
ÓPICOS VANZADOS REDES NEURONALES …ccc.inaoep.mx/~pgomez/cursos/IC-I/acetatos/ApProfundo.pdf ·...
71
C261-69 TÓPICOS AVANZADOS: REDES NEURONALES ARTIFICIALES INTRODUCCIÓN A APRENDIZAJE PROFUNDO Dra. Pilar Gómez Gil Coordinación de Computación INAOE Modificado: 08-Marzo-2018
Transcript of ÓPICOS VANZADOS REDES NEURONALES …ccc.inaoep.mx/~pgomez/cursos/IC-I/acetatos/ApProfundo.pdf ·...

C261-69 TÓPICOS AVANZADOS:
REDES NEURONALES ARTIFICIALES
INTRODUCCIÓN A APRENDIZAJE
PROFUNDO
Dra. Pilar Gómez Gil Coordinación de Computación INAOE
Modificado: 08-Marzo-2018

(c) P.G
óm
ez G
il, INA
OE
20
17
2
Yan LeCun. Photo-illustration: Randi Klett
“Most of the
knowledge in
the world in the
future is going
to be extracted
by machines
and will reside
in machines”
Yann LeCun,
Director of AI
Research, Facebook 1
1 “ The Five Tribes of Machine Learning (And What You Can Learn
from Each),” Pedro Domingos, Webminar produced by the Association
of Computing Machinery (ACM). Dec. 29, 2015

PÁGINA DEL GRUPO DE APRENDIZAJE PROFUNDO
DE LA CCC:
3
(c) P.G
óm
ez G
il, INA
OE
20
17
http://ccc.inaoep.mx/~pgomez/deep/

¿QUÉ ES APRENDIZAJE PROFUNDO? (1/2)
En el contexto de Inteligencia Artificial (IA),
“aprendizaje profundo” (Deep Learning o DL) se
refiere a la actividad automática de
adquisición de conocimiento, a través del uso
de máquinas que usan varios niveles para la
extracción.
El adjetivo “profundo” se aplica no en sí al
conocimiento adquirido, sino a la forma en que el
conocimiento se adquiere.
4
(c) P.G
óm
ez G
il, INA
OE
20
17

(c) P.G
óm
ez G
il, INA
OE
20
17
5

¿QUÉ ES APRENDIZAJE PROFUNDO? (2/2)
La gran ventaja de DL es que no requiere de una
definición “a mano” de las características que
identifican a los patrones que se buscan, sino que
automáticamente se generan dichas
características, manipulando datos crudos
Esto se lleva a cabo a través de construir
automáticamente características de alto nivel, a
través del uso de una gran cantidad de niveles
jerárquicos de extractores, dentro de un sistema
que aprende automáticamente.
6
(c) P.G
óm
ez G
il, INA
OE
20
17
Foto tomada de:
http://www.kodemaker.no/deeplearning/

(c) P.G
óm
ez G
il, INA
OE
20
17
7
(Goodfellow, 2016)

EL PROBLEMA DE CLASIFICAR
8
(c) P.G
óm
ez G
il, INA
OE
20
17
O
BJ
ET
O
CL
AS
ES
SENSADO MEDIDAS
ANALISIS
DE
CONTEXTO
VECTOR DE CARACTERÍSTICAS
DECISION
PRE-
PROCESAMIENTO
Y OBTENCIÓN DE
CARACTERÍSTICA
S
APRENDIZAJ
E
(Tao & Gonzalez ,1974)

RNA Y DL
DL permite que redes neuronales con varios niveles de neuronas aprendan a representar características, sin decirle cuáles son.
A este campo se le conoce como “aprendizaje de representaciones” (representational learning)
Estos modelos utilizan combinaciones de aprendizaje supervisado y no supervisado, en los diferentes niveles.
Las arquitecturas mas populares son:
Red profunda de convolución (convolutional Net)
Red de creencias profundas (deep-belief network)
Redes recurrentes de memoria corta y larga (long-short term memory, LSTM)
9
(c) P.G
óm
ez G
il, INA
OE
20
17

DEFINICIONES
10
(c) P.G
óm
ez G
il, INA
OE
20
17
Tomado de (Jiménez, 2016)
Y. Bengio, A. Courville y P. Vincent, «Representation Learning: A Review and New
Perspectives,» IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, pp. 1798-1828, Aug 2013

EL PROBLEMA FUNDAMENTAL DE
ASIGNACIÓN DE CRÉDITO
Este problema está relacionado con la complejidad de
determinar qué componentes de un sistema, y en que
manera, contribuyen al éxito o fracaso de éste1
DL engloba a un tipo de sistemas universales “resolvedores
de problemas” con estrategias de aprendizaje para
resolverlo
La principal diferencia entre sistemas de aprendizaje
“profundos” (deep) y “superficiales” (shallow) está en la
profundidad del camino que siguen para resolver el
“problema de la asignación de crédito.”
11
(c) P.G
óm
ez G
il, INA
OE
20
17
1 Minsky, M. L. (1963). Steps toward artificial intelligence. In E. A. Feigenbaum &
J. Feldman (Eds.), Computers And Thought (pp. 406-450). New York, NY: McGraw-Hill.

PRINCIPALES APLICACIONES DE DL
Reconocimiento de voz
Reconocimiento de imágenes
Detección de fraudes
Reconocimiento de caracteres manuscritos
Descubrimiento de componentes farmacéuticos
Procesamiento de lenguaje Natural
Clasificación sobre señales en el tiempo
12
(c) P.G
óm
ez G
il, INA
OE
20
17
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-444.

LAS RAÍCES DE “DEEP LEARNING”
13
(c) P.G
óm
ez G
il, INA
OE
20
17

EL NEOCOGNITRON DE FUKUSHIMA (1980)
1/2
14
(c) P.G
óm
ez G
il, INA
OE
20
17
Fukushima, K. (1980). Neocognitron: A self-organizing neural network model for a
mechanism of pattern recognition unaffected by shift in position. Biological cybernetics,
36(4), 193-202.
15
(c) P.G
óm
ez G
il, INA
OE
20
17

EL NEOCOGNITRON DE FUKUSHIMA
(1980)1 1/2
Podría considerarse la primera “red profunda”
Incorpora conceptos de neuro-fisiología
Introdujo a las redes neuronales convolucionales
con el concepto de campos receptivos
Gracias al uso de “replicación de pesos”, es decir,
a que los pesos se comparten en un mismo campo,
el número de parámetros a aprender por la red
disminuye considerablemente
Se entrena de forma no supervisada
16
(c) P.G
óm
ez G
il, INA
OE
20
17
1. Schmidhuber, Jürgen. "Deep learning in neural networks: An overview."
Neural Networks 61 (2015): 85-117.

PROCESANDO DATOS CON EL
NEOCOGNITRON (1980)
17
(c) P.G
óm
ez G
il, INA
OE
20
17
Fukushima, K. (1988). Neocognitron: A hierarchical neural network capable of
visual pattern recognition. Neural Networks, 1(2), 119-130.

EXTRAYENDO CARACTERÍSTICAS EN 1989
18
(c) P.G
óm
ez G
il, INA
OE
20
17
LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., & Jackel, L. D.
(1989). Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4),
541-551.

MI TESIS DE MAESTRÍA (1993) (1/2)
19
(c) P.G
óm
ez G
il, INA
OE
20
17
1991. “Recognition of Handwritten Letters using a Locally-Connected Back-propagation
Neural Network.” María del Pilar Gómez Gil. Master of Science Thesis, Department of
Computer Science, Texas Tech University.

MI TESIS DE MAESTRÍA (1993) (2/2)
20
(c) P.G
óm
ez G
il, INA
OE
20
17
1997. Gómez-Gil P, Ramírez-Cortés JM, Oldham W. “On handwritten character Recognition through Locally
connected structural neural networks.” Proceedings of the “Second Joint Mexico-US International Workshop
on Neural Networks and Neurocontrol Sian Ka’an ‘97,” Quintana Roo, México, August 1997. pp. 251 – 255

EXTRAYENDO CARACTERÍSTICAS ACTUALMENTE: DEEP
CONVOLUTIONAL NEURAL NETWORK
21
(c) P.G
óm
ez G
il, INA
OE
20
17
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-
444.

LA IDEA PRINCIPAL DE DL (GOODFELLOW, 2016)
22
(c) P.G
óm
ez G
il, INA
OE
20
17
I.Goodfellow, Y. Bengio and A. Courville. Deep Learning. Adaptive Computation and
Machine Learning Series. Cambridge, MA. The MIT Press, 2016
http://www.deeplearningbook.org

LA RED DE CONVOLUCION (1/)
23
(c) P.G
óm
ez G
il, INA
OE
20
17
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-
444.

LA RED DE CONVOLUCION
(2/)
Hay 4 ideas importantes: conexiones locales,
pesos compartidos, agrupamiento (pooling) y el
uso de varios niveles.
La arquitectura de CNN está hecha de varios
estados
Los primeros estados están formados de dos
tipos de niveles (layers): convolucionales y de
agrupamiento
24
(c) P.G
óm
ez G
il, INA
OE
20
17
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-
444.

NIVEL DE CONVOLUCIÓN
El trabajo del nivel de convolución es detectar
características locales
Las unidades del nivel de convolución están organizadas en
mapas de características, en los cuales cada unidad se
conecta a “parches” locales en los mapas de característics
del nivel anterior, a través de pesos, llamados “bancos de
filtros”
El resultado de esta suma se pasa a través de una no-
linealidad, como una “Rectified LinearUnit (ReLU):
f(z) = max(0,z)
Todas las unidades en el mapa de características
comparten el mismo banco de filtros
Diferentes mapas en el mismo nivel usan diferentes bancos
de filtros
25
(c) P.G
óm
ez G
il, INA
OE
20
17
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-
444.

RELU
26
(c) P.G
óm
ez G
il, INA
OE
20
17
I.Goodfellow, Y. Bengio and A. Courville. Deep Learning. Adaptive Computation and
Machine Learning Series. Cambridge, MA. The MIT Press, 2016
http://www.deeplearningbook.org

OTRAS FUNCIONES DE ACTIVACIÓN
Tangente hiperbólica
f(z) = (exp(z) − exp(−z))/(exp(z) + exp(−z))
ReLU (rectified linear Unit)
f(z) = max(0,z)
Función Logística:
f(z) = 1/(1 + exp(−z))
27
(c) P.G
óm
ez G
il, INA
OE
20
17

NIVEL DE AGRUPAMIENTO
El papel del nivel de agrupamiento (pooling) es combinar de
manera semántica varias características en una
Las posiciones de las características que representan los
conceptos pueden variar, entonces es necesario combinarlas de
alguna manera
Las unidades “pooling” típicas calculan el máximo de un parche
de unidades que representan un concepto
Los “poolings” vecinos están combinando características vecinas,
lo que va reduciendo la dimensión en la representación y creando
una invarianza a pequeños desplazamientos y distorsiones.
Dos o tres estados de convolución, no linealidades y poolings se
enciman, seguidos de mas niveles de convolución o completamente
conectados
Todos los pesos se entrenan con retro-propagación 28
(c) P.G
óm
ez G
il, INA
OE
20
17
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-
444.

ARQUITECTURA DE RED DE CONVOLUCIÓN
29
(c) P.G
óm
ez G
il, INA
OE
20
17
ℎ𝑖𝑗𝑘 = 𝜙(𝑊𝑖𝑗
𝑘 ∗ 𝑥𝑖𝑗 + 𝑏𝑘)
http://inspirehep.net/r
ecord/1252539/plots
Tomado de Jimenez Guarneros, M. Comentarios del artículo: “Aprendizaje
de representaciones en señales de EEG usando Redes Neuronales
Recurrentes-Convolucionales profundas” Seminario de DL, Junio 2016.

CAPA DE CONVOLUCIÓN [JIMENEZ 2016-B]
30
(c) P.G
óm
ez G
il, INA
OE
20
17
http://cs231n.github.io/convolutional-
networks/

CAPA DE MAX-POOLING [JIMENEZ 2016-B]
31
(c) P.G
óm
ez G
il, INA
OE
20
17
http://cs231n.github.io/convolutional-
networks/

LE-NET5 – CONVOLUTIONAL NEURAL
NETWORK [JIMENEZ 2016-B]
32
(c) P.G
óm
ez G
il, INA
OE
20
17
http://www.rsipvision.com/wp-content/uploads/2015/04/Slide7.png

AUTO-ENCODERS (GOODFELLOW, 2016)
Es un tipo de aprendizaje de representaciones
Está formado por la combinación de un
codificador (encoder) que convierte la entrada
auna representación diferente, y un decodificador
(decoder) que regresa dicha representación a su
formato original
La “representación” de puede diseñar de varias
maneras, y presenta propiedades útiles
33
(c) P.G
óm
ez G
il, INA
OE
20
17

PROCESANDO DATOS CON LA RED DE
CONVOLUCIÓN (2015)
34
(c) P.G
óm
ez G
il, INA
OE
20
17
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature,
521(7553), 436-444.
Imagen originalmente publicada en: Xu, K.,
Ba, J., Kiros, R., Cho, K., Courville, A.,
Salakhudinov, R., ... & Bengio, Y. (2015).
Show, Attend and Tell: Neural Image
Caption Generation with Visual Attention.
In Proceedings of The 32nd International
Conference on Machine Learning (pp. 2048-
2057)
http://arxiv.org/abs/1502.03044
(2014) .

“ZOOM-OUT” DE LA EXPLICACION…
35
(c) P.G
óm
ez G
il, INA
OE
20
17
1. Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., ... & Bengio, Y. (2015). Show,
Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of The 32nd
International Conference on Machine Learning (pp. 2048-2057) http://arxiv.org/abs/1502.03044
(2014) .
1.

TRANSFERENCIA DEL APRENDIZAJE
(TRANSFER LEARNING)
Una red entrenada con una colección de
imágenes grande se usa como punto inicial para
resolver un nuevo problema de clasificación o
detección.
Esta red pre-entrenada ya aprendió una serie de
características que pueden aplicarse a varios
tipos de imágenes, y este aprendizaje se “ajusta”
al nuevo problema.
La gran ventaja de este tipo de aprendizaje es
que el número de imágenes requeridas para
entrenar a la red se reduce. 36
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/help/vision/examples/object-
detection-using-deep-learning.html#zmw57dd0e574

EJEMPLO: DETECCIÓN DE BANDEROLAS DE
“ALTO” EN FOTOGRAFÍAS1
Utiliza a la red R-CNN (Regions with Convolution Neural
Network)2
El objetivo es identificar en una imagen, la región en donde
aparece una señal de alto.
Esta red solo procesa regiones que son probables de
contener a la región buscada, en vez de analizar todas las
posibles regiones
El sistema pre-entrena la red usando la base de datos
CIFAR-10, que contiene 50,000 imágenes
Solo requiere 41 imágenes de “altos” para entrenarse.
37
(c) P.G
óm
ez G
il, INA
OE
20
17
1. https://www.mathworks.com/help/vision/examples/object-detection-using
deep-learning.html#zmw57dd0e574
2. Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and
semantic segmentation." Proceedings of the IEEE conference on computer vision and
pattern recognition. 2014.

UNA IMAGEN DE CIFAR-10
38
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/help/vision/examples/object-
detection-using-deep-learning.html#zmw57dd0e574

PESOS APRENDIDOS POR R-CNN EN UNO
DE LOS NIVELES
39
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/help/vision/examples/object-detection-using-
deep-learning.html#zmw57dd0e574

IDENTIFICACIÓN DE LA BANDEROLA
40
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/help/vision/examples/object-detection-using-
deep-learning.html#zmw57dd0e574

EL PODER DEL CÓMPUTO ACTUAL ES LA
DIFERENCIA
41
(c) P.Gómez Gil, INAOE 2017
K SUPERCOMPUTER, RIKEN Advanced
Institute for Computational Science (AICS), Japan
http://www.datacenterknowledge.com/
top-10-supercomputers-illustrated-june-2012-continued/
http://www.wired.com/2012/03/ibm-watson/
IBM’S Watson
IBM Ble Gene / Q systems powering the
Fermi supercomputer at Cineca in Italy.

LABORATORIO NACIONAL DE
SUPERCÓMPUTO DEL SURESTE DE MÉXICO
42
(c) P.G
óm
ez G
il, INA
OE
20
17
http://www.conacytprensa.mx/index.php/tecnologia/tic/2723-lns-del-sureste-de-mexico-
un-centro-de-datos-de-clase-mundial
http://www.lns.buap.mx/

SE PUEDEN USAR APLICACIONES DE DL CON
EQUIPO DE ALTO DESEMPEÑO MAS PEQUEÑO
43
(c) P.G
óm
ez G
il, INA
OE
20
17
http://www.geforce.com/whats-new/articles/introducing-
the-geforce-gtx-680m-mobile-gpu
http://www.ztex.de/usb-fpga-1/usb-fpga-1.15x.e.html
Spartan 6 LX150 FPGA Board

APLICACIÓN EXITOSA A LA FECHA:
VERIFICACIÓN DE CARAS (1/2)
44
(c) P.G
óm
ez G
il, INA
OE
20
17
Y. Taigman, M. Yang, M. Ranzato and L. Wolf, “DeepFace: Closing the Gap to Human-Level
Performance in Face Verification," Computer Vision and Pattern Recognition (CVPR), 2014
IEEE Conference on, Columbus, OH, 2014, pp. 1701-1708.
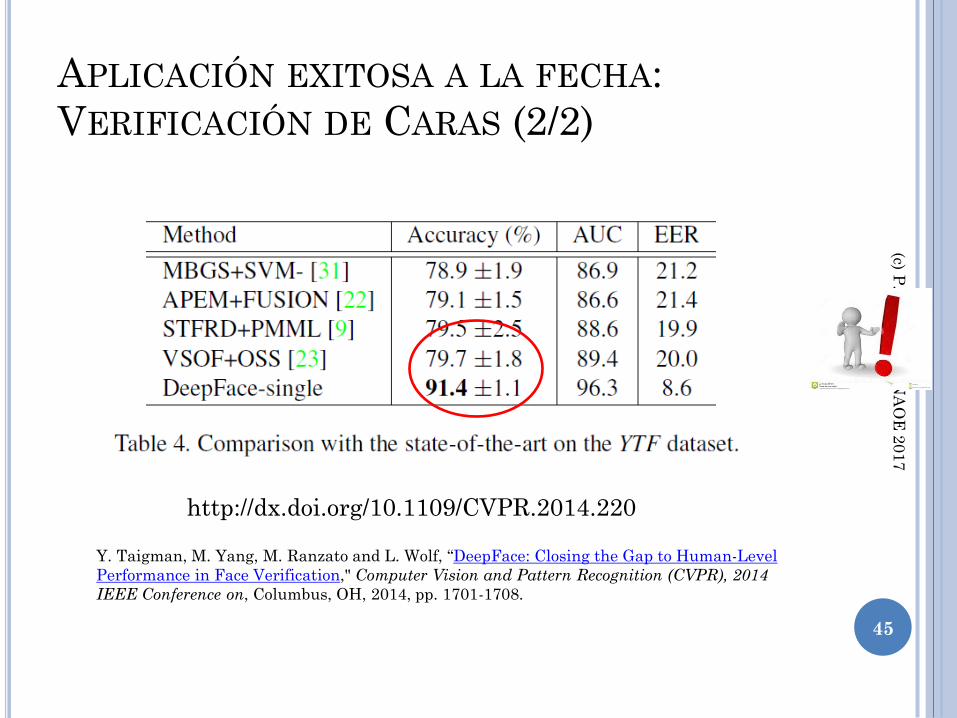
APLICACIÓN EXITOSA A LA FECHA:
VERIFICACIÓN DE CARAS (2/2)
45
(c) P.G
óm
ez G
il, INA
OE
20
17
Y. Taigman, M. Yang, M. Ranzato and L. Wolf, “DeepFace: Closing the Gap to Human-Level
Performance in Face Verification," Computer Vision and Pattern Recognition (CVPR), 2014
IEEE Conference on, Columbus, OH, 2014, pp. 1701-1708.
http://dx.doi.org/10.1109/CVPR.2014.220

CLASIFICACIÓN DE SERIES DE TIEMPO (1/2)
46
(c) P.G
óm
ez G
il, INA
OE
20
17
Bashivan, P., Rish, I., Yeasin, M., & Codella, N. (2015). Learning representations from
EEG with deep recurrent-convolutional neural networks. ICLR 2016 : International
Conference on Learning Representations 2016, https://arxiv.org/abs/1511.06448

CLASIFICACIÓN DE SERIES DE TIEMPO (2/2)
47
(c) P.G
óm
ez G
il, INA
OE
20
17
Zheng, Y., Liu, Q., Chen, E., Ge, Y., & Zhao, J. L. (2016). Exploiting multi-channels deep
convolutional neural networks for multivariate time series classification. Frontiers of
Computer Science, 10(1), 96-112.
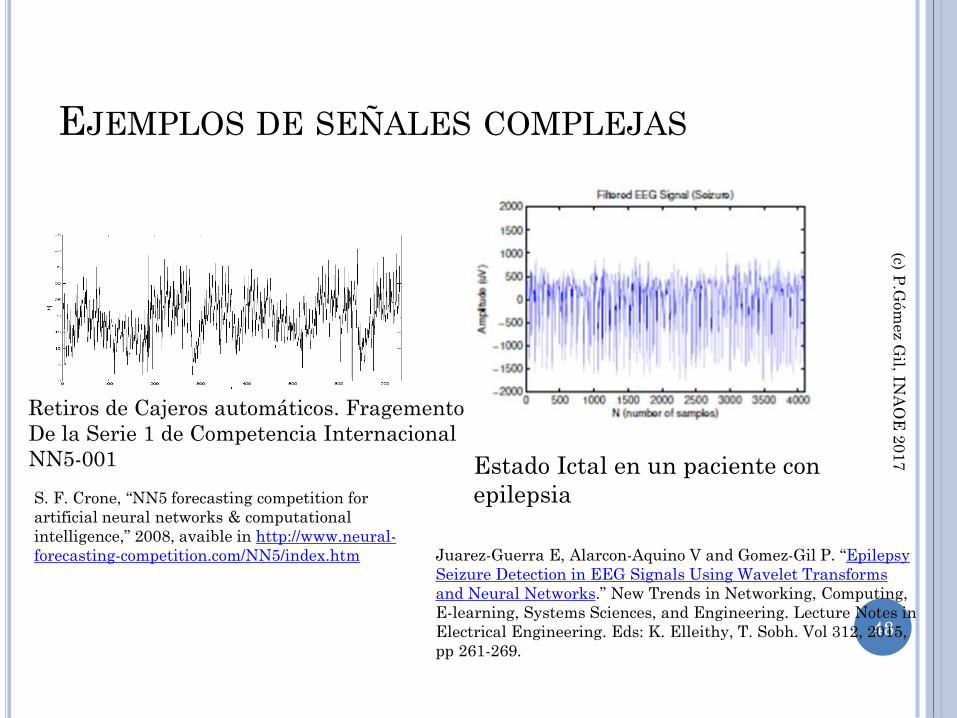
EJEMPLOS DE SEÑALES COMPLEJAS
48
(c) P.G
óm
ez G
il, INA
OE
20
17
Retiros de Cajeros automáticos. Fragemento
De la Serie 1 de Competencia Internacional
NN5-001
Estado Ictal en un paciente con
epilepsia
Juarez-Guerra E, Alarcon-Aquino V and Gomez-Gil P. “Epilepsy
Seizure Detection in EEG Signals Using Wavelet Transforms
and Neural Networks.” New Trends in Networking, Computing,
E-learning, Systems Sciences, and Engineering. Lecture Notes in
Electrical Engineering. Eds: K. Elleithy, T. Sobh. Vol 312, 2015,
pp 261-269.
S. F. Crone, “NN5 forecasting competition for
artificial neural networks & computational
intelligence,” 2008, avaible in http://www.neural-
forecasting-competition.com/NN5/index.htm

ALGUNAS DESVENTAJAS DE DL
En la mayoría de los casos se requieren grandes
cantidades de datos
Los algoritmos de aprendizaje aún necesitan
mejorarse
La migración/adecuación para programar
aplicaciones en paralelo puede ser tediosa
El porcentaje de éxito obtenido aún es bajo para
poder usarse en muchas aplicaciones prácticas,
pero va mejorando
Puede ser que se identifiquen patrones que no
son útiles 49
(c) P.G
óm
ez G
il, INA
OE
20
17

LOS SISTEMAS ENCUENTRAN LO QUE
APRENDIERON ANTES - GOOGLE DEEP DREAM
50
(c) P.G
óm
ez G
il, INA
OE
20
17
Imagen generada usando
http://deepdreamgenerator.com/
Puerto Escondido, Oaxaca

UNA PLAYA DE PUERTO ESCONDIDO
PROCESADA CON DEEP DREAM
51
(c) P.G
óm
ez G
il, INA
OE
20
17
Imagen generada usando
http://deepdreamgenerator.com/

FUTURO DE DL
DL y big-data van de la mano
Esta tecnología aún no está madura, pero está
teniendo avances muy rápidos, y pronto se verá
reflejada en otras aplicaciones
El futuro de DL, según Yan LeCun1 gira
alrededor de:
Aprendizaje no supervisado
Redes Neuronales Recurrentes
Entendimiento de Lenguaje Natural
Combinación de aprendizaje de representaciones con
razonamiento complejo
52
(c) P.G
óm
ez G
il, INA
OE
20
17
1. LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature,
521(7553), 436-444.

LA RED LSTM
Es un modelo recurrente que busca resolver el
problema de “gradiente desvanecido” el cual se
refiere a que el error de retro-propagado se
“desaparece” rápidamente en aplicaciones
recurrentes, después de varios pasos en las redes
recurrentes
La arquitectura de LSTM está basada en “celdas
de memoria”
53
(c) P.G
óm
ez G
il, INA
OE
20
17
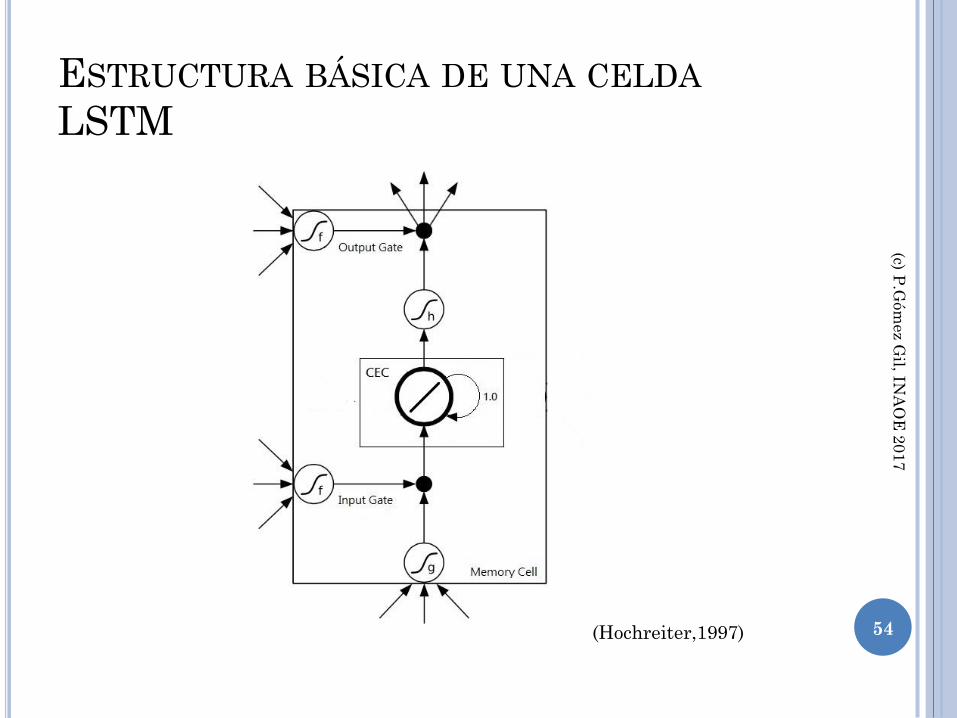
ESTRUCTURA BÁSICA DE UNA CELDA
LSTM
(Hochreiter,1997) 54
(c) P.G
óm
ez G
il, INA
OE
20
17

THE LSTM NETWORK
LSTM ha mostrado buenos resultados para
aplicaciones en:
Reconocimiento de escritura manuscrita (Graves,
2009)
Etiquetado secuencial (Graves, 2013)
Reconocimiento de voz (Sak,2015)
55
(c) P.G
óm
ez G
il, INA
OE
20
17
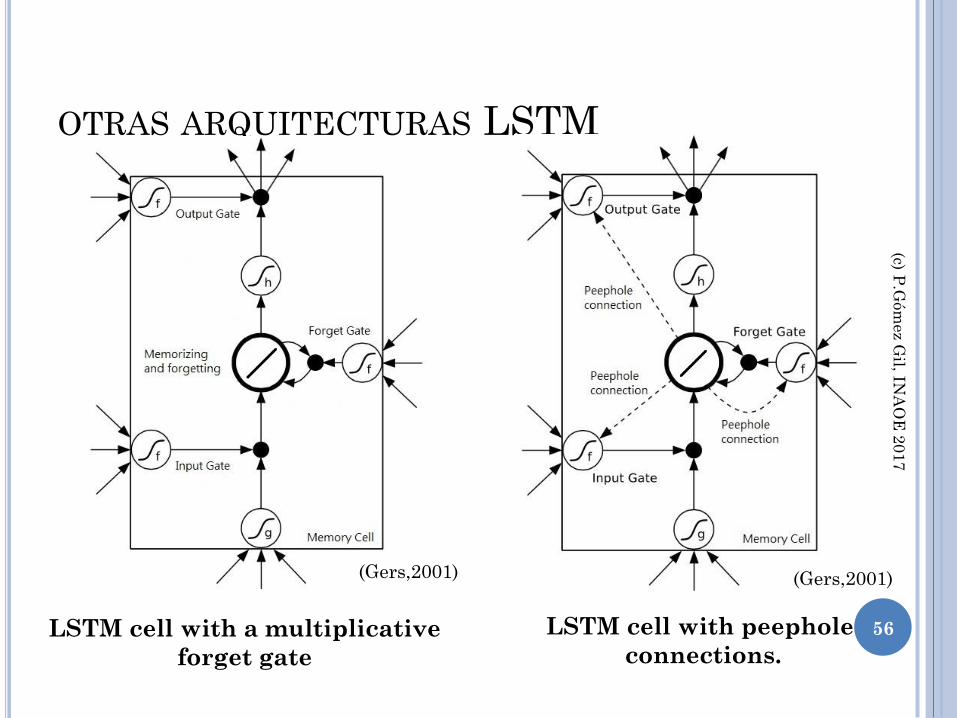
OTRAS ARQUITECTURAS LSTM
LSTM cell with a multiplicative
forget gate
LSTM cell with peephole
connections.
(Gers,2001) (Gers,2001)
56
(c) P.G
óm
ez G
il, INA
OE
20
17
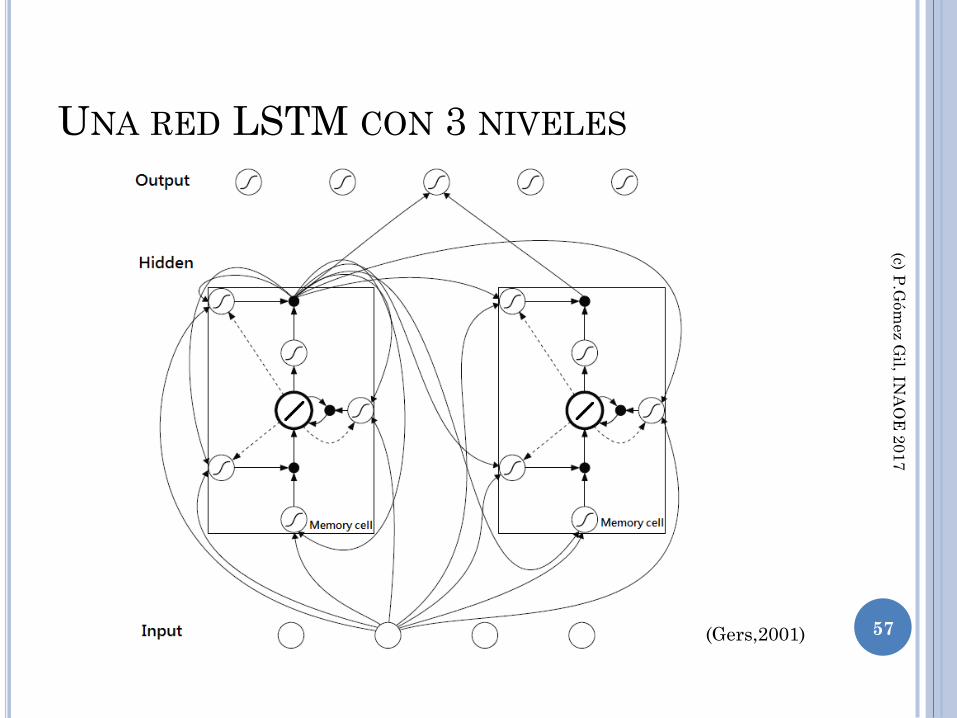
UNA RED LSTM CON 3 NIVELES
(Gers,2001) 57
(c) P.G
óm
ez G
il, INA
OE
20
17

EJEMPLO DE USO DE CNN PROFUNDA
58
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/company/newsletters/articles/deep-
learning-for-computer-vision-with-matlab.html

DL PARA VISION COMPUTACIONAL EN
MATLAB
Se utiliza para detectar objetos de interés y clasificar
El objetivo es entrenar un algoritmo para detectar una
mascota en un video y decir si es un perro o un gato
Usa el clasificador pre-entrenado CNN disponible en
formato deMatlab, llamado AlexNet, para extraer
características discriminativas de la imágenes, disponible
en:
http://www.vlfeat.org/matconvnet/models/beta16/
imagenet-caffe-alex.mat
La red se descarga usando el objeto SeriesNetwork de
Neural Network Toolbox
59
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/company/newsletters/articles/deep-
learning-for-computer-vision-with-matlab.html

ARQUITECTURA DE LA RED CNN DEL
EJEMPLO (OBJETO SERIESNETWORK
60
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/company/newsletters/articles/deep-
learning-for-computer-vision-with-matlab.html

ARQUITECTURA GENERAL DEL SISTEMA
61
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/company/newsletters/articles/deep-
learning-for-computer-vision-with-matlab.html

EXTRACCIÓN DE CARACTERÍSTICAS
AlexNet utiliza imágenes de 227x227 pixeles, por
lo que hay que escalar las imágenes obtenidas
Se extraen las "características" del nivel de la red
CNN fc7, estas alimentan a un clasificador SVM
62
(c) P.G
óm
ez G
il, INA
OE
20
17

63
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/company/newsletters/articles/deep-
learning-for-computer-vision-with-matlab.html

IDENTIFICACIÓN DEL ROI
Para identificar el objeto de interés en el video
utilizan la técnica de "flujo óptico"
Con la información de que pixeles se están
moviendo, obtiene la región de interés y esa
imagen es clasificada por el SVM
64
(c) P.G
óm
ez G
il, INA
OE
20
17

65
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/company/newsletters/articles/deep-
learning-for-computer-vision-with-matlab.html

EJEMPLO EXITOSO DE LA CLASIFICACIÓN
66
(c) P.G
óm
ez G
il, INA
OE
20
17
https://www.mathworks.com/company/newsletters/articles/deep-
learning-for-computer-vision-with-matlab.html

UNA APLICACIÓN INTERESANTE DE
CLASIFICACIÓN TEMPORAL
67
(c) P.G
óm
ez G
il, INA
OE
20
17
Ver: INAOE deep learning interest group – Talks – No. 6

(c) P.G
óm
ez G
il, INA
OE
20
17
68
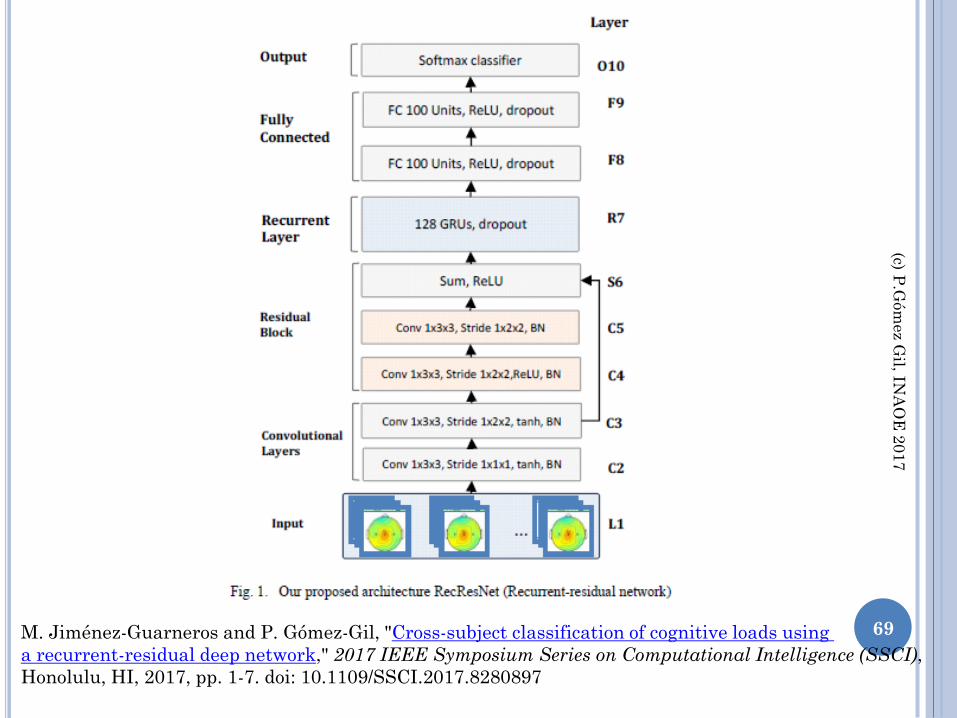
(c) P.G
óm
ez G
il, INA
OE
20
17
69 M. Jiménez-Guarneros and P. Gómez-Gil, "Cross-subject classification of cognitive loads using
a recurrent-residual deep network," 2017 IEEE Symposium Series on Computational Intelligence (SSCI),
Honolulu, HI, 2017, pp. 1-7. doi: 10.1109/SSCI.2017.8280897

70
EJEMPLOS DE DETECCIÓN AUTOMÁTICA DE LA
REGIÓN MAMARIA EN TOMOGRAFÍAS USANDO R-CNN
\Eval_Pru_Frontal_L2Regularization(0004)\Eval_Pru_Frontal2C1
Los rectángulos negros
representan zonas identificadas
inicialmente,
y cubiertas para identificar la
segunda zona
Reynoso Armenta, DM. “Diagnosis of breast cancer through the processing pf
thermographic images and neural networks” Master thesis in Optics, INAOE 2017
http://inaoe.repositorioinstitucional.mx/jspui/handle/1009/856
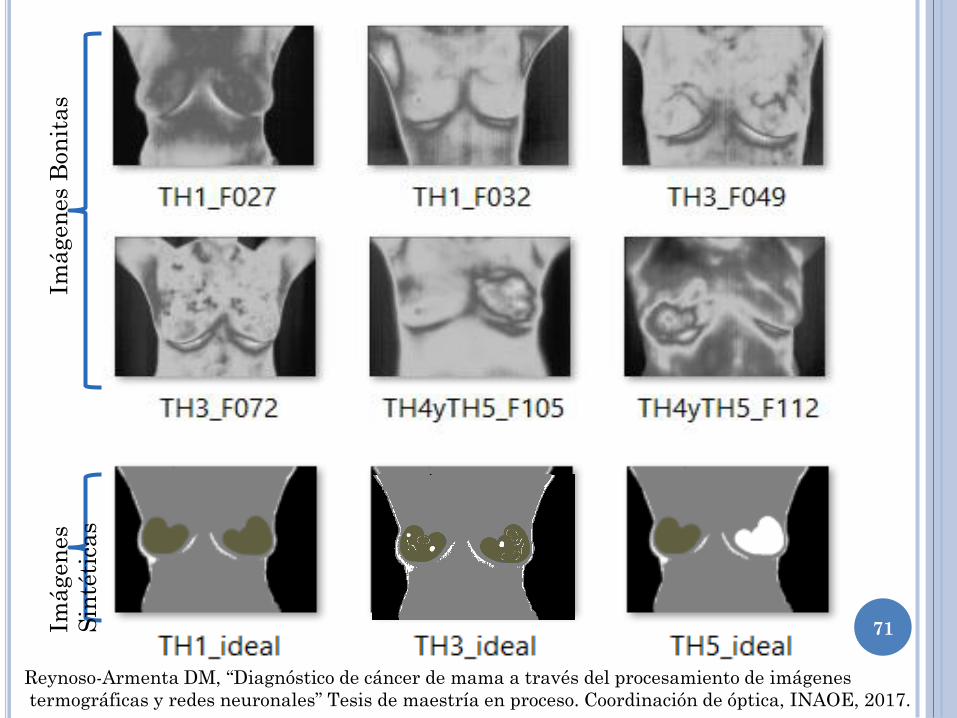
Imágen
es
Bon
itas
Imágen
es
Sin
téti
cas
71
Reynoso-Armenta DM, “Diagnóstico de cáncer de mama a través del procesamiento de imágenes
termográficas y redes neuronales” Tesis de maestría en proceso. Coordinación de óptica, INAOE, 2017.


















