
Odds and Ends With respect to the values that skewness can take on, negative skewness is a negative...
47
Odds and Ends Highestyearofschool com pleted 20.0 18.0 16.0 14.0 12.0 10.0 8.0 6.0 4.0 2.0 0.0 Highestyearofschoolcom pleted Frequency 600 500 400 300 200 100 0 Std.Dev = 3.00 M ean = 13.3 N = 1493.00 With respect to the values that skewness can take on, negative skewness is a negative number, and positive skewness a positive number. Values typically range between -1 and +1 but can be larger Skewness of a normal distribution is zero or near. Skewness for the two pictured distributions: - 431 for highest year of high school completed and .424 for age of respondent. Age ofrespondent 90.0 85.0 80.0 75.0 70.0 65.0 60.0 55.0 50.0 45.0 40.0 35.0 30.0 25.0 20.0 Age ofrespondent Frequency 200 100 0 Std.Dev = 17.34 M ean = 46.4 N = 1490.00 In this formula for putting confidence intervals around sample proportions, CI upper = P + (Z)( σ), use SE or SEP instead of σ for clarity
Transcript of Odds and Ends With respect to the values that skewness can take on, negative skewness is a negative...

Odds and Ends
Highest year of school completed
20.0
18.0
16.0
14.0
12.0
10.0
8.0
6.0
4.0
2.0
0.0
Highest year of school completed
Fre
qu
en
cy
600
500
400
300
200
100
0
Std. Dev = 3.00
Mean = 13.3
N = 1493.00
With respect to the values that skewness can take on, negative skewness is a negative number, and positive skewness a positive number. Values typically range between -1 and +1 but can be larger Skewness of a normal distribution is zero or near. Skewness for the two pictured distributions: -431 for highest year of high school completed and .424 for age of respondent.
Age of respondent
90.0
85.0
80.0
75.0
70.0
65.0
60.0
55.0
50.0
45.0
40.0
35.0
30.0
25.0
20.0
Age of respondent
Fre
qu
en
cy
200
100
0
Std. Dev = 17.34
Mean = 46.4
N = 1490.00
In this formula for putting confidence intervals around sample proportions, CIupper = P + (Z)( σ), use SE or SEP instead of σ for clarity

Odds and ends: Stem and leaf plotStem size = 1000 –each single interval represents 1000lbs, repeated intervals 500 lbs
Each of these is a “leaf” representing 2 cases; the number represents hundreds of pounds; thus there are (allowing for rounding) two sixteen hundred cases, four 1700 cases, etc.
There are 103 cases in the range 2000-2500 lbs; 44 cases between 1000 and 2000 lbs

More odds and ends: test for non-normality Shapiro-Wilks test is calculated in
Analyze/Descriptives/Explore/Plots/Normality Plots with Tests
If the obtained value of “w” is significant at p <.05, then the null hypothesis that the data come from a normal distribution has to be rejected and there is a significant departure from normality

More odds and ends: Grading Labs: Shuya will examine your labs and if
they are correct will mark them as completed. If they contain errors she will return them to you to correct. Your lab grade is the proportion of assigned labs you complete successfully
Paper: The various segments of your paper (literature review, etc) will not be graded but rather reviewed and returned to you for corrections, changes, etc. You will only be graded on the completed paper you turn in at the end of the semester

Significance Test for Difference of Proportions, for One Variable Only
Fifty potential voters were asked if they preferred Smith to her opponent
Fifty potential voters were also asked if they preferred Jones to his opponent
Go here and get the file VoterPref.sav http://www-rcf.usc.edu/~mmclaugh/550x/DataFiles/
Let’s test two hypotheses: (1) that voters preferred Smith to her opponent (2) that voters preferred Jones to his opponent

Chi-Square test of the significant difference of two proportions, single sample We have set up two dummy variables, one for Smith and
one for Jones For the dummy variable Smith, 1 equals a preference for
Smith and 0 a preference for the opponent For the dummy variable Jones, 1 equals a preference for
Jones and 0 a preference for the opponent Let’s first obtain the descriptive data which tells us what the
percentages are for the preferences for Smith, and for the preferences for Jones, vs. their respective opponents
Open the VoterPref.sav file in SPSS Go to Analyze/Descriptives/Explore and move the variables
Smith and Jones, in that order, into the dependent list window
Under Statistics, click Descriptives, Percentiles, Continue, and then OK
Examine your output

Output of Explore for Smith, Jones
We see that the hypothesis that the voters preferred Smith to her opponent might be viable, as 70% preferred Smith
But the hypothesis that voters preferred Jones to his opponent does not seem to be viable, as only 40% of the voters preferred Jones; since we had a directional hypothesis that the voters preferred Jones, we have to say that our hypothesis has failed and do no further testing

Doing a Test of the Significance of the Difference between Proportions for the Smith contest
70% of the voters preferred Smith to her opponent; is this a statistically significant difference?
We will use the Chi-Square distribution to conduct this test
Go to Analyze/Nonparametric Tests/Chi Square
Move the Smith variable into the Test Variable List
Click Options, then Descriptives, then OK

Output of the Single Sample Chi-Square Test
In a chi-square test we are interested in how much the obtained proportions deviate from what we might expect in the population; in the population the most probable result is that 50% of the voters would prefer Smith and 50% would prefer the opponent. These are the “default” expected frequencies. We can change these when we set up the problem if the population is known to have some other values-for example, percentages in ethnic categories
Significant level of Chi-square (< .01) allows us to confirm our research hypothesis and reject the null hypothesis

Single-Sample Chi Square Test
Formula for chi-square:
In this case, we have two products E-O to sum: 25-15, squared, divided by 25, which equals 4, and 25-35, squared, divided by 25, which equals 4, giving us a Chi-square of 8

Chi-square distribution We enter the Chi
square table with 1 DF
A chi square of 8 is significant beyond the .005 level
Thus we have confirmed our directional hypothesis that voters prefer Smith to her opponent
We will return to the Chi square distribution later when we look at bivariate data and consider the relationship between two nominal level variables

Contingency Tables• When we array obtained data in a contingency table we are
interested in seeing to what extent one variable appears to be contingent on another. The question may be to what extent two variables have a relationship, or it may be what the effect of variable A is on variable B
• Contingency table statistics sometimes involve the comparison of “observed” (the actual raw data obtained) to “expected” frequencies, where the latter are what we would expect if there were no particular relationship between the variables. Cases where there is a considerable departure of observed from expected frequencies are likely to be statistically rare and fall into the “critical region”
• Hypothesis testing for contingency tables then largely involves determining if the departure of observed from expected values is sufficiently great to fall within some small probability area in the tails of the distribution for the statistic that is used to obtain the observed/expected difference. Chi-square is a typical statistic used for testing the statistical significance of associations in contingency tables.

Kinds of Questions Embedded in a Contingency Table• Suppose we have data on the following: gender, ethnicity,
preferred type of news source (TV vs. Internet), socio-economic status (class) and job classification. The first three variables are nominal, and the last two are categorical variables which are ordinal but probably not interval. What kinds of questions can we explore through a contingency table?• What are the differences in job classification attributable to gender?• What is the impact of gender on socio-economic status? On preference
for news source?• How does ethnicity affect socio-economic status?• How does job classification affect preference for news source?
• You will note in these questions that some variables will be regarded as causally prior, such as gender and ethnicity, and others will be regarded as both dependent (or susceptible of being influenced by outside factors such as immutable person characteristics) or independent depending on the relationship to other variables in the analysis. So job classification could be dependent in relation to gender or ethnicity, or independent in terms of having a “causal” impact on preference for news source

Example of a Contingency Table• Here are a contingency table and corresponding clustered bar
chart showing the impact of gender on job classification for 473 subjects
It would appear from the tabular and visualized data that women tend to be underrepresented in the managerial category and overrepresented in the clerical category, while men are overrepresented in the custodial category, suggesting strong sex-role segregation in the workplace. But it remains to be seen whether or not the observed trends are so striking that we can conclude with 95% or greater confidence that we can reject the hypothesis that in the population the genders are equally distributed across job categories. And even then, we cannot say that gender is the causal variable, only that there appears to be a relationship.
Employment Category * Gender Crosstabulation
27 0 27
10.5% .0% 5.7%
156 206 362
60.7% 95.4% 76.5%
74 10 84
28.8% 4.6% 17.8%
257 216 473
100.0% 100.0% 100.0%
Count
% within Gender
Count
% within Gender
Count
% within Gender
Count
% within Gender
Custodial
Clerical
Manager
EmploymentCategory
Total
male female
Gender
Total
Employment Category
ManagerClericalCustodial
Pe
rce
nt
120
100
80
60
40
20
0
Gender
male
female

Employment Category * Gender Crosstabulation
27 0 27
10.5% .0% 5.7%
156 206 362
60.7% 95.4% 76.5%
74 10 84
28.8% 4.6% 17.8%
257 216 473
100.0% 100.0% 100.0%
Count
% within Gender
Count
% within Gender
Count
% within Gender
Count
% within Gender
Custodial
Clerical
Manager
EmploymentCategory
Total
male female
Gender
Total
Closer Examination of Contingency Table
Along the top is the “Column Variable”, gender, and its categories form the two columns. The Column Variable is usually the one we want to treat as independent. The “Row Variable” is Employment Category, and its categories form the three rows. The Row Variable is usually the one we want to treat as dependent. The table has six “cells,” one for each combination of gender category and employment category. The data in the cells are the number of respondents who fell into that combination of categories, such as male custodial, female clerical, etc
CellsColumn Variable
Row Variable
Employment Category * Gender Crosstabulation
27 0 27
10.5% .0% 5.7%
156 206 362
60.7% 95.4% 76.5%
74 10 84
28.8% 4.6% 17.8%
257 216 473
100.0% 100.0% 100.0%
Count
% within Gender
Count
% within Gender
Count
% within Gender
Count
% within Gender
Custodial
Clerical
Manager
EmploymentCategory
Total
male female
Gender
Total
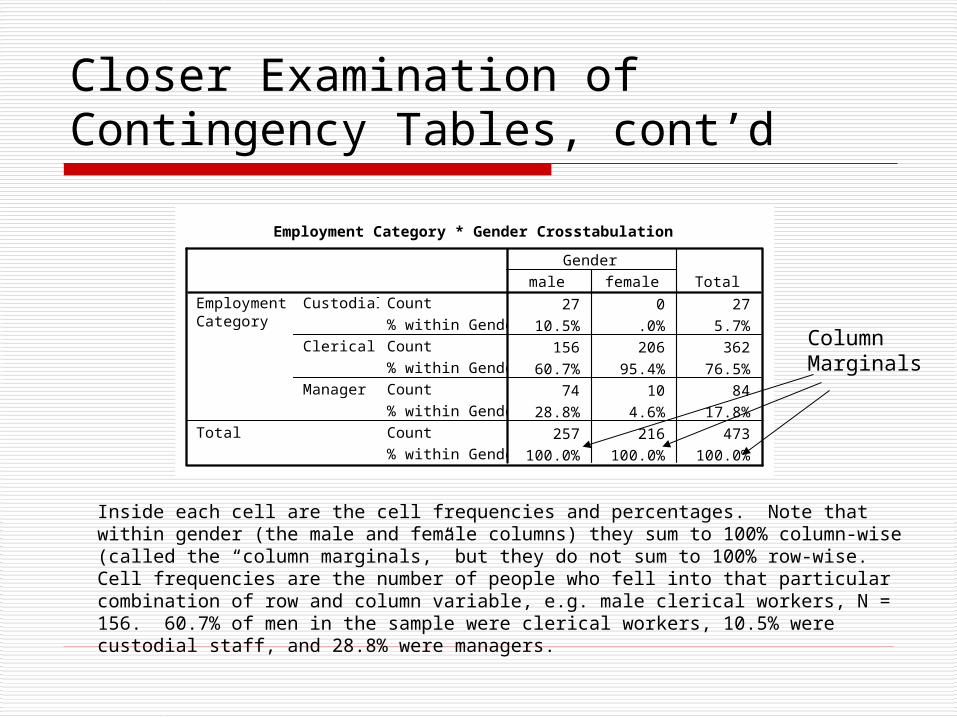
Closer Examination of Contingency Tables, cont’d
Inside each cell are the cell frequencies and percentages. Note that within gender (the male and female columns) they sum to 100% column-wise (called the “column marginals,” but they do not sum to 100% row-wise. Cell frequencies are the number of people who fell into that particular combination of row and column variable, e.g. male clerical workers, N = 156. 60.7% of men in the sample were clerical workers, 10.5% were custodial staff, and 28.8% were managers.
Column Marginals

Employment Category * Gender Crosstabulation
27 0 27
10.5% .0% 5.7%
156 206 362
60.7% 95.4% 76.5%
74 10 84
28.8% 4.6% 17.8%
257 216 473
100.0% 100.0% 100.0%
Count
% within Gender
Count
% within Gender
Count
% within Gender
Count
% within Gender
Custodial
Clerical
Manager
EmploymentCategory
Total
male female
Gender
Total
Closer Examination of Contingency Tables, cont’d; Patterns of Association
Row percentages are of greater interest in a crosstabulation than column percentages. Thus for example we see that within the category “manager,” 28.8% of the males were so classified, but only 4.6% of the women. Similarly, within the category “clerical,” 60.7% of the men were so classified, but 95.4% of the women. This is our first evidence of an possible association between gender and employment category. So we can make tentative statements like, “males were more likely to be employed as managers and custodians than females, while females were more likely to be employed as clerical workers than males”, but again, we don’t know yet how strong the association between gender and employment category is
Row Marginals: How subjects were distributed with respect to the Row Variable

Closer Examination of Contingency Tables, cont’d; Strength of Association and Direction of Association
• If we know gender, how much does it enhance our ability to predict employment classification over assuming that the genders are distributed across the employment categories proportional to their representation in the population? Which prediction would you feel most confident in? That for any given pair of men and women, the man would be more likely to be a custodian than the woman? That the man would be more likely to be a manager than the woman? That the woman would be more likely to be a clerical worker than the man?
• The “employment category” variable could be interpreted as an ordinal categorical variable since presumably the least income and job status are associated with custodial work, then with clerical work, and finally with managerial work (although there may be some clerical positions which pay less than custodial positions). Can we say that there appears to be a general, linear trend for men to have “better” jobs than women? Probably not; the trend seems to be more curvilinear in that men are concentrated in the highest and lowest status positions and women in the medium-status jobs

Evidence of a Trend?
If we look at the cell within each row of employment category with the highest percentage (pink dots) we see a diagonal line from upper left to lower right (connect the dots). For example, within the first row the highest percentage is custodians with an elementary school education; within the second, the highest percentage is clerical workers with a high school education. And within the last row the highest percentage is managers with post-secondary education. This is evidence of a kind of monotonic (order-preserving) trend. There is an apparent positive association between level of educational attainment and employment category such that the higher the educational attainment the higher the employment status. Interestingly, if we look at the relationship between gender and educational attainment we might speculate that some of the apparent relationship between gender and employment status is attributable to educational attainment. It falls to more sophisticated techniques to sort that out
Let’s consider another contingency table: “employment category” by “educational attainment”

Using SPSS to Create Contingency Tables• Download the SPSS file employment2.sav from here• In the SPSS Data Editor, check that the
employment2.sav file has opened up• Go to Analyze/Descriptive Statistics/Crosstabs• The variable you select as your dependent variable
will go in the box called Row. Put the variable “employment category” into that box
• The variable you select as your independent variable will go in the box called Column. Put the variable “educational attainment” into that box
• Click on the Cells button and select Observed, Column Percentages, and click Continue, then OK
• See illustration next slide

Using SPSS to Create Contingency Tables, con’td
Employment Category * Educational Attainment Crosstabulation
13 13 1 27
24.5% 6.8% .4% 5.7%
40 176 146 362
75.5% 92.6% 63.5% 76.5%
0 1 83 84
.0% .5% 36.1% 17.8%
53 190 230 473
100.0% 100.0% 100.0% 100.0%
Count
% within EducationalAttainment
Count
% within EducationalAttainment
Count
% within EducationalAttainment
Count
% within EducationalAttainment
Custodial
Clerical
Manager
EmploymentCategory
Total
elementaryschool high school
college orprofesssional
Educational Attainment
Total
Compare your results to the contingency table below
Now, write up a few sentences summarizing your analysis of the results

Measures of Association for Contingency Tables• Measures of association let us assess the extent to
which variation in one variable is associated with variation in another
• Measures of association often vary between + 1 and -1, where zero is no association and 1 is a perfect (positive) or (negative) association. Thus for a -1, variations in Variable A have a perfect inverse relationship with variations in Variable B. For example, the higher the educational level, the less frequent the viewing of network television shows
• Another way to interpret a measure of association is as an estimate of the proportion by which error in estimating the score on the dependent variable is reduced by virtue of knowing the score on the independent variable

Reduction of Error in Predicting the Dependent Variable
If you tried to guess someone’s occupation without knowing their level of educational attainment, your best guess would be that he or she was a clerical worker because this is the most populated category. So you would get 362 guesses (blue dot) right and make 111 mistakes (473(the total N,
green dot) minus 362). An
error rate of about 23%
If you knew someone’s level of educational attainment, and used that information as the basis for your guessing, how much could you reduce the error of prediction? If you used the most populated category for each level of educational attainment, you would guess right 40 + 176 + 146 times (red dots) or 362 times and make 111 mistakes. No improvement! But if the cases had been less concentrated within the clerical category you might have had an improvement in prediction

Measures of Association for Nominal Variables• Lambda
• For measurement of degree of association between two variables, either both nominal or one nominal and the other ordinal
• Ranges from 0 to 1 (no negative value)• No direction of association, only strength of
association (proportional reduction in error, or finding what proportion of the variation in dependent variable (row variable) is explained by independent variable (column variable)
• λ= E1 – E2/E1 where • E1 is equal to N (total number of subjects) minus the
highest frequency of the dependent variable in the row marginal totals, and
• E2 is equal to N minus the sum of the highest frequency in each of the columns excluding the column totals

Calculating Lambda: λ= E1 – E2/E1
• Let’s calculate lambda for the data in the table below, treating employment category as the dependent variable. (We are going to assume for purposes of illustrating the calculation that employment category is merely nominal although it is probably ordinal)
E1 = green dot number minus blue dot number. E2 = green dot number minus the sum of the red dot numbers! Λ = E1 minus E2, divided by E1 = ?
Remidner: E1 is equal to N (total number of subjects) minus the highest frequency of the dependent variable in the row marginal totals, andE2 is equal to N minus the sum of the highest frequency in each of the columns excluding the column totals
Row marginals

Limitations of lambda• In the preceding case, lambda equals zero! That is, knowing
educational attainment does nothing to improve the prediction of employment category, at least according to the statistic. This seems unlikely to be true!
• In this case, the highest frequency of the total N is the category clerical workers. And within each level of educational attainment, clerical worker is also the category with the highest frequency.
• What has happened is that lambda has let us down. It has the property that if the three highest frequencies of the dependent variable for each category of the independent variable are all in the same row, the number in the numerator of lambda sums to zero. (Lambda also has the property that if you treat employment category as the independent variable you will get a non-zero value of lambda, even though it doesn’t make much sense to do that as job category isn’t causally prior to educational attainment as a rule)
• Let’s give lambda one more chance

Another Lambda Calculation
Let’s consider lambda for the effects of gender on educational attainment. E1 equals 473 (green dot) minus 230 (blue dot), or 243. E2 equals 473 (green dot) minus the sum of 172 and 128 (red dots), or 173. So lambda = 243-173/243, or .288. Thus we can say that knowing gender allows us to reduce the error in predicting educational attainment by about 29%
Reminder: E1 is equal to N (total number of subjects) minus the highest frequency of the dependent variable in the row marginal totals, andE2 is equal to N minus the sum of the highest frequency in each of the columns excluding the column totals
λ= E1 – E2/E1

Using SPSS to Compute Lambda and Obtain a Significance Level• In the SPSS Data Editor, check that the
employment2.sav file is still open• Go to Analyze/Descriptive Statistics/Crosstabs• Click on the Reset button to clear the windows• The variable you select as your dependent variable
will go in the box called Row. Put the variable “educational attainment” into that box
• The variable you select as your independent variable will go in the box called Column. Put the variable “gender” into that box
• Click on the Cells button and under Percentages select Column, and click Continue
• Click on the Statistics button and click lambda under Nominal
• Click Continue and then OK

SPSS Output for lambdaEducational Attainment * Gender Crosstabulation
23 30 53
8.9% 13.9% 11.2%
62 128 190
24.1% 59.3% 40.2%
172 58 230
66.9% 26.9% 48.6%
257 216 473
100.0% 100.0% 100.0%
Count
% within Gender
Count
% within Gender
Count
% within Gender
Count
% within Gender
elementary school
high school
college or professsional
EducationalAttainment
Total
male female
Gender
Total
Directional Measures
.312 .048 5.645 .000
.288 .047 5.282 .000
.338 .059 4.795 .000
.121 .026 .000c
.164 .034 .000c
Symmetric
EducationalAttainment Dependent
Gender Dependent
EducationalAttainment Dependent
Gender Dependent
Lambda
Goodman andKruskal tau
Nominal byNominal
ValueAsymp.
Std. Errora
Approx. Tb
Approx. Sig.
Not assuming the null hypothesis.a.
Using the asymptotic standard error assuming the null hypothesis.b.
Based on chi-square approximationc.
There is a significant effect (lambda= .288, p less than .000) for gender on educational attainment. Note also the two other values of lambda, one for gender as a DV (wouldn’t make sense) and the other symmetric, assuming no causal ordering. We assumed a causal ordering so we pick the .288 value
Goodman and Kruskal’s tau. Similar measure of how much you can reduce error knowing the IV but doesn’t have lambda’s zero problem

Controlling for a Third Variable in Contingency Tables• What is the relationship between two variables when we “control”
for a third? In effect, we look at two separate contingency tables, one for each level of the control variable
• For example, what is the effect of educational attainment on the relationship between gender and employment category?
• In SPSS, go back to Data/Select Cases and choose “select all cases” and click OK
• Go to Analyze/Descriptive Statistics/Crosstabs and click Reset• Enter the employment category variable into the Row box• Enter the gender variable into the Column box • Enter the control variable, educational attainment, into the Layer 1 of 1
box• Click on Cells. Under percentages, select Column, and click Continue• Click on Statistics and select lambda (because our IV is nominal and our
DV is ordinal. Measurement level of control variable is not a factor). Click Continue and then OK

Effect of a Control Variable, Educational Attainment
In one of our first examples of crosstabs in which we ran a gender by employment category analysis we found that more than 95% of the women in the survey held clerical positions and only a little more than 4% were managers and none was a custodian, whereas 28.8% of the men were managers. Yet if we factor in the effect of educational attainment, we find that every one of the women who were managers (red dots) had post-secondary (college or professional) education, as did all but one of the 74 male managers (green dots).
Hence we *might* have reasons to conclude that at least in this sample the relationship between gender and employment category was spurious and was accounted for almost entirely by the relationship between gender and educational attainment

Effect of a Control Variable, cont’d
However, the association between gender and employment category changes between levels of the control variable educational attainment (compare the three lambdas (green dot) and the three values of tau (red dot). Lambda is mostly useless in this comparison but the values of tau suggest that the effects of gender on employment category is most pronounced for the group with the elementary school education and becomes less so as educational attainment increases. This is called a conditional association

Steps in Hypothesis Testing• Specify the research hypothesis and corresponding
null hypothesis• Compute the value of a test statistic about the
relationship between the two hypotheses• Calculate the Degrees of Freedom (DF) and look up
the statistic in the appropriate distribution to see if it falls into the critical region (for example, is a value of the t statistic large enough to fall into the area of the distribution corresponding to the 5% of cases in the upper and lower tails?)
• Based on the information above, decide whether to reject the null hypothesis

Specify the Research Hypothesis and the Null Hypothesis• First, please download the SPSS file socialsurvey.sav. We will
actually analyze the data in a few minutes but for now let’s stay at the hypothetical level
• Let’s consider the relationship between political philosophy (whether one thinks of oneself as liberal or conservative (variable #23) and attitudes toward the death penalty in murder cases (variable #24)
• First, let’s propose a research hypothesis, which speculates as to the nature of association between the two variables• H1: The more conservative the individual, the more likely he or she is to
support imposition of the death penalty in murder cases• Sometimes we would hypothesize that there would be a relationship, but
we would not speculate as to the direction of the relationship• Next, let’s construct the null hypothesis with respect to these two
variables• H0: There is no relationship between how conservative a person is and
his or her attitudes toward the death penalty in murder cases• The null hypothesis is the hypothesis we’ll be testing. We can either
reject it or fail to reject it, but we can’t confirm it. In practice, we are usually hoping to be able to reject it!

Research Hypothesis vs. Null Hypothesis• Our null hypothesis states that attitudes toward capital
murder do not differ based on political philosophy. Another way to state this is that the two variables are independent of one another
• However, after collecting our data and analyzing the contingency table with a measure of association such as chi square, we may look up our obtained value of chi square in a table containing the expected distribution of sample values (there is one in Table B, p. 475 in Kendrick or you can find them online). We decide before we look it up that we are going to require an “unlikelihood” of obtaining such a strong association of 5% or less by chance before we will be impressed. We find that, given our sample size and DF (in the case of chi-square (rows-1)(columns-1)), the value of chi-square we obtained from our sample data is likely to occur only one time in a thousand (.001) by chance

Research Hypothesis vs. Null Hypothesis, cont’d• What this tells us is that it is extremely unlikely that
we would have drawn a result showing such a strong association between political philosophy and death penalty attitudes if in fact there was no such association in the population as a whole. And that the two variables show evidence of statistical dependence
• Therefore, it would be reasonable to reject the null hypothesis of no association. In practice (e.g. write-ups in scholarly journals), researchers write of having “confirmed” the research hypothesis, but what they have actually done is reject the null hypothesis

Failing to Reject the Null Hypothesis, Error Types
• Now suppose we ran our chi-square test and we obtained a result which when we compared it against the chi-square distribution fell below our predetermined cutoff point. Let’s suppose that we learned that a value of chi-square like the one we obtained would be obtained in the population about 20% (.20) of the time by chance
• We would therefore be obliged to conclude that we had “failed to reject the null hypothesis” (not that we could accept it, though…)

Practicing with the Chi-Square TableLet’s practice with the Chi-square table. Suppose we set our critical region for rejection of the null hypothesis at .05., which is the minimum standard in the social sciences generally Assuming a degrees of freedom of 20, what value of chi-square would we have to get in our results to reject the null hypothesis?
DF=20
Critical Region = .05

Chi-Square Test with SPSS• Let’s obtain the contingency table for the relationship
between one’s political self-identification and attitude toward the death penalty• In SPSS, go to Analyze/Descriptives/Crosstabs• Put “favor or oppose the death penalty” as the Row
variable and “think of self as liberal or conservative” as the Column variable. (It makes more sense to treat political self-identification as the independent variable)
• Click on Cells and under Percentages select Row, Column, and Total. Under Counts click both Observed and Expected. Click Continue
• Click on Statistics and select chi-square and lambda, then click Continue and then OK

Contingency Table with Chi-Square in SPSS
Note that the proportion favoring the death penalty increases as you move from left to right (more liberal to more conservative) (follow the colored dots), while the opposite trend occurs as you look along the row for those opposing (Although note that there is a consistent trend for more people to favor the death penalty than oppose it)

Value, Significance of Chi-SquareChi-Square Tests
47.760a 6 .000
45.012 6 .000
38.602 1 .000
1343
Pearson Chi-Square
Likelihood Ratio
Linear-by-LinearAssociation
N of Valid Cases
Value dfAsymp. Sig.
(2-sided)
0 cells (.0%) have expected count less than 5. Theminimum expected count is 6.52.
a.
The obtained value of the statistic chi-square is 47.76, with 6 DF (for chi-square this is rows-1 times columns-1: how many cells in a table are free to vary, once the row and column marginal totals are known). Entering the table of the distribution of chi-square we find that for a DF of 6 we need a value of chi-square of 12.592 or better to reject the null hypothesis of no association in the population at a confidence level of .05. Our value exceeds that and in fact is significant beyond a confidence level of .001 (see output). So it is reasonable for us to assume that the obtained relationship we observed, that the more conservative the person, the more likely to favor the death penalty, holds for the population in general. If we were to write this up for publication we might state it as “results supported the research hypothesis that political philosophy influences attitudes towards the death penalty (χ2 = 47.760, DF=6, p <.001). (p stands for the probability of obtaining a value of chi-square that large)

Calculation and Interpretation of Chi-square• Chi-square, unlike for example lambda, does not range between
zero and 1 and cannot be interpreted as an index of the proportional reduction of error.
• It is a measure of the statistical independence of two variables• The larger the value of chi-square for a constant value of DF, the
stronger the dependence of the two variables (the stronger their association)
• The measure is based on the departure of the observed frequencies in a contingency table from the expected frequencies
• In the formula for chi-square, O represents the observed frequencies (called counts in the SPSS table) and E represents the expected frequencies (called expected counts)

Comparison of Observed and Expected Frequencies
If we look within the “favor” row and we compare the observed (count) to the expected count we notice that generally the observed count is lower than expected
for the liberal end and higher than expected for the conservative end.

How are Expected Frequencies Obtained?
• The expected frequencies are what we would expect to see for a cell of the table if there were no association between the two variables, that is, if political philosophy had no influence on support for the death penalty
• The greater the difference between the observed and expected frequencies, the greater the statistical dependence of the variables

Calculation of Expected Frequencies
To get the expected frequency for a cell (how many people should be in it given the null hypothesis) we multiply its column marginal total by its row marginal proportion. For example, the expected value for the “extremely liberal/favor death penalty” cell is 29 X .775 = 22.5 (purple dot times blue dot). Note that the expected count for “liberal/favor” cell is also .775 of the total # of liberals. The expected count across the “favor” row will be .775 of the column total for that level of the political variable, and across the “oppose” row, .225. The expected percentages will be identical across a row (e.g., across “favor” or across “oppose”) and will be the same as the row marginal percentage

Calculation of Chi-square• 1. For each cell in the contingency table, subtract the expected
from the observed frequency, and square the result. Divide by the expected frequency.• For example, for the cell “favor/extremely liberal,” subtract 22.5
from 16, square the result, and divide by 22.5, for a value for that cell of 1.877
• Repeat this process for all of the cells (not including the total cells). There will be (r-1)(c-1) cells, where r = row and c = column
• Chi square is the sum of the products for all of the cells.

Some Characteristics of Chi-square• Chi square is a positively skewed distribution which becomes less
skewed as the DF increases• Values of chi-square are highly influenced by sample size. It is pretty
easy to get a significant chi-square with a large sample• Use in conjunction with measures of association such as lambda or tau to get
PRE (estimate of proportional reduction of error). It is important to have an adequate number of cases (5 or more) in each cell or that cell becomes influential in the calculation disproportionately to its actual influence
• Collapse categories and recode to increase cell size, and/or increase N• Yates’ continuity correction for 2X2 tables with cell n between 5 and 10
• SPSS output: Likelihood ratio (another test of significance of association between row and column variables based on maximum likelihood estimation Linear by linear association (version of chi-square for ordinal data which assumes data has a near-interval character) Asymptotic significance – tails of the underlying distribution used to do the significance test come as close as you please to the horizontal axis but never meet it, like a normal distribution. Reasonable to assume when N is large. SPSS offers some “exact” tests for use with small N, for example, Fisher’s exact test


















