
Part 1 Introductionto Intel MIC...
67
Part 1 Introduction to Intel MIC Programming Lubomír Říha IT4Innovations
Transcript of Part 1 Introductionto Intel MIC...

Part 1Introduction to Intel MIC Programming
Lubomír ŘíhaIT4Innovations
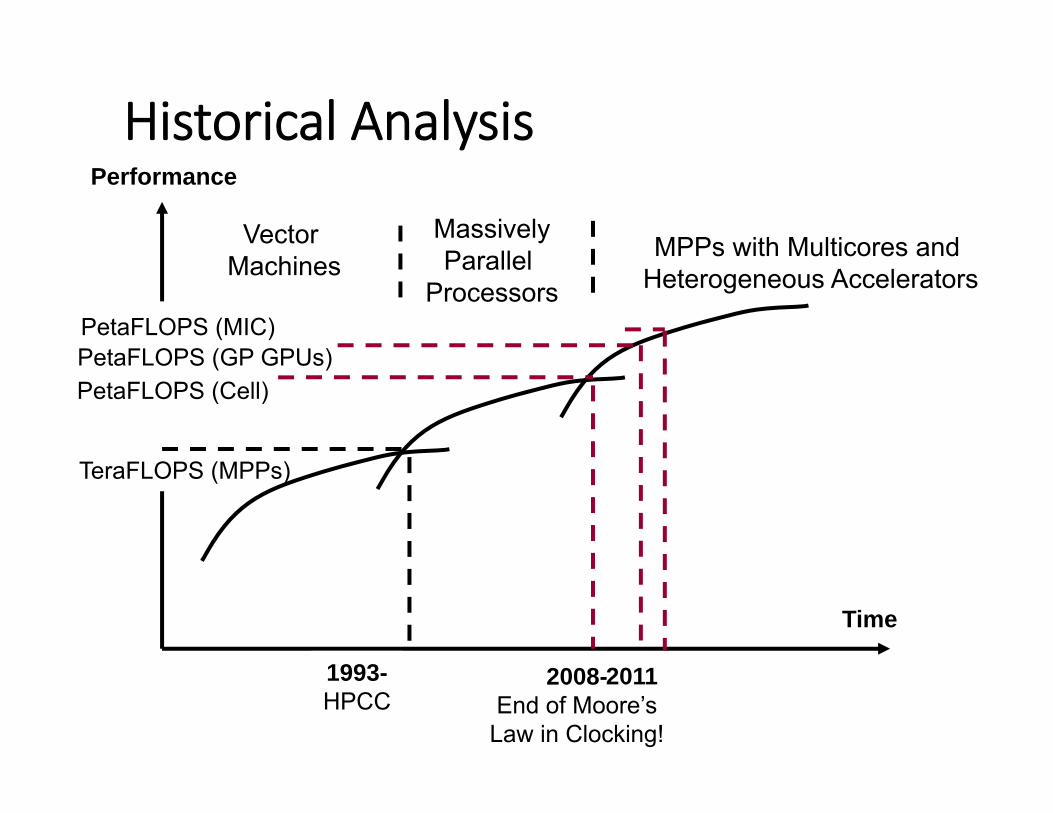
Historical Analysis
PetaFLOPS (MIC)
Vector Machines
MPPs with Multicores and Heterogeneous Accelerators
MassivelyParallel
Processors
1993-HPCC
2008-End of Moore’s
Law in Clocking!
Performance
Time
PetaFLOPS (Cell)
TeraFLOPS (MPPs)
PetaFLOPS (GP GPUs)
2011

IBM Roadrunner – #1 in 2008
• Parameters• 6,480 AMD Opteron processors
• 3,240 LS21 blades• 52 TB RAM
• 12,960 PowerXCell 8i processors• 6480 QS22 blades• 52 TB RAM
• interconnection network• Infiniband
• 296 racks• 2.35 MW power consumption
IBM Roadrunner (2008 )» Los Alamos National Lab
Blade center H – 3x Triblade (2x Opteron, 4x CELL) – 1.2 Tflops

Trends for Petaflop/s Machines CPUs: Wider vector units, more cores • General‐purpose in nature • High single‐thread performance, moderate floating point throughput • 2x E5‐2608 ‐ 0.34 Tflop/s, 260W
GPUs: Thousands of very simple stream processors • Specialized for floating point. • New programming models: CUDA, OpenCL, OpenACC• Tesla K20 ‐ 1.17 Tflop/s, 225W
MIC: Take CPU trends to an extreme, optimize for floating point. • Retain general‐purpose nature and programming models from CPU • Low single‐thread performance, high aggregate FP throughput • SE10P ‐ 1.06 Tflops/s, 300W

Tianhe 2 and Titan: #1 and #2 in 2013
• Tianhe‐2 – 34/55 PFLOPS• 16,000 nodes
• 2x Intel Xeon CPU• 3x Xeon Phi
• 384,000 CPU cores • 48,000 MICs
• Titan – 18/27 PFLOPS• 18,688 nodes
• 1x AMD 6200 CPU• 1x Tesla K20 GPU
• 299,008 CPU cores• 18,688 GPUs

Accelerators in HPC Hardware Accelerators ‐ Speeding up the Slow Part of the Code• Enable higher performance through fine‐grained parallelism
• Offer higher computational density than CPUs
• Accelerators present heterogeneity!
Main Features• Coprocessor to the CPU• PCIe based interconnection• Separate memory• Provide high bandwidth access to local data
GPU or MIC

Accelerated Execution Model
PC
P
GPU, MIC, FPGA, Cell CBE, …
• Transfer of Control• Input Data
• Output Data• Transfer of Control
• Fine grain computations with the accelerators, others with the CPU
• Interaction between accelerator and CPU can be blocking or asynchronous
• This scenario is replicated across the whole system and standard HPC parallel programming paradigms used for intranodeinteractions

Processors vs. Accelerators Accelerators• tailored for compute‐intensive, highly data parallel computation
• many parallel execution units • have significantly faster and more advanced memory interfaces
• more transistors can be devoted to data processing
• less transistors for data caching and flow control
• Very Efficient For• Fast Parallel Floating Point Processing• High Computation per Memory Access
• Not As Efficient For• Branching‐Intensive Operations• Random Access, Memory‐Intensive Operations
DRAM
Cache
ALUControl
ALU
ALU
ALU
DRAM
Processors have few execution units higher clock speeds

Accelerators in Anselm1.) GPU accelerators
• Nvidia Tesla K20m • 23 Nodes ‐ cn[181‐203]
• 2x Intel Sandy Bridge E5‐2470, 2.3GHz • 96 GB RAM
2.) MIC Accelerators• Intel Xeon Phi 5110P • 4 Nodes ‐ cn[204‐207]
• 2x Intel Sandy Bridge E5‐2470, 2.3GHz • 96 GB RAM
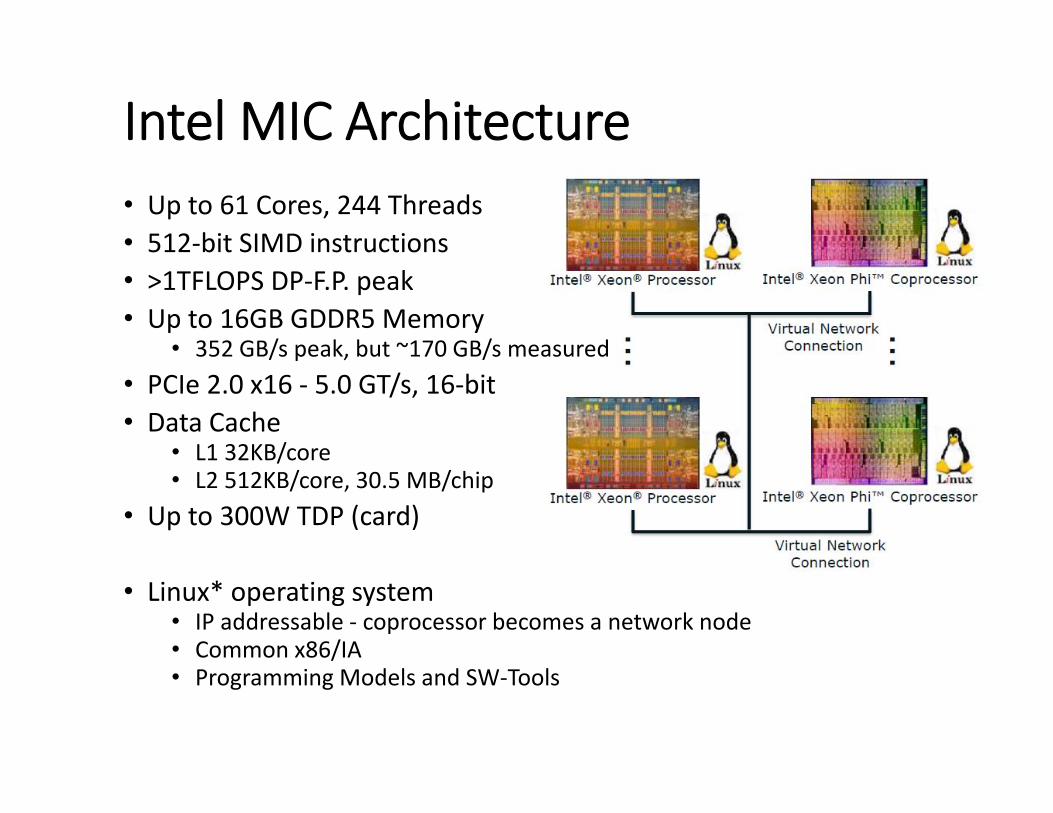
Intel MIC Architecture• Up to 61 Cores, 244 Threads • 512‐bit SIMD instructions • >1TFLOPS DP‐F.P. peak • Up to 16GB GDDR5 Memory
• 352 GB/s peak, but ~170 GB/s measured• PCIe 2.0 x16 ‐ 5.0 GT/s, 16‐bit • Data Cache
• L1 32KB/core • L2 512KB/core, 30.5 MB/chip
• Up to 300W TDP (card)
• Linux* operating system • IP addressable ‐ coprocessor becomes a network node• Common x86/IA • Programming Models and SW‐Tools

Intel MIC Architecture Overview
TD – cache Tag Directory
Based on what Intel learned from – Larrabee– SCC – TeraFlopsResearch Chip
Memory – up to 16 GB of GDDR5• used for everything, including the OS image and the local filesystem• There are multiple memory controllers on the card.• Access over a shared ring bus • Cores compete for access.
• Transfers to/from the card go over PCIe, so maximum speeds around 7GB/s.

Core Architecture Overview• 61 cores
• Full support for the x86 instruction set• In order execution • Coherent caches (per core)
• 32KB L1 instruction and data caches. • 512KB shared L2 data/instruction
• Two scalar pipelines• Scalar Unit based on Pentium® processors• Dual issue with scalar instructions• Pipelined one‐per‐clock scalar throughput• One pipeline is limited in functionality
• SIMD Vector Processing Engine• only significant difference to the Pentium • 512‐bit vector processing unit (VPU) • 32 512‐bit wide vector registers
• 4 hardware threads per core• 4 clock latency, hidden by round‐robin scheduling of
threads• Cannot issue back to back instructions in same thread:
Means minimum two threads per core to achieve full compute potential

History of SIMD ISA extensions (Intel)
• MMX: MMX Pentium and Pentium II (PentiumProdidn’t have MMX)
• SSE: Pentium III
• SSE2: Pentium 4
• SSE3: Pentium 4 with 90nm technology
• SSSE3: Core 2 Duo/Quad (65nm technology)
• SSE4.1: Core 2 Duo/Quad (45nm technology)
• SSE4.2: 1st generation Core i7 (45nm, 32nm)
• AVX: 2nd/3rd generation Core i7 (32nm, 22nm)
MMX™ (1997)
Intel® Streaming SIMD Extensions (Intel® SSE in 1999 to Intel® SSE4.2 in 2008)
Intel® Advanced Vector Extensions (Intel® AVX in 2011 and Intel® AVX2 in 2013)
Intel Many Integrated Core Architecture (Intel® MIC Architecture in 2013)
Intel® Pentium® processor (1993)
Vectorization is essential 512-bit vectors- 16x 4-bytes elements- 8x 8-bytes elements

Vectorization
Source : Xeon Phi Tutorial Tim Cramer | Rechen‐ und Kommunikationszentrum
SIMD Vector Capabilities
• MMX: MMX Pentium and Pentium II (PentiumPro didn’t have MMX)
• SSE: Pentium III
• SSE2: Pentium 4
• SSE3: Pentium 4 with 90nm technology
• SSSE3: Core 2 Duo/Quad (65nm technology)
• SSE4.1: Core 2 Duo/Quad (45nm technology)
• SSE4.2: 1st generation Core i7 (45nm, 32nm)
• AVX: 2nd/3rd generation Core i7 (32nm, 22nm)

Vectorization
Source : Xeon Phi Tutorial Tim Cramer | Rechen‐ und Kommunikationszentrum
SIMD Vector Basic Arithmetic

Vectorization
Source : Xeon Phi Tutorial Tim Cramer | Rechen‐ und Kommunikationszentrum
SIMD Fused Multiply and Add ‐ FMA
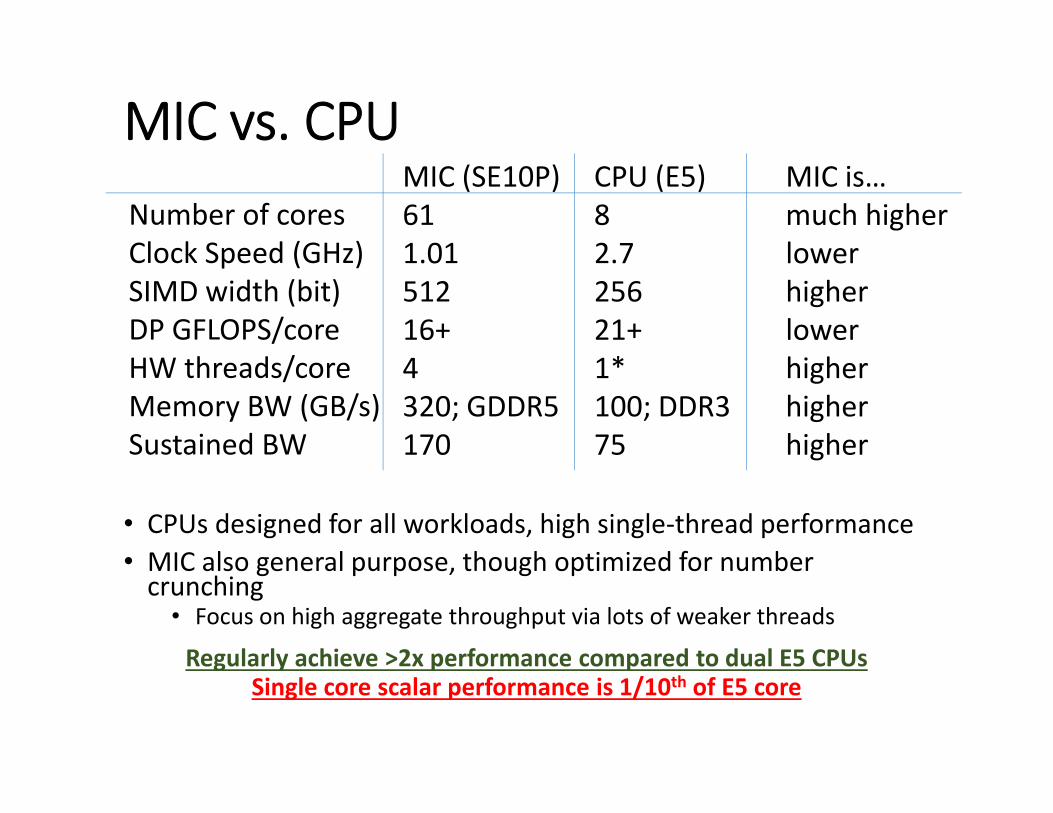
MIC vs. CPU
• CPUs designed for all workloads, high single‐thread performance • MIC also general purpose, though optimized for number crunching
• Focus on high aggregate throughput via lots of weaker threads
Regularly achieve >2x performance compared to dual E5 CPUsSingle core scalar performance is 1/10th of E5 core
MIC (SE10P) CPU (E5) MIC is… 61 8 much higher 1.01 2.7 lower 512 256 higher 16+ 21+ lower 4 1* higher320; GDDR5 100; DDR3 higher170 75 higher
Number of cores Clock Speed (GHz) SIMD width (bit) DP GFLOPS/core HW threads/core Memory BW (GB/s)Sustained BW

High‐performance XeonPhi applications exploitboth parallelism andvector processing.
MIC vs. CPU
Scalar & Single thread
Vector & Single thread
Scalar & Multiple threads
Vector & Multiple threads
More Parallel
More Performance
CPUMIC
CPUMIC
CPUMIC
1 10 100 1000 10000
Threads
Performance [G
FLOPS]

MIC Programming: Advantages• Intel’s MIC is based on x86 technology
• x86 cores w/ caches and cache coherency • SIMD instruction set • but is not x86 compatible (cross‐compilation needed)• Coherent cache (but …)
• Programming for Phi is similar to programming for CPUs • Familiar languages: C/C++ and Fortran • Familiar parallel programming models: OpenMP & MPI • MPI on host and on the coprocessor • Any code can run on MIC, not just kernels
• Optimizing for Phi is similar to optimizing for CPUs • “Optimize once, run anywhere” • Early Phi porting efforts for codes “in the field” have obtained double the performance of Sandy Bridge

Will My Code Run on Xeon Phi?• Yes • … but that’s the wrong question
• Will your code run “best” on Phi?, or • Will you get great Phi performance without additional work?
• Codes port easily • Minutes to days depending mostly on library dependencies
• Performance can require real work • Getting codes to run “at all” is almost too easy• Need to put in the effort to get what you expect
• Scalability• Multiple threads per core is really important • Getting your code to vectorize is really important
• In‐order cores • limited hardware prefetching • Cores running with 1GHz only • Small Caches (2 levels)
• Poor single thread performance • Small main memory • PCIe as bottleneck + offload
overhead
• In‐order cores • limited hardware prefetching • Cores running with 1GHz only • Small Caches (2 levels)
• Poor single thread performance • Small main memory • PCIe as bottleneck + offload
overhead
... most likely NO …

MIC Programming Considerations• Getting full performance from the Intel® MIC architecture requires both a high degree of parallelism and vectorization
• Not all code can be written this way• Not all programs make sense on this architecture
• Intel® MIC is different from Xeon• It specializes in running highly parallel and vectorized code.• Not optimized for processing serial code
• Parallelism and vectorization optimizations are beneficial across both architectures

Definition of a Node• A “node” contains a host component and a MIC component
• host – refers to the Sandy Bridge component • MIC – refers to one or two Intel Xeon Phi co‐processor cards

Spectrum of Programming Models

Coprocessor only Programming Model
MPI ranks on Intel® Xeon Phi™ coprocessor only
• All messages into/out of the coprocessors
• Intel® Cilk™ Plus, OpenMP*, Intel® Threading Building Blocks, Pthreadsused directly within MPI processes
Build Intel Xeon Phi coprocessor binary using the Intel® compiler
Upload the binary to the Intel Xeon Phi coprocessor
Run instances of the MPI application on Intel Xeon Phi coprocessor nodes

Symmetric Programming ModelMPI ranks on both Intel® Xeon Phi™ Architecture and host CPUs
• Messages to/from any core
• Intel® Cilk™ Plus, OpenMP*, Intel® Threading Building Blocks, Pthreads* used directly within MPI processes
Build binaries by using the resp. compilers targeting Intel 64 and Intel Xeon Phi Architecture
Upload the binary to the Intel Xeon Phi coprocessor
Run instances of the MPI application on different mixed nodes

MPI+Offload Programming ModelMPI ranks on CPUs only
• All messages into/out of host CPUs
• Offload models used to accelerate MPI ranks
• Intel® Cilk™ Plus, OpenMP*, Intel® Threading Building Blocks, Pthreads* within Intel® Xeon Phi™ coprocessor
Build Intel® 64 executable with included offload by using the Intel compiler
Run instances of the MPI application on the host, offloading code onto coprocessor
Advantages of more cores and wider SIMD for certain applications

Offload Programming Model Overview• Programmer designates code sections to offload
• No further programming/API usage is needed• The compiler and the runtime automaticallymanage setup/teardown, data transfer, and synchronization
• Add pragmas and new keywords to working host code to make sections of code run on the Intel® Xeon Phi™ coprocessor
• Similar to adding parallelism to serial code using OpenMP* pragmas
• The Intel compiler generates code for both target architectures at once
• The resulting binary runs whether or not a coprocessor is present• Unless you use #pragma offload target(mic:cardnumber)
• The compiler adds code to transfer data automatically to the coprocessor and to start your code running (with no extra coding on your part)
• Hence the term “Heterogeneous Compiler” or “Offload Compiler”

Data Transfer Overview• The host CPU and the coprocessor do not share physical or virtual memory in hardware
• Two offload data transfer models are available:• 1. Explicit Copy
• Programmer designates variables that need to be copied between host and card in the offload pragma/directive
• Syntax: Pragma/directive‐based• C/C++ Example:
• #pragma offload target(mic) in(data:length(size))• 2. Implicit Copy (only Cilk+) – not covered here
• Programmer marks variables that need to be shared between host and card
• The same variable can then be used in both host and coprocessor code
• Runtime automatically maintains coherence at the beginning and end of offload statements

Data Transfer: C/C++ Offload using Explicit Copies
C/C++ Syntax Semantics
Offload pragma #pragma offload <clauses><statement>
Allow next statement toexecute on coprocessor orhost CPU
Offload transfer #pragma offload_transfer<clauses>
Initiates asynchronous data transfer, or initiates and completes synchronous data transfer
Offload wait #pragma offload_wait <clauses> Specifies a wait for a previously initiated asynchronous activity
Keyword forvariable & functiondefinitions
__attribute__((target(mic))) Compile function for, or allocate variable on, both CPU and coprocessor
Entire blocks ofcode
#pragma offload_attribute(push,target(mic))…#pragma offload_attribute(pop)
Mark entire files or large blocks of code for generation on both host CPU and Coprocessor

Conceptual Transformation

OpenMP* examples

Clauses / Modifiers Syntax Semantics
Target specification target( name[:card_number] ) Where to run construct
Inputs in(var‐list modifiersopt) Copy from host to coprocessor
Outputs out(var‐list modifiersopt) Copy from coprocessor to host
Inputs & outputs inout(var‐list modifiersopt) Copy host to coprocessor and back when offload completes
Non‐copied data nocopy(var‐list modifiersopt) Data is local to target
Conditional offload if (condition) Boolean expression
Modifiers
Specify pointer length length(element‐count‐expr) Copy N elements of the pointer’s type
Control pointer memory allocation
alloc_if ( condition ) Allocate memory to hold datareferenced by pointer if condition is TRUE
Control freeing of pointer memory
free_if ( condition ) Free memory used by pointer if condition is TRUE
Control target data alignment
align ( expression ) Specify minimum memoryalignment on target
Variables and pointers restricted to scalars, structs of scalars, and arrays of scalars

Rules & Limitations• The Host from/to Coprocessor data types allowed in a simple offload:
• Scalar variables of all types• Must be globals or statics if you wish to use them with nocopy, alloc_if, or free_if (i.e. if they are to persist on the coprocessor between offload calls)
• Structs that are bit‐wise copyable (no pointer data members)• Arrays of the above types• Pointers to the above types
• What is allowed within coprocessor code?• All data types can be used (incl. full C++ objects)• Any parallel programming technique (Pthreads*, Intel® TBB, OpenMP*, etc.)
• Intel® Xeon Phi™ versions of Intel® MKL

Offload using Explicit Copies: Example
float reduction(float *data, int numberOf){float ret = 0.f;#pragma offload target(mic) in(data:length(numberOf)){#pragma omp parallel for reduction(+:ret)for (int i=0; i < numberOf; ++i)ret += data[i];
}return ret;
}
Note: copies numberOf*sizeof(float)elements to the coprocessor, not numberOf bytes – the compiler knows data’s type

Data Movement
• Default treatment of in/out variables in a #pragma offload statement
• At the start of an offload:• Space is allocated on the coprocessor• in variables are transferred to the coprocessor
• At the end of an offload:• out variables are transferred from the coprocessor• Space for both types (as well as inout) is deallocated on the coprocessor

Heterogeneous Compiler: Reminder of What is Generated• Note that the compiler generates two binaries:
• The host version• includes all functions/variables in the source code, whether marked
• #pragma offload, • __attribute__((target(mic))) …….. or not
• The coprocessor version• includes only functions/variables marked in the source code
• #pragma offload, • __attribute__((target(mic)))
• Linking creates one executable with both binaries included!

Heterogeneous Compiler: Command‐line options• “–openmp” is automatically set when you build• Don’t need –no-offload if compiling only for Xeon
• Generates same Xeon only code as previous compilers• But –no-offload creates smaller binaries
• Most command line arguments set for the host are set for the coprocessor build
• Unless overridden by –offload-option,mic,xx=”…”
• Add –watch=mic-cmd to display the compiler options automatically passed to the offload compilation

Heterogeneous Compiler: Command‐line options cont.
Offload‐specific arguments to the Intel® Compiler:• Generate host only code (by default both host + coprocessor code is generated):-no-offload
• Produce a report of offload data transfers at compile time-opt-report-phase=offload
• Add Intel® Xeon Phi™ compiler switches-offload-options,mic,compiler,“switches”
• Add Intel® Xeon Phi™ assembler switches-offload-options,mic,as:“switches”
• Add Intel® Xeon Phi™ linker switches-offload-options,mic,ld,“switches”
Example:icc -I/my_dir/include -DMY_DEFINE=10 -offload-options, mic,compiler, “-I/my_dir/mic/include -DMY_DEFINE=20“ hello.cPasses “-I/my_dir/mic/include -I/my_dir/include -DMY_DEFINE=10 -DMY_DEFINE=20” to the offload compiler

Simultaneous Host/Coprocessor Computing• #pragma offload statement blocks thread until the statement completes
• Simultaneous host and coprocessor computing requires multiple threads of execution on the host:
• One or more to block until their #pragma offload statements completes
• Others to do simultaneous processing on the host
• You can use most multithreading APIs to do this• OpenMP* tasks or parallel sections• Pthreads*• Intel® TBB’s parallel_invoke, Intel® Cilk™ Plus, …

Simultaneous Host/Coprocessor Computing: using OpenMP*• Simply use OpenMP* task on host to spawn the offload call
• Then use OpenMP* for parallelism on the coprocessor
• Use other OpenMP* task calls to simultaneously run code on the host
#pragma omp parallel#pragma omp single{#pragma omp task#pragma offload target(mic) …{<various serial code>#pragma omp parallel forfor (int i=0; i<limit; i++)<parallel loop body>
}#pragma omp task{<host code or another offload>}
}
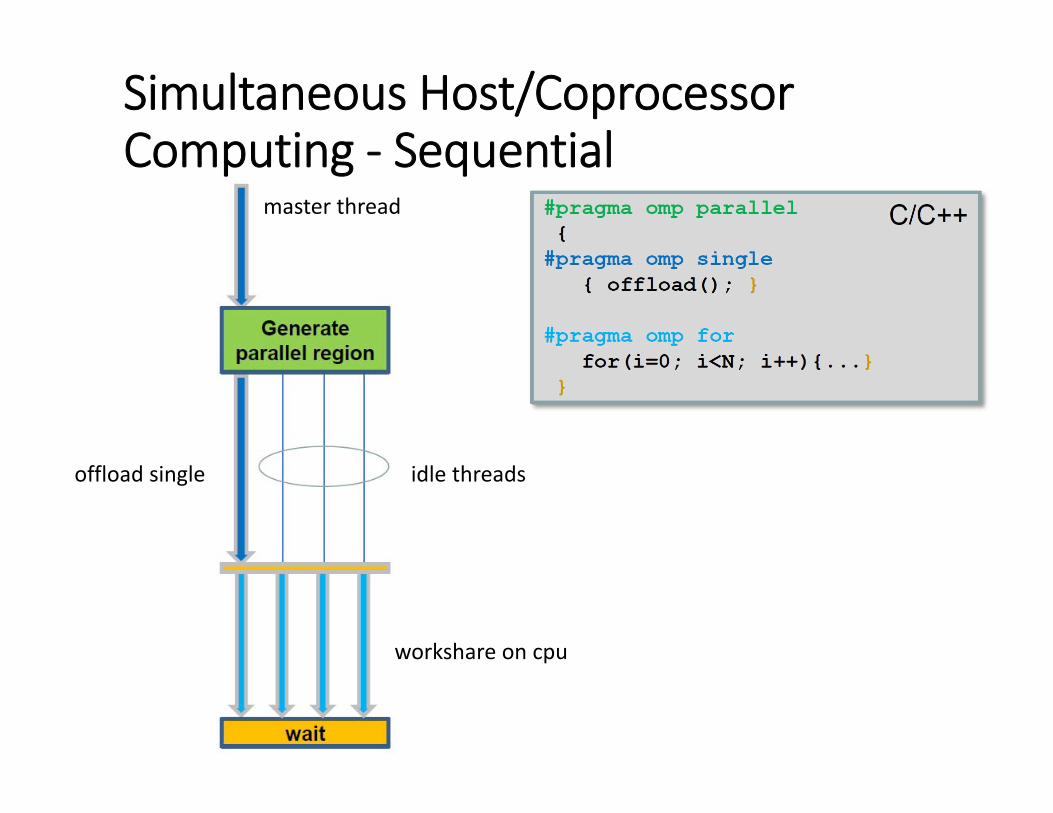
Simultaneous Host/Coprocessor Computing ‐ Sequential
master thread
offload single idle threads
workshare on cpu

Simultaneous Host/Coprocessor Computing ‐ Concurrent
master thread
offload singlenowait
workshare on cpu
assist when done in single

Thread Placement• Thread placement may be controlled with the following environment variable
• KMP_AFFINITY=<type>

Asynchronous Offload and Data Transfer
• signal() and wait()
• Available async functionality• offload• offload_transfer• offload_wait
• Examples#pragma offload target(mic:0) signal(flg1)
#pragma offload_transfer target(mic:0) signal(flg2) wait(flg1)
#pragma offload_wait target(mic:0) wait(flg1)

Signal, Wait and tag• Examples
#pragma offload_transfer target(mic:0) \signal(tagA) wait(tag0, tag1) ...
• Do not start transfer until the operations signaling tag0 and tag1 are complete
• Upon completion, indicate completion using tagA
#pragma offload target(mic:0) \signal(tagB) wait(tag2, tag3, tag4) ...
• Do not start until the operations signaling tag2, tag3 and tag4 are complete
• Upon completion, indicate completion using tagB

Signal, Wait and tag • Notes
• Tags can be a pointer to data of any datatype• E.g. char *myFlag; float *array• Can be a pointer to an explicit signal or even to the data being transferred.
• If you are using signal() or wait()• You must specify an explicit card (e.g. target(mic:0) )• #pragma offload_wait must have a wait() parameter
float *inArray = new float[10000]; char mySignal;#pragma offload_transfer target(mic:0) signal(inArray)\in(inArray:length(theSize))#pragma offload target(mic:0) signal(&mySignal) \nocopy(inArray)

Persistence of Pointer Data• Default treatment of in/out variables in a #pragma offload statement
• At the start of an offload:• Space is allocated on the coprocessor• in variables are transferred to the coprocessor
• At the end of an offload:• out variables are transferred from the coprocessor• Space for both types (as well as inout) is deallocated on the coprocessor
• This behavior can be modified• free_if(boolean) controls space deallocation on the coprocessor at the end of the offload
• alloc_if(boolean) controls space allocation on coprocessor at the start of the offload
• Use nocopy rather than in/out/inout to indicate that the variable’s value is reused from a previous offload or is only relevant within this offload section

Persistence of Pointer Data: Example• Allocate space on coprocessor, transfer data to, and do not release at end (persist)
• Use persisting data in subsequent offload code• At end, transfer data from, and deallocate
__attribute__((target(mic))) static float *A, *B, *C, *C1;
// Transfer matrices A, B, and C to MIC device and // do not deallocate matrices A and B#pragma offload target(mic) \
in(transa, transb, M, N, K, alpha, beta, LDA, LDB, LDC) \in(A:length(NCOLA * LDA) alloc_if(1) free_if(0)) \ // e.g. ALLOCin(B:length(NCOLB * LDB) alloc_if(1) free_if(0)) \ //and RETAINinout(C:length(N * LDC))
{sgemm(&transa, &transb, &M, &N, &K, &alpha, A, &LDA, B, &LDB, &beta, C, &LDC);
}

Persistence of Pointer Data: Example
// Transfer matrix C1 to MIC device and reuse matrices A and B#pragma offload target(mic) \
in(transa1, transb1, M, N, K, alpha1, beta1, LDA, LDB, LDC1) \nocopy(A:length(NCOLA * LDA) alloc_if(0) free_if(0)) \ // e.g. REUSEnocopy(B:length(NCOLB * LDB) alloc_if(0) free_if(0)) \ //and RETAINinout(C1:length(N * LDC1))
{sgemm(&transa1, &transb1, &M, &N, &K, &alpha1, A, &LDA, B, &LDB, &beta1, C1, &LDC1);
}
// Deallocate A and B on an Intel(R) Xeon Phi(TM) device#pragma offload target(mic) \
nocopy(A:length(NCOLA * LDA) alloc_if(0) free_if(1)) \ // e.g. REUSEnocopy(B:length(NCOLB * LDB) alloc_if(0) free_if(1)) \ //and FREEinout(C1:length(N * LDC1))
{x = stuff(C1);
}

Allocation for Parts of Arrays• Allocation of array slices is possible
• alloc(p[5:1000]) modifier allocate 1000 elements on coprocessor
• first useable element has index 5, last 1004 (dark blue + orange) • p[10:100] specifies 100 elements to transfer (orange)
int *p; // 1000 elements allocated. Data transferred into p[10:100] #pragma offload … in ( p[10:100] : alloc(p[5:1000]) ) { … }
Array length 1005lengthfirst element
source: Tim Cramer, Rechen‐ und Kommunikationszentrum (RZ)
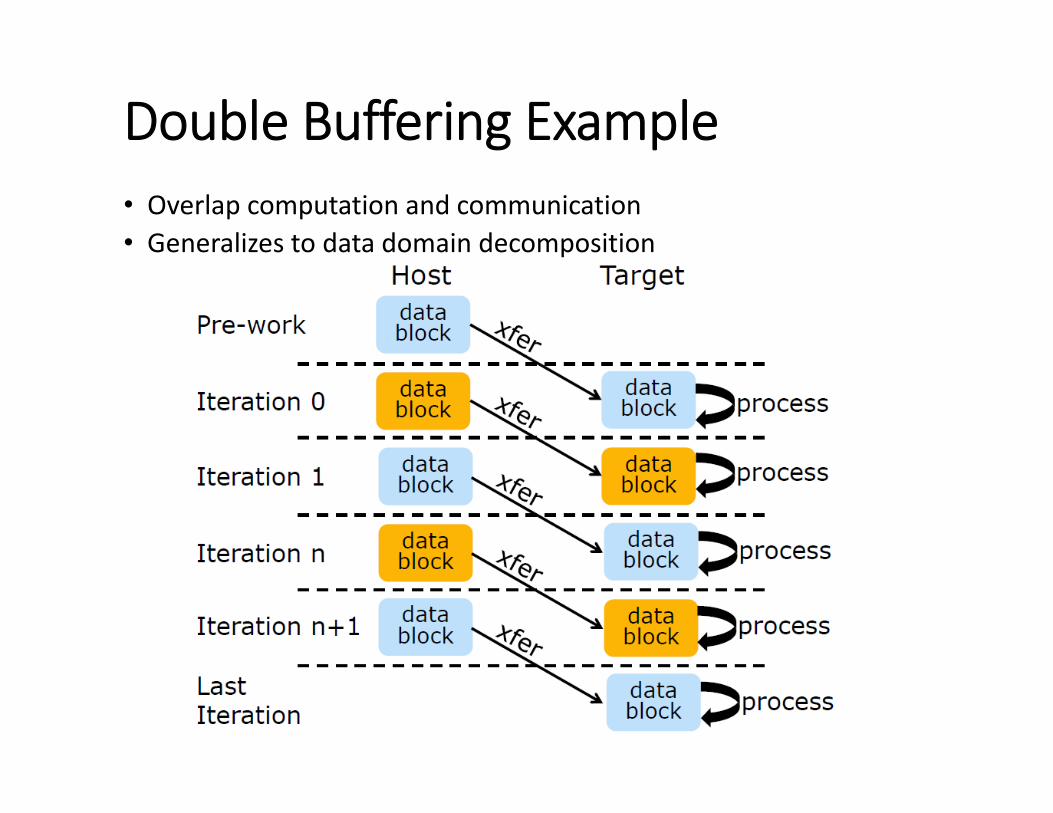
Double Buffering Example• Overlap computation and communication• Generalizes to data domain decomposition

Double Buffering Example

Double Buffering Example

Intel Math Kernel Library ‐MKLUsage Models on Intel Xeon Phi Coprocessor
• Automatic Offload • No code changes required • Automatically uses both host and target • Transparent data transfer and execution management
• Compiler Assisted Offload • Explicit controls of data transfer and remote execution using compiler offload pragmas/directives
• Can be used together with Automatic Offload
• Native Execution • Compile and run code directly on the Xeon Phi• Input data is copied to targets in advance ‐ no need to trasfer data• homogeneous

As of Intel MKL 11.0.2 only the following functions are enabled for AO:
Level‐3 BLAS functions‐ ?GEMM (for m,n > 2048, k > 256)‐ ?TRSM (for M,N > 3072)‐ ?TRMM (for M,N > 3072)‐ ?SYMM (for M,N > 2048)
LAPACK functions‐ LU (M,N > 8192), QR, Cholesky
MKL ‐ Using Automatic Offload#include <mkl.h>…int main(int argc, char** argv){
…sgemm( … )
}
export MKL_MIC_ENABLE = 1export OFFLOAD_REPORT = 2
MKL_MIC_ENABLE can be also invoked from the code using the function mkl_mic_enable()
If no MIC card is present, the code will run as usual on the host machine
./icc mkl sgemm.c o sgemm.x
Computing SGEMM on the hostEnabling Automatic OffloadAutomatic Offload enabled: 1 MIC devices presentComputing SGEMM with automatic workdivision[MKL] [MIC --] [AO Function] SGEMM[MKL] [MIC --] [AO SGEMM Workdivision] 0.00 1.00[MKL] [MIC 00] [AO SGEMM CPU Time] 0.463351 seconds[MKL] [MIC 00] [AO SGEMM MIC Time] 0.179608 seconds[MKL] [MIC 00] [AO SGEMM CPU->MIC Data] 52428800 bytes[MKL] [MIC 00] [AO SGEMM MIC->CPU Data] 26214400 bytesDone

MKL ‐ Compiler assisted offload (CAO)• controlled by directives and pragmas• it can be extended to any MKL function (AO is available only for a subset)
• data transfer and offload is completely managed by the programmer • can exploit data persistence on the MIC
#pragma offload target(mic) \in(transa, transb, N, alpha, beta) \in(A:length(matrix_elements)) \in(B:length(matrix_elements)) \in(C:length(matrix_elements)) \out(C:length(matrix_elements) alloc_if(0)){
sgemm(&transa, &transb, &N, &N, &N, &alpha, A, &N, B,&N,&beta, C, &N);
}

MKL ‐ Choose your usage model
Native if:
‐highly parallel code;
‐want to use MIC cards only;
‐ you use highly MIC optimized MKL functions
AO if:
‐data transfer time is < computation time
‐ you use BLAS3 level functions
‐ you use LU, QR, Cholesky
CAO if:
‐ you want to manage data transfer
‐ you need to use particular MKL functions (not AO‐able)
‐ you want to exploit data persistence

Performance:DGEMM on Xeon Phi• Xeon Phis have 60 cores, 4 HW threads/core:
• $ export OMP_NUM_THREADS=240
• First try … and fail:• $./dgemm_offload• Matrices of size 10000x10000
• 250 Gflops
• Theoretical peak performance is:• peak = (# cores)*(vector size)*(ops/cycle)*(frequency)• peak = 60*8*2*1.052 = 1011 Gflops!
Where are the flops?

Performance:Thread Affinity• Affinity is VERY important on manycore systems. By setting KMP_AFFINITY performance is significantly affected:
• Scatter affinity:• export ENV_PREFIX=MIC; • export MIC_KMP_AFFINITY=scatter; ./dgemm_offload
• 250 Gflops
• Compact affinity:• export MIC_KMP_AFFINITY=compact; ./dgemm_offload
• 500 Gflops
• Balanced affinity:• export MIC_KMP_AFFINITY=balanced; ./dgemm_offload
• 500 Gflops
• Balanced was introduced to the MIC

Performance:Alignment and Huge pages Huge Pages For any array allocation bigger than 10MB, use huge pages:
• export MIC_USE_2MB_BUFFERS=10M• 750 Gflops
Alignment• As a general rule, we need to align arrays to the vector size.
• 16‐byte alignement for SSE processors, • 32‐byte alignement for AVX processors, • 64‐byte for Xeon Phi.
• In offload mode the compiler will consider that arrays alignment is the same on both the host and the device. We need to change the alignement on the host to match that on the device:
double *A = (double*) \_mm_malloc(sizeof(double)*size_A, Alignment);
Alignment = 16 Alignment = 64 750 Gflops 780 Gflops
Inspired by: Gilles Fourestey, CSCS
From 37 % to 80% of the peak performance

[Offload] [MIC 0] [Tag 0] [MIC Time] 8.25 7.89 (seconds) 240 GFLOPS
[Offload] [MIC 0] [Tag 0] [MIC Time] 7.95 7.33 (seconds) 250 GFLOPS
[Offload] [MIC 0] [Tag 0] [MIC Time] 7.82 7.65 (seconds) 255 GFLOPS
[Offload] [MIC 0] [Tag 0] [MIC Time] 4.00 4.00 (seconds) 500 GFLOPS
[Offload] [MIC 0] [Tag 0] [MIC Time] 4.00 4.00 (seconds) 500 GFLOPS
[Offload] [MIC 0] [Tag 0] [MIC Time] 2.67 2.57 (seconds) 750 GFLOPS
[Offload] [MIC 0] [Tag 0] [MIC Time] 2.67 2.58 (seconds) 750 GFLOPS
[Offload] [MIC 0] [Tag 1] [MIC Time] 2.67 (seconds) 750 GFLOPS[Offload] [MIC 0] [Tag 1] [MIC Time] 2.67 (seconds) 750 GFLOPS[Offload] [MIC 0] [Tag 1] [MIC Time] 2.57 (seconds) 780 GFLOPS
MIC_OMP_NUM_THREADS=240, Data alignment = 16
MIC_KMP_AFFINITY=“disabled"
MIC_KMP_AFFINITY=“none"
MIC_KMP_AFFINITY="scatter"
MIC_KMP_AFFINITY="compact"
MIC_KMP_AFFINITY="balanced"
MIC_USE_2MB_BUFFERS=100M
MIC_OMP_NUM_THREADS=236MIC_KMP_AFFINITY="compact“
Data alignment = 16 Data alignment = 32Data alignment = 64
Performance:DGEMM on Anselm
Matrix dimension is set to 10 000
default
leave one core for OS

Stream benchmark on Anselm Size of input arrays [MB]
Bandwidth GB/s
32 119.304764 142.6699128 148.3955256 156.2842512 159.26461024 158.77832048 159.02154096 159.0313
0
50
100
150
200
1 8 64 512 4096
Triad bandwidth GB/s
http://software.intel.com/en‐us/articles/optimizing‐memory‐bandwidth‐on‐stream‐triadhttp://www.cs.virginia.edu/stream/stream_mail/2013/0002.html
Compiler Knobs–mmic :build an application that runs natively on Intel® Xeon Phi coprocessor–O3 :optimize for maximum speed and enable more aggressive optimizations that may not improve performance on some programs–openmp: enable the compiler to generate multi-threaded code based on the OpenMP* directives (same as -fopenmp)-opt-prefetch-distance=64,8:Software Prefetch 64 cachelines ahead for L2 cache;
Software Prefetch 8 cachelines ahead for L1 cache-opt-streaming-cache-evict=0:Turn off all cache line evicts-opt-streaming-stores always: enables generation of streaming stores under the assumption that the application is memory bound-DSTREAM_ARRAY_SIZE=64000000: Increasing the size of the array size to be compliant with the STREAM Rules-mcmodel=medium: compiler restricts code to the first 2GB; no memory restriction on data
a(i) = b(i) + q*c(i)

static void add(double* l, double* r, double *res, int length){# pragma offload target(mic) in(length) in(l,r,res : REUSE){
#ifdef __MIC__# pragma omp parallel
{int part = length/omp_get_num_threads();int start = part*omp_get_thread_num();double *myl=l+start, *myr=r+start, *myres=res+start;
# pragma noprefetchfor (int L2 = 0; L2+512*1024/8/4 <= part; L2 += 512*1024/8/4){
# pragma nofusion# pragma noprefetch
for (int L1 = 0; L1+32*1024/8/4 <= 512*1024/8/4; L1 += 32*1024/8/4){
# pragma nofusion# pragma noprefetch
for (int cacheline = 0; cacheline+8 <= 32*1024/8/4; cacheline += 8){
_mm_prefetch((char*)myr+L2+L1+cacheline, _MM_HINT_T1);_mm_prefetch((char*)myl+L2+L1+cacheline, _MM_HINT_T1);
}# pragma nofusion# pragma noprefetch
for (int cacheline = 0; cacheline+8 <= 32*1024/8/4; cacheline += 8){
_mm_prefetch((char*)myr+L2+L1+cacheline, _MM_HINT_T0); _mm_prefetch((char*)myl+L2+L1+cacheline, _MM_HINT_T0);
}# pragma nofusion# pragma noprefetch
for (int cacheline = 0; cacheline+8+8+8+8 <= 32*1024/8/4; cacheline += 8+8+8+8){__m512d r0 = _mm512_load_pd(myr+L2+L1+cacheline+0*8); __m512d l0 = _mm512_load_pd(myl+L2+L1+cacheline__m512d r1 = _mm512_load_pd(myr+L2+L1+cacheline+1*8); __m512d l1 = _mm512_load_pd(myl+L2+L1+cacheline
_mm512_storenrngo_pd(myres+L2+L1+cacheline+0*8, _mm512_add_pd(r0, l0));_mm512_storenrngo_pd(myres+L2+L1+cacheline+1*8, _mm512_add_pd(r1, l1));
#pragma omp parallel forfor (j=0; j<STREAM_ARRAY_SIZE; j++)a[j] = b[j]+scalar*c[j];
Stream triad

Roofline Model for Intel Xeon Phi
• Memory bandwidth measured with the STREAM benchmark is about 157 GB/s • To reach the peak performance an even mix of multiply and add operations is
need (“fused multiply add”) • Without SIMD vectorization only 1/16 of the peak performance is achievable
Peak performance of a Intel Xeon Phi Coprocessor (1.2 GHz) is • 1171 GFLOPS • (1.2 GHz * 16 OPs/cycle * 61 cores)
source: Tim Cramer, Rechen‐ und Kommunikationszentrum (RZ)

Roofline Model for Intel Xeon Phi Sparse Matrix Vector Multiplication
Intel Xeon Phi STREAM 156 GB/s, O=1/6
source: Tim Cramer, Rechen‐ und Kommunikationszentrum (RZ)
SpMV • ∗• , can be kept in the cache (~ 15 MB), A too big for caches (~ 3200 MB) • Compressed Row Storage (CRS) Format: • 1 value (double) and 1 index (int) element have to be loaded → 12 Bytes
• Operational intensity 212 (→ memory-bound)
2xCPU Sandy Bridge 2.6 GHz, STREAM 74.2 GB/s, Peak 332.8 GFLOPS


Thank you
Lubomír Říha
This project is funded by Structural Funds of the European Union and state budget of the Czech Republic


















