
New Compression Codes for Text Databases A Coruña. April 28th, 2005 Laboratorio de Bases de Datos...
85
New Compression Codes for Text Databases A Coruña. April 28th, 2005 Laboratorio de Bases de Datos Universidade da Coruña Ph.D. Dissertation Ph.D. Dissertation Antonio Fariña Martínez Nieves R. Brisaboa Gonzalo Navarro Advisors
-
Upload
rosa-bennett -
Category
Documents
-
view
217 -
download
4
Transcript of New Compression Codes for Text Databases A Coruña. April 28th, 2005 Laboratorio de Bases de Datos...

New Compression Codes for Text Databases
A Coruña. April 28th, 2005
Laboratorio de Bases de Datos
Universidade da Coruña
Ph.D. DissertationPh.D. DissertationAntonio Fariña Martínez
Nieves R. Brisaboa
Gonzalo Navarro
Advisors

April 2005 Phd dissertation – Antonio Fariña Martínez 2/85
— Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
— Dynamic CompressorsStatistical Dynamic compressors
Word-based Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
OutlineOutlineOutlineOutline
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction

April 2005 Phd dissertation – Antonio Fariña Martínez 3/85
IntroductionIntroduction
In the last years …— Increase of number of text collections and their size
The Web, text databases (jurisprudence, linguistics, corporate data)
Compression reduces:— Storage space— Disk access time— Transmission time
Applications — Efficient retrieval. Searches can be even faster than
in plain text— Transmission of data (and also real time transmission)— …

April 2005 Phd dissertation – Antonio Fariña Martínez 4/85
IntroductionIntroduction
Importance of compression in Text Data Bases
— Reduces their size: 30% compression ratio
— It is possible to search the compressed text directlySearches are up to 8 times faster.
— Decompression is only needed for presenting results
— Compression can be integrated into Text Retrieval Systems, improving their performance
— …

April 2005 Phd dissertation – Antonio Fariña Martínez 5/85
Two big families of compressors
— Dictionary-based (gzip, compress,… )
— Statistical compressors (Huffman-based, arithmetic, PPM,… )
Statistical compressors
— Computation of the frequencies of the source symbols
— More frequent symbols shorter codewords
— A varying length codeword is given to each symbol
Obtain compression
IntroductionIntroduction

April 2005 Phd dissertation – Antonio Fariña Martínez 6/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-based Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 7/85
ScenariosScenarios
2 scenarios
— Semi-static compression (2-pass)Text storage
Text Retrieval
— Dynamic compression (1-pass)Transmission of data
Transmission of streams

April 2005 Phd dissertation – Antonio Fariña Martínez 8/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 9/85
Semi-static compressionSemi-static compression
Statistical compression
2 passes— Gather frequencies of source symbols and encoding— Compression (substitution source symbol codeword)

April 2005 Phd dissertation – Antonio Fariña Martínez 10/85
Semi-static compressionSemi-static compression
vocabulary
En un lugar de
la Mancha de
cuyo nombre
no quiero
acordarmeno
…
1
1
1
1
1
1
2
1
1
1
1
1
2
de 2
no 2
En 1
un 1
lugar 1
acordarme1
la 1
Mancha 1
cuyo 1
nombre 1
quiero 1
C1
C2
C3
C4
C5
C11
C6
C7
C8
C9
C10
1st pass: Text processing > Vocabulary sorting > Code generation
Source text
codeword

April 2005 Phd dissertation – Antonio Fariña Martínez 11/85
Semi-static compressionSemi-static compression
vocabulary
En un lugar de
la mancha de
cuyo nombre
no quiero
acordarmeno
…
C3 C4 C5 C1
C6
C11
C7 C8
C9 C2 C10
C1
C2 …
C1
C2
C3
C4
C5
C11
C6
C7
C8
C9
C10
de 2
no 2
En 1
un 1
lugar 1
acordarme1
la 1
Mancha 1
cuyo 1
nombre 1
quiero 1
codeword
2nd pass: Substitution word codeword
Source text
Compr.data
de*no*En*… header
Output file

April 2005 Phd dissertation – Antonio Fariña Martínez 12/85
Semi-static compressionSemi-static compression
Statistical compression
2 passes— Gather frequencies of words and encoding— Compression (substitution word codeword)
Association between source symbol codeword does not change across the text
— Direct search is possible
Most representative method: Huffman.
April 2005 Phd dissertation – Antonio Fariña Martínez 13/85
Classic HuffmanClassic Huffman
Optimal prefix code (i.e., shortest total length)
Character based (originally)— Characters are the symbols to be encoded
Bit oriented: Codewords are sequences of bits
A Huffman tree is built to generate codewords
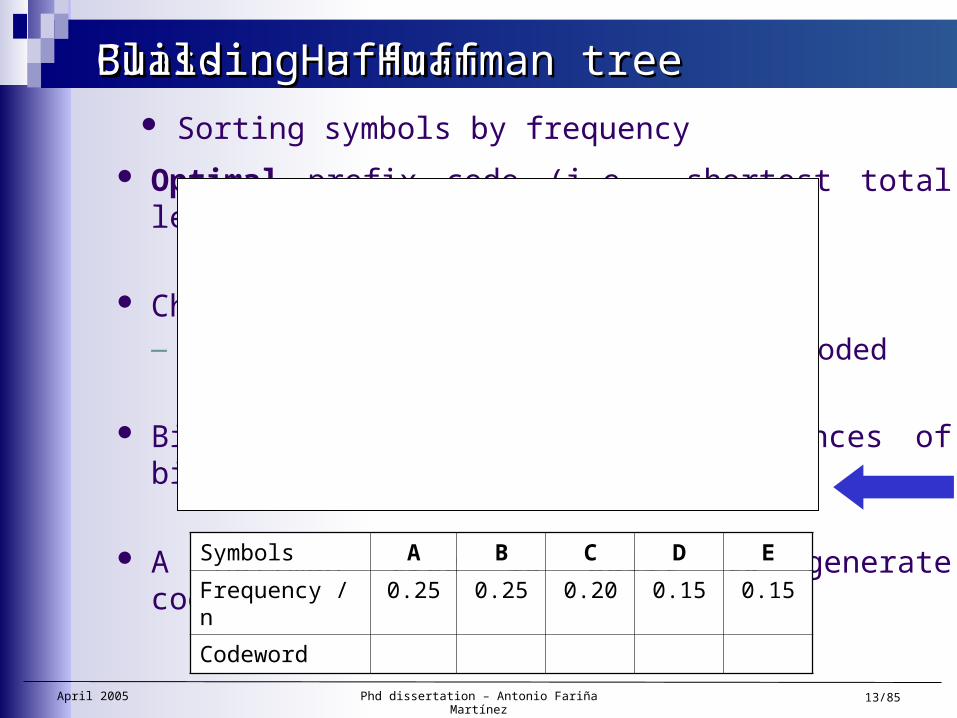
Building a Huffman treeBuilding a Huffman tree Sorting symbols by frequency
Symbols A B C D E
Frequency / n 0.25 0.25 0.20 0.15 0.15
Codeword
April 2005 Phd dissertation – Antonio Fariña Martínez 14/85
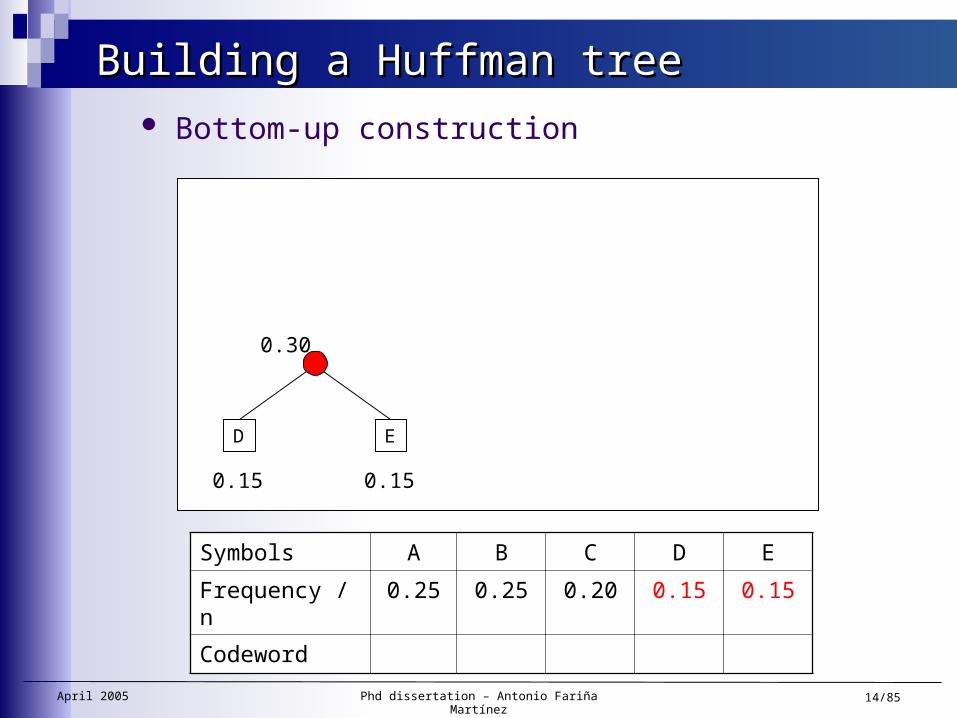
Building a Huffman treeBuilding a Huffman tree Bottom-up construction
Symbols A B C D E
Frequency / n 0.25 0.25 0.20 0.15 0.15
Codeword
ED
0.30
0.15 0.15
April 2005 Phd dissertation – Antonio Fariña Martínez 15/85
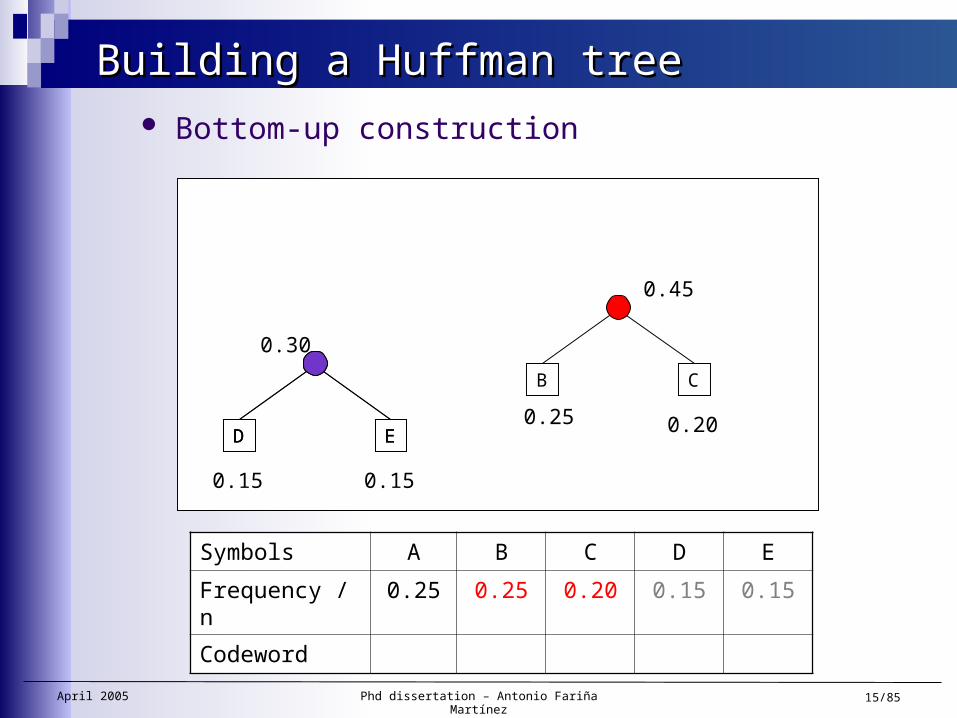
Building a Huffman treeBuilding a Huffman tree Bottom-up construction
Symbols A B C D E
Frequency / n 0.25 0.25 0.20 0.15 0.15
Codeword
ED
0.30
0.15 0.15
ED
CB
0.25 0.20
0.45
April 2005 Phd dissertation – Antonio Fariña Martínez 16/85
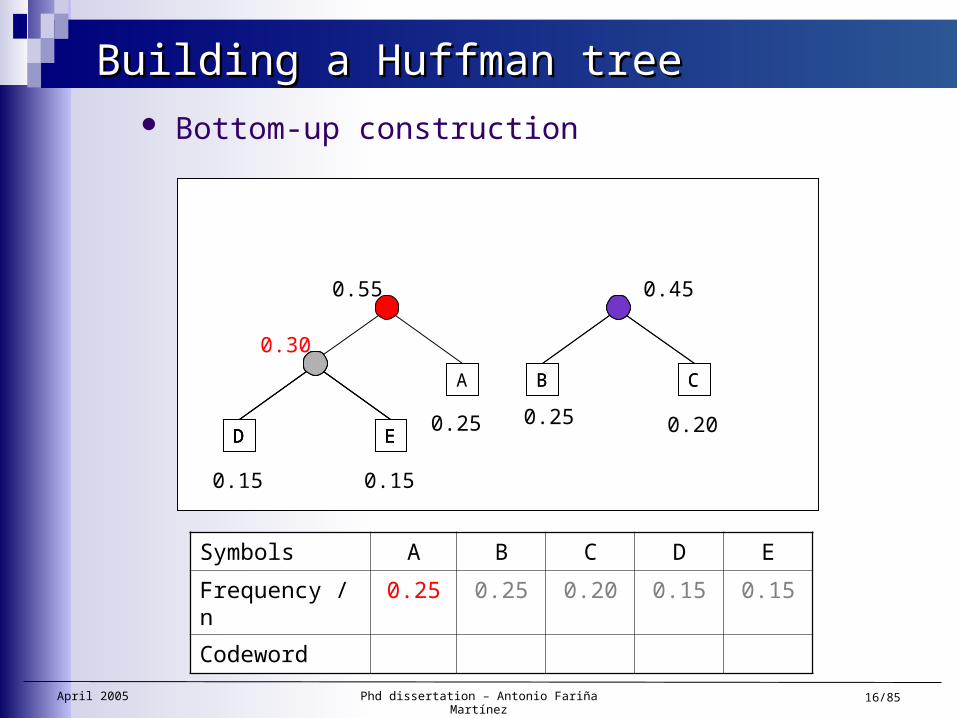
Building a Huffman treeBuilding a Huffman tree Bottom-up construction
Symbols A B C D E
Frequency / n 0.25 0.25 0.20 0.15 0.15
Codeword
ED
0.30
0.15 0.15
ED
CB
0.25 0.20
0.45
A
ED
CB
0.25
0.55
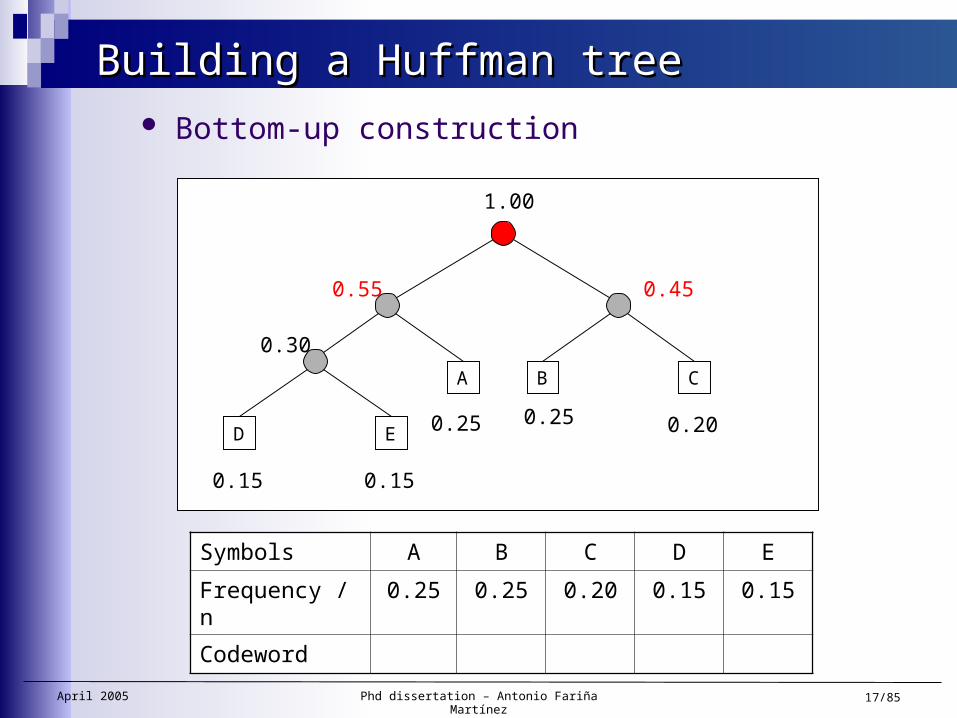
April 2005 Phd dissertation – Antonio Fariña Martínez 17/85
Building a Huffman treeBuilding a Huffman tree Bottom-up construction
Symbols A B C D E
Frequency / n 0.25 0.25 0.20 0.15 0.15
Codeword
0.30
0.15 0.15
0.25 0.20
0.45
0.25
0.55
A
ED
CB
1.00
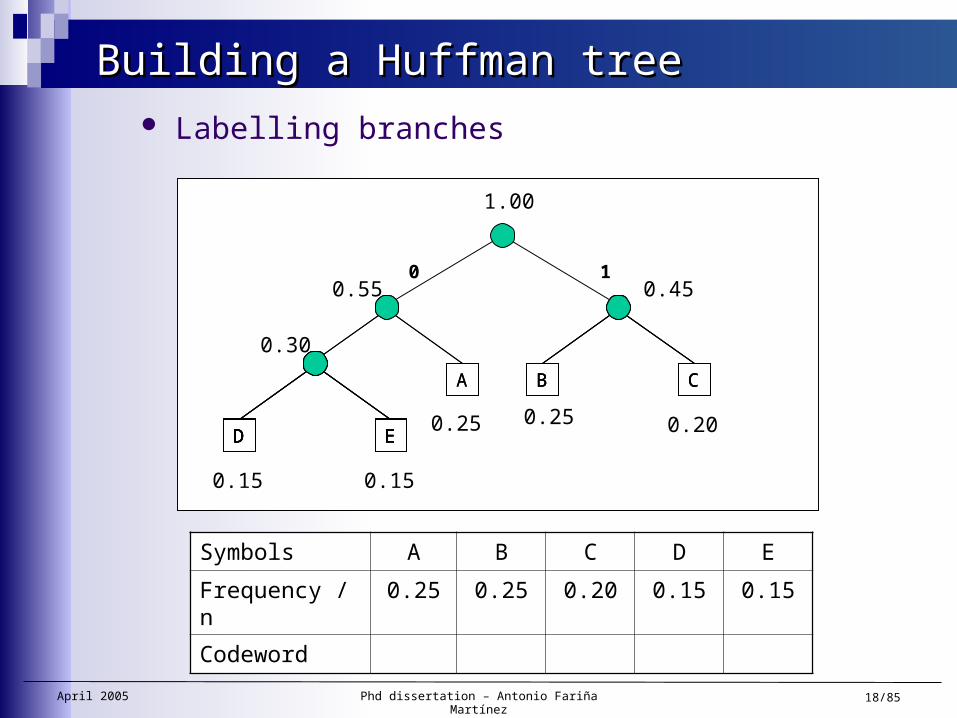
April 2005 Phd dissertation – Antonio Fariña Martínez 18/85
Building a Huffman treeBuilding a Huffman tree Labelling branches
Symbols A B C D E
Frequency / n 0.25 0.25 0.20 0.15 0.15
Codeword
ED
0.30
0.15 0.15
ED
CB
0.25 0.20
0.45
A
ED
CB
0.25
0.55
1.00
0 1
A
ED
CB
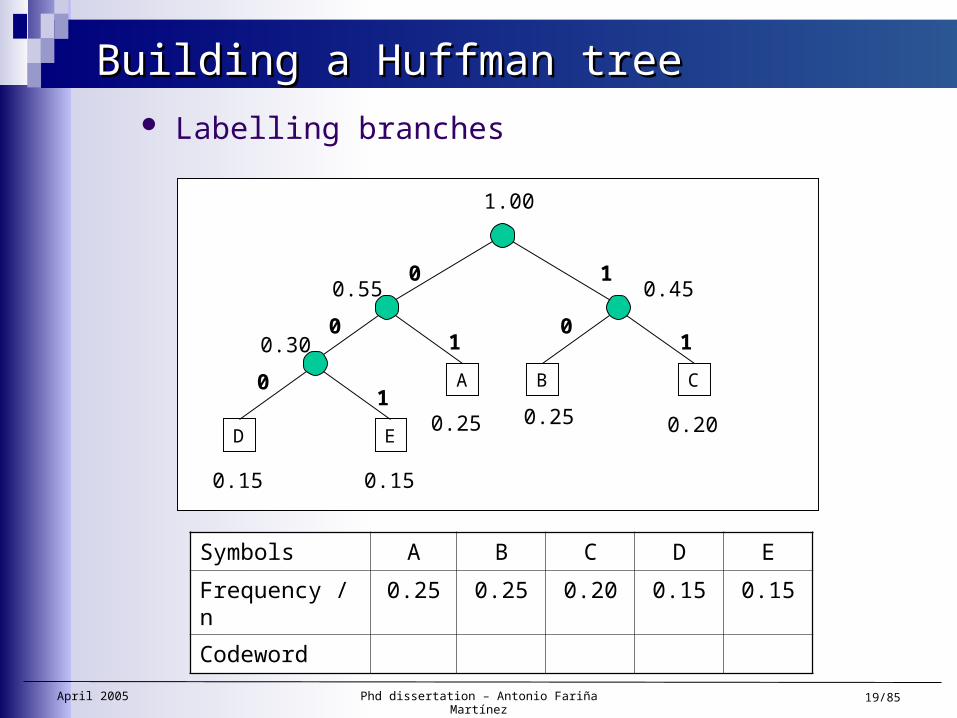
April 2005 Phd dissertation – Antonio Fariña Martínez 19/85
Building a Huffman treeBuilding a Huffman tree Labelling branches
Symbols A B C D E
Frequency / n 0.25 0.25 0.20 0.15 0.15
Codeword
0 1
1
A
0
1
E
0
D
1
C
0
B
0.30
0.15 0.15
0.25 0.20
0.45
0.25
0.55
1.00
April 2005 Phd dissertation – Antonio Fariña Martínez 20/85
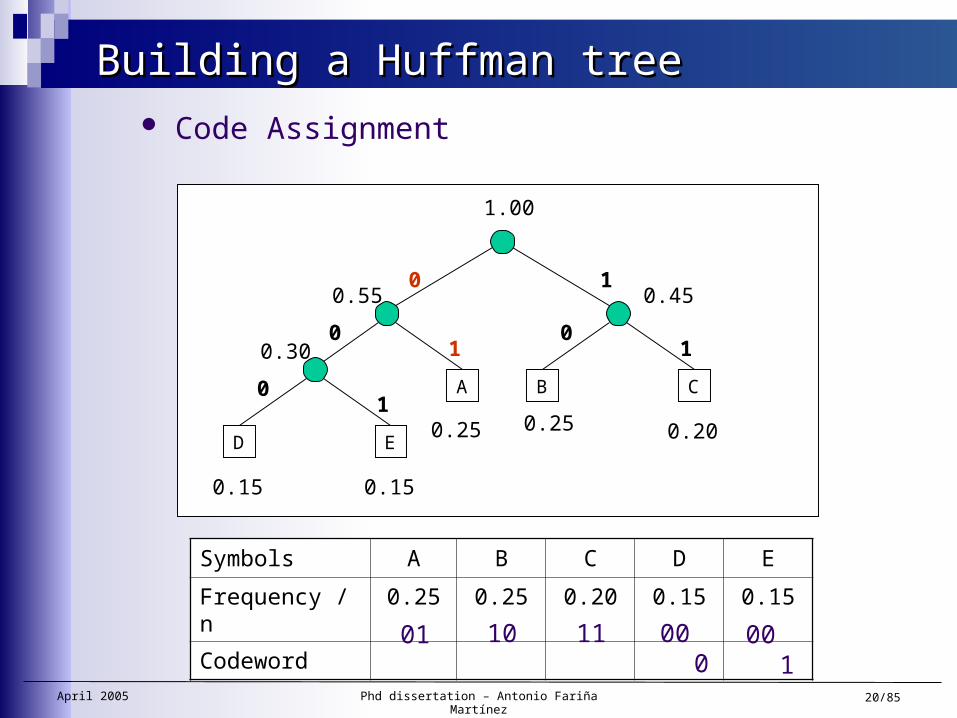
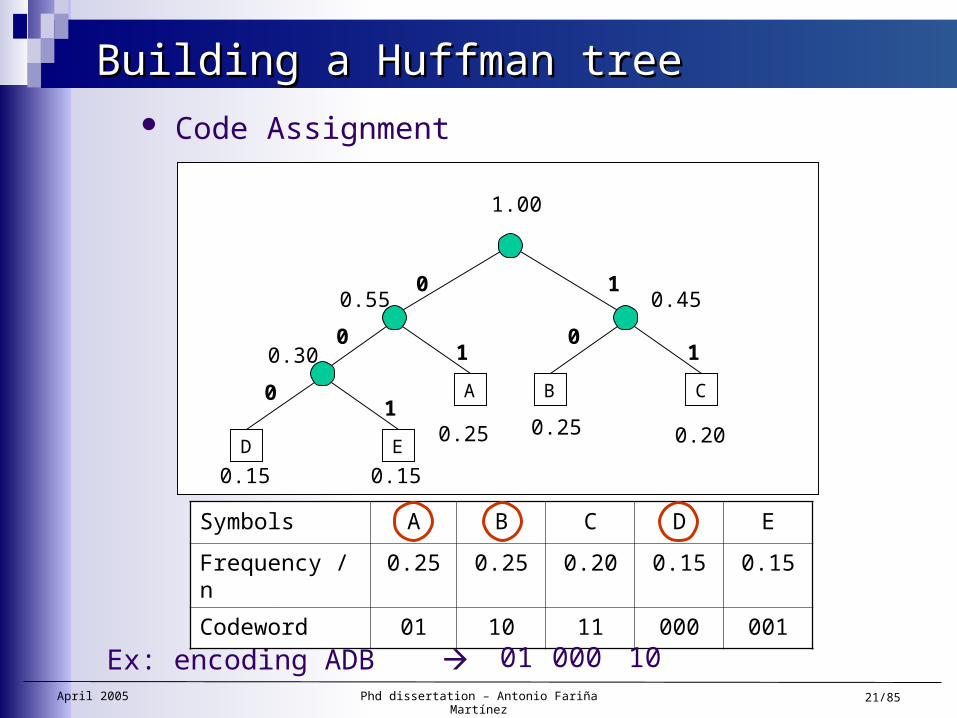
Building a Huffman treeBuilding a Huffman tree Code Assignment
Symbols A B C D E
Frequency / n 0.25 0.25 0.20 0.15 0.15
Codeword
0 1
10
1
E
0
D
1
C
0
B
0.30
0.15 0.15
0.25 0.20
0.45
0.25
0.55
1.00
0010001110
A
01
April 2005 Phd dissertation – Antonio Fariña Martínez 21/85
Building a Huffman treeBuilding a Huffman tree
Ex: encoding ADB
Symbols A B C D E
Frequency / n 0.25 0.25 0.20 0.15 0.15
Codeword 01 10 11 000 001
0 1
1
A
0
1
E
0
D
1
C
0
B
0.30
0.25 0.25 0.20
0.55 0.45
0.15 0.15
1.00
Code Assignment
01 000 10

April 2005 Phd dissertation – Antonio Fariña Martínez 22/85
Classic HuffmanClassic Huffman
Optimal prefix code (i.e., shortest total length)
Character based (originally)— Characters are the symbols to be encoded
Bit oriented: Codewords are sequences of bits
A Huffman tree is built to generated codewords
Huffman tree has to be stored with the compressed text
Compression ratio about 60% (unpopular).

April 2005 Phd dissertation – Antonio Fariña Martínez 23/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word Oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 24/85
Word-based HuffmanWord-based Huffman
Moffat proposed the use of words instead of characters as the coding alphabet
Distribution of words more biased than the distribution of characters
0
2
4
6
8
10
12
14
16
18
E A O L S N D R U I T C P M Y Q B H G F V J Ñ Z X K W
n
Word freq distribution
Character freq distribution (Spanish)
Compression ratio about 25% (English texts) This idea joins the requirements of compression
algorithms and of Information Retrieval systems

April 2005 Phd dissertation – Antonio Fariña Martínez 25/85
Plain Huffman & Tagged HuffmanPlain Huffman & Tagged Huffman
Moura, Navarro, Ziviani and Baeza: — 2 new techniques: Plain Huffman and Tagged Huffman
Common features— Huffman-based
— Word-based
— Byte- rather than bit-oriented (compression ratio ±30%)
Plain Huffman = Huffman over bytes (256-ary tree) Tagged Huffman flags the beginning of each codeword
First bit is:•“1” for 1st bit of 1st byte•“0” for 1st bit remaining bytes
1xxxxxxx 0xxxxxxx 0xxxxxxx

April 2005 Phd dissertation – Antonio Fariña Martínez 26/85
Direct search (searches improved)Boyer-Moore
Random access (random decompression)
Plain Huffman & Tagged HuffmanPlain Huffman & Tagged Huffman
Differences:
— Plain Huffman. (tree of arity 2b=256)
— Tagged Huffman. (tree of arity 2b-1 =128)
Loss of compression ratio (3.5 perc. points)
Tag marks beginning of codewords
April 2005 Phd dissertation – Antonio Fariña Martínez 27/85
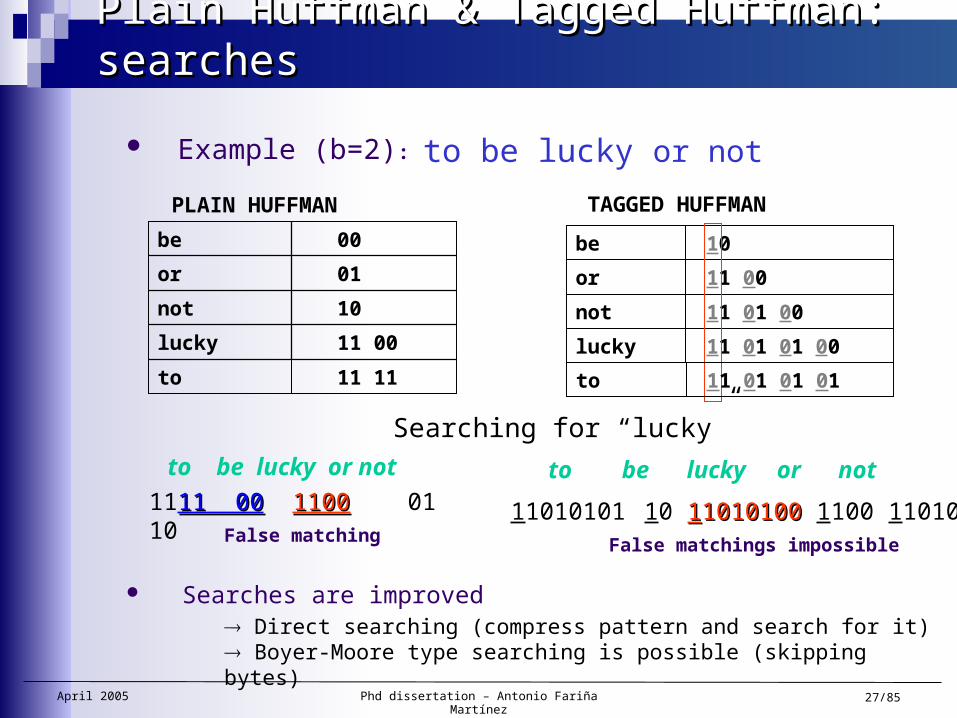
Plain Huffman & Tagged Huffman: searchesPlain Huffman & Tagged Huffman: searches
Example (b=2): to be lucky or not
Direct searching (compress pattern and search for it) Boyer-Moore type searching is possible (skipping bytes)
Searches are improved
to be lucky or not
1111 0011 00 11001100 01 10False matching
Searching for “lucky”
11 00lucky
10not
01or
00be
PLAIN HUFFMAN
11 11to
to be lucky or not
11010101 10 1110101001010100 1100 110100False matchings impossible
11 01 01 00lucky
11 01 00not
11 00or
10be
TAGGED HUFFMAN
11 01 01 01to

April 2005 Phd dissertation – Antonio Fariña Martínez 28/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline
April 2005 Phd dissertation – Antonio Fariña Martínez 29/85
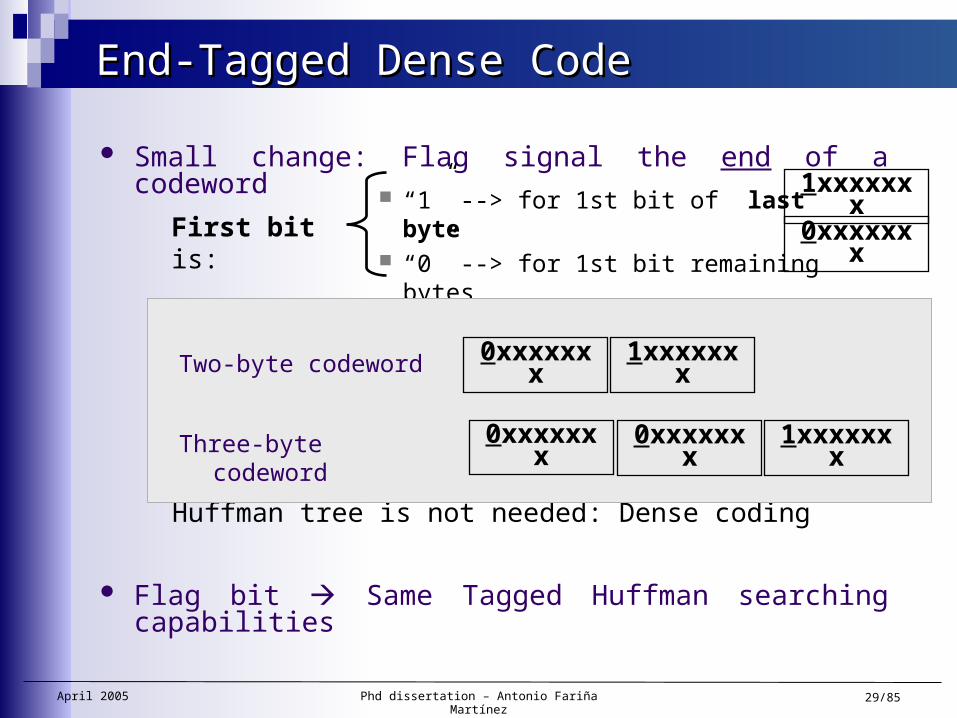
End-Tagged Dense CodeEnd-Tagged Dense Code
Small change: Flag signal the end of a codeword
Prefix code independently of the remaining 7 bits of each byte
Huffman tree is not needed: Dense coding
Flag bit Same Tagged Huffman searching capabilities
First bit is: “1” --> for 1st bit of last byte “0” --> for 1st bit remaining bytes
1xxxxxxx
0xxxxxxx
Two-byte codeword 1xxxxxxx0xxxxxxx
Three-byte codeword 1xxxxxxx0xxxxxxx0xxxxxxx

April 2005 Phd dissertation – Antonio Fariña Martínez 30/85
End-Tagged Dense CodeEnd-Tagged Dense Code Encoding scheme
.....
Words from 128+ 1282+1 to
128 +1282 +1283 use three bytes
(1283 = 221 codewords)
00000000:00000000:10000000
……
01111111:01111111:11111111
Words from 128+1 to 128+1282 are encoded using two bytes
(1282 = 214 codewords)
00000000:10000000
…..
01111111:11111111
First 128 words are encoded using one byte (27 codewords)
1000000010000001…..11111111
Codewords depend on the rank, not on the frequency

April 2005 Phd dissertation – Antonio Fariña Martínez 31/85
Sequential encoding procedure
End-Tagged Dense CodeEnd-Tagged Dense Code
On-the-fly encoding procedure
— Sorting words by frequency
— Code assignment ...0xxxxxxx
< 2b-1
0xxxxxxx < 2b-1
1xxxxxxx ≥ 2b-1
Ci encode(i)
i decode(Ci)
3210
131130129128
132
Ci = encode( i )
0 128
i = decode ( Ci )i=
Ci

April 2005 Phd dissertation – Antonio Fariña Martínez 32/85
End-Tagged Dense CodeEnd-Tagged Dense Code
Decompression: two steps— Load the ranked vocabulary
— i decode(Ci)
C2 C3 C4 C0
C5
C10
C6 C7
C8 C1 C9
C0
C1 …
Compr.data
de*no*En*… header
Compressed file
vocabulary
de
no
En
un
lugar
la
0
1
2
3
4
5
Plain text file
En un lugar de
la mancha de
cuyo nombre
no quiero
acordarmeno
……

April 2005 Phd dissertation – Antonio Fariña Martínez 33/85
End-Tagged Dense CodeEnd-Tagged Dense Code
It is a dense code. All the available codes can be used.— Compresses better than TH (2 percentage points).— It is overcome by PH (1 percentage point).
Flag same search capabilities than Tagged Huff.
— direct search,
— random access.
Efficient encoding and decoding
— Sequential and on-the-fly procedures
Easy to program

April 2005 Phd dissertation – Antonio Fariña Martínez 34/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 35/85
128 230
n=5,000
128 128 + 128x128 = 16,512
230 + 230x26 = 6,210230
128
n=5,000
128 128 + 128x128 = 16,512
(s,c)-Dense Code(s,c)-Dense Code• End Tagged Dense Code
– 27 available values [128, 255] for last byte (stoppers)– 27 available values [0, 127] for other bytes (continuers)
Adapting s,c values to the vocabulary s minimizing compr. text size— number of words
— distribution of frequency of the words End-Tagged Dense Code is a (128,128)-Dense Code
Why using fixed s,c values ?

April 2005 Phd dissertation – Antonio Fariña Martínez 36/85
(s,c)-Dense Code(s,c)-Dense Code
— Stoppers: last byte. Values in [0,s-1]— Continuers: other bytes. Values in [s,s+c-1]
0
...
s-1s more frequent words
s
s
...
s+c-1
0
1
...
s-1
Words from s+1 to s + sc(total sc words)
s...
s...
Words from s + sc + 1 to s + sc + sc2
(total sc2 words)0...
Encoding scheme
April 2005 Phd dissertation – Antonio Fariña Martínez 37/85
(s,c)-Dense Code(s,c)-Dense Code
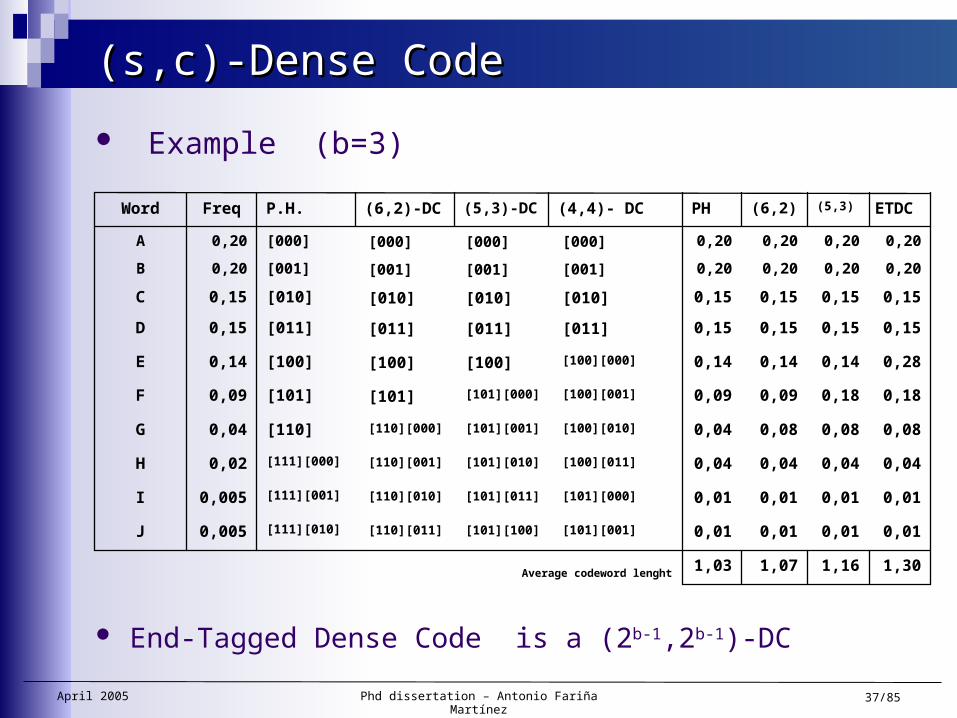
Example (b=3)
1,301,161,071,03 Average codeword lenght
0,010,010,010,01[111][010]0,005J
0,010,010,010,01[111][001]0,005I
0,040,040,040,04[111][000]0,02H
0,080,080,080,04[110]0,04G
0,180,180,090,09[101]0,09F
0,280,140,140,14[100]0,14E
0,150,150,150,15[011]0,15D
0,150,150,150,15[010]0,15C
0,200,200,200,20[001]0,20B
0,200,200,200,20[000]0,20A
ETDC(5,3)(6,2)PH(4,4)- DC(5,3)-DC(6,2)-DCP.H.FreqWord
End-Tagged Dense Code is a (2b-1,2b-1)-DC
[110][011]
[110][010]
[110][001]
[110][000]
[101]
[100]
[011]
[010]
[001]
[000]
[101][100]
[101][011]
[101][010]
[101][001]
[101][000]
[100]
[011]
[010]
[001]
[000]
[101][001]
[101][000]
[100][011]
[100][010]
[100][001]
[100][000]
[011]
[010]
[001]
[000]

April 2005 Phd dissertation – Antonio Fariña Martínez 38/85
Sequential encoding
(s,c)-Dense Code(s,c)-Dense Code
On-the-fly encoding is also possible
Ci encode(s, i)
i decode(s, Ci)
3210
S+3S+2S+1
s
S+4
Ci = encode( s,i )
s 0
i = decode ( s, Ci )i=
Ci
...xxxxxxxx xxxxxxxx zzzzzzzz
s≤ vc < 2b-1 0≤ vs< ss≤ vc< 2b-1

April 2005 Phd dissertation – Antonio Fariña Martínez 39/85
(s,c)-Dense Code(s,c)-Dense Code
It is a dense code— Compresses better than TH (3 percentage points)— Compresses better than ETDC (0.75 percentage points)— It is overcome by PH (0.25 percentage point)— RATIO: PH < SCDC << ETDC <<< TH
Flag? (byte value < s) — Same search capatilities than End-Tagged Dense Code
and Tagged Huffman
Simple encoding and decoding

April 2005 Phd dissertation – Antonio Fariña Martínez 40/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline
April 2005 Phd dissertation – Antonio Fariña Martínez 41/85
Empirical ResultsEmpirical Results
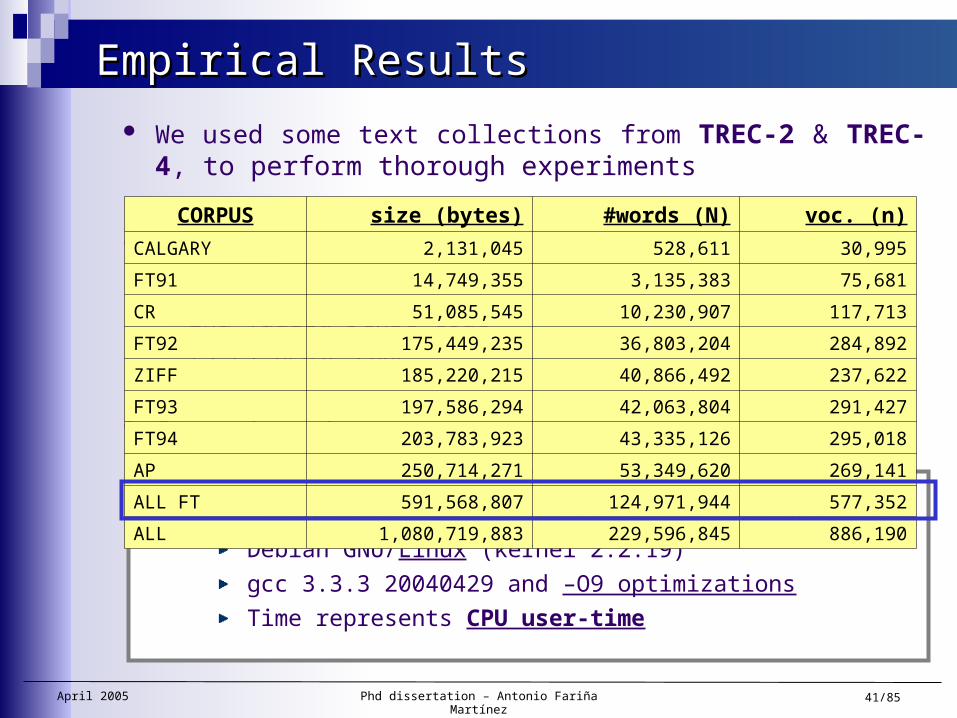
We used some text collections from TREC-2 & TREC- 4, to perform thorough experiments
Methods compared— Plain Huffman & Tagged Huffman
— End-Tagged Dense Code
— (s,c)-Dense Code
Comparison in:— Compression ratio
— Encoding speed
— Compression speed
— Decompression speed
— Search speed
— Dual Intel Pentium-III 800 Mhz with 768Mb RAM. Debian GNU/Linux (kernel 2.2.19)
gcc 3.3.3 20040429 and –O9 optimizations
Time represents CPU user-time
CORPUS size (bytes) #words (N) voc. (n)
CALGARY 2,131,045 528,611 30,995
FT91 14,749,355 3,135,383 75,681
CR 51,085,545 10,230,907 117,713
FT92 175,449,235 36,803,204 284,892
ZIFF 185,220,215 40,866,492 237,622
FT93 197,586,294 42,063,804 291,427
FT94 203,783,923 43,335,126 295,018
AP 250,714,271 53,349,620 269,141
ALL FT 591,568,807 124,971,944 577,352
ALL 1,080,719,883 229,596,845 886,190
April 2005 Phd dissertation – Antonio Fariña Martínez 42/85
PH (s,c)-DC ETDC TH
28
29
30
31
32
33
34
35
com
pres
sion
ratio
(%)
technique
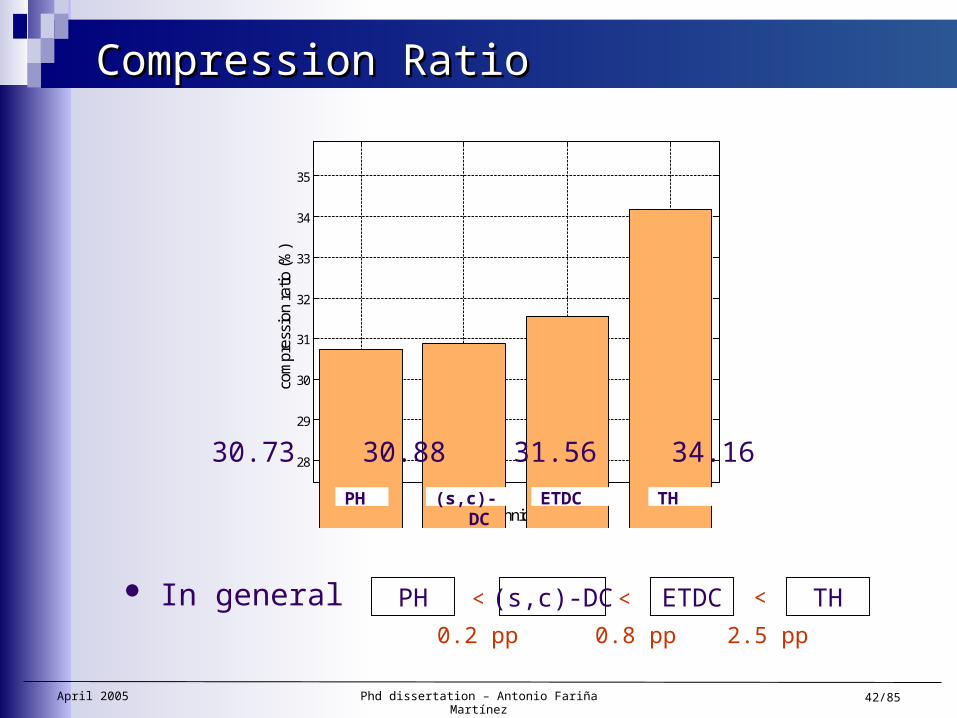
Compression RatioCompression Ratio
In general PH (s,c)-DC ETDC TH
0.2 pp 0.8 pp 2.5 pp
< < <
PH (s,c)-DC ETDC TH
30.73 30.88 31.56 34.16
April 2005 Phd dissertation – Antonio Fariña Martínez 43/85
Compression time & encoding timeCompression time & encoding time
Encoding
Vocabulary extraction
File processing
n1
Sorted Words vector
word
freq
Huffman
ET
DC
Sequential codegeneration
Creating Huffman tree Search for optimal (s,c) values
Accumulated listof frequencies
Find Best S
Sequential codegeneration
Hash table
Compression phase
To
T1
Bui
ld tr
ee
Set depths
Cod
e ge
ner
atio
n
(s-c) DC
wordcode
com
pre
ssio
n
1st p
ass
2n
d p
ass
April 2005 Phd dissertation – Antonio Fariña Martínez 44/85
PH (s,c)-DC ETDC TH
100
120
140
160
180
200
220
240
260
280
Enc
odin
g tim
e (m
sec.
)
technique
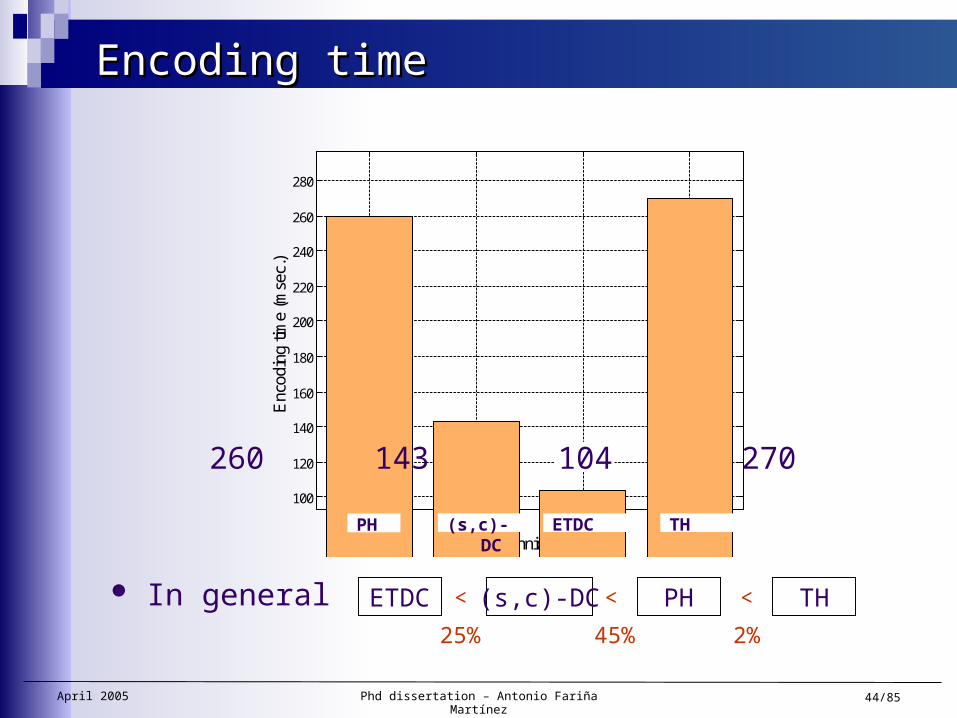
Encoding timeEncoding time
ETDC (s,c)-DC PH TH
25% 45% 2%
In general
260 143 104 270
< < <
PH (s,c)-DC ETDC TH
April 2005 Phd dissertation – Antonio Fariña Martínez 45/85
PH (s,c)-DC ETDC TH
5.3
5.4
5.5
5.6
5.7
5.8
5.9
6
6.1
6.2
Com
pres
sion
spe
ed (M
byte
s/se
c)
technique
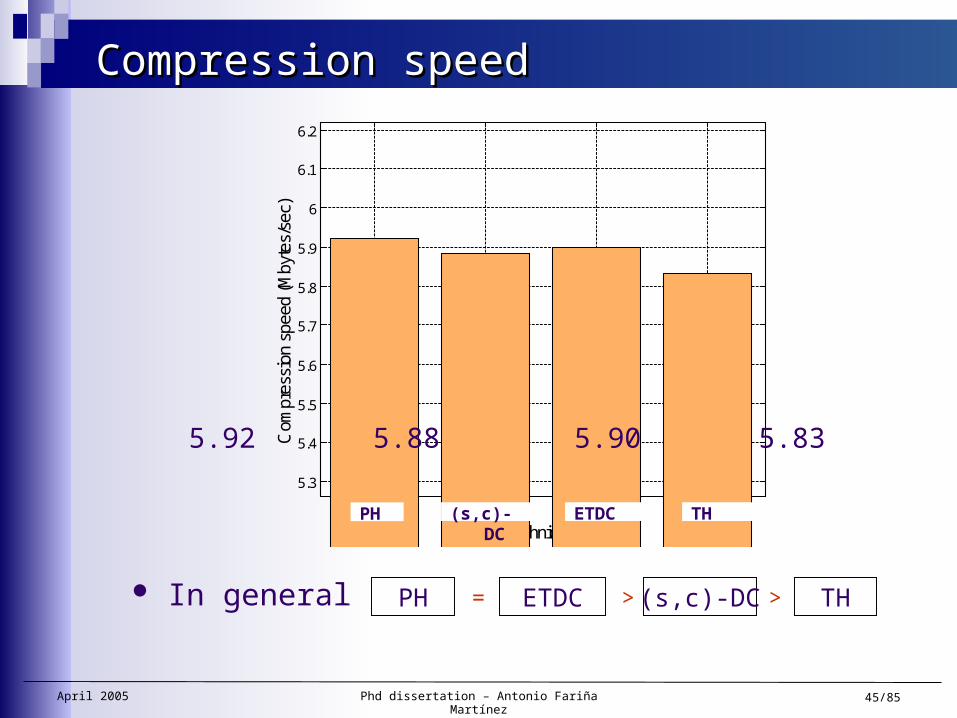
Compression speedCompression speed
PH ETDC (s,c)-DC TH= > > In general
5.92 5.88 5.90 5.83
PH (s,c)-DC ETDC TH
April 2005 Phd dissertation – Antonio Fariña Martínez 46/85
PH (s,c)-DC ETDC TH
20.5
21
21.5
22
22.5
23
23.5
24
24.5
25
Deo
mpr
essi
on s
peed
(Mby
tes/
sec)
technique
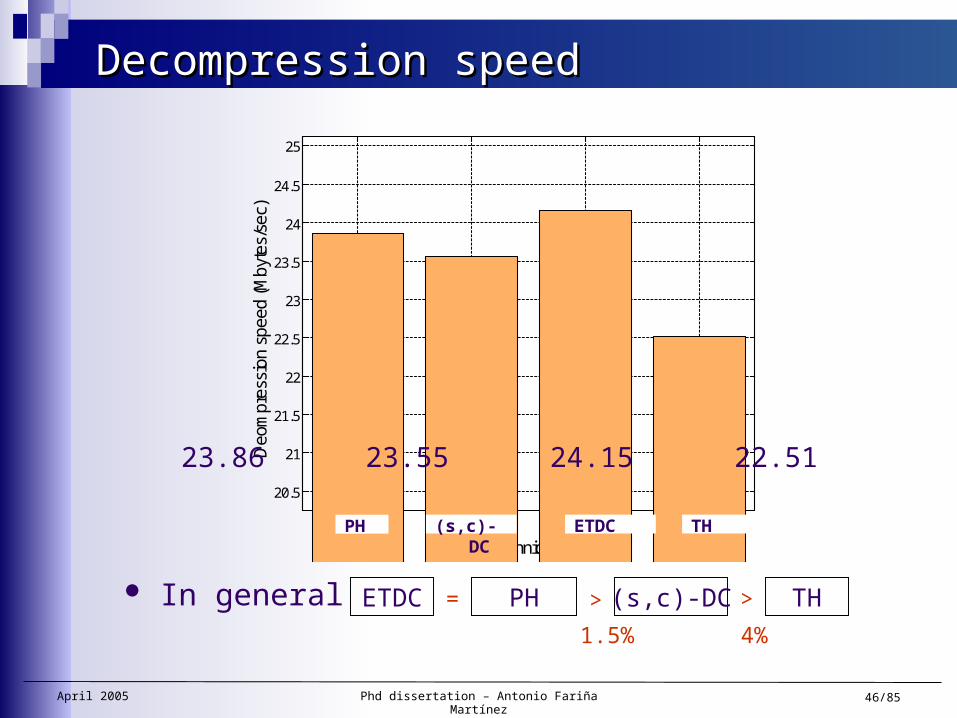
Decompression speedDecompression speed
23.86 23.55 24.15 22.51
ETDC PH (s,c)-DC TH=
1.5% 4%
In general > >
PH (s,c)-DC ETDC TH
April 2005 Phd dissertation – Antonio Fariña Martínez 47/85
PH (s,c)-DC ETDC TH
1.6
1.7
1.8
1.9
2
2.1
2.2
2.3
2.4
2.5
Searc
h ti
me (se
c.)
technique
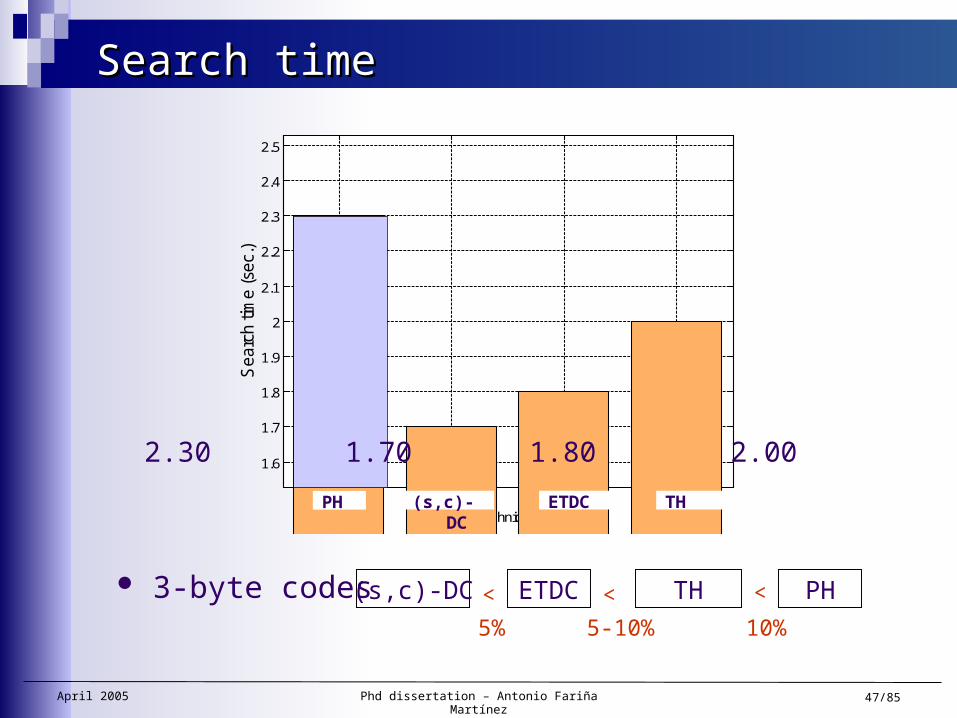
(s,c)-DC
Search timeSearch time
ETDC TH PH
5% 5-10% 10%
3-byte codes < < <
2.30 1.70 1.80 2.00
PH (s,c)-DC ETDC TH

April 2005 Phd dissertation – Antonio Fariña Martínez 48/85
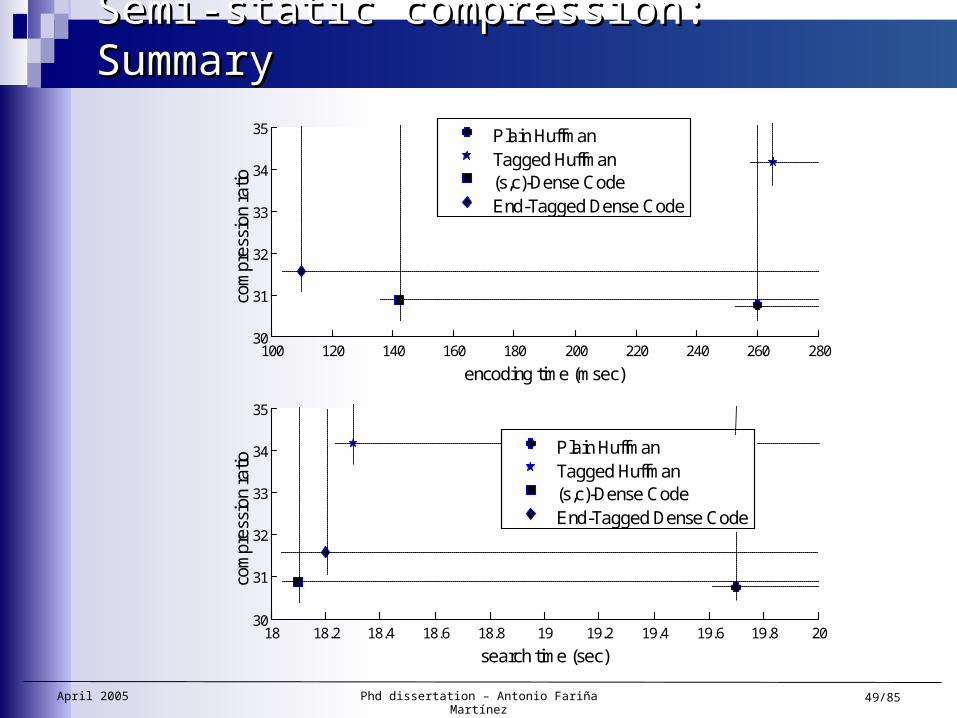
Semi-static compression: SummarySemi-static compression: Summary
Two new semi-static “dense” compressors: ETDC, SCDC Simpler and faster encoding scheme than Huffman-based
ones— Sequential encoding
— on-the-fly encoding
Allowing direct search and random access
Speed: Good compression and decompression speed
Compression ratio close to Plain Huffman
Overcoming Tagged Huffman in:— Compression ratio, compression speed, decompression
speed and searches.
April 2005 Phd dissertation – Antonio Fariña Martínez 49/85
Semi-static compression: SummarySemi-static compression: Summary
100 120 140 160 180 200 220 240 260 28030
31
32
33
34
35
encoding time (msec)
com
pres
sion
ratio
18 18.2 18.4 18.6 18.8 19 19.2 19.4 19.6 19.8 2030
31
32
33
34
35
search time (sec)
com
pres
sion
ratio
Plain HuffmanTagged Huffman(s,c)-Dense CodeEnd-Tagged Dense Code
Plain HuffmanTagged Huffman(s,c)-Dense CodeEnd-Tagged Dense Code

April 2005 Phd dissertation – Antonio Fariña Martínez 50/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 51/85
Dynamic compressorsDynamic compressors
One-pass compressors
Do not allow Text Retrieval* — Varying assotiation word codeword
Well-suited for file transmission and storage— Transmission of streams of text— Real-time transmission— Paralelism of:
Compression - transmision & reception – decompression
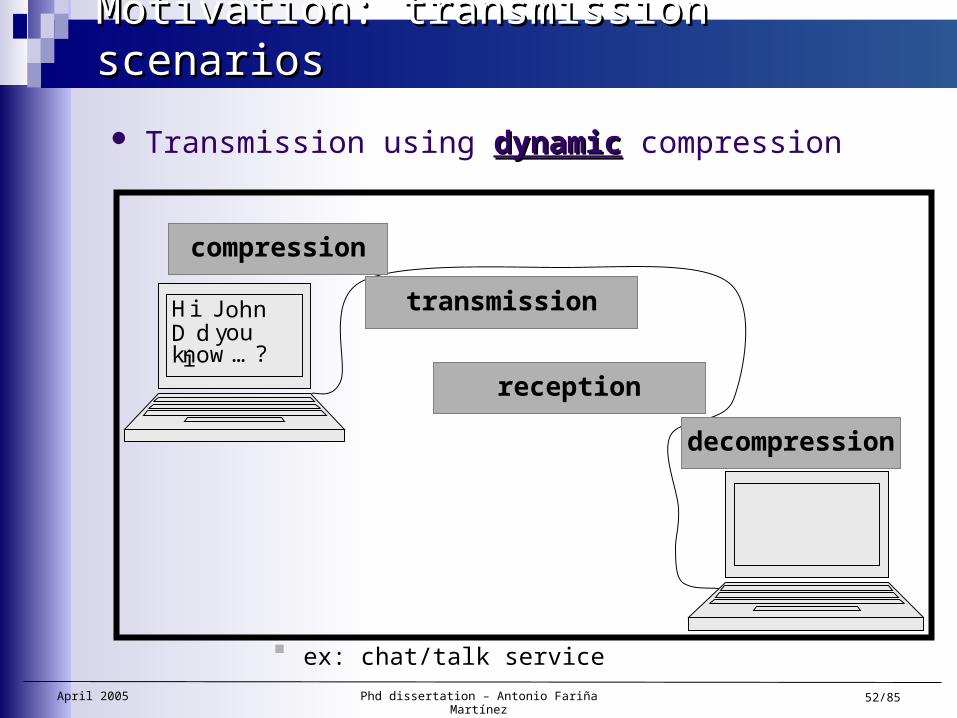
April 2005 Phd dissertation – Antonio Fariña Martínez 52/85
Motivation: transmission scenariosMotivation: transmission scenarios
compression
transmission
reception
decompression
ex: chat/talk service
Transmission using dynamicdynamic compression
Hi JohnD id youknow …?

April 2005 Phd dissertation – Antonio Fariña Martínez 53/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 54/85
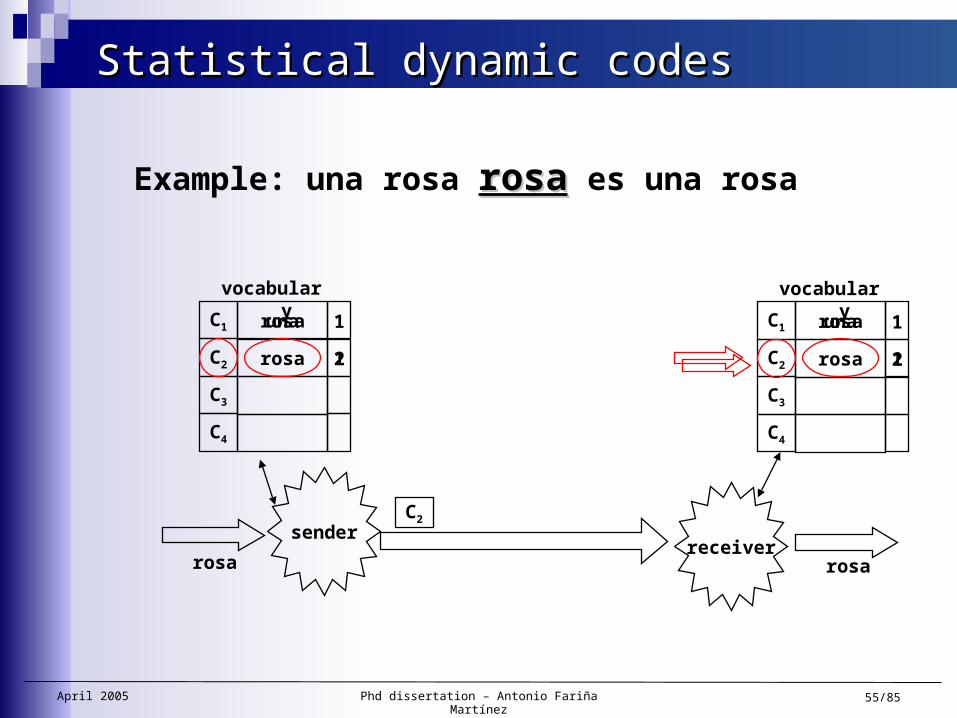
Statistical dynamic codesStatistical dynamic codes
Dynamic model. One pass techniques
Frequencies are computed dynamically as text arrives.
Sender and receiver…
— Start with an empty vocabulary.
— Adapt their vocabulary during the process.
— Both processes are symmetric
April 2005 Phd dissertation – Antonio Fariña Martínez 55/85
Statistical dynamic codesStatistical dynamic codes
rosa
senderreceiver
Example: una rosa rosarosa es una rosa
rosa
una
rosa
C1
C2
C3
C4
vocabulary
1
C2
rosa
21
rosauna
rosa
C1
C2
C3
C4
vocabulary
1
21
April 2005 Phd dissertation – Antonio Fariña Martínez 56/85
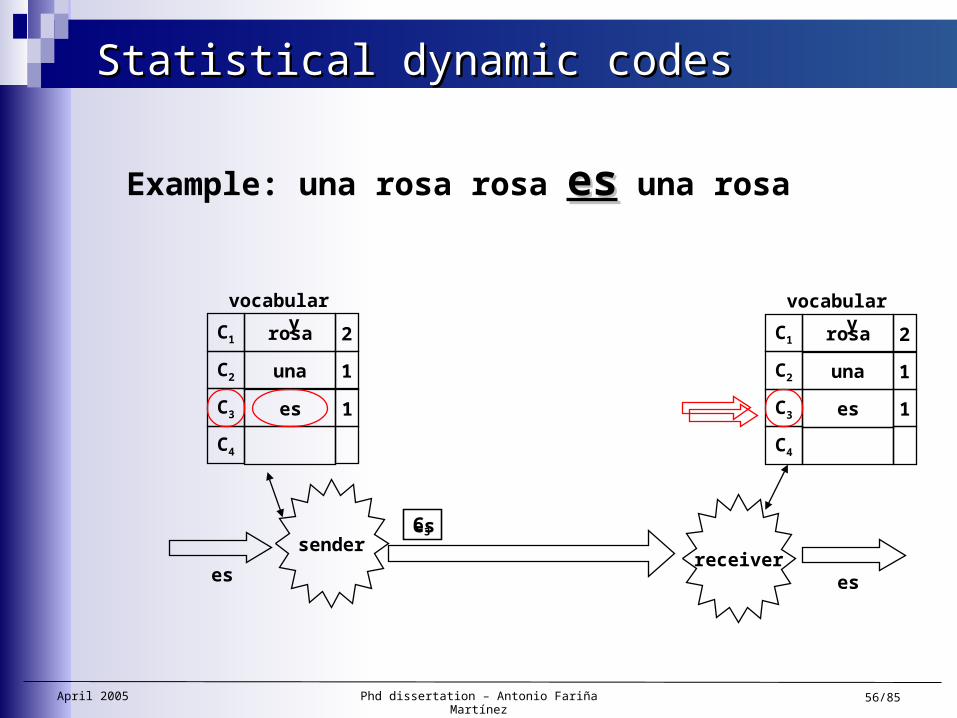
Statistical dynamic codesStatistical dynamic codes
1
rosa
senderreceiver
es
una
C1
C2
C3
C4
vocabulary
2
C3
1
rosa
una
C1
C2
C3
C4
vocabulary
2
es
es
es 1
Example: una rosa rosa eses una rosa
es 1

April 2005 Phd dissertation – Antonio Fariña Martínez 57/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 58/85
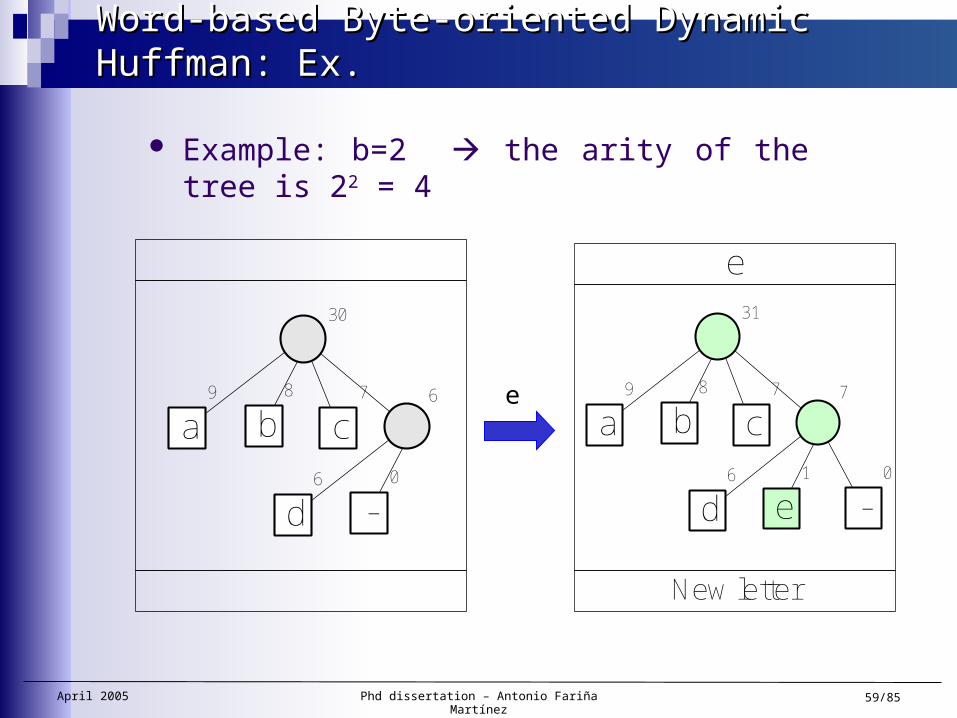
Word-based Byte-oriented Dynamic HuffmanWord-based Byte-oriented Dynamic Huffman
Character-based dynamic Huffman: — [Fal73, Gal78], [Knu85] FGK algorithm, [Vit87]
Our implementation:— Word-based
Use of a hash table to hold words (and to find them efficiently)
— Byte oriented Worsens compression ratio but improves decompression speed256-ary Huffman tree More complex than bit oriented.
— Well-formed Huffman tree during compression/decompr.Update of the tree is a complex task (but height <4)
— Compression ratio about 30-35 %.
April 2005 Phd dissertation – Antonio Fariña Martínez 59/85
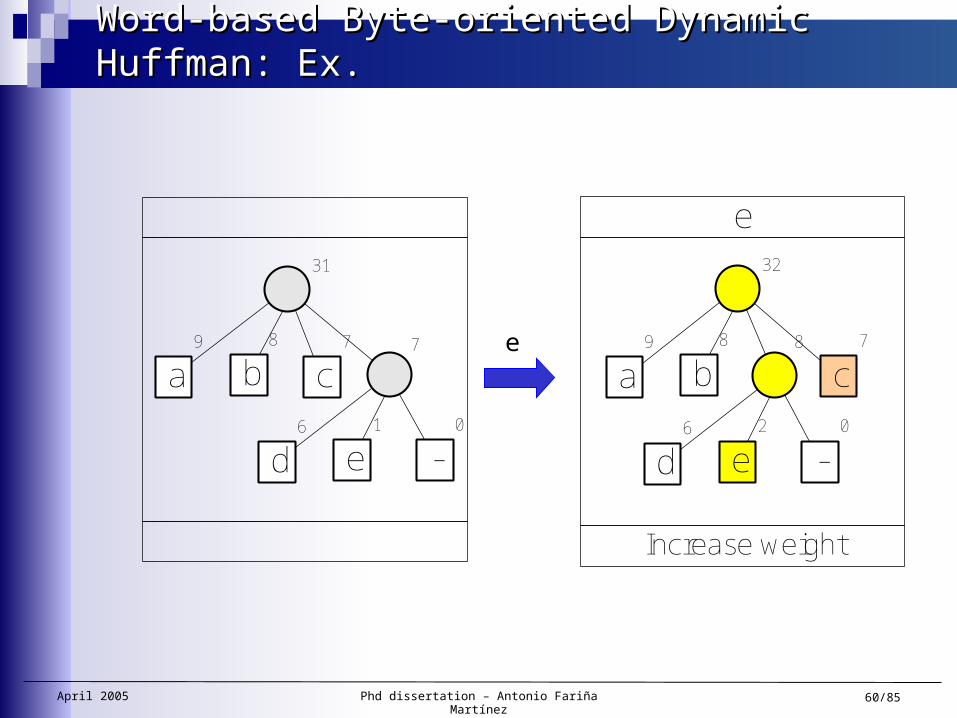
Word-based Byte-oriented Dynamic Huffman: Ex.Word-based Byte-oriented Dynamic Huffman: Ex.
e
New letter
a9
31
b8
c7
d6
7
e1
-0
a9
30
b8
c7
d6
6
-0
e
Example: b=2 the arity of the tree is 22 = 4
April 2005 Phd dissertation – Antonio Fariña Martínez 60/85
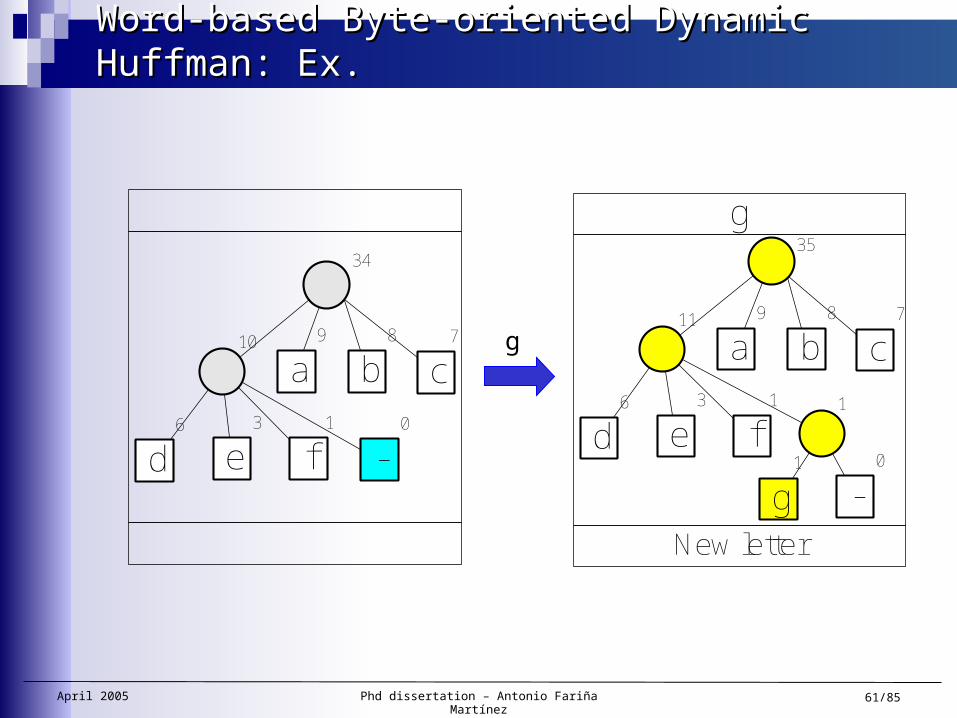
Word-based Byte-oriented Dynamic Huffman: Ex.Word-based Byte-oriented Dynamic Huffman: Ex.
a9
31
b8
c7
d6
7
e1
-0
a9
32
b8
c7
d6
8
e2
-0
e
Increase weight
e
April 2005 Phd dissertation – Antonio Fariña Martínez 61/85
Word-based Byte-oriented Dynamic Huffman: Ex.Word-based Byte-oriented Dynamic Huffman: Ex.
a9
34
b8
c7
d6
10
e3
f1
-0
g
g
New letter
a9
35
b8
c7
d6
11
e3
f1
g1
1
-0

April 2005 Phd dissertation – Antonio Fariña Martínez 62/85
Word-based Byte-oriented Dynamic HuffmanWord-based Byte-oriented Dynamic Huffman
Cost of compression is O(# target symbols output)— Byte-oriented O(# bytes output)— Bit-oriented O(# bits output)
The height of the tree is
lower in the byte-oriented approach
Less propagations of changes upwards in the tree

April 2005 Phd dissertation – Antonio Fariña Martínez 63/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 64/85
Exchange with top send codeword increase frequency
Dynamic End-Tagged Dense CodeDynamic End-Tagged Dense Code
It uses the on-the-fly encoding and decoding algorithms— Requirement: maintaining the vocabulary sorted by freq.
speed
vocabulary
1 the 8
2 is 4
3 code 2
4 tag 2
5 Huffman 2
6
7 ratio 1
8 1
ETDC
speed
12
C8 = encode (8)
Example

April 2005 Phd dissertation – Antonio Fariña Martínez 65/85
exchange with top send codeword increase frequency
Dynamic End-Tagged Dense CodeDynamic End-Tagged Dense Code
It uses the on-the-fly encoding and decoding algorithms— Requirement: maintaining the vocabulary sorted by freq.
speed
vocabulary
1 the 8
2 is 4
3 2
4 tag 2
5 Huffman 2
6
7 ratio 1
8 1ETDC
2 C6 = encode (6)
code
speed
3
Example

April 2005 Phd dissertation – Antonio Fariña Martínez 66/85
Dynamic End-Tagged Dense Code: SummaryDynamic End-Tagged Dense Code: Summary
It is much simpler than the Dynamic Huffman— Maintaining the ranked words Vs maintaining a Huffman
tree.
— Performs one swap per codeword O(1) Vs O(height Huffman tree)
— Cost of compressionO(# codewords output) Vs O(# bytes output)

April 2005 Phd dissertation – Antonio Fariña Martínez 67/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 68/85
Dynamic (s,c)-Dense CodeDynamic (s,c)-Dense Code
Generalization of Dynamic ETDC— On-the-fly encoding and decoding,— Maintaining the sorted vocabulary, and— Maintaining an optimal value of s
Two methods were designed:
Counting bytes approach
Ranges approach
April 2005 Phd dissertation – Antonio Fariña Martínez 69/85
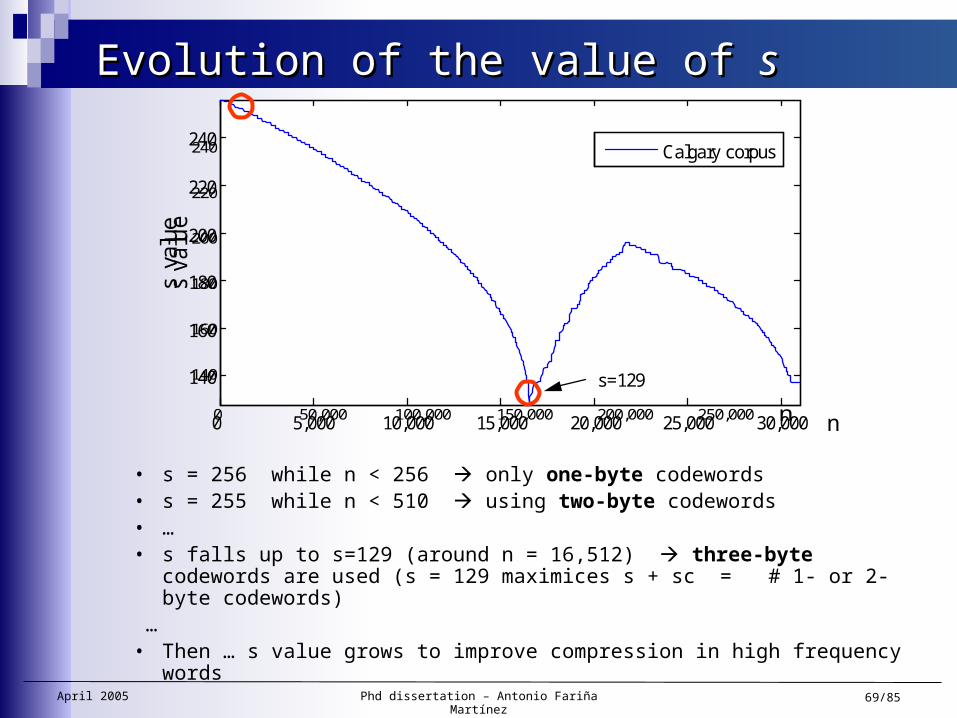
Evolution of the value of Evolution of the value of ss
• s = 256 while n < 256 only one-byte codewords• s = 255 while n < 510 using two-byte codewords• …• s falls up to s=129 (around n = 16,512) three-byte codewords are
used (s = 129 maximices s + sc = # 1- or 2-byte codewords) … • Then … s value grows to improve compression in high frequency words
0 50,000 100,000 150,000 200,000 250,000
140
160
180
200
220
240
n
s v
alu
e
s=129
Ap Newswire corpus
0 5,000 10,000 15,000 20,000 25,000 30,000
140
160
180
200
220
240
n
s v
alue
s=129
Calgary corpus
April 2005 Phd dissertation – Antonio Fariña Martínez 70/85
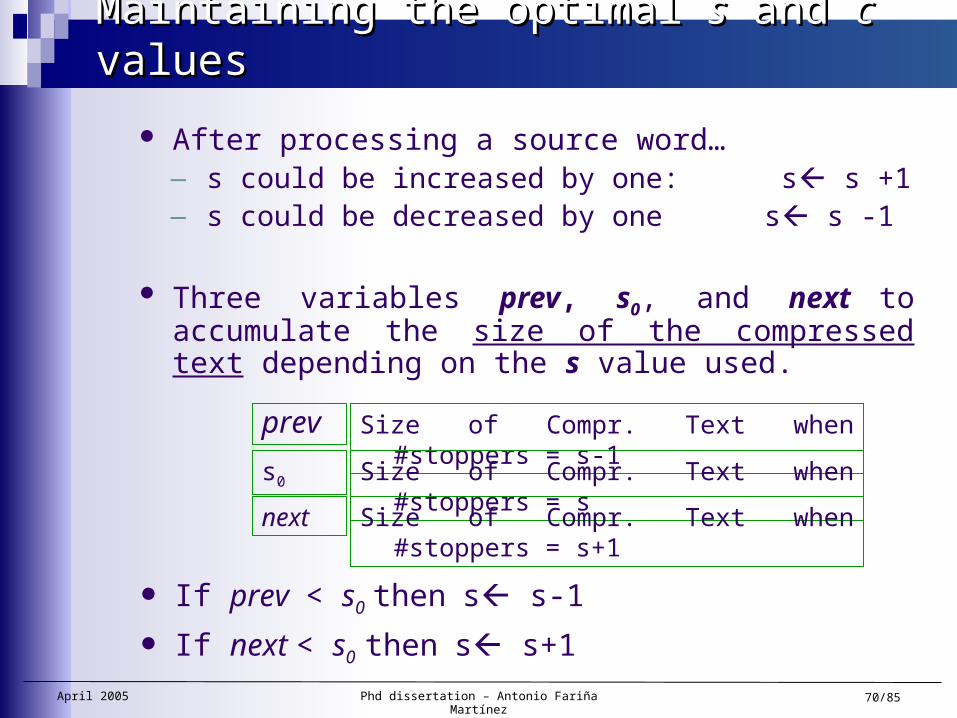
Maintaining the optimal Maintaining the optimal ss and and cc values values
After processing a source word…— s could be increased by one: s s +1— s could be decreased by one s s -1
Three variables prev, s0, and next to accumulate the size of the compressed text depending on the s value used.
prev Size of Compr. Text when #stoppers = s-1
Size of Compr. Text when #stoppers = ss0
Size of Compr. Text when #stoppers = s+1next
If prev < s0 then s s-1
If next < s0 then s s+1
April 2005 Phd dissertation – Antonio Fariña Martínez 71/85
Maintaining the optimal Maintaining the optimal ss and and cc values values
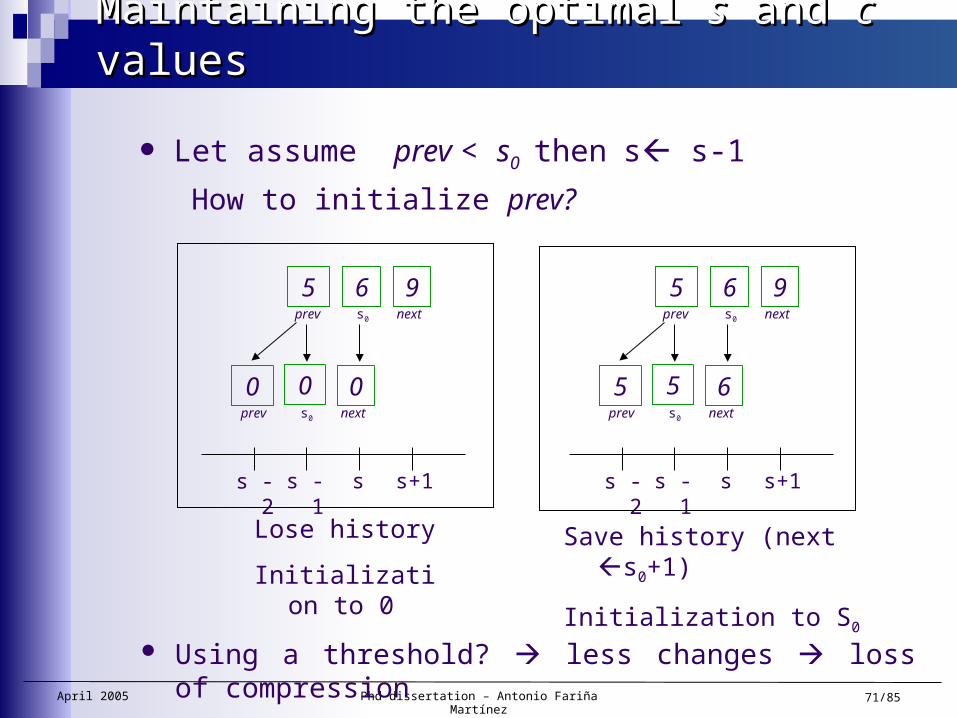
Let assume prev < s0 then s s-1
How to initialize prev?
prev
5 6 9s0 next
0 0s0 nextprev
0
s s+1s -1s -2
Lose history
Initialization to 0
prev
5 6 9s0 next
5 6s0 nextprev
5
s s+1s -1s -2
Save history (next s0+1)
Initialization to S0
Using a threshold? less changes loss of compression

April 2005 Phd dissertation – Antonio Fariña Martínez 72/85
Dynamic (s,c)-Dense Code: SummaryDynamic (s,c)-Dense Code: Summary
Generalization of Dynamic End-Tagged Dense Code
— Same idea:Using swaps to maintain the vocabulary sorted
— Extra operations: Maintaining the optimal value of s

April 2005 Phd dissertation – Antonio Fariña Martínez 73/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 74/85
Empirical ResultsEmpirical Results
Techniques compared:— Semi-static and dynamic versions of:
Plain Huffman (s,c)-Dense Code End-Tagged Dense Code
— Arithmetic word-based bit-oriented compressor
— Gzip
— Bzip2
Comparison in:— Compression ratio
— Compression speed
— Decompression speed
April 2005 Phd dissertation – Antonio Fariña Martínez 75/85
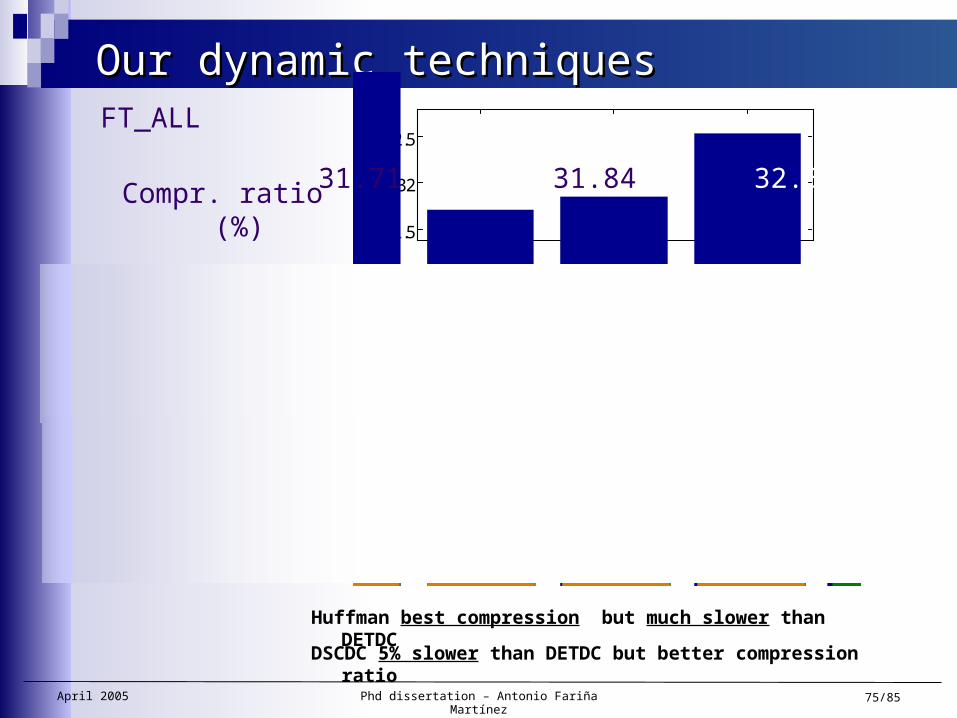
Our dynamic techniquesOur dynamic techniques
D-PH D-SCDC D-ETDC
31.5
32
32.5
com
pres
sion
rat
io (
%)
D-PH D-SCDC D-ETDC55006000650070007500
com
pres
sion
spe
edK
byte
s/se
c
D-PH D-SCDC D-ETDC
8000
10000
12000
14000
16000
deco
mpr
essi
on s
peed
Kby
tes/
sec
31.71 31.84 32.54
5,724 6,944 7,459
7,791 14,067 14,800
Compr. ratio (%)
Compr. Speed(Kbytes/sec)
Decompr. Speed(Kbytes/sec)
Huffman best compression but much slower than DETDC
DSCDC 5% slower than DETDC but better compression ratio
FT_ALL
April 2005 Phd dissertation – Antonio Fariña Martínez 76/85
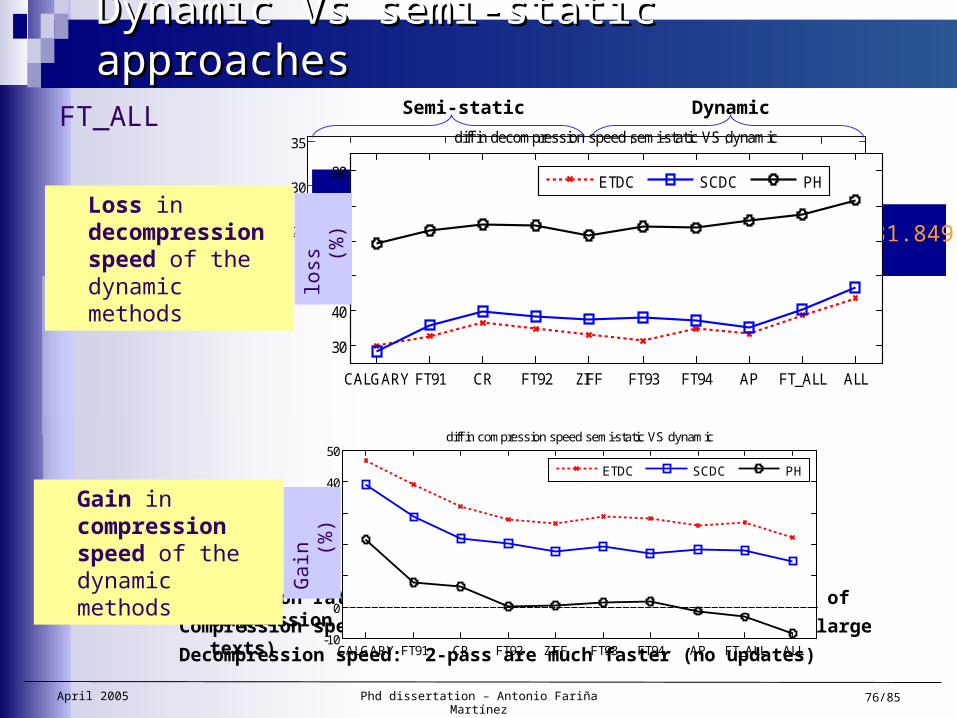
Dynamic Vs semi-static approachesDynamic Vs semi-static approaches
Compression ratio: dynamism causes negligible loss of compressionCompression speed: 1-pass are faster (except DPH in large texts)Decompression speed: 2-pass are much faster (no updates)
PH SCDC ETDC TH D-PH D-SCDC D-ETDC
25
30
35
PH SCDC ETDC TH D-PH D-SCDC D-ETDC
5500
6000
6500
7000
7500
com
pres
sion
spe
edK
byte
s/se
c
PH SCDC ETDC TH D-PH D-SCDC D-ETDC
8000
10000
12000
deco
mpr
essi
on s
peed
Kby
tes/
sec
PH SCDC ETDC TH D-PH D-SCDC D-ETDC
25
30
35
PH SCDC ETDC TH D-PH D-SCDC D-ETDC
5500
6000
6500
7000
7500
com
pres
sion
spe
edK
byte
s/se
c
PH SCDC ETDC TH D-PH D-SCDC D-ETDC
8000
10000
12000
deco
mpr
essi
on s
peed
Kby
tes/
sec
Compression ratio (%)
Compression Speed
(Kbytes/sec)
Decompr. Speed
(Kbytes/sec)
31.696 31.839 32.527 31.710 31.849 32.537
5,922 5,882 5,888 5,724 6,944 7,459
23,856 23,552 24,146 7,791 14,067 14,800
FT_ALL Semi-static Dynamic
CALGARY FT91 CR FT92 ZIFF FT93 FT94 AP FT_ALL ALL
30
40
50
60
70
80
diff in decompression speed semi-static VS dynamic
% g
ain
ETDC SCDC PH
CALGARY FT91 CR FT92 ZIFF FT93 FT94 AP FT_ALL ALL-10
0
10
20
30
40
50
% lo
ss
diff in compression speed semi-static VS dynamic
ETDC SCDC PH
Gain in compression speed of the dynamic methods G
ain
(%
)
Loss in decompression speed of the dynamic methods lo
ss (
%)
April 2005 Phd dissertation – Antonio Fariña Martínez 77/85
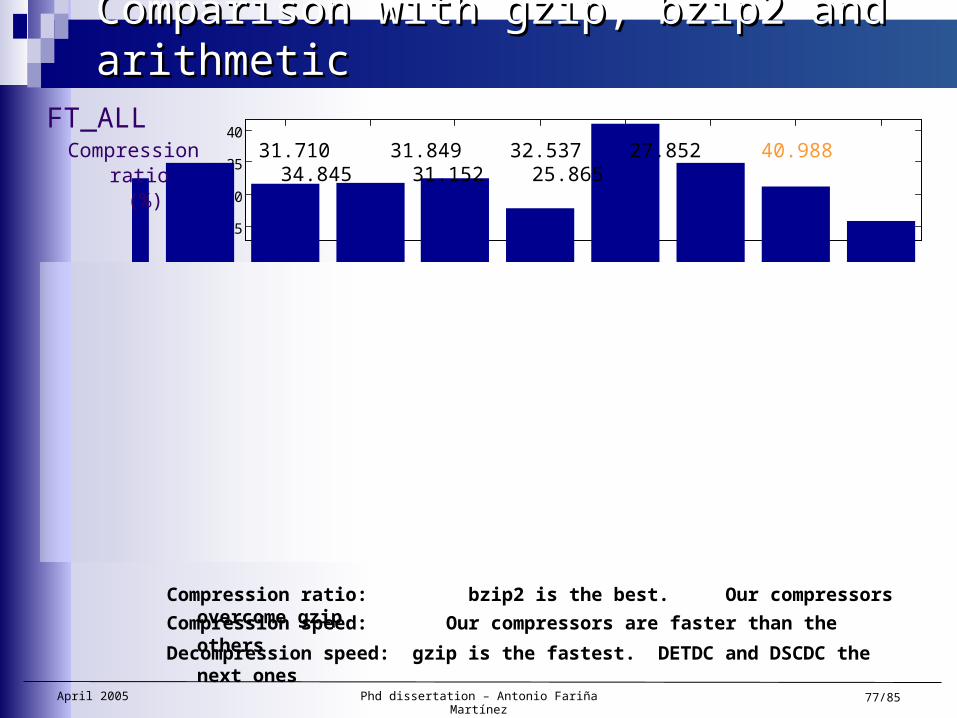
Comparison with gzip, bzip2 and arithmeticComparison with gzip, bzip2 and arithmetic
D-PH D-SCDC D-ETDC arith gzip -f gzip -b bzip2 -f bzip2 -b
25
30
35
40
D-PH D-SCDC D-ETDC arith gzip -f gzip -b bzip2 -f bzip2 -b
2000
4000
6000
com
pres
sion
spe
edK
byte
s/se
c
D-PH D-SCDC D-ETDC arith gzip -f gzip -b bzip2 -f bzip2 -b
8000
10000
12000
14000
deco
mpr
essi
on s
peed
Kby
tes/
sec
Compression ratio (%)
Compression Speed
(Kbytes/sec)
Decompr. Speed
(Kbytes/sec)
31.710 31.849 32.537 27.852 40.988 34.845 31.152 25.865
5,724 6,944 7,459 2,157 5,045 2,015 1,059 824
7,791 14,067 14,800 2,762 17,249 19,440 3,115 2,513
Compression ratio: bzip2 is the best. Our compressors overcome gzipCompression speed: Our compressors are faster than the othersDecompression speed: gzip is the fastest. DETDC and DSCDC the next ones
FT_ALL

April 2005 Phd dissertation – Antonio Fariña Martínez 78/85
Dynamic compression: SummaryDynamic compression: Summary
3 dynamic techniques.— Dyn-Huffman compresses more than the others— DETDC is the fastest (DSCDC is close to DETDC)
Dynamism:— Little impact in compression ratio— 1-pass faster than 2-pass at compression— 2-pass much faster at decompression
They are a valuable contribution— Less compression than bzip2 and arith. But much faster— More compression ratio and speed than gzip. Slower at
decompression
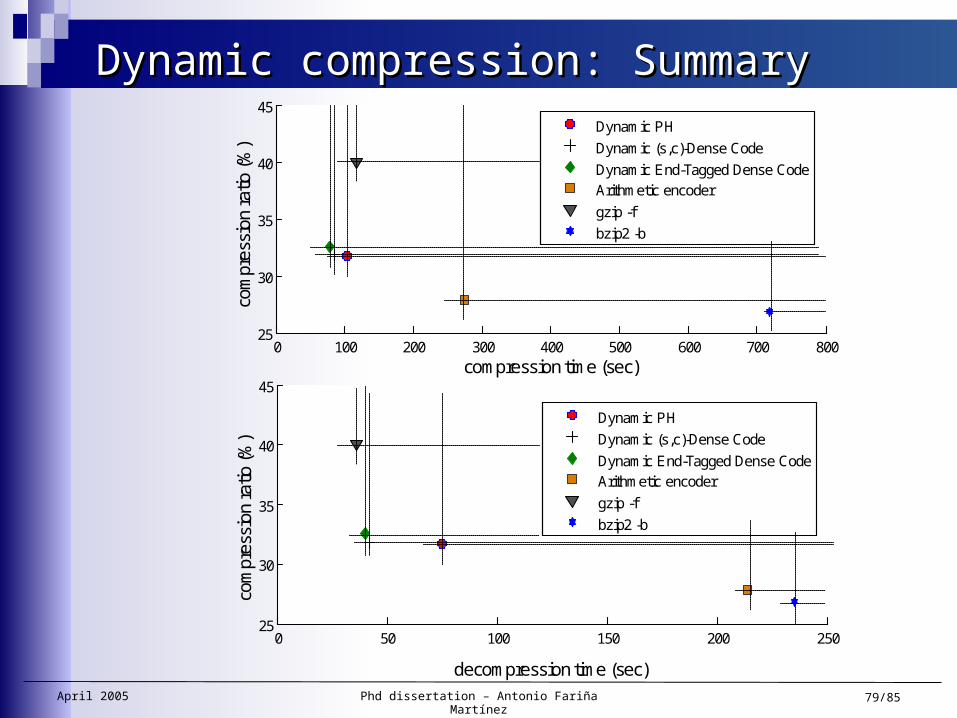
April 2005 Phd dissertation – Antonio Fariña Martínez 79/85
Dynamic compression: SummaryDynamic compression: Summary
0 100 200 300 400 500 600 700 80025
30
35
40
45
compression time (sec)
com
pres
sion
ratio
(%)
Dynamic PH
Dynamic (s,c)-Dense Code
Dynamic End-Tagged Dense CodeArithmetic encoder
gzip -f
bzip2 -b
0 50 100 150 200 25025
30
35
40
45
decompression time (sec)
com
pres
sion
ratio
(%)
Dynamic PH
Dynamic (s,c)-Dense Code
Dynamic End-Tagged Dense CodeArithmetic encoder
gzip -f
bzip2 -b

April 2005 Phd dissertation – Antonio Fariña Martínez 80/85
—Semi-static CompressorsWord-based Huffman: Plain & Tagged Huffman
End-Tagged Dense Code
(s,c)-Dense Code
Empirical Results
—Dynamic CompressorsStatistical Dynamic compressors
Word-oriented Huffman
Dynamic End-Tagged Dense Code
Dynamic (s,c)-Dense Code
Empirical Results
Conclusions and Contributions of the Thesis
Two Scenarios
Introduction
OutlineOutlineOutlineOutline

April 2005 Phd dissertation – Antonio Fariña Martínez 81/85
Conclusions: ContributionsConclusions: Contributions
“Dense” family of word-based byte-oriented compressors— Simple and fast encoding & decoding.
Semi-static compressors— Compression ratio close to that of Plain Huffman— Same searching capabilities than Tagged Huffman.— Overcome Tagged Huffman in all aspects.
Dynamic compressors— Good compression ratio (small cost of dynamism)— Very fast at compression — Good decompression speed

April 2005 Phd dissertation – Antonio Fariña Martínez 82/85
Conclusions: Concrete contributionsConclusions: Concrete contributions
— End-Tagged Dense Code— (s,c)-Dense Code
— New bounds on D-ary Huffman codes.
Semi-static
Dynamic—Dynamic word-based byte-oriented Huffman—Dynamic End-Tagged Dense Code—Dynamic (s,c)-Dense Code
Efficient implementations
Complete experimental validations
Contributions of the thesis

April 2005 Phd dissertation – Antonio Fariña Martínez 83/85
Future WorkFuture Work
Searchable dynamic compression— Adaptation of the D-ETDC— Faster at decompression.— Accepted in SIGIR’05
Compression of growing collections— Permits adding more text to a compressed corpus — Avoids re-compression — Idea: Encoding phrases (for words that become very
frequent) with a unique codeword, instead of recompression
— Submitted to ECDL’05

April 2005 Phd dissertation – Antonio Fariña Martínez 84/85
Research ResultsResearch Results
Ing. Software en la Década del 20001Book Chapter
National. Conferen.
Internat. Conferen.
JISBD’04, JISBD’03, JBIDI’033
SIGIR’05, SPIRE’04, SCCC’04, VODCA’04, SPIRE’035
Accepted papers
Internat. Conference ECDL’051
Submitted papers
International Journals Information Retrieval (IR) Information Processing and Management (IPM)
2
Manuscripts to submit
DCC (Univ. Chile) 2003:2003: August 26th - October 6th
2004:2004: December 2th - December 16th
2
Research Stays

April 2005 Phd dissertation – Antonio Fariña Martínez 85/85
That’s all !! That’s all !!
Thank you very much !!
…?


















