
Performance-Cost Trade-offs in Heterogeneous...
89
PhD Candidate: Anca Iordache Supervised by Guillaume Pierre Myriads Research Team Performance-Cost Trade-os in Heterogeneous Clouds /
Transcript of Performance-Cost Trade-offs in Heterogeneous...

PhD Candidate: Anca IordacheSupervised by Guillaume PierreMyriads Research Team
Performance-Cost Trade-offs inHeterogeneous Clouds
1/33
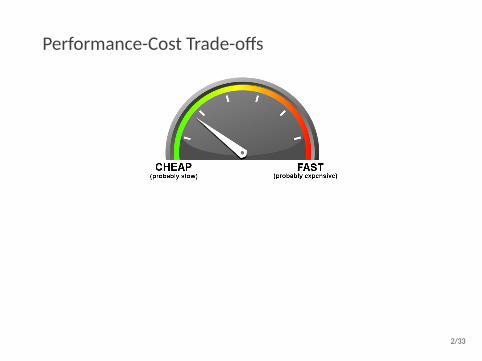
Performance-Cost Trade-offs
Example:
• 10-100TB input data
2/33
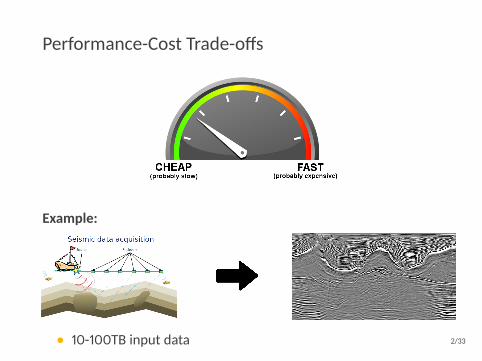
Performance-Cost Trade-offs
Example:
• 10-100TB input data 2/33
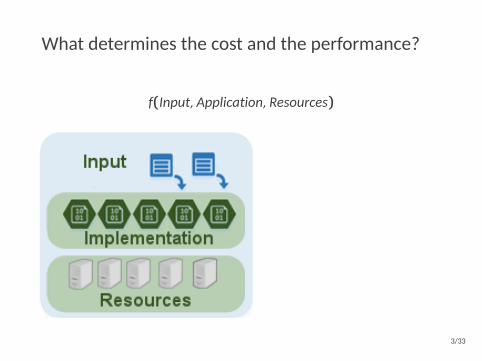
What determines the cost and the performance?
f(Input,Application,Resources)
7 against the purpose of theexecution
7 not application agnostic
3 many options provided byclouds
3/33
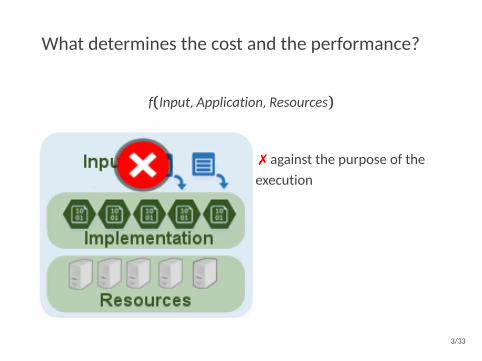
What determines the cost and the performance?
f(Input,Application,Resources)
7 against the purpose of theexecution
7 not application agnostic
3 many options provided byclouds
3/33
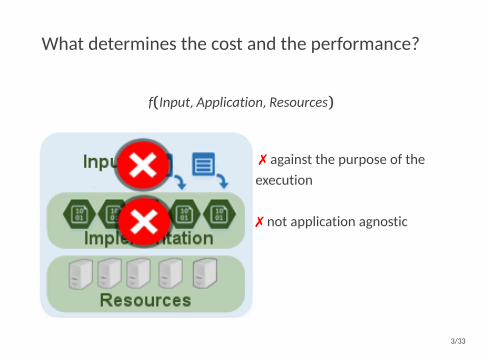
What determines the cost and the performance?
f(Input,Application,Resources)
7 against the purpose of theexecution
7 not application agnostic
3 many options provided byclouds
3/33
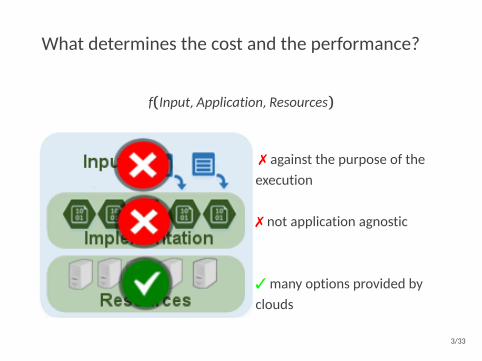
What determines the cost and the performance?
f(Input,Application,Resources)
7 against the purpose of theexecution
7 not application agnostic
3 many options provided byclouds
3/33

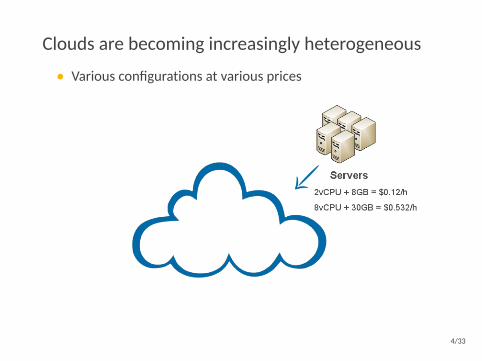
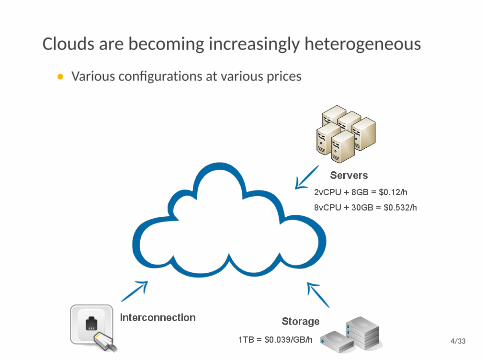
Clouds are becoming increasingly heterogeneous
• Various configurations at various prices
4/33
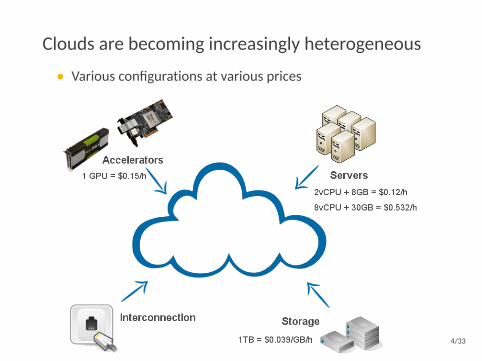
Clouds are becoming increasingly heterogeneous
• Various configurations at various prices
4/33
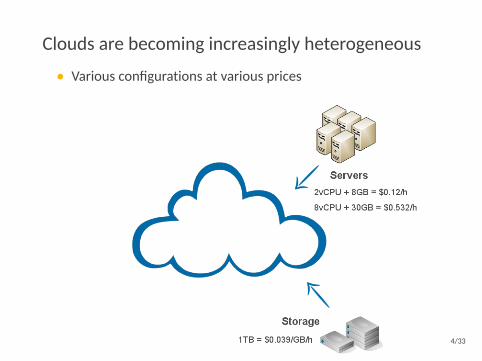
Clouds are becoming increasingly heterogeneous
• Various configurations at various prices
4/33
Clouds are becoming increasingly heterogeneous
• Various configurations at various prices
4/33
Clouds are becoming increasingly heterogeneous
• Various configurations at various prices
4/33

Challenges
To get the best performance-cost trade-offs we need to:
• Make good use of existing resources
• Choose cloud resources carefully
• Make these technologies available to the users
5/33

Contributions of this Thesis
I. Make good use of resources
• Improving resource utilization in the context of FPGAaccelerators
II. Make a good choice of resources
• Resource selection based on performance profiling
III. Integrate in a heterogeneous cloud platform
• We demonstrate how to use these technologies in aheterogeneous cloud.
6/33

Contributions of this Thesis
I. Make good use of resources
• Improving resource utilization in the context of FPGAaccelerators
II. Make a good choice of resources
• Resource selection based on performance profiling
III. Integrate in a heterogeneous cloud platform
• We demonstrate how to use these technologies in aheterogeneous cloud.
6/33

Contributions of this Thesis
I. Make good use of resources
• Improving resource utilization in the context of FPGAaccelerators
II. Make a good choice of resources
• Resource selection based on performance profiling
III. Integrate in a heterogeneous cloud platform
• We demonstrate how to use these technologies in aheterogeneous cloud.
6/33

Contributions of this Thesis
I. Make good use of resources
• Improving resource utilization in the context of FPGAaccelerators
II. Make a good choice of resources
• Resource selection based on performance profiling
III. Integrate in a heterogeneous cloud platform
• We demonstrate how to use these technologies in aheterogeneous cloud.
6/33

Contributions of this Thesis
I. Make good use of resources
• Improving resource utilization in the context of FPGAaccelerators
II. Make a good choice of resources
• Resource selection based on performance profiling
III. Integrate in a heterogeneous cloud platform
• We demonstrate how to use these technologies in aheterogeneous cloud.
6/33

Contributions of this Thesis
I. Make good use of resources
• Improving resource utilization in the context of FPGAaccelerators
II. Make a good choice of resources
• Resource selection based on performance profiling
III. Integrate in a heterogeneous cloud platform
• We demonstrate how to use these technologies in aheterogeneous cloud.
6/33

Contributions of this Thesis
I. Make good use of resources
• Improving resource utilization in the context of FPGAaccelerators
II. Make a good choice of resources
• Resource selection based on performance profiling
III. Integrate in a heterogeneous cloud platform
• We demonstrate how to use these technologies in aheterogeneous cloud.
6/33

Contribution I: Improving FPGAutilization1
1Democratizing High Performance in the Cloud with FPGA Groups. AncaIordache, Peter Sanders, Jose Gabriel de Figueiredo Coutinho, Mark Stillwell andGuillaume Pierre. In Proceedings of the 9th IEEE/ACM International Conference onUtility and Cloud Computing (UCC 2016)
7/33

FPGAs: Next Generation Acceleration Devices
Field-Programmable Gate Arrays (FPGA)
• FPGAs are reconfigurable digital circuits
• When applied to suitable applications, FPGAs provide excellentperformance-cost trade-offs
• Microsoft’s Catapult project 2015: 2x performance for +10%power consumption
• Intel: Xeon-FPGA chip release in 2014, Altera acquisition in 2015
“Up to 1/3 of servers in a datacenter will host an FPGA by 2020.”
8/33

FPGAs: Next Generation Acceleration Devices
Field-Programmable Gate Arrays (FPGA)
• FPGAs are reconfigurable digital circuits
• When applied to suitable applications, FPGAs provide excellentperformance-cost trade-offs
• Microsoft’s Catapult project 2015: 2x performance for +10%power consumption
• Intel: Xeon-FPGA chip release in 2014, Altera acquisition in 2015
“Up to 1/3 of servers in a datacenter will host an FPGA by 2020.”
8/33

FPGAs: Next Generation Acceleration Devices
Field-Programmable Gate Arrays (FPGA)
• FPGAs are reconfigurable digital circuits
• When applied to suitable applications, FPGAs provide excellentperformance-cost trade-offs
• Microsoft’s Catapult project 2015: 2x performance for +10%power consumption
• Intel: Xeon-FPGA chip release in 2014, Altera acquisition in 2015
“Up to 1/3 of servers in a datacenter will host an FPGA by 2020.”
8/33

FPGAs: Next Generation Acceleration Devices
Field-Programmable Gate Arrays (FPGA)
• FPGAs are reconfigurable digital circuits
• When applied to suitable applications, FPGAs provide excellentperformance-cost trade-offs
• Microsoft’s Catapult project 2015: 2x performance for +10%power consumption
• Intel: Xeon-FPGA chip release in 2014, Altera acquisition in 2015
“Up to 1/3 of servers in a datacenter will host an FPGA by 2020.”
8/33

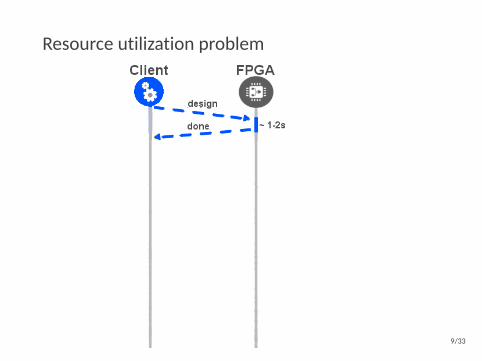
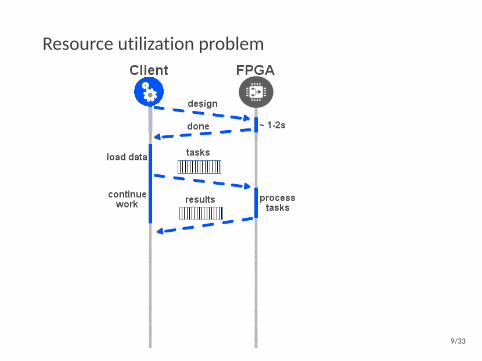
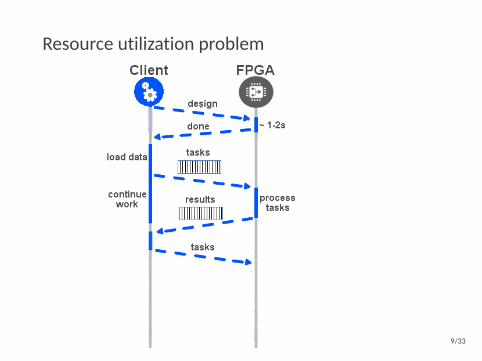
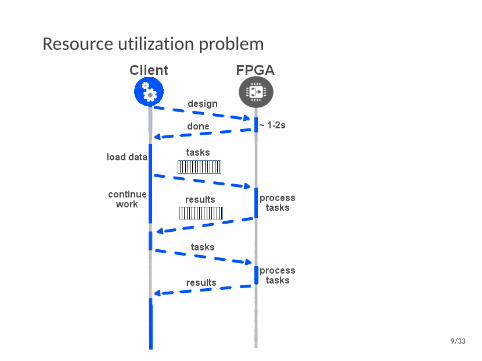
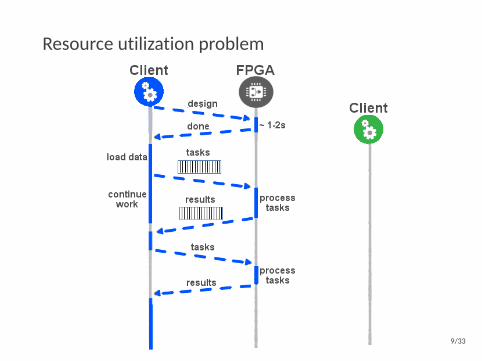
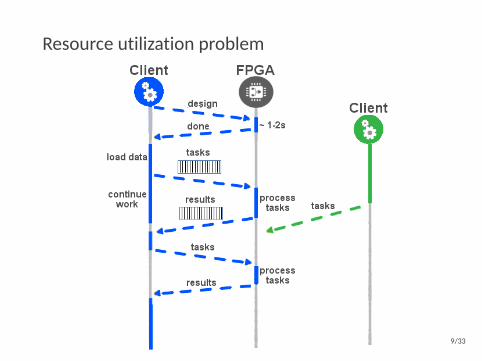
Resource utilization problem
9/33
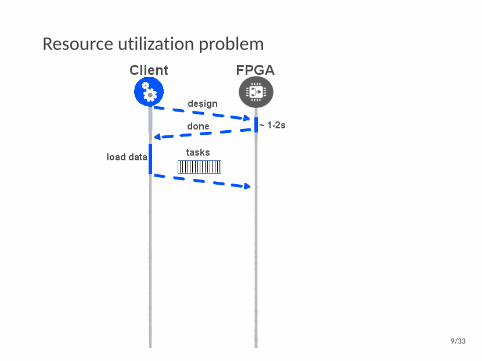
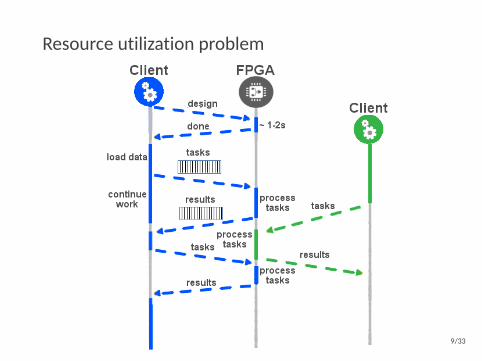
Resource utilization problem
9/33
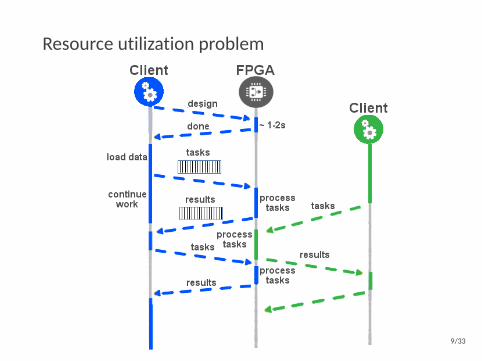
Resource utilization problem
9/33
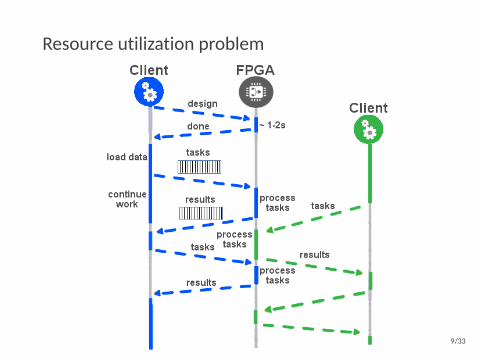
Resource utilization problem
9/33
Resource utilization problem
9/33
Resource utilization problem
9/33
Resource utilization problem
9/33
Resource utilization problem
9/33
Resource utilization problem
9/33
Resource utilization problem
9/33
Resource utilization problem
9/33
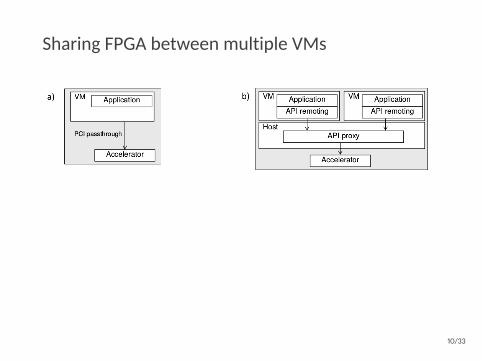
Sharing FPGA between multiple VMs
No sharing Limited sharing
Unlimited sharing
10/33
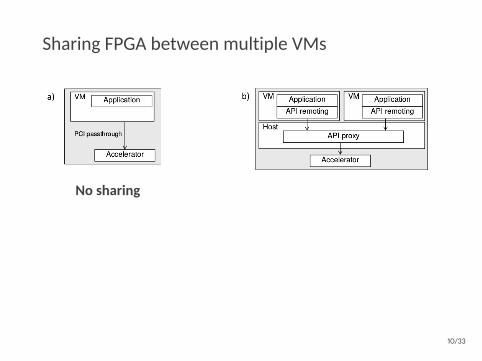
Sharing FPGA between multiple VMs
No sharing
Limited sharing
Unlimited sharing
10/33
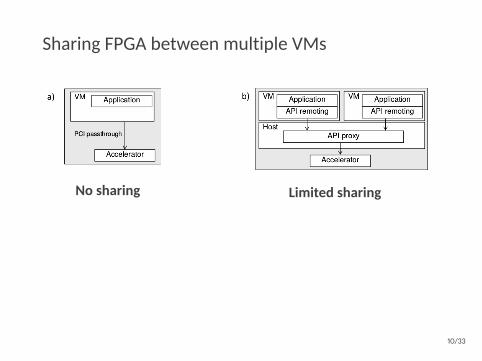
Sharing FPGA between multiple VMs
No sharing Limited sharing
Unlimited sharing
10/33
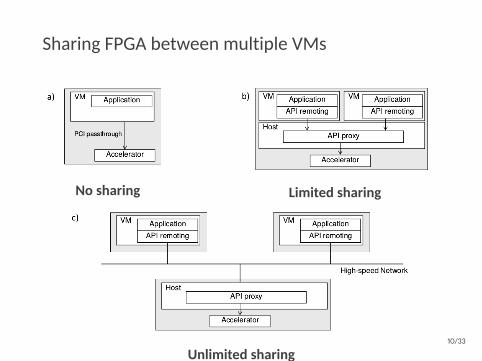
Sharing FPGA between multiple VMs
No sharing Limited sharing
Unlimited sharing10/33
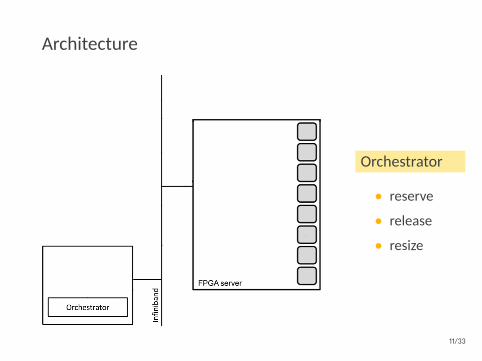
Architecture
Orchestrator
• reserve
• release
• resize
11/33
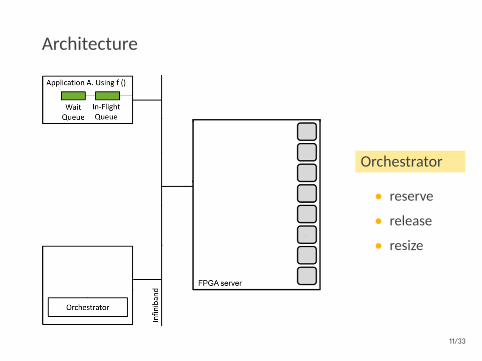
Architecture
Orchestrator
• reserve
• release
• resize
11/33
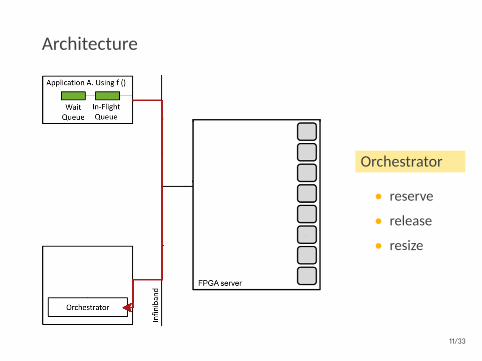
Architecture
Orchestrator
• reserve
• release
• resize
11/33
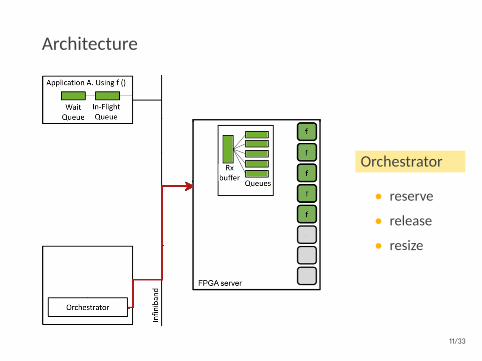
Architecture
Orchestrator
• reserve
• release
• resize
11/33
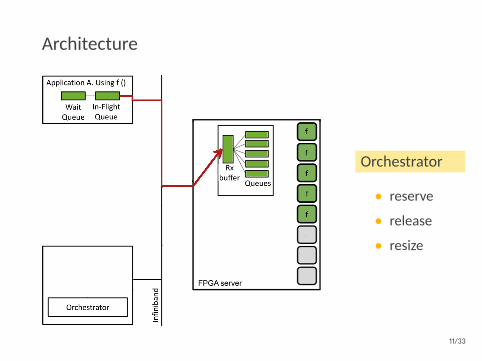
Architecture
Orchestrator
• reserve
• release
• resize
11/33
Evaluation: Virtualization Overhead
VS
Workload : Submission of 1 task (0.33 ms) every second for aninterval of 600s.
0.0 0.5 1.0 1.5 2.0 2.5Latency (ms)
0
1
2
3
4
5
6
Pro
babi
lity
dens
ity
0.78
0.87 Physical FPGA
V irtual FPGA
0.09ms/task performance overhead
12/33
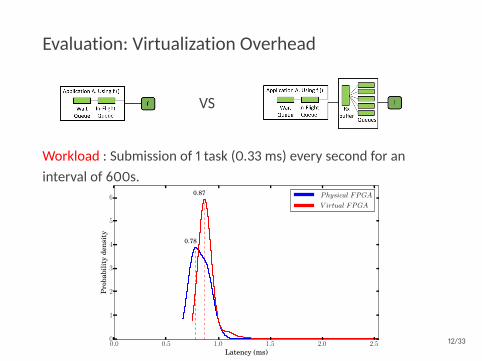
Evaluation: Virtualization Overhead
VS
Workload : Submission of 1 task (0.33 ms) every second for aninterval of 600s.
0.0 0.5 1.0 1.5 2.0 2.5Latency (ms)
0
1
2
3
4
5
6
Pro
babi
lity
dens
ity
0.78
0.87 Physical FPGA
V irtual FPGA
0.09ms/task performance overhead
12/33
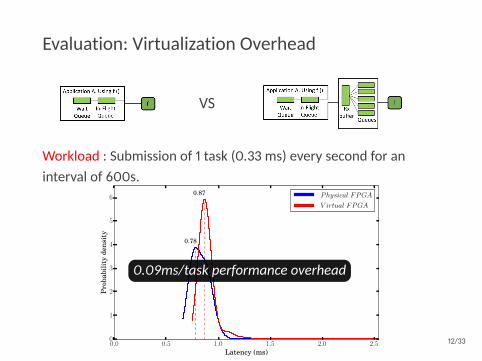
Evaluation: Virtualization Overhead
VS
Workload : Submission of 1 task (0.33 ms) every second for aninterval of 600s.
0.0 0.5 1.0 1.5 2.0 2.5Latency (ms)
0
1
2
3
4
5
6
Pro
babi
lity
dens
ity
0.78
0.87 Physical FPGA
V irtual FPGA
0.09ms/task performance overhead
12/33
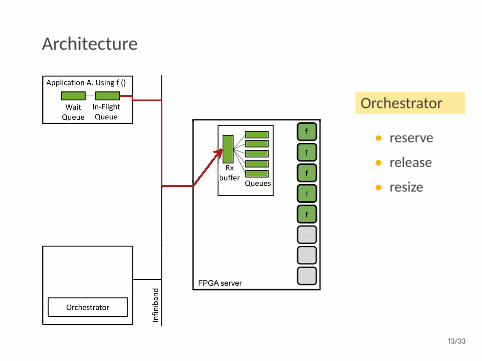
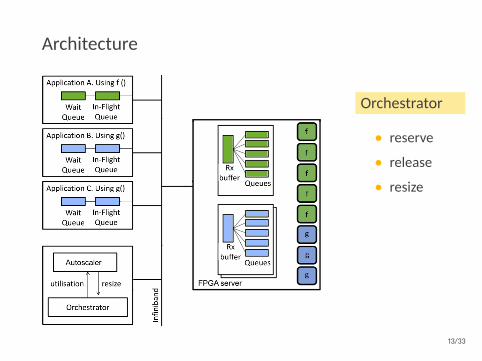
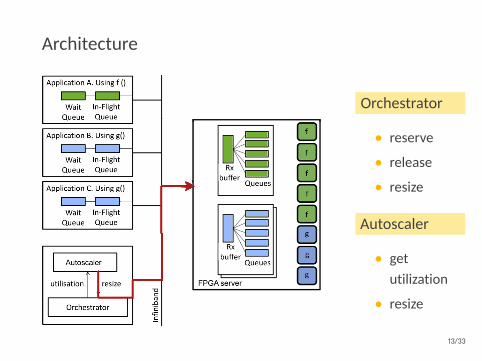
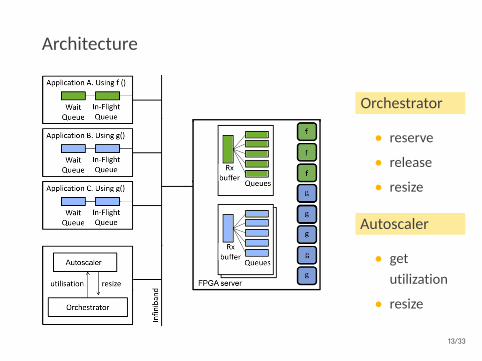
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
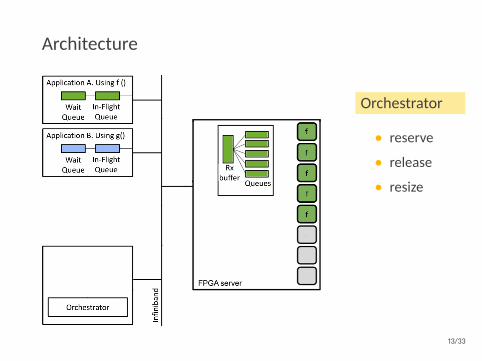
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
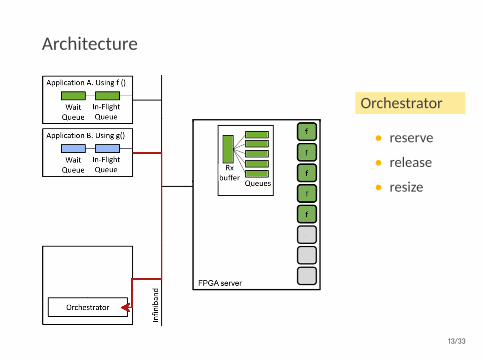
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
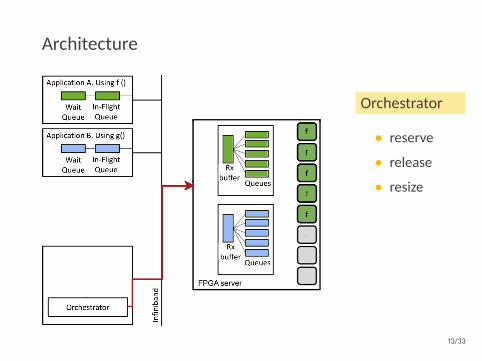
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
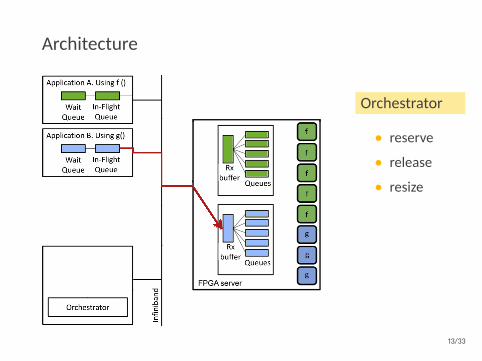
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
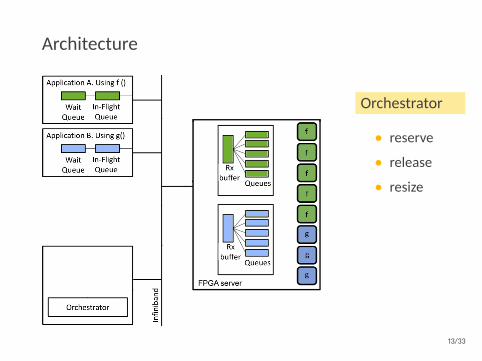
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
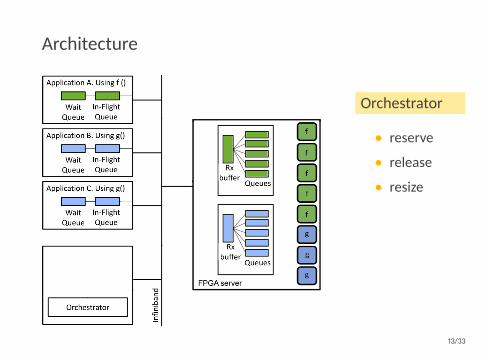
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
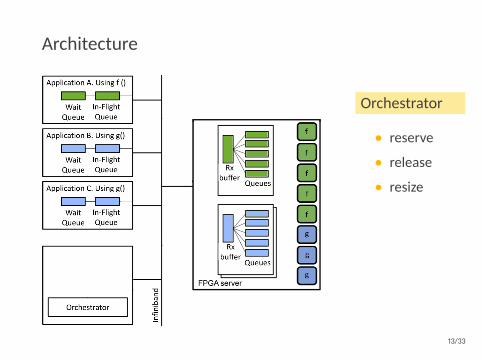
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
Architecture
Orchestrator
• reserve
• release
• resize
Autoscaler
• getutilization
• resize
13/33
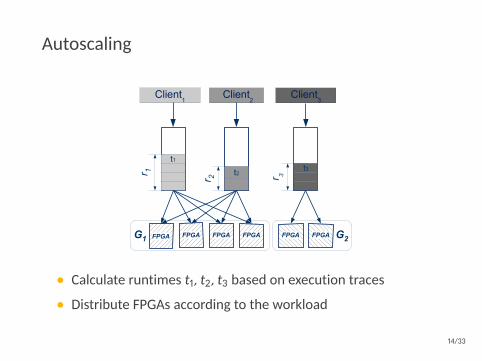
Autoscaling
t1
t2 t3
Client2
Client3
Client1
r 1 r 3r 2
G1 G2FPGA FPGA FPGA FPGA FPGA FPGA
• Calculate runtimes t1, t2, t3 based on execution traces
• Distribute FPGAs according to the workload
14/33
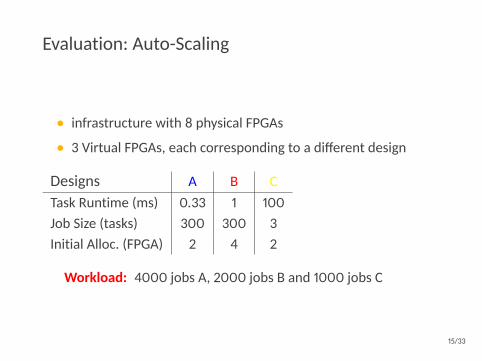
Evaluation: Auto-Scaling
• infrastructure with 8 physical FPGAs
• 3 Virtual FPGAs, each corresponding to a different design
Designs A B CTask Runtime (ms) 0.33 1 100Job Size (tasks) 300 300 3Initial Alloc. (FPGA) 2 4 2
Workload: 4000 jobs A, 2000 jobs B and 1000 jobs C
15/33
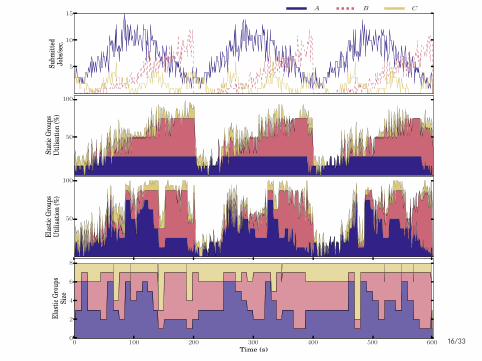
5
10
15
Subm
itted
Jobs
/sec.
A B C
50
100
Stat
icGr
oups
Util
isatio
n(%
)
50
100
Elas
ticGr
oups
Util
isatio
n(%
)
0 100 200 300 400 500 600Time (s)
0
2
4
6
8
Elas
ticGr
oups
Size
Autoscaling increases utilization from 52% to 61%.
Autoscaling reduces latency from 6.49 s to 2.55 s.
16/33
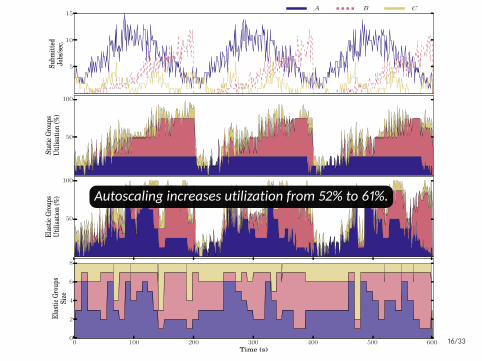
5
10
15
Subm
itted
Jobs
/sec.
A B C
50
100
Stat
icGr
oups
Util
isatio
n(%
)
50
100
Elas
ticGr
oups
Util
isatio
n(%
)
0 100 200 300 400 500 600Time (s)
0
2
4
6
8
Elas
ticGr
oups
Size
Autoscaling increases utilization from 52% to 61%.
Autoscaling reduces latency from 6.49 s to 2.55 s.
16/33
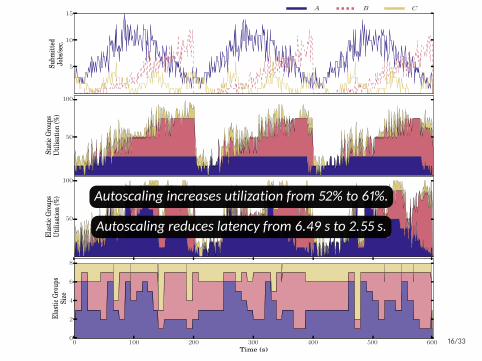
5
10
15
Subm
itted
Jobs
/sec.
A B C
50
100
Stat
icGr
oups
Util
isatio
n(%
)
50
100
Elas
ticGr
oups
Util
isatio
n(%
)
0 100 200 300 400 500 600Time (s)
0
2
4
6
8
Elas
ticGr
oups
Size
Autoscaling increases utilization from 52% to 61%.
Autoscaling reduces latency from 6.49 s to 2.55 s.
16/33

Conclusion for Contribution I : Improving utilizationof FPGAs in the Cloud
• Accessibility Problem: Maximize access to FPGAs– Organize FPGAs as a pool of resources accessible from any host.
• Sharing and Elasticity– Virtual FPGA = an elastic group of FPGA devices + the attached
task queues
• Autoscaling– Dynamically adjusting group size according workload demands
17/33

Contribution II: ResourceSelection2
2Heterogeneous Resource Selection for Arbitrary HPC Applications in the Cloud.Anca Iordache, Eliya Buyukkaya and Guillaume Pierre. In Proceedings of the 10thInternational Federated Conference on Distributed Computing Techniques (DAIS2015)
18/33

The number of possible configurations is enormous
Amazon EC2 now offers > 60 instance types, each instance typehaving different configuration and cost/hour.
• (4 vCPUs + 7.5 GB Mem) -> $0.209/hour
• (8 vCPUs + 15 GB Mem) ->$0.419/hour
• (1 GPU + 8 vCPUs + 15 GB Mem + 60 GB SSD) ->$1.3/hour
• ...
- We choose the number of resources.- We can mix and match.
19/33

Modelling Approaches I: Analytical models
Principle
(ExecTime,Cost) = fApp,input(Resources)
Example:Multi-tier web applications, MapReduce applications are modelledusing queueing theory,machine learning techniques.Pros:
• Potentially very accurate
Cons:
• Labor-intensive
• Built for specific types of applications, hardware architecture20/33

Modelling Approaches II: Code analysis
PrincipleMakes use specialized tools designed to analyze source code and/orcompiled code.Example: Employed to choose the best acceleration device foroptimizing performance.Pros:
• Aims at optimizing resource usage
• Identifies performance bottlenecks
Cons:
• Restricted to specific language, types of applications, hardwarearchitecture
21/33

Modelling Approaches III: Profiling
PrincipleRelies on feedback from past executions to draw conclusion aboutapplication performance.Example:Employed for MapReduce, Bag-of-Tasks applications.Pros:
• May be applied to arbitrary applications, easy to automate
Cons:
• The search space is enormous.
Amazon EC2 recommends to empirically try a variety of instancetypes and choose the one which works best.
22/33
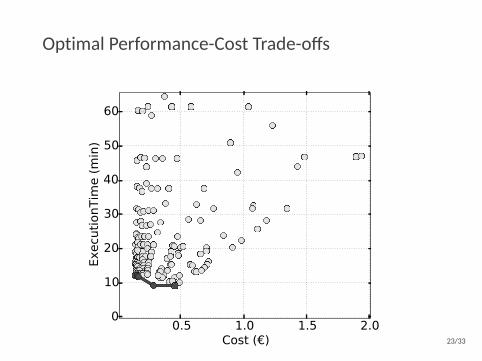
Optimal Performance-Cost Trade-offs
0.5 1.0 1.5 2.0Cost ( )
0
10
20
30
40
50
60Ex
ecut
ionT
ime
(min
)
23/33
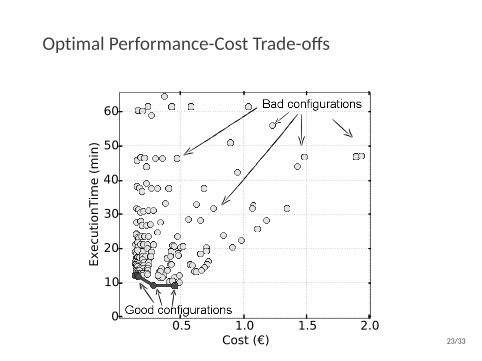
Optimal Performance-Cost Trade-offs
0.5 1.0 1.5 2.0Cost ( )
0
10
20
30
40
50
60Ex
ecut
ionT
ime
(min
)
23/33
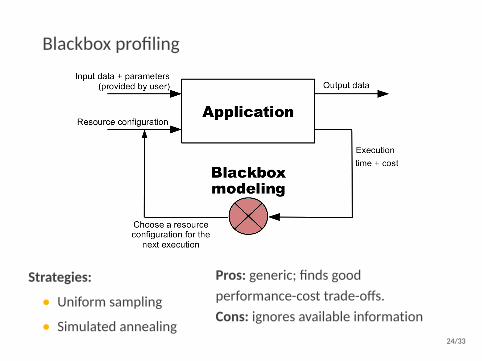
Blackbox profiling
Strategies:
• Uniform sampling
• Simulated annealing
Pros: generic; finds goodperformance-cost trade-offs.Cons: ignores available information
24/33
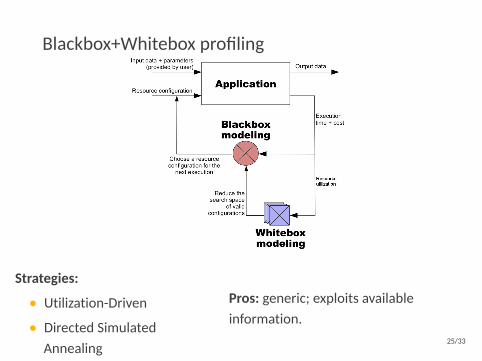
Blackbox+Whitebox profiling
Strategies:
• Utilization-Driven
• Directed SimulatedAnnealing
Pros: generic; exploits availableinformation.
25/33
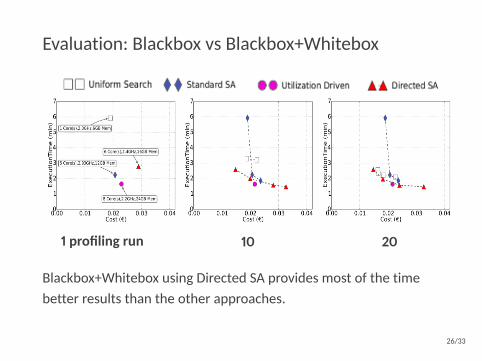
Evaluation: Blackbox vs Blackbox+Whitebox
1 profiling run 10 20
Blackbox+Whitebox using Directed SA provides most of the timebetter results than the other approaches.
Problem: 20 runs may take a long time and be very expensive.
26/33
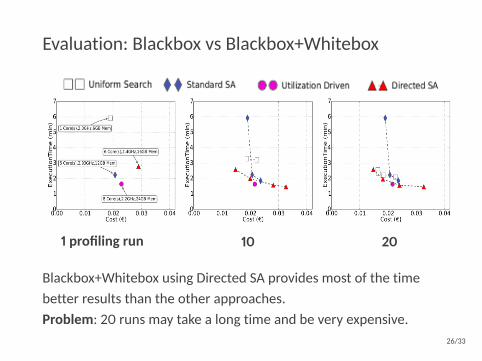
Evaluation: Blackbox vs Blackbox+Whitebox
1 profiling run 10 20
Blackbox+Whitebox using Directed SA provides most of the timebetter results than the other approaches.Problem: 20 runs may take a long time and be very expensive.
26/33

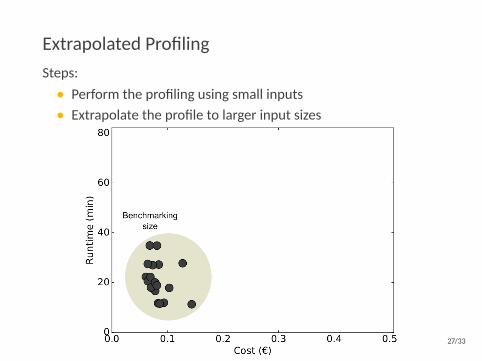
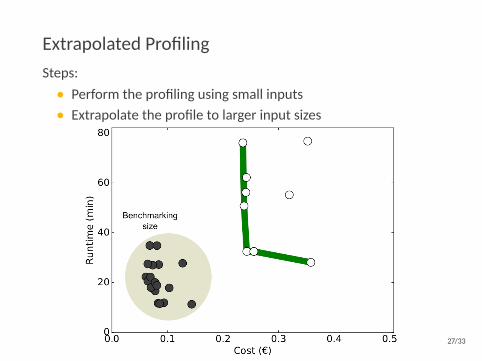
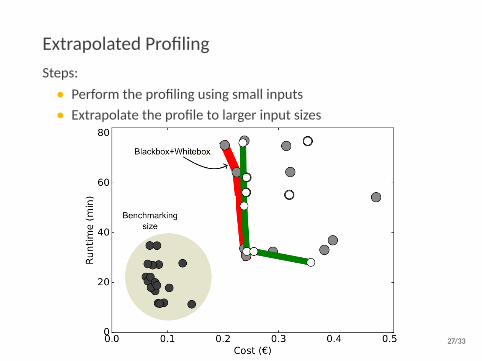
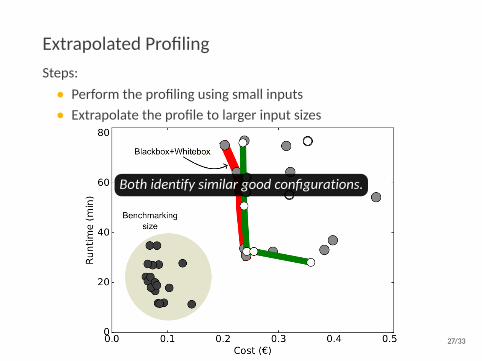
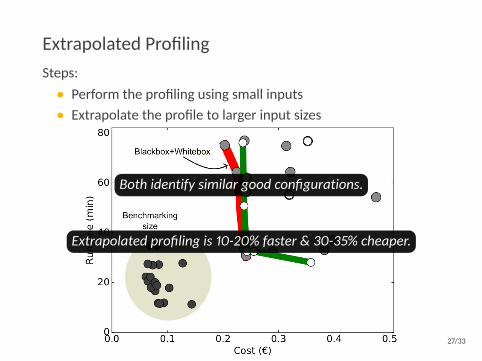
Extrapolated ProfilingSteps:• Perform the profiling using small inputs• Extrapolate the profile to larger input sizes
Both identify similar good configurations.
Extrapolated profiling is 10-20% faster & 30-35% cheaper.
27/33
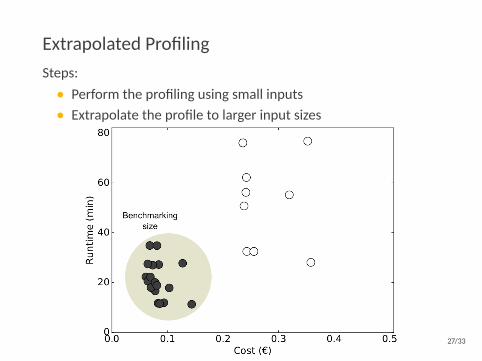
Extrapolated ProfilingSteps:• Perform the profiling using small inputs• Extrapolate the profile to larger input sizes
Both identify similar good configurations.
Extrapolated profiling is 10-20% faster & 30-35% cheaper.
27/33
Extrapolated ProfilingSteps:• Perform the profiling using small inputs• Extrapolate the profile to larger input sizes
Both identify similar good configurations.
Extrapolated profiling is 10-20% faster & 30-35% cheaper.
27/33
Extrapolated ProfilingSteps:• Perform the profiling using small inputs• Extrapolate the profile to larger input sizes
Both identify similar good configurations.
Extrapolated profiling is 10-20% faster & 30-35% cheaper.
27/33
Extrapolated ProfilingSteps:• Perform the profiling using small inputs• Extrapolate the profile to larger input sizes
Both identify similar good configurations.
Extrapolated profiling is 10-20% faster & 30-35% cheaper.
27/33
Extrapolated ProfilingSteps:• Perform the profiling using small inputs• Extrapolate the profile to larger input sizes
Both identify similar good configurations.
Extrapolated profiling is 10-20% faster & 30-35% cheaper.
27/33
Extrapolated ProfilingSteps:• Perform the profiling using small inputs• Extrapolate the profile to larger input sizes
Both identify similar good configurations.
Extrapolated profiling is 10-20% faster & 30-35% cheaper.
27/33
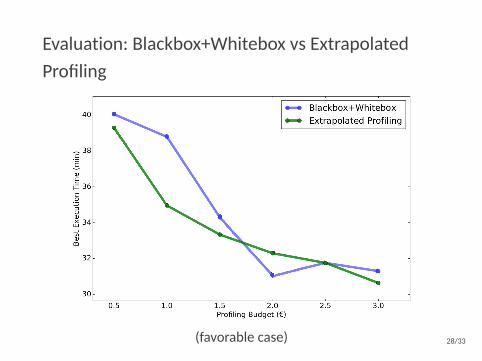
Evaluation: Blackbox+Whitebox vs ExtrapolatedProfiling
(favorable case) 28/33

Conclusion for Contribution II: Making the rightchoice of resources
Choosing the right amount of resources is a difficult problem.
• Blackbox profiling : uses only performance and cost metrics toexplore the configuration space
• Blackbox+Whitebox profiling: makes use of specialized feedback
• Extrapolated profiling : reduces profiling time and cost
Blackbox Blackbox+Whitebox ExtrapolatedGeneric applications 3 3 3/7Exploits available info 7 3 3
Low profiling time/cost 7 7 3
29/33

Contribution III: Integration in aHeterogeneous Cloud Platform3
3HARNESS: A Platform Architecture for Accommodating Specialised Resources inthe Cloud. Jose Gabriel de Figueiredo Coutinho, Mark Stillwell, Katerina Argyraki,George Ioannidis, Anca Iordache, Christoph Kleineweber, Alexandros Koliousis, JohnMcGlone, Guillaume Pierre, Carmelo Ragusa, Peter Sanders, Thursten Schütt, TengYu and Alexander Wolf. Book chapter in "Software Architecture for Big Data and theCloud", Elsevier. To appear in 2017.
30/33
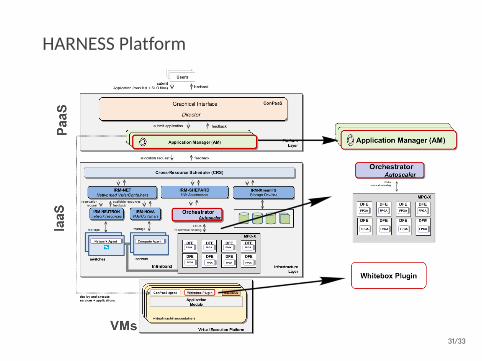
HARNESS Platform
31/33

Conclusions
We addressed the problem of enabling performance-cost trade-offsin heterogeneous clouds.
• Made good use of resources– Improved the utilization of FPGA resources
• Made a good selection of resources– Profiled applications in order to identify optimal resource
configurations
• Provided a blueprint to use of these technologies– Demonstrated how to integrate them in a heterogeneous cloud
platform
32/33

Future Research Directions
• Short-term perspectives– Remote FPGA sharing : Study the network overhead on
data-intensive accelerated applications.– Extrapolated profiling: Exploring input datasets
inter-dependencies.– Study more algorithms as search strategies.
• Long-term perspectives– PaaS system for developing accelerated applications.– Resource utilisation profiles for resource selection during
application runtime.
33/33


















