
Olivia Klosedownload.microsoft.com/download/F/7/E/F7E9A431-DD1D-4082...Apache Spark is a fast and...
43
Olivia Klose Technical Evangelist Sascha Dittmann Cloud Solution Architect
Transcript of Olivia Klosedownload.microsoft.com/download/F/7/E/F7E9A431-DD1D-4082...Apache Spark is a fast and...

Olivia Klose Technical Evangelist
Sascha
Dittmann Cloud Solution Architect


Apache Spark™ is a
fast and general engine
for large-scale data processing.
An unified, open source, parallel,
data processing framework for
Big Data Analytics
What is Apache Spark?

Speed
Ease of Use
Generality
Runs Everywhere
What is Apache Spark?

Speed
Ease of Use
Generality
Runs Everywhere
What is Apache Spark?
Logistic regression on a 100-node cluster with 100 GB of data
Logistic Regression
140
120
100
80
40
20
0
60
Hadoop
Spark 0.9

Speed
Ease of Use
Generality
Runs Everywhere
What is Apache Spark?
text_file = spark.textFile("hdfs://...") text_file.flatMap(lambda line: line.split()) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a+b)
Word count in Spark's Python API

Speed
Ease of Use
Generality
Runs Everywhere
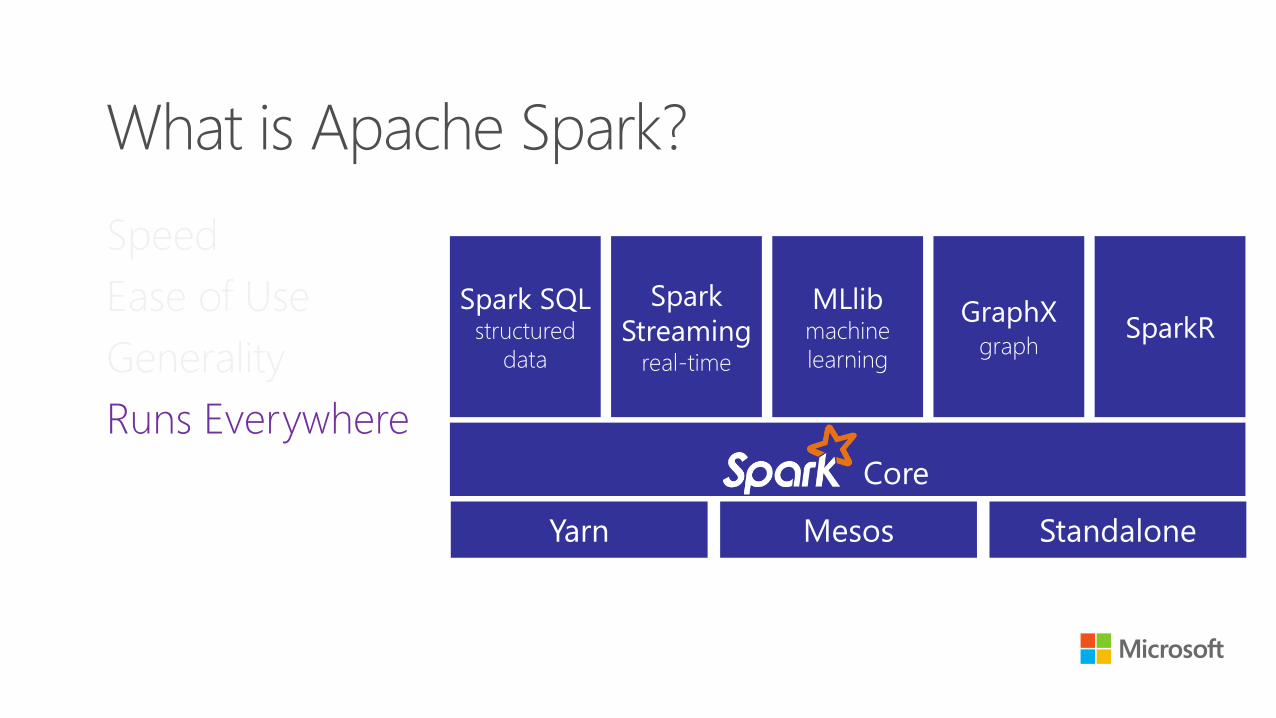
What is Apache Spark?
Spark SQL structured
data
Spark
Streaming real-time
MLlib machine
learning
GraphX graph
Core
SparkR
Speed
Ease of Use
Generality
Runs Everywhere
What is Apache Spark?
Yarn Mesos Standalone
Spark SQL structured
data
Spark
Streaming real-time
MLlib machine
learning
GraphX graph
Core
SparkR

Apache Spark in the Community


Scenarios
Stream Processing Machine Learning
Interactive Analytics Data Integration

Traditional Data Warehouse
ETL & Query
Just-in-Time Data Warehouse
Stream/Cache & Query
Unifying Data Sources
Data Warehouse
Data
Source A
Data
Source B
Data
Source C
ETL
Data
Source A
Data
Source B
Data
Source C
RAM RAM RAM

Traditional Data Warehouse
Download & Play
Just-in-Time Data Warehouse
Stream/Cache & Play
Unifying Data Sources

First cellular
phones
Smartphone
(Unified Device)
Unifying Data Processing
Specialized
devices
First cellular
phones
Smartphone
(Unified Device)
Unifying Data Processing
Specialized
devices
Better Games
Better GPS Better Phone
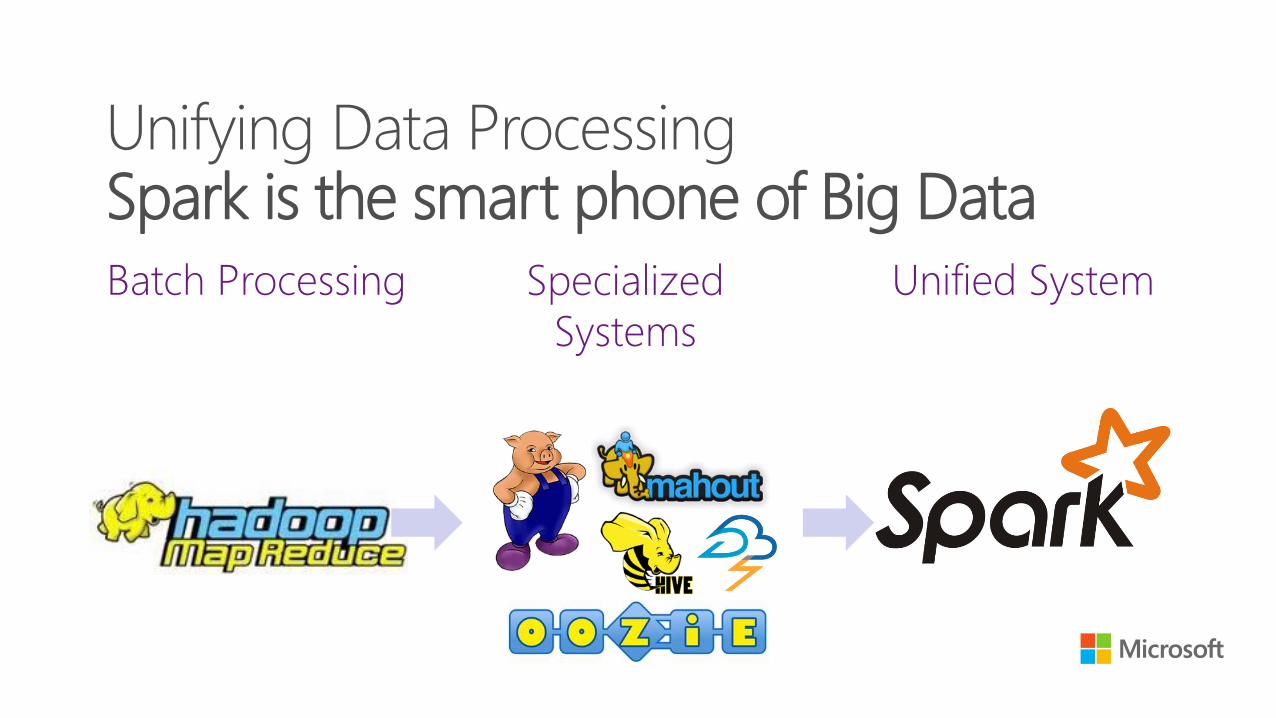
Batch Processing Unified System
Unifying Data Processing Spark is the smart phone of Big Data
Specialized
Systems
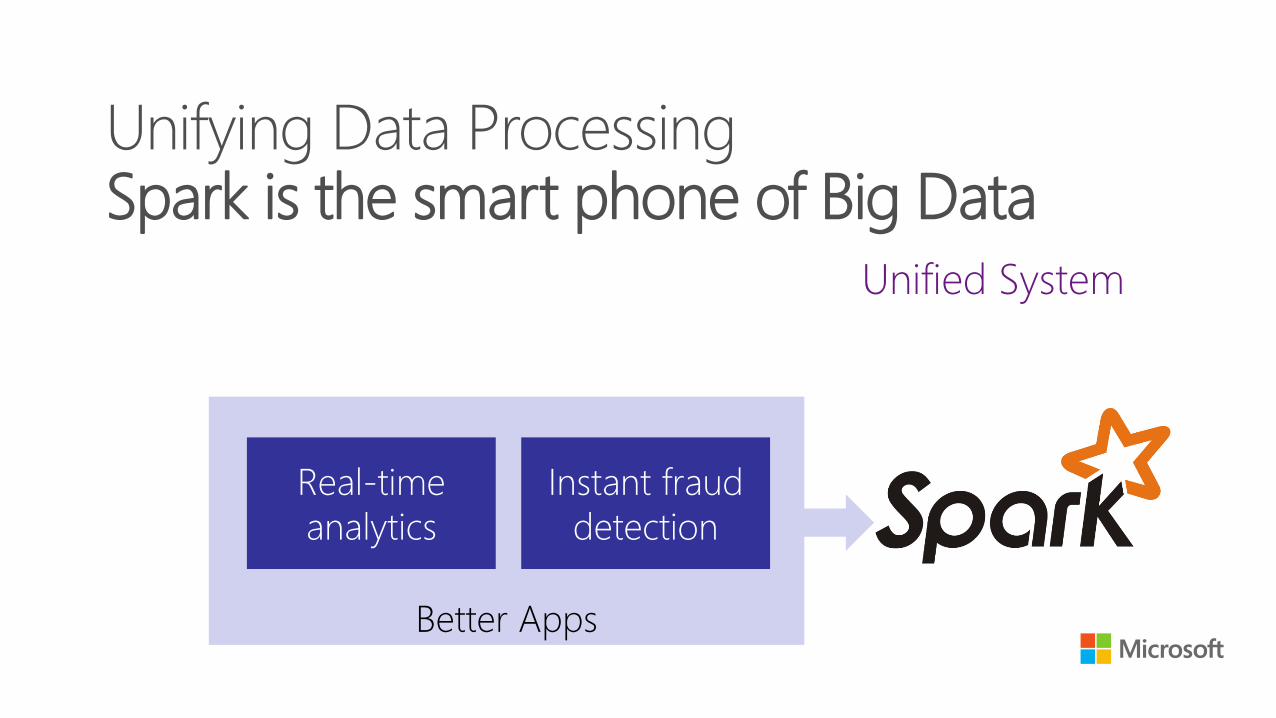
Unified System
Unifying Data Processing Spark is the smart phone of Big Data
Better Apps
Real-time
analytics
Instant fraud
detection



Spark Stack
Spark SQL structured
data
Spark
Streaming real-time
MLlib machine
learning
GraphX graph
Core
SparkR R on Spark
Yarn Mesos Standalone

Storage Options
Azure Data Lake

Resilient Distributed Datasets (RDDs)
RDD RDD
RDD RDD
RDD
transformations Value actions



Hadoop vs. Spark: Compute an Average
private IntWritable one = new IntWritable(1) private IntWritable output = new IntWritable() proctected void map(LongWritable key, Text value, Context context) { String[] fields = value.split("\t") output.set(Integer.parseInt(fields[1])) context.write(one, output) } IntWritable one = new IntWritable(1) DoubleWritable average = new DoubleWritable() protected void reduce( IntWritable key, Iterable<IntWritable> values, Context context) { int sum = 0 int count = 0 for(IntWritable value : values) { sum += value.get() count++ } average.set(sum / (double) count) context.Write(key, average) }
data = sc.textFile(...).split("\t") data.map(lambda x: (x[0], [x.[1], 1])) \ .reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]]) \ .map(lambda x: [x[0], x[1][0] / x[1][1]]) \ .collect()

What can Hadoop give to Spark?
YARN Disaster Recovery Distributed File
System Data Security

What can Spark give to Hadoop?
Read from HDFS
Write to HDFS
Read from HDFS
Write to HDFS
Read from HDFS


DataFrame
1. A distributed collection of rows organized into named
columns
2. An abstraction for selecting, filtering, aggregating and
plotting structured data (cf. R, Pandas)
3. Archaic: Previously SchemaRDD (cf. Spark<1.3)

DataFrame

RDD vs. DataFrame: Compute an Average
Using RDDs
Using DataFrames Using SQL
data = sc.textFile(...).split("\t") data.map(lambda x: (x[0], [int(x[1]), 1])) \ .reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]]) \ .map(lambda x: [x[0], x[1][0] / x[1][1]]) \ .collect()
SELECT name, avg(age) FROM people GROUP BY name
sqlCtx.table("people") \ .groupBy("name") \ .agg("name", avg("age")) \ .map(lambda …) \ .collect()


What else is there?
Spark SQL structured
data
Spark
Streaming real-time
MLlib machine
learning
GraphX graph
Core
SparkR R on Spark
Yarn Mesos Standalone

Streaming with Azure Event Hub
54
Azure Event Hub HDInsight Spark Streaming Power BI

https://spark.apache.org/
https://aka.ms/CortanaAnalyticsWorkshop
http://aka.ms/bigdatasupport
http://aka.ms/SparkOnAzure
http://aka.ms/AzureFriday-Spark


Entwickler:
www.techwiese.de - News, Ressourcen, Events und Support für Entwickler
www.msdn.de/newsletter - MSDN Flash – kostenloser Newsletter für Entwickler
IT Pros:
www.itprohub.de - News, Ressourcen, Events und Support für IT Profis
www.technet.de/flash - TechNet Flash - kostenloser Newsletter für IT Profis
Für Devs und IT Pros:
www.mva.ms - Kostenlose Online-Schulungen für Entwickler und IT Profis
www.ch9.ms - Videoplattform für Entwickler und IT Profis
Weiterführende Informationen
























