
Parallel Programming with MPI Parallel programming overview Brief overview of MPI General Program...
120
Parallel Programming with MPI SARDAR USMAN & EMAD ALAMOUDI SUPERVISOR: PROF. RASHID MEHMOOD [email protected] MARCH 14, 2018
Transcript of Parallel Programming with MPI Parallel programming overview Brief overview of MPI General Program...

Parallel Programming with MPISARDAR USMAN & EMAD ALAMOUDI
SUPERVISOR: PROF. RASHID MEHMOOD
MARCH 14, 2018

SourcesThe presentation is compiled using following sources.▪ http://mpi-forum.org/docs/
▪ https://computing.llnl.gov/tutorials/mpi/
▪ http://open-mpi.org
▪ http://mpi.deino.net/mpi_functions/index.htm
▪ http://mpitutorial.com/tutorials
▪ https://bioinfomagician.wordpress.com/category/parallel-computing/
▪ https://lsi.ugr.es/jmantas/ppr/ayuda/mpi_ayuda.php?ayuda=MPI_Barrier&idioma=en
PARALLEL PROGRAMMGIN WITH MPI 23/18/2018

Outline▪ Parallel programming overview
▪ Brief overview of MPI▪ General Program Structure
▪ Basic MPI Functions
▪ Point to point Communication
▪ Communication modes
▪ Blocking and non-blocking communication
▪ MPI Collective Communication
▪ MPI Groups and Communicators
PARALLEL PROGRAMMGIN WITH MPI 33/18/2018

Parallel Computing
4PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Why Parallel ComputingSave Time and Money
5PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Why Parallel Computing▪ Solve Large/More Complex problems e.g. Web Search engines/databases processing millions of instructions/second.
▪ Provide Concurrency
▪ Take advantage of non-local resources
▪ Make better use of underlying parallel hardware
▪ Parallelism is future of computing and race is already on for Exascale computing.
6PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Parallel Programming Models▪ There are several parallel programming models in common use: ▪ Shared Memory (without threads)
▪ Threads
▪ Distributed Memory / Message Passing
▪ Hybrid
▪ Single Program Multiple Data (SPMD)
▪ Multiple Program Multiple Data (MPMD)
▪ Parallel programming models exist as an abstraction above hardware and memory architectures.
7PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Two Memory Models▪ Shared memory: all processors share the same address space▪ OpenMP: directive-based programming
▪ PGAD languages (UPC, Titanium, X10)
▪ Distributed memory: every processor has its own address space▪ MPI: Message Passing Interface
3/18/2018 PARALLEL PROGRAMMGIN WITH MPI 8

Shared Memory Model On A Distributed Memory Machine▪ Kendall Square Research (KSR) ALLCACHE approach. Machine memory was physically distributed across networked machines, but appeared to the user as a single shared memory global address space. Generically, this approach is referred to as "virtual shared memory".
11PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Distributed Memory Model On A Shared Memory Machine▪ Message Passing Interface (MPI) on SGI Origin 2000. The SGI Origin 2000 employed the CC-NUMA type of shared memory architecture, where every task has direct access to global address space spread across all machines. However, the ability to send and receive messages using MPI, as is commonly done over a network of distributed memory machines, was implemented and commonly used.
3/18/2018 PARALLEL PROGRAMMGIN WITH MPI 12

Parallel Programming Models▪ This model demonstrates the following characteristics: ▪ A set of tasks that use their own
local memory during computation. Multiple tasks can reside on the same physical machine and/or across an arbitrary number of machines.
▪ Tasks exchange data through communications by sending and receiving messages.
▪ Data transfer usually requires cooperative operations to be performed by each process. For example, a send operation must have a matching receive operation.
13PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Message Passing Interface (MPI)▪ MPI is a specification for message passing library that is standardized by MPI Forum
▪ Multiple vendor-specific implementations: MPICH, OpenMPI, Intel MPI
▪ MPI implementations are used for programming systems with distributed memory▪ Each process has a different address space
▪ Processes need to communicate with each other
▪ Can also be used for shared memory and hybrid architectures
▪ MPI specifications have been defined for C, C++ and Fortran programs
▪ Goal of MPI is to establish portable, efficient and flexible standard for writing message passing programs
14PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Message Passing Interface (MPI)▪ Reasons for using MPI
▪ Standardization
▪ Portability
▪ Functionality
▪ Availability
▪ Multiple vendor-specific implementations: MPICH, OpenMPI, Intel MPI
15PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Applications (Science and Engineering) ▪ MPI is widely used in large scale parallel applications in science and engineering ▪ Atmosphere, Earth, Environment
▪ Physics - applied, nuclear, particle, condensed matter, high pressure,
▪ fusion, photonics
▪ Bioscience, Biotechnology, Genetics
▪ Chemistry, Molecular Sciences
▪ Geology, Seismology
▪ Mechanical Engineering - from prosthetics to spacecraft
▪ Electrical Engineering, Circuit Design, Microelectronics
▪ Computer Science, Mathematics
16PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Important considerations while using MPI ▪ All parallelism is explicit: the programmer is responsible for correctly identifying parallelism and implementing parallel algorithms using MPI constructs
17PARALLEL PROGRAMMGIN WITH MPI3/18/2018

MPI Application Structure
18PARALLEL PROGRAMMGIN WITH MPI3/18/2018

MPI Basics▪ mpirun starts the required number of processes.
▪ All processes which have been started by mpirun are organized in a process group (Communicator) called MPI_COMM_WORLD
▪ Every process has unique identifier(rank) which is between 0 and n-1.
19PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Compiling and Running MPI applications▪MPI is a library▪ Applications can be written in C, C++ or Fortran and appropriate calls to MPI
can be added where required
▪Compilation:▪ Regular applications:
▪ gcc test.c -o test
▪ MPI applications▪ mpicc test.c -o test
▪Execution:▪ Regular applications:
▪ ./test
▪ MPI applications (running with 16 processes):▪ mpiexec –n 16 ./test
20PARALLEL PROGRAMMGIN WITH MPI3/18/2018

MPI Basics▪ MPI_Init (&argc,&argv) : Initializes the MPI execution environment.
▪ MPI_Comm_size (comm,&size) : Returns the total number of MPI processes in the specified communicator
▪ MPI_Comm_rank (comm,&rank) : Returns the rank of the calling MPI process within the specified communicator
▪ MPI_Finalize () : Terminates the MPI execution environment
22PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Simple MPI Program Identifying Processes
23PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Data Communication ▪Data communication in MPI is like email exchange
▪One process sends a copy of the data to another process (or a group of processes), and the other process receives it
▪Communication requires the following information: ▪ Sender has to know:
▪ Whom to send the data to (receiver’s process rank)
▪ What kind of data to send (100 integers or 200 characters, etc)
▪ A user-defined “tag” for the message (think of it as an email subject; allows the receiver to understand what type of data is being received)
▪ Receiver “might” have to know: ▪ Who is sending the data (OK if the receiver does not know; in this case
▪ sender rank will be MPI_ANY_SOURCE, meaning anyone can send)
▪ What kind of data is being received (partial information is OK: I might
▪ receive up to 1000 integers)
▪ What the user-defined “tag” of the message is (OK if the receiver does
▪ not know; in this case tag will be MPI_ANY_TAG)
24PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Ranks for communication▪ When sending data, the sender has to specify the destination process’ rank
▪ Tells where the message should go▪ The receiver has to specify the source process’ rank
▪ Tells where the message will come from▪ MPI_ANY_SOURCE is a special “wild-card” source that can be
▪ Used by the receiver to match any source
25PARALLEL PROGRAMMGIN WITH MPI3/18/2018
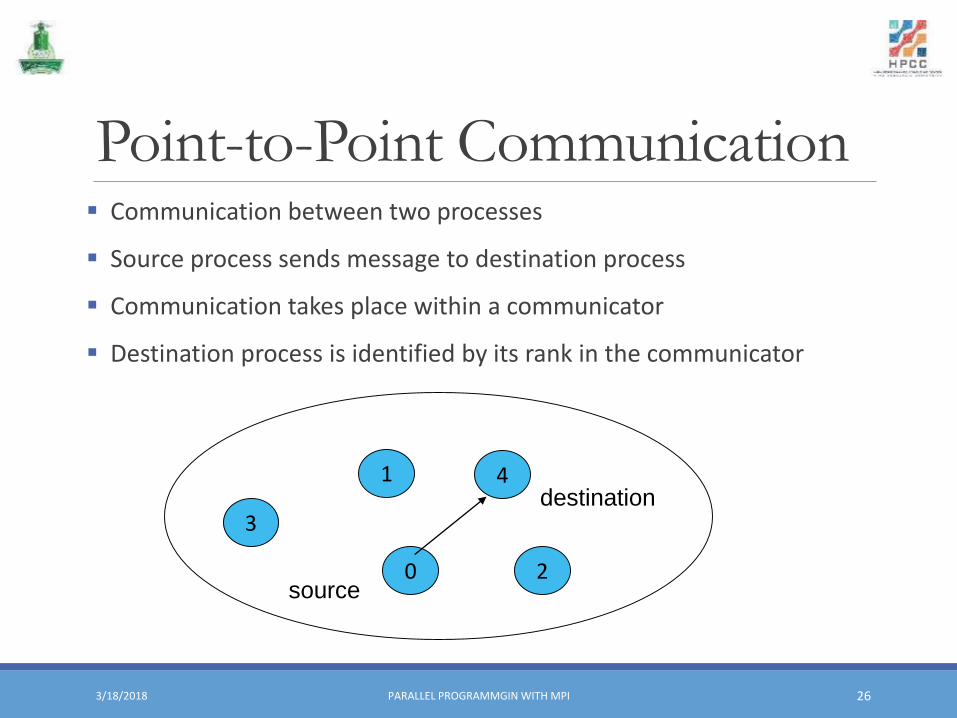
Point-to-Point Communication▪ Communication between two processes
▪ Source process sends message to destination process
▪ Communication takes place within a communicator
▪ Destination process is identified by its rank in the communicator
3/18/2018 PARALLEL PROGRAMMGIN WITH MPI 26
3
1 4
0 2
destination
source

Definitions▪ “Completion” means that memory locations used in the message transfer can be safely accessed▪ send: variable sent can be reused after completion
▪ receive: variable received can now be used
▪ MPI communication modes differ in what conditions on the receiving end are needed for completion
▪ Communication modes can be blocking or non-blocking▪ Blocking: return from function call implies completion
▪ Non-blocking: routine returns immediately
27PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Simple Communication in MPI
28PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Sending data
MPI_Send(&S_buf, count, MPI_Datatype , dest, tag,MPI_COMM_WORLD)
Data to send
Number of Elements to send Data Type of Element Process rank where data
need to be sent
User defined Unique message identifier
Process group for all Process started by mpirun
29PARALLEL PROGRAMMGIN WITH MPI3/18/2018

MPI_Send(&S_buf, count, MPI_Datatype , source, tag,MPI_COMM_WORLD, &status)
Data to send
Number of Elements to send Data Type of Element Process rank from where
data is sent
User defined Unique message identifier
Process group for all Process started by mpirun
Receiving data
Status Information
30PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Array decomposition and addition▪The master task first initializes an array and then distributes an equal portion that array to the other tasks.
▪Other tasks perform an addition operation to each array element
▪As each of the non-master tasks finish, they send their updated portion of the array to the master.
▪Finally, the master task displays selected parts of the final array and the global sum of all array elements
31PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Array Decomposition and Addition
1 2 3 4 5 6 7 8
1 2
2+1 3
3 4
3+4 7
7 8
7+8 15
5 6
5+6 11
Process 0 Process 3Process 2Process 1
Process 0
3 7 11 15
3+7+11+15= 36
Process 0
32PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Array Decomposition and Addition
33PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Serial Vs Parallel
0
0.01
0.02
0.03
0.04
0.05
0.06
Serial Parallel
Execution Time
Execution Time
34PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Communication Modes
35PARALLEL PROGRAMMGIN WITH MPI3/18/2018

BufferingIn a perfect world, every send operation would be perfectly synchronized with its matching receive.
MPI implementation must be able to deal with storing data when the two tasks are out of sync.
A send operation occurs 5 seconds before the receive is ready - where is the message while the receive is pending?
Multiple sends arrive at the same receiving task which can only accept one send at a time - what happens to the messages that are "backing up"?
36PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Buffering
37PARALLEL PROGRAMMGIN WITH MPI3/18/2018

System buffer space ▪ Opaque to the programmer and managed entirely by the MPI library
▪ A finite resource that can be easy to exhaust
▪ Able to exist on the sending side, the receiving side, or both.
▪ Something that may improve program performance because it allows send - receive operations to be asynchronous.
▪ MPI also provides for a user managed send buffer.
38PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Blocking and Non-blocking▪ Send and receive can be blocking or non-blocking
▪ A blocking send can be used with a non-blocking receive, and vice-versa
▪ Non-blocking sends can use any mode – synchronous, buffered, standard, or ready.
▪ Non-blocking send and receive routines return almost immediately.
▪ Non-blocking operations simply "request" the MPI library to perform the operation when it is able.
▪ It is unsafe to modify the application buffer (your variable space) until you know for a fact the requested non-blocking operation was actually performed by the library. There are "wait" routines used to do this.
39PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Non-blocking▪ Non-blocking communications are primarily used to overlap computation with communication and exploit possible performance gains.
▪ Characteristics of non-blocking communications▪No possibility of deadlocks
▪Decrease in synchronization overhead
▪Extra computation and code to test and wait for completion
▪Must not access buffer before completion
40PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Avoiding Race conditions▪ Following code is not safe
▪ int i=123;
▪ MPI_Request myRequest;
▪ MPI_Isend(&i, 1, MPI_INT, 1, MY_LITTLE_TAG, MPI_COMM_WORLD, &myRequest);
▪ i=234;
▪ Backend MPI routines will read the value of i after we changed it to 234, so 234 will be sent instead of 123.
▪ This is a race condition, which can be very difficult to debug.
41PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Avoiding Race conditions▪ int i=123;
▪ MPI_Request myRequest;
▪ MPI_Isend(&i, 1, MPI_INT, 1, MY_LITTLE_TAG, MPI_COMM_WORLD, &myRequest);
▪ // do some calculations here
▪ // Before we re-use variable i, we need to wait until the asynchronous function call is complete
▪ MPI_Status myStatus;
▪ MPI_Wait(&myRequest, &myStatus);
▪ i=234;
42PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Non-blocking Communication Functions
43PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Non-blocking Communication▪ Simple hello world program that uses nonblocking send/receive routines.
▪ Request: non-blocking operations may return before the requested system buffer space is obtained, the system issues a unique "request number".
44PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Blocking▪ A blocking send routine will only "return" after it is safe to modify the application buffer (your send data) for reuse.
▪ The message might be copied directly into the matching receive buffer, or it might be copied into a temporary system buffer.
▪ A blocking send can be synchronous which means there is handshaking occurring with the receive task to confirm a safe send.
▪ A blocking send can be asynchronous if a system buffer is used to hold the data for eventual delivery to the receive.
▪ A blocking receive only "returns" after the data has arrived and is ready for use by the program.
45PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Standard and Synchronous Send▪ Standard send▪Completes once message has been sent▪May or may not imply that message arrived▪Don’t make any assumptions (implementation
dependent)
▪ Buffered send▪Data to be sent is copied to a user-specified buffer▪Higher system overhead of copying data to and from
buffer▪ Lower synchronization overhead for sender
46PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Ready and Buffered Send▪ Ready send▪ Ready to receive notification must be posted; otherwise it exits with an
error
▪ Should not be used unless user is certain that corresponding receive is posted before the send
▪ Lower synchronization overhead for sender as compared to synchronous send
▪ Synchronous send▪ Use if need to know that message has been received
▪ Sending and receiving process synchronize regardless of who is faster. Thus, processor idle time is possible
▪ Large synchronization overhead
▪ Safest communication method
47PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Blocking Communication Functions
48PARALLEL PROGRAMMGIN WITH MPI3/18/2018

MPI_Bsend▪ This is a simple program that tests MPI_bsend.
49PARALLEL PROGRAMMGIN WITH MPI3/18/2018
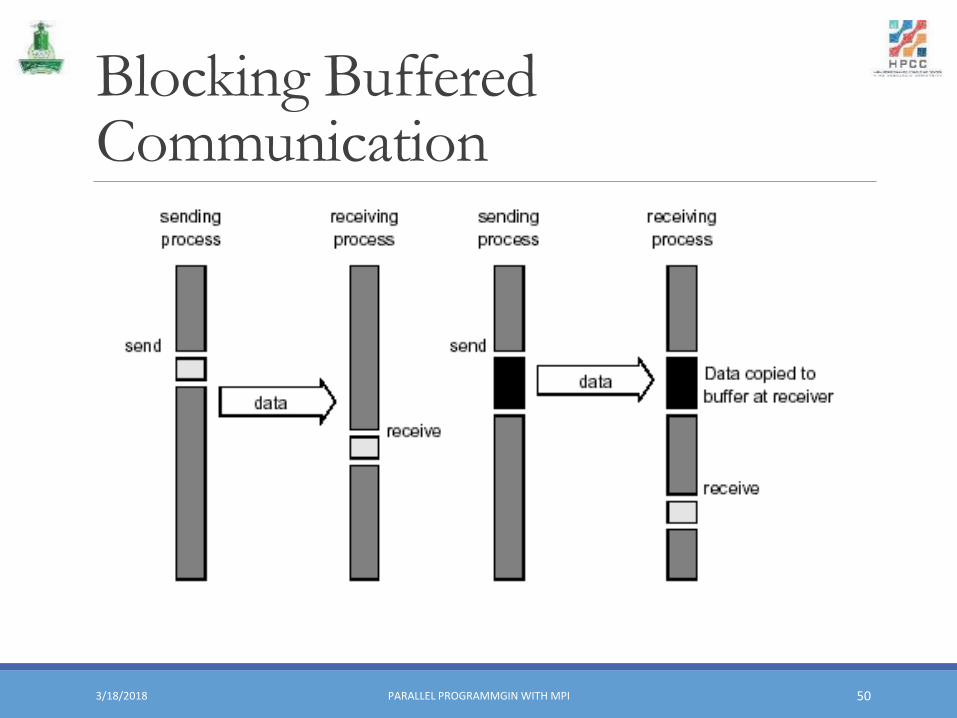
Blocking Buffered Communication
50PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Non-blocking Non-buffered Communication
51PARALLEL PROGRAMMGIN WITH MPI3/18/2018

For a Communication to Succeed▪ Sender must specify a valid destination rank
▪ Receiver must specify a valid source rank
▪ The communicator must be the same
▪ Tags must match
▪ Receiver’s buffer must be large enough
▪ User-specified buffer should be large enough (buffered send only)
▪ Receive posted before send (ready send only)
52PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Completion Tests▪ Waiting and Testing for completion▪ Wait: function does not return until completion finished
▪ Test: function returns a TRUE or FALSE value depending on whether or not the communication has completed
▪ int MPI_Wait(MPI_Request *request, MPI_Status *status)
▪ int MPI_Test(MPI_Request *request, int *flag, MPI_Status*status)
53PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Testing Multiple Communications▪ Test or wait for completion of one (and only one) message
▪ MPI_Waitany & MPI_Testany
▪ Test or wait for completion of all messages▪ MPI_Waitall & MPI_Testall
▪ Test or wait for completion of as many messages as possible
▪ MPI_Waitsome & MPI_Testsome
54PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Wildcarding▪ Receiver can wildcard
▪ To receive from any source specify MPI_ANY_SOURCE as rank of source
▪ To receive with any tag specify MPI_ANY_TAG as tag
▪ Actual source and tag are returned in the receiver’s statusparameter
55PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Receive Information▪ Information of data is returned from MPI_Recv (or MPI_Irecv) as status
▪ Information includes:▪ Source: status.MPI_SOURCE
▪ Tag: status.MPI_TAG
▪ Error: status.MPI_ERROR
▪ Count: message received may not fill receive buffer. Use following function to find number of elements actually received:
▪ int MPI_Get_count(MPI_Status status, MPI_Datatype datatype, int *count)
▪ Message order preservation: messages do not overtake each other. Messages are received in the order sent.
56PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Timers▪ double MPI_Wtime(void)
▪ Time is measured in seconds
▪ Time to perform a task is measured by consulting the timer before and after
57PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Deadlocks▪ A deadlock occurs when two or more processors try to access the same set of resources
▪ Deadlocks are possible in blocking communication
▪ Example: Two processors initiate a blocking send to each other without posting a receive
58
…
…
MPI_Send(P1)
MPI_Recv(P1)
…
…
…
MPI_Send(P0)
MPI_Recv (P0)
…
Process 0 Process 1
PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Avoiding Deadlocks▪ Different ordering of send and receive: one processor post the send while the other posts the receive
▪ Use non-blocking functions: Post non-blocking receives early and test for completion
▪ Use buffered mode: Use buffered sends so that execution continues after copying to user-specified buffer
59PARALLEL PROGRAMMGIN WITH MPI3/18/2018
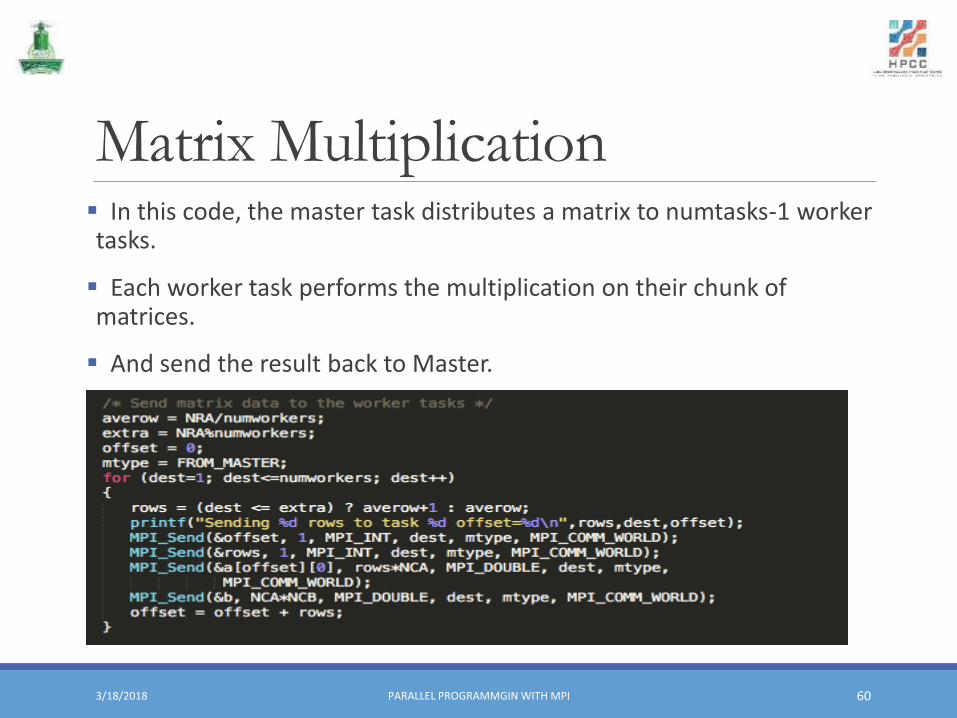
Matrix Multiplication ▪ In this code, the master task distributes a matrix to numtasks-1 worker tasks.
▪ Each worker task performs the multiplication on their chunk of matrices.
▪ And send the result back to Master.
60PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Matrix Multiplication
61PARALLEL PROGRAMMGIN WITH MPI3/18/2018

Serial vs. Parallel
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Serial Parallel
Execution Time
Execution Time
62PARALLEL PROGRAMMGIN WITH MPI3/18/2018

MPI Collective Communication
PARALLEL PROGRAMMGIN WITH MPI 633/18/2018

MPI Collective Communication▪ All processes in the group have to participate in the same operation.
▪ Process group is defined by the communicator.
▪ For each communicator, one can have one collective operation ongoing at a time.
▪ Eases programming
▪ Enables low-level optimizations and adaptations to the hardware infrastructure.
PARALLEL PROGRAMMGIN WITH MPI 643/18/2018

Characteristics of Collective Communication▪ Collective communication will not interfere with point-to-point communication
▪ All processes must call the collective function
▪ Substitute for a sequence of point-to-point function calls
▪ Synchronization not guaranteed (except for barrier)
▪No tags are needed
PARALLEL PROGRAMMGIN WITH MPI 653/18/2018

Types of Collective Communication▪ Synchronization
• barrier
▪ Data exchange
• broadcast
• gather, scatter, all-gather, and all-to-all exchange
• Variable-size-location versions of above
▪ Global reduction (collective operations)
• sum, minimum, maximum, etc
PARALLEL PROGRAMMGIN WITH MPI 663/18/2018

SynchronizationCOLLECTIVE COMMUNICATION
PARALLEL PROGRAMMGIN WITH MPI 673/18/2018

Barrier Synchronization
3/18/2018 PARALLEL PROGRAMMGIN WITH MPI 68

Barrier Synchronization▪ Red light for each processor: turns green when all processors have arrived
▪ A process calling it will be blocked until all processes in the group (communicator) have called it
MPI_ Barrier(MPI_Comm comm)
• comm: communicator whose processes need to be synchronized
PARALLEL PROGRAMMGIN WITH MPI 693/18/2018

Data exchangeCOLLECTIVE COMMUNICATION
PARALLEL PROGRAMMGIN WITH MPI 703/18/2018

MPI_Bcast▪ The process with the rank root distributes the data stored in buffer to all other processes in the communicator comm.
▪ Data in buffer is identical on all other processes after the broadcast.
PARALLEL PROGRAMMGIN WITH MPI 713/18/2018

Traditional Send and Receive
3/18/2018 PARALLEL PROGRAMMGIN WITH MPI 72
0
12
3
4
5
7
6
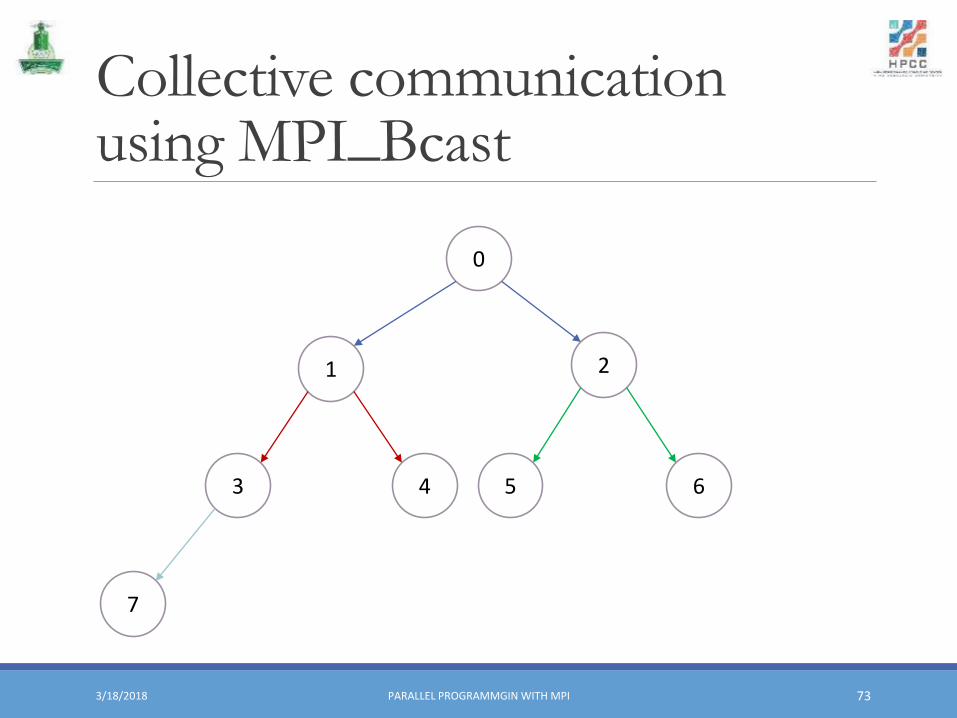
Collective communication using MPI_Bcast
3/18/2018 PARALLEL PROGRAMMGIN WITH MPI 73
0
21
3 4 5
7
6

Broadcast▪ One-to-all communication: same data sent from root process to all others in communicator
▪ All processes must call the function specifying the same root and communicator
MPI_Bcast (&buf, count, datatype, root, comm).
• buf: starting address of buffer (sending and receiving)
• count: number of elements to be sent/received
• datatype: MPI datatype of elements
• root: rank of sending process
• comm: MPI communicator of processors involved
PARALLEL PROGRAMMGIN WITH MPI 743/18/2018

MPI_Bcast
PARALLEL PROGRAMMGIN WITH MPI 75
5
Process 1 Process 2 Process 3 Process 4
5
Process 1
5
Process 2
5
Process 3
5
Process 4
After MPI_Bcast
Before MPI_Bcast
3/18/2018

MPI_Bcast▪ A simple example that synchronize before and after sending data, then calculated the time taken.
PARALLEL PROGRAMMGIN WITH MPI 763/18/2018

MPI_Scatter▪ The process with the rank root distribute data stored in sendbuf to all other processes in communicator comm.
▪ Every process gets different segments of the original data at the root process.
PARALLEL PROGRAMMGIN WITH MPI 773/18/2018

Scatter▪ Example: partitioning an array equally among the processes
MPI_Scatter(&sbuf, scount, stype,&rbuf, rcount, rtype, root, comm)
• sbuf and rbuf: starting address of send and receive buffers
• scount and rcount: number of elements sent and received to/from each process
• stype and rtype: MPI datatype of sent/received data
• root: rank of sending process
• comm: MPI communicator of processors involved
PARALLEL PROGRAMMGIN WITH MPI 783/18/2018
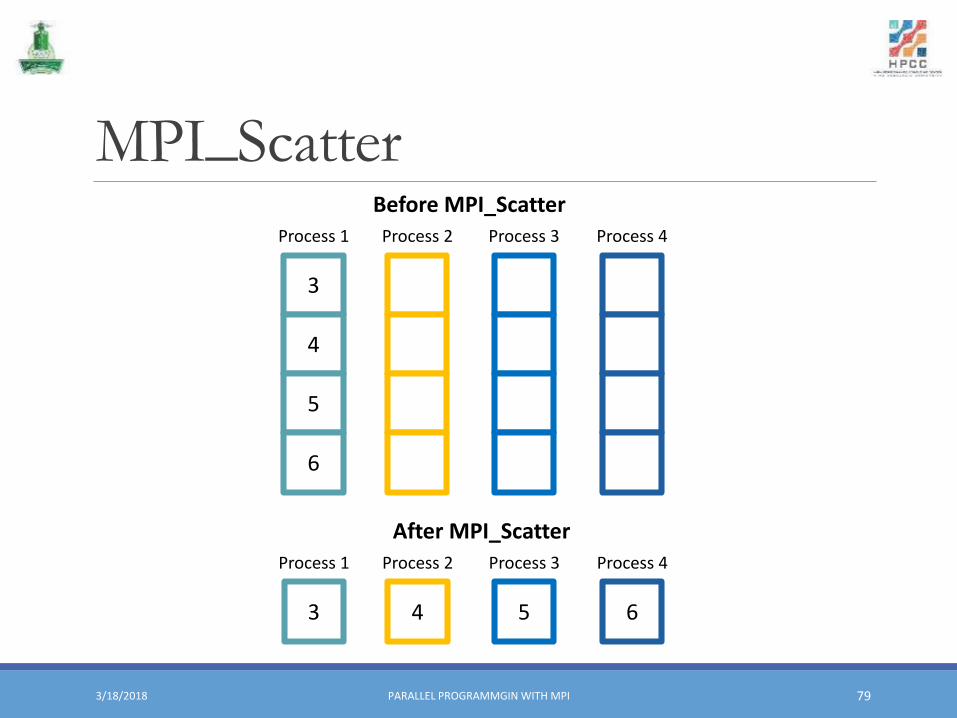
MPI_Scatter
PARALLEL PROGRAMMGIN WITH MPI 79
3
4
5
6
Process 1 Process 2 Process 3 Process 4
3
Process 1
4
Process 2
5
Process 3
6
Process 4
Before MPI_Scatter
After MPI_Scatter
3/18/2018

MPI_Scatter▪ A simple program that distribute a table to different processors that each one takes a row.
PARALLEL PROGRAMMGIN WITH MPI 803/18/2018

MPI_Gather▪ Reverse operation of MPI_Scatter.
▪ The root process receives the data stored in send buffer on all other process in the communicator comm into the receive buffer.
PARALLEL PROGRAMMGIN WITH MPI 813/18/2018

MPI_GatherMPI_Gather(&sbuf, scount, stype, &rbuf, rcount, rtype, root, comm)
• sbuf and rbuf: starting address of send and receive buffers
• scount and rcount: number of elements sent and received to/from each process
• stype and rtype: MPI datatype of sent/received data
• root: rank of sending process
• comm: MPI communicator of processors involved
PARALLEL PROGRAMMGIN WITH MPI 823/18/2018
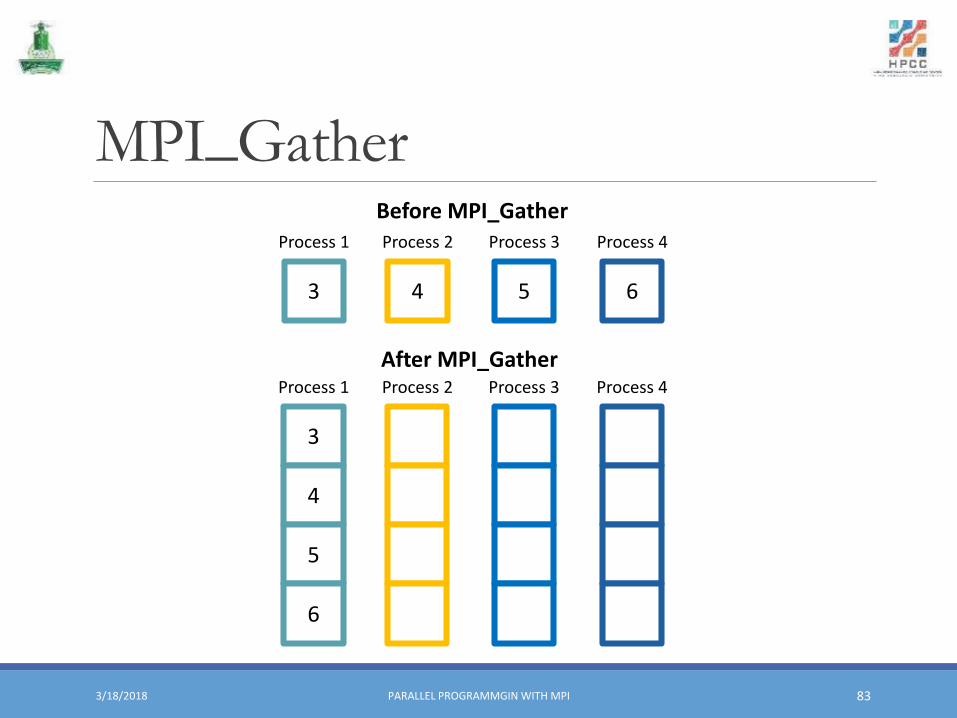
MPI_Gather
PARALLEL PROGRAMMGIN WITH MPI 83
3
4
5
6
Process 1 Process 2 Process 3 Process 4
After MPI_Gather
3
Process 1
4
Process 2
5
Process 3
6
Process 4
Before MPI_Gather
3/18/2018

MPI_Gather▪ A simple program the collect integer values from different processor. The master (Processor 0) is the one that will have all the values.
PARALLEL PROGRAMMGIN WITH MPI 843/18/2018

All-Gather and All-to-All (1)▪ All-gather
• All processes, rather than just the root, gather data from the group
▪ All-to-all
• mpi_alltoall is an extension of mpi_allgather to the case where each process sends distinct data to each of the receivers.
• All processes receive data from all processes in rank order
▪ No root process specified
PARALLEL PROGRAMMGIN WITH MPI 853/18/2018

MPI AllGather Example
PARALLEL PROGRAMMGIN WITH MPI 86
MPI_Allgather
3/18/2018

MPI Alltoall Example
PARALLEL PROGRAMMGIN WITH MPI 87
1 1 1
2 2 2
3 3 3
1 2 3
1 2 3
1 2 3
MPI_Alltoall
3/18/2018

All-Gather and All-to-All (2)
MPI_Allgather(&sbuf, scount, stype, &rbuf, rcount, rtype, comm)
MPI_Alltoall(&sbuf, scount, stype, &rbuf, rcount, rtype, comm)
• scount: number of elements sent to each process; for all-to-all communication, size of sbuf should be scount*p (p = # of processes)
• rcount: number of elements received from any process; size of rbuf should be rcount*p (p = # of processes)
PARALLEL PROGRAMMGIN WITH MPI 883/18/2018

MPI_Allgather▪ A program that computes the average of an array of elements in parallel using MPI_Scatter and MPI_Allgather
PARALLEL PROGRAMMGIN WITH MPI 893/18/2018

Variable-Size-Location Collective Functions
▪ Allows varying size and relative locations of messages in buffer
▪ Examples: MPI_Scatterv, MPI_Gatherv, MPI_Allgatherv, MPI_Alltoallv
▪ Advantages:• More flexibility in writing code
• More compact code
▪ Disadvantage:• may be less efficient than fixed size/location functions
PARALLEL PROGRAMMGIN WITH MPI 903/18/2018

Scatterv and GathervMPI_Scatterv(&sbuf, &scount, &displs, stype, &rbuf, rcount, rtype, root, comm)
MPI_Gatherv(&sbuf, scount, stype, &rbuf, &rcount, &displs, rtype, root, comm)
▪&scount and &rcount: integer array containing number of elements sent/received to/from each process
▪&displs: integer array specifying the displacements relative to start of buffer at which to send/place data to corresponding process
PARALLEL PROGRAMMGIN WITH MPI 913/18/2018

MPI_Gatherv
PARALLEL PROGRAMMGIN WITH MPI 92
P 0
P4
P3
P2
P1
8421
Count
7310
displs
3/18/2018
0137
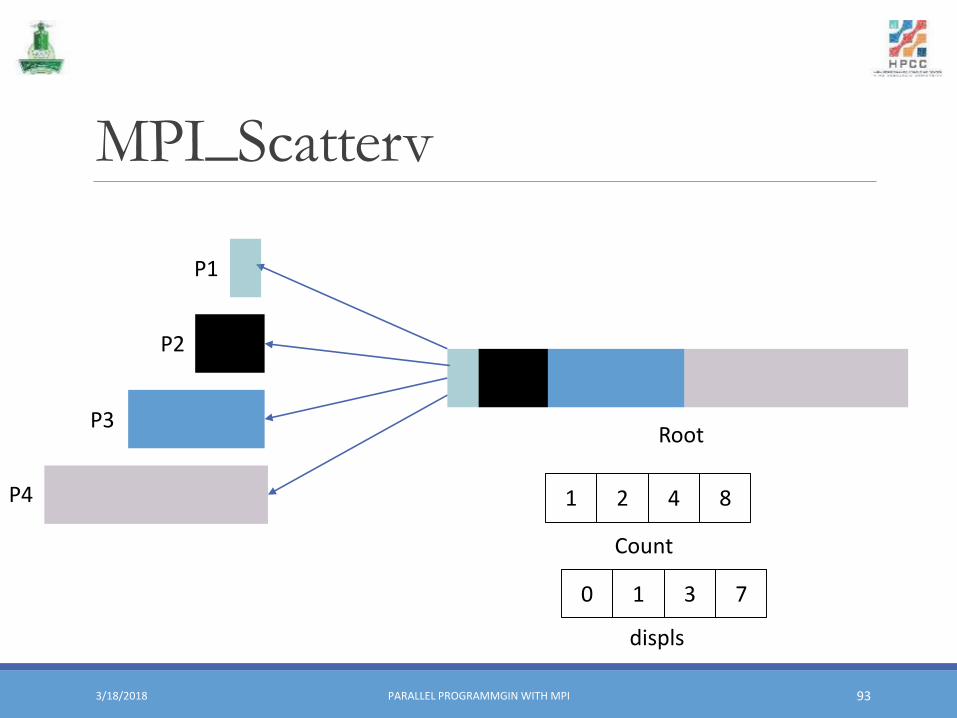
MPI_Scatterv
PARALLEL PROGRAMMGIN WITH MPI 93
Root
P4
P3
P2
P1
8421
Count
7310
displs
3/18/2018

MPI_Scatterv▪ A program the distribute data to several processors. However, the data have variant size.
PARALLEL PROGRAMMGIN WITH MPI 943/18/2018

Global reductionCOLLECTIVE COMMUNICATION
PARALLEL PROGRAMMGIN WITH MPI 953/18/2018

Global Reduction Operations (1)▪ Used to compute a result involving data distributed over a group of processes
▪ Result placed in specified process or all processes
▪ Examples
• Global sum or product
• Global maximum or minimum
PARALLEL PROGRAMMGIN WITH MPI 963/18/2018

Global Reduction Operations (2)▪ MPI_Reduce returns results to a single process (root)
▪ MPI_Allreduce returns results to all processes in the group
▪ MPI_Reduce_scatter scatters a vector, which results from a reduce operation, across all processes
PARALLEL PROGRAMMGIN WITH MPI 973/18/2018

Global Reduction Operations (3)
MPI_Reduce(&sbuf, &rbuf, count, stype, op, root, comm)
MPI_Allreduce(&sbuf, &rbuf, count, stype, op, comm)
MPI_Reduce_scatter(&sbuf, &rbuf, &rcounts, stype, op, comm)
• sbuf: address of send buffer
• rbuf: address of receive buffer
• rcounts: integer array that has counts of elements received from each process
• op: reduce operation, which may be MPI predefined or user-defined (by using MPI_Op_create)
PARALLEL PROGRAMMGIN WITH MPI 983/18/2018

Predefined Reduction Operations
PARALLEL PROGRAMMGIN WITH MPI 99
MPI name Function
MPI_MAX Maximum
MPI_MIN Minimum
MPI_SUM Sum
MPI_PROD Product
MPI_LAND Logical AND
MPI_BAND Bitwise AND
MPI_LOR Logical OR
MPI_BOR Bitwise OR
MPI_LXOR Logical exclusive OR
MPI_BXOR Bitwise exclusive OR
MPI_MAXLOC Maximum and location
MPI_MINLOC Minimum and location
3/18/2018
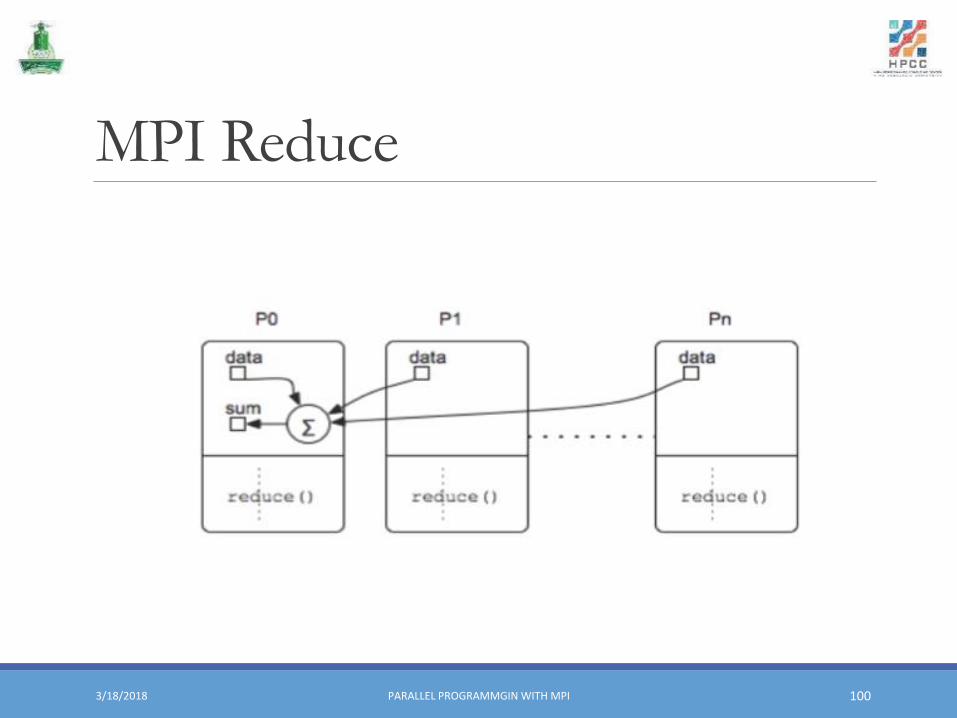
MPI Reduce
PARALLEL PROGRAMMGIN WITH MPI 1003/18/2018

MPI Reduce Example
PARALLEL PROGRAMMGIN WITH MPI 1013/18/2018

MPI_Op
PARALLEL PROGRAMMGIN WITH MPI 1023/18/2018

MPI_Reduce▪ Program that computes the average of an array of elements in parallel using MPI_Reduce.
PARALLEL PROGRAMMGIN WITH MPI 1033/18/2018
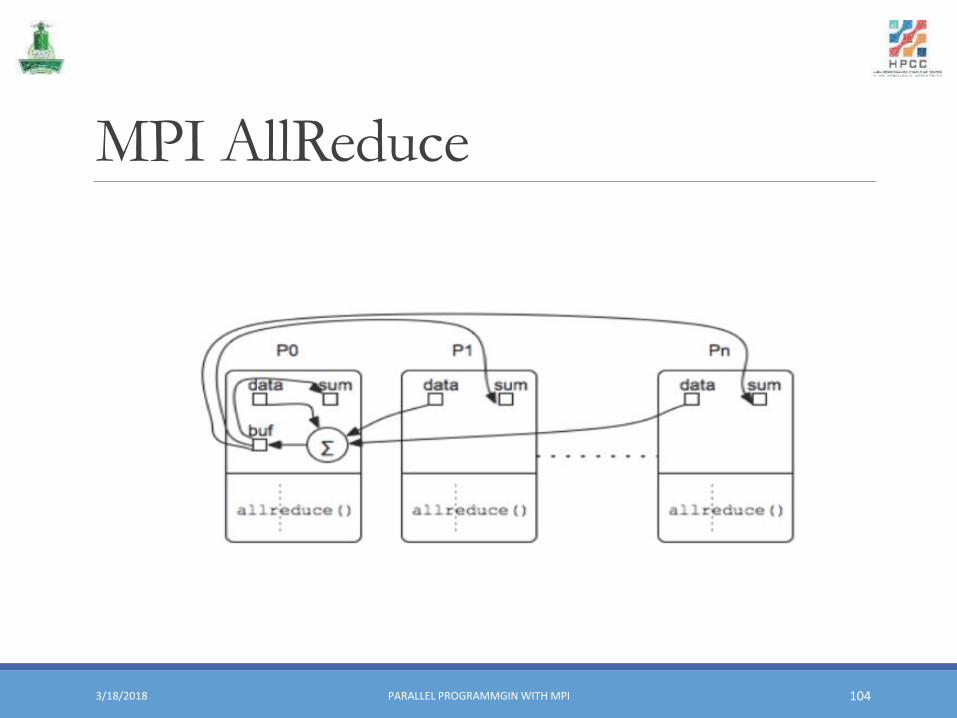
MPI AllReduce
PARALLEL PROGRAMMGIN WITH MPI 1043/18/2018

MPI AllReduce Example
PARALLEL PROGRAMMGIN WITH MPI 1053/18/2018

MPI_AllReduce▪ Program that computes the standard deviation of an array of elements in parallel using MPI_AllReduce.
PARALLEL PROGRAMMGIN WITH MPI 1063/18/2018

MPI Reduce_scatter
PARALLEL PROGRAMMGIN WITH MPI 1073/18/2018

MPI_Reduce_scatter▪ A program that calculate a summation of a vector, then distribute the local results to each processors using MPI_Reduce_scatter.
PARALLEL PROGRAMMGIN WITH MPI 1083/18/2018
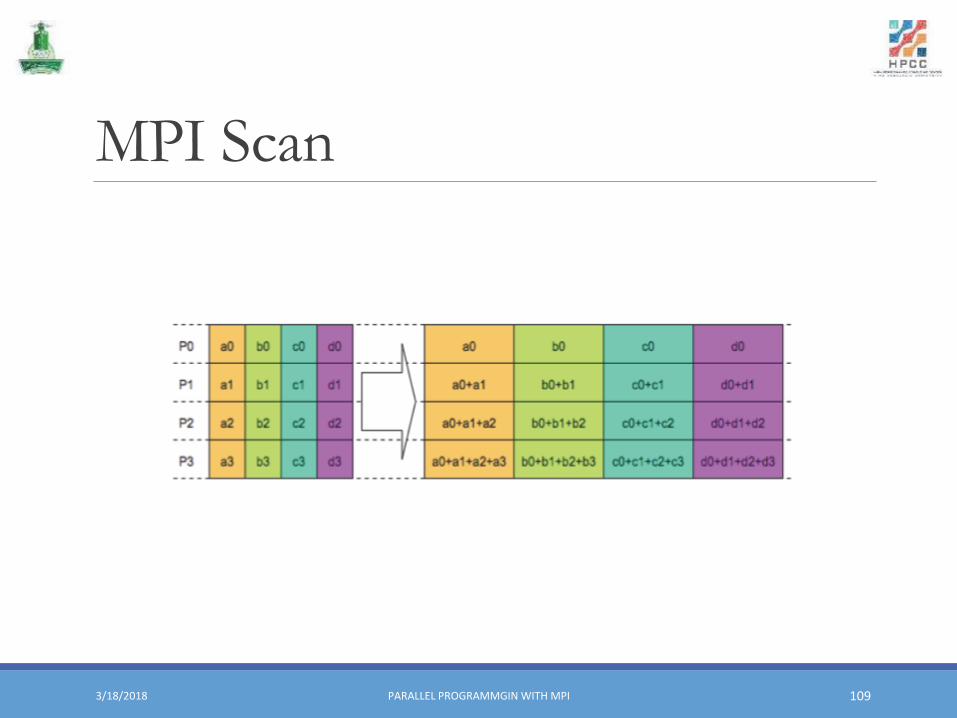
MPI Scan
PARALLEL PROGRAMMGIN WITH MPI 1093/18/2018

MPI_Scan▪ We have a histogram distributed across nodes in exp_pdf_i, and then calculate the cumulative frequency histogram (exp_cdf_i) across all nodes.
PARALLEL PROGRAMMGIN WITH MPI 1103/18/2018

Minloc and Maxloc▪ Designed to compute a global minimum/maximum and an index associated with the extreme value
• index is processor rank that held the extreme value
▪ If more than one extreme exists, index returned is for the first
▪ Designed to work on operands that consist of a value and index pair. MPI defines such special data types:
• MPI_FLOAT_INT, MPI_DOUBLE_INT, MPI_LONG_INT, MPI_2INT, MPI_SHORT_INT, MPI_LONG_DOUBLE_INT
PARALLEL PROGRAMMGIN WITH MPI 1113/18/2018

MPI_Minloc▪ A program that locate a minimum value and its location form an arrays of integer.
PARALLEL PROGRAMMGIN WITH MPI 1123/18/2018

MPI Groups and Communicators
PARALLEL PROGRAMMGIN WITH MPI 1133/18/2018

MPI Groups and Communicators▪A group is an ordered set of processes• Each process in a group is associated with a unique integer rank between 0
and P-1, with P the number of processes in the group
▪A communicator encompasses a group of processes that may communicate with each other• Communicators can be created for specific groups
• Processes may be in more than one group/communicator
▪Groups/communicators are dynamic and can be setup and removed at any time
▪From the programmer’s perspective, a group and a communicator are the same
PARALLEL PROGRAMMGIN WITH MPI 1143/18/2018
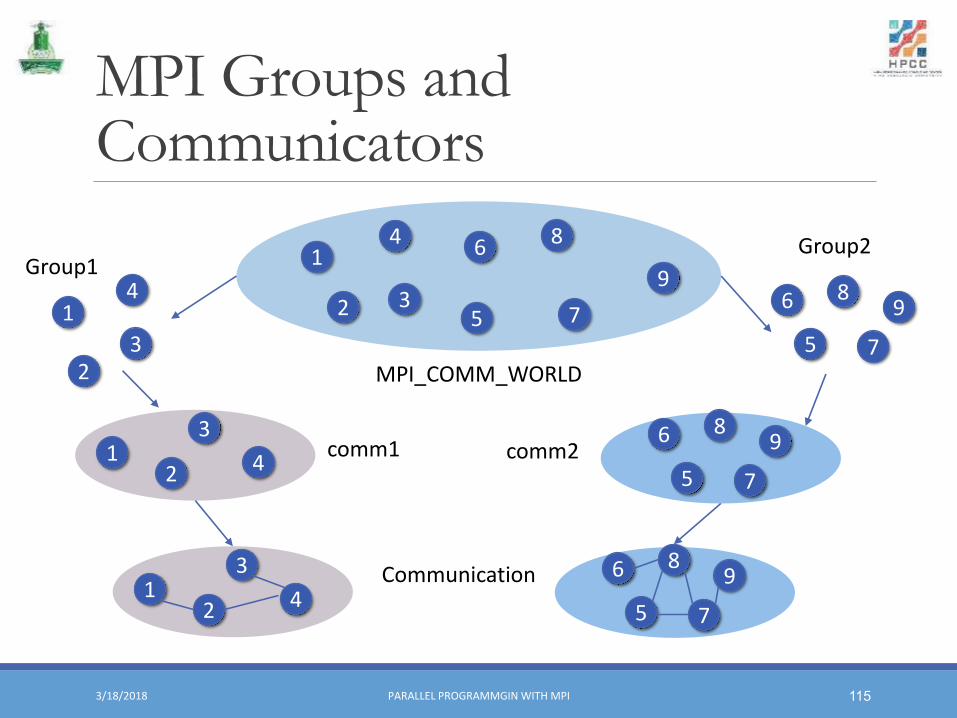
MPI Groups and Communicators
PARALLEL PROGRAMMGIN WITH MPI 115
1
2 3
4
5
6
7
8
9
5
6
7
891
23
4
12
3
4
12
3
4
5
6
7
89
5
6
7
89
Group1Group2
MPI_COMM_WORLD
comm1 comm2
Communication
3/18/2018

MPI Group Operations▪MPI_Comm_group• Returns the group associated with a communicator
▪MPI_Group_union• Creates a group by combining two groups
▪MPI_Group_intersection• Creates a group from the intersection of two groups
▪MPI_Group_difference• Creates a group from the difference between two groups
▪MPI_Group_incl• Creates a group from listed members of an existing group
▪MOI_Group_excl• Creates a group excluding listed members of an existing group
▪MPI_Group_free• Marks a group for deallocation
PARALLEL PROGRAMMGIN WITH MPI3/18/2018 116

MPI Group Operations
PARALLEL PROGRAMMGIN WITH MPI
0 2
1 3
2 4
3 5
0 2
1 3
2 4
3 5
0 2
1 3
4
5
2
3
Union
Intersection
3/18/2018 117

MPI Communicator Operations
▪MPI_Comm_size• Returns number of processes in communicator’s group
▪MPI_Comm_rank• Returns rank of calling process in communicator’s group
▪MPI_Comm_compare• Compares two communicators
▪MPI_Comm_dup• Duplicates a communicator
▪MPI_Comm_create• Creates a new communicator for a group
▪MPI_Comm_split• Splits a communicator into multiple, non-overlapping communicators
▪MPI_Comm_free• Marks a communicator for deallocation
PARALLEL PROGRAMMGIN WITH MPI3/18/2018 118

MPI_Comm_Split
PARALLEL PROGRAMMGIN WITH MPI
0 1
4 5
8 9
2 3
6 7
14 151312
1110
0 1 2 3
0 1 2 3
0 1 2 3
0 1 2 3
3/18/2018 119

MPI_Comm_split▪ Example using MPI_Comm_split to divide a communicator into subcommunicators
PARALLEL PROGRAMMGIN WITH MPI3/18/2018 120

MPI_Group▪ Example using MPI_Comm_group to divide a communicator into subcommunicators
PARALLEL PROGRAMMGIN WITH MPI3/18/2018 121

Thanks
PARALLEL PROGRAMMGIN WITH MPI 1223/18/2018

Contact
3/18/2018 PARALLEL PROGRAMMGIN WITH MPI 123
Prof. Rashid MehmoodDirector of Research, Training, and Consultancy
HPC Center, King Abdul Aziz University, Jeddah, Saudi Arabia,


















