
NVIDIA Clara Train SDK: AI-Assisted Annotation · 2019-06-27 · NVIDIA Clara Train SDK:...
50
NVIDIA CLARA TRAIN SDK: AI- ASSISTED ANNOTATION DU-09358-002 _v2.0 | June 2019 Getting Started Guide
Transcript of NVIDIA Clara Train SDK: AI-Assisted Annotation · 2019-06-27 · NVIDIA Clara Train SDK:...

NVIDIA CLARA TRAIN SDK: AI-ASSISTED ANNOTATION
DU-09358-002 _v2.0 | June 2019
Getting Started Guide

www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | ii
TABLE OF CONTENTS
Chapter 1. Overview............................................................................................ 1Chapter 2. Requirements and installation of the SDK....................................................2
2.1. Running the container................................................................................... 3Chapter 3. Using the annotation server.....................................................................4
3.1. Annotation server setup................................................................................. 43.2. Integrating into your own application................................................................ 5
Chapter 4. Loading models in the Annotation server.................................................... 64.1. Model configuration...................................................................................... 64.2. Pulling models from the NGC......................................................................... 104.3. Bring your own model.................................................................................. 104.4. Refresh the model configuration..................................................................... 114.5. Delete model.............................................................................................124.6. Verify that model is loaded in the server...........................................................12
Chapter 5. Training and deploying annotation models................................................. 135.1. Preparing data for segmentation..................................................................... 135.2. Next steps................................................................................................ 13
Chapter 6. Appendix........................................................................................... 146.1. Available annotation models.......................................................................... 146.2. Data transforms and augmentations................................................................. 296.3. Client C++ API........................................................................................... 39
6.3.1. AIAA services invoked by the AIAAClient.......................................................396.3.2. AIAA Client provides these methods............................................................406.3.3. nvidiaAIAAListModels:............................................................................. 416.3.4. nvidiaAIAADEXTR3D:............................................................................... 416.3.5. nvidiaAIAASegmentation:......................................................................... 436.3.6. nvidiaAIAAMaskPolygon:........................................................................... 446.3.7. nvidiaAIAAFixPolygon:............................................................................. 44
6.4. Client Python API........................................................................................456.4.1. AIAA services invoked by the AIAAClient object..............................................456.4.2. AIAA Client provides these methods:...........................................................45

www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 1
Chapter 1.OVERVIEW
The NVIDIA Clara Train SDK with AI-Assisted Annotation uses deep learningtechniques to take points of interest drawn by radiologists to approximate points asinput along with the 3D volume data to return an auto-annotated set of slices. Theauto-annotation step is achieved using NVIDIA’s pre-trained deep learning modelsfor different organs. Neither application developers nor radiologists need to haveknowledge of deep learning to benefit from NVIDIA’s deep learning expertise out of thebox.
The Clara Train SDK works in conjunction with the Transfer Learning Toolkit formedical imaging. If you are a developer or an engineer developing medical imageanalysis applications for healthcare providers, this guide can help you to get startedwith integrating the AI-Assisted Annotation SDK into your existing custom applicationsor into existing medical imaging applications such as MITK, or ITK-Snap, without anyprior deep learning knowledge.

www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 2
Chapter 2.REQUIREMENTS AND INSTALLATION OFTHE SDK
Using the Clara Train SDK requires the following:
Hardware Requirements
Recommended
‣ 1 GPU or more‣ 16 GB GPU memory‣ 8 core CPU‣ 32 GB system RAM‣ 80 GB free disk space
Software Requirements
‣ Ubuntu 16.04 LTS‣ NVIDIA GPU driver v410.xx or above‣ nvidia-docker 2.0 installed, instructions: https://github.com/NVIDIA/nvidia-docker.
Installation Prerequisites
‣ NVIDIA GPU driver v410.xx or above. Download from https://www.nvidia.com/Download/index.aspx?lang=en-us.
‣ Install the Nvidia Docker 2.0 from: https://github.com/NVIDIA/nvidia-docker.
Access registration
Get an NGC API Key
‣ NVIDIA GPU Cloud account and API key - https://ngc.nvidia.com/

Requirements and installation of the SDK
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 3
1. Go to NGC and search for Clara Train container in the Catalog tab. Thismessage is displayed, Sign in to access the PULL feature of this repository.
2. Enter your email address and click Next or click Create an Account. 3. Click Sign In. 4. Click the Clara Train SDK tile.
Save the API key in a secure location. You will need it to use the AI assistedannotation SDK.
Download the docker container
‣ Execute docker login nvcr.io from the command line and enter yourusername and password.
‣ Username: $oauthtoken‣ Password: API_KEY
‣ dockerImage=nvcr.io/nvidia/clara-train-sdk:v1.0-py3‣ docker pull $dockerImage
2.1. Running the containerOnce downloaded, run the docker using this command:
docker run -it --rm --ipc=host --net=host --runtime=nvidia --mount type=bind,source=/your/dataset/location,target=/workspace/data $dockerImage /bin/bash
If you are on a network that uses a proxy server to connect to the Internet, you canprovide proxy server details when launching the container. docker run --runtime=nvidia -it --rm -e HTTPS_PROXY=https_proxy_server_ip:https_proxy_server_port -e HTTP_PROXY=http_proxy_server_ip:http_proxy_server_port $dockerImage /bin/bash
The docker, by default, starts in the /opt/nvidia folder. To access local directories fromwithin the docker, they have to be mounted in the docker. To mount a directory, use the-v <source_dir>:<mount_dir> option. For more information, see Bind Mounts.Here is an example:docker run --runtime=nvidia -it --rm -v /home/<username>/tlt-experiments:/workspace/tlt-experiments $dockerImage /bin/bash
This mounts the /home/<username>/tlt-experiments directory in your disk to /workspace/tlt-experiments in docker.

www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 4
Chapter 3.USING THE ANNOTATION SERVER
This chapter describes tasks and information needed to use the Annotation server.
3.1. Annotation server setupWays of running the annotation server
Use the proper account credentials, and the container image name, to pull and run thecontainer for the annotation server as follows:
Run the annotation server with Default options (models will be saved inside dockerhence will not persist).
docker run $NVIDIA_RUNTIME \ -it --rm -p 5000:5000 \ $DOCKER_IMAGE \ start_aas.sh
Run the annotation Server with Advanced options (e.g. mount workspace from hostmachine to persist models/logs/configs).
export AIAA_SERVER_PORT=5000export LOCAL_WORKSPACE=/var/nvidia/aiaaexport REMOTE_WORKSPACE=/workspacedocker run $NVIDIA_RUNTIME \ -it --rm -p $AIAA_SERVER_PORT:5000 \ -v $LOCAL_WORKSPACE:$REMOTE_WORKSPACE \ $DOCKER_IMAGE \ start_aas.sh \ --workspace $REMOTE_WORKSPACE \ --port $AIAA_SERVER_PORT
Workspace
The annotation server uses workspace directory (if not specified default shall be insiderdocker at the path: /var/nvidia/aiaa) for saving configs, models (Frozen), logs etc.
You can shutdown and run the docker multiple times, if you mount an externalworkspace path while running the docker. See the advanced options while running thedocker.

Using the annotation server
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 5
Following are files/folders from workspace directory.
Name Description
aiaa_server_config.json The annotation server supports automaticloading of models and correspondingconfigs are saved in this file.
aiaa_server_dashboard.db The annotation Web/API activities aremonitored through Flask Dashboard andcorresponding data is saved here.
downloads Temporary downloads from NGChappens here and temporary data isremoved after successful import of modelinto the annotation Server.
logs The annotation server logs are stored overhere.
models All serving models in Frozen Format arestored here.
Server logs
Once the server is up and running, you can watch or pull the server logs in a browserthrough http://127.0.0.1:5000/logs?lines=100 to fetch recent 100 lines.
Use http://127.0.0.1:5000/logs?lines=-1 to fetch everything from the current log file.
3.2. Integrating into your own applicationOnce the annotation server is setup and started with specific organ models, clientcomponent of the SDK is delivered as an open source reference implementation todemonstrate the integration process. Client code and libraries are provided for both C++ and Python languages on NVIDIA Github page here: https://github.com/NVIDIA/ai-assisted-annotation-client

www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 6
Chapter 4.LOADING MODELS IN THE ANNOTATIONSERVER
These admin utilities (through curl) are supported in the annotation server tomanage annotation and segmentation models or via a browser interface at e.g.http://127.0.0.1:5000/docs.
Run admin utilities from the docker-host machine addressing as 0.0.0.0 or 127.0.0.1or localhost in the request URI.
4.1. Model configurationThe annotation server needs a configuration for each model which needs to be importedeither from NGC or see section 4.3, Bring your own model, for information on usingyour own model.
‣ NGC - this config is expected to be part of MMAR archive. It is in MMAR/configs/config-aiaa.json otherwise the annotation server will make an attempt to use defaultconfig for some pre-trained models.
‣ User provided models - Upload this configuration along with the model (in CKPT/Frozen format) as part of multi-part/data format.
Segmentation model
Name Type Description Example
version string version of model 1.0

Loading models in the Annotation server
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 7
Name Type Description Example
type string Either annotation orsegmentation
annotation
labels array[string] labels for indicatingthe purpose of thesegmentation orannotation
[spleen]
description string Long description ofmodel
3D annotationmodel for spleen
threshold double Threshold ofprobability forinference
0.5
input_nodes dict Dictionary of inputtensor names
"image":"NV_MODEL
_INPUT"
output_nodes dict Dictionary of outputtensor names
"model":
"NV_MODEL
_OUTPUT"
pre_transforms array[Transform] Array of Transformsare applied beforeinference
[ "name":"tlt2.transforms.
VolumeTo4DArray","args":
"fields": List[ "image","label" ] ]
post_transforms array[Transform] Array of Transformsare applied afterinference
[ "name":"tlt2.transforms.
SplitAcrossChannels",
"args":
"applied_key":"model",
"channel_names":List [
"background","prediction" ] ]

Loading models in the Annotation server
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 8
Name Type Description Example
channel_first boolean Channel Firstshould be used forinference
true
roi array[double] Cropped size [x,y,z]to be used in case ofannotation models
[128,128,128]
Annotation model
Name Type Description Example
sigma double Sigma value;reserved for futureuse
3.0
padding double Padding size usedby clients to preparethe input for theannotation model
20.0
Transform
Name Type Description Example
name string Name of Transform.If you are usingany transformsfrom TLT2library/framwork,you can use"tlt2.transforms.xyz"or direct transformsname.
tlt2.transforms.
or
SplitAcrossChannels
args dict Dictionary whichwill be used as inputto the transformer
"applied_key":"model","channel_names":List [ "background","prediction" ]
Annotation_Spleen
Here's an example of model configuration for a spleen annotation model:
"version": "1", "type": "annotation", "labels": [ "spleen"

Loading models in the Annotation server
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 9
], "description": "A pre-trained model for volumetric (3D) segmentation of the spleen from CT image. It is trained using the runner-up awarded pipeline of the \"Medical Segmentation Decathlon Challenge 2018\" with 32 training images and 9 validation images.", "format": "CKPT", "threshold": 0.5, "roi": [ 128, 128, 128 ], "sigma": 3.0, "padding": 20.0, "input_nodes": "image": "NV_MODEL_INPUT" , "output_nodes": "model": "NV_MODEL_OUTPUT" , "pre_transforms": [ "name": "VolumeTo4DArray", "args": "fields": [ "image", "label" ] , "name": "ScaleIntensityRange", "args": "field": "image", "a_min": -1024, "a_max": 1024, "b_min": -1.0, "b_max": 1.0, "clip": true , "name": "AddExtremePointsChannel", "args": "image_field": "image", "label_field": "label", "sigma": 3, "pert": 0 ], "post_transforms": [ "name": "SplitAcrossChannels", "args": "applied_key": "model", "channel_names": [ "background", "prediction" ] ]

Loading models in the Annotation server
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 10
4.2. Pulling models from the NGCMake sure you have access to the models and download them from NGC.
Start the annotation server
Run the annotation server included in the docker container with default optionsdocker run $NVIDIA_RUNTIME \-it --rm -p 5000:5000 \$DOCKER_IMAGE \start_aas.sh
Once the server is up you can start pulling existing segmentation or annotation modelsfrom NGC.
To use Method 1 you should VNC into the server to http://127.0.0.1. If you are in thedocker command line you should use Method 2.
Method 1
Open in browser http://127.0.0.1:5000/docs/.
Try API "/admin/model/load" and provide Version and complete Model Path whichtypically includes org/team/model.
Method 2curl -X PUT "http://0.0.0.0:5000/admin/model/annotation_ct_spleen" \ -H "accept: application/json" \ -H "Content-Type: application/json" \ -d '"path":"nvidia/med/annotation_ct_spleen","version":"1"'
This assumes config_aiaa.json is present in MMAR package under ROOT/ orROOT/config/
1. If you are pulling MMAR model from NGC, config/config_aiaa.json is present 2. Corresponding <model_name>.json is present in docker at /opt/nvidia/
medical/tlt2/src/apps/aas/configs/models
If the required config_aiaa.json is missing in MMAR package, then you have touse the BYOM method described in the next section to push the new model to theannotation server.
4.3. Bring your own modelThis release enables you to use your own models in the annotation server, if you do notwant to use the models developed by Nvidia. Follow the instructions in this section touse your own models.
Train your model
1. Train your own model using Tensorflow. For example you can use V-Net basedsegmentation models to train.
2. Save your model using Tensorflow CheckPoint format (currently only theCheckPoint format is supported on the Annotation Server).

Loading models in the Annotation server
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 11
3. If you have TensorRT version of the model, mode.trt.pb, you can provide itdirectly instead of in the CheckPoint format.
Prepare your model for deployment
1. Prepare corresponding config-aiaa.json (ModelConfig) with respect to theannotation server. For more on ModelConfig refer: http://127.0.0.1:5000/#tag/Admin-(model)/paths/~1admin~1model~1model/put.
2. Deploy required python libraries (to support own pre-transforms/post-transforms)into annotation server manually (through bash).
3. Prepare a zip which includes the model check point and related
files.
Deploy your model
1. You can use CURL or API tryout interface through browser to upload model.zip andconfig-aiaa.json to the annotation server.
2. The best approach is to "Try-Out" upload options through the annotation server inbrowser mode by visiting http://127.0.0.1:5000/docs/.
Here are three examples:curl -X PUT "http://127.0.0.1:5000/admin/model/byom_segmentation_spleen" \ -F "[email protected];type=application/json" \ -F "[email protected]"
# If you have MMAR archivecurl -X PUT "http://127.0.0.1:5000/admin/model/segmentation_ct_spleen" \ -F "[email protected];type=application/json" -F "data=@segmentation_ct_spleen.with_models.tgz"
# If you have MMAR archive (if model config is skipped, it will search config_aiaa.json inside Archive)curl -X PUT "http://127.0.0.1:5000/admin/model/segmentation_ct_spleen" \ -F "data=@segmentation_ct_spleen.with_models.tgz"
4.4. Refresh the model configurationIf you want to update the configuration without updating the model, you can do this byrefreshing the configs and reloading an existing model with new configs.
Here's an example:curl -X PATCH "http://127.0.0.1:5000/admin/model/byom_segmentation_spleen" \ -H "Content-Type: application/json" \ -d @config-aiaa.json

Loading models in the Annotation server
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 12
4.5. Delete modelHere's an example of deleting a model:curl -X DELETE "http://127.0.0.1:5000/admin/model/byom_segmentation_spleen"
4.6. Verify that model is loaded in the serverThe annotation server responds to models API to list all models currently loaded. Inyour shell, run this command:curl http://$MACHINE_IP:5000/v1/models
You should see results similar to this:["sigma": 3.0, "internal name": "annotation_spleen", "labels": ["spleen"], "type": "annotation", "description": "A pre-trained model for volumetric (3D) segmentation of the spleen from CT image. It is trained using the runner-up awarded pipeline of the Medical Segmentation Decathlon Challenge 2018 with 32 training images and 9 validation images.", "roi": [128, 128, 128], "padding": 20.0, "name": "annotation_spleen", "version": "1"]

www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 13
Chapter 5.TRAINING AND DEPLOYING ANNOTATIONMODELS
5.1. Preparing data for segmentationSee Working with Classification and Segmentation Models in the Clara Train SDK:Transfer Learning Getting Started Guide for details on preparing data for use withtransfer learning for classification tasks.
5.2. Next stepsFor Training and Deploying new model using your own data, please see, Medical ModelArchive in the Clara Train SDK: Transfer Learning Getting Started Guide.
‣ Training the model: Run train.sh to train the model.‣ Exporting the model to a Tensorrt Optimized Model Inference: Run export.sh to
export the model.‣ Running inference: Run infer.sh to run inference on the model.‣ Evaluating the model: Run evaluate.sh to evaluate the model a list of images
based on a set of ground truth labels.

www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 14
Chapter 6.APPENDIX
6.1. Available annotation modelsHere are the list of pre-trained annotation models available on NGC. Configuration filesfor using the models in the annotation server are inside MMAR archives on NGC.
Annotation models were trained with our AIAA 3D model (dextr3D) using a trainingapproach similar to [1] where the user input (extreme point clicks) is modeled as 3DGaussians in an additional input channel to the network. The network architectureeither is derived from [2] and initialized with ImageNet pre-trained weights or using ourmodel architecture developed for brain lesion segmentation [3]. During training, pointclicks are "simulated" from the ground truth."
[1] Maninis, Kevis-Kokitsi, et al. "Deep extreme cut: From extreme points to objectsegmentation." Proceedings of the IEEE Conference on Computer Vision and PatternRecognition. 2018. https://arxiv.org/abs/1711.09081.
[2] Liu, Siqi, et al. "3d anisotropic hybrid network: Transferring convolutional featuresfrom 2d images to 3d anisotropic volumes." International Conference on MedicalImage Computing and Computer-Assisted Intervention. Springer, Cham, 2018. https://arxiv.org/abs/1711.08580.
[3] Myronenko, Andriy. "3D MRI brain tumor segmentation using autoencoderregularization." International MICCAI Brainlesion Workshop. Springer, Cham, 2018.https://arxiv.org/abs/1810.11654.
Annotation model Description
Brain tumor annotation
‣ annotation_mri_brain_tumors_t1ce_tc A pre-trained model for volumetric (3D)annotation of brain tumors from T1c MRIs.
This model was trained using our AIAA3D model (dextr3D) using a training

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 15
Annotation model Description
approach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is detailed in [1]. Duringtraining point clicks are "simulated" fromthe ground truth labels.
The model was trained to segment the"tumor core" (TC) based on T1c (T1contrast). It utilized an approach similarto what was described in "3D MRI braintumor annotation using autoencoderregularization," a winning method inMultimodal Brain Tumor annotationChallenge (BraTS) 2018. The labelleddataset from BraTS 2018 was paritioned,based on our own split, into 256 trainingdata and 29 validation data, as shown inconfig/anno_brats18_datalist_t1ce.json.
For more detailed description of tumorregions, please see the MultimodalBrain Tumor Segmentation Challenge(BraTS) 2018 data page at https://www.med.upenn.edu/sbia/brats2018/data.html.
The provided training configurationrequired 16GB GPU memory.
Model Input Shape: 128 x 128 x 128
Training Script: train.sh
Training algorithm based on [1]; Fordetails of model architecture, see [3].
Model input and output:
‣ Input: 1 channel T1c MRIs scan images‣ Output: 2 channels for background &
foreground
This Dice score on the validation dataachieved by this model is 0.882.
‣ annotation_mri_brain_tumors_t2_wt A pre-trained model for volumetric (3D)annotation of brain whole tumors from T2MRIs.

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 16
Annotation model Description
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is detailed in [1]. Duringtraining point clicks are "simulated" fromthe ground truth labels.
This model resembles"annotation_mri_brain_tumors_t1ce_tc"model, except the input in another MRIchannel is used as input (T2) and theoutput is the "whole tumor" region (WT).Both utilized an approach similar towhat was described in "3D MRI braintumor annotation using autoencoderregularization," a winning method inMultimodal Brain Tumor annotationChallenge (BraTS) 2018. The labelleddataset from BraTS 2018 was paritioned,based on our own split, into 256 trainingdata and 29 validation data for thistraining task, as shown in config/anno_brats18_datalist_t2.json.
For more detailed description of tumorregions,please see the MultimodalBrain Tumor Segmentation Challenge(BraTS) 2018 data page at https://www.med.upenn.edu/sbia/brats2018/data.html.
The provided training configurationrequired 16GB GPU memory.
Model Input Shape: 128 x 128 x 128
Training Script: train.sh
Training algorithm based on [1]; Fordetails of model architecture, see [3].
‣ Model input and output:‣ Input: 1 channel T2 MRI‣ Output: 2 channels for background &
foreground
This Dice score on the validation dataachieved by this model is 0.893.

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 17
Annotation model Description
Liver annotation
‣ annotation_ct_liver A pre-trained model for volumetric (3D)annotation of the liver in portal venousphase CT image.
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is derived from [3] andinitialized with ImageNet pre-trainedweights. During training point clicks are"simulated" from the ground truth labels.
This model was trained using the Liverdataset, as part of "Medical SegmentationDecathlon Challenge 2018". It consists of131 labelled data and 70 unlabelled data.The labelled data was partitioned, basedon our own split, into 104 training imagesand 27 validation images for this trainingtask, as shown in config/dataset_0.json.
For more detailed description of "MedicalSegmentation Decathlon Challenge 2018,"see http://medicaldecathlon.com/.
The training dataset is Task03_Liver.tarfrom the link above. The data must beconverted to 1mm resolution beforetraining:tlt-dataconvert -d $SOURCE_IMAGE_ROOT -r 1 -s .nii.gz -e .nii -o $DESTINATION_IMAGE_ROOT
to match up with the defaultsetting, we suggest that$DESTINATION_IMAGE_ROOTmatch DATA_ROOT as defined inenvironment.json in this MMAR'sconfig folder.
The provided training configurationrequired 16GB GPU memory.
Data Conversion: convert to resolution1mm x 1mm x 1mm

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 18
Annotation model Description
Model Input Shape: 128 x 128 x 128
Training Script: train.sh
Training algorithm based on [1]; Fordetails of model architecture, see [2].
Model input and output:
‣ Input: 1 channel CT image‣ Output: 2 channels for background &
foreground
This Dice score on the validation dataachieved by this model is 0.956.
Liver tumor annotation
‣ annotation_ct_liver_tumor A pre-trained model for volumetric (3D)annotation of the liver tumor in portalvenous phase CT image.
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is derived from [3] andinitialized with ImageNet pre-trainedweights. During training point clicks are"simulated" from the ground truth labels.
This model was trained with both theLiver and Hepatic Vessel dataset, as partsof "Medical Segmentation DecathlonChallenge 2018". Only data includinglabelled tumor were selected into ourdataset. The dataset was then partitioned,based on our own split, into 254 trainingimages and 83 validation images forthis training task, as shown in config/anno_liver_tumor_dataset.json.
For more detailed description of "MedicalSegmentation Decathlon Challenge 2018,"please see http://medicaldecathlon.com/.
The training dataset isTask08_HepaticVessel.tar andTask03_Liver.tar from the link above.

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 19
Annotation model Description
The data must be converted to 1mmresolution before training:
tlt-dataconvert -d $SOURCE_IMAGE_ROOT -r 1 -s .nii.gz -e .nii -o $DESTINATION_IMAGE_ROOT
to match up with the defaultsetting, we suggest that$DESTINATION_IMAGE_ROOTmatch DATA_ROOT as defined inenvironment.json in this MMAR'sconfig folder.
The provided training configurationrequired 16GB GPU memory.
Data Conversion: convert to resolution1mm x 1mm x 1mm
Model Input Shape: 128 x 128 x 128
Training Script: train.sh
Training algorithm based on [1]; Fordetails of model architecture, see [2].
Model input and output:
‣ Input: 1 channel CT image‣ Output: 2 channels for background &
foreground
This Dice score on the validation dataachieved by this model is 0.788.
Hippocampus annotation
‣ annotation_mri_hippocampus A pre-trained model for volumetric (3D)segmentation of the hippocampus headand body from mono-modal MRI image.
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is derived from [3] andinitialized with ImageNet pre-trainedweights. During training point clicks are"simulated" from the ground truth labels.

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 20
Annotation model Description
This model is trained with 208 trainingimages and 52 validation images.
Training Data Source:Task04_Hippocampus.tar from http://medicaldecathlon.com/ The data wasconverted to resolution 1mm x 1mm x1mm for training, using the followingcommand:
tlt-dataconvert -d $SOURCE_IMAGE_ROOT -r 1 -s .nii.gz -e .nii.gz -o $DESTINATION_IMAGE_ROOT
The training was performed withcommand train.sh, which required 12GB-memory GPUs.
Training Graph Input Shape: 128 x 128 x128
Training algorithm based on [1]; Fordetails of model architecture, see [2].
Model input and output:
‣ Input: 1 channel MRI image‣ Output 2 channels:
‣ Label 1: hippocampus‣ Label 0: everything else.
This model achieve the following Dicescore on the validation data (our own splitfrom the training dataset): Hippocampus:0.873 (mean_dice1: 0.886 mean_dice2:0.865)
Lung tumor annotation
‣ annotation_ct_lung_tumor A pre-trained model for volumetric (3D)annotation of the lung tumors from CTimage.
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is derived from [3] andinitialized with ImageNet pre-trained

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 21
Annotation model Description
weights. During training point clicks are"simulated" from the ground truth labels.
This model is trained with 50 trainingimage pairs and 13 validation images.
The training dataset is Task06_Lung.tarfrom http://medicaldecathlon.com/.
The data was converted to resolution 1mmx 1mm x 1mm for training.tlt-dataconvert -d $SOURCE_IMAGE_ROOT -r 1 -s .nii.gz -e .nii.gz -o $DESTINATION_IMAGE_ROOT
To match up with the defaultsetting, we suggest that$DESTINATION_IMAGE_ROOTmatch DATA_ROOT as defined inenvironment.json in this MMAR'sconfig folder.
The training was performed withcommand train.sh, which required 16GB-memory GPUs.
Training Graph Input Shape: 128 x 128x128
Training algorithm based on [1]; Fordetails of model architecture, see [2].
Model input and output:
‣ Input: 1 channel CT image‣ Output: 2 channels for background &
foreground
This model achieves the following Dicescore on the validation data (our own splitfrom the training dataset):
‣ Lung tumor: 0.79
Prostate annotation
‣ annotation_mri_prostate_cg_and_pz A pre-trained model for volumetric (3D)segmentation of the prostate central glandand peripheral zone from the multimodalMR (T2, ADC).

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 22
Annotation model Description
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is derived from [3] andinitialized with ImageNet pre-trainedweights. During training point clicks are"simulated" from the ground truth labels.
Training Data Source: Task05_Prostate.tarfrom http://medicaldecathlon.com/ Thedata was converted to resolution 1mmx 1mm x 1mm for training using thefollowing command:tlt-dataconvert -d $SOURCE_IMAGE_ROOT -r 1 -s .nii.gz -e .nii.gz -o $DESTINATION_IMAGE_ROOT.
The training was performed withcommand train.sh, which required 16GB-memory GPUs.
Training Graph Input Shape: 128 x 128 x128
Training algorithm based on [1]; Fordetails of model architecture, see [2].
This model achieves the following Dicescore on the validation data (our own splitfrom the training dataset):
‣ Prostate central gland and peripheralzone: 0.74
Model input and output:
‣ Input: 2 channel MRI image‣ Output 2 channels:
‣ Label 1: prostate‣ Label 0: everything else
This model achieve the following Dicescore on the validation data (our own splitfrom the training dataset): Prostate: 0.743(mean_dice1: 0.506 mean_dice2: 0.883)
Left atrium annotation

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 23
Annotation model Description
‣ annotation_mri_left_atrium A pre-trained model for volumetric (3D)annotation of the left atrium from MRIimage.
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is derived from [3] andinitialized with ImageNet pre-trainedweights. During training point clicks are"simulated" from the ground truth labels.
This model is trained with 16 trainingimage pairs and 4 validation images.
The training dataset is Task02_Heart.tarfrom http://medicaldecathlon.com/.
The data was converted to resolution 1mmx 1mm x 1mm for training. tlt-dataconvert -d $SOURCE_IMAGE_ROOT -r 1 -s .nii.gz -e .nii.gz -o $DESTINATION_IMAGE_ROOT
To match up with the defaultsetting, we suggest that$DESTINATION_IMAGE_ROOTmatch DATA_ROOT as defined inenvironment.json in this MMAR'sconfig folder.
The training was performed withcommand train.sh, which required 16GB-memory GPUs.
Training Graph Input Shape: 128 x 128x128
Training algorithm based on [1]; Fordetails of model architecture, see [2].
Model input and output:
‣ Input: 1 channel MRI image‣ Output: 2 channels for background &
foreground

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 24
Annotation model Description
This model achieves the following Dicescore on the validation data (our own splitfrom the training dataset): Left Atrium:0.92
Pancreas
‣ annotation_ct_pancreas A pre-trained model for volumetric(3D)annotation of the colon from CTimage.
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is derived from [3] andinitialized with ImageNet pre-trainedweights. During training point clicks are"simulated" from the ground truth labels.
This model was trained with the Pancreasdataset, as part of "Medical SegmentationDecathlon Challenge 2018". It consistsof 281 labelled data and 139 unlabelleddata. The labelled data were partitioned,based on our own split, into 224 trainingimages and 57 validation images forthis training task, as shown in config/dataset_0.json.
For more detailed description of "MedicalSegmentation Decathlon Challenge 2018,see http://medicaldecathlon.com/.
The training dataset is Task07_Pancreas.tarfrom the link above.
The data must be converted to 1mmresolution before training:tlt-dataconvert -d $SOURCE_IMAGE_ROOT -r 1 -s .nii.gz -e .nii -o $DESTINATION_IMAGE_ROOT
To match up with the defaultsetting, we suggest that$DESTINATION_IMAGE_ROOTmatch DATA_ROOT as defined in

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 25
Annotation model Description
environment.json in this MMAR'sconfig folder.
The provided training configurationrequired 16GB GPU memory.
Data Conversion: convert to resolution1mm x 1mm x 1mm
Model Input Shape: 128 x 128 x 128
Training Script: train.sh
Training algorithm based on [1]; Fordetails of model architecture, see [2].
Model input and output:
‣ Input: 1 channel CTimage‣ Output: 2 channels for background &
foreground
This model achieves the following Dicescore on the validation data (our own splitfrom the training dataset):
‣ Pancreas (including tumor): 0.840
Colon tumor annotation
‣ annotation_ct_colon_tumor A pre-trained model for volumetric (3D)annotation of the colon from CT image.
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is derived from [3] andinitialized with ImageNet pre-trainedweights. During training point clicks are"simulated" from the ground truth labels.
This model is trained with 100 trainingimage pairs and 26 validation images.
The training dataset is Task10_Colon.tarfrom http://medicaldecathlon.com/.
The data was converted to resolution 1mmx 1mm x 1mm for training.

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 26
Annotation model Description
tlt-dataconvert -d $SOURCE_IMAGE_ROOT -r 1 -s .nii.gz -e .nii -o $DESTINATION_IMAGE_ROOT
To match up with the defaultsetting, we suggest that$DESTINATION_IMAGE_ROOTmatch DATA_ROOT as defined inenvironment.json in this MMAR'sconfig folder.
The training was performed withcommand train.sh, which required16GB-memory GPUs.
Training Graph Input Shape: 28 x 128 x128
Model input and output:
‣ Input: 1 channel CT image‣ Output: 2 channels for background &
foreground
This model achieves the following Dicescore on the validation data (our own splitfrom the training dataset): colon: 0.68
Hepatic vessel annotation
‣ annotation_ct_hepatic_vessel A pre-trained model for volumetric (3D)annotation of the hepatic vessel CT image.
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is derived from [3] andinitialized with ImageNet pre-trainedweights. During training point clicks are"simulated" from the ground truth labels.
This model was trained on the Hepaticvessel dataset, as part of "MedicalSegmentation Decathlon Challenge 2018".It consists of 303 labelled data and 140unlabelled data. The labelled data waspartitioned, based on our own split, into242 training images and 61 validation

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 27
Annotation model Description
images for this training task, as shown inconfig/dataset_0.json.
For more detailed description of "MedicalSegmentation Decathlon Challenge 2018,"see http://medicaldecathlon.com/.
The training dataset isTask08_HepaticVessel.tar from the linkabove.
The data must be converted to 1mmresolution before training:tlt-dataconvert -d$SOURCE_IMAGE_ROOT -r1 -s .nii.gz -e .nii -o$DESTINATION_IMAGE_ROOT
To match up with the defaultsetting, we suggest that$DESTINATION_IMAGE_ROOTmatch DATA_ROOT as defined inenvironment.json in this MMAR'sconfig folder.
The provided training configurationrequired 16GB GPU memory.
Data Conversion: convert to resolution1mm x 1mm x 1mm
Training Script: train.sh
Training algorithm based on [1]; Fordetails of model architecture, see [2].
Model input and output:
‣ Input: 1 channel CTimage‣ Output: 2 channels for background &
foreground
This model achieves the following Dicescore on the validation data (our own splitfrom the training dataset):
‣ Hepatic vessel: 0.564
Spleen annotation
‣ annotation_ct_spleen A pre-trained model for volumetric (3D)annotation of the spleen from CT image.

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 28
Annotation model Description
This model was trained using our AIAA3D model (dextr3D) using a trainingapproach similar to [6] where the userinput (extreme point clicks) is modeledas 3D Gaussians in an additional inputchannel to the network. The networkarchitecture is derived from [3] andinitialized with ImageNet pre-trainedweights. During training point clicks are"simulated" from the ground truth labels.
The training dataset is Task09_Spleen.tarfrom http://medicaldecathlon.com/.
The data was converted to 1mm resolutionbefore training: tlt-dataconvert -d $SOURCE_IMAGE_ROOT -r 1 -s .nii.gz -e .nii.gz -o $DESTINATION_IMAGE_ROOT
To match up with the defaultsetting, we suggest that$DESTINATION_IMAGE_ROOTmatch DATA_ROOT as defined inenvironment.json in this MMAR'sconfig folder.
The training was performed withcommand train.sh, which required 16GB-memory GPUs.
Training Graph Input Shape: 128 x 128x128
Training algorithm based on [1]; Fordetails of model architecture, see [2].
Model input and output:
‣ Input: 1 channel CTimage‣ Output: 2 channels for background &
foreground‣ Training algorithm based on [1]; For
details of model architecture, see [2].
This model achieves the following Dicescore on the validation data (our own splitfrom the training dataset):
‣ Spleen: 0.96

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 29
[1] Myronenko, Andriy. "3D MRI brain tumor segmentation using autoencoderregularization." International MICCAI Brainlesion Workshop. Springer, Cham,2018.https://arxiv.org/abs/1810.11654.
[2] Xia, Yingda, et al. "3D Semi-Supervised Learning with Uncertainty-AwareMulti-View Co-Training." arXiv preprint arXiv:1811.12506 (2018).https://arxiv.org/abs/1811.12506.
[3] Liu, Siqi, et al. "3d anisotropic hybrid network: Transferring convolutional featuresfrom 2d images to 3d anisotropic volumes." International Conference on Medical ImageComputing and Computer-Assisted Intervention. Springer, Cham, 2018.https://arxiv.org/abs/1711.08580.
[4] Huang, Gao, et al. "Densely connected convolutional networks." Proceedings of theIEEE conference on computer vision and pattern recognition. 2017.https://arxiv.org/abs/1608.06993.
[5] Wang, Xiaosong, et al. "Chestx-ray8: Hospital-scale chest x-ray database andbenchmarks on weakly-supervised classification and localization of common thoraxdiseases." Proceedings of the IEEE conference on computer vision and patternrecognition. 2017.https://arxiv.org/abs/1705.02315.
[6] Maninis, Kevis-Kokitsi, et al. "Deep extreme cut: From extreme points to objectsegmentation." Proceedings of the IEEE Conference on Computer Vision and PatternRecognition. 2018.https://arxiv.org/abs/1711.09081.
6.2. Data transforms and augmentationsHere is a list of built-in data transformation functions. If you need additionaltransformation functions, please contact us at the TLT user forum: http://devtalk.nvidia.com.
Transforms Description
LoadNifty Load NIfTI data. The value of each key(specified by fields) in input "dict" can be astring (a path to a single NIfTI file) or a listof strings (several paths to multiple NIfTIfiles, if there are several channels saved asseparate files).
‣ init_args:
- fields: string or list of strings
key_values to apply, e.g. ["image","label"].
‣ Returns:
- Each field of "dict" is substituted by a4D numpy array.

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 30
Transforms Description
VolumeTo4dArray Transforms the value of each key(specified by fields) in input "dict" from3D to 4D numpy array by expanding onechannel, if needed.
‣ init_args:
- fields: string or list of strings
key_values to apply, e.g. ["image","label"].
‣ Returns:
- Each field of "dict" is substituted by a4D numpy array.
ScaleIntensityRange Randomly shift the intensity level of thenumpy array.
‣ init_args:
- field: string
one key_value to apply, e.g. "image".
- magnitude: float
quantity scale of shift, has to begreater than zero.
ScaleIntensityOscillation Randomly shift scale level for image.
‣ Args:
‣ field: key string, e.g. "image".‣ magnitude: quantity of scale shift,
has to be greater than zero.‣ Returns
‣ Data with an offset on intensityscale.
data with an offset on intensity scale.
CropSubVolumePosNegRatioCtrlEpoch Randomly crop the foreground andbackground ROIs from both the imageand mask for training. The sampling ratiobetween positive and negative samples isadjusted with the epoch number.
‣ init_args:
- image_field: string

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 31
Transforms Description
one key_value to apply, e.g. "image".
- label_field: string
one key_value to apply, e.g. "label".
- size: list of ints
cropped ROI size, e.g., [96, 96, 96].
- ratio_start: float
positive/negative ratio when trainingstart.
- ratio_end: float
positive/negative ratio when trainingend.
- ratio_step: float
changing of positive/negative ratioafter each step.
- num_epochs: int
epochs of one step.
‣ Returns:
- Updated dictionary with croppedROI image and mask
transforms_fastaug.
TransformVolumeCropROIFast
PosNegRatio
Fast 3D data augmentation method (CPUbased) by combining 3D morphologicaltransforms (rotation, elastic deformation,and scaling) and ROI cropping. Thesampling ratio is specified by pos/neg.
‣ init_args:
- applied_keys: string or list of strings
key_values to apply, e.g. ["image","label"].
- size: list of int
cropped ROI size, e.g., [96, 96, 96].
- deform: boolean
whether to apply 3D deformation.
- rotation: boolean
whether to apply 3D rotation.

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 32
Transforms Description
- rotation_degree: float
the degree of rotation, e.g., 15 meansrandomly rotate the image/label in arange [-15, +15].
- scale: boolean
whether to apply 3D scaling.
- scale_factor: float
the percentage of scaling, e.g., 0.1means randomly scaling the image/label in a range [-0.1, +0.1].
- pos: float
the factor controlling the ratio ofpositive ROI sampling.
- neg: float
the factor controlling the ratio ofnegative ROI sampling.
‣ Returns:
- Updated dictionary with croppedROI image and mask after dataaugmentation.
AdjustContrast Randomly adjust the contrast of the field ininput "dict".
‣ init_args:
- field: string
one key_value to apply, e.g. "image".
AddGaussianNoise Randomly add Gaussian noise to the fieldin input "dict".
‣ init_args:
- field: string
one key_value to apply, e.g. "image".
LoadPng Load png image and the label. The valueof "image" must be a string (a path toa single png file) while the value of the"label" must be a list of labels.

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 33
Transforms Description
‣ init_args:
- fields: string or list of strings
key_values to apply, e.g. ["image","label"].
‣ Returns:
- "image" of "dict" is substituted by a3D numpy array while the "label" of"dict" is substituted by a numpy list
CropRandomSubImageInRange Randomly crop 2D image. The crop sizeis randomly selected between lower_sizeand image size.
‣ init_args:
- lower_size: int or float
lower limit of crop size, if float, thenmust be fraction <1
- max_displacement: float
max displacement from center to crop
- keep_aspect: boolean
if true, then original aspect ratio iskept
‣ Returns:
- The "image" field of input "dict" issubstituted by cropped ROI image.
NPResizeImage Resize the 2D numpy array (channel xrows x height) as an image.
‣ init_args:
- applied_keys: string
one key_value to apply, e.g. "image".
- output_shape: list of int with length 2
e.g., [256,256].
- data_format: string
''channels_first', 'channels_last', or'grayscale'.

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 34
Transforms Description
NP2DRotate Rotate 2D numpy array, or channelled 2Darray. If random is set to true, then rotatewithin the range of [ -angle, angle]
‣ init_args:
- applied_keys: string
one key_value to apply, e.g. "image".
- angle: float
e.g. 7.
- random: boolean
default is false.
NPExpandDims Add a singleton dimension to the selectedaxis of the numpy array.
‣ init_args:
- applied_keys: string or list of strings
key_values to apply, e.g. ["image","label"].
- expand_axis: int
axis to expand, default is 0
NPRepChannels Repeat a numpy array along specifiedaxis, e.g., turn a grayscale image into a 3-channel image.
‣ init_args:
- applied_keys: string or list of strings
key_values to apply, e.g. ["image","label"].
- channel_axis: int
the axis along which to repeat values.
- repeat: int
the number of repetitions for eachelement.
CenterData Center numpy array's value by subtractinga subtrahend and dividing by a divisor.
‣ init_args:

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 35
Transforms Description
- applied_keys: string or list of strings
key_values to apply, e.g. ["image","label"].
- subtrahend: float
subtrahend. If None, it is computed asthe mean of dict[key_value].
- divisor: float
divisor. If None, it is computed as thestd of dict[key_value]
NPRandomFlip3D Flip the 3D numpy array along randomaxes with the provided probability.
‣ init_args:
- applied_keys: string or list of strings
key_values to apply, e.g. ["image","label"].
- probability: float
probability to apply the flip, valuebetween 0 and 1.0.
NPRandomZoom3D Apply a random zooming to the 3Dnumpy array.
‣ init_args:
- applied_keys: string or list of strings
key_values to apply, e.g. ["image","label"].
- lower_limits: list of float
lower limit of the zoom along eachdimension.
- upper_limits: list of float
upper limit of the zoom along eachdimension.
- data_format: string
'channels_first' or "channels_last".
- use_gpu: boolean

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 36
Transforms Description
whether to use cupy for GPUacceleration. Default is false.
- keep_size: boolean
default is false which means thisfunction will change the size of thedata array after zooming. Settingkeep_size to True will result in anoutput of the same size as the input.
CropForegroundObject Crop the 4D numpy array and resize.The numpy array must have foregroundvoxels.
‣ init_args:
- size: list of int
resized size.
- image_field: string
"image".
- label_field: string
"label".‣ pad: int number of voxels for adding a
margin around the object‣ foreground_only: boolean whether
to treat all foreground labels as onebinary label (default) or whether toselect foreground label at random.
‣ keep_classes : boolean; if true, keeporiginal label indices in label image(no thresholding), useful for multi-class tasks.
‣ pert: int; random perturbation ineach dimension added to padding (invoxels).
NPRandomRot90_XY Rotate the 4D numpy array along randomaxes on XY plane (axis = (1, 2)).
‣ init_args:
- applied_keys: string
one key_value to apply, e.g. "image".
- probability: float
Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 37
Transforms Description
probability to utilize the transform,between 0 and 1.0.
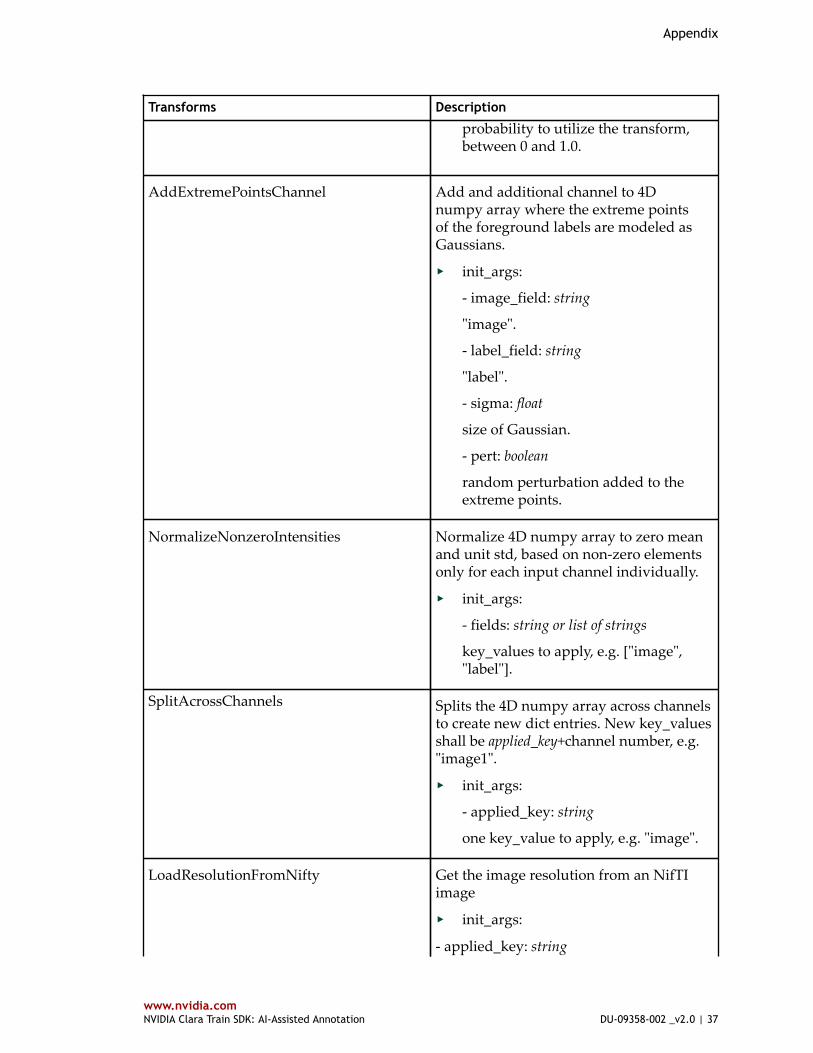
AddExtremePointsChannel Add and additional channel to 4Dnumpy array where the extreme pointsof the foreground labels are modeled asGaussians.
‣ init_args:
- image_field: string
"image".
- label_field: string
"label".
- sigma: float
size of Gaussian.
- pert: boolean
random perturbation added to theextreme points.
NormalizeNonzeroIntensities Normalize 4D numpy array to zero meanand unit std, based on non-zero elementsonly for each input channel individually.
‣ init_args:
- fields: string or list of strings
key_values to apply, e.g. ["image","label"].
SplitAcrossChannels Splits the 4D numpy array across channelsto create new dict entries. New key_valuesshall be applied_key+channel number, e.g."image1".
‣ init_args:
- applied_key: string
one key_value to apply, e.g. "image".
LoadResolutionFromNifty Get the image resolution from an NifTIimage
‣ init_args:
- applied_key: string

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 38
Transforms Description
one key_value to apply, e.g. "image".
‣ Returns:
- "dict" has a new key-value pair:dict[applied_key+"_resolution"]:resolution of the NIfTI image
Load3DShapeFromNumpy Get the image shape from an NifTI image
‣ init_args:
- applied_key: string
one key_value to apply, e.g. "image".
‣ Returns:
- "dict" has a new key-value pair:dict[applied_key+"_shape"]: shape ofthe NIfTI image
ResampleVolume Resample the 4D numpy array fromcurrent resolution to a specific resolution
‣ init_args:
- applied_key: string
one key_value to apply, e.g. "image".
- resolution: list of float
input image resolution.
- target_resolution: list of float
target resolution.
BratsConvertLabels Brats data specific. Convert input labelsformat (indices 1,2,4) into proper format.
‣ init_args:
- fields: string or list of strings
key_values to apply, e.g. ["image", "label"].
CropSubVolumeRandomWithinBounds Crops a random subvolume from withinthe bounds of 4D numpy array.
‣ init_args:
- fields: string or list of strings
key_values to apply, e.g. ["image","label"].

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 39
Transforms Description
- size: list of int
the size of the crop region e.g.[224,224,128].
FlipAxisRandom Flip the numpy array along its dimensionsrandomly.
‣ init_args:
- fields: string or list of strings
key_values to apply, e.g. ["image","label"].
- axis : list of ints
which axes to attempt to flip (e.g.[0,1,2] - for all 3 dimensions) - the axisindices must be provided only forspatial dimensions.
CropSubVolumeCenter Crops a center subvolume from within thebounds of 4D numpy array.
‣ init_args:
- fields: string or list of strings
key_values to apply, e.g. ["image","label"].
- size: list of int
the size of the crop regione.g. [224,224,128] (similar toCropSubVolume
RandomWithinBounds,
but crops the center)
6.3. Client C++ API
6.3.1. AIAA services invoked by the AIAAClientThe AIAA object is constructed with the IP address, port, and version of the AIAAserverclient = client_api.AIAAClient(ip, port, api_version)

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 40
6.3.2. AIAA Client provides these methods 1. models(): supported model list; 2. dextr3d(): 3D image segmentation using DEXTR3D method; 3. segmentation(): 3D image segmentation using classical segmentation model; 4. mask2PolygonConversion(): 3D binary mask to polygon representation conversion 5. fixPolygon(): 2D polygon update with single point edit.
Here's an example using the AIAA Client APIs#include <nvidia/aiaa/client.h>
// Create AIAA Client Objectnvidia::aiaa::Client client("http://10.110.45.66:5000/v1");
try
// models():: Get all the models supported by AIAA Server nvidia::aiaa::ModelList modelList = client.models(); std::string label = "spleen";
// Get Matching Model for a given label nvidia::aiaa::Model model = modelList.getMatchingModel(label); std::cout << model << std::endl; std::string inputImageFile = "image.nii.gz"; std::string outputDextra3dImageFile = "result.nii.gz"; nvidia::aiaa::Point3DSet pointSet = nvidia::aiaa::Point3DSet::fromJson("[[1,2,3]"]);
// dextra3d():: Call dextra3D API for a given model, pointSet int ret1 = client.dextr3d(model, pointSet, inputImageFile, outputDextra3dImageFile);
// dextra3d():: Call dextra3D API for a given label, pointSet, PAD and ROI double PAD = 20; std::string ROI_SIZE = "128x128x128"; double SIGMA = 3; int ret2 = client.dextr3d(label, pointSet, inputImageFile, outputDextra3dImageFile, PAD, ROI_SIZE, SIGMA);
// mask2Polygon():: Call mask2Polygon API to get slice-wise polygon set int pointRatio = 10; nvidia::aiaa::PolygonsList result = client.mask2Polygon(pointRatio, outputDextra3dImageFile); std::cout << result << std::endl; // [[], [[[169,66],[163,74],[[[169,66],[163,74],[175,66]]]]
int neighborhoodSize = 10;
nvidia::aiaa::Polygons p1 = nvidia::aiaa::Polygons::fromJson("[[10,20],[20,30]" nvidia::aiaa::Polygons p2 = nvidia::aiaa::Polygons::fromJson("[[10,20],[21,31]]"); int polygonIndex = 0; int vertexIndex = 1; std::string input2DImageFile = "image_slice_2D.png"; std::string output2DImageFile = "updated_slice_2D.png";
// fixPolygon():: Call Fix Polygon with new Polygon Points nvidia::aiaa::Polygons result = client.fixPolygon(p1, p2, neighborhoodSize, polygonIndex, vertexIndex, input2DImageFile, output2DImageFile); std::cout << result << std::endl;

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 41
// [[11,21],[21,31]]
catch (aiaa::nvidia::exception &e) std::cerr << "nvidia::aiaa::exception => nvidia.aiaa.error." << e.id << "; description: " << e.name() << std::endl;
6.3.3. nvidiaAIAAListModels:nvidiaAIAAListModels: provides implementation for nvidia::aiaa::Client::model()
These options are available:
Option Description Default Example
-h Prints the helpinformation
-server Server URI for theannotation server
-server
http://10.110.45.66:5000/v1
-label Label Name formatching
-label liver
-model Model Name -
modelannotation_liver
-type Filter modelby annotation/segmentation
-type annotation
-output Save output resultinto a file
-output models.json
Here's an example:bin/nvidiaAIAAListModels \ -server http://10.110.45.66:5000/v1 \ -label spleen
6.3.4. nvidiaAIAADEXTR3D:nvidiaAIAADEXTR3D: provides implementation for nvidia::aiaa::Client::dextra3d()
These options are available:
Option Description Default Example
-h Prints the helpinformation

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 42
Option Description Default Example
-server Server URI forAIAA Server
-server
http://10.110.45.66:5000/v
-label Label Name formatching; Either -model or -label isrequired
-label liver
-model Model name -modelDextr3DLiver
-points JSON Array of3D Points (ImageIndices) in [[x,y,z]+]format
-points[[70,172,86],...,[105,161,180]]
-image Input imagefilename whereimage is stored in3D format
-image image.nii.gz
-output File name to store3D binary maskimage result fromAIAA server
-output result.nii.gz
-pad Padding size forinput Image
20 -pad 20
-roi ROI Image sizein XxYxZ formatwhich is used whiletraining the AIAAModel
128x128x128 -roi 96x96x96
-sigma Sigma value for theannotation server
3 -sigma 3
Here's an example using the label:bin/nvidiaAIAADEXTR3D \ -server http://10.110.45.66:5000/v1 \ -label spleen \ -points `cat ../test/data/pointset.json` \ -image _image.nii.gz \ -output tmp_out.nii.gz \ -pad 20 \ -roi 128x128x128 \ -sigma 3
Here's an example using the model:bin/nvidiaAIAADEXTR3D \ -server http://10.110.45.66:5000/v1 \

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 43
-model annotation_spleen \ -points `cat ../test/data/pointset.json` \ -image _image.nii.gz \ -output tmp_out.nii.gz \ -pad 20 \ -roi 128x128x128 \ -sigma 3
6.3.5. nvidiaAIAASegmentation:nvidiaAIAASegmentation: provides implementation fornvidia::aiaa::Client::segmentation()
These options are available:
Option Description Default Example
-h Prints the helpinformation
-server Server URI for theannotation server
-server
http://10.110.45.66:5000/v
-label Label Name formatching; Either -model or -label isrequired
-label liver
-model Model Name -modelSegmentationLiver
-image Input imagefilename whereimage is stored in3D format
-image image.nii.gz
-output File name to store3D binary maskimage result fromthe annotationserver
-output result.nii.gz
Here's are some examples:bin/nvidiaAIAASegmentation \ -server http://10.110.45.66:5000/v1 \ -label spleen \ -image _image.nii.gz \ -output tmp_out.nii.gz
bin/nvidiaAIAASegmentation \ -server http://10.110.45.66:5000/v1 \ -model segmentation_spleen \ -image _image.nii.gz \ -output tmp_out.nii.gz

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 44
6.3.6. nvidiaAIAAMaskPolygon:nvidiaAIAAMaskPolygon: provides implementation fornvidia::aiaa::Client::model().
These options are available:
Option Description Default Example
-h Prints the helpinformation
-server Server URI for theannotation server
-server
http://10.110.45.66:5000/v
-ratio Point Ratio 10 -ratio 10
-input Input 3D binarymask image filename (which is anoutput of dextra3d)
-inputtmp_out.nii.gz
-output Save output result(JSON Array)representing the listof polygons for eachslice into a file
-outputpolygonlist.json
Here's an example:bin/nvidiaAIAAMaskPolygon \ -server http://10.110.45.66:5000/v1 \ -image tmp_out.nii.gz \ -output polygonlist.json
6.3.7. nvidiaAIAAFixPolygon:nvidiaAIAAFixPolygon: provides implementation fornvidia::aiaa::Client::mask2Polygon()
These options are available
Option Description Default Example
-h Prints the helpinformation
-server Server URI forAIAA Server
-server
http://10.110.45.66:5000/v

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 45
Option Description Default Example
-neighbor Neighborhood sizefor propagation
10 -neighbor 10
-poly New 2D PolygonArray in [[[x,y]+]]format
-poly [[[54,162],…,[62,140]]]
-ppoly Current or Old 2DPolygon Array in[[[x,y]+]] format
-poly [[[53,162],…,[62,140]]]
-pindex Polygon Indexwithin new PolygonArray which needsto be updated
-pindex 0
-vindex Vertical Indexwithin new PolygonArray which needsto be updated
-vindex 17
-image Input 2D image slice -imageimage_slice_2D.png
-output Output file name tothe updated image
-outputupdated_image_
2D.png
Here's an example:bin/nvidiaAIAAFixPolygon \ -server http://10.110.45.66:5000/v1 \ -neighbor 10 \ -poly `cat ../test/data/polygons.json` \ -ppoly `cat ../test/data/polygons.json` \ -pindex 0 \ -vindex 17 \ -image ../test/data/image_slice_2D.png \ -output updated_image_2D.png
6.4. Client Python API
6.4.1. AIAA services invoked by the AIAAClient objectThe AIAA object is constructed with the IP address, port, and version of the AIAAserverclient = client_api.AIAAClient(ip, port, api_version)
6.4.2. AIAA Client provides these methods:

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 46
1. model_list: supported model list; 2. dextr3d: 3D image annotation using DEXTR3D method; 3. segmentation: 3D image segmentation using traditional segmentation models; 4. mask2polygon: 3D binary mask to polygon representation conversion; 5. fixpolygon: 2D polygon update with single point edit.
Details of the four methods:
1. model_list
Input:
1. label: label to filter the model selection; If not provided will list all the models 2. type: type of model; It can be either segmentation or annotation; If not given
then both types are selected
Output:
1. A json string containing current supported object names along with theircorresponding object model names for DEXTR3D or Segmentation
2. dextr3d
Input:
1. object model name, according to the output of GetModelList() 2. temporary folder path, needed for http request/response 3. point set: a json string containing the extreme points' indices 4. input 3D image file name 5. output 3D binary mask image file name 6. optional padding size in mm (default is 20) 7. optional ROI Image size (default is '128x128x128') 8. optional sigma param for inference
Output
1. output 3D binary mask will be saved to the specified file 3. segmentation
Input:
1. object model name, according to the output of GetModelList() 2. temporary folder path, needed for http request/response 3. point set: a json string containing the extreme points' indices 4. input 3D image file name 5. output 3D binary mask image file name 6. optional padding size in mm (default is 20) 7. optional ROI Image size (default is '128x128x128') 8. optional sigma param for inference
Output
1. set of extreme polygon points for the segmentation mask 2. output 3D binary mask will be saved to the specified file

Appendix
www.nvidia.comNVIDIA Clara Train SDK: AI-Assisted Annotation DU-09358-002 _v2.0 | 47
4. mask2polygon
Input:
1. point ratio controlling how many polygon vertices will be generated 2. input 3D binary mask image file name
Output:
1. A json string containing the indices of all polygon vertices slice by slice. 5. fixpolygon
Input:
1. A json string containing parameters of polygon editing:
a. Neighborhood size b. Index of the changed polygon c. Index of the changed vertex d. Polygon before editing e. Polygon after editing
2. input 2D image file name 3. output 2D mask image file name
Output:
1. A json string the indices of updated polygon vertices 2. output binary mask will be saved to the specified name
Examples:
test_aiaa_server.py gives method to test the API under configurations specified byaas_tests.json:
1. server information: IP, port, version 2. test-specific information:
a. test name b. disable flag for running / skipping a particular test c. api name for selecting different methods d. test-dependent parameters: input/output file path, other parameters

Notice
THE INFORMATION IN THIS GUIDE AND ALL OTHER INFORMATION CONTAINED IN NVIDIA DOCUMENTATION
REFERENCED IN THIS GUIDE IS PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED,
STATUTORY, OR OTHERWISE WITH RESPECT TO THE INFORMATION FOR THE PRODUCT, AND EXPRESSLY
DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A
PARTICULAR PURPOSE. Notwithstanding any damages that customer might incur for any reason whatsoever,
NVIDIA’s aggregate and cumulative liability towards customer for the product described in this guide shall
be limited in accordance with the NVIDIA terms and conditions of sale for the product.
THE NVIDIA PRODUCT DESCRIBED IN THIS GUIDE IS NOT FAULT TOLERANT AND IS NOT DESIGNED,
MANUFACTURED OR INTENDED FOR USE IN CONNECTION WITH THE DESIGN, CONSTRUCTION, MAINTENANCE,
AND/OR OPERATION OF ANY SYSTEM WHERE THE USE OR A FAILURE OF SUCH SYSTEM COULD RESULT IN A
SITUATION THAT THREATENS THE SAFETY OF HUMAN LIFE OR SEVERE PHYSICAL HARM OR PROPERTY DAMAGE
(INCLUDING, FOR EXAMPLE, USE IN CONNECTION WITH ANY NUCLEAR, AVIONICS, LIFE SUPPORT OR OTHER
LIFE CRITICAL APPLICATION). NVIDIA EXPRESSLY DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY OF FITNESS
FOR SUCH HIGH RISK USES. NVIDIA SHALL NOT BE LIABLE TO CUSTOMER OR ANY THIRD PARTY, IN WHOLE OR
IN PART, FOR ANY CLAIMS OR DAMAGES ARISING FROM SUCH HIGH RISK USES.
NVIDIA makes no representation or warranty that the product described in this guide will be suitable for
any specified use without further testing or modification. Testing of all parameters of each product is not
necessarily performed by NVIDIA. It is customer’s sole responsibility to ensure the product is suitable and
fit for the application planned by customer and to do the necessary testing for the application in order
to avoid a default of the application or the product. Weaknesses in customer’s product designs may affect
the quality and reliability of the NVIDIA product and may result in additional or different conditions and/
or requirements beyond those contained in this guide. NVIDIA does not accept any liability related to any
default, damage, costs or problem which may be based on or attributable to: (i) the use of the NVIDIA
product in any manner that is contrary to this guide, or (ii) customer product designs.
Other than the right for customer to use the information in this guide with the product, no other license,
either expressed or implied, is hereby granted by NVIDIA under this guide. Reproduction of information
in this guide is permissible only if reproduction is approved by NVIDIA in writing, is reproduced without
alteration, and is accompanied by all associated conditions, limitations, and notices.
Trademarks
NVIDIA, the NVIDIA logo, and cuBLAS, CUDA, cuDNN, cuFFT, cuSPARSE, DIGITS, DGX, DGX-1, DGX Station,
GRID, Jetson, Kepler, NVIDIA GPU Cloud, Maxwell, NCCL, NVLink, Pascal, Tegra, TensorRT, Tesla and Volta are
trademarks and/or registered trademarks of NVIDIA Corporation in the Unites States and other countries.
Other company and product names may be trademarks of the respective companies with which they are
associated.
Copyright
© 2019 NVIDIA Corporation. All rights reserved.
www.nvidia.com


















