
Peer Communications. References Many of the slides are from a tutorial “P2P Systems” by Keith...
53
Peer Communications
-
Upload
iris-caldwell -
Category
Documents
-
view
223 -
download
0
Transcript of Peer Communications. References Many of the slides are from a tutorial “P2P Systems” by Keith...

Peer Communications

References
• Many of the slides are from a tutorial “P2P Systems” by Keith Ross and Dan Rubenstein
1. Dejan S. Milojicic, Vana Kalogeraki, Rajan Lukose,Kiran Nagaraja1, Jim Pruyne, Bruno Richard, Sami Rollins 2 ,Zhichen Xu, “Peer-to-Peer Computing, HP Technical Report HPL-2002-57.
2. http://www.bsdg.org/Jim/Peer2Peer/Paper/3214.html
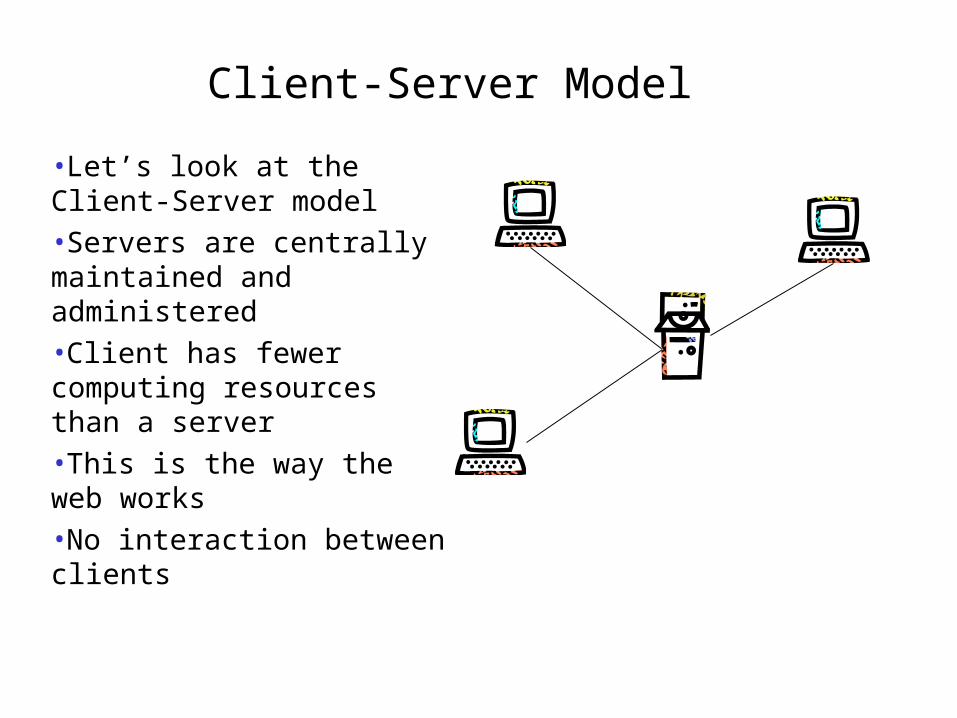
Client-Server Model
•Let’s look at the Client-Server model
•Servers are centrally maintained and administered
•Client has fewer computing resources than a server
•This is the way the web works
•No interaction between clients

Client Server Model
• Disadvantages of the client-server model Reliability
The network depends on a possibly highly loaded server to function properly.
Server needs to be replicated to some extent to provide better reliability.
Scalability More users imply more demand for computing power,
storage space and bandwidth
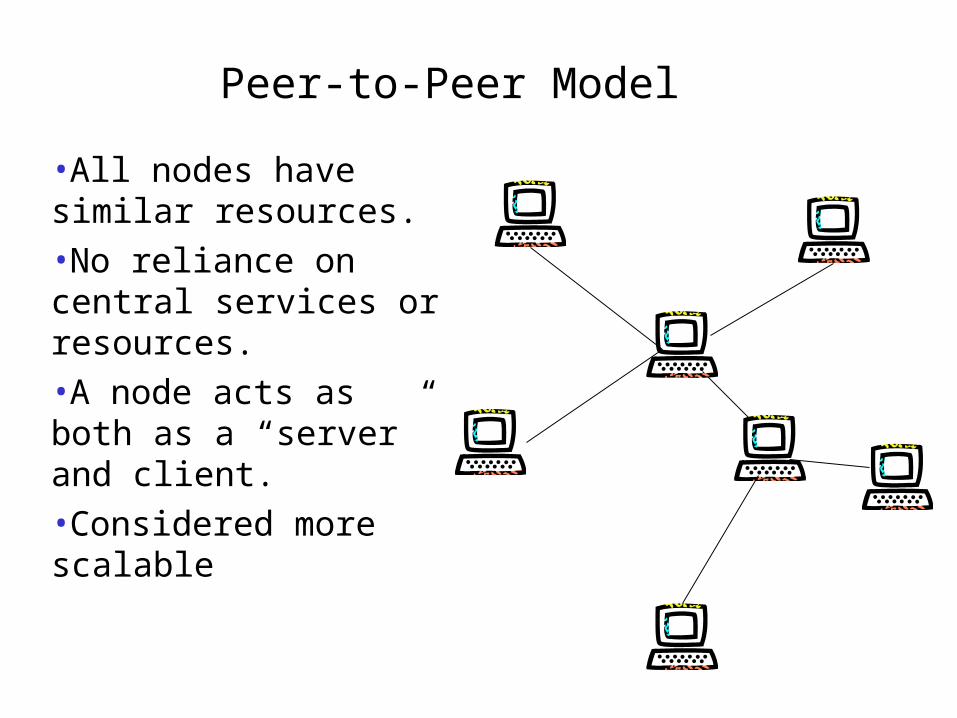
Peer-to-Peer Model
•All nodes have similar resources.•No reliance on central services or resources.•A node acts as both as a “server” and client.•Considered more scalable

Why P2P?
• The Internet has three valuable fundamental assets Information Computing resources Bandwidth
• All of which are vastly under utilized,partly due to the traditional client-server model

Why P2P?
• No single search engine can locate and catalog the ever-increasing amount of information on the Web in a timely way
• Moreover, a huge amount of information is transient and not subject to capture by techniques such as Web crawling Google claims that it searches about 1.3x108 web
pages Finding useful information in real time is
increasingly difficult!

Why P2P?
• Although miles of new fiber have been installed, the new bandwidth gets little use if everyone goes to Yahoo for content and to eBay
• Instead, hot spots just get hotter while cold pipes remain cold
• This is partly why most people still feel the congestion over the Internet while a single fiber’s bandwidth has increased by a factor of 10 6 since 1975, doubling every 16 months

Why P2P?
• P2P potentially can eliminating the single-source bottleneck
• P2P can be used to distribute data and control and load-balance requests across the Net
• P2P potentially eliminates the risk of a single point of failure
• P2P infrastructure allows direct access and shared space, and this can enable remote maintenance capability

Peer-to-Peer Applications
• File/Object sharing (e.g., Gnutella)
• Distributed computing(e.g., SETI@Home)
• Collaboration (e.g., Jabber, Magi, Groove)

Environment Characteristics for Peer-to-Peer Systems
• Unreliable environments• Peers connecting/disconnecting – network
failures to participation• Random Failures e.g. power outages, cable
and DSL failures, hackers• Personal machines are much more vulnerable
than servers

Evaluating Peer-to-Peer Systems
• A node’s database: What does a node need to save in order to operate
properly/efficiently
• Success rate (if the file is in the network, what are the changes that a search will find it)
• Lookup cost: Time Communication (bandwidth usage)
• Join/departure cost• Fault Tolerance – Resilience to faults• Resilience to denial of service attacks, security.

SETI@HomeMain Server
• Distributes a screen saver–based application to users • Applies signal analysis algorithms different data sets to process radio-telescope data. • Has more than 3 million users - used over a million years of CPU time to date
1. InstallScreen Server
Radio-telescope Data
2. SETI client (screen Saver) starts
3. SETI client getsdata from server and runs
4. Client sends resultsback to server
Distributed Computing: SETI@HOME

Issues in File Sharing Services
• Publish – How to insert a new file into the network
• Lookup – Find a specific file
• Retrieval – Getting a copy of a file

P2P File Sharing Software
• Allows a user to open up a directory in their file system
Anyone can retrieve a file from directory Like a Web server
• Allows the user to copy files from other users’ open directories:
Like a Web client
• Allows users to search nodes for content based on keyword matches:
Like Google

Napster: How Did It Work
• Application-level, client-server protocol over point-to-point TCP
• Centralized directory server• Steps:
Connect to Napster server Give server keywords to search the full list with. Select “best” of correct answers.
One approach is select based on the response time of a pings.– Shortest response time is chosen.
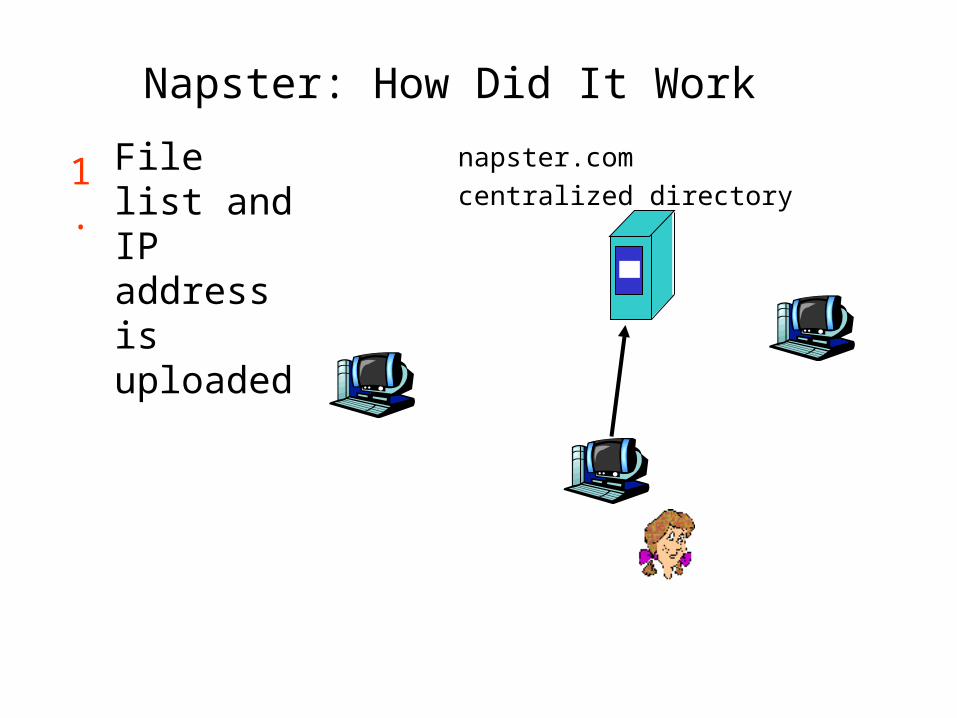
Napster: How Did It Work
File list and IP address is uploaded
1.napster.com centralized directory

Napster: How Did It Work
napster.com centralized directory
Queryand
results
User requests search at server.
2.
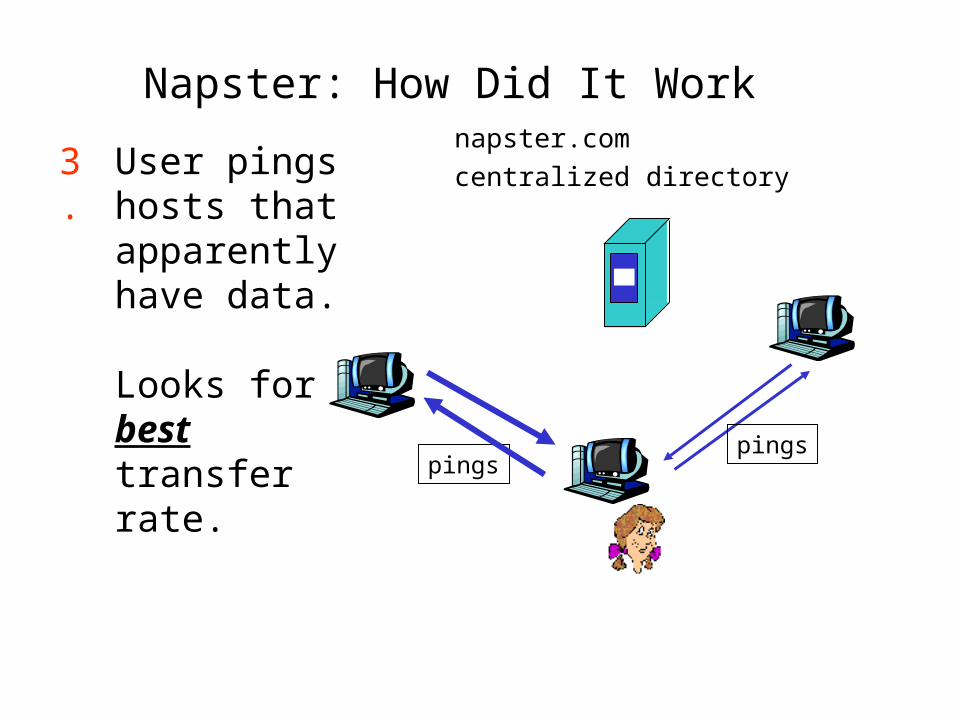
Napster: How Did It Work
pingspings
User pings hosts that apparently have data.
Looks for best transfer rate.
3.napster.com centralized directory
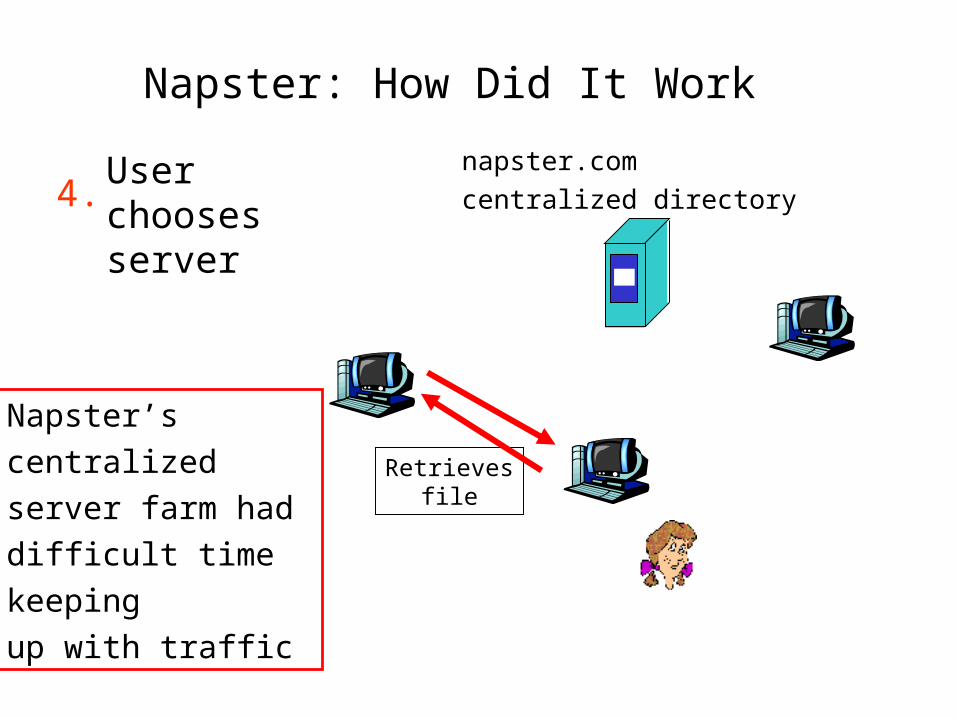
Napster: How Did It Work
napster.com centralized directory
Retrievesfile
User choosesserver
4.
Napster’s centralized server farm had difficult time keeping up with traffic

Napster
• History: 5/99: Shawn Fanning (freshman, Northeasten U.)
founds Napster Online music service 12/99: first lawsuit 3/00: 25% UWisc traffic Napster 2/01: US Circuit Court of
Appeals: Napster knew users
violating copyright laws
7/01: # simultaneous online users:
Napster 160K, Gnutella: 40K, Morpheus (KaZaA): 300K

Napster
• Judge orders Napster to pull plug in July ‘01
• Other file sharing apps take over!
gnutellanapsterfastrack (KaZaA)
8M
6M
4M
2M
0.0bit
s per
sec

Napster: Discussion
• Locates files quickly
• Vulnerable to censorship and technical failure
• Popular data become less accessible because of the load of the requests on a central server

Gnutella
• The focus is on a decentralized method of searching for files Central directory server no longer the bottleneck More difficult to “pull plug”
• Each application instance serves to: Store selected files Route queries from and to its neighboring peers Respond to queries if file stored locally Serve files

Gnutella
• Gnutella history: 3/14/00: release by AOL, almost immediately withdrawn Became open source Many iterations to fix poor initial design (poor design
turned many people off)
• Issues: How much traffic does one query generate? How many hosts can it support at once? What is the latency associated with querying? Is there a bottleneck?

Gnutella: Searching
• Searching by flooding:• A Query packet might ask, "Do you have any content
that matches the string ‘Homer"? If a node does not have the requested file, then 7
(default set by Gnutella) of its neighbors are queried. If the neighbors do not have it, they contact 7 of their
neighbors. Maximum hop count: 10 (this is called time-to-live
TTL) Reverse path forwarding for responses (not files)

Gnutella: Searching
• Downloading• Peers respond with a “QueryHit” (contains contact info)• File transfers use direct connection using HTTP protocol’s
GET method • When there is a firewall a "Push" packet is used – reroutes
via Push path

Gnutella: Searching

Gnutella: Searching

Gnutella: Discovering Peers
• A peer has to know at least one other peer to send requests to.
• Addresses of some peers have been published on a website.
• When a peer enters the network, it contacts a designated peer and receives a list of other peers that have recently entered the network.

Gnutella: Discussion
• Robust: The failure of peer is not a failure of Gnutella.
• Performance: Flooding leads to poor performance
• Free riders: Those who get data but do not share data.

KaZaA: The Service
• More than 3 million up peers sharing over 3,000 terabytes of content
• More popular than Napster ever was• More than 50% of Internet traffic ?• MP3s & entire albums, videos, games• Optional parallel downloading of files• Automatically switches to new download server
when current server becomes unavailable• Provides estimated download times

KaZaA: The Service
• A user can configure the maximum number of simultaneous uploads and maximum number of simultaneous downloads
• Queue management at server and client Frequent uploaders can get priority in server queue
• Keyword search User can configure “up to x” responses to keywords
• Responses to keyword queries come in waves; stops when x responses are found

KaZaA: The Technology
• Proprietary
• Control data encrypted
• Everything in HTTP request and response messages

KaZaA: Architecture
• Each peer is either a supernode or is assigned to a supernode
56 min avg connect Each SN has about 100-
150 children Roughly 30,000 SNs
•Each supernode has TCP connections with 30-50 supernodes
23 min avg connect
supernodes

KaZaA: Architecture
• Nodes that have more connection bandwidth and are more available are designated as supernodes
• Each supernode acts as a mini-Napster hub, tracking the content and IP addresses of its descendants
• A supernode tracks only the content of its children.• Considered a cross between Napster and Gnutella

KaZaA: Finding Supernodes
• List of potential supernodes included within software download
• New peer goes through list until it finds operational supernode
Connects, obtains more up-to-date list, with 200 entries Nodes in list are “close” to ON. Node then pings 5 nodes on list and connects with the one
• If supernode goes down, node obtains updated list and chooses new supernode

KaZaA Queries
• Node first sends query to supernode Supernode responds with matches If x matches found, done.
• Otherwise, supernode forwards query to subset of supernodes If total of x matches found, done.
• Otherwise, query further forwarded Probably by original supernode rather than
recursively

Peer Topologies
• Core• Centralized• Ring• Hierarchical• Decentralized
• Hybrid• Centralized-Ring• Centralized-Centralized• Centralized-Decentralized
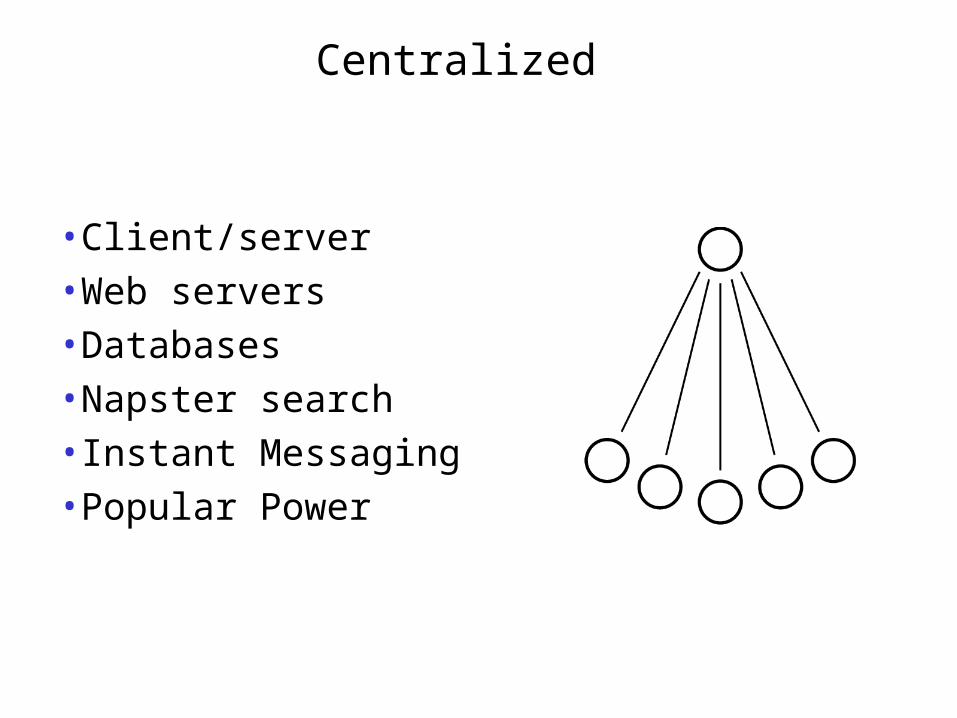
Centralized
•Client/server•Web servers•Databases•Napster search•Instant Messaging•Popular Power

Ring
•Fail-over clusters•Simple load balancing•Assumption
Single owner

Hierarchical
•Tree structure•Example: DNS
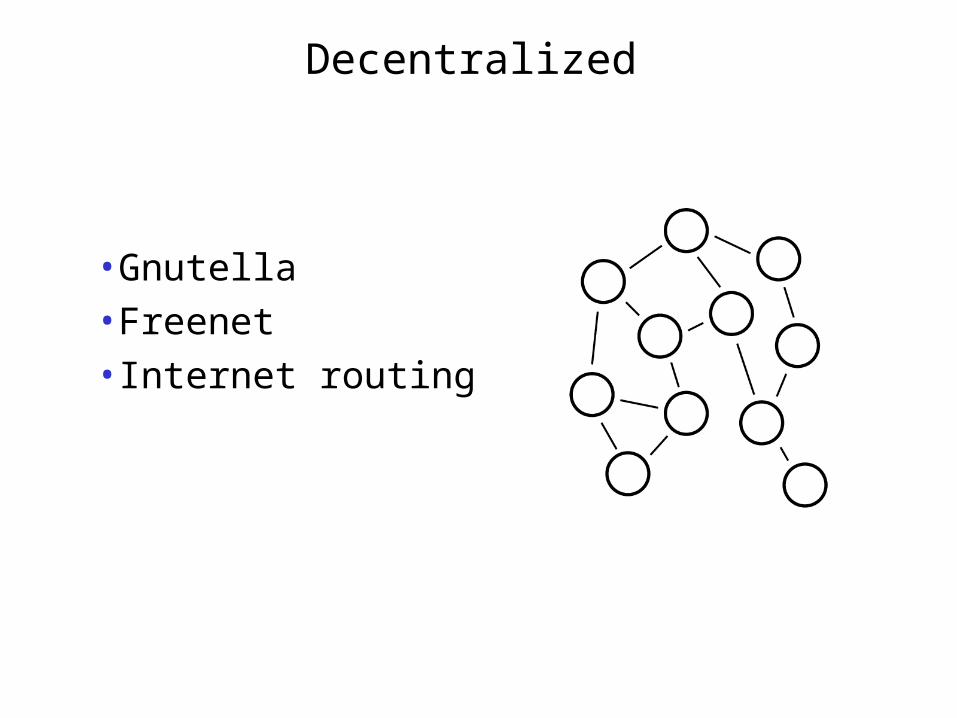
Decentralized
•Gnutella•Freenet•Internet routing

Centralized + Ring
•Robust web applications•High availability of servers
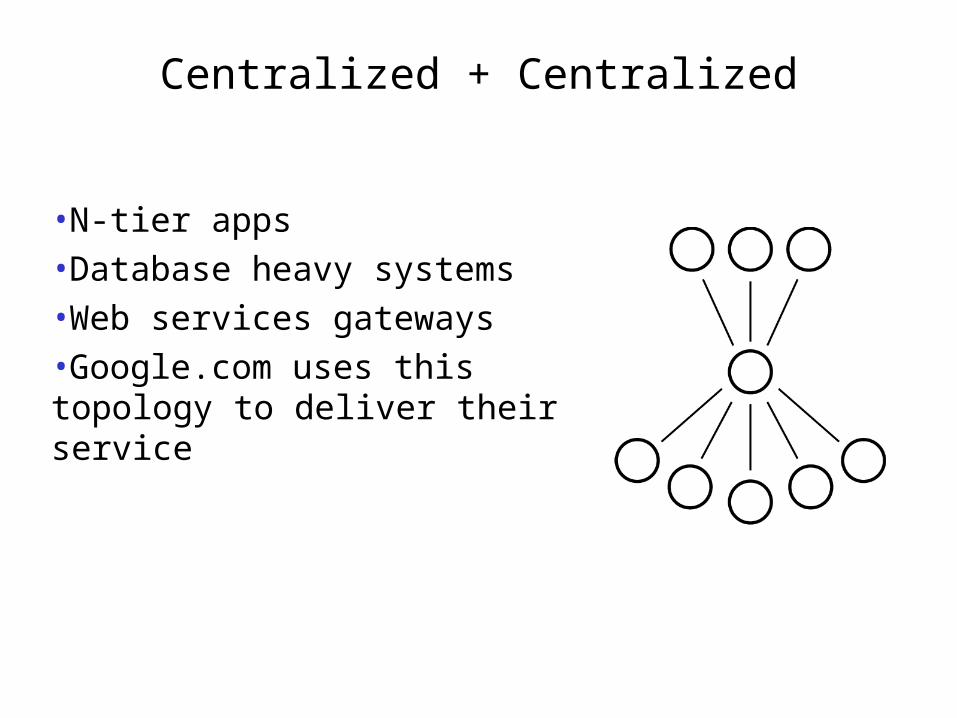
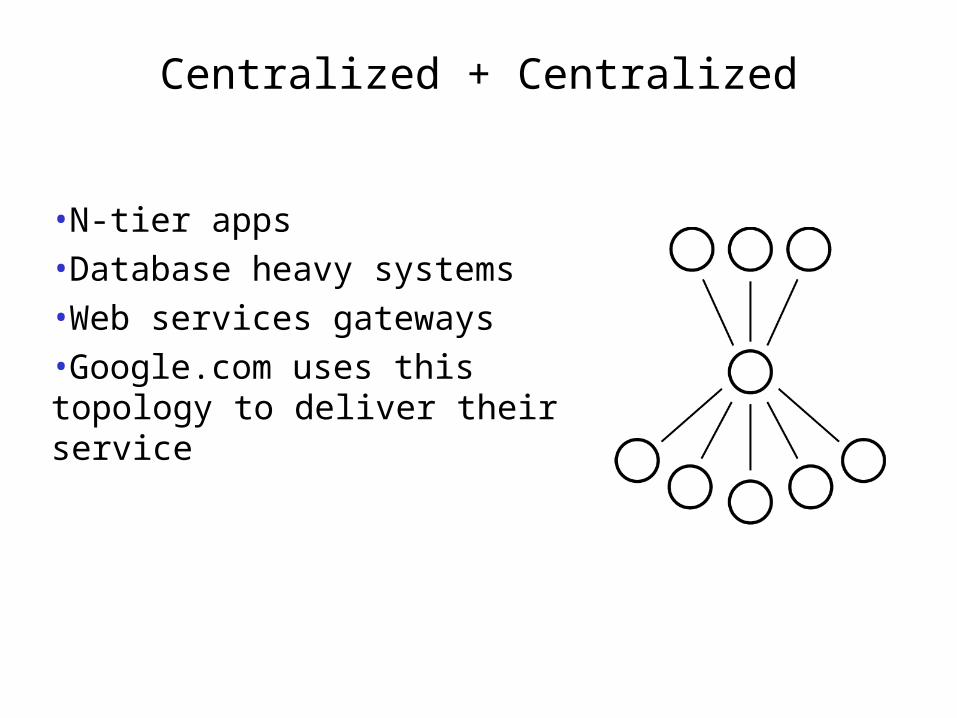
Centralized + Centralized
•N-tier apps•Database heavy systems•Web services gateways•Google.com uses this topology to deliver their service
Centralized + Centralized
•N-tier apps•Database heavy systems•Web services gateways•Google.com uses this topology to deliver their service

Centralized + Decentralized
•New Wave of P2P•Clip2 Gnutella Reflector (next)•FastTrack
KaZaA Morpheus

Structured P2P
• So far the examples that we have seen are considered unstructured P2P in the sense that looking for content does not actually take the content into account.
• Structured P2P allows for more directed searches based on the content.
• Directed searches are an attempt to address the flooding problem

Distributed Hash Tables (DHT)
• This is used to overcoming the flooded search problem• Operationally like standard hash tables• Data is distributed around the network• Features
Efficient: O(log N) messages per lookup Even distribution of keys among nodes
Adaptable Network reconfiguration does not cascade to all nodes
Robust: replication of tables provides survival to node failures

DHT Step 1: The Hash• Introduce a hash function to map the object being searched
for to a unique identifier: e.g., h(“NGC’02 Tutorial Notes”) → 8045
• Distribute the range of the hash function among all nodes in the network
• Each node must “know about” at least one copy of each object that hashes within its range (when one exists)
0-9999500-9999
1000-19991500-4999
9000-9500
4500-6999
8000-8999 7000-8500
8045
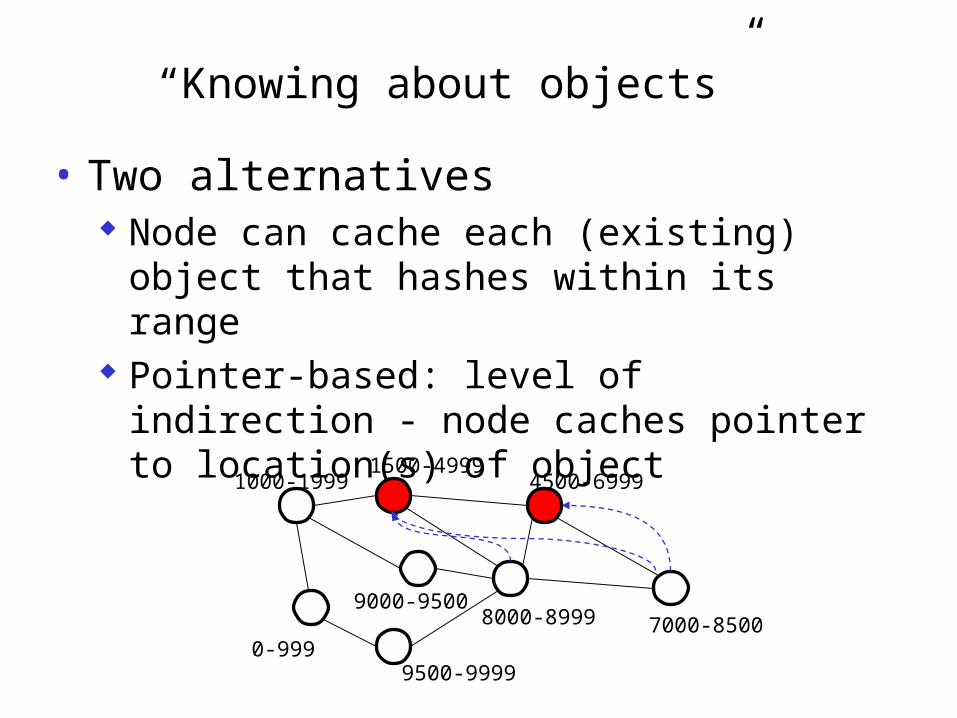
“Knowing about objects”
• Two alternatives Node can cache each (existing) object that hashes
within its range Pointer-based: level of indirection - node caches
pointer to location(s) of object
0-9999500-9999
1000-19991500-4999
9000-9500
4500-6999
8000-8999 7000-8500

DHT Step 2: Routing
• For each object, node(s) whose range(s) cover that object must be reachable via a “short” path
by the querier node (assumed can be chosen arbitrarily) by nodes that have copies of the object (when pointer-based approach
is used)
• The different approaches (CAN,Chord,Pastry,Tapestry) differ fundamentally only in the routing approach
any “good” random hash function will suffice
• This is a major research topic

Summary
• P2P is a major portion of Internet traffic. Has exceeded web traffic
• There are different approaches to structuring P2P applications.
• There is a good deal of concern about future scalability and traffic which leading to a lot research from academia and industry.


















