
Patent documentation - comparison of two MT strategies Lene Offersgaard, Claus Povlsen Center for...
16
Patent documentation - comparison of two MT strategies Lene Offersgaard, Claus Povlsen Center for Sprogteknologi, University of Copenhagen [email protected], [email protected]
-
Upload
ana-kernell -
Category
Documents
-
view
213 -
download
0
Transcript of Patent documentation - comparison of two MT strategies Lene Offersgaard, Claus Povlsen Center for...

Patent documentation -comparison of two MT strategies
Lene Offersgaard, Claus Povlsen
Center for Sprogteknologi, University of [email protected], [email protected]

MT-Summit, Sep 2007 2
A comparison of two different MT strategies
RBMT and SMT, similarities and differences, in a patent documentation context
What requirements should be met in order to develop an SMT production system within the area of patent documentation?
The two strategies:
PaTrans: A transfer and rule based translation system, used the last 15 years at Lingtech A/S (Ørsnes, 1996).
SpaTrans: A SMT system based on the Pharaoh framework (Koehn, 2004). Investigations supported by Danish Research Council.
Subdomain: chemical patents

MT-Summit, Sep 2007 3
A comparison of two different MT strategies -2
PaTrans: Transfer and rule based • En-Da, linguistic development• Grammatical coverage tailored to the text type of
Patents• Tools for terminology selection and coding• Handling of formulas and references
SpaTrans: An SMT system based on Pharaoh framework• En-Da, research version• Word and grammatical coverage determined by training
corpus• No termilology handling yet• Simple handling of formulas and references
MT-Summit, Sep 2007 4
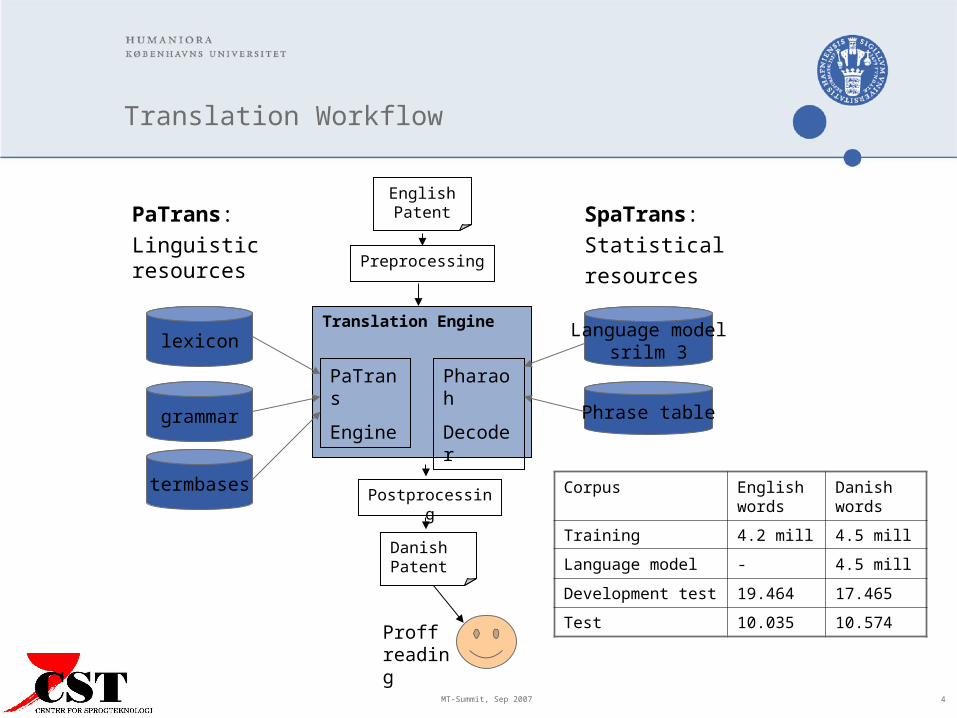
SpaTrans:Statistical resources
Translation Workflow
PaTrans:Linguistic resources Preprocessing
EnglishPatent
Translation Engine
Postprocessing
Danish Patent
Proff reading
PaTrans
Engine
lexicon
grammar
termbases
Language modelsrilm 3
Phrase table
Pharaoh
Decoder
Corpus English words
Danishwords
Training 4.2 mill 4.5 mill
Language model - 4.5 mill
Development test 19.464 17.465
Test 10.035 10.574

MT-Summit, Sep 2007 5
BLEU Evaluation
Reference translations are two post-edited PaTrans translations
• The PaTrans system is favoured: term bases, wording and sentence structure
• Some SpaTrans errors are caused by incomplete treatment of formulas and references
• BLEU differs for the two patents • Very promising results for the SpaTrans system
BLEU % Test patent A Test patent B
PaTrans 53.90 61.03
SpaTrans with reordering 39.92 43.97
SpaTrans monotonic 44.73 50.13
Diff (PaTrans - SpaTrans mono.) 9.17 10.90

MT-Summit, Sep 2007 6
Human evaluation of the SMT system
Limited resources for manual evaluation
Proof readers have post-edited SMT output and focussed on:Post editing time
Quality of output• Intelligibility (understandable?)• Fidelity (same meaning?)• Fluency (fluent Danish?)
Conclusions:• Usable translation quality• Both intelligibility and fidelity scores are best without
reordering• Annoying agreement errors• New terms has to be included in the SMT system easily

MT-Summit, Sep 2007 7
SpaTrans translation results
A dominant error pattern is the frequent occurrence of agreement errors in nominal phrases
ExamplesGender disagreement:(lit:… control of the full spectrum)… kontrol af den fulde spektrum
… kontrol af den[DET_common_sing] fulde spektrum[N_neuter_sing]
Corrected output:
… kontrol af det[DET_neuter_sing] fulde spektrum[N_neuter_sing]

MT-Summit, Sep 2007 8
SpaTrans translation results - 2
Number disagreement: (lit: … the active ingredients)… den aktive bestanddele
… den[DET_common_sing] aktive bestanddele[N_common_plur]
... denne[DET_definite] konstant[ADJ_indefinite] erosion
Corrected output:
… de[DET_common_plur] aktive bestandele[N_common_plur]
Corrected output:
... denne[DET_definite] konstante[ADJ_definite] erosion
Lets give linguistic information a try!
Definiteness disagreement:(lit: ... this constant erosion)... denne konstant erosion
MT-Summit, Sep 2007 9
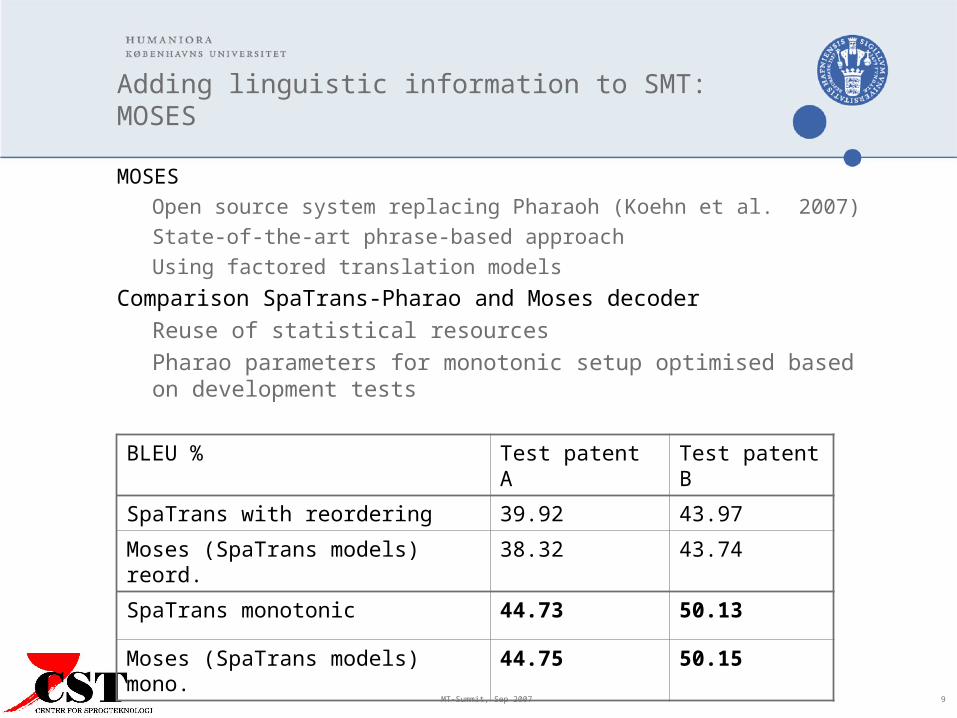
MOSESOpen source system replacing Pharaoh (Koehn et al. 2007)State-of-the-art phrase-based approachUsing factored translation models
Comparison SpaTrans-Pharao and Moses decoder Reuse of statistical resourcesPharao parameters for monotonic setup optimised based on development tests
Adding linguistic information to SMT: MOSES
BLEU % Test patent A Test patent B
SpaTrans with reordering 39.92 43.97
Moses (SpaTrans models) reord. 38.32 43.74
SpaTrans monotonic 44.73 50.13
Moses (SpaTrans models) mono. 44.75 50.15

MT-Summit, Sep 2007 10
Using factored translation models
Makes it possible to build translation models based on surface forms, part-of-speech, morphology etc.
We use:
Translation model: word->word, pos->posGeneration model determine the output
Adding linguistic information using MOSES
Input Output
word
pos+morf
word
pos+morf

MT-Summit, Sep 2007 11
Adding POS-tags and morphology
Pos-tagging training material: Brill tagger usedDifferent tagsets for Danish and English text
Experiments with language model (lm) orderorder 3 or 5 Results not significant: Test Patent A: +0.1% BLEUTest Patent B: -0.1% BLEU Perhaps training material too small to do lm orderexperiments
Training parameters kept: phrase-length 3, lm order 3No tuning of parameters, just training.

MT-Summit, Sep 2007 12
Results adding pos-tags – by inspection
With inclusion of morpho-syntactic information:
(lit:… control of the full spectrum)... kontrol af det fulde spektrum (gender agreement)
(lit: … the active ingredients)... de aktive bestanddele (number agreement)
(lit: ... this constant erosion)... denne konstante erosion (definiteness agreement)

MT-Summit, Sep 2007 13
BLEU not designed to test linguistic improvement, anyway:
Significant improvement!
Results using pos-tags - BLEU
BLEU % BLEU %
Test patent A Test patent B
Moses word, lm3, with reordering 39.96 48.55
Moses word+pos, lm3, with reordering 41.44 49.07
Moses word, lm3, monotonic 40.19 48.77
Moses word+pos, lm3, monotonic 42.06 50.10

MT-Summit, Sep 2007 14
ConclusionsMOSES
En-Da Patents: best results when no reordering
Agreement errors can be reduced by applying factored training using pos+mophology
Experiments using a ”language” model order > 3 for POS-tags might give even better results

MT-Summit, Sep 2007 15
Conclusions SMT test results for patent text
Usable• translation quality comparable with RBMT systems
in production• low cost development for new domain• possible to have SMT-systems tailored to different
domains of patents - if training data are available
Patent texts always contain new terms/conceptsTherefore new terms have to be handled in SMT production systems
Agreement errors can be reduced by applying factored training with pos-information - BLEU score improved!

MT-Summit, Sep 2007 16
Acknowledgements
Thanks!
The work was partly financed by the Danish Research Council.
Special thanks to Lingtech A/S and Ploughmann & Vingtoft for providing us with training material and proofread patents.







![Meta-Complexity Theoretic Approach to Complexity Theoryigorcarb/complexity... · 2020. 9. 17. · Theorem [Ilango-Loff-Oliveira (CCC’20)] Definition (Multi-MCSP) ∧ 𝑥1 ∨ 𝑥2](https://static.fdocuments.in/doc/165x107/6124bd05d1cdd941c015100d/meta-complexity-theoretic-approach-to-complexity-theory-igorcarbcomplexity.jpg)










