
Evidence of gene deletion of p21 (WAFl/CIPi), a cycin-dependent ...

Optimizing the WAFL File System for the
Many-core and Many-media EraMatthew Curtis-Maury, PhD [email protected]
© 2016 NetApp, Inc. All rights reserved. 1

Agenda
1) Background on NetApp and WAFL
2) Multiprocessor Execution in WAFL
3) Write Allocation Architecture
4) Buffer Cache Management
5) Summary
© 2016 NetApp, Inc. All rights reserved. 2

Background on NetApp
© 2016 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---3

What is NetApp?
§ Primarily a data storage technology company§ Servers with software to manage huge amounts of data§ High performance data access, replicate data, backup to the cloud, etc
§ 12,000 global employees (Silicon Valley, RTP, Bangalore)
§ $6.1 billion annual revenue
§ It’s a great place to work§ #4 “World Best Multinational Workplaces” (Great Place to Work Institute)§ 13 consecutive years on FORTUNE’s “100 Best Companies to Work For”
§ #1 in 2009§ Engineering sites in RTP, Sunnyvale, and Bangalore
© 2016 NetApp, Inc. All rights reserved. 4

Background on ONTAP
§ Data ONTAP is our proprietary storage operating system that runs on storage servers (or “filers”)§ On real hardware or in a virtual machine
§ Connect over one of many supported protocols to access data
© 2016 NetApp, Inc. All rights reserved. 5
FCP iSCSI CIFS NFS
Lun Semantics File Semantics
WAFL Virtualization Layer
RAID and storage interface

Background on WAFL
§ WAFL: Write Anywhere File Layout§ Filesystem in the NetApp Data ONTAP OS§ All data and metadata stored in files, hierarchy rooted at the SuperBlock§ File data stored in 4K blocks that can be cached in core as buffers§ Storage is managed as Aggregates (collections of drives)§ Data is managed as Volumes (FlexVols) within the Aggregates
§ Writes flushed to disk in a batch called Consistency Point§ Persistence guaranteed through non-volatile log in NVRAM§ Data always written to new blocks on disk (no overwrites)
§ Currently supported hardware:§ 2 – 40 cores on a single node§ 4 – 512GB of RAM
© 2016 NetApp, Inc. All rights reserved. 6

Historical Perspective
© 2016 NetApp, Inc. All rights reserved. 7
1994 2016 ChangeMemory 256MB 512GB 2K xMax Capacity 28GB 138PB 5M xStorageMedia
SPI HDD SATA, SAS, SSD, NVMe, SMR, Cloud, etc
SFS ops 626 500k ~1K xNum Cores 1 ~40LoC 18K 30M 1K x
This talk is about supporting more cores, more media types, and more memory.

Evolution of Multiprocessor Execution in WAFL
© 2016 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---8

© 2016 NetApp, Inc. All rights reserved. 9
Summary
§ Problem Statement:§ New systems continue to have more cores, but WAFL cannot be rewritten from scratch for better scalability.
§ Solution:§ A set of techniques that allow WAFL to be INCREMENTALLY parallelized with reasonable effort at each stage to achieve the required parallelism.
§ Classical Waffinity (2006), Hierarchical Waffinity (2011), Hybrid Waffinity (2016)
§ From “To Waffinity and Beyond: A Scalable Architecture for Incremental Parallelization of File System Code”§ OSDI 2016

Background
© 2016 NetApp, Inc. All rights reserved. 10
§ NetApp Data ONTAP OS§ Commercial operating system running on storage servers
§ WAFL File System: Write Anywhere File Layout§ Processes messages that represent file system requests § All data and metadata stored in files§ File data stored in 4K blocks that can be cached in core as buffers§ Storage is managed as Aggregates (collections of drives)§ Data is managed as Volumes within the Aggregates
§ Competitive performance requires continued CPU scaling§ Problem: WAFL is millions of lines of complicated code§ A pure locking model would require impractical levels of code changes§ Many other techniques in the literature, not suitable for (our) legacy system
§ E.g., Barrelfish, fos, Corey, Multikernel, …

History of Parallelism in ONTAP
© 2016 NetApp, Inc. All rights reserved. 11
§ Data ONTAP was created for single-CPU systems of 1994
§ Parallelism via “Coarse-grained Symmetric Multi-processing”§ Each subsystem was assigned to a single-threaded domain§ Minimal explicit locking required, message passing between domains§ Scaled to 4 cores, but all of WAFL serialized
RAID WAFL Network Storage Protocol
CPUs
…

Classical Waffinity
© 2016 NetApp, Inc. All rights reserved. 12
§ In the beginning… WAFL processed all messages serially§ WAFL parallelism introduced with Waffinity (2006)
§ User files partitioned into 2MB file stripes§ Messages to each file stripe are mapped to data partitions called Stripe affinities§ Scheduler dynamically assigns affinities to a set of parallel threads § Facilitates parallelism with minimal locking/code changes§ Serial affinity that excludes all Stripe affinities
§ Parallelized the most common operations: R and W to user files§ Scaled effectively to 8 cores
CPUs
WAFL

S3
Classical Waffinity (2006)
© 2016 NetApp, Inc. All rights reserved. 13
W(A, 0)
0 2 31 4 6 75
W(B, 0)
W(A, 7)
R(A, 0)
A0 2 31 4 6 75B
Stripe 1
Stripe 2
Stripe 3
Serial
Delete A
Idle threads
S1
S5
S6
Runnable affinities
S4 S8
Cores
Incoming messages
Work in Serial affinity is bad!

Hierarchical Waffinity (2011)
© 2016 NetApp, Inc. All rights reserved. 14
§ Hierarchical data partitioning to match hierarchical data§ Particular shape fine-tuned for WAFL§ Hierarchical permissions / exclusion
§ Allows parallelization of work that used to run in Serial affinity§ Friendly to incremental development
AGGR
STRIPE
Node
Aggregates
Volumes
Files
Blocks
File system Hierarchy
STRIPE
Files
Blocks STRIPE
Volumes
Files
Blocks STRIPE
Files
Blocks
AGGR
VOL
STRIPE
Serial
Aggregate
Volume
Volume Logical
Stripe
Aggregate VBN
Volume VBN
STRIPEVVBN Range
STRIPEAVBN Range
Affinity Hierarchy

Hierarchical Waffinity – Data mappings
© 2016 NetApp, Inc. All rights reserved. 15
Aggregate
Serial
Aggregate
Volume
Volume Logical
Stripe
Aggregate VBN
Volume VBN
Range
Range
Stripe Range
Volume
Volume Logical
Stripe
Volume VBN
RangeStripe RangeRange
Retain Stripe affinities (now per volume)
Parallelism between user file and metafile accesses
User data Metadata
Parallelism between different volumes and aggregatesParallelism between different volumes and aggregates

Classical vs. Hierarchical Waffinity
© 2016 NetApp, Inc. All rights reserved. 16
§ SFS2008 contains metadata operations (Create, Remove, etc)§ Classical Waffinity: Ran in Serial affinity (48% of wallclock time)§ Hierarchical Waffinity allows the messages to run in Volume (Logical)
§ 2.59 additional cores used translated into a 23% throughput increase
7.79
10.38
0
3
6
9
12
0
40
80
120
160
Classical Waffinity Hierarchical Waffinity
Core Usage
Throughput
(K ops/sec)
SFS2008
Throughput Core Usage
AGGR
VOL
STRIPE
Serial
Aggregate
Volume
Volume Logical
Stripe
Aggregate VBN
Volume VBN
STRIPEVVBN Range
STRIPEAVBN Range

Hierarchical Waffinity CPU Scaling
© 2016 NetApp, Inc. All rights reserved. 17
§ 95% average core occupancy across 6 key workloads
0
5
10
15
20
1 2 3 4 5 6 7 8
Core Usage
RandomRead SequentialRead RandomWriteSequentialWrite SFS2008 SPC1

Hierarchical Waffinity Limitations
© 2016 NetApp, Inc. All rights reserved. 18
§ Some important workloads access two different file blocks§ SnapVault: Replicates a volume’s contents. Writes user data plus metadata.§ Block Free: Updates FS metadata. Writes to multiple metafiles.
§ Mappings optimized for traditional cases not well-suited here
AGGR
VOL
STRIPE
Serial
Aggregate
Volume
Volume Logical
Stripe
Aggregate VBN
Volume VBN
STRIPEVVBN Range
STRIPEAVBN Range
User DataMetadataUser Data + Metadata

© 2016 NetApp, Inc. All rights reserved. 19
Hybrid Waffinity (2016)
§ Extends Waffinity with fine-grained locking§ Allows particular blocks to be accessed from multiple affinities§ These blocks protected with locking
§ Allows incremental development§ Most blocks (and therefore code) continue to use partitioning§ Even lock-protected buffers can remain unchanged
AGGR
VOL
STRIPE
Serial
Aggregate
Volume
Volume Logical
Stripe
Aggregate VBN
Volume VBN
STRIPEVVBN Range
STRIPEAVBN Range
User DataMetadata
Lock-free MetadataNo Access

Hybrid vs. Hierarchical Waffinity
© 2016 NetApp, Inc. All rights reserved. 20
§ Block allocation and free operations in Volume VBN for metadata accesses§ Hybrid Waffinity allows message to run in Volume VBN Range§ 62.8% increase in throughput from 4.8 cores additional cores
0
10
20
0
1,000
2,000
1 2 3 4 5 6 7 8 9
Core Usage
Throughput (MB/s)
Sequential Overwrite
Hierarchical Waffinity Tput Hybrid Waffinity TputHierarchical Waffinity Cores Hybrid Waffinity Cores
AGGR
VOL
STRIPE
Serial
Aggregate
Volume
Volume Logical
Stripe
Aggregate VBN
Volume VBN
STRIPEVVBN Range
STRIPEAVBN Range

Conclusion
© 2016 NetApp, Inc. All rights reserved. 21
§ Developed a set of techniques to allow incremental parallelization of the WAFL file system§ Focusing on data partitioning has kept the required code changes to a manageable level while allowing sufficient parallelism
§ Selectively adding in locking in a restricted way has further parallelized workloads with poor data partition mappings
§ Provided insight into the internals of a high-performance production file system

Write Allocation Architecture in WAFL
© 2016 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---22

© 2016 NetApp, Inc. All rights reserved. 23
Summary
§ Problem Statement:§ Existing write allocator not extensible to new storage types AND not scalable on many cores. Must adapt to new media to stay competitive.
§ Solution:§ A write allocation architecture in WAFL that allows for the rapid adoption of new storage media and scales to many cores.
§ From “White Alligator: An Architecture for WAFL Write Allocation in the Many-Core and Many-Media Era”§ Submitted to FAST 2017

What is Write Allocation?
© 2016 NetApp, Inc. All rights reserved. 24
§ Storage systems must store modifications to persistent storage§ Write allocation is everything involved in persisting FS changes
§ Identifying “desirable” locations on disk to write to§ Arranging data and metadata on these locations
§ Drives are carved up into fixed size blocks§ Blocks within a drive and across drive types have different properties§ Match the right data to the right disk location
§ Need to quickly and efficiently:§ Find free locations§ Perform the write§ Update metadata§ Perform subsequent reads of the data

Background on WAFL
© 2016 NetApp, Inc. All rights reserved. 25
§ In WAFL, every write is to a new disk location (no overwrites)§ Writes are buffered in memory and flushed to disk in a batch
§ Reply to client quickly after operation is logged in NVRAM§ Consistent set of changes flushed to disk atomically (Consistency Point)§ Batching allows for better layout and amortization of overhead
User dataMetadata
Super Block
In-coreFS Flush modifications to disk Flush modifications to disk
Start CPFreeze FS data
Start CPFreeze FS data
User dataMetadata
Super Block
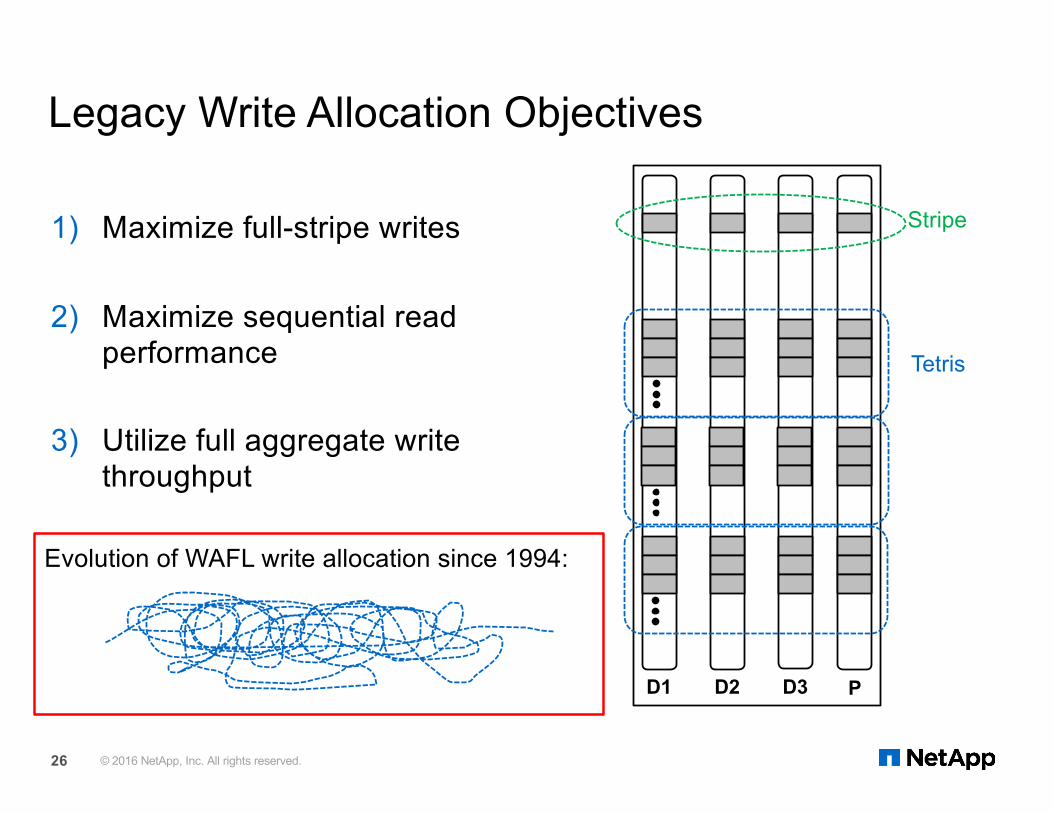
Legacy Write Allocation Objectives
© 2016 NetApp, Inc. All rights reserved. 26
1) Maximize full-stripe writes
2) Maximize sequential readperformance
3) Utilize full aggregate writethroughput
D1 PD2 D3
Stripe
Tetris
Evolution of WAFL write allocation since 1994:

Legacy Write Allocation Architecture
© 2016 NetApp, Inc. All rights reserved. 27
Infrastructure to:(a) find desired blocks, (b) efficiently write to them, and(c) update corresponding metadata
Policy to control the specific layoutof file blocks on the storage medium

White Alligator Architecture
© 2016 NetApp, Inc. All rights reserved. 28
Traditionalpolicy
Policy
Infrastructure
API
FlashPools© NextThing

White Alligator Architecture
© 2016 NetApp, Inc. All rights reserved. 29
§ Buckets of blocks are passed across the API§ Infrastructure provides blocks with certain attributes
§ E.g., SSD, outer cylinder HDD blocks, cloud block, etc§ Keeps a supply of filled buckets available in a lock-protected “bucket cache”
§ Policies implemented to make use of the provided types of blocks§ Many advantages to operating on buckets 1) Quick adoption of new storage media2) Policy and infrastructure are independently parallelizable• Write allocation running on parallel threads using different buckets• Modifications to the filesystem done in parallel in Hierarchical Waffinity
3) Amortize the cost of “turning the crank” for a free block4) Modularity improves code maintainability
§ Successfully used to develop a variety of allocation policies

White Alligator Performance
© 2016 NetApp, Inc. All rights reserved. 30
§ FlashPools achieves ~same throughput with 0.1X the latency§ Using fewer drives, replace many HDDs with a few SSDs§ Better $/iops, less shelf space, less maintenance, less power
70.187 67.4069.10
0.910
2
4
6
8
10
0
20
40
60
80
100
HDD SSD+HDD
Latency (ms)
Throughput (MB/s)
Throughput Latency

White Alligator CPU Scaling
© 2016 NetApp, Inc. All rights reserved. 31
§ Sequential Overwrite on 20-core server§ Every overwrite requires write allocation
§ Frontend = Policy, Backend = Infrastructure
7.759.35 10.35
17.39
0
5
10
15
20
0
500
1000
1500
2000
2500
Serial Frontend, Serial Backend
Serial Frontend, Parallel Backend
Parallel Frontend, Serial Backend
Parallel Frontend, Parallel Backend
Core Occupancy
Throughput (MB/sec)
Throughput Core Occupancy

Buffer Cache Management in WAFL
© 2016 NetApp, Inc. All rights reserved. --- NETAPP CONFIDENTIAL ---32

© 2016 NetApp, Inc. All rights reserved. 33
Summary
§ Problem Statement:§ Distributed buffer cache processing requires complex distributed heuristics.
§ Solution:§ Global buffer priority ordering, with parallel processing of key buffer cache operations.
§ From “Think Global, Act Local: A Buffer Cache Design for Global Ordering and Parallel Processing in the WAFL File System”§ ICPP 2016

Buffer Cache: Read from Disk
SAN Host
UNIXClient
WindowsClient
Console
HBA
NIC
SANService
NFSService
CIFSService
Storage
NetworkNetworkStack
Protocols
RAID
34
Memory Buffer / Cache
WAFL
NVRAM
Data block colors are not significant. NFS and CIFS can read the same cached data.

Buffer Cache: Read from Cache
SAN Host
UNIXClient
WindowsClient
RS-232
HBA
NIC
SANService
NFSService
CIFSService
NetworkNetworkStack
Protocols
RAID
Storage
35
NVRAM
Memory Buffer / Cache
WAFL
Data block colors are not significant. NFS and CIFS can read the same cached data.

WAFL Buffer Cache
Goal: Cache disk blocks in memory that are predicted to be needed in the near future to accelerate future accesses.
§ 7-level Multi-queue, LRU ordered
§ Prioritization based on type, frequency, and recency of access
§ Operations: Insertion, Touching, Scavenging, Aging
© 2016 NetApp, Inc. All rights reserved. 36
High Pri
Low Pri
Recycle Queues
Free Cache
Scavenging

Per-Affinity Buffer Cache (PABC)
§ For CPU scalability, recycle queues were replicated per affinity§ Buffers mapping to each affinity are managed together§ Allows buffer cache management to be performed in parallel with no locking
§ Distributed heuristics added to approximate global ordering
§ Distributed decision making created problems§ Often resulted in bad replacement decisions which hurt performance§ Created complicated code that was difficult to maintain
© 2016 NetApp, Inc. All rights reserved. 37
Affinity 1 Affinity 1 Affinity 2 Affinity n
High Pri
Low Pri

Global Recycle Queue (GRQ)
§ Objective: Global Ordering with Parallel processing
§ Organize buffers across all affinities in a single global queue§ Stage 1 Scavenging — “sorts” lowest priority buffers into affinity queues§ Stage 2 Scavenging — parallel execution of costly operations within the affinities
© 2016 NetApp, Inc. All rights reserved. 38
High PriorityBuffers
Low PriorityBuffers
Untouched buffers logically flow towards the scavenger
Touching promotes away from scavenger
Insert buffers at various pointsdepending on buffer importance
FreeCache
Global Recycle Queue Per-AffinityPer-AffinityQueuesPer-Affinity
Recycle Queues

Global Recycle Queue Set
© 2016 NetApp, Inc. All rights reserved. 39
§ Global queue is implemented as a set of smaller queues§ One spinlock per queue for MP safety§ Many short queues to reduce lock contention§ Buffers inserted at the same time are sprayed over a range of queues
Priority
Q1Q2
Q3Q4Q5
Q6
Q7
…Qn
Insert BuffersFrom All Affinities
GRQ
Buffers A, B, C, D, E, Fof same type inserted together

GRQ Performance Evaluation
§ Summary: GRQ performance on-par with PABC§ Even though PABC had been heavily optimized over a decade§ Ordering is achieved despite removal of code complexity
© 2016 NetApp, Inc. All rights reserved. 40
Experimental Platform:8 core48GB RAM

Workload Management
§ Goal: Provide QoS management to buffer cache usage§ Provide mechanism for upper and lower bounds on buffer cache usage§ No hard partitioning of buffers
§ Allocations§ Guarantee a portion of cache space for a workload§ No buffer scavenging until Allocation is exceeded§ Buffers are isolated on a dedicated Global Holding Queue
§ Soft Limits§ Prevent a workload from loading buffers so quickly that others’ are thrashed§ Offending workloads experience degraded service
§ i.e,. Its buffers are inserted at lower-priority queues
© 2016 NetApp, Inc. All rights reserved. 41

Workload Management: Allocations
§ Primary Workload: Random read with working set = 80% of RAM§ Allocation = 80% of memory
§ Interfering Workloads: Random read with working set > RAM size
© 2016 NetApp, Inc. All rights reserved. 42
Experimental Platform:8 core32 GB RAM
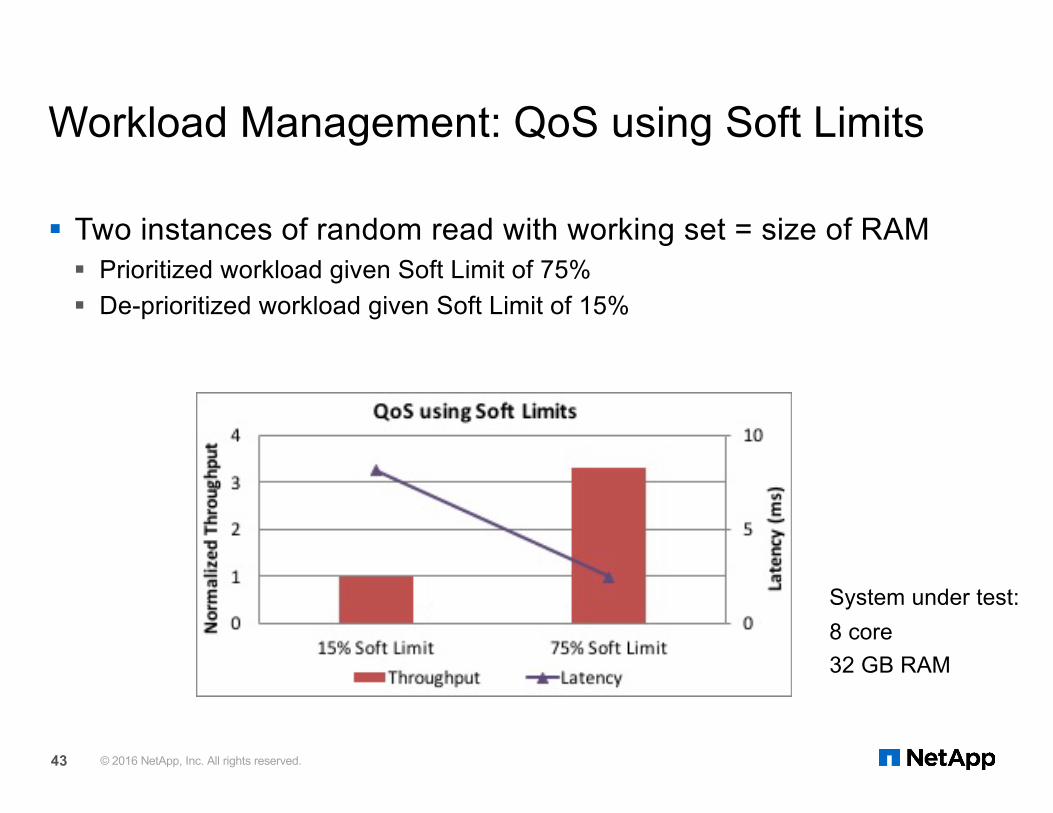
Workload Management: QoS using Soft Limits
§ Two instances of random read with working set = size of RAM § Prioritized workload given Soft Limit of 75%§ De-prioritized workload given Soft Limit of 15%
© 2016 NetApp, Inc. All rights reserved. 43
System under test:8 core32 GB RAM

Conclusions
§ Think Global, Act Local§ Global ordering of buffers§ Local (distributed) processing of buffers§ Achieved via a two stage buffer management algorithm
§ Architecture allowed for the removal of unmaintainable code
§ Introduced workload management capabilities to the buffer cache
§ GRQ has been adopted in several other areas of WAFL
© 2016 NetApp, Inc. All rights reserved. 44

Thank you.
© 2016 NetApp, Inc. All rights reserved45


















