prune irrelevant subjects. When a user en-
ters a query, the model is exactly a mimic of the term-based model that is good
at returning the overlapping subjects to the query. A collection of the LCSH
library from QUT in 2006 is specified as the database for the model. It is im-
portant to be aware that both exactly matched subjects (e.g. subjecti = {t1, t2},
query = {t1, t2}, then subjecti = query) and partially overlapping subjects (e.g.
subjectj = {t2, t3}, subjectj∩query 6= ∅) would be returned simultaneously. This
is because both “AND” and “OR” operators are employed while executing the
model. This process might occur the redundancy issue due to a large amount

80 Chapter 3. Ontology-Based Technique for Search Intent Mining
of overlapping subjects. However, from the IR prospective, it can extend the
scope to cover potential user intents with correlative information. To illustrate
the subject-based model, Figure 3.3 provides a screenshot of the model.
Figure 3.3: The screenshot of subject-based Model
As shown in the figure, we can easily observe that all the matched subjects and
their corresponding semantic relations are displayed on the screen. In the right
corner, a clear number indicates how many satisfactory subjects are gathered
from the database. Along with the subjects, there might exist various semantics
that can be utilized to point out the correlations with other subjects in the LCSH
database. To recognize the special representation of the embedded semantics, a
suitable method is designed for extraction and future uses.
3.3.2 Semantic Extraction
Extracting semantic relations is a preliminary step before constructing a domain
ontology. Without the extraction, it is difficult to understand the logical rela-
tions among subjects or other instances [14]. It is also important to convert

3.3. Personalized Ontology Learning 81
information in such a way that it is readable and perspicuous by both humans
and computers [58]. This section presents an overview of the method to obtain
the desired semantics and to deal with their unique and original representations
defined by the LCSH database.
The extraction occurs only a subject having the is − a relation as redefined
at Section 3.2 . All the references of ancestor and descendent will be taken into
account for ontology learning since the is−a relation is based on these references.
For each subject, the assigned unique ID is used to search and its references are
basically stored by a string format in the LCSH database, like the example in
Figure 3.4. Except the ancestor references, the subject “economic espionage”
has no other references.
1: Total matched subject(s): 1593
2: User selected: Economic Espionage
3: Ancestors: T19[T18087[T115130[T81991[T69623[T64842[T98712,],],],],],T102353,],
4: Descendants:
5: UsedFor:
6: RelatedTo:
Figure 3.4: The extracted semantic relations
All the references specified in the world knowledge base are beneficial in our
approach to acquire a set of new subjects in other levels. All the levels are defined
as two directions: one is upper, and the other is lower. The pilot level is selected
as a benchmark in the hierarchy. When nodes appear in a higher level than the
pilot, they are located in upper levels. In contrast, nodes are in lower levels if they

82 Chapter 3. Ontology-Based Technique for Search Intent Mining
appear lower than the pilot. Some subjects might just occur one time in the pilot
because there are no semantic relations. Meanwhile, some of them might merely
have related subjects either in upper or lower levels due to they just hold one
type of reference (ancestor or descendant). However, except the subjects in the
pilot, all the subjects in other levels would definitely have at least one semantic
relation. Taking Figure 3.5 for example, “economic espionage” is a subject in the
pilot level. It has three accestor references, but no descendant. In this case, the
subject can only return three more general subjects in the upper level. Later on
other subjects can be found in the upper levels based on references from these
three subjects.
Figure 3.5: A Segment of the Subject Headings
3.3.3 In-Level Ontology Mining Method
The concept hierarchy is an essential subtask of ontology learning [90]. In the-
ory, it is a prerequisite hierarchy where an amount of nodes represent concepts

3.3. Personalized Ontology Learning 83
in a domain, and related links served as prerequisite relationships. For this ap-
proach, we create a special hierarchy format to satisfy our research purposes. The
hierarchical backbone is drawn as Figure 3.6. The step is similar as the knowl-
edge diagram depicted in Figure 3.2, which is to mine the implicit knowledge
for the explicit knowledge. One of the objectives is to take advantage of this
hierarchy to structure information into categories, thus enhancing the effective-
ness and reusability of the subject-based search model. In addition, to acquire
implicit knowledge by tracking internal relationships among concepts is another
objective. Since we believe user search intentions are somewhere in the world
knowledge base, the concept hierarchy is pre-defined into several abstract levels.
The gathered implicit knowledge will be used to estimate whether the user search
intention appears in a certain level.
Figure 3.6: The backbone of in-levels hierarchy
At the beginning, the matched results are a set of subjects that can be re-

84 Chapter 3. Ontology-Based Technique for Search Intent Mining
trieved after implementing the subject-based search model. Each of the subjects
is realized as a concept here, which is represented by a single node in Figure 3.6.
To learn a personalized ontology, a domain’s scope needs to be confirmed by tak-
ing these subjects into account because all the subjects within this domain are
identified to discuss the correlative information regarding a entered topic. They
are all in the same abstract level, originally defined as the “pilot level”. Initially,
a formalized definition for the domain is provided as:
Definition 5 (Domain for a Level): Let Ci denote a set of subjects Ci :=
{s1, s2, ..., sh} in a level li. We define its domain by dom(l)i := dom(s1)∪dom(s2)∪
... ∪ dom(sh), where dom(sh) are all the terms involved into the subject sh.
Dashed circulars in Figure 3.6 are utilized to indicate the domains of different
levels. With respect to the ontology learning, we also formalize:
Definition 6 (Personalized Ontology): the personalized ontology for a topic
in a 4-tuple Θp := (C, L,DOM, e), where
• C is a super set of C including all subjects in levels C = {s1, s2, ...sh};
• L is a set of levels consisting of a domain and subjects L = {l1, l2, ..., li},
l1 ⊇ sh;
• DOM contains DOM := (dom(l1), dom(l2), ..., dom(le));
• e is the number of levels.
The major in-levels concept is also related to a knowledge generalization pro-
cess [44]. In our thinking, a subject in an upper level covers more general knowl-

3.3. Personalized Ontology Learning 85
edge than a subject in the lower one. For instance, in Figure 3.5, “economic
espionage” is in a lower level, and it has a “is − a” semantic relation associ-
ated with the subject “business ethics” is the upper level. “business ethics” is a
broader knowledge that covers the knowledge of “economic espionage”, and can
be presented in a statement of “economic espionage is a business ethics”. In other
words, the knowledge in a level can be summarized by the knowledge in the next
upper level. Eventually, all the knowledge in the world knowledge base will be
summarized in philosophy. This is a main reason why the domains of the upper
levels are getting smaller when moving towards to the peak of the backbone in
Figure 3.6, which looks like the shape of a cone. However, the question arises
about why this happens the same why in the lower levels. From the perspective
of IR, the subject-based search model uses to return specific subjects based on
keywords. The majority of the subjects lack the semantic relations to be associ-
ated with the more specific knowledge. As a result, the number of subjects in the
lower levels is decreasing as well as their domains. Therefore, the shape becomes
an inverse cone. It is noted that the backbone structure is not a formal tree, and
a node can have more than one parent or child.
Before proving the discussed hypothesis, an iterative ontology mining method
is proposed in this section. It starts from the pilot level, and then builds a
personalized ontology (the backbone of the in-level hierarchy) in order to find a
suitable level for the search intent. The building process simply uses the is − a
relation to find all the parents for an upper level or to get all the children for

86 Chapter 3. Ontology-Based Technique for Search Intent Mining
a lower level. For precise understanding, a study example is separated into two
phases to explain the method in detail. Each phase involves several steps.
Using feature for level representation
There are two main objectives: 1) to decide subjects and weights for the pilot
level lρ; and 2) to represent it as a query Qρ.
Firstly, a number of matched subjects are retrieved for the pilot level lρ after
implementing the subject-based search model. Then, a weight is calculated for
all the subjects s ∈ Cρ by using the following formula:
weight(s) = |q∩s||s|
where |q ∩ s| denotes the term that appeared in both query q and subject s, |s|
denotes the total number of terms in the subjects. Therefore, a set of subject
weight pairs is obtained S(w) = {< s1, w1 >,< s2, w2 >, ..., < sn, wn >};
Secondly, the query is expanded to a set of terms by union of all the terms
from the submitted query and matched subjects, and letting Qρ = {t1, t2, ..., tm}.
For example, the submitted query is query = {t1, t2}, and the other subjects
are s1 = {t1, t2}, s2 = {t1, t2, t6}, and s3 = {t1, t2, t5, t8}. After that, Qρ =
query ∪ s1 ∪ s2 ∪ s3 = {t1, t2, t5, t6, t8};
Thirdly, term weight pairs are calculated for all terms t ∈ Qρ via using the
following formula:
weight(t) =∑
t∈s,s∈Cρ
weight(s)|s|

3.3. Personalized Ontology Learning 87
Then, we receive a set of term weight pairs as a feature Fρ = {< t1, w1 >,<
t2, w2 >, ..., < tm, wm >} to represent this level.
Determining the best level for user search intent
The goal is to determine the suitable level for characterizing the user search intent
according to a training set.
Let Dt stand for a set of documents in the training set (the approach uses
the RCV1 training set), t denotes a certain topic of the documents. All these
documents have been initialized with a value of either 0 or 1 by linguists. These
two values are used for indicating whether a document is relevant to the topic.
0 means the document is irrelevant, whereas 1 means the document is relevant.
We calculate a weight for each document in the training set by using the feature
of a level. Thus, rank Dt by using Algorithm 1 provided as follows:
Algorithm 1 Ranking Algorithm based on a levelInput:
The set of documents Dt in the training set of RCV1;level i.
Output:Sort Dt
1: for each d ∈ Dt do2: //initialize a document d with a weight 0;3: rank(d) = 0;4: for each t ∈ Qi do5: if t ∈ d then6: rank(d) = rank(d) + rank(t);7: end if8: end for9: end for
10: return Sort Dt based on the rank function;

88 Chapter 3. Ontology-Based Technique for Search Intent Mining
Step one, a top-K precision precision(lρ) of the ranked documents based on
the specified values is calculated by applying the formula below:
precision(lρ) =
K∑i=1
f(di)
K
where f(di) = 1 if relevant, otherwise f(di) = 0;
Step two, shift to the upper level lρ+1 in the hierarchy. Thereby, a new set of
subjects in lρ+1 is returned by getting all subjects s that have a is−a relationship
with any subjects in the pilot level lρ. Repeat the same step in Phase 1 to rank
the documents Dt+1 by using the feature Fρ+1 for level lρ+1, and then calculate
the top-K precision on precision(lρ+1);
In the last step, make a comparison of the top K precision in the pilot level
precision(lρ) and the upper level precision(lρ+1). If precision(lρ) > precision(lρ+1),
return lρ as a level of search intents. Otherwise, go to step two and implement
the same procedure in lρ+2 again.
Phase 2 is kept looping for upper levels until the satisfactory level is met based
on precision performance. The entire process is presented in Algorithm 2, where
parameter µ is used to control the distance between the selected level li with the
pilot level lρ. If a level is too far away from the pilot level, we assume that it is less
significant to search intentions. Hence, we set the parameter here as a threshold
to prove our assumption. To save space, the approach omits the explanation for
the lower levels because its algorithm is quite similar to Algorithm 2.
According to the two phases outlined above, we are able to gain a level with
the best top-K precision among all the hierarchical levels. This level is considered

3.4. Summary 89
Algorithm 2 for Phase 2 (consider go to upper levels only)
Input:The set of documents Dt in the training set of RCV1;Parameter µ.
Output:A level of search intents
1: Let j = ρ, i = j;2: i = i+ 1; //Shift to the upper level;3: Get Qi and Fi;4: Use Fi to rank Dt;5: if precision(li) < precision(lj) then6: return j;7: else8: if i− ρ > µ then9: return i
10: end if11: end if12: j = i;13: Go to 2;
as the output of user search intents from our proposed approach.
Through taking the approach above, a personalized ontology can be gathered
successfully in terms of the definition specified in 3.3.3. A set of concepts is
obtained from the global LCSH ontology. The concepts have been partitioned
by a clear domain and the abstract level. As the level selection is based on
the precision measurement, the completed personalized ontology is expected to
enhance the top-k performance in retrieval evaluation.
3.4 Summary
In this chapter, a novel ontology-based mining approach is introduced for the
discovery of user search intents. The discovery is about personalized ontology ex-

90 Chapter 3. Ontology-Based Technique for Search Intent Mining
traction and its purpose is to describe characterized user information needs. The
entire approach is supported by knowledge generalization and representation the-
ories. A two dimensional mining method is first developed based on the theory
of specificity and exhaustivity in search intent. To effectively filter out irrelevant
information, a subject-based search model is encoded and fully functional. It can
also allocate matched results into a world knowledge base, namely the LCSH.
The method to deal with semantic extraction is outlined for ontology learning.
A concept-based hierarchy is built by applying extracted semantic relations from
the world knowledge base, which enable the possible user intents to be charac-
terized in a virtual level. Eventually, the personalized ontology can be obtained
to facilitate the retrieval with the aim to achieve high top-k precision. For the
evaluation, a large RCV1 testing bed is employed for various measurements. A
benchmark and baseline models are carefully decided for comparison.

Chapter 4
Relevance Feature Matching
In Chapter 1, one crucial question was how to reasonably match local informa-
tion with global knowledge. To answer the question, this chapter introduces a
sound approach to match the relevance feature extracted from local documents
to ontological concepts existing in a world knowledge base. The proposed ap-
proach incorporates both pattern mining and ontology learning techniques. In
regard to the mining prospective, the chapter begins by describing the method
of the relevance feature acquisition, and then outlines why the feature is the best
candidate for local information. Regarding the ontology learning, a creative dis-
tributed matching is developed by following the theory of conceptual intension
and extension. It can successfully accomplish two expected tasks. One task is 1)
to ensure that the core feature can be firstly converted into high level concepts,
91

92 Chapter 4. Relevance Feature Matching
and the other task is 2) to obtain potential relevant concepts for the core feature.
The entire approach will help to interpret user information needs by personalized
ontologies. It is extremely significant as those filtering systems aim to achieve
personalization functions through studying user specific information.
4.1 Design and Definitions
Comparing with query-based process, relevance feature-based process is more
complicate and rely on text mining technique. First of all, the relevance features
are mined from a set of user local documents. These documents implicitly reflect
user personal interests and preferences. It is worth to take advantage of the
context among the documents for better understanding and refining user needs.
Figure 4.1 provides an overview of the proposed approach. Local information
is the input and consists of two parts, namely: relevance feedback and a set of
training documents. The relevance feedback is initialized as positive feedback
and negative feedback. The positive feedback indicates the document is relevant
to the user’s interests, whereas the negative feedback indicates the document
is irrelevant. By applying the method discussed in Section 4.2, the extracted
relevance features can be categorized into three groups: positive specific group
(SPE), general group, and positive negative group. Here, our approach only
selects terms in the SPE group as candidates because they contain more topic-
related interests rather than other groups [65], which was demonstrated in the
preliminary study also reported in this chapter (Section 4.3.1). The LCSH, which

4.1. Design and Definitions 93
is a large thesaurus of subject headings, is chosen to be the representation of
global knowledge. Each subject heading denotes a concept in the knowledge
base. Normally, the concept is a short phrase which contains one or several
terms. We match the SPE terms to the subject headings, and the learning process
of personalized ontologies in 3 can eventually take advantage of the matched
concepts and their enclosed relations in the LCSH.
Figure 4.1: Overview of the relevance feature matching approach
The design of the approach can be understood in two separate sections. One is
drawn at the left portion of Figure 4.1. It is based on data mining (more precisely
adopting the pattern mining technique) to obtain local information. The local
information is recognized as a set of terms after deploying a set of patterns existing
in RCV1 training documents. The positive feedback plays an important role for
mining the closed sequential patterns to represent the documents. The other
direction is related to ontology learning. It is talking about concepts, which are
realized the same as the subjects in the LCSH. To build a relationship between
the two directions, a distributed matching is guided by the theory of concept

94 Chapter 4. Relevance Feature Matching
extension and intension to define the coverage of the matched subjects. Once the
matched subjects are confirmed, the major components including the concepts
of the personalized ontologies and their interrelationships can be determined for
construction.
4.1.1 Definitions of Patterns and Closed Patterns
The purpose of relevance feature discovery is to find useful features, including
patterns, terms and their weights, in a training set D, which consists of a set of
positive documents, D+, and a set of negative documents, D−. In this study, we
assume that all documents are split into paragraphs, so a given document d yields
a set of paragraphs PS(d). To clearly understand the concepts of patterns, we in-
troduce normal patterns and closed patterns first, and then we discuss sequential
closed patterns. These definitions can be found in [118] or [67].
Let T = {t1, t2, . . . , tm} be a set of terms which are extracted from D+. Given
a termset X, a set of terms, in document d, coverset(X) = {dp|dp ∈ PS(d), X ⊆
dp}. Its absolute support
supa(X) = |coverset(X)|;
and its relative support
supr(X) =|coverset(X)||PS(d)|
.

4.1. Design and Definitions 95
A termset X is called frequent pattern if its supa (or supr) ≥ min sup, a minimum
support. Given a set of paragraphs Y ⊆ PS(d), we can define its termset, which
satisfies
termset(Y ) = {t|∀dp ∈ Y ⇒ t ∈ dp}.
Let Cls(X) = termset(coverset(X)) be the closure of X. We call X closed if
and only if X = Cls(X). Let X be a closed pattern. We have
supa(X1) < supa(X) (4.1)
for all pattern X1 ⊃ X.
Patterns can be structured into a taxonomy by using the is-a (or subset) rela-
tion and closed patterns. Put simply, a pattern taxonomy is described as a set of
patterns, and the relation in the taxonomy is the subset relation. Smaller patterns
in the taxonomy are usually more general because they could be used frequently
in both positive and negative documents; but larger patterns in the taxonomy
are usually more specific since they may be used only in positive documents.
Closed Sequential Patterns
A sequential pattern s =< t1, . . . , tr > (ti ∈ T ) is an ordered list of terms.
A sequence s1 =< x1, . . . , xi > is a sub-sequence of another sequence s2 =<
y1, . . . , yj >, denoted by s1 v s2, iff ∃j1, . . . , ji such that 1 ≤ j1 < j2 . . . < ji ≤ j
and x1 = yj1 , x2 = yj2 , . . . , xi = yji . Given s1 v s2, we usually say s1 is a

96 Chapter 4. Relevance Feature Matching
sub-pattern of s2, and s2 is a super-pattern of s1. In the following, we refer to
sequential patterns as patterns.
Given a sequential pattern X in document d, coverset(X) is still used to
denote the covering set of X, which includes all paragraphs ps ∈ PS(d) such that
X v ps, i.e., coverset(X) = {ps|ps ∈ PS(d), X v ps}. Its absolute support and
relative support are defined as the same as for the normal patterns.
A sequential pattern X is called a frequent pattern if its relative support
≥ min sup, a minimum support. The property of closed patterns (see Equa-
tion (4.1)) can be used to define closed sequential patterns. A frequent sequen-
tial pattern X is called closed if not ∃ any super-pattern X1 of X such that
supa(X1) = supa(X).
4.1.2 Global Knowledge Base: the LCSH
Global knowledge is the common-sense knowledge acquired by people based on
their experience and education. The LCSH is an ideal global knowledge repre-
sentation because a rich vocabulary is used to cover all subject areas. In the
LCSH, subject headings are basic elements to convey knowledge in the format
of concepts, where they have three main types of references: broader term (BT),
narrower term (NT) and related term (RT). The related definitions are clarified
as follows.
Definition of subject headings: Let C denote a set of subject headings in the
LCSH, a subject s ∈ C is formalized as a pair (label, reference), where

4.2. Relevance Feature Acquisition 97
• label is the heading of s in the LCSH thesaurus;
• reference is a statement regarding all references that the subject c has.
The LCSH world knowledge base can be formalized as:
Definition of world knowledge base: A world knowledge base ontology is in a
directed acyclic graph structure defined as a pair Θ := (C,R), where
• C is a set of subjects in LCSH C = {s1, s2, ..., sn};
• R is the semantic relations R = {ref1, ref2, ..., refn} existing among the
subjects in C.
4.2 Relevance Feature Acquisition
In general, the concept of relevance is subjective. People can easily determine
the relevance of a topic (or document) in specificity or generality. However,
it is difficult to use these concepts for interpreting relevance features in text
documents. This section first discusses the use of the concepts for understanding
the different roles of the low-level feature terms for answering what users want.
We also present the ideas for accurately weighting terms based on their specificity
and distributions in the discovered higher level features. Finally, we describe
algorithms for both the discovery of higher level features and the revision of
weights of low-level terms.

98 Chapter 4. Relevance Feature Matching
4.2.1 Specificity of Low-Level Features
A term’s specificity describes the extent to which the topic of the term focuses on
what users want. It is very difficult to measure the specificity of terms because a
term’s specificity depends on users’ perspectives on their information needs [104].
In this study, the terms are grouped into three groups (SPE, general, and nega-
tive specific terms) based on their appearances in a training set. Given a term
t ∈ T , its coverage+ is the set of positive documents that contains t, and its
coverage− is the set of negative documents that contains t. We assume that
terms frequently used in both positive documents and negative documents are
general terms. Therefore, we want to classify terms that are more frequently
used in the positive documents in the positive specific category; and the terms
that are more frequently used in the negative documents in the negative specific
category. Based on the above analysis, we define the specificity of a given term t
in the training set D = D+ ∪D− as follows:
spe(t) =|coverage+(t)| − |coverage−(t)|
n
where coverage+(t) = {d ∈ D+|t ∈ d}, coverage−(t) = {d ∈ D−|t ∈ d}, and
n = |D+|. spe(t) > 0 means that term t is used more frequently in positive
documents than in negative documents. We present the following classification
rules for determining the general terms G, the SPE terms T+, and the negative

4.2. Relevance Feature Acquisition 99
specific terms T−:
G = {t ∈ T |θ1 ≤ spe(t) ≤ θ2},
T+ = {t ∈ T |spe(t) > θ2}, and
T− = {t ∈ T |spe(t) < θ1}.
where θ2 is an experimental coefficient, the maximum boundary of the specificity
for the general terms, and θ1 is also an experimental coefficient, the minimum
boundary of the specificity for the general terms. We assume that θ2 > 0 and
θ2 ≥ θ1. It is easy to verify that G ∩ T+ ∩ T− = ∅. Therefore, {G, T+, T−} is
a partition of all terms. To describe the relevance features for a given topic, we
believe that specific terms are very useful for the topic in order to distinguish it
from other topics.
Basically, we can understand the specificity of terms based on their positions in
a concept hierarchy. For example, terms are more general if they are in the upper
part of the LCSH hierarchy; otherwise, they are more specific. However, in many
cases, a term’s specificity is measured based on the topics we are talking about.
For example, “knowledge discovery” will be a general term in the data mining
community; however it may be a specific term when we talk about information
technology.

100 Chapter 4. Relevance Feature Matching
4.2.2 Term Weighting
This section develops equations for deploying patterns on low-level terms by
evaluating term supports based on their appearances in patterns. The evalu-
ation of term supports (weights) is different from term-based approaches. For
a term-based approach, the evaluation of a given term’s weight is based on its
appearances in documents. However, here, terms are weighted according to their
appearances in discovered patterns.
In the pattern taxonomy Model (PTM), relevance features are discovered from
a set of positive documents. To improve the efficiency of the PTM, an algorithm,
SPMining(D+,min sup) [119], was proposed (also used in [118]) to find closed
sequential patterns for all documents ∈ D+, which used the well-known Apriori
property in order to reduce the searching space. For all positive documents
di ∈ D+, the SPMining algorithm can discover all closed sequential patterns,
SPi, based on a given min sup. (We omit this algorithm to save space.)
Let SP1, SP2, ..., SPn be the sets of discovered closed sequential patterns for
all documents di ∈ D+(i = 1, · · · , n), where n = |D+|. For a given term t, its
support (or called weight) in discovered patterns can be described as follows:
support(t,D+) =n∑i=1
|{p|p ∈ SPi, t ∈ p}|∑p∈SPi |p|
(4.2)
where |p| is the number of terms in p.
Table 4.1 illustrates an example of sets of discovered closed sequential pat-

4.2. Relevance Feature Acquisition 101
terns for D+ = {d1, d2, · · · , d5}. For example, the term global appears in three
documents (d2, d3 and d5). Therefore, its support is evaluated based on patterns
in the sets of closed sequential patterns that contain global:
support(global,D+) =2
4+
1
3+
1
3=
7
6.
Table 4.1: Example of pattern miningDoc. Discovered Closed Sequential Patterns (SPi)
d1 {〈carbon〉 , 〈carbon, emiss〉, 〈air, pollut〉 }d2 {〈greenhous, global〉, 〈emiss, global〉}d3 {〈greenhous〉, 〈global, emiss〉}d4 {〈carbon〉, 〈air〉, 〈air, antarct〉}d5 {〈emiss, global, pollut〉}
After the supports of the terms have been computed from the training set,
the following rank will be assigned to every incoming document d to decide its
relevance:
rank(d) =∑t∈T
weight(t)τ(t, d) (4.3)
where weight(t) = support(t,D+); and τ(t, d) = 1 if t ∈ d; otherwise τ(t, d) = 0.
Because of significant levels of noise in the discovered patterns (an inherent
disadvantage of data mining), the evaluated supports are not accurate enough.
To improve the effectiveness of PTM, we use negative documents in the training
set in order to remove the noises. If a document’s rank (see Equation. 4.3)
is less than or equals to zero, this document is clearly negative to the system.

102 Chapter 4. Relevance Feature Matching
If a negative document has a high ranking position, the document is called an
offender [66] because it forces the system to make a mistake. The offenders are
normally defined as the top-K negative documents in a ranked set of negative
documents, D−. The basic hypothesis is that the relevance features should be
mainly discovered from the positive documents. Therefore, in our experiments,
we set K = n2, the half of the number of positive documents.
There are two major issues for effectively using negative documents. The first
is : 1) how to select a suitable set of negative documents because we usually can
obtain a very large set of negative samples. For example, a Google search can
return millions of documents; however, only a few documents are interesting to a
Web user. Obviously, it is not efficient to use all of the negative documents. The
second issue is 2) how to accurately revise the features discovered in the positive
documents.
Many people believe that negative documents can be helpful if they are used
appropriately. The existing methods can be grouped into two approaches: revis-
ing terms that appear in both positive and negative documents; and observing
how often terms appear in positive and negative documents. However, how much
improvement in accuracy can be achieved by using negative feedback still remains
an open question.
In this section, we present an innovative solution for these issues. We show
how to select a set of negative samples. We also show the process of the revision.
Once we select the top-K negative documents, the set of negative document

4.2. Relevance Feature Acquisition 103
D− will be reduced to include only K offenders (negative documents). The next
step is to classify terms into three categories, namely, G, T+, and T−, based on
D+ and the updated D−. We can easily verify that the experimental coefficients
θ1 and θ2 satisfy the following properties if K = n2:
0 ≤ θ2 ≤ 1, and − 1
2≤ θ1 ≤ θ2.
Here, we show the basic process of revising discovered features in a training
set. This process can help readers to understand the proposed strategies for
revising the weights of low-level terms in different categories. Formally, let DP+
be the union of all discovered closed sequential patterns in D+, DP− be the union
of all discovered closed sequential patterns in D− and T be the set of terms that
appear in DP+ or DP−, where a closed sequential pattern of D+ (or D−) is called
a positive pattern (or negative pattern).
It is obvious that ∃d ∈ D+ such that t ∈ d for all t ∈ T+ since spe(t) > θ2 ≥ 0
for all t ∈ T+. Therefore, for each t ∈ T+, it can obtain an initial weight by the
deploying method on D+ (using the higher level features, see Equation. 4.2).
For the term in (T− ∪G), there are two cases. If ∃d ∈ D+ such that t ∈ d, t
will get its initial weight by using the deploying method on D+; otherwise it will
get a negative weight by using the deploying methods on D−.
The initial weights of terms finally are revised according to the following
principles: increment the weights of the SPE terms, decline the weights of the
negative specific terms, and do not update the weights of the general terms. The

104 Chapter 4. Relevance Feature Matching
details are described as follows:
weight(t) =
w(t) + w(t)× spe(t), if t ∈ T+
w(t), if t ∈ G
w(t)− |w(t)× spe(t)|, if t ∈ T−
(4.4)
where w is the initial weight(or the support in Equation. 4.2).
4.3 Concept Matching Method
4.3.1 Limitations of Query-Based Method
Before introducing our new matching method, this section first discusses the basic
theory of query-based matching and its associated disadvantages. It is important
to be aware that the disadvantages lead to a serious problem when we attempt
to incorporate data mining and ontology learning techniques.
Generally speaking, query-based matching happens along with two sets of
terms. The matching is based on the degree of their overlapping. In this sce-
nario, for example, a relevance feature extracted from the previous pattern min-
ing approach is recognized as a query, where q = {t1, t2, t3, t4, t5}. One subject
in the LCSH represents a concept, where s = {t0, t3, t5, t6}. The traditional
method [50, 88] would primarily consider the number of overlapping terms as
|q ∩ s| = 2. The larger the number of overlapping terms, the more optimal the
matching. From the data mining point of view, the theory is correct and has

4.3. Concept Matching Method 105
no argument. This is because of the fact that if a term frequently appears in
the text, it must be a specific and highly relevant term of a topic. This term is
used to describe significant information needs. The query-based matching offers
a reasonable way to estimate the similarity between queries and subjects. How-
ever, it is not good enough due to the disadvantage of redundancy. According to
the output from a preliminary study, we realize that the general terms defined in
the previous section appear frequently in the LCSH database. Consequently, the
retrieved subjects must contain a lot of useless terms to decrease effectiveness.
Figure 4.2: Occurrence of terms in the first 50 RCV1 topics
The preliminary study was carried out to investigate the occurrence of the
SPE and general terms in the LCSH. The study applied the first 50 RCV1 topics
for testing. Each term in the two groups was assigned a value computed by:
SPEonto(t) = 1|coverage(t)|
where |coverage(t)| was the number of subjects containing t. To allocate all the
values between 0 and 1, we applied a normalization method as:
SPEonto(t) = log10(N
|coverage(t)|)/log10(N
MAX)

106 Chapter 4. Relevance Feature Matching
where N = total number of subjects, MAX = the maximum of coverage(t)
for all t ∈ T+orG . As shown in Figure 4.2, the “ONTO-SPE” curve is generated
by the results of SPEonto(t), t ∈ T+ whereas the “ONTO-G” is from the results
of SPEonto(t′), t′ ∈ G. It was apparently that the terms belonging to the general
group occurred frequently in the majority of the topics. This causes a possible
consequence that the matched concepts were not only irrelevant, but also regular
rather than specific.
4.3.2 Concept Intension & Extension
In the study of formal concepts, every concept is understood as a unit of thoughts
that consists of two parts, namely, the intension and extension of the concept [124].
A concept can be described jointly by its intension and extension.
In order to find accurate concepts from the LCSH for building personalized
ontologies, this section presents a creative strategy that is applied to supervise
concept acquisition prior to matching. The strategy takes concept intension and
extension into account to theoretically support the proposed matching. With
different objectives, there are diverse explanations of the intension and extension.
Here, we understand it in the logic way [84] as: correlative words that indicate
the reference of a term or concept: “intension” indicates the internal content of a
term or concept that constitutes its formal definition; and “extension” indicates
its range of applicability by naming the particular objects that it denotes. For
instance, the intension of “ship” as a substantive is “vehicle for conveyance on

4.3. Concept Matching Method 107
water”, whereas its extension embraces such things as cargo ships, passenger
ships, battle ships, and sailing ships. It is easy to know from the example that
the intension is about the attribute of a concept of its own, and the extension is
a list of members with the attribute.
In other words, the intension is used to represent properties and characteristics
of the entire concept while extension is used to represent a specific part of this
concept [124]. A concept is thus described jointly by its intension and extension.
Therefore, it is true to state that extension is part of intension and it cannot
survive on its own. The major advantage of this characteristic of extension is
that it can always be used to define different specific characteristics in the main
concept set, for it can take various combinations of elements in the main set.
Furthermore, the main disadvantage of the characteristic is that extension cannot
be defined on its own. Extension can create various forms of unique characteristics
to be contained in a single developed intension concept, and thus it is of great
importance to the expansion of various aspects in model development. To be able
to develop an advanced matching approach, a proper management of intension
attributes should be considered so as to develop strong unique characteristics
while defining the extension aspect.
Through the previous explanation, the goal of using the concept intension and
extension can be understood. We believe that once a core concept is identified, the
potential useful and relative concepts can be obtained by enlarging the coverage of
its extension. These additional concepts might better contribute to personalized

108 Chapter 4. Relevance Feature Matching
ontologies so as to capture more precise information needs. However, how to
adopt the intension and extension becomes a challenging issue. The two main
questions arise: 1) what are the candidates that should be chosen with intension;
and 2) how many extensions are enough for the candidates. Along with these
questions, we first redefine the definitions of intension and extension as below:
Definition (Intension): A set of terms T that is originally used in the LCSH to
describe the meaning of the concept s. For instance, “blood pressure” a subject
heading s from the LCSH. The set of terms T = {blood, pressure} is the intension
of the concept s.
Definition (Extension): the extension consists of the specific terms in the LCSH.
These terms are used to describe the ideas, properties, or corresponding signs that
are related to the concept s.
The specific terms can be clarified by the LCSH reference types in the chapter
3 section 3.2. There are totally four specific terms that could be associated
with the concepts. The broader terms mean that the extension covers more
general concepts. The narrow terms indicate that the related concepts are more
focusing. These two are used to form the relation of “Is-A”. Another two types
are the used-for terms and the related-to terms. The used-for terms are little bit
similar to the “Is-A” relation because they have the whole/part meaning. Hence,
the extension of the used-for terms is to describe the potential metronymic and
inclusive concepts. The related-to terms present the concepts that have the same
characteristics with a concept’s intension.

4.3. Concept Matching Method 109
For the first question, we determine the use of the SPE terms as the candidates
of intension. This decision aims to coincide the specificity of low-level features.
Since the SPE terms are highly focused on user wants in one specific topic, each
SPE term is realized as a quality or property which can make up a clear concept.
Yet, the term must satisfy a pre-condition to grant the intension, which is
⋃s∈C
Intension(s) ⊇ all SPE terms (4.5)
where Intension(s) denotes the intension of a matched subject in the LCSH. By
meeting the condition 4.5, the concept intensions are well-defined and coherent
with the SPE terms for sure. They always act as core elements to interpret
specific concepts.
The second question is difficult to answer without a certain explicit scope of
extension. Earlier, we described that the extension can help to cover more related
portions in terms of the intension. However, there is no universal judgement
for all possible cases. Taking a real instance for example, a concept intension
is “network”, and one of its extensions is “network security”. Apparently, after
having one more term, the new concept is more specific than merely the intension.
Meanwhile, another extension is added through a large amount of terms “qut b
block network security training”. At this time, the new concept may be confusing
and not appropriate. Our thinking is to make the potential extensions as specific
as possible, or keep them small. The main reason is that since our goal is to find
the most specific concepts, the new coming terms might be excess and useless.

110 Chapter 4. Relevance Feature Matching
Again, they might result in redundancy. As a result, we set up another condition
is to minimize extension in a virtual space, which can be formulated as shown
below. To better understand the condition, a diagram is shown in Figure 4.3.
The condition 4.6 is to get the smallest shadow portion.
Figure 4.3: Difference between extension and intension
∫ sn
s1
(Extension(s)− Intension(s))ds (4.6)
where Extension(s) denotes the extension of a matched subject in the LCSH,
and ds means the variable. The above two conditions guide the design of our new
distributed matching method.
4.3.3 Distributed Matching
The matching occurs between the terms mined from the previous sections and
subjects appearing s ∈ C in the LCSH. Note that the mined terms are dis-
tinguished into three groups and their values can be calculated by the weight

4.3. Concept Matching Method 111
function in Equation. 4.4. In this method, we only use terms in the first scenario
where t ∈ T+ for matching the concepts among the LCSH. The SPE terms are
sufficient and indispensable to represent user desired information according to
our prior testing.
Closely referring to the specified conditions 4.5 and 4.6, this section provides
a distributed method for matching relevance features and concepts. The reason
that the method is called “distributed” is because each SPE term will be assigned
the corresponding concepts individually. In order to satisfy the condition 4.5,
the candidate concepts must involve or exactly cover the particular SPE term
si ⊇ t = {t|t ∈ T+}. The matching method is divided into several steps and
described in detail as follows:
1) To gather the importance of terms in T+, we first sort them based on the
weight values from Equation. 4.4. This action aims to identify the significant
terms from the text mining perspective and highlight them.
2) The second step consists of two phases. For this step, the condition 4.6 is
brought to our attention. Since the scope of extension is difficult to determine,
our strategy is to keep all the original intensions and to minimise their exten-
sions. To control this strategy in a practical way, phase one is allocated the top
25% terms in T+ based on their values. They are considered as the core portion
of local information. Consequently, the four most relevant subjects s ∈ C are
referred to each of the top 25% terms. In the second phase, the relevance of
subjects is computed by rel(s) = |T+∩ s|/|s|, where |T+∩ s| denotes the number

112 Chapter 4. Relevance Feature Matching
of overlapped terms between T+ and subject s, |s| stands for the total number
of terms in the subject s. According to the rel values, four subjects can be con-
firmed. The idea of choosing 25% and four parameters is supported by empirical
experiments. The matching performance can be impacted while modifying these
parameters. A comparison of using other parameters is shown in the evaluation
section.
Algorithm 3 Concept Matching AlgorithmInput:
A set of SPE terms T+; weight(t) from Eq. 4.4; a set of LCSH subjects C.Output:
A set of matched concepts SC.1: Let SC = ∅;2: Sort T+ using weight(t) in descendant order;3: Let K = |T+|/4, Let T+
1 be the top-K terms in T+;4: for each t ∈ T+
1 {5: Let s1 = s2 = s3 = s4 = t;6: Let c(t) = {s ∈ C|t ∈ s};7: Select the top-4 relevant concepts in c(t) using rel(s), and let s1, s2, s3, s4
be the subjects; //if |c(t)| < 4, t will be the default value of si because ofstep 5
8: Let SC = SC ∪ {s1, s2, s3, s4} }9: for each t ∈ (T+ − T+
1 ) {10: Let s1 = t, rel(s1) = 0;11: for each (s ∈ C&t ∈ s)12: if |s∩T
+||s| > rel(s1) then
13: Let s1 = s, rel(s1) = |s∩T+||s| ;
14: Let SC = SC ∪ {s1} }
3) This step is for the rest of the terms (75%) in T+. To find accurate subjects
for each of these terms, we select the most relevant one based on rel value instead
of four. The step can also guarantee that all the intensions of the SPE terms
have been covered. The majority of the extensions are disregarded to reduce the
opportunity of redundancy.

4.4. Summary 113
4) A set of specified concepts and their references existing in the LCSH can be
obtained to form a personalized ontology. By taking advantage of the ontology, a
scope of user background knowledge can be defined, and search systems can offer
tailoring results after understanding precise user preferences.
In most cases, a term t ∈ T+ can successfully find a subject or a set of
subjects s = {s|s ∈ C} in the LCSH. It is a challenging issue when a term cannot
match concepts in the global knowledge base. For example, “dutroux” is not
a valid word/term in the vocabulary but it appears frequently in the training
documents. It could be important to describe user needs. However, no subject
can be matched by the proposed method. To overcome this issue, we count the
term itself as a subject directly as if c(t) = {s ∈ C|t ∈ s} = ∅.
Algorithm 3 illustrates the entire process for our concept matching method,
which enables the work to be repeated and optimize. Noting that the output is a
set of specific concepts SC, the process can be also understood as a transition of
the informative descriptor and conceptional descriptor. These acquired concepts
and their semantic relations in the LCSH are used to construct personalized
ontologies.
4.4 Summary
This chapter presents a systematic approach to build personalized ontologies by
adopting relevance features. The purpose of the approach is to address a hard
question which is how to associate low level features (local information) with high

114 Chapter 4. Relevance Feature Matching
level concepts (global knowledge). The approach also builds a bridge to inter-
preting user information needs by studying the produced personalized ontologies.
The user orientated feature is used to represent user information need and match
concepts appearing in the global knowledge base. At the beginning, the pattern
mining technique for acquiring relevance features is fully introduced including
related definitions, feature classification, and term weighting. To match with ap-
propriate concepts in the global knowledge, the theory of intension and extension
is employed to guide a distributed matching process. The process is an effective
solution to solve the problem of local informative references and common knowl-
edge mismatch. The final deliverable is the tailored personalized ontology, which
is composed of “is-a” superior and subordinate concepts in the world knowledge
base. For evaluation, the standard topics and a large test-bed are employed for
scientific experiments. We expect to gather substantial results to prove that the
proposed matched concepts outperform in information filtering measurements af-
ter comparison with baseline models.

Chapter 5
Evaluation
In the previous chapters, two ontology-based approaches were fully discussed.
One is the ontology-based mining approach, which is abbreviated by OM in this
chapter; and the other is the approach for using relevance features to match con-
cepts in the world knowledge base, which is abbreviated by POM. A common
hypothesis in this dissertation is that personalized ontologies contain useful con-
tent for the capture of user information needs. They can offer more accurate
results when users participate in retrieval activities. User search intentions can
be discovered somewhere in a hierarchical concept-based structure by the first
approach. In the second approach, we consider the specificity features extracted
from positive documents containing user-focused needs. When adopting the rel-
evance features for ontology matching, gathered concepts should be helpful to
115

116 Chapter 5. Evaluation
improve search effectiveness. Related experiments were conducted to evaluate
and support this hypothesis. The similar ontological mining model - ONTO has
been selected as one of the baseline models. This chapter provides an overview
of experiment design, data collection, baseline models, information filtering mea-
surements, and the obtained results.
5.1 Evaluation Environment
5.1.1 Experimental Dataset
The LCSH was chosen as the database for the development of the proposed ap-
proaches. It is originally a 719 mega bytes database stored in Microsoft Office
Access (.mdb). Comprehensive reviews and discussion in the related literature
led to the specifications of its definition, types, roles, and subject headings. In to-
tal, the database contains 20 tables to save data regarding semantics, topics, and
subject headings. After classifying and arranging the useful information, we built
up a table called ontology to store the relevant data for ontology construction,
including items of ID, subject headings, and the assigned semantic relations. Ini-
tially, 491,250 subject headings and their internal references between the headings
were extracted, including ancestor, descendent, part− of , and related− to.
The Reuters Corpus Volume 1 (RCV1) consists of all and only English lan-
guage stories produced by Reuter’s journalists between August 20, 1996, and
August 19, 1997, a total of 806,791 documents that cover a very wide range of

5.1. Evaluation Environment 117
topics and information. TREC (2002) developed and provided 100 assessor top-
ics [85] for the filtering track, aimed at building a robust filtering system. These
topics were developed by human assessors of the National Institute of Standards
and Technology. Relevance judgements on the RCV1 were also made by the as-
sessors. The assessor topics are more reliable than any artificially constructed
topics [100]. For each topic, some documents in the RCV1 are divided into a
training set and a testing set. Both the training and testing set have two kinds
of documents, namely, positive documents and negative documents. The positive
documents have been manually indicated as relevant to the topic, whereas the
negative documents have been indicated as irrelevant. Figure 5.1 clarifies the
structure and relations of the RCV1.
According to Buckley et al. [16], the first 50 topics are stable and sufficient
for high quality experiments. This dissertation uses the RCV1 and the first 50
assessor topics to evaluate the proposed model. The documents in RCV1 are
marked in XML. To avoid bias in experiments, all of the meta-data information
in the collection has been ignored. The documents are treated as plain text
documents by pre-processing the documents. For the pre-processing purpose, an
associated program has been built in the Java programming language. There are
two functions, namely, stemming and stopwords removal. The stemming uses the
Porter stemming algorithm (or Porter stemmer) , which is a process for removing
the more common morphological and inflexional endings from words in English.
Its main use is as part of a term normalization process that is usually done when

118 Chapter 5. Evaluation
Figure 5.1: RCV1 data structure

5.1. Evaluation Environment 119
setting up information retrieval systems. For instance, before stemming, a text
is presented as follows:
At least 44 people were feared drowned when their vessel capsized in the
Nagavalli river in the southern state of Andhra Pradesh, the United News of
India said on Sunday. It quoted official sources as saying the boat was
carrying some 50 people, mainly tribespeople, when it sank on Saturday. Six
people swam to safety, it said.
Then, the text becomes the following statement after stemming:
least peopl fear drown vessel capsiz nagav river southern state andhra
pradesh unit new india sundai quot offici sourc sai boat carri peopl mainli
tribespeopl sank saturdai six peopl swam safeti
The aim of the stopwords removal is to prune the meaningless terms in a text
(e.g. the, a, for, of etc). As well as the above functions, the program can also
calculate term frequency in a text and compute the relevance value rel(s) specified
on Algorithm 3 for each subject. Figure 5.2 is the primary user interface of the
pre-processing program.
5.1.2 Baseline Models
For evaluation, we employed a number of baseline models. These models belongs
to different categories, including three well-known IR models, two effective pat-
tern mining models, and one ontology mining model. The selected IR models and
parameter settings are outlined as follows:

120 Chapter 5. Evaluation
Figure 5.2: Primary user interface of the coded pre-processing program
• TFIDF [88]: This model has been introduced in related work and is widely
used. The term t can be weighted by w(t) = TF (d, t) × IDF (t), where
term frequency TF (d, t) is the number of times term t occurs in document
d(d ∈ D) and D is a set of documents in the dataset; DF (t) is the document
frequency which is the number of documents where the term t occurs at least
one; IDF (t), the inverse document frequency, is denoted by log( |D|DF (t)
).
• Rocchio [53]: This method generates a centroid for representing user pro-
files by extracting terms from positive documents and performing a revision
of the weights of the terms from negative documents. The centroid ~c of a
topic can be generated as follows:
~c = α1
|D+|∑−→d ∈D+
−→d
||−→d ||− β 1
|D−|∑−→d ∈D−
−→d
||−→d ||
(5.1)

5.1. Evaluation Environment 121
where ||−→d || is the normalized vector for document d. α and β are two
control parameters for the effect of relevant and non-relevant data respec-
tively. According to [?, ?], there are two recommendations for setting the
two parameters: α = 16 and β = 4; and α = β = 1.0. We have tested both
recommendations on the assessor topics and found the latter recommenda-
tion was the best one. Therefore, we let α = β = 1.0.
• Okapi BM25 [86] is one of the state-of-the-art term-based models. The
term weights are estimated using the following probabilistic model-based
equation:
W (t) =tf · (k1 + 1)
k1 · ((1− b) + b DLAVDL
) + tf· log
(r+0.5)(n−r+0.5)
(R−r+0.5)(N−n−R+r+0.5)
(5.2)
where N is the total number of documents in the training set; R is the
number of positive documents in the training set; n is the number of doc-
uments which contain term t; r is the number of positive documents which
contain term t; tf is the term frequency; DL and AVDL are the document
length and average document length, respectively; and k1 and b are the ex-
perimental parameters, where the recommended values of k1 and b for this
data collection are 1.2 and 0.75, respectively [133].
The pattern mining models are listed here:
• PDS [118]: The data mining method for using frequent patterns in the
text was proposed. This method focuses on addressing the difficulties of

122 Chapter 5. Evaluation
using specific long patterns in text by using patterns to accurately weight
low-level terms based on their distributions in the patterns. Given a term
t ∈ D+, the support of term t can be computed as the following function.
w(t) =
|D+|∑i=1
∑t∈p⊆SPi
Supa(p, di)
|p|(5.3)
where SPi denotes a set of closed sequential patterns in document di and
|p| indicates the length of pattern p. The extracted low-level terms are used
to score a test document based on the total weight of the terms contained
in the document.
• RFD [65]: The RFD model was fully introduced by the section 4.2 in
Chapter 4. The core idea is to discover both positive and negative patterns
in text documents as higher level features in order to accurately weight
low-level features (terms) based on their specificity and their distributions
in the higher level features. All the terms are pre-defined into three groups
and used for document weighting and sorting.
The last baseline model is an ontology-based model.
• ONTO [104]: The ONTO model builds personalized ontologies for improv-
ing retrieval effectiveness and is close to our model. The idea of the model
is to use a similarity to determine relevant concepts c for describing the
themes of the local instances, P (c|F ) = P (c ∩ F )/P (F ), where F is a set
of features discovered in the local instances. The conceptual ontology user

5.1. Evaluation Environment 123
profile was also proposed by this model.
5.1.3 Experimental Measurements
In order to prove the accuracy and feasibility of our approaches, an objective
experiment is conducted by applying five state-of-the art IR measuring metrics.
These are the top 20 precision measures based on the relevance judgement in
RCV1 (top@20), the precision averages at 11 standard recall levels (11− points),
the Mean Average Precision (MAP ), the F1-measure (F1), and the breakeven
point (b/p).
The top 20 precision is considered to be the most important standard in
the evaluation since a Web searcher is mostly going to look at the top 20 docu-
ments [64]. In the domain of IR, precision is the percentage of retrieved documents
that are relevant. Obviously, the precision of search results will be improved after
discovering the precise user intents. By using the ranking algorithm 4.3 presented
in the previous chapter, we obtained a list of documents sorted based on the value
of their weights. The relevance of each document in the RCV1 has already been
judged and scored by 0 and 1. Compared to these judgements, the top 20 preci-
sion can be computed as follows.
top@20 =|{first 20 sorted docs} ∩ {relevant docs}|
20
MAP is correlated with average precision (Ave(p)). Ave(p) is the average of
precision at each relevant document retrieved in the ranked sequence. Consisting
of the Ave(p), the equation of MAP is formed as

124 Chapter 5. Evaluation
MAP = 1|Q|
|Q|∑s=1
Ave (p)
where Q stands for the number of queries. The F1-measure was first introduced
by C. J. van Rijsbergen [111]. It combines recall and precision with an equal
weight in the following form:
F1 −Measure = 2×precision×recall(precision+recall)
The 11−points measure is also used to estimate the performance of retrieval mod-
els by averaging precision at 11 standard recall levels (i.e. recall = 0, 0.1, 0.2, ..., 1).
5.2 Experiment Design and Settings
As known that the related experiments are required to evaluate the two pro-
posed approaches. Since their experiment designs are different, we explain them
separately. This section starts with an overview of the experiment design of the
first ontology-based mining approach (abbreviated as OM). In essence, the design
aims to answer which level contains the most proper user information needs in
the LCSH ontology. A simple way is to use the performance of the pilot level
(first matching level) as the benchmark, and then check the performance for all
the levels. However, this method was felt to be too trivial and time-consuming
because of the large number of levels that occurs in the LCSH. The result from
our preliminary study shows that topic R117 has the longest depth of levels (28
levels including upper and lower levels). The shortest depth is owned by topic
R116 (10 levels for two directions). For the first 25 topics in the RCV1, their

5.2. Experiment Design and Settings 125
average depth is 20.32. Based on the observations, we noticed that all these 25
topics have relative subjects in the upper level 7 and lower level 2. Therefore, we
defined these two levels as other benchmarks while testing. Finally, we designed
an experiment to estimate the performance for the first 7 upper and 2 lower levels
one by one. This would help to determine which level is the best candidate to
interpret information of interest to the user. The ONTO model was chosen as the
baseline for comparison because it belongs to a pure ontology-based model. To
conduct a thorough evaluation, all the results would be considered in the specified
information measurements above.
The second approach is a learning approach by adopting relevance features,
named POM here. The goal of the approach is to match a set of concepts in the
LCSH ontology for personalized ontology creation. The design aims to clarify two
points: 1) what are the best candidates for concept matching, and 2) whether
the proposed matching approach is useful. Figure 5.3 provides an overview of
the entire experimental design. First of all, all the models would make use of
the RCV1 training set for feature selection. The produced features are a set of
term weight pairs pending to be matched with concepts. After implementing
the distributed matching method, the features are converted into concepts. The
RCV1 testing set is prepared for evaluating whether the concepts are useful for
improving the mining effectiveness.
As explained in Section 4.3.3, two parameters are defined for distributed
matching. Table 5.1 shows the reason for predefining the parameters as the top

126 Chapter 5. Evaluation
Figure 5.3: Experiment design for POM
25% terms with 4 subjects and 1 for the rest. A number of combination settings
such as 50% 33%, and 25% with different numbers of subjects were tested but are
omitted here for space. After conducting duplicate attempts, we found that using
the association of the top 25% with 4 subjects and 1 for the rest can produce the
best result. This decision also meets the constraints of the conditions in 4.5 and
4.6.
#subjects % top@20 MAP F1 b/p50 0.43 0.3967 0.4103 0.3880
4 33 0.42 0.3941 0.4084 0.385525 0.46 0.4124 0.4195 0.404250 0.44 0.4029 0.4141 0.3968
3 33 0.44 0.4008 0.4125 0.400125 0.45 0.4053 0.4157 0.3971
2 ......
Table 5.1: Comparison results for different parameter settings
5.3 Experimental Results
This section outlines the gathered results regarding the performance of both the
OM and POM approaches.

5.3. Experimental Results 127
5.3.1 Evaluation of Ontology-Based Mining Approach
Table 5.2 summarizes the results for the OM. It gives an intuitive view of all
the levels in the constructed hierarchy. To indicate the influences affected, the
percentage change in performance was used to compute the difference in the top
20 precision, MAP , and F1−Measure results among the levels. It is formulated
as:
%chg =Resultafter−Resultbefore
Resultbefore× 100
The larger the %chg value is, the more significant improvement it achieves.
By observing the output, we can identify that the upper level 7 is the desired
solution to store the user search intent because it has a major improvement
(21.19%) in the top precision compared with the pilot and other levels. All
these statistical results are computed for the average of the first 50 topics in the
RCV1. Another vital point that attracts our attention is the number of subjects
in different levels. The pilot level has the largest number of subjects but with
low performance. This scenario indicates that the majority of the subjects are
redundant, which means they are not useful to represent user wants. However,
for the upper and lower levels, they follow the descending order and the number
of subjects in these levels reduce dramatically. This can be understood by the
nature of the LCSH ontology, which is that not every subject has been specified
with internal references. In addition, we can picture a shape of the upper levels
as a cone, whereas an inverse cone is for the lower levels (chapter 3, Section 3.3).
Based on the table, we can prove that the OM approach works for top precision

128 Chapter 5. Evaluation
enhancement.
pr@20 MeanAve.Pre. F1 −Measure
# Subjects Value % Chg Value % Chg Value % ChgUpper Lv.7 25.96 0.204 21.19 0.228 0.07 0.281 -1.025Upper Lv.6 37.76 0.199 18.42 0.224 -1.43 0.279 -1.66Upper Lv.5 54.04 0.193 14.39 0.225 -1.01 0.281 -1.02Upper Lv.4 75.96 0.18 6.49 0.221 -2.69 0.278 -2.1Upper Lv.3 114.16 0.183 8.53 0.223 -1.9 0.28 -1.35Upper Lv.2 178.8 0.188 11.79 0.229 0.55 0.284 0.08Upper Lv.1 365.16 0.18 7.03 0.231 1.5 0.287 1.15Pilot Lv. 2132.04 0.168 0.228 0.284Lower Lv.1 370.04 0.17 1.19 0.228 0.39 0.284 0.21Lower Lv.2 103.84 0.19 11.31 0.23 0.88 0.285 0.5Lower Lv.3 32.52 0.174 3.54 0.222 -2.41 0.2798 -1.63Lower Lv.4 11.39 0.2 16.14 0.229 0.48 0.284 0.04
Table 5.2: Overall performance of first 50 topics
Focusing on the effect of top precision, an expanded test was conducted to
examine the performance in different experimental stages (topics 1-25, 1-50, 1-
100). We separated the testing into three stages according to the RCV1 topics.
The results also compute the averages and compare the benchmarks and the
ontology-based baseline, namely, the ONTO model. As seen in Figure 5.4, the
results produced by our model consistently outperform the others. In the first
stage (topics 1-25), the improvement is most distinct. During the next stage of
topics 1-50, the result of our model is similar to the one from the upper level 7. In
the final stage, the improvement changes to be obvious again. The possible reason
is that the last 50 topics were generated by the machine learning algorithm.
Figure 5.5 shows the comparison result of 11-points in the first 50 RCV1 topics.
The performance indicates that our approach is better than other approaches
at the early stage, and slightly worst at last. The possible reason is about the

5.3. Experimental Results 129
Figure 5.4: Top 20 precision for three stages
redundancy. When moving toward different levels, the uncertain number of terms
would be increased for each RCV1 topic. So far, there is no way to prove that the
increased terms are all relevant to information needs. Based on our observation,
we claim that the majority of terms are noise in terms of the prospective of
text mining. For example, the precise terms economy espionage have a parent
business. The terms are apparently related in the logical point of view. However,
the term business would possibly become a noisy while adopting information
filtering measure.
Limitations: Three main limitations exist in this approach. The first one is
that: our investigation is mainly focused on the usage of is − a relations in
the LCSH. The other relations, including used − for and related − to are not
regarded in our approach. As a result, the maximum number of depth relations
detected based on the constructed concept hierarchy is 28, not 37 as specified

130 Chapter 5. Evaluation
Figure 5.5: Comparison of 11-points in first 50 topics
in the LCSH specification [104]. Some useful implicit knowledge might be not
entirely discovered from world knowledge representation. The second limitation
is caused naturally from the LCSH. In reality, user interests are usually changing
all the time. The choice and form of headings are not necessarily current because
the LCSH terms have evolved over time, but they can never be totally up-to-date.
This might lead to misinterpretation of user search intentions. The last limitation
is about the dataset applied for evaluation. It is a textual collection of news, but
the database used for searching is a subject collection of library headings. This
might possibly influence the experimental results.

5.3. Experimental Results 131
5.3.2 Evaluation of Distributed Matching
As shown in Figure 5.3, all the models need to have features before taking the
matching into account. Consequently, every model was first executed along with
its particular techniques for feature selection. All the generated features are
treated as a set of term weight pairs, like feature = {< t1, w1 >,< t2, w2 >
, ..., < ti, wi >}, where i denotes to the number of terms in the feature. In fact,
the numbers of terms produced by diverse models are completely different.The
table 5.3 summarizes the differences. The number of terms for each model is
the average result in the first 50 RCV1 topics. Here, we list an item as “RCV1
Title”. It is the number of terms appearing in the original RCV1 titles, which
were summarized by news experts. The “RFD-T+” represents the number of
terms appearing in the specificity group of the RFD model.
Model #termsRCV1 Title 3.04
RFD-T+ 23.12TFIDF 147.32Rocchio 621.96BM25 615.86PDS 154.82
ONTO 75.96
Table 5.3: Number of terms extracted by all the models
Due to the diversity, we made a solution to fairly evaluate the proposed match-
ing approach. Firstly, all the extracted terms by one model are sorted based on
the assigned weight wi. Then, a cut-off is made to keep the terms in the first
23 positions. At last, these top 23 terms are determined as representatives of

132 Chapter 5. Evaluation
the model to establish the concept-based matching. They are regarded as a long
query Q for expressing user preferences.
To prove that our matched concepts can truly contain user information needs,
all terms in the matched concepts are revised with a new weight as follows:
weight(t,Θ) =∑
t∈s,s∈SC
rel(s)/|Q|
where Q denotes the long query in the paragraph. For each model, we use the
revised weights computed by Equation. 4.3 to rank documents for the first 50
topics in the RCV1 testing set. Finally, the comprehensive experimental results
are obtained and showed in Table 5.4 in the first 50 topics. As displayed, RFD-
T+ achieves excellent performance with 11.82% (maximum 13.88% and minimum
7.36%) in percentage change on average for all four measures. The deploying
method is:
weight(t,Θ) = 1/|the occurrence of t|
#terms top@20 MAP F1 b/pRFD-T+ 23.12 0.467 0.42193 0.42416 0.41356TFIDF 23.00 0.317 0.30218 0.34484 0.29754Rocchio 23.00 0.463 0.42266 0.42575 0.39965BM25 23.00 0.452 0.41328 0.41872 0.41231PDS 23.00 0.448 0.41435 0.42059 0.40016
ONTO 23.00 0.335 0.34035 0.37876 0.33552%chg +12.57% +13.47% +7.36% +13.88%
Table 5.4: Comparison results after matching
In Table 5.6, we list the original results produced by all the models for analysis.

5.3. Experimental Results 133
A big difference is the number of extracted terms by different techniques. There
are 23.12 SPE terms on average, which is approximately 7 times less than the
number of terms extracted by TFIDF (147.32) and PDS (154.82). It is around
27 times less the Rocchio (621.96) and BM25 (615.86). This demonstrates that
the SPE terms are quantitatively enough to summarize all user needs with a
small number of words. The matched concepts should capture all concrete user
knowledge. It is clear that all the models after adopting the developed matching
process perform with similar results compared with the their original results. For
some of models, including the BM25 and ONTO, they even achieve slightly better
results.
#terms top@20 MAP F1 b/pRFD-T+ 23.12 0.413 0.37591 0.39476 0.37036TFIDF 23.00 0.318 0.30049 0.34118 0.30245Rocchio 23.00 0.439 0.39196 0.40463 0.38596BM25 23.00 0.457 0.42098 0.42633 0.41588PDS 23.00 0.444 0.39963 0.41115 0.38465
ONTO 23.00 0.26 0.29237 0.33729 0.29207
Table 5.5: Comparison of deploying results
In terms of the displayed results from Table 5.5, we found that the deploying
method is not suitable to the predication of concept matching. Although the de-
ployment are widely applied by data mining models for prediction or classification
to new data, the results are not good as the prior weighting method weight(t,Θ).
Figure 5.6 shows the 11 − points comparison after adopting the matching
approach. It is noted that the relevance features of RFD-T+ perform a little
better than the other models. This is the evidence upon with we identify the

134 Chapter 5. Evaluation
#terms top@20 MAP F1 b/pRFD-T+ 23.12 0.489 0.44826 0.44457 0.43804TFIDF 147.32 0.369 0.344278 0.37128 0.34418Rocchio 621.96 0.475 0.4305 0.4299 0.4201BM25 615.86 0.445 0.4069 0.414 0.4074PDS 154.82 0.496 0.44 0.444 0.439
ONTO 75.96 0.328 0.3455 0.37237 0.33015
Table 5.6: Comparison of original results
relevance features of RFD-T+ as the best alternative for queries to express user
information needs.
Figure 5.6: 11 points result after matching
As well as Table 5.6, we also provide Figure 5.7 to show the original 11 points
result of the models. Comparing Figure 5.6 and Figure 5.7, there is no major
difference between the original results and the results after matching. The trends
of the curves are consistent. After matching, the concepts can recover the perfor-
mance achieved by the features. The consequence was expected because it can
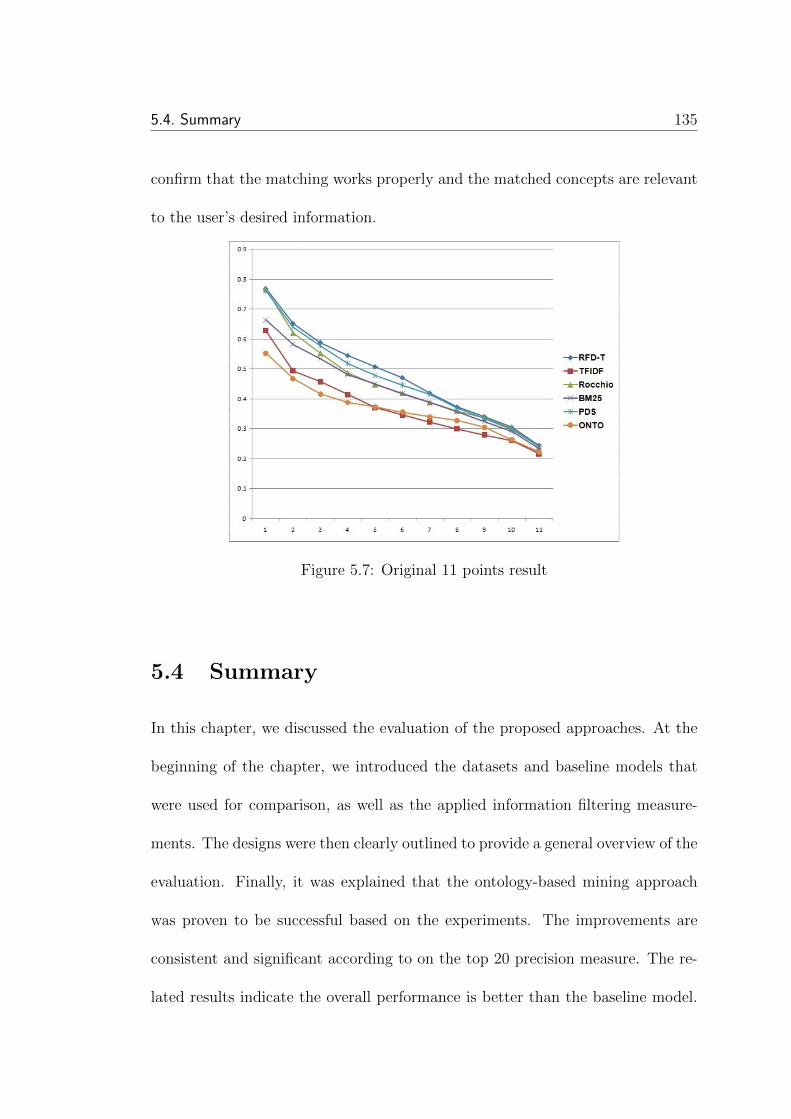
5.4. Summary 135
confirm that the matching works properly and the matched concepts are relevant
to the user’s desired information.
Figure 5.7: Original 11 points result
5.4 Summary
In this chapter, we discussed the evaluation of the proposed approaches. At the
beginning of the chapter, we introduced the datasets and baseline models that
were used for comparison, as well as the applied information filtering measure-
ments. The designs were then clearly outlined to provide a general overview of the
evaluation. Finally, it was explained that the ontology-based mining approach
was proven to be successful based on the experiments. The improvements are
consistent and significant according to on the top 20 precision measure. The re-
lated results indicate the overall performance is better than the baseline model.

136 Chapter 5. Evaluation
For the proposed matching approach, the substantial results show that it can suc-
cessfully address the problem of local instances and global knowledge mismatch,
and indicates an effective way to discover desired concepts by adopting relevance
features for building personalized ontologies. The dramatic improvements are
significant after comparison with three state-of- art IR, two popular text mining,
and one ontology-based baseline models. More importantly, three fundamental
points can be summarized based on the discussion in this chapter as follows:
1) The performance of the proposed matching approach is consistently better
for all feature selection models; 2) Based on the experimental results, there is
an accepted recommendation that: using the weighting function is better than
using the deploying method for concepts in the LCSH ontology; 3) The results
produced by the proposed matching approach are approximately equal to the
results from the state-of-art IR and effective data mining models.

Chapter 6
Conclusion
In this dissertation, we have proposed a potentially semantic and novel approach
to discover user search intent from personalized ontologies. The key aspect of
our innovation is the deployment of an ontology-based mining approach that fa-
cilitates responses to requests for information with high top 20 precision. The
approach constructs a backbone of a concept hierarchy to store relevant subjects
gained by a term-based search model. By learning the concepts and their refer-
ences from a general ontology, more potential relative concepts can be inferred
in other virtual levels and tracked in a two dimensional structure. An iterative
algorithm is developed to evaluate the performance level by level until meeting
the best result. A huge test bed was utilized for a number of experiments. The
gathered experimental results demonstrated that this approach is working and
137

138 Chapter 6. Conclusion
promising. It can enhance the search effectiveness within top precision. We
are also confident that the fundamental conceptual framework is sound, and its
implementation is feasible form a technical standpoint.
This dissertation has also introduced an automated approach to allocate local
information into global knowledge. This is a significant work that transfers low-
level features to high-level concepts. It builds a bridge to construct personalized
ontologies by adopting the results from different types of models. The approach
uses term-to-concept matching between user requests mined from documents and
concepts learned from a world ontology rather than keyword-to-keyword match-
ing. Therefore, the key problem in the use of this technique is to identify and
match appropriate concepts which describe specific items of interest to the user
on one hand, and on the other hand, to employ the candidate features in the
user information needs. It is critical to ensure that irrelevant concepts will not be
associated and matched, and that relevant concepts will not be discarded. To ad-
dress these concerns, the approach takes advantage of the theory of intension and
extension for concept selection. It is a creative attempt because the theory has
not been used in ontology learning, but only for granular and rough set mining.
The intension ensures that the relevant concepts would not be missed, whereas
the extension supplies possible relevant concepts. In evaluation, the standard as-
sessing topics and a huge testbed were employed for scientific experiments. The
overall results prove that the proposed approach is successful and reliable after
comparison with diverse baseline models.

139
The above innovations and developments enable us to make a claim that
the ontology-based technique will become more popular as a search mechanism
expected to offer intelligent service in the near future. In terms of our study,
data mining techniques are very effective to mine valuable information. At the
current stage, it is difficult for a pure ontology-based model to outperform the
data mining models for many reasons. One reason 1) is that the data mining
models always reply keywords or core features that are related to the keywords.
However, the keywords might disappear when the model describes the user need
in concepts. For example, the keywords “optical mouse” can help a user to
find the desired information. Once interpreted by the concept, the description
could change to “computer accessory”. As a result, the results would be totally
different. Another reason 2) for the poorer performance of a pure ontology-based
model is the length of a concept. In general, a concept consists of a small number
of terms. This factor is a limitation when a user directly uses the concept for
searching because the small number of terms provides restricted information to
present the user’s wants. Many data mining models have already proven that long
patterns achieve better results than short patterns. This is due to the fact that
the long patterns have sufficient terms to make the expression discriminatingly.
In addition, the data mining models have been trained according to the context
of documents, which is inoperational for the ontology-based models. The third
reason 3) is related to the ontologies themselves. The ontologies are developed by
domain experts for individual objectives. They might not cover all the concepts

140 Chapter 6. Conclusion
for each domain. This leads to a series of problems such as misinterpretation, lack
of content, and complexity in use. The last reason 4) is related to the ontology
evaluation. After producing an ontology for a model, researchers struggle with a
common issue that is, how to evaluate the ontology. There is no existing standard,
suitable measurement, or baseline recognized by most research communities for
ontology examination. Consequently, it is difficult to judge whether the ontology
is correct or not.
6.1 Future work
At this stage, two ontological mining approaches were developed separately though
they have the same objective. The first approach builds a backbone of person-
alized ontology based on the overlapping concepts of user proposed queries. In
order to improve the retrieval performance, the second approach was carried out
to match relevant concepts by relevance features extracted from local documents.
In other words, the second was proposed for serving the first approach. However,
the conduced evaluation had not provided the related contents after integrating
the two approaches to facilitate knowledge generalization process. As a result,
an urgent task for the next step is to look for the possibility of combing the two
approaches. An entire personalized ontology system is expected for discovering
desirable user information needs.
In future, we plan to investigate the use of learned ontologies by utilizing the
abundant semantic relations including part-of and related-to among concepts.

6.1. Future work 141
The part-of semantic relation is formalized in the LCSH by the reciprocal refer-
ences User-For and provides a mereological part-hood relationship between two
subjects. The related-to semantic relation is formally represented in the LCSH
as a bi-directional associative relationship Related-To in which two subjects are
linked in some manner other than hierarchy. It is noted that ontologies play an
important role as the backbone for facilitating access to information in knowledge
management systems. Consequently, how to properly take advantage of these re-
lations is an interesting question that is worth to study since the present work
aimed to define user wants in terms of extensive concepts in world knowledge. In
addition, we are quite interested in weight revising methods for performance en-
hancement. Future investigations would extend the applicability for the majority
of existing Web documents, and maximize the contribution of the present work.
For future study, we would also aim to try the approaches with other ontology
datasets, such as WordNet. This plan is motivated by the problem that the
existing LCSH dataset is a collection of library subject headings. Yet, in the
evaluation, the employed testing dataset was from a collection of news documents.
They look unitary and inconsistent. The WordNet dataset classifies all knowledge
into seven main separate categories. Each category is an individual ontology that
is useed to discuss a focused domain. In addition, the WordNet has relatively
complete relations that are similar to the LCSH but they are considered based on
a variety of words, including verbs, nouns, adjectives, and adverbs. Beside, we are
also interested in comparing with other language modeling approaches for XML

142 Chapter 6. Conclusion
component retrieval like the hierarchical language model (HLM) [82]. Because the
model can smooth with parent/child elements and differential weighting for each
element type. Once the personalized ontology is constructed from our approach, it
can be interpreted as a semi-structured document. In this sense, the representing
and ranking of scores for XML possibly can be applied.

Bibliography
[1] E. Agichtein, E. Brill, and S. Dumais. Improving web search ranking by
incorporating user behavior information. In Proceedings of the 29th ACM
SIGIR conference on Research and development in information retrieval
(SIGIR ’06), page 26. ACM, 2006.
[2] R. Agrawal, T. Imielinski, and A. Swami. Mining association rules between
sets of items in large databases. In ACM SIGMOD Record, volume 22,
pages 207–216. ACM, 1993.
[3] R. Agrawal and R. Srikant. Mining sequential patterns. In Data Engineer-
ing, 1995. Proceedings of the Eleventh International Conference on, pages
3–14. IEEE, 1995.
[4] R. Agrawal, R. Srikant, et al. Fast algorithms for mining association rules.
In Proc. 20th Int. Conf. Very Large Data Bases, VLDB, volume 1215, pages
487–499, 1994.
[5] A. Algarni, Y. Li, and X. Tao. Mining specific and general features in
both positive and negative relevance feedback. In Text Retrieval Conference
143

144 BIBLIOGRAPHY
(TREC 2009), 2009.
[6] G. Antoniou and F. Harmelen. Web ontology language: Owl. Handbook on
ontologies, pages 91–110, 2009.
[7] G. Antoniou and F. Van Harmelen. A semantic web primer. The MIT
Press, 2004.
[8] G. Antoniou and F. van Harmelen. A Semantic Web Primer, (Cooperative
Information Systems). 2008.
[9] F. Baader. The description logic handbook: theory, implementation, and
applications. Cambridge Univ Pr, 2003.
[10] R. Baeza-Yates, B. Ribeiro-Neto, et al. Modern information retrieval.
Addison-Wesley Reading, MA, 1999.
[11] R. J. Bayardo Jr. Efficiently mining long patterns from databases. In ACM
Sigmod Record, volume 27, pages 85–93. ACM, 1998.
[12] S. Bechhofer, F. Van Harmelen, J. Hendler, I. Horrocks, D. McGuinness,
P. Patel-Schneider, L. Stein, et al. OWL web ontology language reference.
W3C recommendation, 10:2006–01, 2004.
[13] N. Belkin and W. Croft. Information filtering and information retrieval:
two sides of the same coin? Communications of the ACM, 35(12):29–38,
1992.

BIBLIOGRAPHY 145
[14] T. Berners-Lee, J. Hendler, O. Lassila, et al. The semantic web. Scientific
american, 284(5):28–37, 2001.
[15] J. Bhogal, A. Macfarlane, and P. Smith. A review of ontology based query
expansion. Information Processing & Management, 43(4):866–886, 2007.
[16] C. Buckley and E. Voorhees. Evaluating evaluation measure stability. In
Proceedings of the 23rd ACM SIGIR conference on Research and develop-
ment in information retrieval (SIGIR ’00), pages 33–40, 2000.
[17] A. Carlyle. Matching LCSH and user vocabulary in the library catalog.
Cataloging & Classification Quarterly, 10(1):37–63, 1989.
[18] L. Chan. Library of Congress subject headings: principles of structure
and policies for application. Cataloging Distribution Service, Library of
Congress, 1990.
[19] L. Chan. Exploiting LCSH, LCC, and DDC To Retrieve Networked Re-
sources: Issues and Challenges. 2000.
[20] M. Chau, D. Zeng, and H. Chen. Personalized spiders for web search and
analysis. In Proceedings of the 1st ACM/IEEE-CS joint conference on Dig-
ital libraries, page 87. ACM, 2001.
[21] C. Chekuri, M. Goldwasser, P. Raghavan, and E. Upfal. Web search using
automatic classification. In Proceedings of the Sixth International Confer-
ence on the World Wide Web. Citeseer, 1997.

146 BIBLIOGRAPHY
[22] C. Chen, S. Hsu, Y. Li, and C. Peng. Personalized intelligent m-learning
system for supporting effective english learning. In Systems, Man and Cy-
bernetics, 2006. SMC’06. IEEE International Conference on, volume 6,
pages 4898–4903. IEEE, 2006.
[23] M. Chen and A. Hauptmann. Discriminative fields for modeling semantic
concepts in video. In Large Scale Semantic Access to Content (Text, Image,
Video, and Sound), pages 151–166. LE CENTRE DE HAUTES ETUDES
INTERNATIONALES D’INFORMATIQUE DOCUMENTAIRE, 2007.
[24] Y. Chen, T. Suel, and A. Markowetz. Efficient query processing in geo-
graphic web search engines. In Proceedings of the 2006 ACM SIGMOD
international conference on Management of data, page 288. ACM, 2006.
[25] P. Chirita, C. Firan, and W. Nejdl. Summarizing local context to person-
alize global web search. In Proceedings of the 15th ACM international con-
ference on Information and knowledge management, pages 287–296. ACM,
2006.
[26] P. Chirita, C. Firan, and W. Nejdl. Personalized query expansion for the
web. In Proceedings of the 30th ACM SIGIR conference on Research and
development in information retrieval (SIGIR ’07), pages 7–14. ACM, 2007.
[27] M. Craven, D. DiPasquo, D. Freitag, A. McCallum, T. Mitchell, K. Nigam,
and S. Slattery. Learning to construct knowledge bases from the world wide
web. Artificial Intelligence, 118(1):69–113, 2000.

BIBLIOGRAPHY 147
[28] W. Dakka and P. G. Ipeirotis. Automatic extraction of useful facet hierar-
chies from text databases. In Data Engineering, 2008. ICDE 2008. IEEE
24th International Conference on, pages 466–475. IEEE, 2008.
[29] Z. Dou, R. Song, J. Wen, and X. Yuan. Evaluating the Effectiveness of
Personalized Web Search. IEEE Transactions on Knowledge and Data En-
gineering, 21(8):1178–1190, 2009.
[30] U. Fayyad, G. Piatetsky-Shapiro, and P. Smyth. From data mining to
knowledge discovery in databases. AI magazine, 17(3):37, 1996.
[31] U. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy. Advances
in knowledge discovery and data mining. 1996.
[32] R. Feldman and J. Sanger. The text mining handbook: advanced approaches
in analyzing unstructured data. Cambridge University Press, 2006.
[33] D. Florescu, D. Kossmann, and I. Manolescu. Integrating keyword search
into XML query processing. Computer Networks, 33(1-6):119–135, 2000.
[34] M. Fontoura, V. Josifovski, R. Kumar, C. Olston, A. Tomkins, and S. Vas-
silvitskii. Relaxation in text search using taxonomies. Proceedings of the
VLDB Endowment, 1(1):672–683, 2008.
[35] S. Fox, K. Karnawat, M. Mydland, S. Dumais, and T. White. Evaluating
implicit measures to improve web search. ACM Transactions on Informa-
tion Systems (TOIS), 23(2):168, 2005.

148 BIBLIOGRAPHY
[36] W. Frawley, G. Piatetsky-Shapiro, and C. Matheus. Knowledge discovery
in databases: An overview. AI magazine, 13(3):57, 1992.
[37] B. Gaines and M. Shaw. Supporting the creativity cycle through visual
languages. In AAAI Spring Symposium: AI and Creativity, pages 155–162,
1993.
[38] E. Garcia and M. Sicilia. User interface tactics in ontology-based informa-
tion seeking. PsychNology Journal, 1(3):242–255, 2003.
[39] S. Gauch, J. Chaffee, and A. Pretschner. Ontology-based personalized
search and browsing. Web Intelligence and Agent Systems, 1(3):219–234,
2003.
[40] F. Giunchiglia, D. Soergel, V. Maltese, and A. Bertacco. Mapping large-
scale knowledge organization systems. Technical report, University of
Trento, 2009.
[41] C. Govindarajulu and B. J. Reithel. Beyond the information center: an
instrument to measure end-user computing support from multiple sources.
Information & management, 33(5):241–250, 1998.
[42] B. Grau. A possible simplification of the semantic web architecture. In
Proceedings of the 13th international conference on World Wide Web, pages
704–713. ACM, 2004.

BIBLIOGRAPHY 149
[43] J. Han, H. Cheng, D. Xin, and X. Yan. Frequent pattern mining: cur-
rent status and future directions. Data Mining and Knowledge Discovery,
15(1):55–86, 2007.
[44] J. Han and Y. Fu. Dynamic generation and refinement of concept hierar-
chies for knowledge discovery in databases. In Proc. Aaai, volume 94, pages
157–168, 1994.
[45] J. Han, S. Nishio, H. Kawano, and W. Wang. Generalization-based data
mining in object-oriented databases using an object cube model. Data &
Knowledge Engineering, 25(1):55–97, 1998.
[46] J. Han, J. Pei, B. Mortazavi-Asl, Q. Chen, U. Dayal, and M. Hsu. Freespan:
frequent pattern-projected sequential pattern mining. In Proceedings of the
sixth ACM SIGKDD international conference on Knowledge discovery and
data mining, pages 355–359. ACM, 2000.
[47] J. Han, J. Pei, B. Mortazavi-Asl, H. Pinto, Q. Chen, U. Dayal, and M. Hsu.
Prefixspan: Mining sequential patterns efficiently by prefix-projected pat-
tern growth. In Proceedings of the 17th International Conference on Data
Engineering, pages 215–224, 2001.
[48] J. Han, J. Pei, Y. Yin, and R. Mao. Mining frequent patterns without
candidate generation: A frequent-pattern tree approach. Data mining and
knowledge discovery, 8(1):53–87, 2004.

150 BIBLIOGRAPHY
[49] M. Henzinger, R. Motwani, and C. Silverstein. Challenges in web search
engines. In ACM SIGIR Forum, volume 36, page 22. ACM, 2002.
[50] D. Hiemstra. A probabilistic justification for using tf× idf term weighting in
information retrieval. International Journal on Digital Libraries, 3(2):131–
139, 2000.
[51] S. Jaroszewicz and D. Simovici. Interestingness of frequent itemsets using
bayesian networks as background knowledge. In Proceedings of the tenth
ACM SIGKDD international conference on Knowledge discovery and data
mining, pages 178–186. ACM, 2004.
[52] X. Jiang and A. Tan. Learning and inferencing in user ontology for per-
sonalized Semantic Web search. Information Sciences, 179(16):2794–2808,
2009.
[53] T. Joachims. A probabilistic analysis of the rocchio algorithm with tfidf for
text categorization. Technical report, DTIC Document, 1996.
[54] Y. Kalfoglou and M. Schorlemmer. Ontology mapping: the state of the art.
The knowledge engineering review, 18(01):1–31, 2003.
[55] K. Keenoy and M. Levene. Personalisation of web search. Intelligent Tech-
niques for Web Personalization, pages 201–228, 2005.
[56] I. Keleberda, V. Repka, and Y. Biletskiy. Building learner’s ontologies to
assist personalized search of learning objects. In Proceedings of the 8th

BIBLIOGRAPHY 151
international conference on Electronic commerce: The new e-commerce:
innovations for conquering current barriers, obstacles and limitations to
conducting successful business on the internet, page 573. ACM, 2006.
[57] D. Kelly and J. Teevan. Implicit feedback for inferring user preference: a
bibliography. In ACM SIGIR Forum, volume 37, pages 18–28. ACM, 2003.
[58] L. Khan and F. Luo. Ontology construction for information selection. In
Proceedings of the 14th 2002 IEEE International Conference on Tools with
Artificial Intelligence, pages 122–127, 2002.
[59] J. King, Y. Li, X. Tao, and R. Nayak. Mining world knowledge for analysis
of search engine content. Web Intelligence and Agent Systems, 5(3):233–
253, 2007.
[60] A. J. Knobbe and E. K. Ho. Pattern teams. In Knowledge Discovery in
Databases: PKDD 2006, pages 577–584. Springer, 2006.
[61] H. Kum, J. Pei, W. Wang, and D. Duncan. Approxmap: Approximate
mining of consensus sequential patterns. In Proceedings of SIAM Int. Conf.
on Data Mining, 2003.
[62] S. Lawrence. Context in web search. Bulletin of the Technical Committee
on, page 25, 2000.

152 BIBLIOGRAPHY
[63] M. Lee, K. Tsai, and T. Wang. A practical ontology query expansion
algorithm for semantic-aware learning objects retrieval. Computers & Ed-
ucation, 50(4):1240–1257, 2008.
[64] H. Leighton and J. Srivastava. First 20 precision among world wide web
search services(search engines). Journal of the American Society for Infor-
mation Science, 50(10):870–881, 1999.
[65] Y. Li, A. Algarni, and N. Zhong. Mining positive and negative patterns
for relevance feature discovery. In Proceedings of the 16th ACM SIGKDD
conference on Knowledge discovery and Data mining (KDD ’10), pages
753–762, 2010.
[66] Y. Li and N. Zhong. Mining ontology for automatically acquiring web user
information needs. IEEE Transactions on Knowledge and Data Engineer-
ing, 18(4):554–568, 2006.
[67] Y. Li, X. Zhou, P. Bruza, Y. Xu, and R. Lau. A two-stage text mining
model for information filtering. In Proceedings of the 17th ACM conference
on Information and Knowledge Management (CIKM ’08), pages 1023–1032,
2008.
[68] F. Liu, C. Yu, and W. Meng. Personalized web search for improving re-
trieval effectiveness. IEEE Transactions on knowledge and data engineering,
16(1):28–40, 2004.

BIBLIOGRAPHY 153
[69] H. Liu and H. Motoda. Feature selection for knowledge discovery and data
mining. Springer, 1998.
[70] X. Long and T. Suel. Three-level caching for efficient query processing in
large web search engines. World Wide Web, 9(4):369–395, 2006.
[71] A. Maedche. Ontology learning for the semantic web. Springer Netherlands,
2002.
[72] A. Maedche and S. Staab. Learning ontologies for the semantic web. IEEE
Intelligent Systems, 16(2):72–79, 2001.
[73] M. Mampaey, N. Tatti, and J. Vreeken. Tell me what i need to know: suc-
cinctly summarizing data with itemsets. In Proceedings of the 17th ACM
SIGKDD international conference on Knowledge discovery and data min-
ing, pages 573–581. ACM, 2011.
[74] F. Manola and E. Miller. RDF Primer. W3C Recommendation
(2004). World Wide Web Consortium (W3C),¡ http://www. w3.
org/TR/2004/REC-rdf-primer-20040210/¿(Last access date: 30 Aug
2004).
[75] W. Mischo. Library of Congress Subject Headings. Cataloging & Classifi-
cation Quarterly, 1(2):105–124, 1982.
[76] N. Nanas, V. Uren, and A. De Roeck. A comparative evaluation of term
weighting methods for information filtering. In Proceedings of the 4th

154 BIBLIOGRAPHY
IEEE International Workshop on natural language and information sys-
tems (NLIS ’04), pages 13–17, 2004.
[77] M. Naphade, L. Kennedy, J. Kender, S. Chang, J. Smith, P. Over, and
A. Hauptmann. A light scale concept ontology for multimedia understand-
ing for trecvid 2005. IBM Research Report RC23612 (W0505-104), 2005.
[78] R. Navigli and P. Velardi. An analysis of ontology-based query expan-
sion strategies. In Proceedings of the 14th European Conference on Ma-
chine Learning, Workshop on Adaptive Text Extraction and Mining, Cavtat-
Dubrovnik, Croatia, pages 42–49, 2003.
[79] R. Navigli, P. Velardi, and A. Gangemi. Ontology learning and its appli-
cation to automated terminology translation. IEEE Intelligent Systems,
18(1):22–31, 2003.
[80] N. Noy. Semantic integration: a survey of ontology-based approaches. SIG-
MOD record, 33(4):65–70, 2004.
[81] D. Oberle, R. Volz, B. Motik, and S. Staab. An extensible ontology soft-
ware environment. Handbook on Ontologies, International Handbooks on
Information Systems, pages 311–333, 2004.
[82] P. Ogilvie and J. Callan. Hierarchical language models for xml compo-
nent retrieval. In Advances in XML Information Retrieval, pages 224–237.
Springer, 2005.

BIBLIOGRAPHY 155
[83] J. Pei, J. Han, and W. Wang. Constraint-based sequential pattern mining:
the pattern-growth methods. Journal of Intelligent Information Systems,
28(2):133–160, 2007.
[84] U. Priss. Formal concept analysis in information science. Annual review of
information science and technology, 40:521, 2006.
[85] S. Robertson and I. Soboroff. The trec 2002 filtering track report. In
Proceedings of the 10th Text REtrieval Conference (TREC ’01), pages 26–
37, 2002.
[86] S. Robertson, S. Walker, and M. Beaulieu. Experimentation as a way of
life: Okapi at trec. Information Processing & Management, 36(1):95–108,
2000.
[87] D. Rose and D. Levinson. Understanding user goals in web search. In
Proceedings of the 13th international conference on World Wide Web, pages
13–19. ACM, 2004.
[88] G. Salton and C. Buckley. Term-weighting approaches in automatic text
retrieval. Information processing & management, 24(5):513–523, 1988.
[89] G. Salton and M. McGill. Introduction to modern information retrieval.
McGraw-Hill New York, 1983.
[90] M. Sanderson and B. Croft. Deriving concept hierarchies from text. In
Proceedings of the 22nd annual international ACM SIGIR conference on

156 BIBLIOGRAPHY
Research and development in information retrieval, pages 206–213. ACM,
1999.
[91] B. Sarwar, G. Karypis, J. Konstan, and J. Riedl. Item-based collaborative
filtering recommendation algorithms. In Proceedings of the 10th interna-
tional conference on World Wide Web, pages 285–295. ACM, 2001.
[92] V. Schickel-Zuber and B. Faltings. Inferring user’s preferences using on-
tologies. In Proceedings of the national conference on artificial intelligence,
volume 21, page 1413. Menlo Park, CA; Cambridge, MA; London; AAAI
Press; MIT Press; 1999, 2006.
[93] F. Sebastiani. Machine learning in automated text categorization. ACM
computing surveys (CSUR), 34(1):1–47, 2002.
[94] S. Sendhilkumar and T. Geetha. Personalized ontology for web search per-
sonalization. In Proceedings of the 1st Bangalore annual Compute confer-
ence, page 18. ACM, 2008.
[95] C. Shahabi and Y. Chen. Web information personalization: Challenges
and approaches. Databases in Networked Information Systems, pages 5–15,
2003.
[96] X. Shen, B. Tan, and C. Zhai. Context-sensitive information retrieval using
implicit feedback. In Proceedings of the 28th annual international ACM
SIGIR conference on Research and development in information retrieval,
page 50. ACM, 2005.

BIBLIOGRAPHY 157
[97] Y. Shen, Y. Li, Y. Xu, R. Iannella, A. Algarni, and X. Tao. An ontology-
based mining approach for user search intent discovery. In Proceedings of the
16th Australasian Document Computing Symposium (ADCS 2011), pages
39–46. Royal Melbourne Institute of Technology, 2011.
[98] A. Sieg, B. Mobasher, and R. Burke. Web search personalization with
ontological user profiles. In Proceedings of the 16th ACM conference on In-
formation and Knowledge Management (CIKM ’07), pages 525–534, 2007.
[99] A. Silberschatz and A. Tuzhilin. What makes patterns interesting in knowl-
edge discovery systems. Knowledge and Data Engineering, IEEE Transac-
tions on, 8(6):970–974, 1996.
[100] I. Soboroff and S. Robertson. Building a filtering test collection for trec
2002. In Proceedings of the 26th ACM SIGIR conference on Research and
development in informaion retrieval (SIGIR ’03), pages 243–250, 2003.
[101] R. Srikant and R. Agrawal. Mining sequential patterns: Generalizations and
performance improvements. Advances in Database TechnologyEDBT’96,
pages 1–17, 1996.
[102] S. Staab and R. Studer. Handbook on ontologies. Springer Verlag, 2004.
[103] P. Tan, V. Kumar, and J. Srivastava. Selecting the right interesting-
ness measure for association patterns. In Proceedings of the eighth ACM
SIGKDD international conference on Knowledge discovery and data min-
ing, pages 32–41. ACM, 2002.

158 BIBLIOGRAPHY
[104] X. Tao, Y. Li, and N. Zhong. A personalized ontology model for web infor-
mation gathering. IEEE Transactions on Knowledge and Data Engineering,
23(4):496–511, 2011.
[105] X. Tao, Y. Li, N. Zhong, and R. Nayak. Ontology mining for personalized-
web information gathering. In Proceedings of the IEEE/WIC/ACM Inter-
national Conference on Web Intelligence, pages 351–358. IEEE Computer
Society, 2007.
[106] X. Tao, Y. Li, N. Zhong, and R. Nayak. An ontology-based framework for
knowledge retrieval. In IEEE/WIC/ACM International Conference on Web
Intelligence and Intelligent Agent Technology, 2008. WI-IAT’08, volume 1,
2008.
[107] S. Tata and J. Patel. Estimating the selectivity of tf-idf based cosine simi-
larity predicates. ACM SIGMOD Record, 36(2):7–12, 2007.
[108] N. Tatti. Maximum entropy based significance of itemsets. Knowledge and
Information Systems, 17(1):57–77, 2008.
[109] J. Trajkova and S. Gauch. Improving ontology-based user profiles. In
Proceedings of Conference Adaptivity, Personalization and Fusion of Het-
erogeneous Information (RIAO ’04), volume 4, pages 380–389, 2004.
[110] F. Van Harmelen and D. McGuinness. OWL web ontology lan-
guage overview. World Wide Web Consortium (W3C) recommendation,
http://www. w3. org/TR/2004/REC-owl-features-20040210, 2004.

BIBLIOGRAPHY 159
[111] C. Van Rijsbergen. Information retrieval, chapter 7. Butterworths, London,
2:111–143, 1979.
[112] A. Varzi. Spatial reasoning and ontology: parts, wholes, and locations.
Handbook of Spatial Logics, pages 945–1038, 2007.
[113] E. Voorhees. Query expansion using lexical-semantic relations. In Pro-
ceedings of the 17th annual international ACM SIGIR conference on Re-
search and development in information retrieval, pages 61–69. Springer-
Verlag New York, Inc., 1994.
[114] B. Wang, R. McKay, H. Abbass, and M. Barlow. A comparative study
for domain ontology guided feature extraction. In Proceedings of the 26th
Australasian computer science conference, volume 16, pages 69–78, 2003.
[115] T. Wang, B. Parsia, and J. Hendler. A survey of the web ontology landscape.
The Semantic Web-ISWC 2006, pages 682–694, 2006.
[116] R. White, J. Jose, and I. Ruthven. Comparing explicit and implicit feed-
back techniques for web retrieval: Trec-10 interactive track report. NIST
SPECIAL PUBLICATION SP, pages 534–538, 2002.
[117] R. White, I. Ruthven, and J. Jose. The use of implicit evidence for relevance
feedback in web retrieval. Advances in Information Retrieval, pages 449–
479, 2002.

160 BIBLIOGRAPHY
[118] S. Wu, Y. Li, and Y. Xu. Deploying approaches for pattern refinement in
text mining. In Proceedings of the 6th IEEE Conference on Data Mining
(ICDM ’06), pages 1157–1161, 2006.
[119] S. Wu, Y. Li, Y. Xu, B. Pham, and P. Chen. Automatic pattern-taxonomy
extraction for web mining. In Proceedings of IEEE/WIC/ACM Interna-
tional Conference on Web Intelligence (WI ’04), pages 242–248, 2004.
[120] D. Xin, X. Shen, Q. Mei, and J. Han. Discovering interesting patterns
through user’s interactive feedback. In Proceedings of the 12th ACM
SIGKDD international conference on Knowledge discovery and data min-
ing, pages 773–778. ACM, 2006.
[121] X. Yan, H. Cheng, J. Han, and D. Xin. Summarizing itemset patterns:
a profile-based approach. In Proceedings of the eleventh ACM SIGKDD
international conference on Knowledge discovery in data mining, pages 314–
323. ACM, 2005.
[122] H. Yang and C. Liu. A new standard of on-line customer service process:
Integrating language-action into blogs. Computer Standards & Interfaces,
31(1):227–245, 2009.
[123] Y. Yang and J. Pedersen. A comparative study on feature selection in text
categorization. In MACHINE LEARNING-INTERNATIONAL WORK-
SHOP THEN CONFERENCE-, pages 412–420. MORGAN KAUFMANN
PUBLISHERS, INC., 1997.

BIBLIOGRAPHY 161
[124] Y. Yao. On modeling data mining with granular computing. In Com-
puter Software and Applications Conference, 2001. COMPSAC 2001. 25th
Annual International, pages 638–643. IEEE, 2001.
[125] L. Yu and H. Liu. Efficient feature selection via analysis of relevance and
redundancy. The Journal of Machine Learning Research, 5:1205–1224, 2004.
[126] D. Yuan, D. Liu, S. Shen, and P. Yan. Improved semantic retrieval method
based on domain ontology. In Proceedings of the 6th international confer-
ence on Fuzzy systems and knowledge discovery-Volume 1, pages 207–211.
IEEE Press, 2009.
[127] L. Zadeh. Web intelligence and world knowledge-the concept of web iq
(wiq). In Fuzzy Information, 2004. Processing NAFIPS’04. IEEE Annual
Meeting of the, volume 1, pages 1–3. IEEE, 2004.
[128] M. Zaki. Scalable algorithms for association mining. Knowledge and Data
Engineering, IEEE Transactions on, 12(3):372–390, 2000.
[129] M. Zaki. Spade: An efficient algorithm for mining frequent sequences.
Machine Learning, 42(1):31–60, 2001.
[130] M. J. Zaki. Generating non-redundant association rules. In Proceedings of
the sixth ACM SIGKDD international conference on Knowledge discovery
and data mining, pages 34–43. ACM, 2000.

162 BIBLIOGRAPHY
[131] L. Zhang, Y. Yu, J. Zhou, C. Lin, and Y. Yang. An enhanced model
for searching in semantic portals. In Proceedings of the 14th international
conference on World Wide Web, page 462. ACM, 2005.
[132] N. Zhong. Representation and construction of ontologies for Web in-
telligence. International Journal of Foundations of Computer Science,
13(4):555–570, 2002.
[133] N. Zhong, Y. Li, and S. Wu. Effective pattern discovery for text mining.
IEEE Transactions on Knowledge and Data Engineering, 24(1):30–44, 2012.
[134] X. Zhou, S. Wu, Y. Li, Y. Xu, R. Lau, and P. Bruza. Utilizing search intent
in topic ontology-based user profile for web mining. In IEEE/WIC/ACM
International Conference on Web Intelligence, 2006. WI 2006, pages 558–
564, 2006.
[135] A. Zhu, J. Pedro, and T. Cunha. Pruning the volterra series for behavioral
modeling of power amplifiers using physical knowledge. Microwave Theory
and Techniques, IEEE Transactions on, 55(5):813–821, 2007.


















