
NEXT GENERATION SEQUENCING SERVICE GUIDEsepantapaya.com/myfiles/_sys/core.fileman/fa10040/1.pdf ·...
25
www.lifescience.sourcebioscience.com NEXT GENERATION SEQUENCING SERVICE GUIDE
-
Upload
nguyenngoc -
Category
Documents
-
view
221 -
download
0
Transcript of NEXT GENERATION SEQUENCING SERVICE GUIDEsepantapaya.com/myfiles/_sys/core.fileman/fa10040/1.pdf ·...

www.lifescience.sourcebioscience.com
NEXT GENERATION SEQUENCING SERVICE GUIDE

www.lifescience.sourcebioscience.com
ABOUT SOURCE BIOSCIENCE
Source BioScience is an international genetic analysis and diagnostics business
serving the research and healthcare markets. The group headquarters are based in
Nottingham, U.K. operating state of the art laboratory facilities with additional
laboratories in Oxford, Cambridge, Dublin, Rochdale and Germany. Source
BioScience provides a comprehensive portfolio of genetic analysis services and
diagnostic testing’s for both the Research and Healthcare sectors.
Life Science Research
Source BioScience LifeSciences is the European leader in DNA sequencing and
genomic services. We offer a diverse range of services and products, including
Sanger Sequencing, Next Generation Sequencing, Genotyping, Gene Expression,
Bioinformatics, Clones and Antibodies. Our extensive portfolio includes over 20
million clones and over 100,000 antibodies, plus a wide range of research reagents
for applications such as cell culture, immunology and nucleic acid analysis.
Further information about our Services and Products can be found on our
website: www.lifesciences.sourcebioscience.com
As a leading provider of genomic research service in the UK, Source BioScience
is pleased to offer our customers Next Generation Sequencing using the
Illumina HiSeq 2000 and MiSeq platforms.
Our Key Strengths are:
Over a decade of experience in the sequencing field
We have the largest commercial capacity for Illumina Sequencing in the UK with two
HiSeq 2000 and one MiSeq platforms, providing our clients with the fastest
turnaround times.
Dedication to providing the highest quality service to our clients
Our service is certified to the Illumina sequencing CSPro™ status and operates a
robust quality management system. In addition, we are also GLP, GCP and CPA
certified, ensuring that our clients enjoy the highest quality of data and service.

www.lifescience.sourcebioscience.com
Individual project managers for every project
We understand the importance of your project. An individual project manager is
assigned to your project and will be your point of contact. They will continually
update you on the progress of your project throughout the process.
Advanced Bioinformatic Solutions
We offer advanced bioinformatics solutions for every application to assist
researchers in the analysis of the vast amounts of data produced by the Illumina
Sequencing Systems.
This guide explains our Illumina sequencing service and processes which we hope
will help you in understanding our service.
Contact Us
We are happy to talk to you about experimental designs and to assist you in grant
applications. If you have any queries regarding our Illumina sequencing service, please do
not hesitate to get in touch.
Tel (UK): 0800 652 6774 Tel (Non UK): +44 (0) 115 973 9018 Fax: +44 (0) 115 973 9021 Email: [email protected]

www.lifescience.sourcebioscience.com
SEQUENCING PLATFORMS
INTRODUCTION
The Illumina HiSeq 2000 and MiSeq are groundbreaking platforms for genetic
analysis and functional genomics. Both platforms combine’s Illumina’s Sequencing-
by-Synthesis (SBS) technology providing high sequencing throughput and fast data
generation. The HiSeq 2000 generates up to 300Gb (gigabase) of data per
sequencing run, equivalent to 37.5Gb per lane. The MiSeq generates up to 13.2-
15Gb of data per sequencing run. The Illumina sequencing platforms combines
innovative engineering with advanced SBS chemistry technology to provide high
outputs, simplicity and cost-effectiveness making any sequencing project possible.
NGS SEQUENCING PLATFORMS PROVIDED BY SOURCE BIOSCIENCE
1. HiSeq 2000
2. MiSeq
SEQUENCING PLATFORM: HISEQ 2000
INTRODUCTION TO HISEQ 2000
The Illumina HiSeq 2000 utilizes Illumina’s reversible terminator sequencing by
synthesis (SBS) chemistry with cutting-edge scanning and imaging technology. The
HiSeq 2000 is able to dramatically increase the number of reads, sequence output
and data generation rate. The HiSeq 2000 has the ability to operate a single or dual
flow cell mode offering experimental flexibility. The flow cells are operated
independently of each other to allow different read lengths to be run
simultaneously.
FIGURE 1: ILLUMINA HISEQ 2000, IMAGE PROVIDED BY ILLUMINA

www.lifescience.sourcebioscience.com
SEQUENCING ON THE HISEQ 2000
After Library Preparation, the libraries are ready to be sequenced. To prepare the
libraries for sequencing, the libraries are amplified by cluster generation using the
cBot. The cBot is a revolutionary automated clonal amplification system providing
efficiency and ease of use for the highest quality sequencing results. The process of
clonal amplification on the cBot is called Bridge Amplification. Bridge amplification
produces clusters that are used for sequencing.
CLUSTER GENERATION
Cluster generation is completed on the cBot. The cBot uses Bridge Amplification to
create hundreds of millions of single-molecule DNA templates. The Illumina Flow
Cell is coated in oligonucleotides complimentary to the adapters used to generate
the libraries. The oligonucleotides enable the adapters on the DNA strands to bind
to the surface of the Illumina Flow cell. There are 8 lanes on an Illumina Flow cell,
allowing one sample to be run per lane or more if multiplexed.
FIGURE 2: CLUSTER GENERATION BY BRIDGE AMPLIFICATION

www.lifescience.sourcebioscience.com
CLUSTER GENERATION STEP-BY-STEP
TEMPLATES CAPTURED BY OLIGONUCLEOTIDE LAWN ON FLOW CELL
DNA LIBRARY DILUTED & DENATURED
TEMPLATES BOUND TO THE PRIMERS ARE 3’ EXTENDED, PRODUCING COVALENTLY
ATTACHED DISCRETE SINGLE MOLECULE
DOUBLE STRANDED MOLECULE IS DENATURED AND ORGINAL TEMPLATE WASHED AWAY
FREE ENDS OF BOUND TEMPLATES HYBRIDZE TO ADJACENT LAWN PRIMERS TO FORM
U-SHAPED BRIDGES
THE DNA BRIDGE IS COPIED FROM THE PRIMER TO CREATE A DOUBLE STRANDED DNA
BRIDGE
THE RESULTING DOUBLE STRANDED DNA IS DENATURED FROM A HYBRIDIZED TO LAWN-
PRIMERS TO FORM NEW BRIDGES AND EXTEND AGAIN
REPEAT 35 TIMES TO CREATE A DENSE CLUSTER OF OVER 2000 MOLECULES
REVERSE STRANDS IN THE CLUSTER ARE REMOVED BY CLEAVAGE ST THE REVERSE
STRAND SPECIFIC LAWN PRIMERS, LEAVING A CLUSTER WITH FORWARD STRANDS ONLY
THE FREE 3’ OH ENDS ARE BLOCKED TO PREVENT NON-SPECIFIC PRIMING
SEQUENCING PRIMERS ARE HYBRIDIZED TO FREE ENDS OF THE DNA TEMPLATES

www.lifescience.sourcebioscience.com
SEQUENCING BY SYNTHESIS (SBS)
The clustered flow cell is ready to be sequenced using the SBS chemistry on the
HiSeq 2000. Hundreds of millions of DNA fragment clusters are sequenced in
parallel using a propriety reversible-terminator method that detects single
nucleotide base as they are incorporated into growing DNA strands. The SBS
chemistry uses four fluorescently labeled deoxynucleotide triphosphate (dNTP) to
sequence the clusters present on the flow cell. Each nucleotide label serves as a
terminator for polymerization, thus after each dNTP incorporation, the fluorescent
dye is imaged to identify the base and then enzymatically cleaved to allow
incorporation of the next nucleotide. The process of adding the dNTP, scanning and
imaging of the base occurs at each cycle until the DNA strand is sequenced. All four
reversible terminator-bound dNTPs (A, G, T, C) are present as single, separate
molecules, natural competition minimizes incorporation bias. The base calls are
made directly from the signal intensity measurements during each sequencing
cycle. This results in an accurate base–by-base sequencing that greatly reduces
sequence-context specific errors enabling robust base calling across the genome,
including repetitive regions.
FIGURE 3: ILLUSTRATION OF SEQUENCING BY SYNTHESIS (SBS)
www.lifescience.sourcebioscience.com
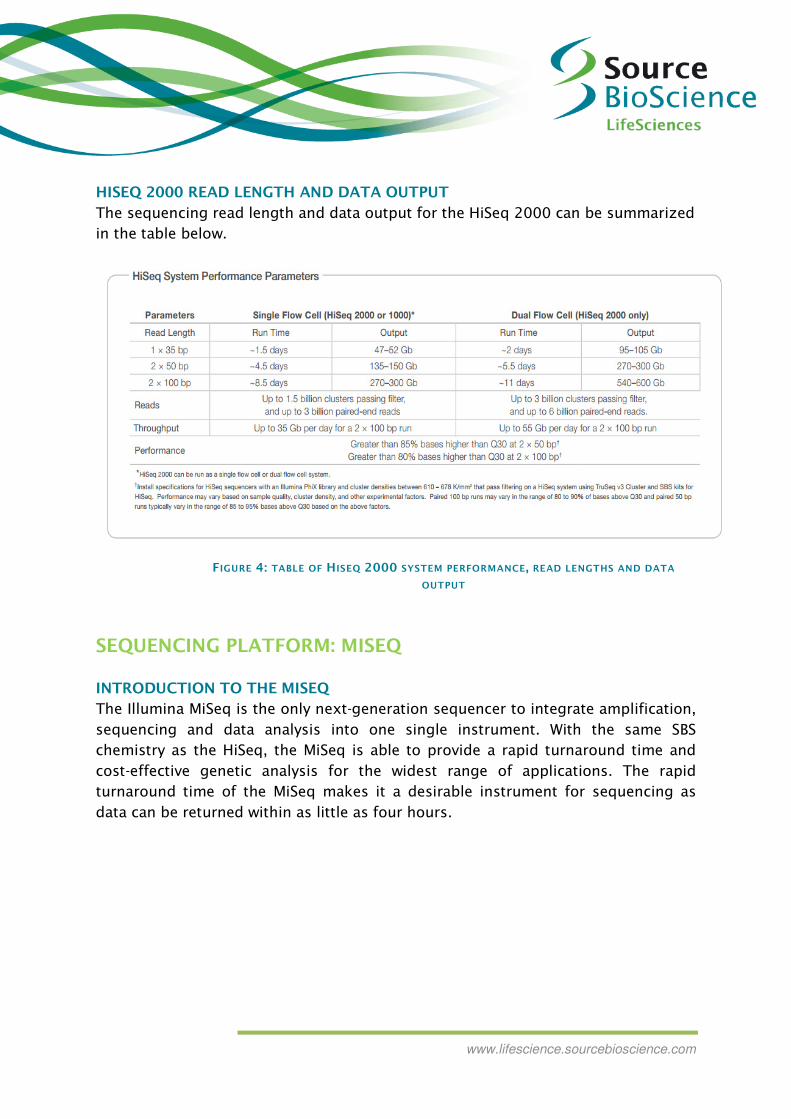
HISEQ 2000 READ LENGTH AND DATA OUTPUT
The sequencing read length and data output for the HiSeq 2000 can be summarized
in the table below.
FIGURE 4: TABLE OF HISEQ 2000 SYSTEM PERFORMANCE, READ LENGTHS AND DATA
OUTPUT
SEQUENCING PLATFORM: MISEQ
INTRODUCTION TO THE MISEQ
The Illumina MiSeq is the only next-generation sequencer to integrate amplification,
sequencing and data analysis into one single instrument. With the same SBS
chemistry as the HiSeq, the MiSeq is able to provide a rapid turnaround time and
cost-effective genetic analysis for the widest range of applications. The rapid
turnaround time of the MiSeq makes it a desirable instrument for sequencing as
data can be returned within as little as four hours.

www.lifescience.sourcebioscience.com
FIGURE 5: ILLUMINA M ISEQ, IMAGE PROVIDED BY ILLUMINA
SEQUENCING ON THE MISEQ
The all-in-one MiSeq platform incorporates cluster generation, paired-end fluidics
and completes data analysis. The MiSeq is able to perform cluster generation
without the need of another instrument, sequencing is completed using SBS
chemistry followed by data analysis. Primary analysis is performed by the MiSeq
which includes base calling, filtering and quality scoring. Secondary analysis is
performed to include alignment and variant calling. The primary and secondary
analysis is performed using Illumina MiSeq Reporter software. Customers are able
to use Illumina’s BaseSpace, the next-generation sequencing cloud computing
environment which enables researchers to easily and securely analyze, archive and
share MiSeq data.
The Illumina MiSeq is the first sequencer to be integrated into a cloud platform
allowing data to be pushed to the cloud for automatic storage and analysis. Source
Bioscience customers can create a BaseSpace account and this would enable us to
share the MiSeq data files with the customer through a collaborator site. This allows
access to NGS data on any internet enabled device including tablets and smart
phones.
BaseSpace also allows MiSeq user access to a multitude of sequence analysis apps
allowing applications ranging from genome visualization to de-novo assembly of
small genomes and variant calling.
Further information on BaseSpace can be found on the Illumina Website:
https://basespace.illumina.com/home/index

www.lifescience.sourcebioscience.com
MISEQ READ LENGTH AND DATA OUTPUT
The sequencing read length and data output for the MiSeq is summarized in the
table below.
FIGURE 6: TABLE OF MISEQ SYSTEM PERFORMANCE , READ LENGTH AND DATA OUTPUT
PLATFORM COMPARISON
This quick guide is to give an overview of the two Next-Generation Sequencing
platforms we have to offer, the HiSeq 2000 and MiSeq. The table gives a
comparison of both platforms and what applications the platforms can be used for.
HISEQ 2000 MISEQ

www.lifescience.sourcebioscience.com
HiSeq 2000 MiSeq
OUTPUT Up to 300 Gb Up to 13.2-15 Gb
SINGLE READS (MAXIMUM)
1.5 billion total 187 million/lane
22-25 million total
PAIRED- END READS
(MAXIMUM)
3 billion 374 million/lane
44-50 million total
REQUIRED INPUT
50ng with Nextera 100ng-1ug with TruSeq
50ng with Nextera 100ng-1ug with TruSeq
READ LENGTH Up to 2 x 100bp Up to 2 x 300bp
PERCENTAGE OF BASES >Q30
>85% (2 x 50bp) >80% (2 x 100bp)
>85% (2 x 75bp) >70% (2 x 300bp)
APPLICATIONS
Whole Genome Sequencing
Exome Sequencing Targeted Resequencing Transcriptome Sequencing
ChIP Sequencing Small RNA Sequencing Amplicon Sequencing
Whole Genome Sequencing Exome Sequencing
Targeted Resequencing Transcriptome Sequencing
ChIP Sequencing Small RNA Sequencing
Metagenomics Sequencing Amplicon Sequencing
APPLICATIONS
Next generation sequencing (NGS) platforms enable a wide variety of applications,
allowing researchers to ask virtually any question of the genome, transcriptome and
epigenome of any organism. There are a range of library preparation kits that offer
protocols for sequencing whole genomes, mRNA, targeted regions such as whole
exomes, custom-selected regions, protein-binding regions and more. The sample
preparation protocols are very straightforward. Researchers start with gDNA or RNA
samples. DNA or cDNA fragments are then ligated to platform-specific

www.lifescience.sourcebioscience.com
oligonucleotide adapters needed to perform the sequencing biochemistry. The
samples are then clustered onto the flow cell in preparation for sequencing.
The Illumina Sequencing Platforms supports multiple applications including:
1. Whole Genome Sequencing
2. Exome Sequencing
3. Transcriptome Sequencing
4. Small RNA Sequencing
5. Chromatin-Immunoprecipitation Sequencing (ChIP-Seq)
6. Metagenomics Sequencing
7. Targeted Re-Sequencing
Each section will have information about the library preparation kits we use at
Source BioScience. There will be web links to each of the library preparation kits if
you need further information. Each of the library preparations allow for the
multiplexing of large numbers of samples on a single sequencing run. Most of the
standard kits allow for multiplexing of 48 samples per run but some allow up to 96
samples per run.
WHOLE GENOME SEQUENCING
Whole genome sequencing determines the complete DNA sequence of an organism.
This includes sequencing of all of an organism’s chromosomal DNA as well as DNA
contained in the mitochondria or chloroplast. The cost of sequencing a genome has
reduced dramatically as the technology greatly improves. This gives us the
opportunity to discover more about variations in genomes by utilizing these
powerful NGS platforms.
The NGS Platforms are able to offer single and pair-end reads to enable the
discovery and confirmation of mutations, chromosomal rearrangements or single
polynucleotide polymorphisms through re-sequencing or de novo assemblies.
Re-sequencing enables researchers to align the data to a known reference genome,
whereby de novo assembly reads are aligned without a reference genome.
De novo assemblies are challenging as a range of factors can affect the data quality
such as short read lengths and size and continuity of contigs which may present
gaps in the data and reduce alignment. To overcome this issue, pair-end reads
sequence both ends of the DNA fragment which results in superior alignment,
particularly across repetitive sequencing regions and produces longer contigs that

www.lifescience.sourcebioscience.com
align better and gives a fuller complete coverage. Mate pair sequencing with large
insert also can provide useful information for assembly of repetitive regions in the
genome and results in more complete assemblies. Source Bioscience also offer the
UK largest commercial Sanger sequencing service which can be used to close gaps
after a de novo assembly has been created from NGS data.
The popular areas in which researchers are taking advantage of this powerful
technology are:
• Human & Mammalian Genetics: Detection of known and novel mutations in
specific regions of interest using targeted re-sequencing
• Microbial sequencing: using de novo and re-sequencing of multiple strains
for identification of phenotype specific mutations
• Agrigenomics: using de novo and re-sequencing of species of commercial
and research interest
• Pathogen detection in host systems: Detection and characterization of
foreign DNA in infected samples from plants or animals
For Whole Genome Sequencing, Source BioScience uses the latest library preparation
kits to prepare the samples ready for sequencing. The library preps we currently
use are:
• Illumina TruSeq Nano DNA Library Preparation
http://www.illumina.com/documents/products/datasheets/datasheet_truseq_
nano_dna_sample_prep_kit.pdf
• Illumina TruSeq DNA PCR-Free Library Preparation
http://www.illumina.com/documents/products/datasheets/datasheet_truseq_
dna_pcr_free_sample_prep.pdf
• Illumina Nextera DNA Library Preparation
http://www.illumina.com/documents/products/datasheets/datasheet_nexter
a_dna_sample_prep.pdf
• Illumina Nextera XT Library Preparation
http://www.illumina.com/documents/products/datasheets/datasheet_nexter
a_xt_dna_sample_prep.pdf
• Illumina Nextera Mate Pair Sample Preparation
http://www.illumina.com/documents/products/datasheets/datasheet_nexter
a_mate_pair.pdf
Whole genome sequencing techniques can also be applied to the sequencing of
smaller constructs such as plasmids, cosmids, fosmids and BAC’s.

www.lifescience.sourcebioscience.com
TRANSCRIPTOME SEQUENCING (RNA-SEQ)
The transcriptome is a collection of all transcripts present in a given cell. This
includes various kinds of RNA such as mRNA and rRNA. The Transcriptome
sequencing (also known as RNA-Seq) sequences cDNA to further obtain information
about a sample’s RNA content. This enables researchers to characterize RNA
transcribed from a particular genome to decipher information about gene
regulation and protein function. Stranded information identifies from which of the
two DNA strands a given RNA transcript was derived. This information is useful in
determining strand orientation to identify antisense expression. The ability to
capture sense and antisense expression provides insight into regulatory
interactions that might have been missed. This provides a further understanding of
specific cell types, how a cell functions and changes in gene activity can contribute
to disease.
At Source BioScience we understand the importance of Transcriptome Sequencing
and have an extensive library preparation protocols to assist with your research.
The library preps we currently use are:
• Illumina TruSeq RNA Library Preparation – This gives non-stranded
information after a poly-A purification of mRNA from a total RNA sample.
http://www.illumina.com/documents/products/datasheets/datasheet_truseq_
sample_prep_kits.pdf
• Illumina Stranded Total RNA Library Preparation – This gives stranded
information after a ribo-depletion of rRNA from a total RNA sample.
http://www.illumina.com/documents/products/datasheets/datasheet_truseq_
stranded_rna.pdf
• Illumina Stranded mRNA Library Preparation - This gives stranded
information after a poly-A purification of mRNA from a total RNA sample.
http://www.illumina.com/documents/products/datasheets/datasheet_truseq_
stranded_rna.pdf
• Clontech Smarter Ultra Low RNA Library Preparation – Useful for low RNA
input (10pg-10ng)
http://www.clontech.com/GB/Products/cDNA_Synthesis_and_Library_Constru
ction/cDNA_Synthesis_Kits/Ultra_Low_Input_RNA_cDNA_Synthesis?sitex=100
30:22372:US
• NuGen Ovation RNA-Seq FFPE Library Preparation - Used for Formalin
Fixed Paraffin Embedded samples.
http://www.nugeninc.com/nugen/index.cfm/products/cs/ngs/ovation-rna-
seq-ffpe-system/
• Epicentre Ribo-Zero Library Preparation - These kits remove ribosomal RNA
in samples before proceeding to sequencing library preparation. Depletion

www.lifescience.sourcebioscience.com
of ribosomal RNA as opposed to poly-A purification of mRNA allows for
sequencing analysis of non-polyadenylated RNA’s such as lincRNA’s.
http://www.epibio.com/products/rna-sequencing/rrna-removal/ribo-zero-
rrna-removal-kits-selection-guide
o We have kits for different species such as:
� Human/Mouse/Rat
� Gram Positive Bacteria
� Gram Negative Bacteria
� Metabacteria
� Plant
� Yeast
o Script-Seq Library Preparation
http://www.epibio.com/products/rna-sequencing/rna-library-
prep/scriptseq-v2-rna-seq-library-preparation-kit?details
SMALL RNA SEQUENCING
Small RNA sequencing is a powerful application to discover the profiling of micro
RNAs and other non-coding RNA on any organism without prior knowledge of the
genome. This would include sequencing micro RNA (miRNA), short interfering RNA
(siRNA) and piwi-interacting RNA (piRNA). Small RNA Sequencing allows researchers
to identify expression patterns, disease association and to characterize previously
unknown small RNAs.
At Source BioScience we use the latest products from Illumina to enable us to
sequence small RNAs with the most accurate detection and quantification of rare
small RNA sequences. The small RNA library prep available to our customers is:
• Illumina TruSeq Small RNA Sample Prep Kit
http://support.illumina.com/documents/documentation/Chemistry_Documentation/SamplePre
ps_TruSeq/TruSeqSmallRNA/TruSeq_SmallRNA_SamplePrep_Guide_15004197_E.pdf
CHROMATIN-IMMUNOPRECIPITATION SEQUENCING (ChIP-SEQ)
Chromatin-Immunoprecipitation sequencing has enabled researchers to identify
protein-DNA interactions and its regulation expressions to understand many
biological processes and disease states. ChIP-Seq is an extremely versatile
application and has successfully been applied against a wide range of protein

www.lifescience.sourcebioscience.com
targets, including transcription factors and histones. ChIP produces libraries of
target DNA sites bound to the protein of interest in vivo. The ChIP process enriches
specific crosslinked DNA-protein complexes using an antibody against the protein
of interest. Oligonucleotide adapters are then added to the small stretches of DNA
that were bound to the protein of interest. After size selection, the ChIP DNA
fragments are sequenced on the Illumina HiSeq 2000 or MiSeq.
At Source BioScience we offer the latest ChIP library prep for your research needs to
enable high-quality, cost-efficiency and high-throughput data. The ChIP library prep
available to our customers is:
• Illumina TruSeq ChIP Sample Preparation
http://www.illumina.com/documents/products/datasheets/datasheet_truseq_chip_sample_pre
p_kit.pdf
METAGENOMICS SEQUENCING
Metagenomics is the study of metagenomes (all the genetic material present in an
environmental sample, consisting of the genomes of many organisms). This enables
researchers to discover new hidden and diverse microscopic life to enable further
understanding of the living world. Sequence variation in the 16S ribosomal RNA
(rRNA) gene is widely used to characterize taxonomic diversity present in microbial
communities. The 16S sequence is composed of nine hypervariable regions
interspersed with conserved regions. The sequence of the 16S rRNA gene and its
hypervariable regions has been identified in a large number of organisms. For
taxonomic classification it is sufficient to sequence individual hypervariable regions
instead of the entire gene length. In most microbial species the fourth hypervariable
(V4) region is approximately 254bp and only deviates by a few base pairs. The 16S
V4 region is sequenced on the MiSeq to generate high quality, full length reads of
the entire V4 region. This enables microbial profiling at the Species level from the
V4 region of the 16S ribosomal RNA. Our current protocol allows for the
multiplexing of hundreds of samples in a run. Please feel free to contact us if you
need more information.
At Source BioScience, we offer this exciting service for your research needs.
Currently this service is offered on the MiSeq only as it produces high-quality data
and faster turnaround time. The MiSeq Reporter software also enables data analysis
of your samples to identify the variety of metagenomes in your sample. Customers
can be supplied with both classification data as well as sequencing reads derived
from each sample.

www.lifescience.sourcebioscience.com
We are also in a position to offer sequencing of other regions other than the V4
region mentioned above. Please feel free to contact us with your specific
requirements.
TARGETED RE-SEQUENCING
Targeted Re-sequencing enables researchers to focus on small subset of the
genome such as, an exome, particular chromosome, a set of genes or region of
interest. Focusing on a subset of the genome reduces costs but also allows
researchers to only sequence regions that they are interested in. This technique is a
popular approach to sequence many individuals to discover, screen or validate
genetic variation within a population. This enables researchers to identify rarer
variants that were missed or too expensive to indentify using other sequencing
methods. There are two different approaches to creating libraries for targeted
sequencing and Resequencing projects – target enrichment and amplicon
sequencing.
TARGET ENRICHMENT
Target enrichment captures selected regions or genes enriched in the library from
genomic DNA. Target enrichment allows larger DNA insert sizes and enables a
greater amount of total DNA to be sequenced per sample. This enables researchers
to further expand the information that they can gather from each sample. For
example, rather than sequencing a few hundred exons, the entire exome can be
sequenced to identify functional single nucleotide polymorphisms (SNPs) for an
individual. This application enables researchers to identify rare disease-associated
alleles within a population.
At Source BioScience, we offer a wide range of target enrichment products to aid
customer’s research needs. The target enrichment kits that we used are:
• Illumina Nextera Rapid Capture Exome and Expanded Exome Kits
http://www.illumina.com/documents/products/datasheets/datasheet_nextera_rapid_capture_
exome.pdf
• Illumina Nextera Rapid Capture Custom Enrichment Kit
http://www.illumina.com/documents/products/datasheets/datasheet_nextera_rapid_capture_
custom_enrichment.pdf
• Illumina TruSight Cancer
http://www.illumina.com/documents/products%5Cdatasheets%5Cdatasheet_trusight_cancer.p
df
• Illumina TruSight Cardiomyopathy
http://www.illumina.com/documents/products\datasheets\datasheet_trusight_cardio.pdf
• Illumina TruSight Inherited Disease

www.lifescience.sourcebioscience.com
http://www.illumina.com/documents/products\datasheets\datasheet_trusight_inherited_disea
se.pdf
• Illumina TruSight Autism
http://www.illumina.com/documents/products%5Cdatasheets%5Cdatasheet_trusight_autism.p
df
• Illumina TruSight Tumor
http://www.illumina.com/documents/products/datasheets/datasheet_trusight_tumor.pdf
• Illumina TruSight One Sequencing Panel
http://www.illumina.com/documents/products/datasheets/datasheet_trusight_one_panel.pdf
• Agilent SureSelect XT Human Exome Enrichment
http://www.chem.agilent.com/library/brochures/SureSelect-HaloPlex-NGS-Brochure-5990-
8747EN.pdf
• Agilent HaloPlex Human Exome Enrichment
http://www.chem.agilent.com/library/brochures/SureSelect-HaloPlex-NGS-Brochure-5990-
8747EN.pdf
• Agilent SureSelect XT Custom Target Enrichment
http://www.chem.agilent.com/library/brochures/SureSelect-HaloPlex-NGS-Brochure-5990-
8747EN.pdf
• Agilent HaloPlex Custom Human Target Enrichment
http://www.chem.agilent.com/library/brochures/SureSelect-HaloPlex-NGS-Brochure-5990-
8747EN.pdf
• Agilent SureSelect XT Mouse Exome Enrichment
http://www.chem.agilent.com/library/brochures/SureSelect-HaloPlex-NGS-Brochure-5990-
8747EN.pdf
• Agilent HaloPlex Cancer Panel
http://www.chem.agilent.com/library/flyers/Public/Haloplex%20Cancer_Flyer_Final.pdf
• Agilent HaloPlex Cardiomyopathy Panel
http://www.chem.agilent.com/library/datasheets/Public/HaloPlexDiseaseResearchPanels5991-
2526ENa.pdf
• Agilent HaloPlex Arrhythmia Panel
http://www.chem.agilent.com/library/datasheets/Public/HaloPlexDiseaseResearchPanels5991-
2526ENa.pdf
• Agilent HaloPlex Noonan Syndrome Panel
http://www.chem.agilent.com/library/datasheets/Public/HaloPlexDiseaseResearchPanels5991-
2526ENa.pdf
• Agilent HaloPlex ICCG Panel
http://www.chem.agilent.com/library/datasheets/Public/HaloPlexDiseaseResearchPanels5991-
2526ENa.pdf
• Agilent HaloPlex Connective Tissue Disorder Panel
http://www.chem.agilent.com/library/datasheets/Public/HaloPlexDiseaseResearchPanels5991-
2526ENa.pdf
• Agilent HaloPlex X Chromosome Panel
http://www.chem.agilent.com/library/datasheets/Public/HaloPlexDiseaseResearchPanels5991-
2526ENa.pdf

www.lifescience.sourcebioscience.com
AMPLICON SEQUENCING
Amplicon sequencing allows researchers to sequence small, selected regions of the
genome spanning hundreds of base pairs. This approach enables researchers to
create thousands of amplicons spanning multiple areas of interest in multiple
samples that can be simultaneously prepared, making it more cost-effective than
previous sequencing methods. Amplicon sequencing has a wide range of
applications for discovering, validating and screening genetic variants for various
studies. Using NGS, sequencing amplicons give a high depth of coverage to identify
common and rare sequence variations. This is useful for the discovery or rare
somatic mutations in complex samples, e.g. cancerous tumors mixed with germline
DNA. This makes amplicon sequencing suitable for clinical environments where
researchers are limited to disease-related variants.
Source BioScience offers a range of amplicon kits to prepare samples for sequencing. The
kits we use are:
• Illumina TruSeq Custom Amplicon
http://www.illumina.com/documents//products/datasheets/datasheet_truseq_custom_amplico
n.pdf
• Illumina TruSeq Cancer Panel
http://www.illumina.com/Documents/products/datasheets/datasheet_truseq_amplicon_cancer
_panel.pdf
Custom sequencing requires the design of custom capture probes or oligos and both
Illumina and Agilent provide online resources to design custom kits.
Illumina:
http://www.illumina.com/applications/designstudio.ilmn
Agilent:
https://earray.chem.agilent.com/suredesign/
SERVICE TYPE
We offer two types of services:
- Full Service
This includes sample library preparation and sequencing run.
- Run Only
This includes sequencing run only.

www.lifescience.sourcebioscience.com
NGS SEQUENCING WORKFLOW From Sample to Sequence…
This is a general NGS sequencing workflow to show you what happens to the samples when
they reach our lab.
SAMPLES ARRIVE INTO
LAB
SAMPLES ARE QUALITY
CHECKED TO SEE IF
THEY MEET THE SAMPLE
REQUIREMENTS
PASS
CUSTOMER INFORMED & SAMPLES
CONTINUE TO LIBRARY
PREPARTION
FAIL
CUSTOMER INFORMED & NEW
SAMPLES REQUESTED
LIBRARY PREPARATION
& LIBRARY REPORT QC SENT TO
CUSTOMER
CLUSTER GENERATION ON CBOT
(FOR HISEQ RUN ONLY)
SEQUENCING ON HISEQ 2000 OR
MISEQ
BIOINFORMATICS
DATA SENT BACK TO CUSTOMER VIA
FTP (SERVER LINK) OR HARD DRIVE
(HHD) WITH BIOINFORMATICS REPORT

www.lifescience.sourcebioscience.com
SAMPLE REQUIREMENTS
The input material we require exceeds the amounts required for sample
preparation. This is due to the additional amount that is necessary to perform
initial QC on the samples.
SAMPLE TYPES AND REQUIREMENTS
Library preparation required Input requirements Minimum concentration
Buffer
ChIP seq 20ng – 350bp 1ng/µl TE buffer
Genome sequencing 2µg genomic DNA 100ng/µl TE buffer
Targeted re-sequencing 6µg genomic DNA 100ng/µl TE buffer
mRNA - seq (total RNA) 2µg total RNA 100ng/µl DEPC water
mRNA – seq (mRNA) 200ng mRNA 6.25ng/µl DEPC water
DGE – small RNA (total RNA) 2µg total RNA 500ng/µl DEPC water
Mate pair 2µg genomic DNA 100ng/µl TE buffer
Nextera (Nextera XT) 200ng DNA 10ng/ µl DEPC Water
Run only 100nM 10nM Water
Please contact us if your sample requirements do not meet the minimum requirements
QUALITY CHECK (QC) METHODS
We will perform an initial QC of all sample material as follows:
Library preparation Method Quantification Method
ChIP seq Agilent 2100 High Sensitivity DNA chip
Genome sequencing Qubit Flourometer dsDNA broad range assay
Targeted re-sequencing Qubit Flourometer dsDNA broad range assay
mRNA - seq (total RNA) Agilent 2100 RNA Nano chip
mRNA – seq (mRNA) Agilent 2100 RNA Pico chip
DGE – small RNA (total RNA) Agilent 2100 RNA Nano chip
Mate pair Qubit Flourometer dsDNA broad range assay
Nextera (Nextera XT) Qubit Flourometer dsDNA high sensitivity assay
Run only Agilent 2100 High Sensitivity DNA chip
If the samples received do not meet our QC requirements, we will contact you to discuss
how to proceed.
DNA QUALITY
When submitting DNA we recommend measuring the concentration with
fluorescence based measurements (such as the Qubit). This is preferable to the
Nanodrop which tends to overestimate the concentration of the DNA. A Nanodrop

www.lifescience.sourcebioscience.com
however is useful for determining the 268:280 ratios of submitted samples. For
highest quality sequencing a range of 1.8:2 is desirable.
The quality of DNA can be assessed by running ~50ng of DNA on a 1% agarose gel.
Good quality DNA should appear as a strong band at a high molecular weight
(>10000bp). The presence of a lower molecular weight smear would indicate DNA
of insufficient quality or RNA contamination.
RNA QUALITY
The RIN (RNA Integrity Number) of all submitted RNA (except for FFPE samples)
should be above 8. This can be measured using the Agilent BioAnalyzer. If this is
not possible, running the samples on a denaturing agarose gel to confirm the
integrity of the rRNA peaks if preferable. All RNA samples will be run on the Agilent
BioAnalyzer and the RINs measured.
FIGURE 7: RNA INTEGRITY VALUES
FIGURE 9: RNA INTEGRITY ON A GEL.
(Image provided by Invitrogen
http://www.invitrogen.com/site/us/en/home/Refere
nces/Ambion-Tech-Support/rna-isolation/tech-
notes/is-your-rna-intact.html)

www.lifescience.sourcebioscience.com
After the samples are QC’ed, we will generate an Initial QC report stating whether
the samples meet the library preparation requirements. If the samples fail QC, we
will recommend that new samples are to be submitted. If samples pass QC, we will
prepare the samples according to the relevant protocol.
SAMPLE PREPARATION & LIBRARY VALIDATION
SAMPLE PREPARATION FOR SEQUENCING
Each separate application requires specific sample preparation for the sequencing.
The sample library will be prepared according to the protocol recommended for that
particular application. Further information on each of the library preparations for
various NGS applications can be found under the ‘Application’ section of this guide.
There are website links to each of the different library preparations to provide
further information. If you need further assistance with selecting the correct library
preparation for your project, please contact us.
LIBRARY VALIDATION
After completion of the library preparation, the libraries are validated prior to
cluster generation. This is to ensure that library preparation has worked. We use the
Agilent 2100 BioAnalyser to determine fragment size, yield and concentration
according to the protocol used for the library preparation. We aim to obtain over
10nM of each library before proceeding to sequencing.
LIBRARY PREPARATION REPORT
Customers will receive an extensive library preparation report stating which library
preparation was carried out on their samples. We include further information such
as External and internal sample identification, indexes used, library validation
Agilent BioAnalyser traces, Agilent BioAnalyser traces of Pool (if applicable) and
further recommendation if the library preparation has failed. We understand the
importance of information and we strive to always send this report to our customers
prior to any further sequencing work. If the library preparation has failed we will be
in contact to recommend alternatives or further information as to why the library
preparation did not work. If the library preparation has passed, we wait to make
sure you are happy with the results of the library preparation before continuing on
with sequencing. We aim to make sure that our work is of high quality and is
transparent, so that you receive the best quality from us.
www.lifescience.sourcebioscience.com
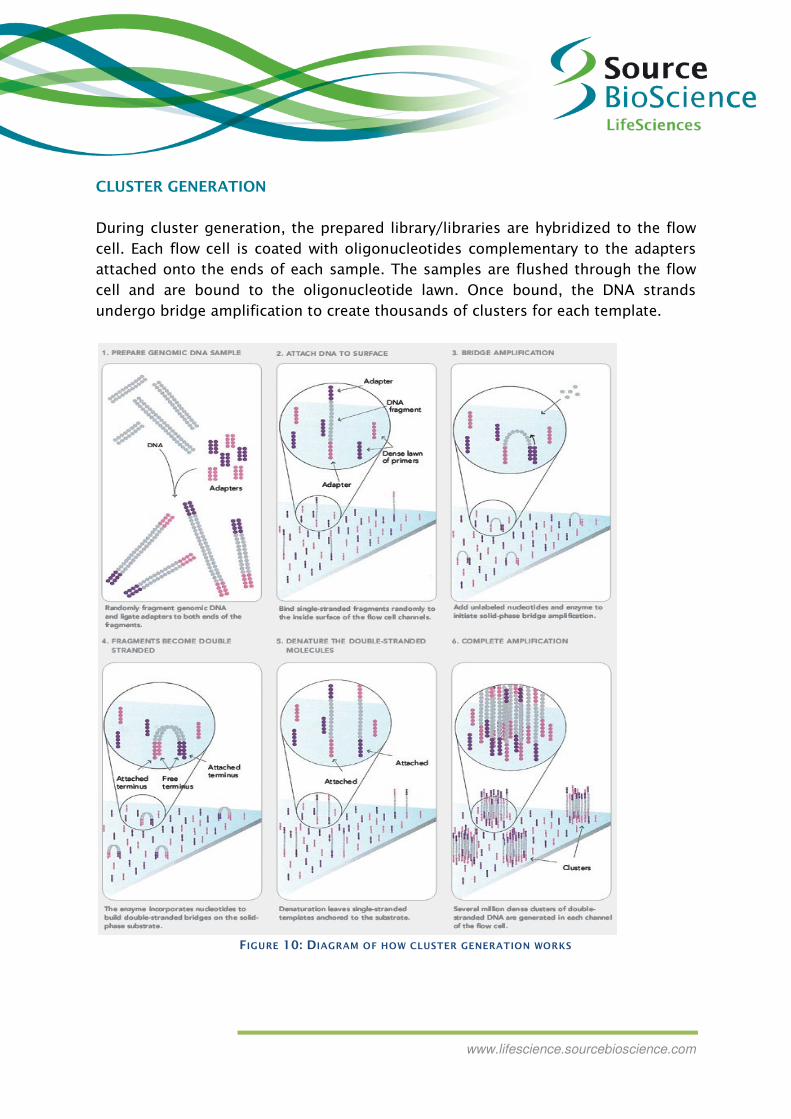
CLUSTER GENERATION
During cluster generation, the prepared library/libraries are hybridized to the flow
cell. Each flow cell is coated with oligonucleotides complementary to the adapters
attached onto the ends of each sample. The samples are flushed through the flow
cell and are bound to the oligonucleotide lawn. Once bound, the DNA strands
undergo bridge amplification to create thousands of clusters for each template.
FIGURE 10: DIAGRAM OF HOW CLUSTER GENERATION WORKS

www.lifescience.sourcebioscience.com
SEQUENCING
Illumina’s Sequencing by Synthesis (SBS) chemistry enables the incorporation of a
single fluorescent nucleotide, followed by high resolution imaging of the entire flow
cell. Each cluster appears as a dot on the image scanned by the camera. Any signal
above the background identifies the physical location of a cluster and the
fluorescent emission identifies which of the four bases (A, G, C, T) was incorporated
at that position. The fluorophore is removed and a new base is added, scanned and
imaged. This process is continued depending on the read length.


















