
On The Development of A Metric for Quality of Information Content over Anonymised Data Sets
30
1 © Nokia 2016 On The Development of A Metric for Quality of Information Content over Anonymised Data Sets Public Ian Oliver, Yoan Miche Security Team, Bell Labs, Finland 8 September 2016 Quatic2016, Lisbon
-
Upload
ian-oliver -
Category
Technology
-
view
536 -
download
0
Transcript of On The Development of A Metric for Quality of Information Content over Anonymised Data Sets

1 © Nokia 2016
On The Development of A Metric for Quality of Information Content over Anonymised Data Sets
Public
Ian Oliver, Yoan Miche
Security Team, Bell Labs, Finland
8 September 2016
Quatic2016, Lisbon

2 © Nokia 2016
Introduction
Data collection is ubiquitous
DataCollection
CellID->Location
DataStorage
OperatorPrivacy
Preprocessing
Extraction Hashing
FileStorage
RawData
Processing &Enrichment
External Data
ExternalCross-
referencing
Atomic Data
Aggregation/Report
Generation
CustomerReception
ReportStorage
<<data subject>>Customer

3 © Nokia 2016
Introduction
Data collection is ubiquitous
Privacy laws:GDPR, ePrivacy, Telecommunications, Banking, Medical

4 © Nokia 2016
Introduction
Data collection is ubiquitous
Privacy laws:GDPR, ePrivacy, Telecommunications, Banking, Medical
Business needs:High quality/fidelity data, information content

5 © Nokia 2016
Introduction
Data collection is ubiquitous
Privacy laws:GDPR, ePrivacy, Telecommunications, Banking, Medical
Business needs:High quality/fidelity data, information content
Technical Solutions:Anonymisation

6 © Nokia 2016
Case Study
Telecommunications Switching DataSubscriber IdentifierBTS LocationTime StampEvent : { cell handover, subscriber attach/detach, UE loss, ... }
ProcessSubscriber ID removal/obfuscationTrack reconstruction ( + Noise addition )Aggregation ( + Noise addition )Outlier removal
Prove: final aggregated data set can not be used to ”easily” identify subscribersNB: subscribers = humans (sometimes cats and dogs too)

7 © Nokia 2016
Case Study
DataCollection
CellID->Location
DataStorage
OperatorPrivacy
Preprocessing
Extraction Hashing
FileStorage
RawData
Processing &Enrichment
External Data
ExternalCross-
referencing
Atomic Data
Aggregation/Report
Generation
CustomerReception
ReportStorage
<<data subject>>Customer
increasing level of anonymisation...

8 © Nokia 2016
Case Study
DataCollection
CellID->Location
DataStorage
OperatorPrivacy
Preprocessing
Extraction Hashing
FileStorage
RawData
Processing &Enrichment
External Data
ExternalCross-
referencing
Atomic Data
Aggregation/Report
Generation
CustomerReception
ReportStorage
<<data subject>>Customer
must not/never be reidentified
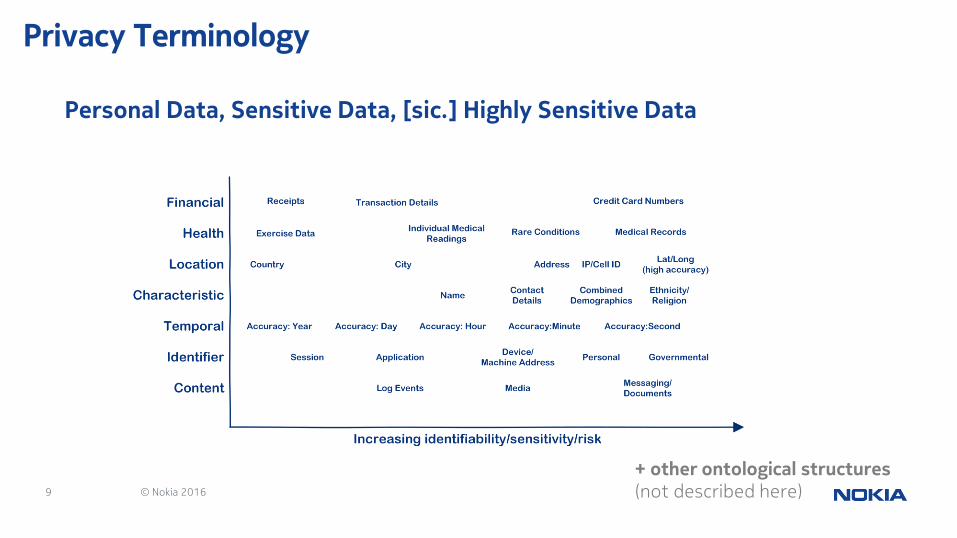
9 © Nokia 2016
Privacy Terminology
Personal Data, Sensitive Data, [sic.] Highly Sensitive Data
+ other ontological structures(not described here)

10 © Nokia 2016
Anonymisation
Supressionk-Anon, l-diversity, t-closenessDifferential Privacy
Identifier Regeneration/Recycling
HashingEncryption

11 © Nokia 2016
Challenge(s)
1. Given any data set how do we prove it has been [sufficiently] anonymised?
2. Given any [sufficiently] anonymised data set how do we prove that it can not be de-anonymised?

12 © Nokia 2016
The Privacy Machine
DataCollection
CellID->Location
DataStorage
OperatorPrivacy
Preprocessing
Extraction Hashing
FileStorage
RawData
Processing &Enrichment
External Data
ExternalCross-
referencing
Atomic Data
Aggregation/Report
Generation
CustomerReception
ReportStorage
<<data subject>>Customer
Is the original recoverable to some degree from the
anonymised set?
No
Yes
DataCollection
CellID->Location
DataStorage
OperatorPrivacy
Preprocessing
Extraction Hashing
FileStorage
RawData
Processing &Enrichment
External Data
ExternalCross-
referencing
Atomic Data
Aggregation/Report
Generation
CustomerReception
ReportStorage
<<data subject>>Customer
OriginalData Set
AnonymisedData Set
Privacy Oracle Machine (TM)

13 © Nokia 2016
The Privacy Machine
DataCollection
CellID->Location
DataStorage
OperatorPrivacy
Preprocessing
Extraction Hashing
FileStorage
RawData
Processing &Enrichment
External Data
ExternalCross-
referencing
Atomic Data
Aggregation/Report
Generation
CustomerReception
ReportStorage
<<data subject>>Customer
Is the original recoverable to some degree from the
anonymised set?
No
Yes
DataCollection
CellID->Location
DataStorage
OperatorPrivacy
Preprocessing
Extraction Hashing
FileStorage
RawData
Processing &Enrichment
External Data
ExternalCross-
referencing
Atomic Data
Aggregation/Report
Generation
CustomerReception
ReportStorage
<<data subject>>Customer
OriginalData Set
AnonymisedData Set
Privacy Oracle Machine (TM)
This result makes privacy lawyers
happy:
”compliance”

14 © Nokia 2016
Challenge(s)
1. Given any data set how do we prove it has been [sufficiently] anonymised?
2. Given any [sufficiently] anonymised data set how do we prove that it can not be de-anonymised?
3. What does ’sufficiently’ mean?
4. Automation (see points 1 to 3 above)

15 © Nokia 2016
Mutual Information
Better Metric than Information Entropy
DataSet -> Matrix of Tensors
Each cell in the matrix is a measure of correlation of two fields
Principal Component Analysis / Eigenvectors to find important correlations over the set as a whole
Extension: DataSet2 -> Measure of Correlation between data sets

16 © Nokia 2016
Mutual Information Under Anonymisation

17 © Nokia 2016
Theory
Learn to classify which data points correspond to unique or small set of subscribers

18 © Nokia 2016
Theory
h = differential privacy function with suitable values of \Delta f and \epsilon

19 © Nokia 2016
TheoryDoes a sufficiently deanonymising function exist?

20 © Nokia 2016
Theory
Topologicial Stretching

21 © Nokia 2016
Questions
What is relationship between the anonymisation function and the amount of deformation of the underlying topological space?
Can we calculate/learn the required deformation and thus properties of the anonymisation function (\delta F,\epsilon) Deformation?
Can we then apply this to other data sets?

22 © Nokia 2016
Answer
Yes.

23 © Nokia 2016
Answer
Yes.
For a ’sufficient’ definition of ‘yes’

24 © Nokia 2016
Questions
What is relationship between the anonymisation function and the amount of deformation of the underlying topological space?
For non-causal data, the deformation appears continuous
Can we calculate/learn the required deformation and thus properties of the anonymisation function (\delta F,\epsilon) Deformation?
Yes, see above
Can we then apply this to other data sets?
Yes, but ML requires metricisable data, some metrics are ’nasty’

25 © Nokia 2016
Preliminary Results
Data sets (telecoms swtiching data), c. 1m-10m data pointsDiff priv function applied to time and location, ids suppressed
Recovery possible (>90% accuracy) with non causal data (location) even with small \epsilon (<0.01), \delta F doesn’t appear to have an effect unless large
becomes possible to recover the anonymisation function properties and apply to other anonymised data sets
Recovery extremely difficult with causal data (time) even with large \epsilon

26 © Nokia 2016
Implications
Recovery possible (>90% accuracy) with non causal data (location) even with small \epsilon (<0.01), \delta F doesn’t appear to have an effect unless large
Even with highly anonymised data sets, reconstruction can be learnt and applied to other (similarly) anonymised data sets
ie: we can learn what anonymisation took place and attempt to reverse it
Puts significant limits on data usage in telecommunications situations
Decreases the usability of anonymised data setscommercialisation, limits of legal compliance

27 © Nokia 2016
Next Steps
Larger data sets: 240,000,000,000 data points
Provide better values for \epsilon and \delta F for given contexts
Improving the recovery algorithm
extremely CPU and Memory dependentgood news for supercomputer/GPU manufacturers though...
Currently not very scalable (good news for privacy advocates)

28 © Nokia 2016
New Problems
risk, priv and use are horribly non-lineartrade-off between sufficient anonymisation and usability

29 © Nokia 2016
Conclusions
Anonymisation is [mathematically] hardmetrics are not simple numbersn-dimensional metric spaces, non-linearity, non-Euclidean
”Sufficient” means: Not recoverable, but no usable dataprivacy becomes an optimisation problem...or hyperplanes are fun
Differential Privacy best applied when causality is ”attacked”
Underlying theory needs to be better developedThe mathematics of privacy is ”horrible”
we have work to doAny metric is hard, good metrics are nigh on impossible



















