
Overview of Text Mining Expertise @ SCD. Text Mining @ SCD Introduction Text mining team @ SCD ...
24
Overview of Text Mining Expertise @ SCD
-
date post
19-Dec-2015 -
Category
Documents
-
view
223 -
download
3
Transcript of Overview of Text Mining Expertise @ SCD. Text Mining @ SCD Introduction Text mining team @ SCD ...

Overview of Text Mining Expertise @ SCD

Text Mining @ SCD
Introduction
Text mining team @ SCD
Started around 2000 Currenty 1 postdoc, 4 PhD students Tailored, generic text mining analysis Diverse application areas Several collaborations and projects.
Supported by more general SCD expertise in a.o.• Data mining• Numerical linear algebra• Optimization

Text Mining @ SCD
Strategic mission
To consolidate, deepen and extend SCD’s text mining expertise
By combining statistical approaches and domain-specific information
To support knowledge discovery through literature analysis in various domains: Bio-informatics Knowledge management Mapping of science and technology Bibliometrics

Text Mining @ SCD
Problem setting
Given a set of documents,
compute a representation, called index
to retrieve, summarize, classify or cluster them
<1 0 0 1 0 1>
<1 1 0 0 0 1>
<0 0 0 1 1 0>

Text Mining @ SCD
Problem setting - 2
InformationRetrieval
InformationExtraction
Full NLP parsing
Shallow Statistics
GenericProblemspecific
Domain-specific
Shallow Parsing
Document analysis &Extraction of tokens
Text mining goals
Text mining methodology
Overall approach

Text Mining @ SCD
Overview
Bio-informatics Knowledge management Bibliometrics & scientometrics

Text Mining @ SCD
Overview
Bio-informatics Knowledge management Bibliometrics & scientometrics
Text Mining @ SCD
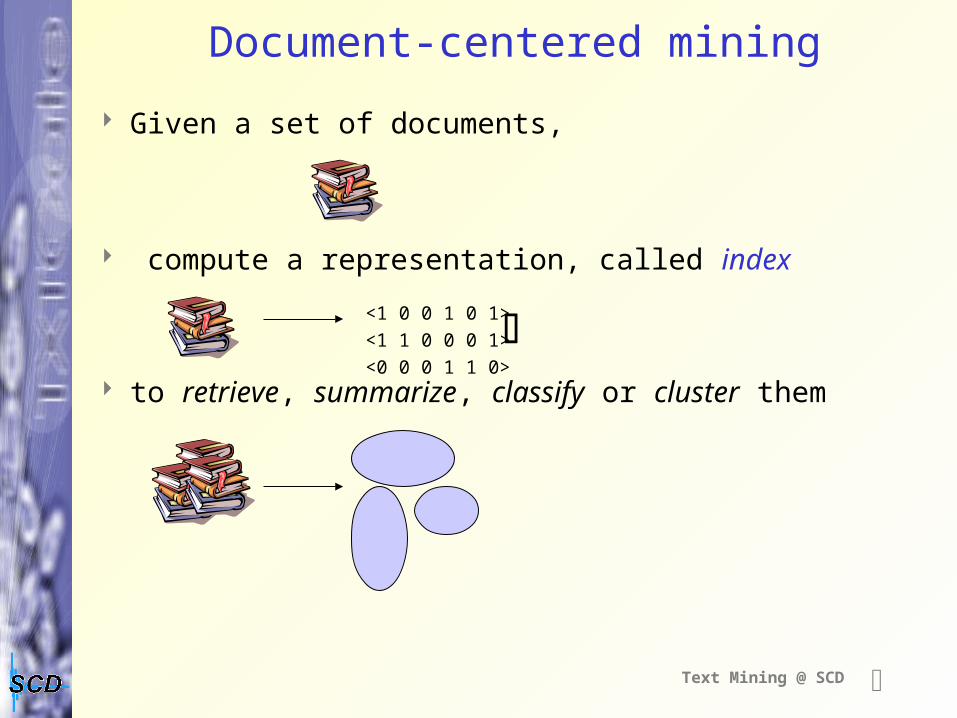
Document-centered mining
Given a set of documents,
compute a representation, called index
to retrieve, summarize, classify or cluster them
<1 0 0 1 0 1>
<1 1 0 0 0 1>
<0 0 0 1 1 0>
Text Mining @ SCD
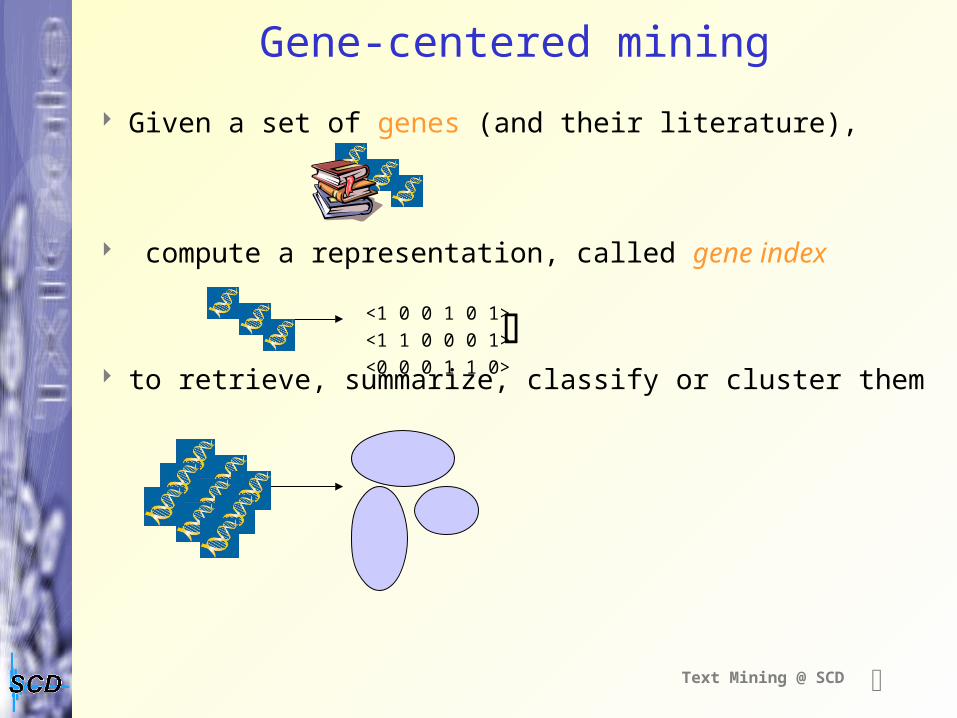
Gene-centered mining
Given a set of genes (and their literature),
compute a representation, called gene index
to retrieve, summarize, classify or cluster them
<1 0 0 1 0 1>
<1 1 0 0 0 1>
<0 0 0 1 1 0>
Text Mining @ SCD
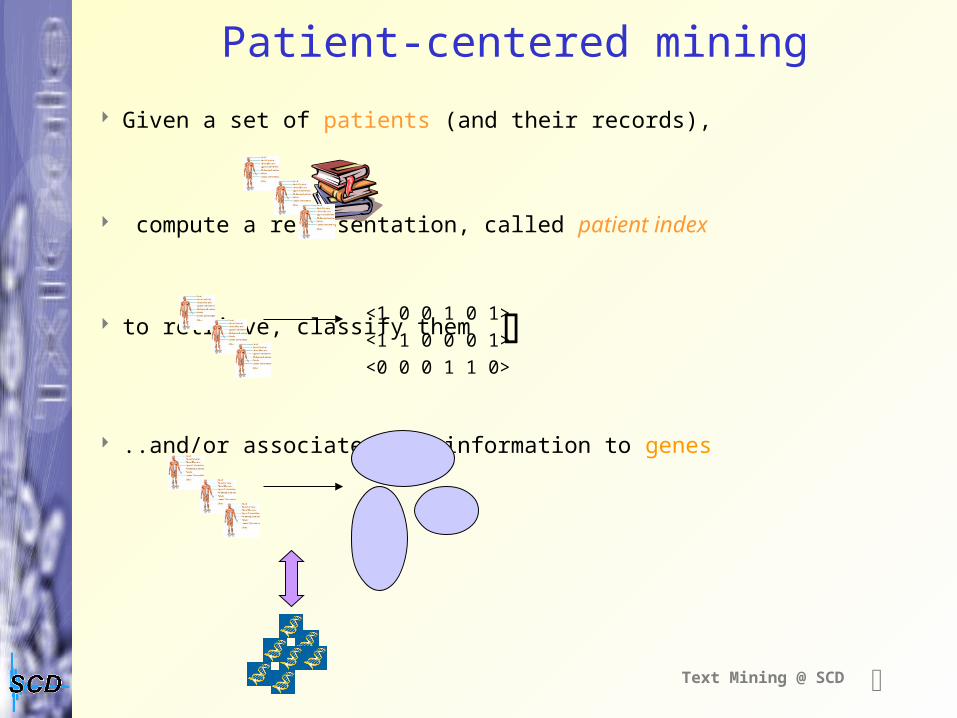
Patient-centered mining
Given a set of patients (and their records),
compute a representation, called patient index
to retrieve, classify them
..and/or associate this information to genes
<1 0 0 1 0 1>
<1 1 0 0 0 1>
<0 0 0 1 1 0>
Text Mining @ SCD
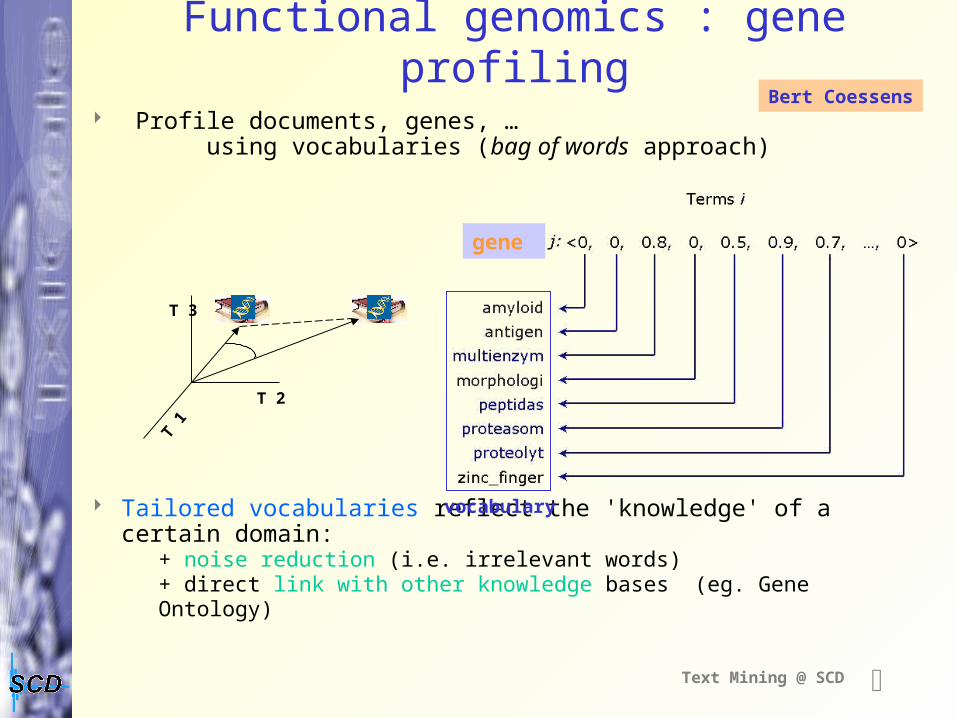
Functional genomics : gene profiling
Profile documents, genes, … using vocabularies (bag of words approach)
Tailored vocabularies reflect the 'knowledge' of a certain domain:+ noise reduction (i.e. irrelevant words) + direct link with other knowledge bases (eg. Gene Ontology)
vocabulary
T 1
T 3
T 2
gene
Bert Coessens
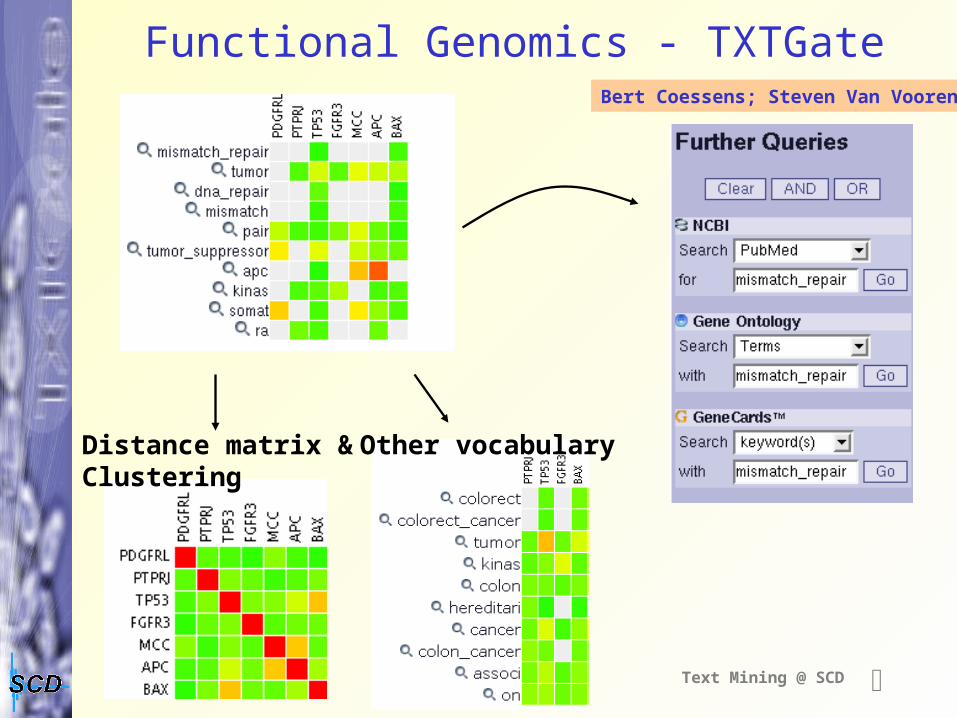
Text Mining @ SCD
Functional Genomics - TXTGate
Distance matrix &Clustering
Other vocabulary
Bert Coessens; Steven Van Vooren

Text Mining @ SCD
Functional genomics – Networks from literature
gene networks
term networks
Bert Coessens; Frizo Janssens

Text Mining @ SCD
Human genetics
Collaboration with Human Genetics Centre @ University Hospital KU Leuven.
Mining on clinical profile and chromosomal footprint of patients (CGH microarrays)
Knowledge discovery for genomic annotation Aiming at tools and standards for reporting, data entry and
visualisation supporting experts in exploring hypotheses in linking phenotypes to genotypes and in inference of novel gene candidates
Steven Van Vooren
Data Analysis Text AnalysisNLP; Ontologies
Text Mining @ SCD
Human genetics
Knowledge discovery for genomic annotation• From µA-CGH profiles• From Biomedical text
Similarity measures for biomedical text what: patient records, literature, genes, loci, cloneswhy: retrieval, clustering, inference• Clustering similar patients, genes, loci, documents • Finding genes associated by patient records
Extracting entities from text• gene name symbols, loci, diseases, phenotypes, clinical
entities, karyotypes
Text summarization • Profiling of patients, genes, loci, clones, clusters of ~ .
Steven Van Vooren

Text Mining @ SCD
Overview
Bio-informatics
Knowledge management Bibliometrics & scientometrics
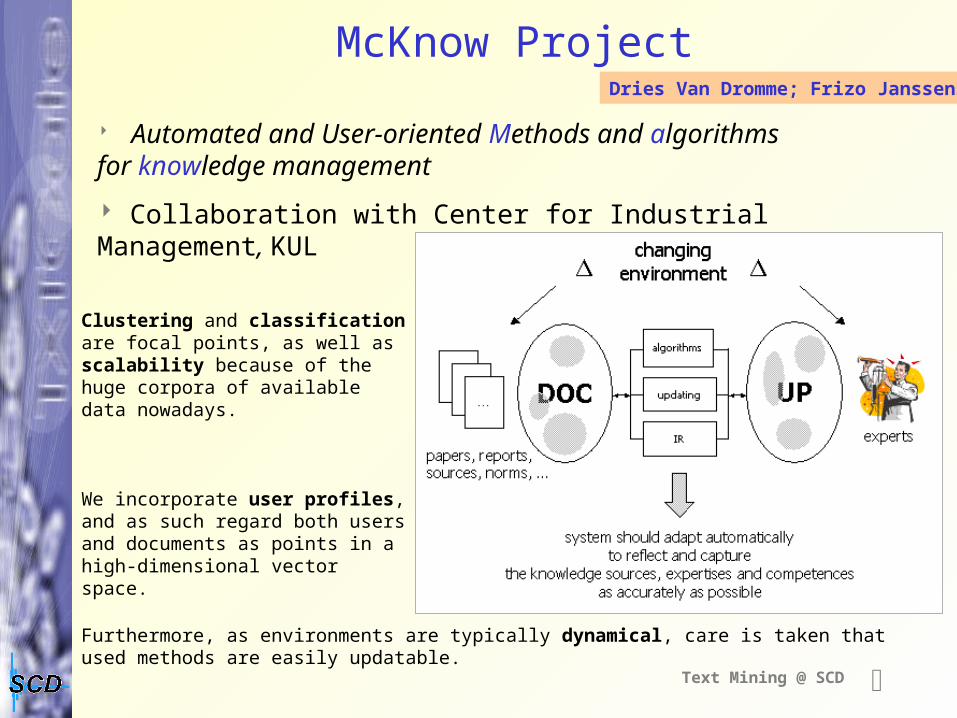
Text Mining @ SCD
McKnow Project
Clustering and classification are focal points, as well as scalability because of the huge corpora of available data nowadays.
We incorporate user profiles, and as such regard both users and documents as points in a high-dimensional vector space.
Furthermore, as environments are typically dynamical, care is taken that used methods are easily updatable.
Dries Van Dromme; Frizo Janssens
Automated and User-oriented Methods and algorithms for knowledge management
Collaboration with Center for Industrial Management, KUL

Text Mining @ SCD
Case studies knowledge management Dimensionality of clustered text-mining cases:
sista papers• electronically available publications (ps, pdf) – full text• 1024 x 49.237
De Standaard• full text newspaper articles, but a lot of them very short• 1776 x 39.363 - but much more data available
kuleuven papers• electronically available papers pertaining to researchers from different
departments (pdf, word,...)• 576 x 68.257 ! less documents, broader spectrum
patent abstracts• international patent abstracts and titles• 16.488 x 21.019 ! a lot more doc’s, denser spectrum
PMA papers• full text publications of the K.U.Leuven dept. of Mechanics• 380 x 18.206
Locuslink “known genes with proteins”• gene documents from MEDLINE abstracts• 12.263 x 58.924
Dries Van Dromme

Text Mining @ SCD
Overview
Bio-informatics Knowledge management
Bibliometrics & scientometrics

Text Mining @ SCD
Scope
Bibliometricsthe application of mathematical and statistical methods to books and other media of communication
Scientometricsthe application of those quantitative methods which are dealing with the analysis of science viewed as an information process
Patent analysis and miningThe analysis of patent information is considered to be one of the best established, directly available and historically reliable methods of quantifying the output of a science and technology system
Collaboration with Steunpunt O&O Statistieken<< to consolidate and to further develop Flanders position as a European innovation intensive region >>

Text Mining @ SCD
Projects
1. Domain Analysis Mapping of Nanotechnology field from USPTO/EPO patents
• Text-based clustering ; identification of sub-domains• comparison with IPC (International Patent Classification)• comparison with FTC (Fraunhofer Technology Classification)
2. Science-Technology mapping link scientific publications (WoS) and new technologies (patents)
• text-based clustering & analysis of citation network structure• Case study: Ljung
3. Trend Detection assess trends & emerging fields from “change over time” in
structure and characterization of clusters & citation network
Dries Van Dromme; Frizo Janssens

Text Mining @ SCD
Software
Preprocessing &Indexing Lucene & TextPack
Search engine and webservices TXTGate and McKnow

Text Mining @ SCD
Publicationstargetted submissions by Dec
Bio-informatics (1-2) (BMC) bioinformatics, special issues,.. (BC) More biological journals (BC, SVV)
Knowledge management (1) Scientometrics, SIAM DM,
Bibliometrics & scientometrics (1) Case study Bioinformatics, Trends in.. IEEE transactions, engineering, webmining journals SIAM DM
High, moderate, fair impact

Text Mining @ SCD
Collaborations Formalized
GBOU-McKnow• partner CIB olv Joost Duflou (Joris Vertommen, Dries Cleymans)• User Committee (ICMS, Verhaert, LMS, TriSoft, WTCM)
IWT met Joris V (Steven: aanvullen/corrigeren) Steunpunt O&O Statistieken, INCENTIM
• Patent clustering and detection of emerging trends
Informal M-F Moens (SBO ?) IBM – Bart VL Gasthuisberg en Peter M: TXTGate als ‘vak’ J&J


















