
Panagiotis Papapetrou, George Kollios, Stan Sclaroff, Dimitrios Gunopulos Department of Computer...
49
Panagiotis Papapetrou, George Kollios, Stan Sclaroff, Dimitrios Gunopulos Department of Computer Science Boston University University of California, Riverside Discovering Frequent Arrangements of Temporal Intervals
-
Upload
brianne-holmes -
Category
Documents
-
view
219 -
download
0
Transcript of Panagiotis Papapetrou, George Kollios, Stan Sclaroff, Dimitrios Gunopulos Department of Computer...

Panagiotis Papapetrou, George Kollios, Stan Sclaroff, Dimitrios GunopulosDepartment of Computer Science
Boston University University of California, Riverside
Discovering Frequent Arrangements of Temporal Intervals

Introduction and Motivation Sequential pattern mining has received particular attention in the last decade:
Database of sequences: ordered lists of instantaneous events.
Extract frequent sequential patterns.
In many applications events occur over time intervals.
Extracting frequent arrangements of these temporally correlated labeled
intervals may lead to useful observations.
So far, algorithms concentrate on the case where events occur
instantaneously.
The idea of mining temporal patterns of interval-based events introduced in [1].
However, the extracted patterns are restricted to certain forms.
1. P. Kam and A. W. Fu. “Discovering temporal patterns of Interval-based Events”. In Proc. of the DaWak, pages 317–326, London, UK, 2000. Springer-Verlag.

Applications (1/4)Linguistics
(Eye-brow Lower)
(WH-Question)
(WH-Word)
time
ASL Database Collections of utterances.
Utterance:
Associates a segment of video with a detailed transcription.
Contains a number of ASL gestural and grammatical fields
each one occurring over a time interval. (WH-Word)
(Rapid head-shake)

Applications (2/4)Linguistics (An example)
> Who drove the car, who?
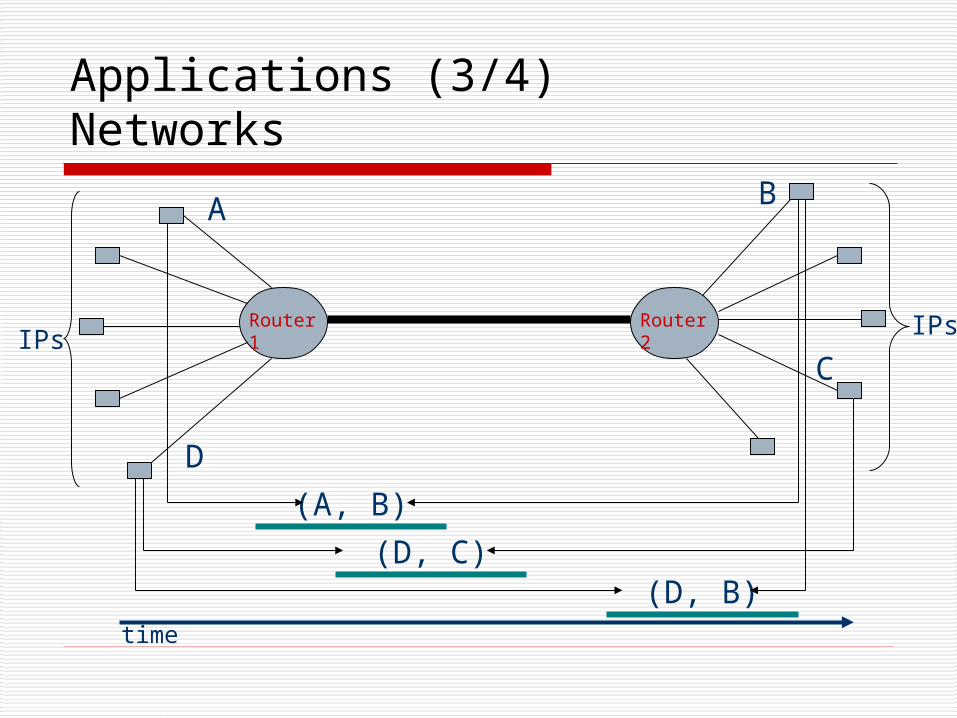
Applications (3/4)Networks
Router 1 Router 2IPs IPs
A B
(D, C)(D, B)
(A, B)
D
C
time

Applications (4/4)Biology
Human Gene
Region ofNucleodite A
Region ofNucleodite G
Region ofNucleodite C
(Nucleodite C)
(Nucleodite G)
(Nucleodite A)
Position in the Gene

Main Contributions
Formal definition of the problem of mining frequent temporal
arrangements of intervals in an interval database.
Development of two efficient mining algorithms that use
breadth first and depth search techniques in an enumeration
tree of temporal arrangements.
Extensive experimental evaluation and comparison with a
standard sequential pattern mining method both on real and
synthetic datasets.

Outline
Preliminaries Problem Formulation Proposed Algorithms
BFS-based DFS-based Hybrid-DFS
Experimental Evaluation Related Work Conclusions Future Work

Preliminaries (1/6) There can be many types of relations between two event intervals2. We consider five of them:
2. J. F. Allen and G. Ferguson. “Actions and events in interval temporal logic”. Technical Report 521, The University of Rochester, July 1994”.
A[tstart, tend] B[tstart, tend]
(a)
A[tstart, tend]
B[tstart, tend]
(b)
A[tstart, tend]
B[tstart, tend]
(c)Meet of A and B, denoted as: AB
Match of A and B, denoted as: A || B
Overlap of A and B, denoted as: A | B
A[tstart, tend]
B[tstart, tend]
(d)
A[tstart, tend] B[tstart, tend]
(e)
Contain of A and B, denoted as: A > B
Follow of A and B, denoted as: A → B
+/- e
+/- e+/- e

Preliminaries (2/6)
Let SS = { = {EE11, , EE22, …, , …, EEmm} be an ordered set of event intervals, called } be an ordered set of event intervals, called
event interval sequenceevent interval sequence, or, or e-sequence e-sequence..
Each Each EEii is a triple (eis a triple (eii, t, tiistartstart, t, tii
endend))
eeii: an event label.: an event label.
ttiistart:start:: the event start time.: the event start time.
ttiiend:end:: the event end time.: the event end time.
Note: Note: SS is ordered by t is ordered by tiistartstart..
k-e-sequencek-e-sequence: an e-sequence of size k.
e-sequence databasee-sequence database D: D: a set of e-sequences.

Preliminaries (3/6)
Example of a 5-e-sequence:
SS = { (A,1,7), (B,3,19), (D,4,30), (C,7,15), C,23,42) }= { (A,1,7), (B,3,19), (D,4,30), (C,7,15), C,23,42) }
A
B
CC
31 4 7 15 19 23 30 42
D

Preliminaries (4/6) k-Arrangement:k-Arrangement: a set of kk temporally correlated events in an
e-sequence, denoted as A = {EE , R}, where: E E : the set of labels of the event intervals in the arrangement.
R R : the set of temporal relations between the events in E.
)}E ,(Er ... ),E ,(Er ..., ),E ,(Er ),E ,(Er ..., ),E ,(Er ),E ,(E{r R n1-nn232n13121
}, |, ||, { )E ,(Er ji A
B
C
} }|, |, { C},B,{A, {
E1 Ei Ei+1 EnEi+3Ei+2Ei-1
where is the temporal relation between EEii and EEjj.

Preliminaries (5/6)
Given an e-sequence SS and an arrangement AA = {EE , RR}:
SS contains AA, if all the events in EE appear in SS, with the
relations defined in RR.
Given an e-sequence database DD and a minimum support
threshold min_supmin_sup:
An arrangement AA is frequent, if it is contained in at least
min_supmin_sup e-sequences (i.e. records) of DD.

Preliminaries (6/6)
A
B
C
A
B
CC
31 4 7 15 19 23 30 42
D
SS = {(A,1,7), (B,3,19), (D,4,30), (C,7,15), C,23,42)}= {(A,1,7), (B,3,19), (D,4,30), (C,7,15), C,23,42)}
Example of an arrangement AA, contained in an e-sequence SS:
} }, |, { C},B,{A, {

Problem Formulation
Our Goal:
Find the complete set of frequent arrangements given:
A e-sequence database D.D.
A minimum support threshold min_sup.min_sup.

Apply a sequential pattern mining algorithm?
Consider start and end points of an interval as two instantaneous events.
Convert each e-sequence into a regular sequence. Apply an efficient sequential pattern mining algorithm + post-
processing. Basic drawbacks:
k-arrangement = sequence of 2k events. May produce 22k patterns. Can we reduce it to 2k?
Extracted patterns will carry lots of redundant information.A
B
{Astart, Bstart, Aend, Bend},
but also: {Astart, Bstart},…
Sequential Pattern MiningAlgorithm will produce

Frequent Arrangement Mining Algorithms
Use a logical Tree-like structure to enumerate the
arrangements3.
Traverse the Tree using:
BFS
DFS
Hybrid DFS
BFS for the first two levels.
DFS for the rest of the mining process.
3. R. J. Bayardo. “Efficiently mining long patterns from databases”. In Proc. of ACM SIGMOD, pages 85–93, 1998.

The Arrangement Enumeration Tree
NULL
{A, B} {A, C} {B, A} {B, C} {C, A} {C, B}{A, A} {B, B} {C, C}
A->A A>B A->B AC A|C A||C A>C A->C
{A} {B} {C}
{A, A, A} {A, A, B} {A, B, A} {A, B, B} {A, B, C}{A, A, C}
AB*A|C*B||CAB*AC*B|C A||B*A->C*BC ...
AA A|A A||A A >A A||BAB A|B
Let },,{ CBAE
LEVEL3
LEVEL2
LEVEL1
Intermediate
Intermediate

BFS-based Approach (1/2) Traverses Tree in BFS order.
2 database scans.
On each step k:
Build candidate k-arrangements based on (k-1)-arrangements.
Find 2-relations by scanning the second level of the Tree.
Determine frequency: min_supmin_sup threshold must be satisfied.
If a node is not frequent, do not expand sub-tree (Apriori Principle)4.
Stop at step k, where no frequent arrangements are found.
4. R. Agrawal and R. Srikant. “Fast algorithms for mining association rules”. In Proc. of VLDB, pages 487-499, 1994.
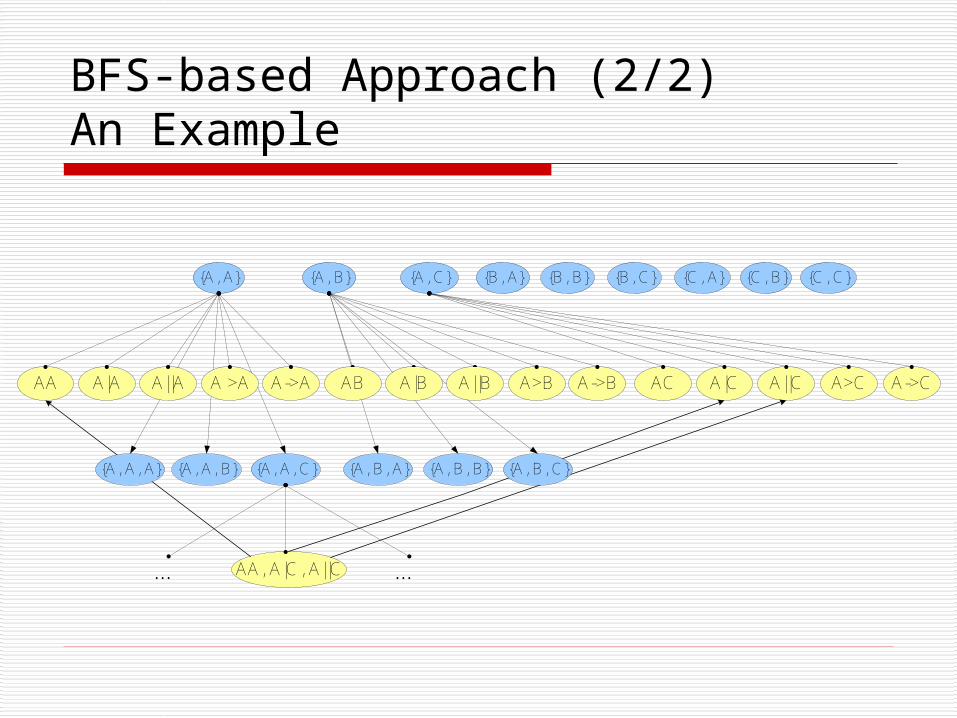
BFS-based Approach (2/2)An Example
{A, B} {A, C} {B, A} {B, C} {C, A} {C, B}{A, A} {B, B} {C, C}
A->A A>B A->B AC A|C A||C A>C A->C
{A, A, B} {A, B, A} {A, B, B}{A, A, C}
AA, A|C, A||C
AA A|A A||A A >A A||BAB A|B
… …
{A, B, C}{A, A, A}

DFS-based Approach Candidate generation in DFS order.
Leads to frequent large arrangements faster.
Skips expansions of nodes that are definitely going to lead to frequent
arrangements.
DFS is inappropriate:
For each node we would have to scan the database multiple times to
detect the 2-relations among the items in the node.
Hybrid-DFS
Generates the first two levels of the Tree using BFS, then uses DFS.
Eliminates multiple database scans, 2-relations are available.

Experimental Setup (1/4)Real Datasets SignStream Database
Created by the National Center for Sign Language and
Gesture Resources at Boston University.
Collection of 884 utterances.
Some types of event labels: Grammatical or syntactic structures:
WH-Question.
Negation.
Yes/No Question.
Gestural Fields: Head-shake.
Eye-brow raise/lower.

Experimental Setup (2/4)Real Datasets Network Data
Sampled from flow data.
Two routers with high communication rate:
ATLA: router in Atlanta.
LOSA: router in LA.
Monitored communication for 10 days, between 200 IPs.
An e-sequence is a set of IP connections for every 15 minutes:
An event label is the two IPs (source-destination).
The interval corresponds to the duration of this communication.
Size of dataset: 960 e-sequences.

Experimental Setup (3/4)Synthetic Datasets
Generated considering the following factors: Number of e-sequences in the Database.
Average e-sequence size.
Number of distinct items.
Density of frequent patterns.

Experimental Setup (4/4)Algorithms
Compared:
BFS.
Hybrid-DFS.
SPAM5, modified as follows:
Considered the start and end points of each interval as
two instantaneous events.
Post-processed the extracted sequential patterns to
convert them into arrangements.
5. J. Ayres, J. Gehrke, T. Yiu, and J. Flannick. Sequential pattern mining using a bitmap representation. In Proc. of ACM SIGKDD, pages 429–435, 2002.

Performance Analysis
BFS outperforms SPAM in large database sizes
and small supports.
Hybrid-DFS outperforms both SPAM and BFS.
In low supports Hybrid-DFS is twice as fast as
BFS.

Sample Results (1/4) SignStream Database

Head: tilt side
Negation
Eye-brow raise
Negation
72 % 87 %
Head: tilt side
Yes/No Word
Eye-brow raise
Yes/No Word
68 % 87 %
Eye-brow lower
Yes/No Word
76 %
Head: tilt side
Eye-brow lower
Yes/No Word
74 %
Negations:
YES/NO Questions:
Sample Results (2/4) SignStream Database

Sample Results (3/4) SignStream Database
WH-questions:
For more detailed results visit the following web page:http://cs-people.bu.edu/panagpap/Research/asl_mining.htm
Eye-brow lower
Wh-word
Head: jut forward
Wh-word
Eye-aperture: squint
Wh-word
Head: rapid shake
Wh-word85 %
56 %
51 %
85 %

Sample Results (4/4)Network Dataset

Related Work Problem of mining frequent itemsets and association rules was first
introduced by R. Agrawal and R. Srikant, 1994.
An extension to episodes (i.e. combinations of events with a partially
specified order) was proposed in [H. Mannila et. al. 1995].
Some efficient sequential pattern mining algorithms have been proposed
in [M. Zaki. et. al. 2001] and [J. Ayres et. al. 2002].
Closed sequential pattern mining algorithms presented in [X. Yan. et. al.
2003] and [J.Wang et. al. 2004].
Interval-based events introduced in [P. Kam et. Al. 2000], however
restricted to certain forms + apriori-based.

Conclusions The problem of mining frequent arrangements of temporal
intervals has been formally defined. Two efficient methods for solving the problem have been
discussed. Both methods use an arrangement enumeration tree to
discover the set of frequent arrangements. The DFS-based approach further improves performance over
BFS:
Longer arrangements are reached faster. The need to examine smaller subsets of these
arrangements is eliminated.

Future Work
Push additional constraints into the mining process:
Gap constraints.
Regular expression constraints.
Mine top-k frequent arrangements.
Mine frequent closed arrangements.
Apply other interestingness measures.

EXTRA SLIDES

Applications American Sign Language databases
Extract frequent correlations between grammatical and syntactic structures + manual and gestural fields.
Network Monitoring: Analyze packet and router logs. Detect temporal relations of events occurring over time
periods. Patterns can be used for prediction and intrusion detection.
Biology: Find frequent overlapping regions of nucleotides in the
human gene.

Apply a closed sequential pattern mining algorithm*?
Noise again…
A
B
A
B
A
B
{Astart, Bstart, Aend, Bend}: 2/3
But also:
{Astart, Aend, Bend}: 3/3
Closed Sequential PatternMining Algorithm
*. J.Wang and J. Han. “Bide: Efficient mining of frequent closed sequences”. In Proc. of IEEE ICDE, pages 79–90, 2004.

The ISIdList Structure (1/2) An ISIdList is defined for every arrangement generated
throughout the mining process. The ISIdList for an arrangement AA = { , R} in an e-
sequence database DD, has the following structure: Head: Arrangement representation using and R. A record for each e-sequence in the database that supports AA. Each record is of type (idid, intv-Listintv-List), where:
idid is the id of the e-sequence in DD. intv-List:intv-List:
set of intervals where AA occurs in the e-sequence A (for | | ≤ 2). set of pointers to records of ISIdLists of the second level (for | | > 2).
E
E
EE

The ISIdList Structure (2/2) (Example)
Database D
id e-sequence
1
2
4
3
A [1, 3], B [1, 3], A [6, 12], B [8, 11], C [ 9, 10]
A [1, 2], B [2, 6], A [10, 12], B [11, 15], C [14, 17]
B [1, 3], A [4, 7], A [9, 11], B [11, 12] , C [12, 14]
B [1, 5], A [6, 14], B [7, 10], C [8, 9]
A
esid Intv-List
1
1
2
2
3
3
4
[1, 3]
[6, 12]
[1, 2]
[10, 12]
[4, 7]
[9, 11]
[6, 14]
B
esid
1
1
2
2
3
3
4
[1, 3]
[8, 11]
[2, 6]
[11, 15]
[1, 3]
[11, 12]
[1, 5]
Intv-List
4 [7, 10]
C
esid
1
2
3
4
[9, 10]
[14, 17]
[12, 14]
[8, 9]
Intv-List
Let DD consist of a set or e-sequences of event intervals with labels A, B, C.
The set of frequent 1 arrangements is {A, B, C}, with the following ISIdLists:

BFS-based Approach
At each Step k: Use Tree to generate candidate arrangements:
Build N(k) from N(k-1). Construct IMk. For every 2-relation, point to the
second level of the Tree. Check support. If it satisfies min_sup, then add to
Fk. Continue with the rest of the Tree in a BFS order. If a node is found not to be frequent, do not expand
its sub-tree (Apriori Principle)3. Stop at step k, where Fk = empty.
3. R. Agrawal and R. Srikant. “Fast algorithms for mining association rules”. In Proc. of VLDB, pages 487-499, 1994.

BFS-based Approach (1/4) DD: an input e-sequence database. FF: the complete set of frequent
arrangements. FFkk: the complete set of frequent k-
arrangements. CCkk: the current set of candidate k-
arrangements. min_supmin_sup: the minimum support threshold. ISIdList (A)ISIdList (A): the ISIdList of arrangement A.

BFS-based Approach (2/4)
BFS:STEP 1: Find F1
Use Tree to generate C1
Build N(1). For each ni
1 in N(1): Build ISIdList (Ai), where Ai is the arrangement that
corresponds to ni1.
If the number of records in ISIdList (Ai) is at least min_sup,min_sup, then A is inserted into F1.

BFS-based Approach (3/4)
BFS:STEP k: Find Fk
Use Tree to generate Ck
Build N(k) from N(k-1). Construct IMk.
For each node in IMk: Build ISIdList. If the number of records in the ISIdList is at least
min_sup,min_sup, insert arrangement into F1.
Continue with the rest of the Tree in a BFS order.

BFS-based Approach (4/4)
Continue with the rest of the Tree in a BFS order.
If a node is found not to be frequent, do not expand its sub-tree (Apriori Principle)1.
Stop at step k, where Fk = empty.
1. R. Agrawal and R. Srikant. Fast algorithms for mining association rules. In proc. of VLDB, pages 487-499, 1994.

Hybrid DFS-based Approach
DFS is inappropriate:
For each node we would have to scan the database multiple
times to detect the 2-relations among the items in the node.
Though in BFS these relations are already available.
Generate the first two levels of the Tree using BFS.
Then use DFS.
Eliminates multiple database scans, since now the 2-relations are
available.

BFS-based Approach (1/2) Creating a 2-arrangement (Example)
A
esid Intv-List
1
1
2
2
3
3
4
[1, 3]
[6, 12]
[1, 2]
[10, 12]
[4, 7]
[9, 11]
[6, 14]
B
esid
1
1
2
2
3
3
4
[1, 3]
[8, 11]
[2, 6]
[11, 15]
[1, 3]
[11, 12]
[1, 5]
Intv-List
4 [7, 10]
Meet (A, B)
esid
2
3
[1, 2] , [2, 6]
Intv-List
[9, 11] , [11, 12]
Follow (A, B)
esid
1
2
[1, 3] , [8, 11]
Intv-List
[1, 2] , [11, 15]
3 [4, 7] , [11, 12]
{A, B}
Contain (A, B)
esid
1 [6, 12] , [8, 11]
Intv-List
4 [6, 14] , [7, 10]

BFS-based Approach (2/2)Creating a 3-arrangement (Example)
{A, B, C}
Contain (A, B) * Contain (A, C) * Contain (B, C)
esid
1
4
Intv-List
Contain (A, B)
esid
1 [6, 12] , [8, 11]
Intv-List
4 [6, 14] , [7, 10]
Contain (B, C)
esid
1
4
[8, 11] , [9, 10]
Intv-List
[7, 10] , [8, 9]
Contain (A, C)
esid
1
4
[6, 12] , [9, 10]
Intv-List
[6, 14] , [8, 9]

Experimental SetupReal Datasets
Dataset 1: Utterances of WH-Questions.
Size: 73 e-sequences.
# of labels: 400.
Dataset 2: SignStream Database.
Size: 884 e-sequences.
# of labels: 400.

Related Work (1/2) Problem of frequent itemset mining first introduced in:
R. Agrawal and R. Srikant. Fast algorithms for mining association rules. In proc. of VLDB, pages 487-499, 1994.
An extension to episodes (i.e. combinations of events with a partially specified order) was proposed in: H. Mannila, H. Toivonen, and A. Verkamo. Discovering Frequent episodes in
sequences. In Proc. of ACM SIGKDD, pages 210–215, 1995.
The Itemset Enumeration Tree was described in: R. J. Bayardo. Efficiently mining long patterns from
databases. In Proc. of ACM SIGMOD, pages 85–93, 1998.
Some efficient sequential pattern mining algorithms have been proposed in: M. Zaki. Spade: An efficient algorithm for mining sequences. Machine Learning,
40:31–60, 2001. J. Ayres, J. Gehrke, T. Yiu, and J. Flannick. Sequential pattern mining using a bitmap
representation. In Proc. of ACM SIGKDD, pages 429–435, 2002.

Related Work (2/2) Closed frequent itemset mining algorithms:
J. Pei, J. Han, and R.Mao. Closet: An efficient algorithm form ining frequent closed itemsets. In Proc. of DMKD, pages 11–20, 2000.
M. Zaki and C. Hsiao. Charm: An efficient algorithm for closed itemset mining. In Proc. of SIAM, pages 457–473, 2002.
Closed sequential pattern mining: X. Yan, J. Han, and R. Afshar. Clospan: Mining closed sequential patterns in large
databases. In Proc. of SDM, 2003. J.Wang and J. Han. Bide: Efficient mining of frequent closed sequences. In Proc. of
IEEE ICDE, pages 79–90, 2004. Mining association rules in temporal and spatio-temporal databases:
T. Abraham and J. F. Roddick. Incremental meta-mining from large temporal data sets. In ER ’98: Proceedings of the Workshops on Data Warehousing and Data Mining , pages 41–54, 1999.
X. Chen and I. Petrounias. Mining temporal features in association rules. In Proc. of PKDD, pages 295–300, London, UK, 1999. Springer-Verlag.
I. Tsoukatos and D. Gunopulos. Efficient mining of spatiotemporal patterns. In Proc. of the SSTD, pages 425–442, 2001.
Discovering temporal patterns of Interval-based Events: P. Kam and A. W. Fu. Discovering temporal patterns of Interval-based Events. In Proc.
of the DaWak, pages 317–326, London, UK, 2000. Springer-Verlag.


















