
NUMERICAL PARALLEL COMPUTINGpeople.inf.ethz.ch/arbenz/PARCO/5.pdf · NUMERICAL PARALLEL COMPUTING...
57
NUMERICAL PARALLEL COMPUTING NUMERICAL PARALLEL COMPUTING Lecture 5, March 23, 2012: The Message Passing Interface http://people.inf.ethz.ch/iyves/pnc12/ Peter Arbenz * , Andreas Adelmann ** * Computer Science Dept, ETH Z¨ urich E-mail: [email protected] ** Paul Scherrer Institut, Villigen E-mail: [email protected] Parallel Numerical Computing. Lecture 5, Mar 23, 2012 1/57
Transcript of NUMERICAL PARALLEL COMPUTINGpeople.inf.ethz.ch/arbenz/PARCO/5.pdf · NUMERICAL PARALLEL COMPUTING...

NUMERICAL PARALLEL COMPUTING
NUMERICAL PARALLEL COMPUTINGLecture 5, March 23, 2012: The Message Passing Interface
http://people.inf.ethz.ch/iyves/pnc12/
Peter Arbenz∗, Andreas Adelmann∗∗∗Computer Science Dept, ETH Zurich
E-mail: [email protected]∗∗Paul Scherrer Institut, Villigen
E-mail: [email protected]
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 1/57

NUMERICAL PARALLEL COMPUTING
MIMD: Multiple Instruction stream - Multiple Data stream
MIMD: Multiple Instruction stream - Multiple Data stream
I distributed memory machines (multicomputers)I all data are local to some processor,I programmer responsible for data placementI communication by message passing
CPU
Memory
CPU
Memory
CPU
Memory
CPU
Memory
Interconnect
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 2/57

NUMERICAL PARALLEL COMPUTING
Message passing
Message passing
I Communication on parallel computers with distributedmemory (multicomputers) is most commonly done bymessage passing.
I Processes coordinate their activities by explicitly sending andreceiving messages.
I We assume that processes are statically allocated. That is, thenumber of processes is set at the beginning of the programexecution; no further processes are created during execution.
I There is usually one process executing on one processor orcore.
I Each process is assigned a unique integer rank in the range0, 1, . . . , p − 1, where p is the number of processes.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 3/57

NUMERICAL PARALLEL COMPUTING
The Message Passing Interface: MPI
The Message Passing Interface: MPI
I Like OpenMP for shared memory programming, MPI is anapplication programmer interface to message passing.
I MPI extends programming languages (C, C++, Fortran) witha library of functions for point-to-point and collectivecommunication and additional functions for managing theprocesses participating at the computation and for queryingtheir status. MPI has become a de facto standard for messagepassing on multicomputers.
I Standardization by MPI forum: http://www.mpi-forum.org
I Implementations:
I OpenMPI: http://www.open-mpi.org/(Brutus runs OpenMPI)
I MPICH: http://www-unix.mcs.anl.gov/mpi/mpich/
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 4/57

NUMERICAL PARALLEL COMPUTING
The Message Passing Interface: MPI
The Message Passing Interface: MPI (cont.)I Goal of the Message Passing Interface:
I to be practicalI to be portableI to be efficient
I Supported hardware platforms:I Distributed Memory: Original target systems.I Shared memoryI Hybrid
I All parallelism is explicit: programmer is responsible forcorrectly identifying parallelism and implementing parallelalgorithms using MPI constructs.
I The number of tasks dedicated to run a parallel program isstatic. New tasks can not be dynamically spawned during runtime.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 5/57

NUMERICAL PARALLEL COMPUTING
The Message Passing Interface: MPI
The Message Passing Interface: MPI (cont.)I MPI-2
I Dynamic processes – extensions that remove the static processmodel of MPI. Provides routines to create new processes.
I One-Sided communications – provides routines for onedirectional communications. Include shared memory operations(put/get) and remote accumulate operations.
I Extended collective operations – allows e.g. for non-blockingcollective operations.
I Additional language bindings – C++ and F90 bindingsI Parallel I/O
I Here we restrict ourselves to basic MPI-1.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 6/57

NUMERICAL PARALLEL COMPUTING
The Message Passing Interface: MPI
MPI References
I P. S. Pacheco: Parallel programming with MPI. MorganKaufmann, San Francisco CA 1996.Easy to read. Much of the material is with Fortran
I P. S. Pacheco: Introduction to Parallel programming. MorganKaufmann, San Francisco CA 2011.Easy to read. Not limited to MPI. Programs mostly in C.
I W. Gropp, A. Skjellum, E. Lusk: Using MPI: Portable ParallelProgramming with the Message Passing Interface. MIT Press,2nd ed, 2000.
I Online tutorial by Blaise Barney, Lawrence Livermore NationalLaboratory athttps://computing.llnl.gov/tutorials/mpi/
(I took images on p. 8 and 26 from that web page.)
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 7/57

NUMERICAL PARALLEL COMPUTING
The Message Passing Interface: MPI
General MPIprogramstructure
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 8/57

NUMERICAL PARALLEL COMPUTING
The Message Passing Interface: MPI
hello.c
hello.c#include <stdio.h>
#include "mpi.h"
main(int argc, char** argv) {
int rank; /* rank of process */
int p; /* number of processes */
MPI_Init(&argc, &argv); /* Start up MPI */
MPI_Comm_rank(MPI_COMM_WORLD, &rank);/* Find out proc rank */
MPI_Comm_size(MPI_COMM_WORLD, &p); /* Find out number
of processes */
printf("Hello world from %d (out of %d procs)\n", rank, p);
MPI_Finalize(); /* Shut down MPI */
}
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 9/57

NUMERICAL PARALLEL COMPUTING
The Message Passing Interface: MPI
hello.c
hello.c (cont.)[iyves@brutus3 ~]$ module load quadrics_mpi/stable
[iyves@brutus3 ~]$ mpicc -o hello hello.c
[iyves@brutus3 ~]$ bsub -n 4 -o output prun ./hello
Quadrics MPI job.
Job <853076> is submitted to queue <qsnet.s>.
[iyves@brutus3 ~]$ cat output
...
Hello world from 0 (out of 4 procs)
Hello world from 2 (out of 4 procs)
Hello world from 1 (out of 4 procs)
Hello world from 3 (out of 4 procs)
...
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 10/57

NUMERICAL PARALLEL COMPUTING
The Message Passing Interface: MPI
hello.c
MPI communicator
I A communicator indicates a collection of processes that cansend messages to each other.
I MPI assumes that p processes “ranked” 0, . . . , p−1 have beenstatically allocated (on hopefully p processors) that cancommunicate with each other by means of MPI commands.
I The initial set of processes are assigned thedefault communicator MPI COMM WORLD.MPI Comm rank and MPI Comm size areused by a process to find out its position inthe MPI world.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 11/57

NUMERICAL PARALLEL COMPUTING
Simple send and receive commands
Example of simple send and receive commands
A typical usage of sending and receiving is given by the followingexample, where process 0 sends a single float x to process 1.Process 0 executes
MPI_Send(&x, 1, MPI_FLOAT, 1, 0, MPI_COMM_WORLD);
while process 1 executes
MPI_Recv(&x, 1, MPI_FLOAT, 0, 0, MPI_COMM_WORLD, &status);
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 12/57

NUMERICAL PARALLEL COMPUTING
Simple send and receive commands
SPMD programming model
Process 0 and process 1 execute different statements.However, the single-programm, multiple-data (SPMD)programming model permits individual processes executingdifferent statements of the same program by means of conditionalbranches.
if (my_rank==0)
MPI_Send(&x, 1, MPI_FLOAT, 1, 0, MPI_COMM_WORLD);
else if (my_rank==1)
MPI_Recv(&x, 1, MPI_FLOAT, 0, 0, MPI_COMM_WORLD, &status);
The SPMD programming model is the most common approach toprogramming MIMD systems.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 13/57

NUMERICAL PARALLEL COMPUTING
Simple send and receive commands
MPI Messages
MPI messages
Message = Data + Envelope
Data: the load that has to be transfered from one place to another.In MPI: A sequence (array) of items of equal type.The data is given by a memory address (e.g. a pointer in C),an array length, and a MPI datatype (cf. next slide).
(We do not discuss how to send messages composed of dataof varying types.)
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 14/57

NUMERICAL PARALLEL COMPUTING
Simple send and receive commands
MPI Messages
MPI datatype C datatype
MPI CHAR signed char
MPI SHORT signed short int
MPI INT signed int
MPI LONG signed long int
MPI UNSIGNED CHAR unsigned char
MPI UNSIGNED SHORT unsigned short int
MPI UNSIGNED INT unsigned int
MPI UNSIGNED LONG unsigned long int
MPI FLOAT float
MPI DOUBLE double
MPI LONG DOUBLE long double
MPI BYTE
MPI PACKED
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 15/57

NUMERICAL PARALLEL COMPUTING
Simple send and receive commands
MPI Messages
MPI messages (cont.)
Message = Data + Envelope
Envelope: Contains (1) address (of sender or recipient, respectively,within the communicator)(2) a ‘tag’ (or ‘message type’) to distinguish messages fromsame sender to same recipient. Tag of sent and receivedmessage must match!Different tags avoid confusion if messages are communicatedbetween same sender/receiver, e.g. in an iteration.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 16/57

NUMERICAL PARALLEL COMPUTING
Simple send and receive commands
Simple MPI send and receive functions
Simple MPI send and receive functions
int MPI_Send(void* buffer /* in */,
int count /* in */,
MPI_Datatype datatype /* in */,
int destination /* in */,
int tag /* in */,
MPI_Comm communicator /* in */)
int MPI_Recv(void* buffer /* out */,
int count /* in */,
MPI_Datatype datatype /* in */,
int source /* in */,
int tag /* in */,
MPI_Comm communicator /* in */,
MPI_Status* status /* out */)
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 17/57

NUMERICAL PARALLEL COMPUTING
Simple send and receive commands
Simple MPI send and receive functions
Message matching
The message sent by process source by the call to MPI Send canbe received by process destination if
I source and destination fit
I recv comm = send comm
I recv tag = send tag
I recv type = send type
I recv buf size ≥ send buf size
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 18/57

NUMERICAL PARALLEL COMPUTING
Simple send and receive commands
Simple MPI send and receive functions
The status in MPI Recv returns information on the data that wasactually received. status is a C structure with (at least) threemembers:status -> MPI SOURCE
status -> MPI TAG
status -> MPI ERROR
If, e.g., tag or source have been set to be a wildcard,i.e. MPI ANY TAG or MPI ANY SOURCE,then status -> MPI TAG and status -> MPI SOURCE return theactual values of these parameters.
The length of the message is obtained by
int MPI_Get_count(MPI_Status* status, /* in */
MPI_Datatype datatype, /* in */
int* count)} /* out */
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 19/57

NUMERICAL PARALLEL COMPUTING
Simple send and receive commands
Pacheco’s greetings.c
Pacheco’s greetings.c
#include <stdio.h>
#include <string.h>
#include "mpi.h"
main(int argc, char** argv) {
int my_rank; /* rank of process */
int p; /* number of processes */
int source; /* rank of sender */
int dest; /* rank of receiver */
int tag = 0; /* tag for messages */
char message[100]; /* storage for message */
MPI_Status status; /* return status for receive */
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &p);
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 20/57

NUMERICAL PARALLEL COMPUTING
Simple send and receive commands
Pacheco’s greetings.c
if (my_rank != 0) {
/* Create message */
sprintf(message, "Greetings from process %d!", my_rank);
dest = 0;
/* Use strlen+1 so that ’\0’ gets transmitted */
MPI_Send(message, strlen(message)+1, MPI_CHAR,
dest, tag, MPI_COMM_WORLD);
} else { /* my_rank == 0 */
for (source=1; source < p; source++) {
MPI_Recv(message, 100, MPI_CHAR, source, tag,
MPI_COMM_WORLD, &status);
printf("%s\n", message);
}
}
}
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 21/57

NUMERICAL PARALLEL COMPUTING
Communication
Point-to-point communication
Point-to-point communication
I Point-to-point communication routines involve messagepassing between two, and only two, different MPI tasks. (Pairof send/receive operations.)
I In MPI there are different types of send and receive routinesused for different purposes. For example:
I Blocking send / blocking receiveI Non-blocking send / non-blocking receiveI Buffered send / buffered receiveI ...
I Any type of send routine can be paired with any type ofreceive routine.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 22/57

NUMERICAL PARALLEL COMPUTING
Communication
Point-to-point communication
Semantics of MPI Send
I MPI Send may buffer the message in MPI-internal storage.The call to MPI Send will then return.
This type of communication is called asynchronous.
I MPI Send may block until MPI Recv has started to receive thedata. Only then MPI Send returns.
This type of communication is called synchronous.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 23/57

NUMERICAL PARALLEL COMPUTING
Communication
Point-to-point communication
Semantics of MPI Send (cont.)I The exact behavior of MPI Send depends on the
implementation.
I Typically, messages that are smaller than a default cutoff arebuffered, longer messages are blocked.
I Programmer’s view: A blocking send (MPI Send) routine willonly ”return” after it is safe to modify the application buffer(your send data) for reuse.
This holds for both synchronous and asynchronousimplementations.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 24/57

NUMERICAL PARALLEL COMPUTING
Communication
Point-to-point communication
Semantics of MPI Recv
I MPI Recv always blocks until a matching message has beenreceived.
I When MPI Recv returns, the message is available in thereceive buffer.
I MPI messages are nonovertaking: If a source process sendstwo messages to a destination process, then the first messagemust be available to the destination process before the secondone.
(This holds only if two processes are involved.)
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 25/57
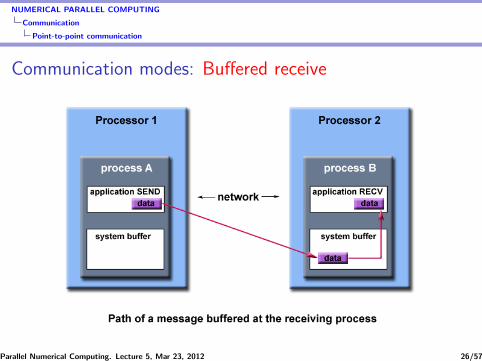
NUMERICAL PARALLEL COMPUTING
Communication
Point-to-point communication
Communication modes: Buffered receive
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 26/57

NUMERICAL PARALLEL COMPUTING
Communication
Point-to-point communication
Deadlocks
Program fragment that can generates a deadlock
MPI_Comm_rank (comm, &my_rank);
if (my_rank == 0) {
MPI_Recv (recvbuf, count, MPI_INT, 1, tag, comm, &status);
MPI_Send (sendbuf, count, MPI_INT, 1, tag, comm);
}
else if (my_rank == 1) {
MPI_Recv (recvbuf, count, MPI_INT, 0, tag, comm, &status);
MPI_Send (sendbuf, count, MPI_INT, 0, tag, comm);
}
Problem: Both processes wait on each other.Possible solution: Swap send/recv for one of the processes.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 27/57

NUMERICAL PARALLEL COMPUTING
Communication
Point-to-point communication
Deadlocks (cont.)Program fragment generates a deadlock implementationdependent.
MPI_Comm_rank (comm, &my_rank);
if (my_rank == 0) {
MPI_Send (sendbuf, count, MPI_INT, 1, tag, comm);
MPI_Recv (recvbuf, count, MPI_INT, 1, tag, comm, &status);
}
else if (my_rank == 1) {
MPI_Send (sendbuf, count, MPI_INT, 0, tag, comm);
MPI_Recv (recvbuf, count, MPI_INT, 0, tag, comm, &status);
}
The communication completes correctly if the messages sendbuf
are stored in a system buffer.
See MPI Sendrecv command for data exchange.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 28/57

NUMERICAL PARALLEL COMPUTING
Communication
Point-to-point communication
Non-blocking communication
I Blocking communication often leads to a bad usage ofcompute resources.(In particular as todays hardware may have processorsdedicated to communication.)
I A message may be sent long after the receive (MPI Recv) hasbeen issued, leaving the receiving process idling.
I Non-blocking communication comes to our rescue.
I Non-blocking send (MPI Isend) and receive (MPI Irecv)routines return almost immediately.They do not wait for any communication events to complete,such as message copying from user memory to system bufferspace or the actual arrival of message.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 29/57

NUMERICAL PARALLEL COMPUTING
Communication
Point-to-point communication
Non-blocking communication (cont.)I Non-blocking operations simply request the MPI library to
perform the operation when it is able. The user can notpredict when that will happen.
I It is unsafe to modify the application buffer before therequested non-blocking operation was actually performed.There are functions for checking this.
I Non-blocking communication is primarily used to overlapcomputation with communication and exploit possibleperformance gains (Latency hiding).
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 30/57

NUMERICAL PARALLEL COMPUTING
Communication
Point-to-point communication
Example of a non-blocking receive
Non-blocking routines have an additional output parameter, calleda request. It allows for checking if a message actually has beenreceived, i.e., has been copied into memory.
int MPI_Irecv(...
MPI_Comm communicator /* in */,
MPI_Request* request /* out */)
int MPI_Wait(MPI_Request* request /* in/out */
MPI_Status* status /* out */)
The MPI Wait call blocks. The parameter status holds the sameinformation as the MPI Recv would provide.
MPI Test does not block.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 31/57

NUMERICAL PARALLEL COMPUTING
Communication
Collective communication
Collective communication
In collective communication, all processes participate at thecommunication.
Let’s assume that process 0 reads some input data that it needs tomake available to all other processes in the group. We know howprocess 0 could proceed:
for (dest = 1; dest < p; dest++) {
MPI_Send(data, 10, MPI_INT, dest, tag, MPI_COMM_WORLD);}
In this approach p − 1 messages are sent, all with the same sender.We know that there are more elegant (and in general moreefficient) algorithms to do the above by a tree-structured algorithm(see page 39).
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 32/57

NUMERICAL PARALLEL COMPUTING
Communication
Collective communication
Broadcast
A broadcast implements the tree-structured algorithm:
int MPI_Bcast(void* message /* in/out */,
int count /* in */,
MPI_Datatype datatype /* in */,
int root /* in */,
MPI_Comm communicator /* in */)
The above example becomes:
MPI_Bcast(data, 10, MPI_INT, 0, MPI_COMM_WORLD);
Here, the number 0 is the rank of the source process. By issuingMPI Bcast the message data is sent from the source process to allother processes in the communicator. All processes execute thesame statement. So, data is input data in the source process andoutput data other wise. Notice that there is no tag! (The reasonis history: broadcasts have been used for synchronization.)
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 33/57

NUMERICAL PARALLEL COMPUTING
Communication
Collective communication
Reduction
As OpenMP, MPI provides a reduction function (that uses atree-structured algorithm):
int MPI_Reduce(void* operand /* in */,
void* result /* out */,
int count /* in */,
MPI_Datatype datatype /* in */,
MPI_Op operator /* in */,
int root /* in */,
MPI_Comm comm /* in */)
MPI Reduce combines the operands stored in memory locationoperand and stores the result in *result in process root. Bothoperand and result refer to count memory locations with datatype datatype. MPI Reduce must be called by all processes in thecommunicator comm, and count, datatype, operator, and root
must be the same in each invocation.Parallel Numerical Computing. Lecture 5, Mar 23, 2012 34/57

NUMERICAL PARALLEL COMPUTING
Communication
Collective communication
Operation name Meaning
MPI MAX MaximumMPI MIN MinimumMPI SUM SumMPI PROD ProductMPI LAND Logical andMPI BAND Bitwise andMPI LOR Logical orMPI BOR Bitwise orMPI LXOR Logical exclusive orMPI BXOR Bitwise exclusive orMPI MAXLOC Maximum and location of maximumMPI MINLOC Minimum and location of minimum
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 35/57

NUMERICAL PARALLEL COMPUTING
Example: Dot product
Example: Dot product
Parallel inner (dot) product with block distribution of the data.
float Serial_dot(
float x[] /* in */,
float y[] /* in */,
int n /* in */) {
int i;
float sum = 0.0;
for (i = 0; i < n; i++)
sum = sum + x[i]*y[i];
return sum;
}
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 36/57

NUMERICAL PARALLEL COMPUTING
Example: Dot product
float Parallel_dot(
float local_x[] /* in */,
float local_y[] /* in */,
int n_bar /* in */) {
float local_dot;
float dot = 0.0;
float Serial_dot(float x[], float y[], int m);
local_dot = Serial_dot(local_x, local_y, n_bar);
MPI_Reduce(&local_dot, &dot, 1, MPI_FLOAT,
MPI_SUM, 0, MPI_COMM_WORLD);
return dot;
} /* Parallel_dot */
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 37/57

NUMERICAL PARALLEL COMPUTING
Example: Dot product
Allreduce
The function MPI Allreduce is used in the same way asMPI Reduce. However, in contrast to MPI Reduce all processes getthe result. Thus, parameter root is not needed.
int MPI_Allreduce(
void* operand /* in */,
void* result /* out */,
int count /* in */,
MPI_Datatype datatype /* in */,
MPI_Op operator /* in */,
MPI_Comm comm /* in */)
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 38/57

NUMERICAL PARALLEL COMPUTING
Example: Dot product
Reduction algorithm for p = 8 (cf. hypercube in d = 3 dimensions.)
The reduction takes d = log2 p steps.In step i (i = 0, . . . , d−1), processors (k+1)2i
(k = 0, 2, . . . , p/2i − 2) sends a message to processor k · 2icontaining the partial sum σik . Processor k · 2i then computesσi+1k = σik + σik+1.
The desired result is σd0 = x · y.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 39/57
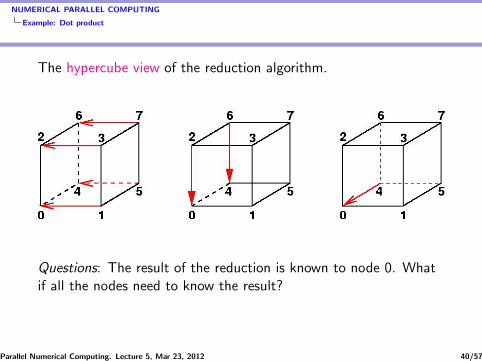
NUMERICAL PARALLEL COMPUTING
Example: Dot product
The hypercube view of the reduction algorithm.
Questions: The result of the reduction is known to node 0. Whatif all the nodes need to know the result?
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 40/57

NUMERICAL PARALLEL COMPUTING
Communication cost
Communication cost
Communication often means overhead when executing parallelprograms. The time for transfering a message between twoprocessors is called communication latency. Most of the time ithas the form
tcomm = tstartup + `msg × tword
where tstartup is the time for preparing a message by the sendingprocess, `msg is the length of the message, tword is the per-wordtransfer time. This is the inverse of the bandwidth of the network.In static networks we have an additional term depending on thenumber of intermediate nodes (hops). (This effect is in generalnegligible.) There are two routing strategies in static networks
I store-and-forward-routing
I cut-through-routing (pipelining)
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 41/57

NUMERICAL PARALLEL COMPUTING
Example: Dot product
Speedup analysis for the dot product
For simplicity wa assume p = 2q, i.e., q = log2 p, q ∈ N
T (p) = (2n
p− 1) tflop + log2 p (tstartup + 1 · tword + 1 · tflop)
S(p) =T (1)
T (p)=
(2n − 1)tflop
(2np − 1)tflop + log2 p (tstartup + tword + tflop)
=p
p (2n/p + q − 1)2n − 1 +
p q (tstartup + tword)(2n − 1)tflop
n�p≈ p
1 +p log2 p
2ntstartup + tword
tflop
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 42/57

NUMERICAL PARALLEL COMPUTING
Example: Dot product
Speedup analysis for the dot product (cont.)
S(p) ≈ p
1 + p log2 p︸ ︷︷ ︸algorithm
1
2n︸︷︷︸problem size
tstartup
tflop︸ ︷︷ ︸hardware
.
E (p) =S(p)
p≈ 1
1 +p log2 p
2ntstartup + tword
tflop
What happens if p is not an (integer) power of 2?
The isoefficiency function is f (p) = Cp log2 p.Parallel Numerical Computing. Lecture 5, Mar 23, 2012 43/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
Matrix-vector multiplication
Let’s consider what ingredients we need to do a matrix-vectormultiplication, y = Ax. For simplicity we assume that A is squareof order n. Then
yj =n−1∑i=0
ajixi , 0 ≤ j < n.
In OpenMP we could parallelize this by
#pragma omp parallel for schedule (static)
for (j=0; j< N; j++){
y[j] = 0.0;
for (i=0; i < N; i++)
y[j] = y[j] + a[j][i] * x[i];
}
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 44/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
As the outer-most loop is parallelized and we access the matrixrow-wise, we can visualize the matrix vector product as follows.
This is not quite correct as all processes access all of x.Parallel Numerical Computing. Lecture 5, Mar 23, 2012 45/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
How can we do this in a distributed memory environment?Let us assume that the matrix A and the vectors x and y aredistributed in the block-wise (or panel) distribution as displayed onthe previous slide. Let
xk ∈ IRm, yk ∈ IRm, Ak ∈ IRm×n m =n
p0 ≤ k < p,
be the portions of x, y, and A, respectively, stored in process k(usually on processor k). Then,
yk = Akx.
Thus, each element of the vector y is the result of the innerproduct of a row of A with the vector x. In order to form the innerproduct of each row of A with x we either have to gather all of xonto each process or we have to scatter each (block-)row of Aacross the processes.(In our previous OpenMP code the former was done.)
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 46/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 47/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
In MPI, gathering vector x on process 0 can be done by the call
/* Space allocated in calling program */
float local_x[]; /* local storage for x */
float global_x[]; /* storage for all of x */
/* Assumes that p divides both n */
MPI_Gather(local_x, n/p, MPI_FLOAT,
global_x, n/p, MPI_FLOAT,
0, MPI_COMM_WORLD);
The syntax is
int MPI_Gather(void* send_data /* in */,
int send_count /* in */,
MPI_Datatype send_type /* in */,
void* recv_data /* out */,
int recv_count /* in */,
MPI_Datatype recv_type /* in */,
int dest /* in */,
MPI_Comm comm /* in */)
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 48/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
Collecting all the pieces of a distributed vector on a singleprocessor (and arranging the pieces in the correct order) is called agather operation in MPI. Doing this in all processes is anallgather. That’s evidently what we need in the matrix-vectormultiplication. MPI provides MPI Allgather to that end.
int MPI_Allgather(void* send_data /* in */,
int send_count /* in */,
MPI_Datatype send_type /* in */,
void* recv_data /* out */,
int recv_count /* in */,
MPI_Datatype recv_type /* in */,
MPI_Comm comm /* in */)
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 49/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
Remark: The cost of a gather with a vector of length m on pprocessors is
Tgather(p)(m) = dlog2(p)etstartup + 2dlog2(p)em tword
=
log2 p−1∑i=0
(1 · tstartup + 2im tword
)= q tstartup + p m tword, if p = 2q,
as the length of the message doubles in each stage of thetree-structured algorithm.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 50/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
If A is stored block column-wise, we have
Here,xk ∈ IRm, yk ∈ IRm, Ak ∈ IRn×m.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 51/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
Formally, we have to do the following
1. Compute (locally) yj = Ajxj , 0 ≤ j < p.
2. Reduce y =∑p−1
j=0 yj with root process 0, e.g.
3. Scatter y on the p processes.
The last two items can be combined by the call toMPI Reduce Scatter (see next page).
Remark: The cost of a reduce scatter with vector pieces of lengthm on p processors is
Treduce−scatter(p)(m) = dlog2(p)e tstartup + 2dlog2(p)em tword
= q tstartup + p m tword, if p = 2q,
Here, we have neglected the arithmetic operations in the reduction.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 52/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 53/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
If A is stored in blocks of size m ×m we combine the twoalgorithms.
For convenience, we assume that p = q2, q ∈ N, and indicate theprocess with rank k by
(j , l) = (bk/qc, k mod q)Parallel Numerical Computing. Lecture 5, Mar 23, 2012 54/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
Life is easier, if we split x and y in chunks of n/q and store thesein the “diagonal processes” (i , i).Then,
xi ∈ IRm, yj ∈ IRm, Aj ,i ∈ IRm×m
and
yj =
q−1∑i=0
Aj ,ixi =
q−1∑i=0
y(i)j , q =
√p,
where Aj ,i denotes the block of A on process(or) (j , i) ∼ jq + i .
The algorithm proceeds as follows:
1. Broadcast xc along column c
2. Local computation: y(r)c = Ar ,cxc .
3. Reduce along row: y(r) =∑q−1
c=0 y(r)c on process (c , c).
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 55/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
Complexity of matrix-vector multiplication
I A stored block-wise (p = q2)
TMxV =2n2
ptflop + Tbcast(q)(
n
q) + Treduce(q)(
n
q)
=2n2
ptflop + log2 p tstartup + 2n tword.
Remark: Note that log2 p = 2 log2 q.Remark: Here, we have assumed that p is a power of 2. Otherwise,the complexity rises by at most a factor 2.Remark: The complexity of all three matrix-vector multiplicationsis (approximately) equal.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 56/57

NUMERICAL PARALLEL COMPUTING
Example: Matrix-vector multiplication
Speedup and efficiency
The speedup of these algorithm is
S(p) =p
1 +p log2 p tstartup
2n2 tflop+ p tword
2n tflop
.
Recall that efficiency is defined as
E (p) =S(p)
p.
Thus, iso-efficiency holds if
p ∼ n.
The algorithm is perfectly scalable.
Parallel Numerical Computing. Lecture 5, Mar 23, 2012 57/57


![A Parallel Compact Multi-dimensional Numerical … PARALLEL COMPACT MULTI-DIMENSIONAL NUMERICAL ALGORITHM WITH AEROACOUSTICS APPLICATIONS ALEX POVITSKY* AND PHILIP .]. MORRIS ¢ Abstract.](https://static.fdocuments.in/doc/165x107/5aeb54fa7f8b9ae5318d9568/a-parallel-compact-multi-dimensional-numerical-parallel-compact-multi-dimensional.jpg)















