In Pursuit of Complete Visibility within Cloud Foundry (Cloud Foundry Summit 2014)
Upload
alpine-dataCategory
view
151download
0
Operationalizing Data Science using Cloud Foundry Alpine Data Lawrence Spracklen VPE

2
Alpine Data

3
Operationalization
• What happens after the models are created? • How does the business benefit from the
insights? • Operationalization is frequently the weak link – Operationalizing PowerPoint? – Hand rolled scoring flows?

4
Barriers to Model Ops
• Scoring often performed on a different data source to training
• Batch training versus RT/stream scoring • How frequently are models updated? • How is performance monitored?

5
Define Act
Transform Deploy
Model
Business Leader Employees and Customers
Chorus 6
The Chorus Process

6
Turn-key solutions Train models
Coordinate Govern Deploy
RESTful Scoring engines

7
Pivotal BDS
• Provides support for high-performance SQL on both Hadoop and traditional data warehouses – HDB/HAWQ and GreenPlum
• Alpine supports SQL & MADlib accelerated machine learning algorithms on both HAWQ and GPDB
• Alpine models trained on HAWQ can be scored on GPDB and vice versa

8
Cloud Foundry (CF)
• Models trained on HAWQ or GPDB may not be scored against these systems – May not use the Hadoop cluster at all
• Need standalone scoring support – Readily deployed, maintained and scaled to meet the
requirements of specific customers • CF provides an elegant way to deploy scalable
scoring engines – Across a variety of public and private clouds and datacenters
• Require execution framework agnostic way to specify models

9
PMML
• XML based predictive model interchange format – Created in 1998 – Version 4.3 just released
• Good for specifying many common model types • Limited support for complex data preprocessing
– Can require companion scripts/code • Broad PMML export support • Limited import support

10
Turn-key model updates
Conditionally push model to Cloud Foundary Scoring engine

11
Turnkey Model Ops 1) Launch CF scoring engine 2) Configure export 3) Score data
Curl –X POST …

12
PFA
• Portable Format for analytics is the JSON-based successor to PMML – Version 0.8.1 available
• Significant flexibility in encapsulating complex data pre- and post-processing
13
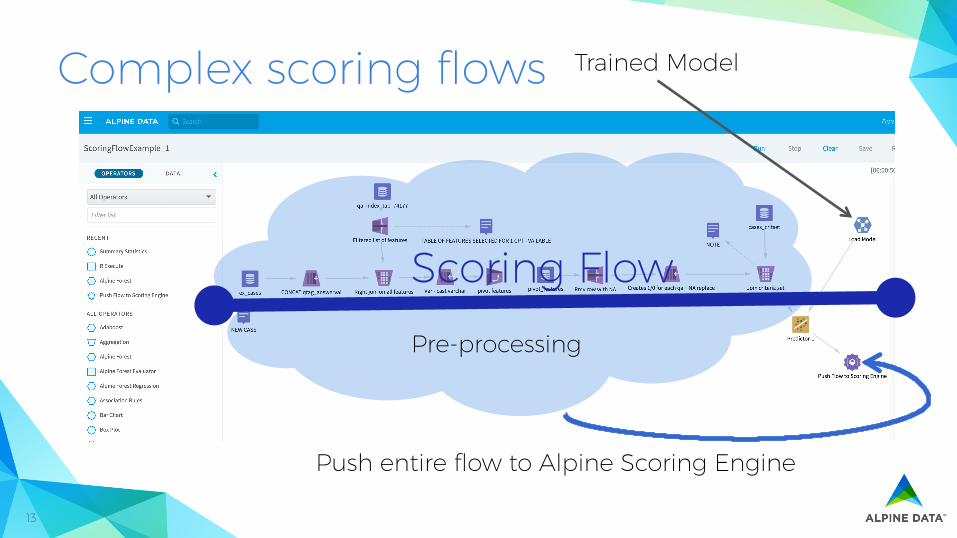
Complex scoring flows
Push entire flow to Alpine Scoring Engine
Trained Model
Pre-processing
Scoring Flow

14
PFA Support
• Not only model operators need to export PFA • Process entire DAG from raw data input to final
model output – Synthetize PFA doc to represent the flow
• PFA is capable of representing many key operations – Much richer than PMML
• Provides support for supplemental info to be leveraged by the scoring flows

15
Conclusions
• Operationalization of Data Science findings often overlooked
• Need easy model deployment to ensure maximum impact
• PFA makes it much simpler to deploy complex scoring flows
• Pivotal + Alpine Chorus provide turn-key model operationalization support

Additional information
18
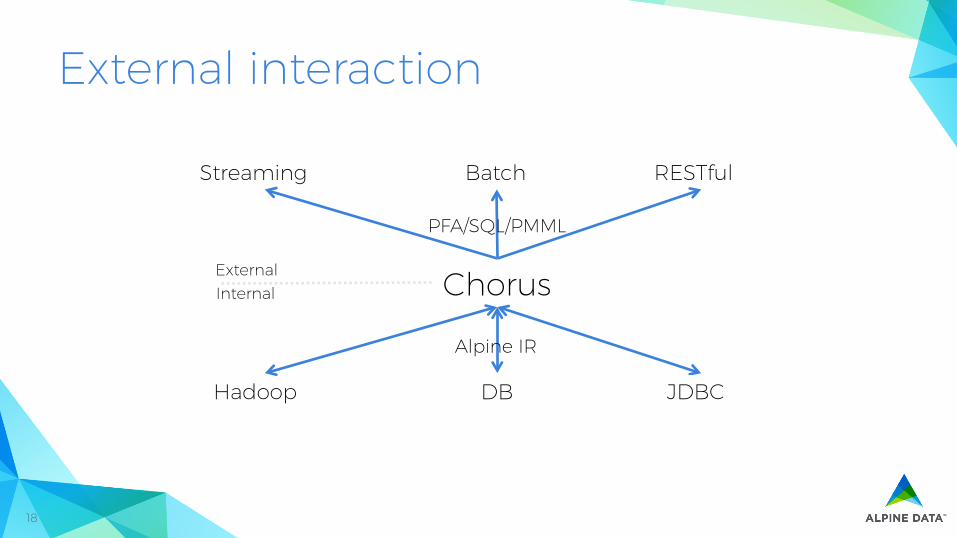
External interaction
Streaming RESTful Batch
Hadoop DB
Chorus
Alpine IR
JDBC
PFA/SQL/PMML
Internal External

19
Model lifecycles
Sources
Stores
Models
Engines
Apps
Actions