
Parallel I/O and Portable Data Formats - PRACE
33
May 21, 2014 Mitglied der Helmholtz-Gemeinschaft Parallel I/O and Portable Data Formats | Wolfgang Frings, Michael Stephan, Florian Janetzko
Transcript of Parallel I/O and Portable Data Formats - PRACE

May 21, 2014
Mitg
lied
de
r H
elm
ho
ltz-G
em
ein
sch
aft
Parallel I/O and Portable
Data Formats
| Wolfgang Frings, Michael Stephan, Florian Janetzko

May 21, 2014 Slide 2
Outline
Introduction
Introduction to different I/O strategies
MPI I/O
HDF5
PnetCDF
SIONlib
Summary and conclusions
Wed 21st
Wed 21st
Thu 22nd
Thu 22nd
Fri 23rd
Fri 23rd

May 21, 2014
Mitg
lied
de
r H
elm
ho
ltz-G
em
ein
sch
aft
Parallel I/O and Portable
Data Formats
| Florian Janetzko
Introduction

May 21, 2014 Slide 4
Fast growth of parallelism of HPC systems
• Multi-core CPUs
• GPUs
Why to think about I/O in HPC?
► Distribution of data
► Parallel data access for high performance
► Data interface managability of data
Growth of problem sizes
Efficient usage of resources:
PERFORMANCE

May 21, 2014 Slide 5
JUROPA – Hardware Overview
Nodes
2 Intel Nehalem quad-core processors,
2.93 GHz
24 GB/node (52 TB total main memory)
SuSE Linux (SLES 11)
7 login nodes
6 GPFS login nodes
Fat tree IB QDR HCA
2,208 compute nodes = 17,664 cores
208 Teraflop/s peak performance
File system
Lustre (900 TB work, 400 TB home)
GPFS gateway (GPFSWORK, ARCH)
Interconnection
Memory
Core Core
Core Core
CPU
CNs (schematically)
Memory
Core Core
Core Core
CPU

May 21, 2014 Slide 6
JUQUEEN
Nodes
– IBM PowerPC A2 1.6 GHz,
16 cores/node, 4-way SMT,
64-bit
– 4-wide (dbl) SIMD (FMA)
– 16 GB RAM per node
– Torus network
– 28 racks, 458,752 cores
– 5.9 Petaflop/s peak performance
File System
– Connected to a Global Parallel File System (GPFS) with
14 PByte online disk and 60 PByte offline tape capacity
Interconnection(s)
Memory
CPU
CN (schematically)
C C C C C C C C
C C C C C C C C
C

May 21, 2014 Slide 7
JUDGE
Nodes
2 Intel Westmere 6-core processors,
2.66 GHz, SMT
12 GB/node (19.8 TB total main memory)
GPUs (1.15 GHz):
54 nodes: 2 NVIDIA Tesla M2050
152 nodes: 2 NVIDIA Tesla M2070
SuSE Linux (SLES 11)
1 login node
206 nodes = 2,472 cores, 412 GPUs
239 Teraflop/s peak performance
File system
GPFS gateway (GPFSWORK, ARCH, HOME)
Interconnection
Memory
CN (schematically)
Memory
CPU
Core
Core
Core
Core
Core
Core
CPU
Core
Core
Core
Core
Core
Core
GPU GPU

May 21, 2014 Slide 8
Exclusive access to file system blocks
Bandwidth parallel file systems, multiple disks
I/O Basics – Data Storage – File Systems
…
Area for meta data (number of blocks, modification date, etc.)
Meta data for file
Free file system block
File data

May 21, 2014 Slide 9
File Systems on HPC-Systems@JSC
Available file systems in general:
$HOME
for source code, binaries, libraries and applications
Backup
$WORK
temporary storage location for applications with large size
and I/O demands
No Backup – automatic deletion of old files
$ARCH
storage for all files not currently in use
Available for project’s life time

May 21, 2014 Slide 10
JUROPA – File Systems
$HOME
Lustre file system, backup
3 TB / 2 mio files group limits
Available from FEN and CN
$WORK
Lustre file system
3 TB / 2 mio files group limits
No Backup – files older than 28 days are automatically deleted
Available from FEN and CN
$GPFSHOME, $GPFSWORK, $GPFSARCH
GPFS file system (see $HOME, $WORK, $ARCH of JUQUEEN)
Only available from juropagpfs nodes ([email protected])

May 21, 2014 Slide 11
Lustre File System
Lustre (Combination of the words Linux and Cluster)
Distributed file system
GPL
Version 1.0 in 2003, latest version 2.3 (Oct 2012)
Major functional units
Metadata server (MDS)
Object Storage Servers (OSS)
Object Target Servers (OST)

May 21, 2014 Slide 12
Juropa – Configuration

May 21, 2014 Slide 13
JUROPA $WORK OSS/OST Distribution O
SS
jf9
2o05
OST
OST
OST
OST
OST
OST
OST
Example: $WORK scratch file system on Juropa/HPC-FF (2012)
OST
OST
OST
OST
OST
OST
OST
OST
OST OS
S jf9
2o06
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST OS
S jf9
2o07
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OS
S jf9
2o08
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST: 7 TB disk space
stripe_size
block size used
for I/O operations
(default 1MB)
stripe_count
Number of OSTs
(default 1 $HOME
4 $WORK)
stripe_offset
OST to start
(default: -1 (random)) OS
S jf9
2o13
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST OS
S jf9
2o14
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST OS
S jf9
2o15
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OS
S jf9
2o16
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST
OST

May 21, 2014 Slide 14
Modification of Lustre Parameters
Getting information about Lustre settings
Settings can be changed on the file or directory level
inherited by all files created inside the directory
Do not change the parameters for the Luster file system unless
you know what you are doing
Do not change the parameters for the Luster file system unless
you know what you are doing
lfs getstripe <directory or file>
lfs setstripe [options] <directory>
options: --size stripe_size
--count stripe_count
--offset start_ost

May 21, 2014 Slide 15
Blue Gene/Q Packaging Hierarchy
I/O-
Nodes
© IBM 2012
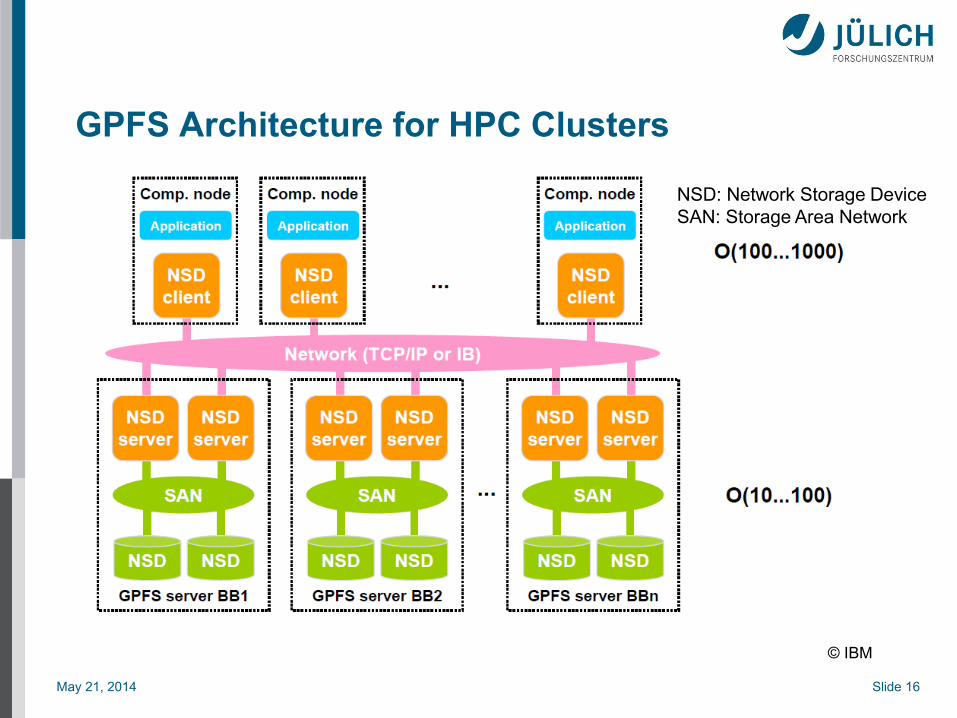
May 21, 2014 Slide 16
GPFS Architecture for HPC Clusters
NSD: Network Storage Device
SAN: Storage Area Network
© IBM

May 21, 2014 Slide 17
GPFS Architecture for Blue Gene/Q
© IBM 2012

May 21, 2014 Slide 18
Blue Gene/Q: I/O-Node Cabling (8 ION/Rack)
© IBM 2012

May 21, 2014 Slide 19
I/O-Node Cabling (8 ION/Rack) – ID-J00 Clients
© IBM 2012

May 21, 2014 Slide 20
I/O-Node Cabling (8 ION/Rack) – ID-J02 Clients
© IBM 2012

May 21, 2014 Slide 21
JUQUEEN – File Systems
$HOME
GPFS (IBM General Parallel File System) backup
6 TB / 2 mio files group limits
Available from FEN and CN
$WORK
GPFS, Block size 4 MB (no changes possible ↔ Lustre)
20 TB / 4M files group limits
No Backup – files older than 90 days and empty directories older than 3 days
are automatically deleted
Available from FEN and CN
$ARCH
GPFS
2 mio files (USE TAR ARCHIVES!!!)
Only available from FEN

May 21, 2014 Slide 22
Common I/O strategies
1. One process performs I/O
2. All or several processes write to one file
3. Each process writes to its own file (task-local files)

May 21, 2014 Slide 23
1. One process performs I/O
+ Simple to implement
‒ I/O bandwidth is limited to the rate of this single
process
‒ Additional communication might be necessary
‒ Other processes may idle and waste computing
resources during I/O time

May 21, 2014 Slide 24
Pitfall 1 – Frequent flushing on small blocks
Modern file systems in HPC have large file system
blocks
A flush on a file handle forces the file system to
perform all pending write operations
If application writes in small data blocks the same file
system block it has to be read and written multiple
times
Performance degradation due to the inability to
combine several write calls

May 21, 2014 Slide 25
2. All or several processes write to one file
+ Number of files is independent of number of
processes
+ File is in canonical representation (no post-
processing)
‒ Uncoordinated client requests might induce time
penalties
‒ File layout may induce false sharing of file system
blocks

May 21, 2014 Slide 26
Pitfall 2 – False sharing of file system blocks
Data blocks of individual processes do not fill up a
complete file system block
Free file system block
Data block
Several processes share a file system block
Exclusive access (e.g. write) must be serialized
The more processes have to synchronize the more
waiting time will propagate

May 21, 2014 Slide 27
3. Each process writes to its own file (task-local files)
+ Simple to implement
+ No coordination between processes needed
+ No false sharing of file system blocks
‒ Number of files quickly becomes unmanageable
‒ Files often need to be merged to create a canonical dataset
‒ File system might serialize meta data modification

May 21, 2014 Slide 28
Pitfall 3 – Serialization of meta data modification
1,7 3,2 4,0 5,5 18,2 76,2182,3
676,5
2004,6
0
500
1000
1500
2000
1k 2k 4k 8k 16k 32k 64k 128k 256k
# of Files
Tim
e (
s)
parallel create of task-local files
Example: Creating files in parallel in the same directory
Jugene, IBM Blue Gene/P, GPFS, filesystem /work using fopen()
> 3 minutes
> 11 minutes
> 33 minutes
The creation of 256.000 files costs 142.500 core hours !

May 21, 2014 Slide 29
Pitfall 4 – Portability
Endianess (byte order) of binary data
Example (32 bit):
2.712.847.316
=
10100001 10110010 11000011 11010100
Address Little Endian Big Endian
1000 11010100 10100001
1001 11000011 10110010
1002 10110010 11000011
1003 10100001 11010100
Conversion of files might be necessary and expensive
Solution: Choosing a portable data format (HDF5, NetCDF)

May 21, 2014 Slide 30
How to choose an I/O strategy?
Performance considerations
Amount of data
Frequency of reading/writing
Scalability
Portability
Different HPC architectures
Data exchange with others
Long-term storage

May 21, 2014 Slide 31
The Parallel I/O Software Stack
multi-dimensional data sets, various data types, attributes, ...
Application
Storage Hardware HDD SCM
SCM SCM
HDD
HDD
Parallel File System (GPFS), with POSIX API
MPI – I/O, supports collective and non-contiguous I/O
netCDF-4 P-HDF5 PnetCDF

May 21, 2014 Slide 32
I/O Libraries and Formats – Overview

May 21, 2014 Slide 33
Summary
Future performance of HPC systems will be driven through
more inherent parallelism
Increasing amount of data needs to be handled
Parallel file systems (Lustre and GPFS) to provide sufficient
I/O bandwidth
Application I/O has to exploit parallelism to make use of the
full available I/O bandwidth of modern storage solutions
Portable data formats are needed to efficiently process data
in heterogeneous environments
Multiple solutions to portable parallel I/O are available


















