
NoSQL - sigs.de · NoSQL is specialization! ... +-kein tuning / config. Document Databases. any...
61
Prof. Dr. Stefan Edlich NoSQL Prof. Dr. Stefan Edlich NoSQL © Geek&Poke
Transcript of NoSQL - sigs.de · NoSQL is specialization! ... +-kein tuning / config. Document Databases. any...

Prof. Dr. Stefan Edlich
NoSQL
Prof. Dr. Stefan Edlich
NoSQL
© Geek&Poke

nosqlberlin.denosqlfrankfurt.denosql powerdays

http://nosql-database.orghttp://nosql-database.org



70% Scaling 30%
Business
70% Business 30%
ScalingWerner VogelsCTO Amazon
70% KV20%
SingleTable
10%
Joins
Interaktion vs. Transaktion bis 1000 : 1
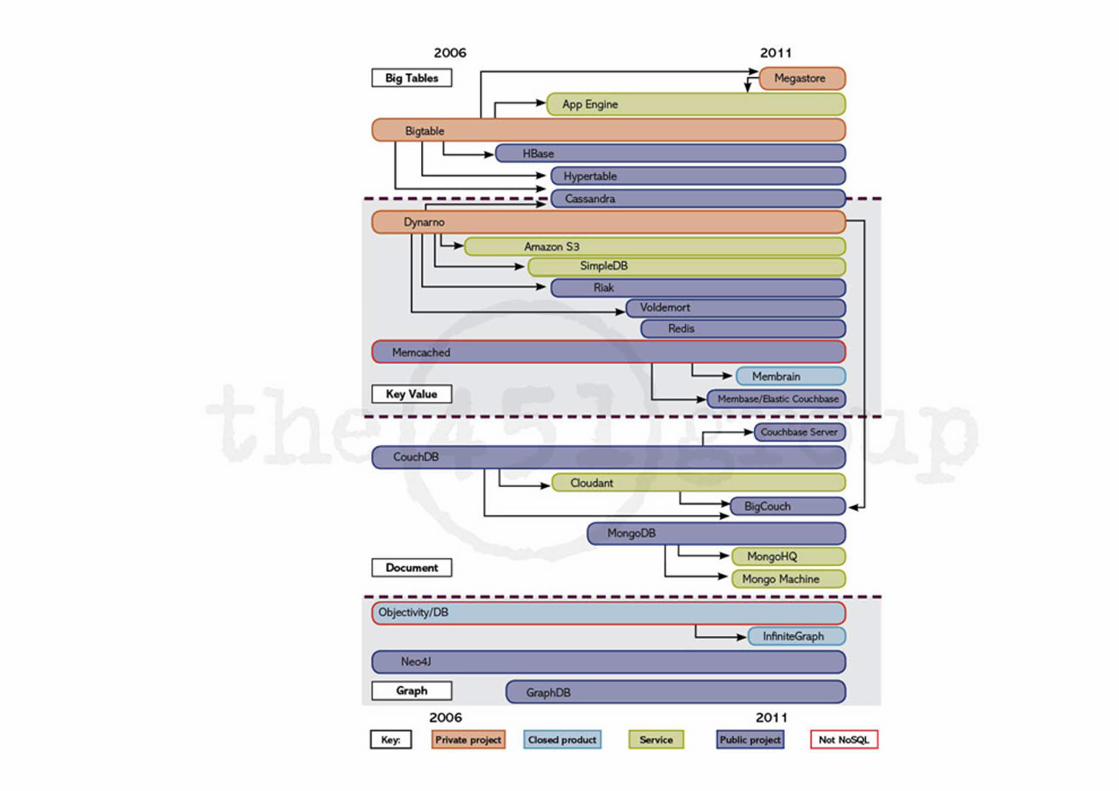

nosqltapes.comNoSQL is specialization!
• Big Data
• Massive Write Performance
• Fast KV Access
• Write Availability
• Flexible Schema (Migration) + Flexible Datatypes
• Easier maintainability, administration and operations
• No single point of failure
• Programmer ease of use

Theorie?!Theorie?!
Map/Reduce � Map/Reduce Nachfolger!
ACID / BASE & CAP � P liegt in der Regel nie vor!
Consistent Hashing � Basis skalierbarer K/V Stores
MVCC � non blocking Vorteile
Vector Clocks � [122:1][147:2|122:1]
[97:3|147:2|122:1]
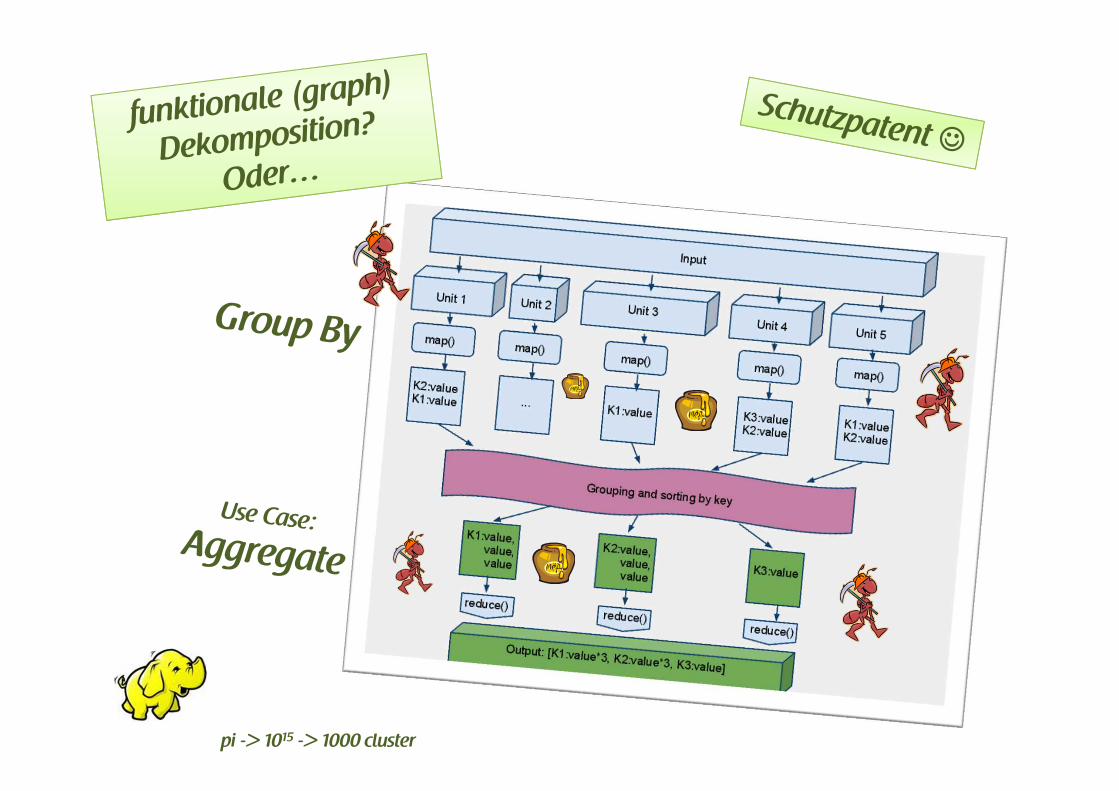
pi -> 1015 -> 1000 cluster

Starke Konkurrenz: Stratosphere (TUB), ePic, SwissBox, etc.
„A giant step back! Imcompatible, missing features, not new, …“
Stonebraker

Paralellization Contracts
compile, analyze, optimize
auf einer atmenden Cloud!

ACID
BASE• Amazon Dynamo• MySQL Replikation
Eventually Eventually Eventually Eventually ConsistentConsistentConsistentConsistent
WATER
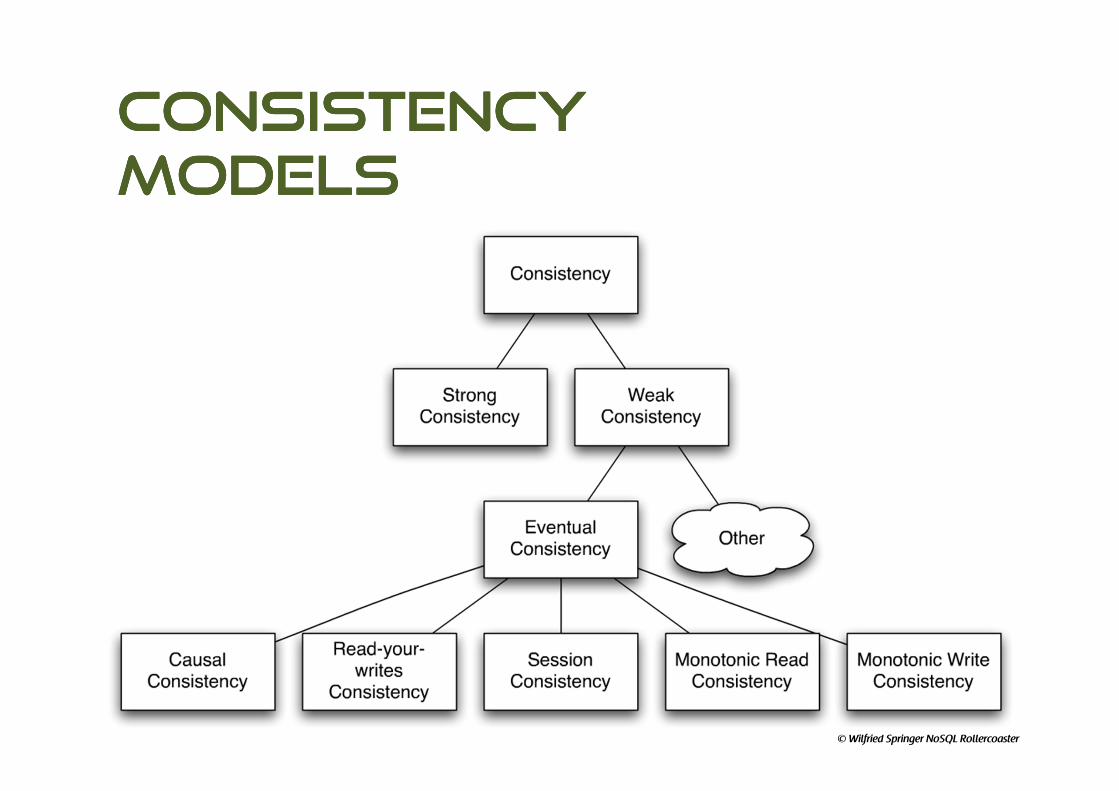
Consistency Consistency Consistency Consistency
ModelsModelsModelsModels
© Wilfried Springer NoSQL Rollercoaster

Availability
Partition
ToleranceConsistency
CAP TheoremeCAP TheoremeCAP TheoremeCAP Theoreme
ACID / Isolation
Clients see equal data
System is always ‘ on‘
Clients find replicas
Pick 2!
NoSQLKlassiker

„Don‘t throw C away so easy! It‘s complex.“
What you really have is: 1. Application errors2. Repetable DBMS errors3. Unrepeatable DBMS errors4. Operating System errors5. Hardware failure in cluster6. Network partition in local cluster7. A disaster8. WAN failure

• 6 = Network Partition is rare• 3,4,5,6 is mostly a Single Node• Algorithms can help!
„give up P rather than sacrificing C. Use VoltDB or NimbusDB”

M:[0,5)
N:[5,10)
O:[10,15)
P:[15,20)
Q:[20,25)
R:[25,30)
HASH KNOTEN REPLIKAT
2 M N,O
8 N O,P
10 O P,Q
17 P Q,R
22 Q R,M
26 R M,N
W �= 2*WR �= 1*R
Consistent Consistent Consistent Consistent
HashingHashingHashingHashing
• ausfallsicher �• leicht erweiterbar �• gut verteilt / vnodes �

pessimistisches Locking?
MVCCMulti Version Concurrency Control

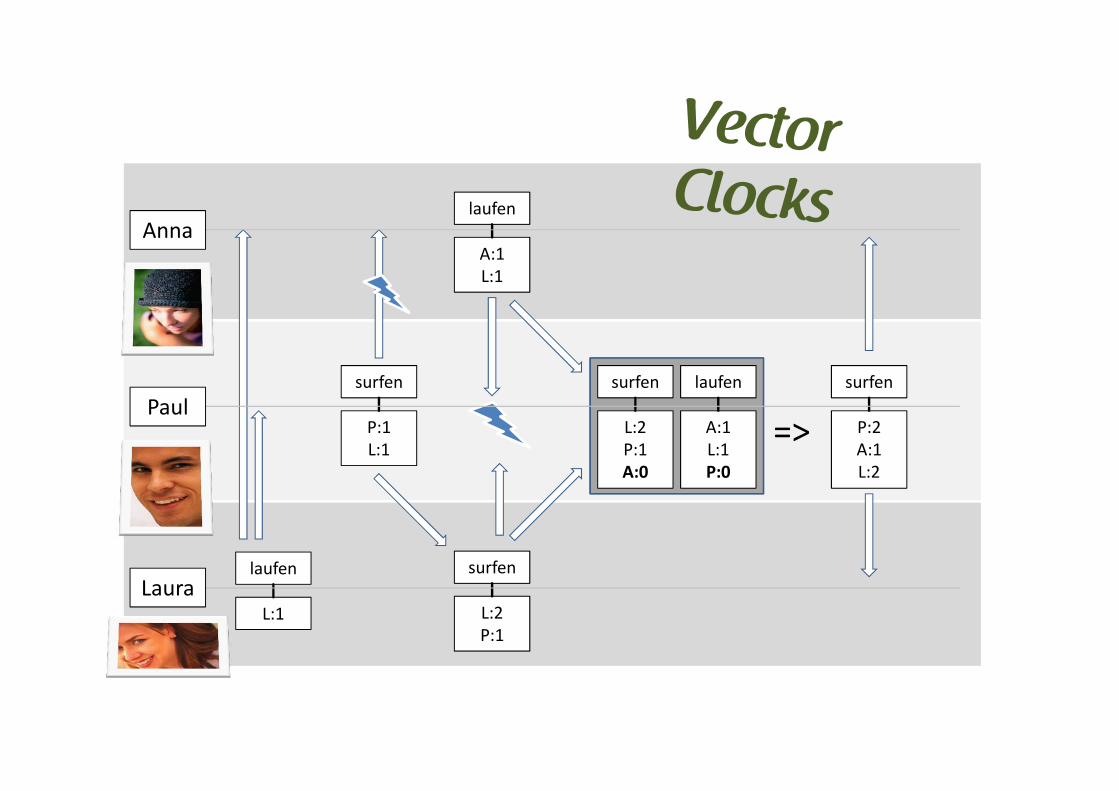
laufen
L:1
surfen
P:1
L:1
surfen
L:2
P:1
laufen
A:1
L:1
laufen
A:1
L:1
P:0
surfen
L:2
P:1
A:0
surfen
P:2
A:1
L:2
=>
Anna
Paul
Laura

Google Protocol Buffers
=>

• JSON
• Binary data transfer
• automatic RPC generation
• no code generation
• Client + Server tauschen Schema bei Änderung
unbedingt evaluieren!
Apache Avro!Apache Avro!

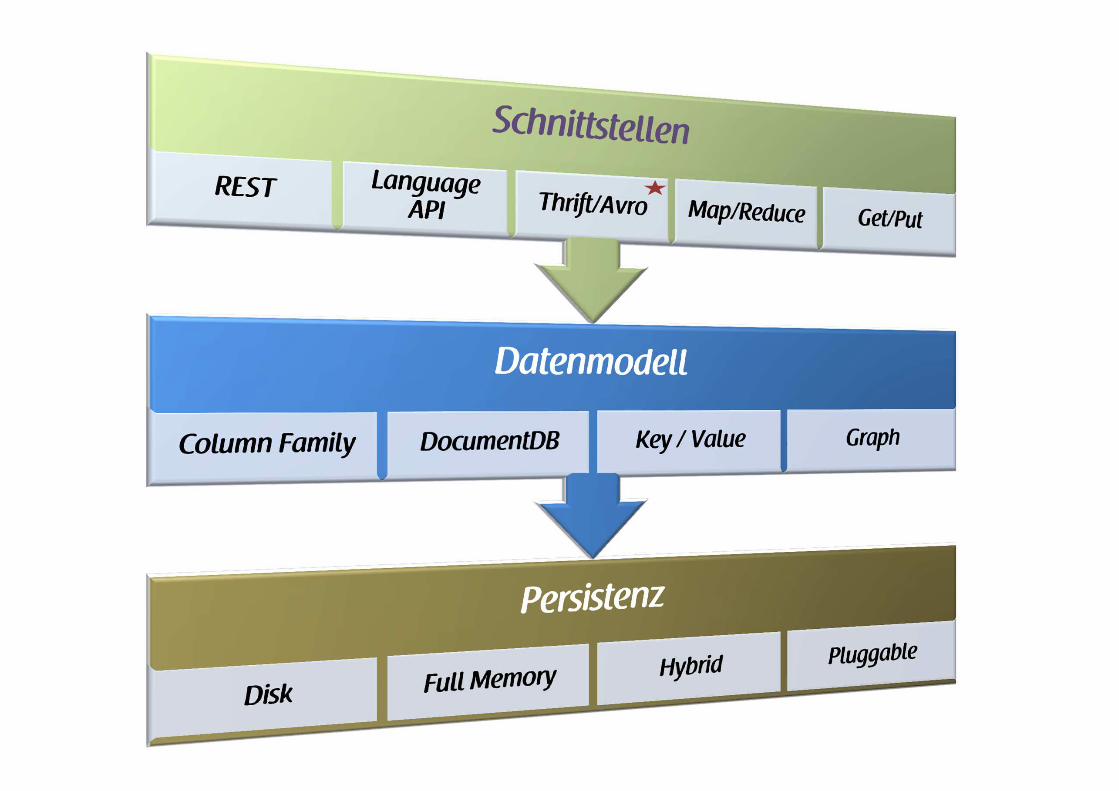
DatenmodelleDatenmodelle

Voldemort, Chordless, Scalaris, Dynamo / Dynomite
db4o, Versant, Objectivity, Gemstone, Progress, Mark Logic, EMC Momentum, Tamino, GigaSpaces, Hazelcast, Terracotta, …
Column Family
DocumentDBs
Key/ValueDBs
GraphDBs
andere

HBase Cassandra
SimpleDB

+ Skalierung = new node
+ Community
+ API
- Replikation
- Aufsetzen, Optimierung, Wartung + Skalierung = new node
+ Replikation
+ Konfiguration (r, w)
- Dokumentation
- Abfragen
+ stressfreie SaaS Lösung
+ transparent scaling
- UTF-8 String
- Daten liegen bei Amazon
+- kein tuning / config

Document Databases

any JSany JSany JSany JS----ClientClientClientClient
no Middleware!no Middleware!no Middleware!no Middleware!
DB+WebServerDB+WebServerDB+WebServerDB+WebServer++++evolvingevolvingevolvingevolving AppAppAppApp


- nicht normalisiert (Duplicates, Delete Orphans, ...)
- (konfigurierbare Zeit Crash anfällig) (Journaling)
- Eventually Consistent
- echte Skalierung nur über Sharding
- (noch nicht kill -9 fest)

67 GB
Index ����
Data ����
11 hours + 1 day off

+ nicht normalisiert
+ Schema Agilität
+ Doku exzellent
+ Speed (MemMapped Files)
+ Installation (18 sek!)
+ beliebige Indizes
+ MapReduce
+ Rich Query Language
+ GridFS (statt HDFS)
+ einfache Replizierung (Master-Slave / Replica Sets)

db.system. indexes .find();db.friends.getIndexes();db.friends.ensureIndex({friend: 1});db.friends.ensureIndex({friend: 1, zip: 1}); //compounddb.friends.find({friend: „Mario“,
zip: „13755“}).explain();
Queries : age: {$gt: 10} food:{$all: [„pizza“, „noodles“]}$gt, $lt, $lte, $ne, $in, $nin, $mod, $all, $size, $exists, $type, , $or, $elem, $elemMatch, regexp, ...
NoSQL Query LockIn?!

Migrations Architektur-Pattern:
A) Blacklist
Sich veränderndes Schema
rename
try { ...} catch (FirstException | SecondException ex) {
// newName = BlackList.checkName(OldName)}
����

B) „Rails“ Migration
new namenew name
new namenew name
old namenew name
(nicht wenn zu oft repliziert)
old namenew name
old namenew name
old namenew name

Duplikate = SpaceDuplikate = SpaceDuplikate = SpaceDuplikate = SpaceAktualität der DatenAktualität der DatenAktualität der DatenAktualität der Daten
„Pre„Pre„Pre„Pre----Joined“ Daten!Joined“ Daten!Joined“ Daten!Joined“ Daten!„pre„pre„pre„pre----computeD“computeD“computeD“computeD“
wachsende Daten wachsende Daten wachsende Daten wachsende Daten raus oder Preraus oder Preraus oder Preraus oder Pre----SPACEDSPACEDSPACEDSPACED

In die Cloud…
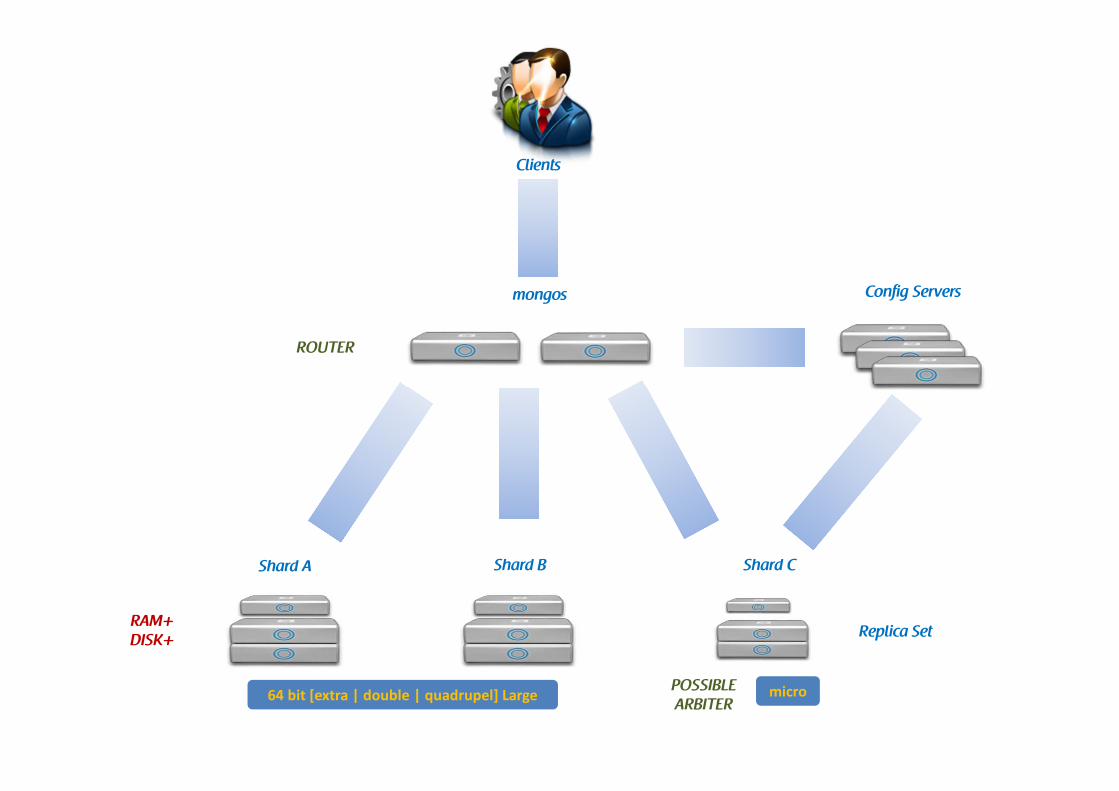
Clients
Config Serversmongos
ROUTER
Replica Set
Shard A Shard B Shard C
RAM+DISK+
POSSIBLE ARBITER
micro64 bit [extra | double | quadrupel] Large

Erfahrungen…
• RAID Konfigurationen (00,01,10,03,05, …)• Journaling-Dateisysteme (ext4, xfs, …)• (Security) Ports, F-Deskriptoren, Snapshots,…
www.mongodb.org/display/DOCS/Amazon+EC2

K/VK/VK/VK/V----StoresStoresStoresStores
+ sehr schnell > 100.000 /sek
+ konfigurierbarer Disc sync
+ API für eigene Anbindung
+ einfache Replikation
+ hash, list, set, sorted set, messages
+ Installation
UNIX: 38 sek
Windows: 18 sek
- cloud-cluster erst in Version 3.*
Datenstrukturen abbilden ->
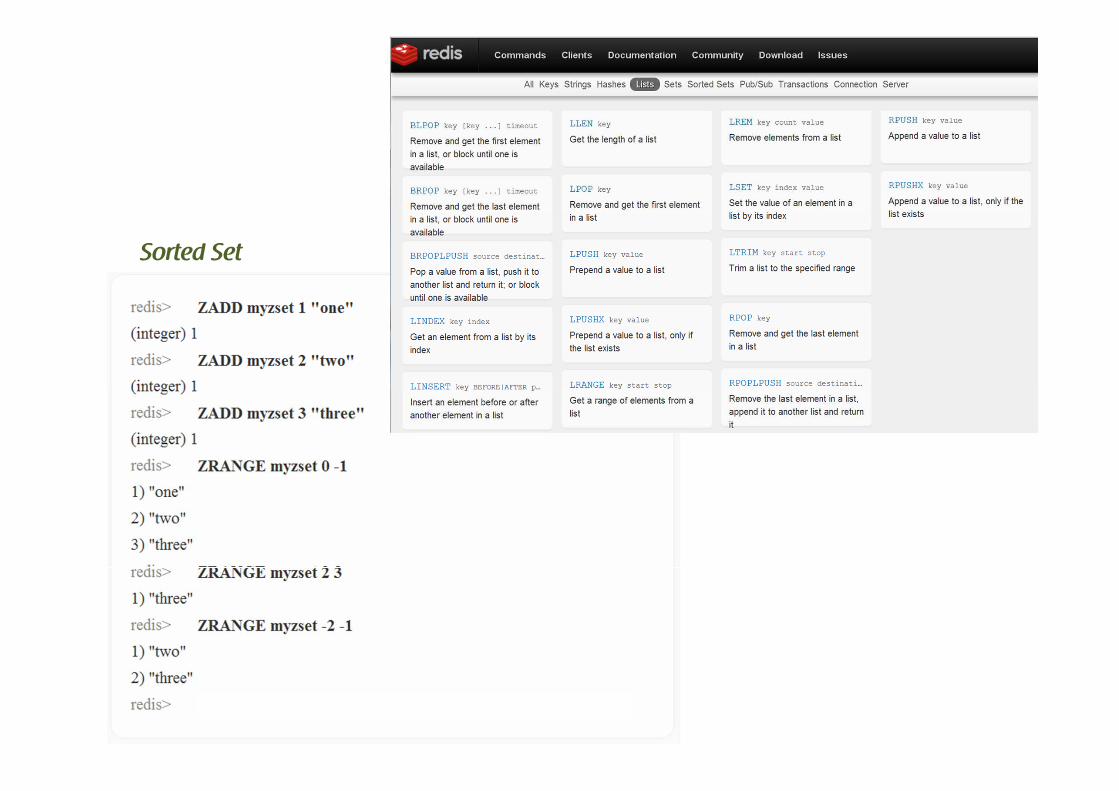
Sorted Set

memcached API

• simply dynamic scaling (up & down)• scales linear• bullet proof by Zynga.com• limited membase protocol• Membase Tap (Protocol Interception)• Code-Node:

Membase in der Cloud
• Fertige RightScale & AMI templates!
• Diverse Ports öffnen
• DNS Eintrag und keine verändernden IPs
• Master Node angeben• legt Quota für die Erben fest
• Backups für EBS
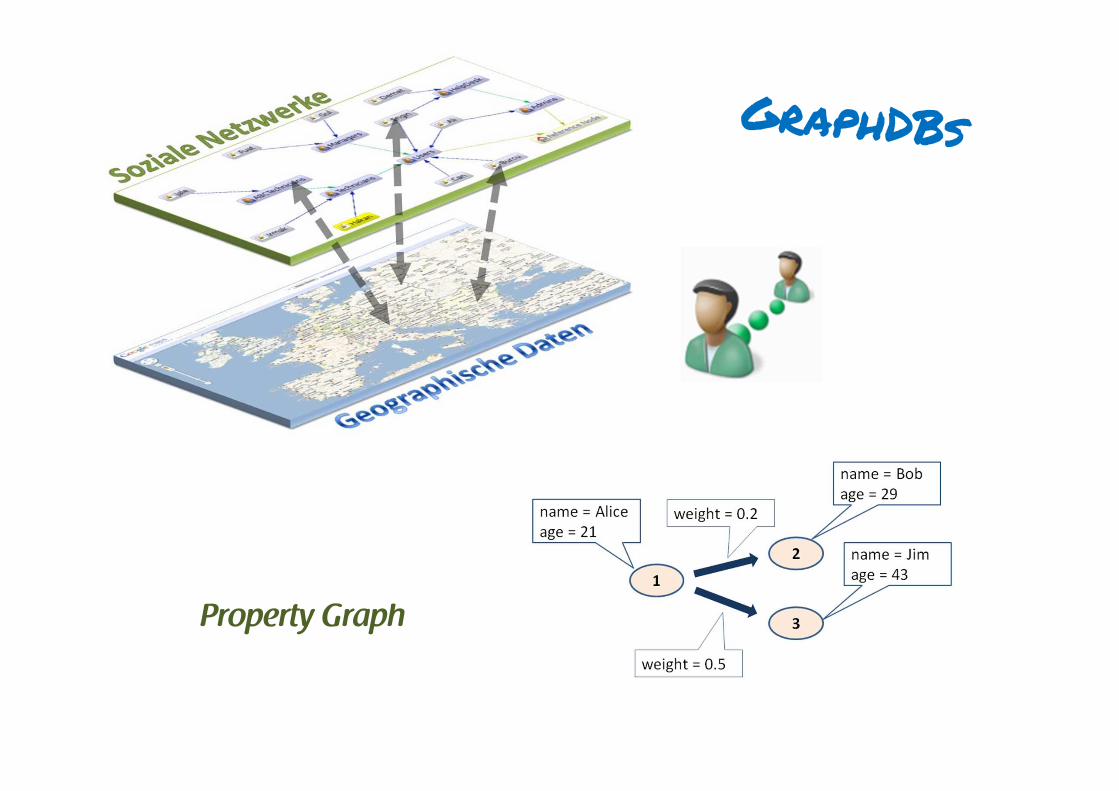
Property Graph


Graph DBs in der Cloud
Sharding!?
no „predictable lookup“ �
Domain Specific Knowledge
ausbalancierte DBs
Access Patterns + Heuristiken
(HA) Neo4j Cache Sharding!

> 220 DBs
durchausfrustrierendes Consulting…

Analyse your DataDomain-Data, Log-Data, Event-Data, Message-Data, critical Data, Business-Data, Meta-Data, temp Data, Session-Data, Geo Data, etc.
Data- / Storage-Model:relational, column-o, doc-alike, graphs, objects, etc.What Types / Type-System?Data-Navigation, Data Amount, Data Komplexity (Deep XML?)
ACID vs. BASE vs. Mixture?CAP decisions
Performance Dimension AnalysisLatency, Request behaviour, Throughput
Scale-Up vs Scale-Out
Distribution Architecturelocal, parallel, distributed / grid, service, cloud, mobile, p2p, …
Data Access Patternsread / write distribution, random / sequential, Access Design Patterns
Query RequirementsTypical queries, Tools, Ad-Hoc Queries, SQL / LINQ needed, Map/Reduce? …
Non Functional Requirements:Replication, Refactoring Frequency, DB-Support, Qualification / simplicity, Company restrictions, DB diversity (allowed?), Security, Safety / Backup & Restore, Crash Resistance, Licence…

NoSQL
FAZIT

Unbedingt RAM & SDD annehmen!
Lot‘s of >1 PT RAM DBsin California!
Service, RAM, Cloud, Mobile
SAP-Strategie:

DaaS Zeitalter
Alleine für MongoDB weit über 100 „Database-as-a-Service“ Provider!Amazon: SimpleDB, Hadoop, etc.

Viele clevere hybrid Lösungen!Viele clevere hybrid Lösungen!
CouchBase, Hadoop+MySQL

Database-aaS => best Mix!
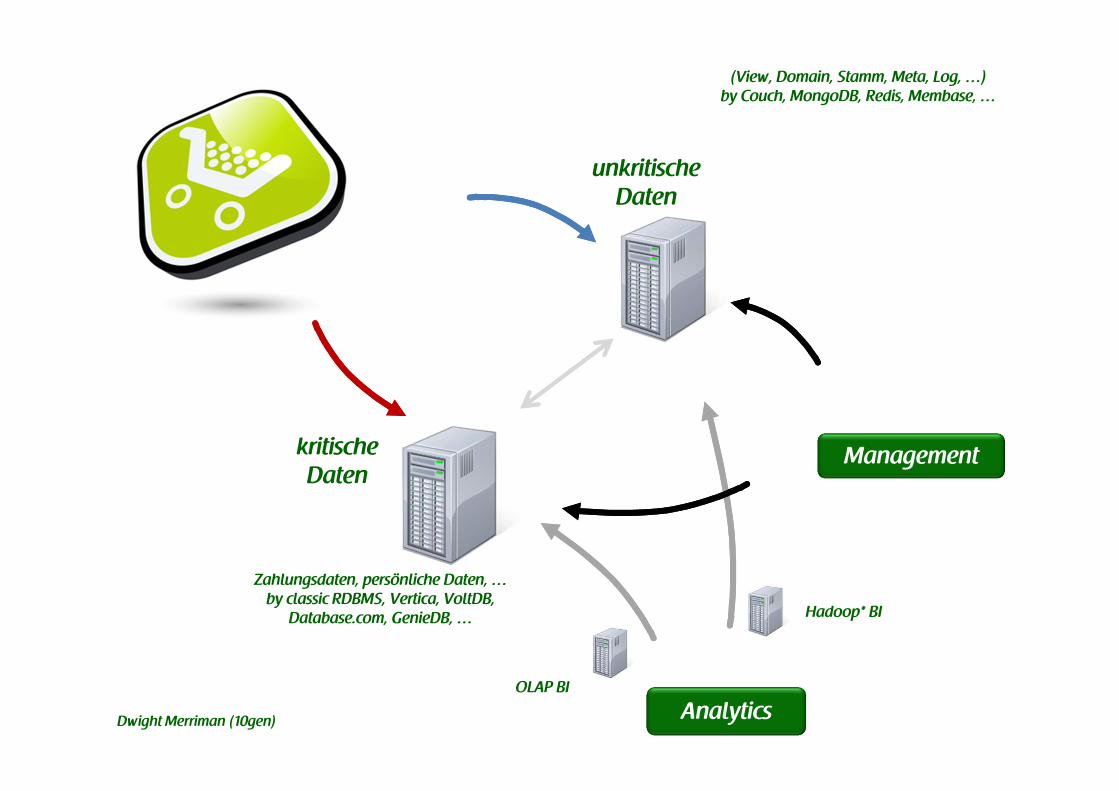
kritischeDaten
unkritischeDaten
(View, Domain, Stamm, Meta, Log, …)by Couch, MongoDB, Redis, Membase, …
Management
Analytics
Zahlungsdaten, persönliche Daten, …by classic RDBMS, Vertica, VoltDB,
Database.com, GenieDB, … Hadoop* BI
OLAP BI
Dwight Merriman (10gen)

451Group

Links
• nosql-database.org
• nosqltapes.com
• mynosql.com
.com

http://edlich.de


















