
On Availability of Intermediate Data in Cloud Computations Steven Y. Ko, Imranul Hoque, Brian Cho,...
32
On Availability of Intermediate Data in Cloud Computations Steven Y. Ko , Imranul Hoque, Brian Cho, and Indranil Gupta Distributed Protocols Research Group (DPRG) University of Illinois at Urbana-Champaign
-
Upload
felix-haynes -
Category
Documents
-
view
214 -
download
0
Transcript of On Availability of Intermediate Data in Cloud Computations Steven Y. Ko, Imranul Hoque, Brian Cho,...

On Availability of Intermediate Data in Cloud Computations
Steven Y. Ko,Imranul Hoque,Brian Cho, and Indranil Gupta
Distributed Protocols Research Group (DPRG)University of Illinois at Urbana-Champaign

2
Our PositionIntermediate data as a first-class
citizen for dataflow programming frameworks in clouds

3
Our PositionIntermediate data as a first-class
citizen for dataflow programming frameworks in clouds◦Dataflow programming frameworks

4
Our PositionIntermediate data as a first-class
citizen for dataflow programming frameworks in clouds◦Dataflow programming frameworks◦The importance of intermediate data

5
Our PositionIntermediate data as a first-class
citizen for dataflow programming frameworks in clouds◦Dataflow programming frameworks◦The importance of intermediate data◦Outline of a solution

6
Our PositionIntermediate data as a first-class
citizen for dataflow programming frameworks in clouds◦Dataflow programming frameworks◦The importance of intermediate data◦Outline of a solution
This talk◦Builds up the case◦Emphasizes the need, not the solution

7
Dataflow Programming FrameworksRuntime systems that execute
dataflow programs◦MapReduce (Hadoop), Pig, Hive, etc.◦Gaining popularity for massive-scale
data processing◦Distributed and parallel execution on
clustersA dataflow program consists of
◦Multi-stage computation◦Communication patterns between stages

8
Example 1: MapReduceTwo-stage computation with all-to-all
comm.◦ Google introduced, Yahoo! open-sourced
(Hadoop)◦ Two functions – Map and Reduce – supplied
by a programmer◦ Massively parallel execution of Map and
ReduceStage 1: Map
Stage 2: Reduce
Shuffle (all-to-all)

9
Example 2: Pig and HivePig from Yahoo! & Hive from
FacebookBuilt atop MapReduceDeclarative, SQL-style languagesAutomatic generation &
execution of multiple MapReduce jobs

10
Example 2: Pig and HiveMulti-stage with either all-to-all
or 1-to-1
Stage 1: Map
Stage 2: Reduce
Stage 3: Map
Stage 4: Reduce
Shuffle (all-to-all)
1-to-1 comm.

11
Usage

12
UsageGoogle (MapReduce)
◦ Indexing: a chain of 24 MapReduce jobs◦ ~200K jobs processing 50PB/month (in 2006)
Yahoo! (Hadoop + Pig)◦ WebMap: a chain of 100 MapReduce jobs
Facebook (Hadoop + Hive)◦ ~300TB total, adding 2TB/day (in 2008)◦ 3K jobs processing 55TB/day
Amazon◦ Elastic MapReduce service (pay-as-you-go)
Academic clouds◦ Google-IBM Cluster at UW (Hadoop service)◦ CCT at UIUC (Hadoop & Pig service)

13
One Common CharacteristicIntermediate data
◦Intermediate data? data between stages
Similarities to traditional intermediate data◦E.g., .o files◦Critical to produce the final output◦Short-lived, written-once and read-
once, & used-immediately

14
One Common CharacteristicIntermediate data
◦Written-locally & read-remotely◦Possibly very large amount of
intermediate data (depending on the workload, though)
◦Computational barrier
Stage 1: Map
Stage 2: Reduce
Computational Barrier
15
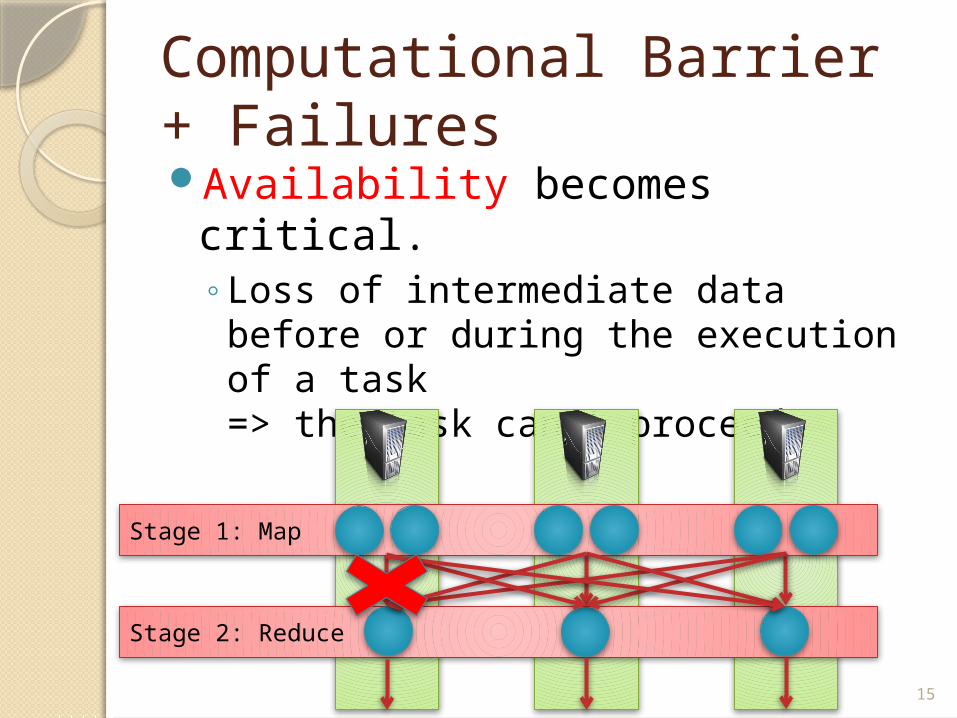
Computational Barrier + FailuresAvailability becomes critical.
◦Loss of intermediate data before or during the execution of a task=> the task can’t proceed
Stage 1: Map
Stage 2: Reduce

16
Current SolutionStore locally & re-generate when
lost◦Re-run affected map & reduce tasks◦No support from a storage system
Assumption: re-generation is cheap and easy
Stage 1: Map
Stage 2: Reduce

17
Hadoop ExperimentEmulab setting (for all plots in
this talk)◦20 machines sorting 36GB◦4 LANs and a core switch (all 100
Mbps)Normal execution: Map–Shuffle–
Reduce
MapShuffleReduc
e

18
Hadoop Experiment1 failure after Map
◦Re-execution of Map-Shuffle-Reduce~33% increase in completion
time
MapShuffleReduc
eMap
Shuffle
Reduce

19
Re-Generation for Multi-StageCascaded re-execution:
expensive
Stage 1: Map
Stage 2: Reduce
Stage 3: Map
Stage 4: Reduce

20
Importance of Intermediate DataWhy?
◦Critical for execution (barrier)◦When lost, very costly
Current systems handle it themselves.◦Re-generate when lost: can lead to
expensive cascaded re-execution◦No support from the storage
We believe the storage is the right abstraction, not the dataflow frameworks.

21
Our PositionIntermediate data as a first-class
citizen for dataflow programming frameworks in cloudsDataflow programming frameworksThe importance of intermediate data◦Outline of a solution
Why is storage the right abstraction? Challenges Research directions
22
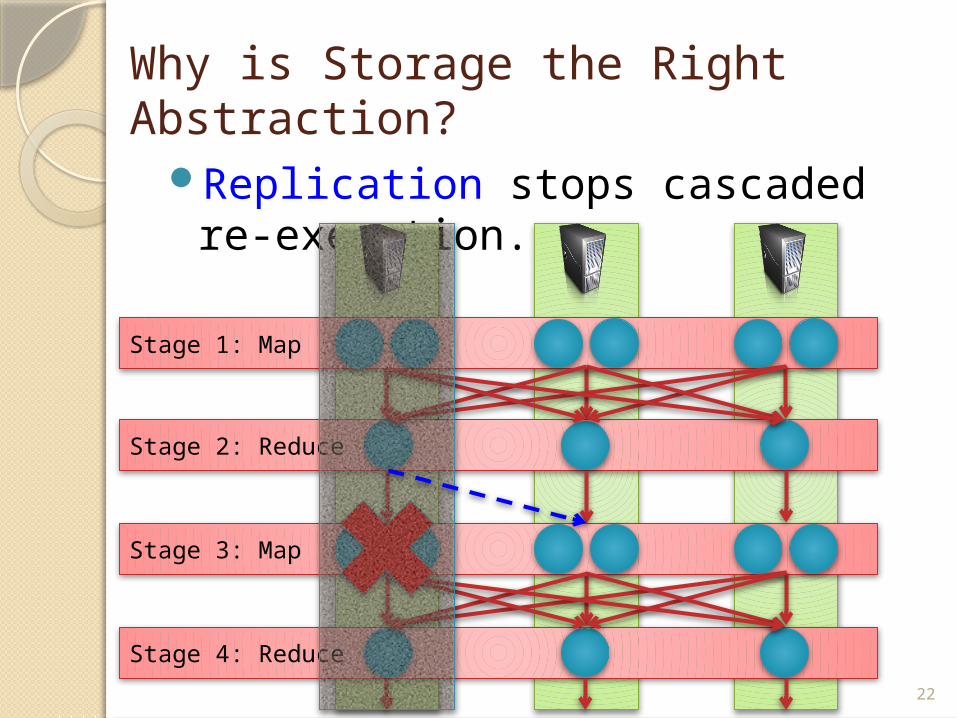
Why is Storage the Right Abstraction?
Replication stops cascaded re-execution.
Stage 1: Map
Stage 2: Reduce
Stage 3: Map
Stage 4: Reduce

23
So, Are We Done?No!Challenge: minimal interference
◦Network is heavily utilized during Shuffle.◦Replication requires network transmission too.◦Minimizing interference is critical for the
overall job completion time.Any existing approaches?
◦HDFS (Hadoop’s default file system): much interference (next slide)
◦Background replication with TCP-Nice: not designed for network utilization & control (no further discussion, please refer to our paper)

24
Modified HDFS InterferenceUnmodified HDFS
◦Much overhead with synchronous replicationModification for asynchronous replication
◦With an increasing level of interferenceFour levels of interference
◦Hadoop: original, no replication, no interference
◦Read: disk read, no network transfer, no actual replication
◦Read-Send: disk read & network send, no actual replication
◦Rep.: full replication

25
Modified HDFS InterferenceAsynchronous replication
◦Network utilization makes the difference
Both Map & Shuffle get affected◦Some Maps need to read remotely

26
Our PositionIntermediate data as a first-class
citizen for dataflow programming frameworks in cloudsDataflow programming frameworksThe importance of intermediate data◦Outline of a new storage system
designWhy is storage the right abstraction?Challenges Research directions

27
Research DirectionsTwo requirements
◦Intermediate data availability to stop cascaded re-execution
◦Interference minimization focusing on network interference
Solution◦Replication with minimal interference

28
Research DirectionsReplication using spare
bandwidth◦Not much network activity during
Map & Reduce computation◦Tight B/W monitoring & control
Deadline-based replication◦Replicate every N stages
Replication based on a cost model◦Replicate only when re-execution is
more expensive

29
SummaryOur position
◦Intermediate data as a first-class citizen for dataflow programming frameworks in clouds
Problem: cascaded re-executionRequirements
◦Intermediate data availability◦Interference minimization
Further research needed

30
BACKUP

31
Default HDFS InterferenceReplication of Map and Reduce
outputs

32
Default HDFS InterferenceReplication policy: local, then
remote-rackSynchronous replication


















