
NLP for Everyday People
35
1 Natural Language Processing for Everyday People Dr. Rebecca Bilbro, Lead Data Scientist
-
Upload
rebecca-bilbro -
Category
Technology
-
view
107 -
download
0
Transcript of NLP for Everyday People

1
Natural Language Processing for Everyday People
Dr. Rebecca Bilbro,Lead Data Scientist

2
Rebecca BilbroLead Data Scientist, BytecubedOrganizer, Data Science DCFaculty, Georgetown Univ.& District Data Labs
[email protected]/rebeccabilbrotwitter.com/rebeccabilbro

3Main take-aways
NLP is... • different from numerical ML (but also the same).• not about beautiful, bespoke algorithms. • hard and messy work.• necessary.

4Overview
• Everyday NLP• Language aware applications• Nuts and bolts of NLP• Open source tools• Questions

5
Everyday NLP

6
• Summarization• Reference Resolution• Machine Translation• Language Generation• Language Understanding• Document Classification• Author Identification• Part of Speech Tagging
• Question Answering• Information Extraction• Information Retrieval• Speech Recognition• Sense Disambiguation• Topic Recognition• Relationship Detection• Named Entity Recognition
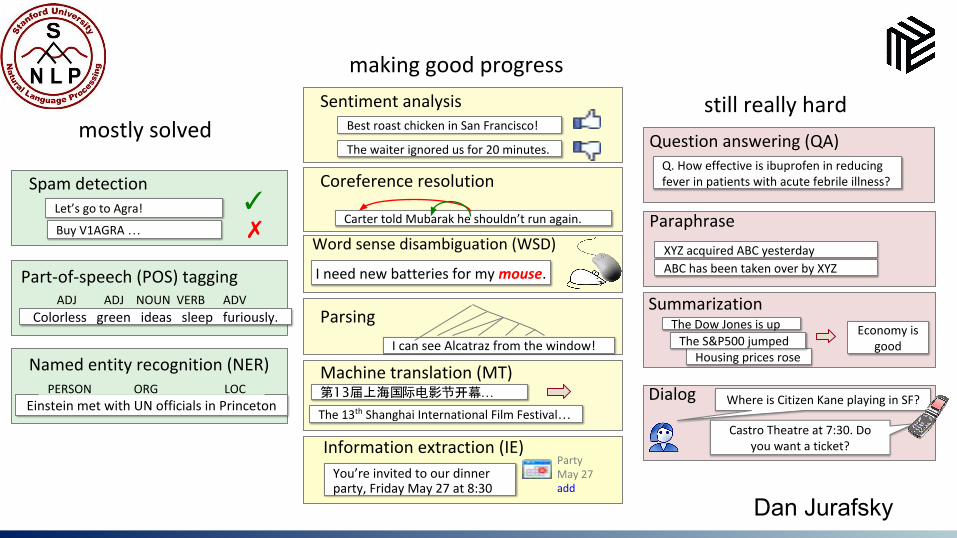
Everyday NLP Problems
7
Coreference resolution
Question answering (QA)
Part-of-speech (POS) tagging
Word sense disambiguation (WSD)
Paraphrase
Named entity recognition (NER)
ParsingSummarization
Information extraction (IE)
Machine translation (MT)Dialog
Sentiment analysis
mostly solved
making good progress
still really hard
Spam detectionLet’s go to Agra!
Buy V1AGRA …
✓✗
Colorless green ideas sleep furiously. ADJ ADJ NOUN VERB ADV
Einstein met with UN officials in PrincetonPERSON ORG LOC
You’re invited to our dinner party, Friday May 27 at 8:30
PartyMay 27add
Best roast chicken in San Francisco!
The waiter ignored us for 20 minutes.
Carter told Mubarak he shouldn’t run again.
I need new batteries for my mouse.
The 13th Shanghai International Film Festival…第13届上海国际电影节开幕…
The Dow Jones is up
Housing prices rose
Economy is good
Q. How effective is ibuprofen in reducing fever in patients with acute febrile illness?
I can see Alcatraz from the window!
XYZ acquired ABC yesterday
ABC has been taken over by XYZ
Where is Citizen Kane playing in SF?
Castro Theatre at 7:30. Do you want a ticket?
The S&P500 jumped
Dan Jurafsky

8

9
Language aware applications
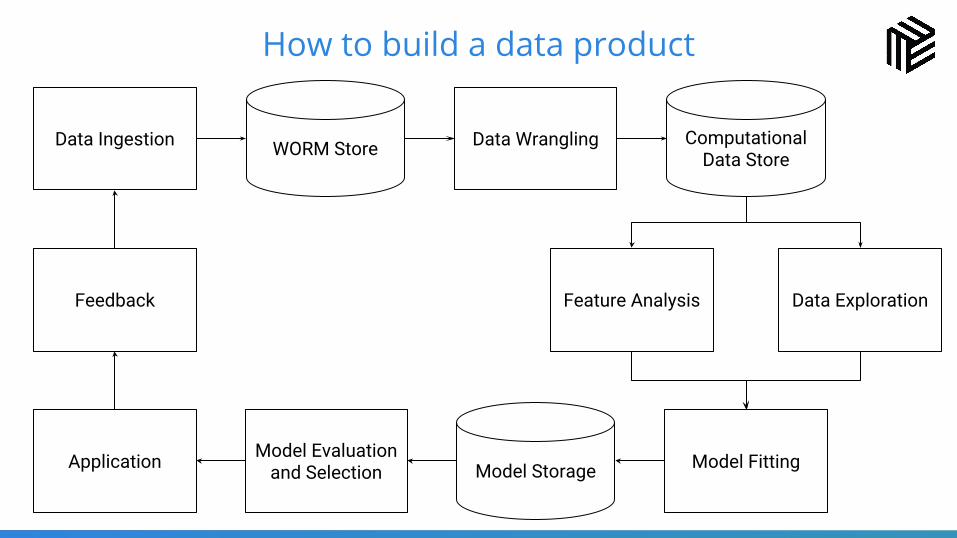
10How to build a data product
Data Ingestion Data Wrangling Computational Data StoreWORM Store
Data ExplorationFeature Analysis
Model Storage Model FittingModel Evaluation and SelectionApplication
Feedback
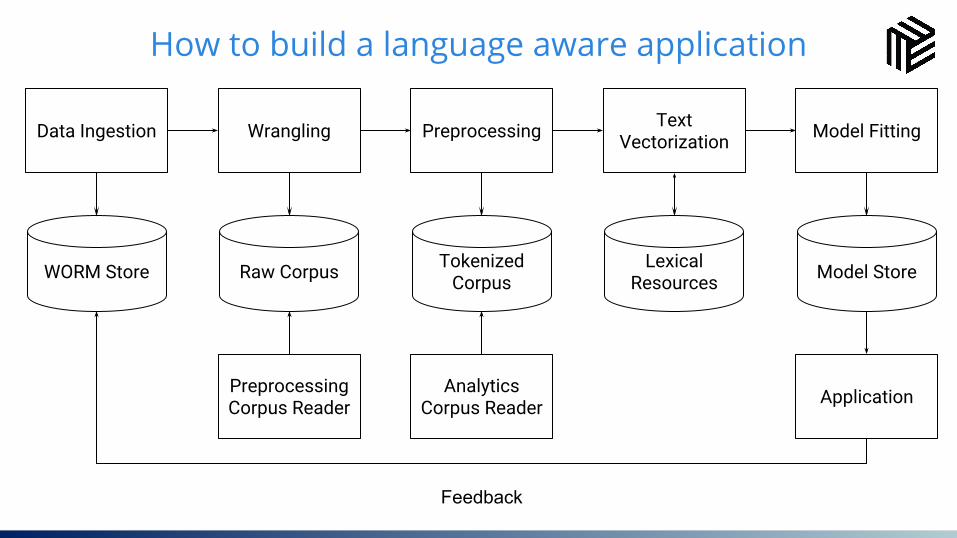
11How to build a language aware application
Data Ingestion Wrangling Preprocessing
WORM Store
Analytics Corpus Reader
Preprocessing Corpus Reader
Raw Corpus Tokenized Corpus
Text Vectorization Model Fitting
Model Store
Application
Lexical Resources
Feedback

12Language Aware Applications
• Not automagic• Take in text data as input• Parse into composite parts• Compute upon composites• Derive model• Introduce new data• Predict• Deliver result• Ingest feedback• Do it all again (but better!)

13Language Aware Applications
Challenges:• Ingestion• Messy data• Language Ambiguity• High dimensional feature space• Computation speed• Cross-validation• Pipelines

14Language Aware Applications
Requirements:• Robust data management• Domain-specific corpora• Normalization• Vectorization• Streaming• Dimensionality reduction• Visualization• Repeatability

15
Nuts and bolts of NLP

16Nuts and Bolts
• Ingestion• Parsing• Tokenization• Normalization• Vectorization• Classification• Clustering• Pipelines

17Nuts and Bolts
• Ingestion• Parsing• Tokenization• Normalization• Vectorization• Classification• Clustering• Pipelines
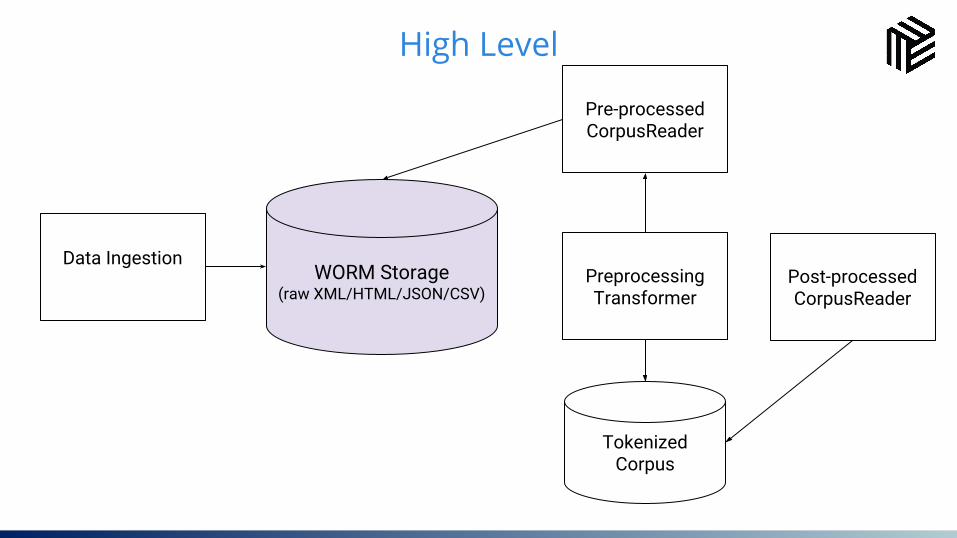
18High Level
Data IngestionPreprocessingTransformer
Pre-processed CorpusReader
WORM Storage(raw XML/HTML/JSON/CSV)
Tokenized Corpus
Post-processed CorpusReader

19Nuts and Bolts
• Ingestion• Parsing• Tokenization• Normalization• Vectorization• Classification• Clustering• Pipelines

20Parse
from nltk import sent_tokenize
def sents(self, fileids=None, categories=None): """ Uses built-in NLTK sentence tokenizer to extract sentences from Paragraphs. """ for paragraph in self.paras(fileids, categories): for sentence in sent_tokenize(paragraph): yield sentence

21Tokenize
from nltk import wordpunct_tokenize
def words(self, fileids=None, categories=None): """ Use built-in NLTK word tokenizer to extract tokens from
sentences. """ for sentence in self.sents(fileids, categories): for token in wordpunct_tokenize(sentence): yield token
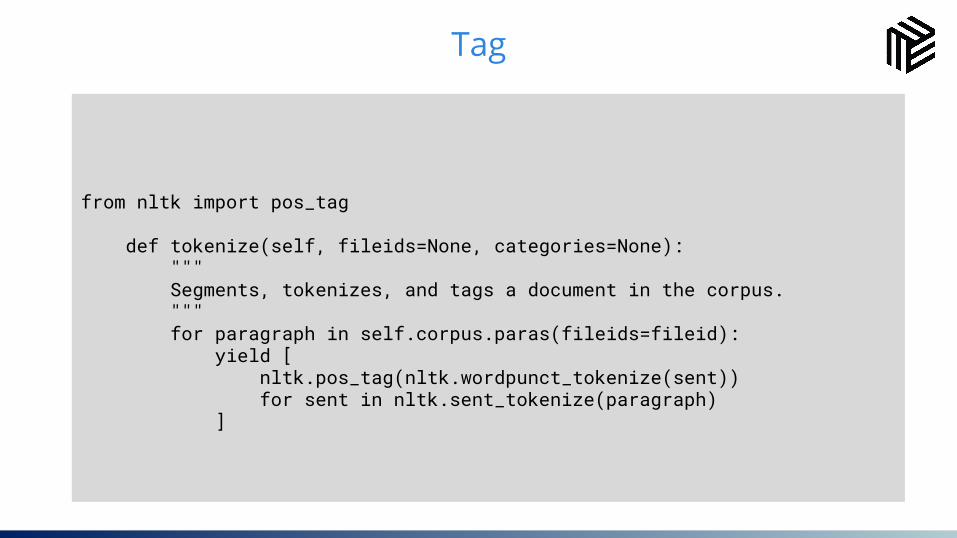
22Tag
from nltk import pos_tag
def tokenize(self, fileids=None, categories=None): """ Segments, tokenizes, and tags a document in the corpus. """ for paragraph in self.corpus.paras(fileids=fileid): yield [ nltk.pos_tag(nltk.wordpunct_tokenize(sent)) for sent in nltk.sent_tokenize(paragraph) ]

23Nuts and Bolts
• Ingestion• Parsing• Tokenization• Normalization• Vectorization• Classification• Clustering• Pipelines

24Normalization
import nltkimport string
def tokenize(text): stem = nltk.stem.SnowballStemmer('english') text = text.lower()
for token in nltk.word_tokenize(text): if token in string.punctuation: continue yield stem.stem(token)
corpus = [ "The elephant sneezed at the sight of potatoes.", "Bats can see via echolocation. See the bat sight sneeze!", "Wondering, she opened the door to the studio.",]

25Nuts and Bolts
• Ingestion• Parsing• Tokenization• Normalization• Vectorization• Classification• Clustering• Pipelines

26Vectorization
The elephant sneezed at the sight of potatoes.
Bats can see via echolocation. See the bat sight sneeze!
Wondering, she opened the door to the studio.
at bat can
door
echo
locati
on
elepha
nt ofop
en
potato se
esh
esig
ht
snee
ze
studio th
e to via
wonder
Multiple Options!Bag-of-words · One-hot encoding · TFIDF · Distributed representation

27Nuts and Bolts
• Ingestion• Parsing• Tokenization• Normalization• Vectorization• Classification• Clustering• Pipelines
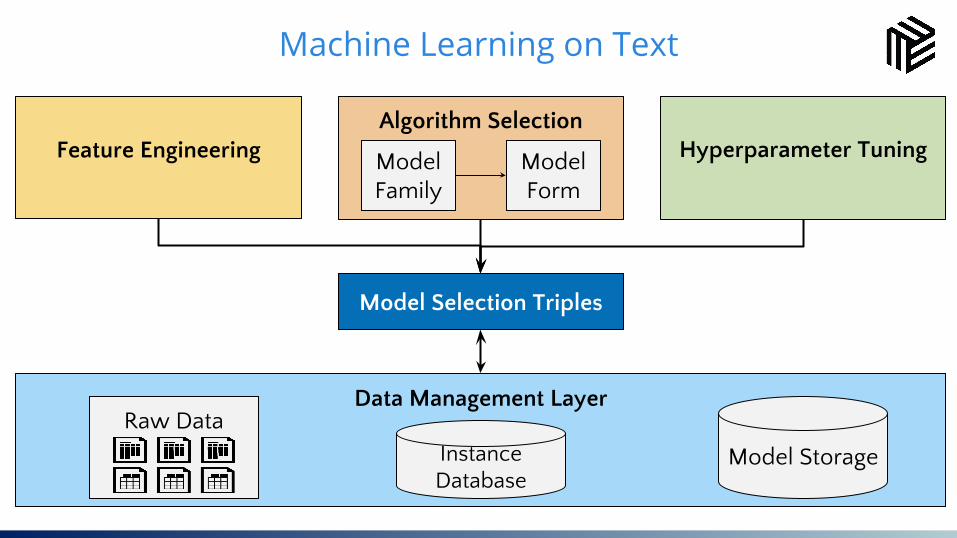
28Machine Learning on Text
Data Management LayerRaw Data
Feature Engineering Hyperparameter TuningAlgorithm Selection
Model Selection Triples
Instance Database
Model Storage
Model Family
Model Form

29Nuts and Bolts
• Ingestion• Parsing• Tokenization• Normalization• Vectorization• Classification• Clustering• Pipelines
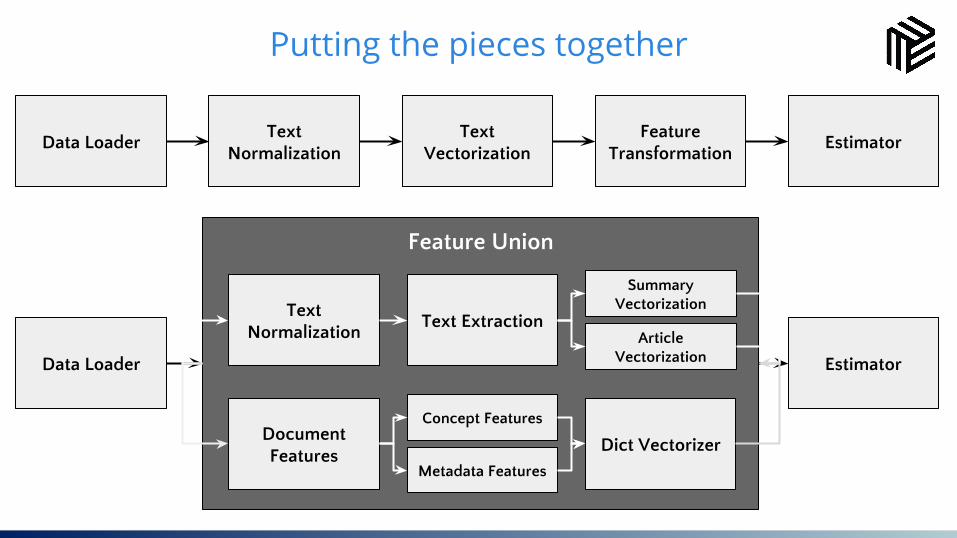
30Putting the pieces together
Data LoaderText
NormalizationText
VectorizationFeature
TransformationEstimator
Data Loader
Feature Union
Estimator
Text Normalization
Document Features
Text Extraction
Summary Vectorization
Article Vectorization
Concept Features
Metadata Features
Dict Vectorizer

31
Open Source Tools(in Python)
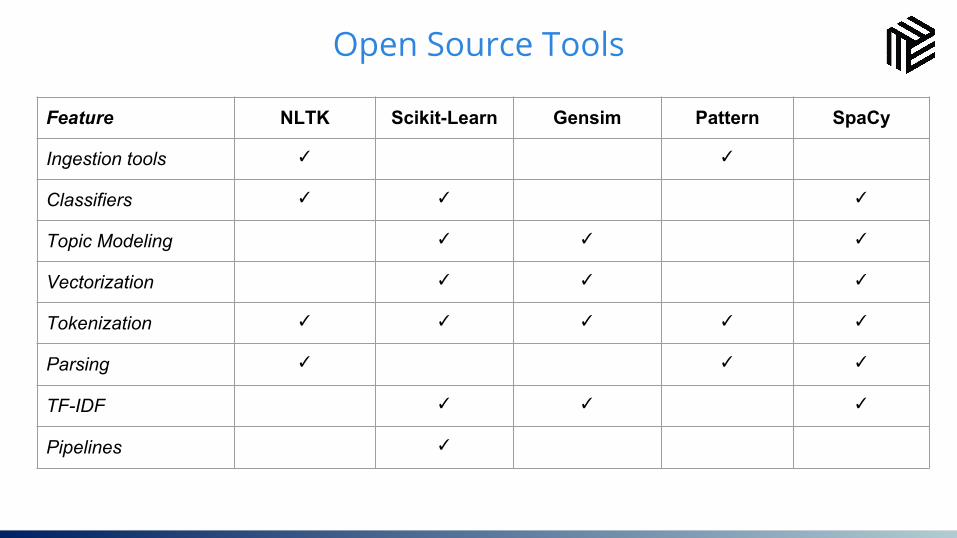
32Open Source Tools
Feature NLTK Scikit-Learn Gensim Pattern SpaCy
Ingestion tools ✓ ✓
Classifiers ✓ ✓ ✓
Topic Modeling ✓ ✓ ✓
Vectorization ✓ ✓ ✓
Tokenization ✓ ✓ ✓ ✓ ✓
Parsing ✓ ✓ ✓
TF-IDF ✓ ✓ ✓
Pipelines ✓

33Open Source Tools
For ingestionRequests, BeautifulSoup => Baleen
For preprocessing and normalizationNLTK => Minke
For machine learningScikit-Learn, Gensim, Spacy => Yellowbrick

34Main take-aways
NLP is... • different from numerical ML (but also the same).• not about beautiful, bespoke algorithms. • hard and messy work.• necessary.


















