
Offsite presentation original
35
oheila Dehghanzadeh
Transcript of Offsite presentation original

Soheila Dehghanzadeh

Agenda•I
ntroduction to Trade-offs in Integration Systems
•Requirements and Research Questions
•Contributions
•Conclusions and Future Work

Introduction
•What is data integration?
• “Combining data from different distributed sources”1.
•Why is it important?
• Most queries requires integrating data from various sources.
•Why is it challenging?
• Sources are autonomous and distributed.• Distributing query among sources to provide the response has performance, scalability
and availability problems.• Caching solves above problems but leads to inconsistencies.• Maintaining cache increases latency.
31. https://en.wikipedia.org/wiki/Data_integration
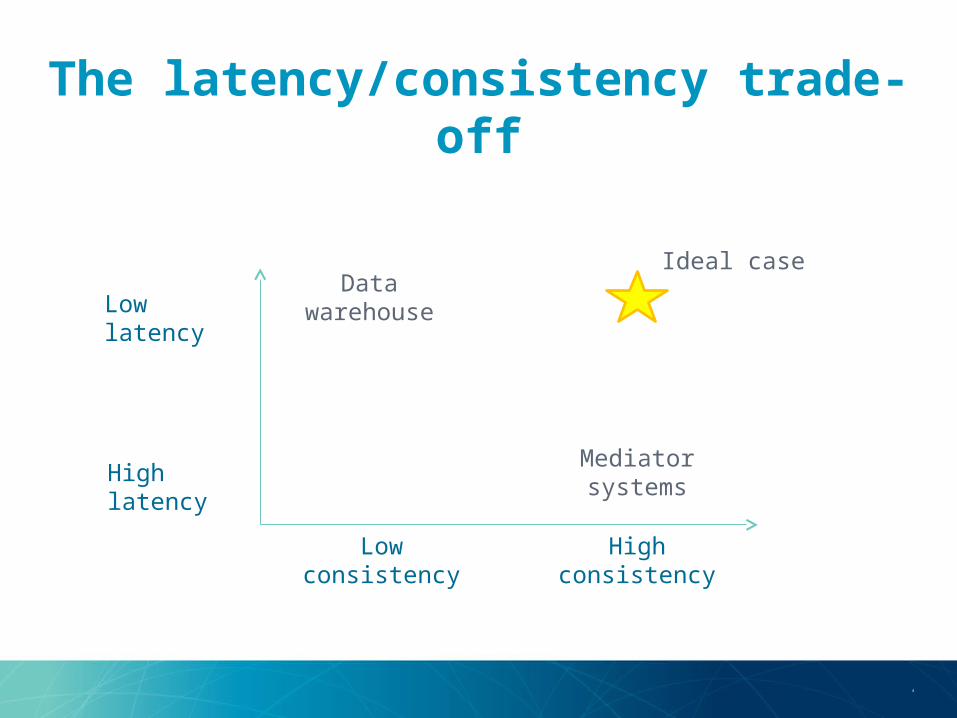
The latency/consistency trade-off
4
High consistencyLow consistency
Low latency
High latency
Ideal caseData
warehouse
Mediator systems

Data integration
•Data integration approaches
• Data warehouse (DW)• Low latency• Low consistency
High consistencyLow consistency
Low latency
High latency
Ideal caseData
warehouse
Mediator systems

Data warehouse
Low latencyLow consistency

Data Market: Lowest latency with a consistency threshold
Minimize cost (financial and latency) as far as consistency is
above a threshold
Find me emails of
“The North Face”
customers.
My existing data can provide you a
response with 60% freshness.Ok
Here is the responseNo, I want
the fastest response with at
least 80% freshness
To provide 80%
freshness you need to wait 30 sec
and pay 60$

Research Question 1
How to optimally maintain data when consistency is restricted and latency is demanded to be
minimized?
8

Summary of contribution 1
•A method to estimate the response freshness using the existing data (JIST2014, ISWC2014).
• Extend summarization techniques to trace the freshness.• Indexing, histogram and Qtree • Use summary to estimate the response freshness.
•Evaluation
• We managed to estimate the freshness of a query with 6% error rate.
•Future work
• Use more advanced summarizations to lower the error rate.
9
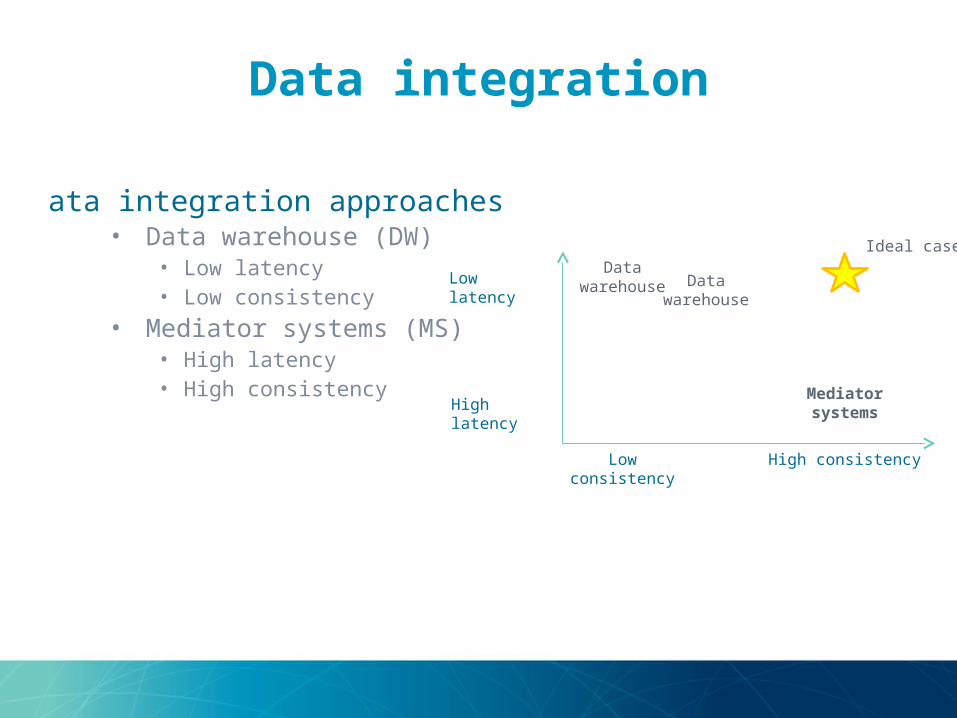
Data integration
•Data integration approaches
• Data warehouse (DW)• Low latency• Low consistency
• Mediator systems (MS)• High latency• High consistency
High consistencyLow consistency
Low latency
High latency
Ideal caseData
warehouse
Mediator systems
Data warehouse

Mediator System
High latencyhigh consistency
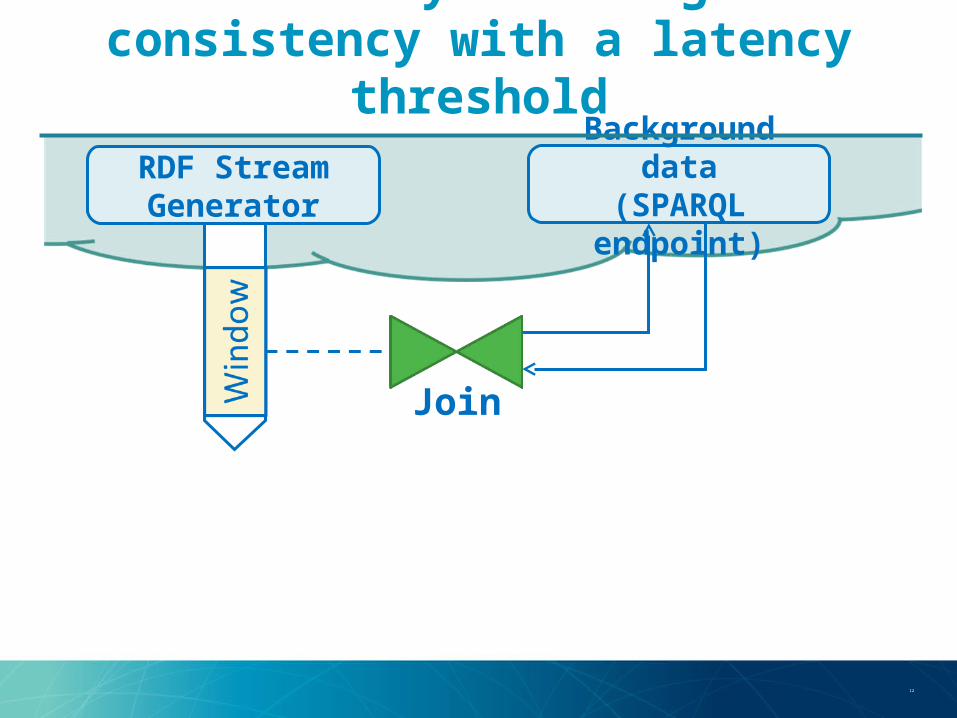
Mediator system: Highest consistency with a latency threshold
Join
RDF Stream Generator
Background data(SPARQL endpoint)
12

Mediator system: Highest consistency with a latency threshold
Join
RDF Stream Generator
Background data(SPARQL endpoint)
Local View
13

Mediator system: Highest consistency with a latency threshold
Join
RDF Stream Generator
Background data(SPARQL endpoint)
Local View
Maintenance Process
Freshness decreases
Refresh Cost/Quality trade-
off
14

Research Question 2
How to optimally maintain data when the latency is restricted and consistency is demanded to be
maximized?
15

Summary of contribution 2•A
maintenance process to maximize consistency with respect to latency constraint (WWW2015, ICWE2015).
• Query driven: maintain cache entries that are involved in current evaluation• Freshness driven: maintain cache entries that
• Are stale• Change less frequently • Affect future evaluations
•Evaluation
• The proposed approach outperforms a set of baseline policies.
•This work has already been followed up
• Queries with FILTER clauses (ICWE2016)• Queries with complex join patterns (ISWC2016)
16
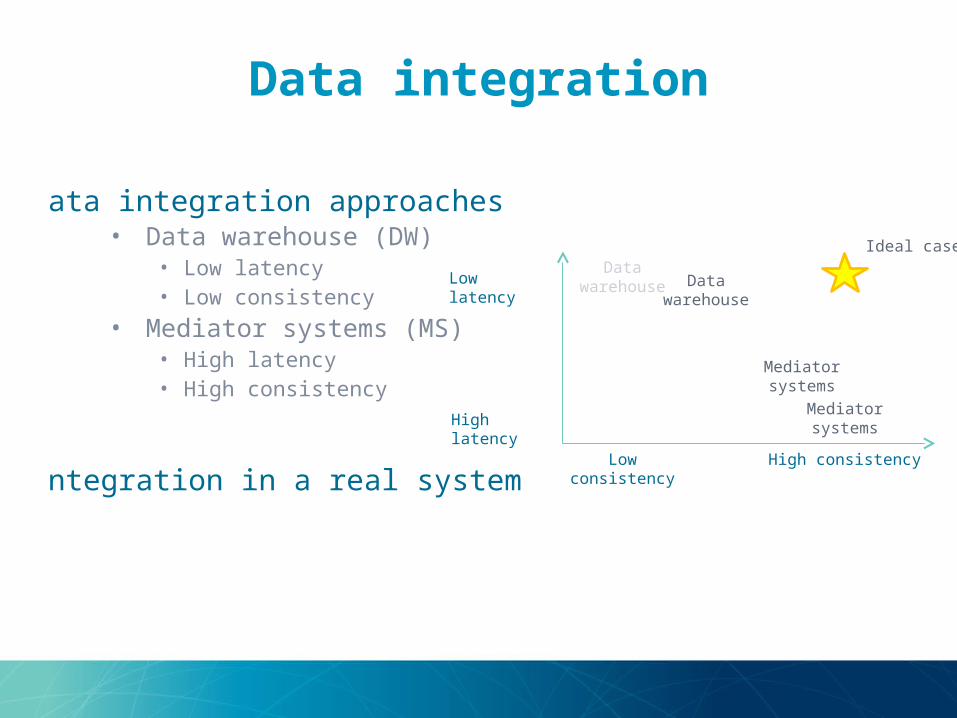
Data integration
•Data integration approaches
• Data warehouse (DW)• Low latency• Low consistency
• Mediator systems (MS)• High latency• High consistency
•Integration in a real system
High consistencyLow consistency
Low latency
High latency
Ideal caseData
warehouse
Mediator systems
Data warehouse
Mediator systems

Contributing the proposed policies to CSPARQL
• So far we assumed all required data to provide the response exists in the local cache but needs to be maintained.
• What if required data does not fit in the local cache?
18
entries
SERVICE Provider
Local cache

Research Question 3
How to take into account space constraint while optimizing data integration with regards to
latency or consistency constraints?
19

20
Summary of contribution 3• An extension of the maintenance policy (contribution 2) to take into
account both latency and space constraints. • Fetching policies to cope with cache incompleteness • A freshness based cache replacement policy • An implementation in CSPARQL
• Evaluation• The proposed replacement policy outperforms state-of-the-art
replacement policies.• Future work
• Investigating more complex queries (e.g., with multiple SERVICE clauses, complex join patterns)
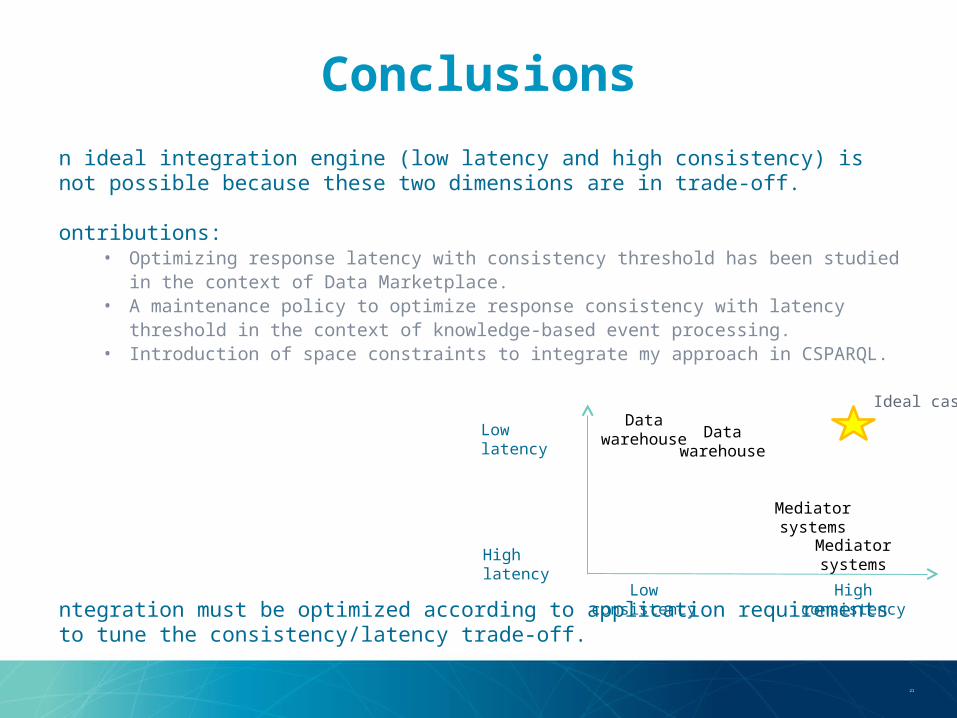
Conclusions•A
n ideal integration engine (low latency and high consistency) is not possible because these two dimensions are in trade-off.
•Contributions:
• Optimizing response latency with consistency threshold has been studied in the context of Data Marketplace.
• A maintenance policy to optimize response consistency with latency threshold in the context of knowledge-based event processing.
• Introduction of space constraints to integrate my approach in CSPARQL.
•Integration must be optimized according to application requirements to tune the consistency/latency trade-off.
21
High consistencyLow consistency
Low latency
High latency
Ideal caseData
warehouse
Mediator systems
Data warehouse
Mediator systems

Slide 22
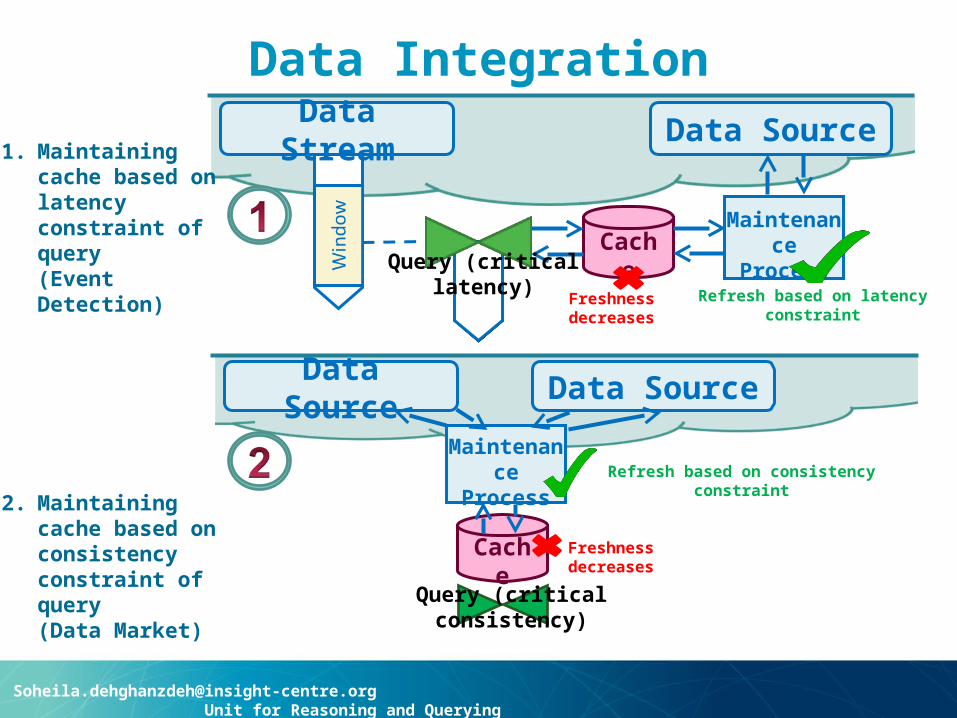
Data IntegrationData Stream Data Source
CacheMaintenance
Process
Freshness decreases
Refresh based on latency constraint
Query (critical latency)
Data Source Data Source
Cache
Maintenance Process
Freshness decreases
Refresh based on consistency constraint
Query (critical consistency)
1. Maintaining cache based on latency constraint of query (Event Detection)
2. Maintaining cache based on consistency constraint of query (Data Market)
[email protected] Unit for Reasoning and Querying
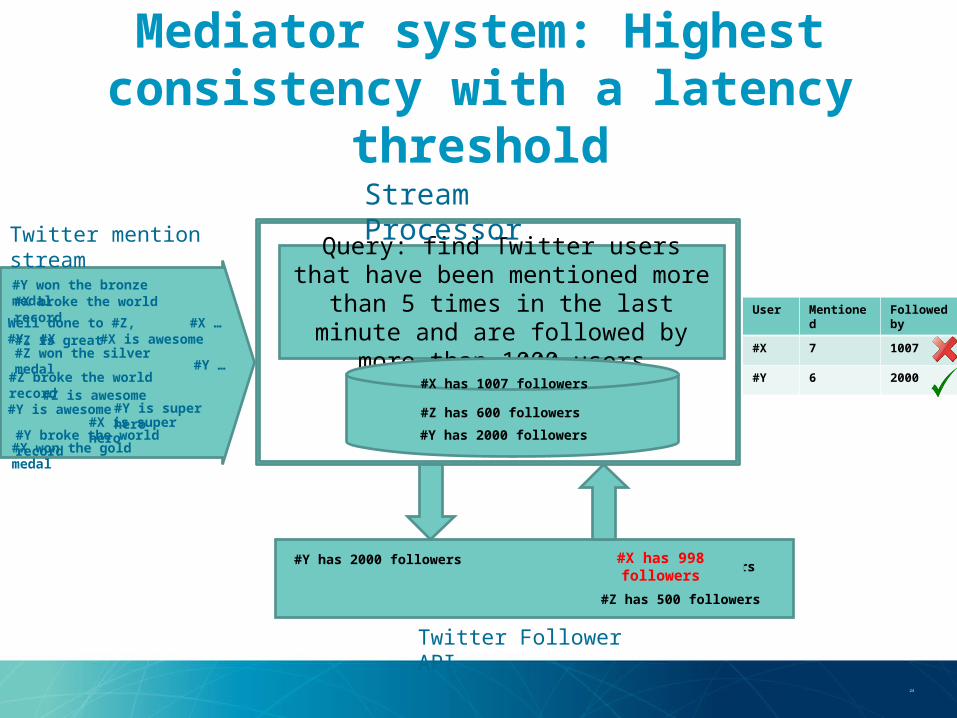
Mediator system: Highest consistency with a latency threshold
24
Query: find Twitter users that have been mentioned more than 5 times in the last minute and are followed
by more than 1000 users
Stream ProcessorTwitter mention stream
#X has 1007 followers#Y has 2000 followers
#Z has 500 followers
Twitter Follower API
#X is super hero#X won the gold medal
#X broke the world record
#X is awesome#X …
#Y is super hero
#Y won the bronze medal
#Y broke the world record
#Y is awesome
#Y …
#Z is great#Z won the silver medal#Z broke the world
record#Z is awesome
Well done to #Z, #Y, #X
User Mentioned
Followed by
#X 7 1007
#Y 6 2000#X has 1007 followers
#Y has 2000 followers#Z has 600 followers
#X has 998 followers

Contributing the proposed policies to CSPARQL
Requirements•A local cache R•Fetch SERVICE from R•Maintain R•ESPER external time
25
The modified engine is available on github
Time stamp
entries
SERVICE Provider
Local cache

Workloads with significant improvements with proposed policy
•We hypothesize that WSJ-WBM is more influential if :
• Hypothesis 1: the BKG data change slower• Hypothesis 2: the BKG data changes with more diversity in change rate• Hypothesis 3: there is a negative correlation between the streaming rate
and the change rate• Hypothesis 4: total number of possible events (i.e., caching space) is
larger•T
he time overhead of WSJ-WBM is negligible
26

Experiments set up•A
data generator to generate various workloads with • Various change rate distributions within an interval- random or normal
distribution• Various streaming rates- the inter arrival time of elements follows a
Poisson distribution with various lambda intervals
27

Hypothesis 1: BKG data change slower.
28

Hypothesis 2: BKG data changes with more diversity in change rate.
29

Hypothesis 3: negative correlation between the streaming and change rate
30
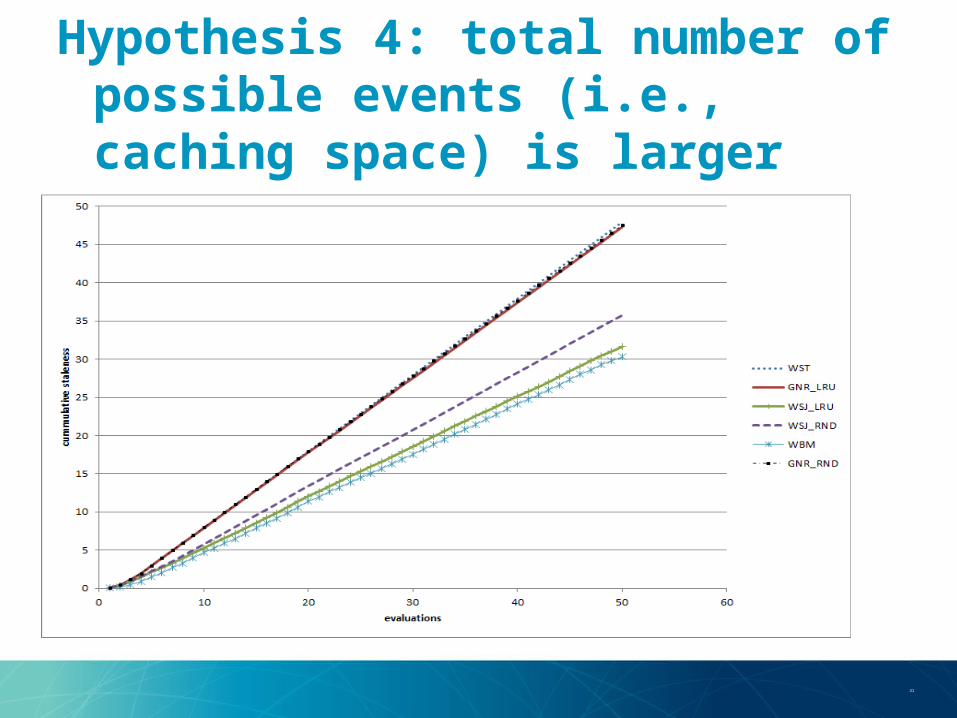
Hypothesis 4: total number of possible events (i.e., caching space) is larger
31
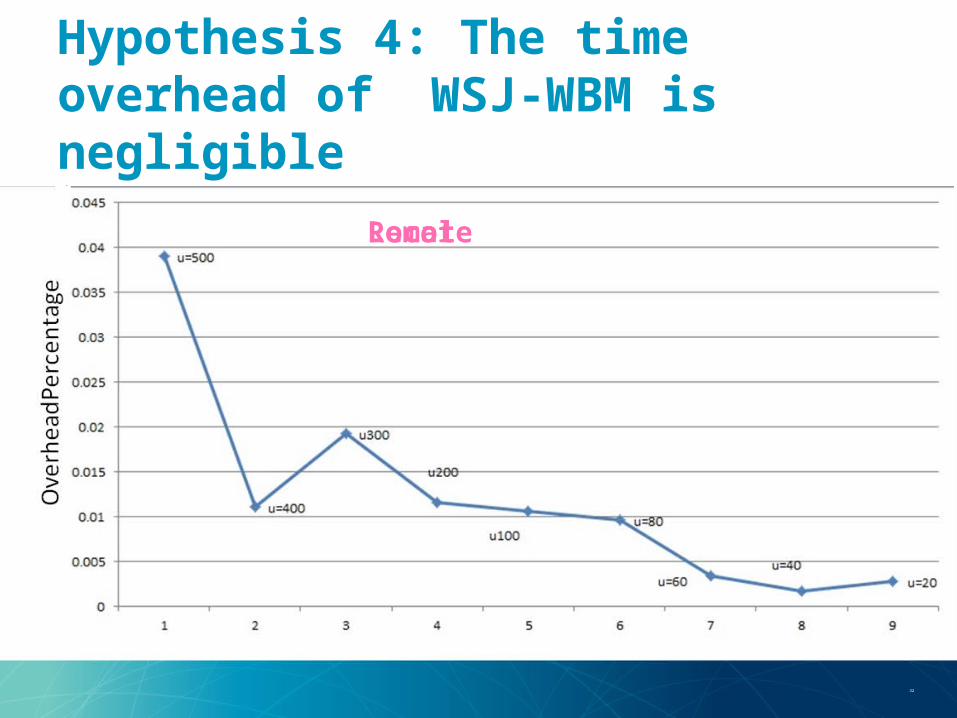
Hypothesis 4: The time overhead of WSJ-WBM is negligible
32
LocalRemote

Combining RDF Streams and Remotely Stored Background Data
•We move to an approximate setting, and we introduce a local view to store part of the data involved in the query processing, and update part of it to capture the dynamicity
33

A query-driven maintenance process
•SELECT * WHERE WINDOW(S, ω, β) PW . SERVICE(BKG) PS
34
WINDOW clause
JOIN Proposer Ranker
MaintainerLocal View
4 2
3
1
SERVICE clause
E
C
RNDLRUWBM
CWSJWSJGNR
LRUFRP

Evaluation
35


















