
Reference:Dongsheng Lu’s Normalization slides Normalization.
Upload
artem-lukaninCategory
view
67download
2
ANALYSIS OF IMAGES, SOCIAL NETWORKS, AND TEXTSApril, 9-11th, 2015, Yekaterinburg
Normalization of Non-Standard Words with Finite State Transducers for Russian Speech Synthesis
Artem Lukanin

Text Preprocessing for Speech Synthesis• is usually a very complex task
• Text normalization is one of the steps in text preprocessing [1]
• sentence segmentation
• tokenization
• normalization of non-standard words (NSWs)
• numbers, abbreviations, and acronyms
• different characters like % , $ , # , № , etc.
2

Normalization of Non-Standard Words• NSWs must be expanded into full SW to be pronounced correctly
• It's even more complex in inflective languages such as Russian
• ordinal number can be converted into 36 different word forms (6
cases * 2 numers * 3 genders)
• digit position changes the output standard word
• 1111 1 — первый
• 111 11 — одиннадцатый
• 11 1 11 — сто
• 1 1 111 — тысяча
• 11 111 — одиннадцать
тысяч
3

Existing Russian Normalization Systems• As a part of proprietory Text-to-Speech (TTS) systems
• Google Translate, https://translate.google.ru/
• VitalVoice, http://cards.voicefabric.ru/
• Windows SAPI voices, etc.
• As a part of open-source TTS systems
• Festival [2]
• only digit-by-digit number normalization for the Russian voice
4

Normatex• is the first Russian open-source normalization system, known to the
author, github.com/avlukanin/normatex
• If the input texts are normalized beforehand the quality of the
synthesized speech of existing TTS systems can be improved
• 118 finite state transducers (FSTs) for conversion of cardinal and ordinal
numbers into the corresponding numerals, which can preprocess
different ranges, time, dates, telephone numbers, postal codes, etc.
• 33 FSTs for normalization of graphic abbreviations and acronyms
5

Test Parallel Corpus• 66 original texts of the official site of South Ural State University,
susu.ac.ru, which contains 38,439 tokens (broad segmentation units [3]):
• 14,661 word tokens
• 333 acronyms and 98 initials; 379 graphic abbreviations
• 977 number tokens (2,511 digits)
• 66 manually preprocessed texts, where all numbers, abbreviations and
acronyms were expanded into full words or replaced with pronounceable
combination of letters
6

Finite State Transducers• are developed in the form of graphs in Unitex 3.1beta
• Before applying FSTs to a text, it is preprocessed:
• The text is splitted into sentences
• The text is tokenized
• Every token is assigned all possible grammatical forms
• Number FSTs are applied first to deal with numbers and measure unit
abbreviations
• Abbreviation FSTs and acronym FSTs are applied sequentially after that
7

Cardinal Numbers• agree with nouns in case, but the numerals один “one” and два “two”
agree in gender as well
• all the constituent words of a compound numeral agree with the
corresponding noun: двадцати одного and двадцати одной (“twenty-
one” in gen. m. and f.)
• одни (“one” in plural) agrees only with pluralia tantum, e.g. одни
ножницы “one pair of scissors”, одни брюки “one pair of pants” [4]
8
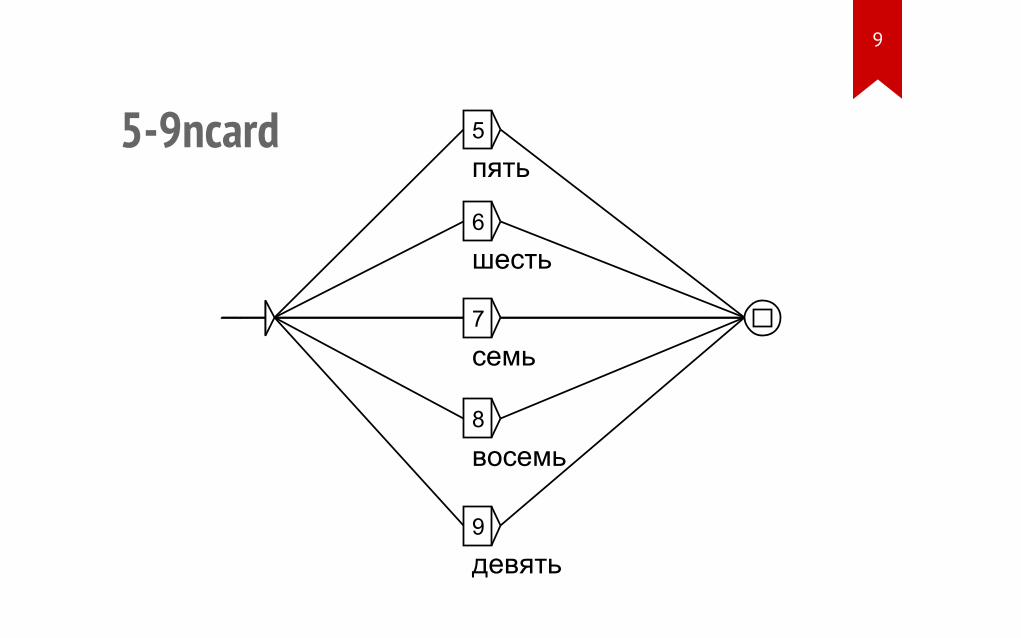
5-9ncard 5пять
6шесть
7семь
8восемь
9девять
9

2x-9xncard2двадцать
3тридцать
4сорок
5пятьдесят
6шестьдесят
7семьдесят
8восемьдесят
9девяносто
10

NUM-5-9-ncard
59ncard
2x9xncard
1019ncard
пробел
0
NUMxxncard
0
пробел
11

units
NUM1ncard
NUM2ncard
NUM59ncard
NUM34ncard
units1 <N:g><A:g>[ ]
units24
" "
" "
из 29gcard*1mgcard
12

Ordinal Numbers• Simple ordinal numerals agree with nouns in gender, case and number
• In compound ordinal numerals only the last constituent word agrees with
the noun [5]: две тысячи четырнадцатом (“two thousand fourteenth” in
prepositional masculine)
• Complex ordinal numbers, ending in -00, -000, -000000, -000000000, are
written without spaces: “153000” is converted into
стопятидесятитрёхтысячный “one hundred and fifty-three thousandth”
in nominative masculine
13

Ordinal Numbers• Only the last constituent words -сотый “hundredth”, -тысячный
“thousandth”, -миллионный “millionth”, -миллиардный “billionth”
agree with the nouns
• The words, preceding the last word, are used in genitive plural (the
exceptions are сто “one hundred” and девяносто “ninety”, which are
used in the nominative case) [6]
14

Acronyms• Most acronyms should be converted into full words before speech
synthesis, because it is difficult for people to comprehend a letter-by-
letter pronunciation in speech and because acronyms are often rare for
everybody to know what phrase the acronym corresponds to
ФГБОУ ВПО «ЮУрГУ» (НИУ) → Федеральное государственное
бюджетное образовательное учреждение высшего
профессионального образования «Южно-Уральский государственный
университет» (Научно-исследовательский университет)
ФГБОУ ВПО «ЮУрГУ» (НИУ)
15

Acronyms• The main component of an acronym is a noun, that is why there can be
12 possible forms of the converted phrase (six cases and two numbers) in
Russian
• There are rules for all six cases in Normatex
• Acronyms can be ambiguous in different corpora
• For all ambiguous or unknown acronyms Normatex substitutes each
letter with its alphabet name: ВПП → ВэПэПэ
16

Graphic Abbreviations• Single interpretation: и т.д. “etc.” → и так далее , т.е. “i.e.” → то есть
• The interpretation depends on the context: и др. “et al.” → и другие
“and others”, и других “and others”, и другим “and others”, и другое
“and other”
• Ambiguous: г. → год “year”, город “city”, грамм “gram” (every noun
can have 12 word forms), Аудитория: 339-г, 339-д “Room 339-g, 339-d
• Sufficient left and right contexts should be provided in FSTs as well as
FSTs should be applied in a definite order
17

ResultsToken type Tokens Correct Errors Recall Precision
Numbers 977 920 53 94.17% 94.55%
Acronyms and initials 431 355 40 82.37% 89.87%
Graphic abbreviations 379 232 4 61.21% 98.05%
Total 1787 1507 97 84.33% 93.95%
The work is still in progress
18

References1. Reichel, U.D., Pfitzinger, H.R.: Text preprocessing for speech synthesis
(2006)
2. The Festival Speech Synthesis System,
http://www.cstr.ed.ac.uk/projects/festival/
3. Dutoit, T.: An introduction to text-to-speech synthesis (Vol. 3). Springer
Science & Busi-ness Media (1997)
4. Russian Grammar [Русская грамматика]. Vol. 1. Nauka, Moscow (1980)
19

References5. Rosental, D.E., Golub, I.B., Telenkova, M.A.: The Modern Russian Language
[Современный русский язык]. Airis-Press, Moscow (1997)
6. Rosental, D.E., Djandjakova, E.V., Kabanova, N.P.: Reference Book on
Orthography, Pronunciation, Literary Editing [Справочник по
правописанию, произношению, литературному редактированию].
CheRo, Moscow (1998)
20

Normatex — Russian text normalizationgithub.com/avlukanin/normatex
Artem Lukanin
• about.me/alukanin
• @avlukanin
Slides: artyom.ice-lc.com/slides/normatex
21


















