

Parsing Discrete Mathematics and Its Applications Baojian Hua [email protected].
56
-
date post
19-Dec-2015 -
Category
Documents
-
view
227 -
download
0
Transcript of Parsing Discrete Mathematics and Its Applications Baojian Hua [email protected].

Syntax Tree A systematic way to put some program into
memory data type definition + a bunch of functions programmer explicit calls them
tedious and error-prone
But we write programs in ASCII form, so how can we construct the tree automatically? A technique called (automatic) parsing A program clever enough to do this automatically

Roadmap
Lexer: eat ascii sequence, emit token sequence
Parser: eat token sequence, emit abstract syntax trees
other part: later in this course
Lexer Parser
stream ofcharacters
stream oftokens
abstractsyntax other
part

Parsing
Take as input a sequence of terminals, and construct syntax trees automatically
Problem: how do we know whether a sequence of input tokens is valid?

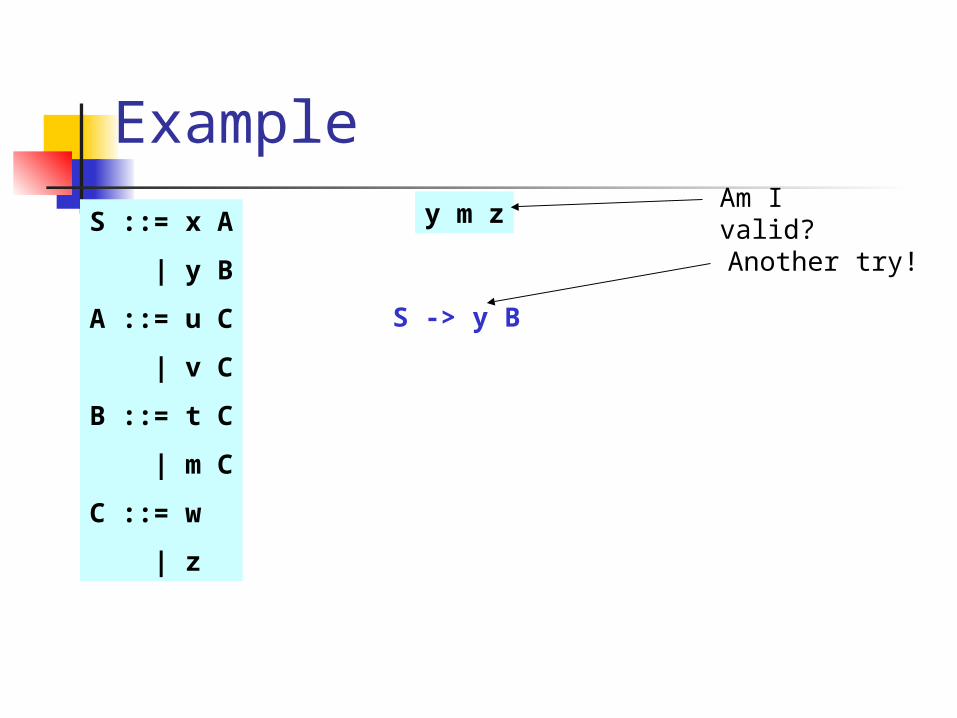
Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
y m zAm I valid?
S -> x A
Oops, mismatch!
Nonterminals: S A B C
terminals: ID_X ID_Y ID_U ID_V ID_T ID_M ID_W ID_Z
Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
y m zAm I valid?
S -> y B
Another try!

Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
y m zAm I valid?
S -> y B
Aha, Great!
Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
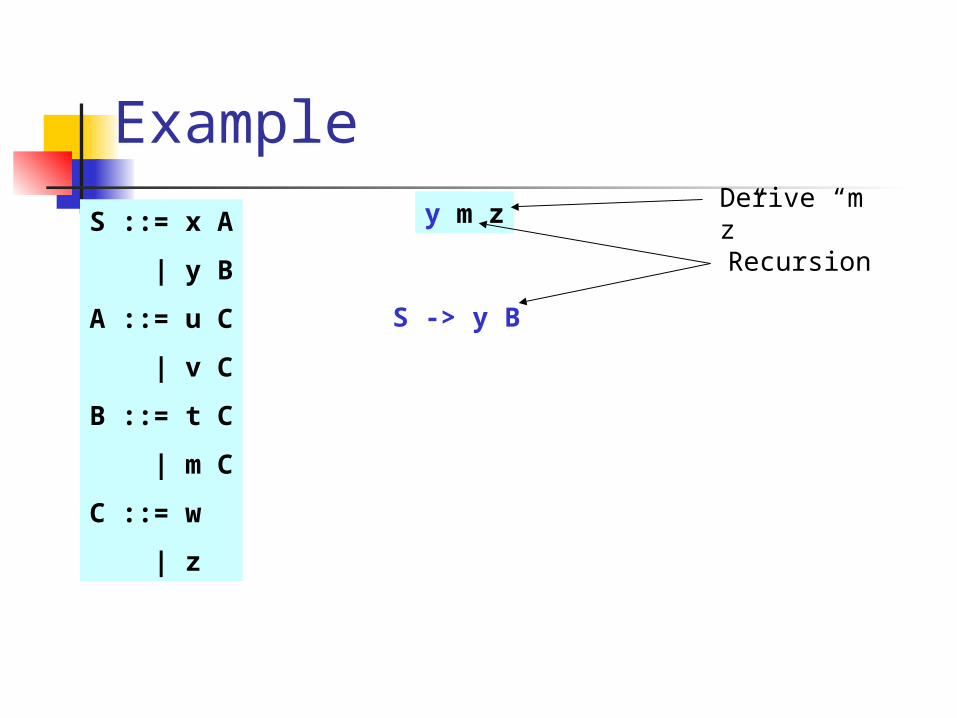
y m zDerive “m z”
S -> y B
Recursion

Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
y m zDerive “m z”
S -> y B
B -> t C
First try

Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
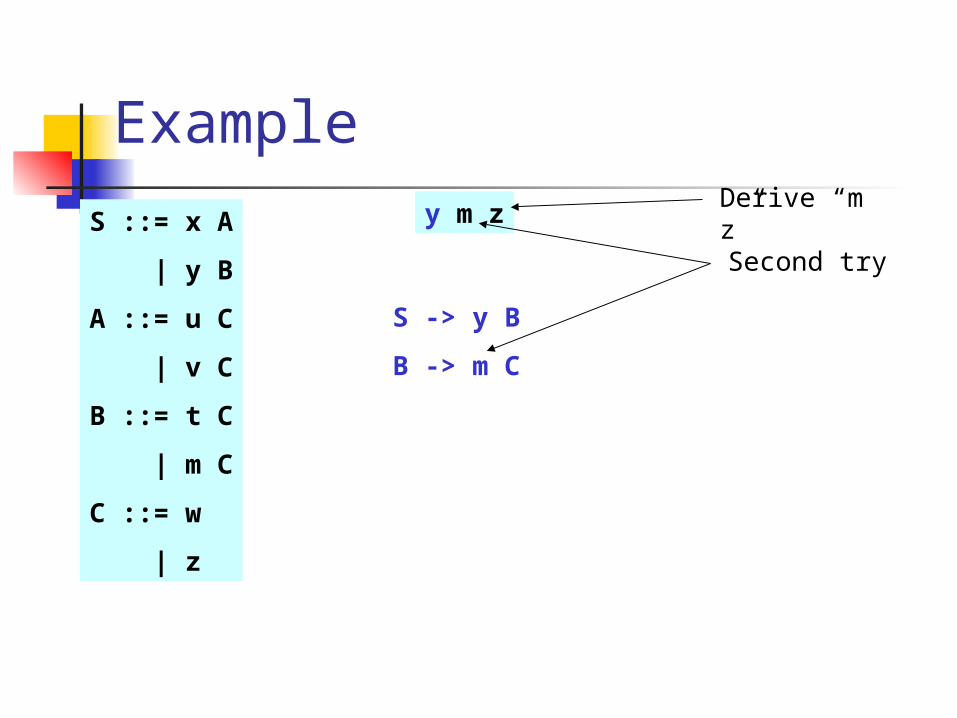
y m zDerive “m z”
S -> y B
B -> t C
Mismatch
Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
y m zDerive “m z”
S -> y B
B -> m C
Second try
Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
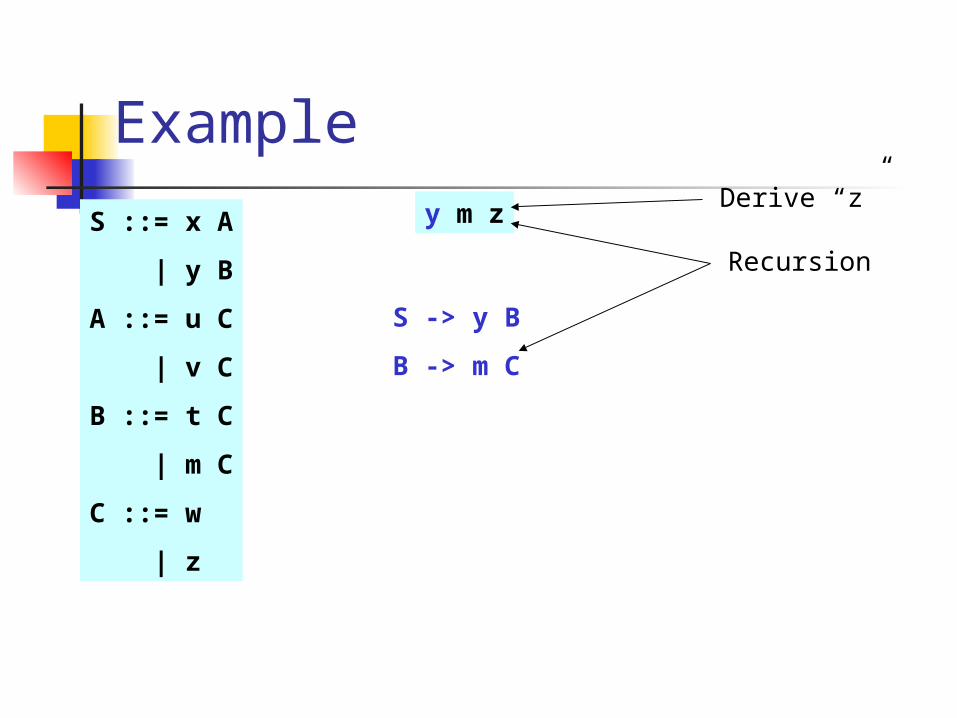
y m zDerive “z”
S -> y B
B -> m C
Recursion

Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
y m zDerive “z”
S -> y B
B -> m C
C -> w
Mismatch

Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
y m zDerive “z”
S -> y B
B -> m C
C -> z
Second try

Example
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z
y m zDerive “z”
S -> y B
B -> m C
C -> z
Matched. Sucess
S
y B
m C
z

Recursive Decedent Algorithm
This process can be described by a recursive decedent algorithm For each nonterminal, write a (recursive)
parsing function every RHS becomes a case in a big switch function may take some semantic action
s, besides parsing later in this course

Recursive Decedent Algorithm// The function interface looks like:
void parseS ();
void parseA ();
void parseB ();
void parseC ();
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z

Recursive Decedent Algorithmstruct token t; // recall the token module t = getToken (); // and the lexer module
void parserS (){ switch (t) { case ID_X: t = getToken (); parseA (); return; case ID_Y: t = getToken (); parseB (); return;
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z

Recursive Decedent Algorithm default: // not ID_X or ID_Y error (“want ‘x’ or ‘y’); return; }}
// Leave the algorithm for// parseA (), parseB () and// parseC () to you.
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z

Summary so Far Recursive decedent parsing:
also called predictive parsing, or top-down parsing
simple and efficient can be coded by hand quickly
see problem 2 in lab #4
But the constraint is that not all formal grammar can be parsed by a recursive decedent parser Example below

Example
S ::= x A
| x B
A ::= m C
| m C
B ::= m z
| m z
C ::= w
| y
x m zDerive me
S -> x A
or
S -> x B

Recursive Decedent Algorithm?struct token t; // recall the token module t = getToken (); // and the lexer module
void parserS (){ switch (t) { case ID_X: t = getToken (); ?????? // what code here? return; default: error (“….”); return;}}
S ::= x A
| x B
A ::= m C
| m C
B ::= m z
| m z
C ::= w
| y

Another Example
stm -> id = exp; | id = exp; stm exp -> exp + exp | exp - exp | num | id | (exp)
x = 3+4;y = x-(1+2);
Derive me
stm -> id = exp;
or
stm -> id = exp; stm

Moral
We’d introduce a notion of what’s a production’s RHS s could start with s\in (T\/N)*
We call it a first (terminal) set, written as F[s], for string s\in (T\/N)*
Next, we first compute the first set F for given terminals or nonterminals

First Set FF [S] = {x, y}
F [A] = {u, v}
F [B] = {t, m}
F [C] = {w, z}
// And generalize to string
F [x A] = {x}
F [y B] = {y}
F [u C] = {u}
F [v C] = {v}
…
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z

First Set FF (S) = {x, y}F (A) = {u, v}F (B) = {t, m}F (C) = {w, z}
// And generalize to stringF (x A) = {x}F (y B) = {y}F (u C) = {u}F (v C) = {v}…// Then why this grammar could be parsed?
S ::= x A
| y B
A ::= u C
| v C
B ::= t C
| m C
C ::= w
| z

Parsing Table
x y u v t m …
S s->x A S->y B
A A->u C A -> v C
B B->t C B->m C
C …

Example
S ::= x A
| x B
A ::= m C
| m C
B ::= m z
| m z
C ::= w
| y
F (S) = ?
F (A) = ?
F (B) = ?
F (C) = ?
Predicative parsing?

Another Example
stm -> id = exp; | id = exp; stm exp -> exp + exp | exp - exp | num | id | (exp)
F (stm) = ?
F (exp) = ?
Predicative parsing?

Empty Production Rules
Z ::= d
| X Y Z
Y ::= c
| \eps
X ::= Y
| a
F (Z) = ?
F (Y) = ?
F (X) = ?
Predicative parsing?

Algorithm #1: nullable// nullable[X]: whether X derives \eps or not
// all initialized to false
repeat
for each production rule X -> Y1 Y2 … Yn
if (nullable[Y1, …, Yn]=true) or (n=0))
nullable[X] = true
until nullable[] did not change

Example
Z ::= d
| X Y Z
Y ::= c
| \eps
X ::= Y
| a
// initialization
nullable[Z, Y, X] = false
// round 1
nullable[Z] = false
nullable[Y] = true
nullable[X] = true
// round 2nullable[Z] = falsenullable[Y] = truenullable[X] = true// finished!

Algorithm #2: First Set// F[X]: first terminals X could derive
// all initialized to empty
repeat
for each production rule X -> Y1 Y2 … Yn
for (i=1 to n)
if (nullable[Y1, Y2, Y_{i-1}]=true or (i=1))
F[X] = F[X] \/ F[Yi]
until F[] did not change

Example
Z ::= d
| X Y Z
Y ::= c
| \eps
X ::= Y
| a
// initialization
F[Z, Y, X] = {}
// round 1
F[Z] = {d}
F[Y] = {c}
F[X] = {c, a}
// round 2F[Z] = {d, c, a}F[Y] = {c}F[X] = {c, a}// round 3…

Pitfalls
S ::= x A B
A ::= y
| \eps
B ::= y
| \eps
Try to calculate nullable[] and F[]
Try to derive “x y”
What’s the problem?

Algorithm #3: Follow Set// W[X]: terminals may follow X// all initialized to emptyrepeat for each production rule X -> Y1 Y2 … Yn for (i=1 to n) for (j=i+1 to n) if (nullable[Y_{i+1}, …, Yn]=true or (i=n)) W[Yi] = W[Yi] \/ W[X] if (nullable[Y_{i+1}, …, Y_{j-1}]=true
or(i+1=j)) W[Yi] = W[Yi] \/ F[Yj]until W[] did not change

Example
Z ::= d
| X Y Z
Y ::= c
| \eps
X ::= Y
| a
// initialization
W[Z, Y, X] = {}
// round 1
W[Z] = {EOF}
W[Y] = {d, c, a}
W[X] = {c, d, a}
// round 2W[Z] = {EOF}W[Y] = {d, c, a}W[X] = {d, c, a}// finished!

First and Follow Together
Z ::= d
| X Y Z
Y ::= c
| \eps
X ::= Y
| a
// firstF[Z] = {d, c, a}F[Y] = {c}F[X] = {c, a}
// followW[Z] = {EOF}W[Y] = {d, c, a}W[X] = {d, c, a}
// firstAll[X] = { F[X], if nullable[X]=false { W[X], otherwise.
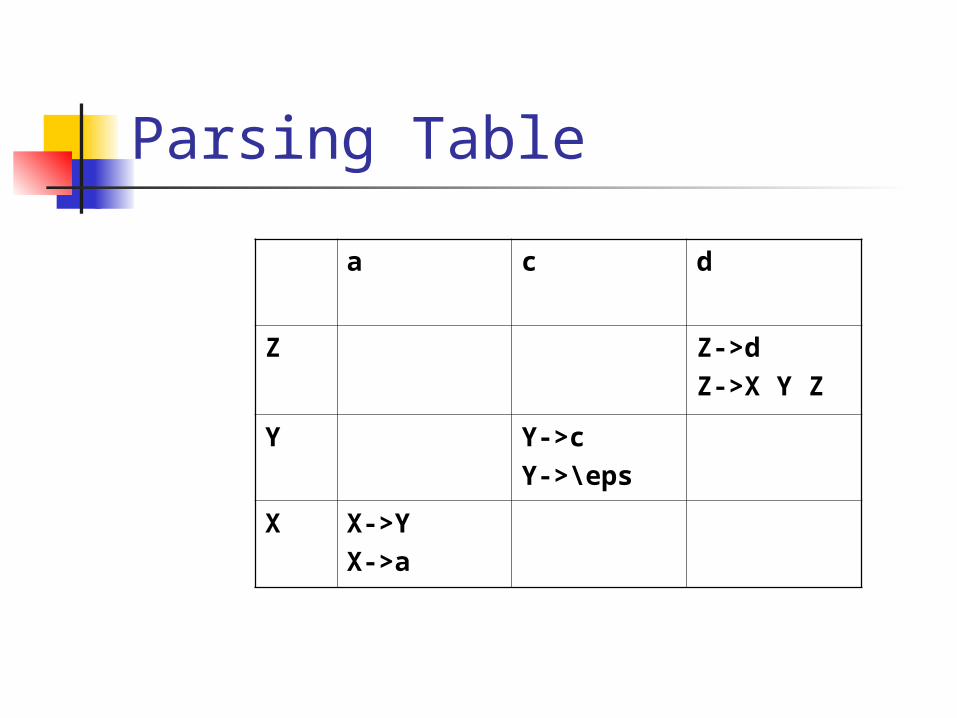
Parsing Table
a c d
Z Z->d
Z->X Y Z
Y Y->c
Y->\eps
X X->Y
X->a

LL(1) Grammar whole predicative parsing tables
contain no duplicate entries are called LL(1) left-to-right parse, left-to-right-derivation, 1-sy
mbol lookahead one pass, no backtracking, very efficient precise error reports
For some non-LL(1) grammar, there are some standard methods to transform them example below

Eliminating Left Recursion
X -> X a
| c
// General transforming rules:X -> X α1 | … | X αm | β1 | … | βn // toX -> β1 X’ | … | βn X’X’ -> α1 X’ | … | αm X’ | \eps
X -> c X’
X’ -> a X’
| \eps

Eliminating Left Recursion
S -> if (E) then S else S;
| if (E) then S;
// General rules:X -> α X1 | … | α Xn// toX -> α X’X’ -> X1 | … | Xn
S -> if (E) then S S’
S’ -> else S;
| ;

Eliminating Ambiguity In programming language syntax, am
biguity often arises from missing operator precedence or associativity * higher precedence than +? * and + are left associative?
Ambiguious grammar are hard to use as language syntax

Ambiguous grammars
A grammar is ambiguous if there is a sentence with >1 parse tree
15 - 3 - 4E
E - E
15 E - E
3 4
E
E - E
4E - E
15 3

Association
exp -> exp - exp
| num
// Derivation #1:exp -> exp - exp -> 15 - exp -> 15 - exp - exp -> 15 - 3 - exp -> 15 - 3 - 4// Derivation #2:exp -> 15 X -> 15 - 3 X -> 15 - 3 - 4 X -> 15 - 3 - 4
exp -> num X
X -> - num X
| \eps

Precedence
exp -> exp - exp
| exp * exp
| num
// But the derivation: 3-4*5exp -> 3 X -> 3 - 4 X -> 3 - 4 X -> 3 - 4 * 5 X -> 3 - 4 * 5 X -> 3 - 4 * 5 \eps -> 3 - 4 * 5
// What’s the problem?
exp -> num X
X -> - num X
| * num X
| \eps

Precedence
exp -> exp - exp
| exp * exp
| num
// The derivation: 3-4*5exp -> term X -> 3 Y X -> 3 \eps X -> 3 X -> 3 - term X -> 3 - 4 Y X -> 3 - 4 * 5 Y X -> 3 - 4 * 5 \eps X -> 3 - 4 * 5 X -> 3 - 4 * 5 \eps -> 3 - 4 * 5
exp -> term X
X -> - term X
| \eps
term -> num Y
Y -> * num Y
| \eps

Parsing Function// Given production: X -> s// Parsing function has the form:void parseX (){
trans (s);}// case analysis on possible shape of s:// 1. s == a; for some terminal atrans (a) = if (t==a) t = nextToken (); else error (“syntax error: expecting: a”);

Parsing Function// Given production: X -> s
void parseX ()
{
trans (s);
}
// case analysis on possible shape of s:
// 2. s == Y; for some nonterminal Y
trans (Y) =
Y ()

Parsing Function// Given production: X -> s
void parseX ()
{
trans (s);
}
// case analysis on possible shape of s:
// 3. s == s1 s2 … sn
trans (s1 s2 … sn) =
trans(s1) trans(s2) … trans(sn)

Parsing Function// Given production: X -> svoid parseX (){
trans (s);}// case analysis on possible shape of s:// 4. s == s1 | s2 | … | snif (t\in All[s1]) trans(s1)else if (t\in All[s2]) trans(s2)…else if (t\in All[sn]) trans(sn)else error (“syntax error: …”);

Parsing Function// Given production: X -> s
void parseX ()
{
trans (s);
}
// case analysis on possible shape of s:
// 5. s == [s’]
if (t\in All[s’]) trans(s’)

Parsing Function// Given production: X -> s
void parseX ()
{
trans (s);
}
// case analysis on possible shape of s:
// 6. s == {s’}
while (t\in All[s’]) trans(s’)

Parsing Function Generating Trees// We only analyze case 3, other are similar:
// 3. s == s1 s2 … sn
S parseS ()
{
S1 v1 = parseS1 ();
S2 v2 = parseS2 ();
…;
Sn vn = parseSn ();
return newS (v1, …, vn);
}

David Cutler
“ 编程绝对是你遇到的最奇怪的事情,代码写好后,你坚信自己是对的,然而运行结果却证明你错了。你错了是因为你从来都是错的,只
不过是编程让你第一次意识到了这一点。”

Automatic Tools
semantic analyzer
specification
parser
YaccOriginally developed for C, and now almost every main-st
ream language has its own Yacc-like tool:
bison (C), ml-yacc (SML), Cup (Java), GPPG (C#), …


















