
Near-optimal limited-search detection on ISI/CDMA channels and decoding of long convolutional codes
24
IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46,NO. 4, JULY2000 1459 Near-Optimal Limited-Search Detection on ISI/CDMA Channels and Decoding of Long Convolutional Codes Lei Wei, Senior Member, IEEE, and Honghui Qi Abstract—We derive an upper bound on the bit-error proba- bility (BEP) in limited-search detection over a finite interference channel. A unified channel model is presented; this includes finite-length intersymbol interference channels and multiuser CDMA channels as two special cases. We show that the BEP of the -algorithm (MA) is bounded from above by the sum of three terms: an upper bound on the error probability of the Viterbi algorithm (VA) detection given in [10], and upper bounds on the error probabilities of two types of erroneous decision caused by the correct path loss event. We prove that error propagation (in terms of the mean recovery step number) is finite for all finite interference channels. The convergence and asymptotic behavior of the upper bounds are studied. The results show that, if a channel satisfies certain mild conditions, all series in the bounds are convergent. One of the key results is that, for any finite interference channel satisfying certain mild conditions, the asymptotic BEP of the MA is bounded by the same upper and lower bounds (which have the same asymptotical behavior) as those for the VA if the correct path loss probability is smaller than that of the VA. Furthermore, we extend the above results to near optimally decode long convolutional codes in a short packet format (about 200–300 bits). We present a nonsorting combined algorithm and showed that the algorithm with and can near-optimally decode the code. We also propose a hierarchical decoding algorithm (HDA) to further cut down the average decoding complexity. Numerical results show that the bounds are reasonably tight. The HDA can achieve a performance within about 0.8 dB of the sphere-packing lower bound for a packet error rate of and a packet length below 200 bits, which is the best reported decoding performance so far for block sizes from 100 to 200 bits. Index Terms—Convolutional codes and decoding algorithm, fi- nite ISI channels, the -algorithm or the breadth-first search al- gorithm, multiuser detection, performance analysis, performance bounds. Manuscript received July 1, 1998; revised January 13, 2000. The material in this paper was presented in part at the IEEE International Symposium on Information Theory, Ulm, Germany, June 29–July 4, 1997, and in part at the IEEE International Symposium on Information Theory, Cambridge, MA, Au- gust 16–21, 1998. L. Wei was with the Department of Engineering, FEIT, Australian National University, Canberra, ACT 0200, Australia. He is now with The Institute of Telecommunications Research (TITR), School of Electrical, Computer, and Telecommunications Engineering, Faculty of Informatics, University of Wol- longong, Wollongong, NSW 2522, Australia (e-mail: [email protected]). H. Qi is with the Telecommunications and Information Technology Research (TITR) Institute, University of Wollongong, Wollongong, NSW 2522, Australia. Communicated by R. Kohno, Associate Editor for Detection. Publisher Item Identifier S 0018-9448(00)05012-4. I. INTRODUCTION N OISE and interference often severely impede reliable communications. Interference includes intersymbol interference (ISI) in pulse-modulation systems and multiuser interference (MUI) in code-division multiple-access (CDMA) systems. Over the last 30 years, the famous Viterbi algorithm (VA) has been widely applied for solving these problems [1], [2]. It has also been well known since the 1970’s that the optimum receiver for ISI channels consists of a linear filter (i.e., a whitened matched filter [10] or a matched filter [11]), a symbol-rate sampler, and the VA. For MUI channels the optimum receiver can be achieved by a matched filter [12] or a whitened matched filter [14], a symbol-rate sampler, and the VA. The complexity of the VA (in terms of the number of states) grows exponentially with the memory length of the code, or the number of ISI taps for ISI channels, or the number of users for MUI channels. For codes with large memory lengths, sequential algorithms such as the Fano algorithm [3], [4] or the stack algo- rithm [7] are often used, since they can achieve a better tradeoff between the error performance and the decoding complexity at a high bit energy-to-noise ratio region. On the other hand, many reduced-complexity VA algorithms to deal with in- terference problems have been proposed and became popular. Much work has been done in the area of sequential detec- tion [3]–[9], [14]–[37]. A detailed survey and comparison of the reduced VA algorithms can be found in [16] and [22]. These reduced-complexity algorithms can be divided into three cat- egories: breadth-first, metric-first, and depth-first [16]. For in- terference channels, the breadth-first algorithms are especially promising and can often achieve near-optimum performance with very low complexity [14], [15], [17], [18], [23]–[28], and [36]. The breadth-first algorithms include the well-known -al- gorithm (MA) or the list algorithm [16]–[22], the -algorithm [28] and reduced-state sequence detection (RSSD) [23]–[25]. In [21], Anderson and Offer have shown that the MA is more effi- cient than the RSSD algorithm. Although the RSSD algorithm is not optimal, it is still very popular. One reason is that the error probability of the RSSD algorithm is much easier to determine than that of the MA. When the MA is applied in the decoding of most convolu- tional codes, its error performance is often much worse than that of the -state Viterbi algorithm using optimal convolu- tional codes (listed in [42, Table 11.1]). This poor performance 0018–9448/00$10.00 © 2000 IEEE
Transcript of Near-optimal limited-search detection on ISI/CDMA channels and decoding of long convolutional codes

IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000 1459
Near-Optimal Limited-Search Detection onISI/CDMA Channels and Decoding of Long
Convolutional CodesLei Wei, Senior Member, IEEE,and Honghui Qi
Abstract—We derive an upper bound on the bit-error proba-bility (BEP) in limited-search detection over a finite interferencechannel. A unified channel model is presented; this includesfinite-length intersymbol interference channels and multiuserCDMA channels as two special cases. We show that the BEP of the
-algorithm (MA) is bounded from above by the sum of threeterms: an upper bound on the error probability of the Viterbialgorithm (VA) detection given in [10], and upper bounds on theerror probabilities of two types of erroneous decision caused bythe correct path loss event. We prove that error propagation (interms of the mean recovery step number) is finite for all finiteinterference channels.
The convergence and asymptotic behavior of the upper boundsare studied. The results show that, if a channel satisfies certain mildconditions, all series in the bounds are convergent. One of the keyresults is that, for any finite interference channel satisfying certainmild conditions, the asymptotic BEP of the MA is bounded by thesame upper and lower bounds (which have the same asymptoticalbehavior) as those for the VA if the correct path loss probability issmaller than that of the VA.
Furthermore, we extend the above results to near optimallydecode long convolutional codes in a short packet format (about200–300 bits). We present a nonsorting combined algorithmand showed that the algorithm with 2 and
( free ) can near-optimally decode the code. We alsopropose a hierarchical decoding algorithm (HDA) to further cutdown the average decoding complexity.
Numerical results show that the bounds are reasonably tight.The HDA can achieve a performance within about 0.8 dB of thesphere-packing lower bound for a packet error rate of10 4 and apacket length below 200 bits, which is the best reported decodingperformance so far for block sizes from 100 to 200 bits.
Index Terms—Convolutional codes and decoding algorithm, fi-nite ISI channels, the -algorithm or the breadth-first search al-gorithm, multiuser detection, performance analysis, performancebounds.
Manuscript received July 1, 1998; revised January 13, 2000. The materialin this paper was presented in part at the IEEE International Symposium onInformation Theory, Ulm, Germany, June 29–July 4, 1997, and in part at theIEEE International Symposium on Information Theory, Cambridge, MA, Au-gust 16–21, 1998.
L. Wei was with the Department of Engineering, FEIT, Australian NationalUniversity, Canberra, ACT 0200, Australia. He is now with The Institute ofTelecommunications Research (TITR), School of Electrical, Computer, andTelecommunications Engineering, Faculty of Informatics, University of Wol-longong, Wollongong, NSW 2522, Australia (e-mail: [email protected]).
H. Qi is with the Telecommunications and Information Technology Research(TITR) Institute, University of Wollongong, Wollongong, NSW 2522, Australia.
Communicated by R. Kohno, Associate Editor for Detection.Publisher Item Identifier S 0018-9448(00)05012-4.
I. INTRODUCTION
NOISE and interference often severely impede reliablecommunications. Interference includes intersymbol
interference (ISI) in pulse-modulation systems and multiuserinterference (MUI) in code-division multiple-access (CDMA)systems. Over the last 30 years, the famous Viterbi algorithm(VA) has been widely applied for solving these problems [1],[2]. It has also been well known since the 1970’s that theoptimum receiver for ISI channels consists of a linear filter(i.e., a whitened matched filter [10] or a matched filter [11]),a symbol-rate sampler, and the VA. For MUI channels theoptimum receiver can be achieved by a matched filter [12] ora whitened matched filter [14], a symbol-rate sampler, and theVA.
The complexity of the VA (in terms of the number of states)grows exponentially with the memory length of the code, or thenumber of ISI taps for ISI channels, or the number of users forMUI channels. For codes with large memory lengths, sequentialalgorithms such as the Fano algorithm [3], [4] or the stack algo-rithm [7] are often used, since they can achieve a better tradeoffbetween the error performance and the decoding complexity ata high bit energy-to-noise ratio region. On the otherhand, many reduced-complexity VA algorithms to deal with in-terference problems have been proposed and became popular.
Much work has been done in the area of sequential detec-tion [3]–[9], [14]–[37]. A detailed survey and comparison ofthe reduced VA algorithms can be found in [16] and [22]. Thesereduced-complexity algorithms can be divided into three cat-egories: breadth-first, metric-first, and depth-first [16]. For in-terference channels, the breadth-first algorithms are especiallypromising and can often achieve near-optimum performancewith very low complexity [14], [15], [17], [18], [23]–[28], and[36].
The breadth-first algorithms include the well-known-al-gorithm (MA) or the list algorithm [16]–[22], the -algorithm[28] and reduced-state sequence detection (RSSD) [23]–[25]. In[21], Anderson and Offer have shown that the MA is more effi-cient than the RSSD algorithm. Although the RSSD algorithmis not optimal, it is still very popular. One reason is that the errorprobability of the RSSD algorithm is much easier to determinethan that of the MA.
When the MA is applied in the decoding of most convolu-tional codes, its error performance is often much worse thanthat of the -state Viterbi algorithm using optimal convolu-tional codes (listed in [42, Table 11.1]). This poor performance
0018–9448/00$10.00 © 2000 IEEE

1460 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
Fig. 1. Baseband equivalent model of the system.
is due to error propagation caused by the correct path loss event.The performance of the MA can be improved by either usingerror-control codes with good recovery capability (for example,systematic feed forward (SFF) codes [19]) or by modifying thestructure to overcome error propagation (for example, by usingthe bidirectional algorithm [29]).
It is very difficult to analyze the exact bit-error probability(BEP) of the MA, even for the simplest case of decision feed-back detection (DFD). In [31], Duttweileret al.have shown anupper bound on the error probability in DFD over ISI chan-nels. In [32], O’Reilly and de Oliveira Duarte have further de-veloped upper and lower bounds on the error probability inDFD over ISI channels. In [18] and [20], Anderson and Mohanhave shown that two typical factors (the correct path loss eventand error propagation) severely affect the error performance ofthe MA and furthermore that the MA can rapidly recover fromerror propagation for ISI channels and continuous-phase mod-ulation (CPM). Anderson’s work [16]–[21] has provided a veryimportant basis for us to understand the MA. In [34], Johan-nesson and Zigangirov have given an upper bound on the correctpath loss probability for convolutional codes on a binary-sym-metric channel. In [36], Aulin proposed the vector Euclideandistance concept to study the correct path loss probability. Per-haps, Hashimoto is the first person who derived a unified al-gorithm which includes the VA, the MA, and the list algorithmas special cases, as well as derived a performance upper boundfor the generalized algorithm in [17], based on the Gallager’srandom coding approach. In [17], Hashimoto also pointed outthe problem caused by error propagation and observed that forISI channels “error propagation is not significant.” Unfortu-nately, this work has been largely ignored.
In this paper, we will derive an upper bound on the error prob-ability of the MA over finite interference channels. Unlike thebounds in [17], which were based on random coding arguments,we will derive an upper bound for a particular channel or code,which is similar to that in [10] and [12]. We will show that theBEP of the MA is bounded from above by the sum of threeterms: an upper bound on the error probability of the Viterbi al-gorithm detection given in [10], and upper bounds on the errorprobabilities of two types of erroneous decision caused by thecorrect path loss event. Thus if the quantities of the second andthird terms of the upper bound can be reduced to a level much
lower than the first term, then we will be able to achieve near-op-timal detection using the MA.
In this paper, we will further use the upper bound as a basicanalytical criterion for us to tune the breadth-first algorithms,in order to achieve near-optimal decoding of long convolutionalcodes with a low decoding complexity in a short packet format.The tuning includes the selection of important parameters suchas the minimum number of paths kept, and the design of a hier-archical decoding structure.
The paper is organized as follows. In Section II we introducethe concept of interference channels, which include ISI chan-nels and MUI channels as two special cases. We then derive anupper bound on the error probability for MA detection and studythe correct path loss probability and the recovery behavior inSection III. In Section IV, the asymptotic behavior of the upperbound is analyzed and the results show that under mild condi-tions there is a minimum number of paths kept (denoted as)such that the error probability of the MA with has an asymp-totic error probability identical to that of the VA. In Section Vwe study properties for near-optimal decoding. In Section VIwe propose a hierarchical decoding algorithm to near-optimallydecode long convolutional codes. Section VII presents numer-ical results. Finally, in Section VIII, conclusions are given. Inthis paper, we indicate the states of a discrete random process“states” (in Roman), the states of a trellis “states” (in Italic), andthe (state) paths kept in the MA “paths.”
II. FINITE-LENGTH INTERFERENCECHANNEL
The baseband equivalent model of the system is illustrated inFig. 1. The system can be viewed as a point-to-point single-usersystem, where is the number of parallel transmissions, and
is the impulse response of theth transmitter.For conven-tional ISI channels, we have , thus subscript can bedropped. The system can also be viewed as a multiple-accesssystem (multiple points to one point), such as a CDMA system,where is then the number of users and is comprised ofa spreading code and a chip pulse-shaping filter. In both cases,
can be time-varying [37]. In Fig. 1, is the transmissiondelay, is the carrier phase, is the transmitted bit where
, and is the bit duration.

WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1461
TABLE IASSUMPTIONSUSED IN THIS PAPER
The input signal of the receiver is
(1)
where
(2)
(3)
is the information bit vector, is a positive integer, is theenergy per bit, is white Gaussian noise with double-sidedpower spectral density , and the index denotes signalinginterval (i.e., ).
In this paper there are a number of assumptions and some ofthem will be justified in later sections. In Table I we list all theseassumptions.
From now on we assume Assumptions 1, 2, 3, and 4 are trueand the noise is additive white Gaussian (AWGN). These as-sumptions are given with no further justification.
The sampled output of a bank of matched filters is [38]
(4)
where
(5)
(6)
(7)
(8)
, is a identity matrix , thesuperscript denotes matrix transpose, is the matched filteroutput noise vector with autocorrelation matrix given by
(9)
and is the correlation matrix. The thelement of is
(10)
If is positive-definite and symmetric, we can find a lowertriangular matrix which satisfies by Choleskydecomposition.
If the whitening filter , given in [14], [37], is appliedto the sampled output of the matched filter, the output vector is
(11)
where
(12)
and
(13)
is a white Gaussian noise vector with autocorrelation matrix.
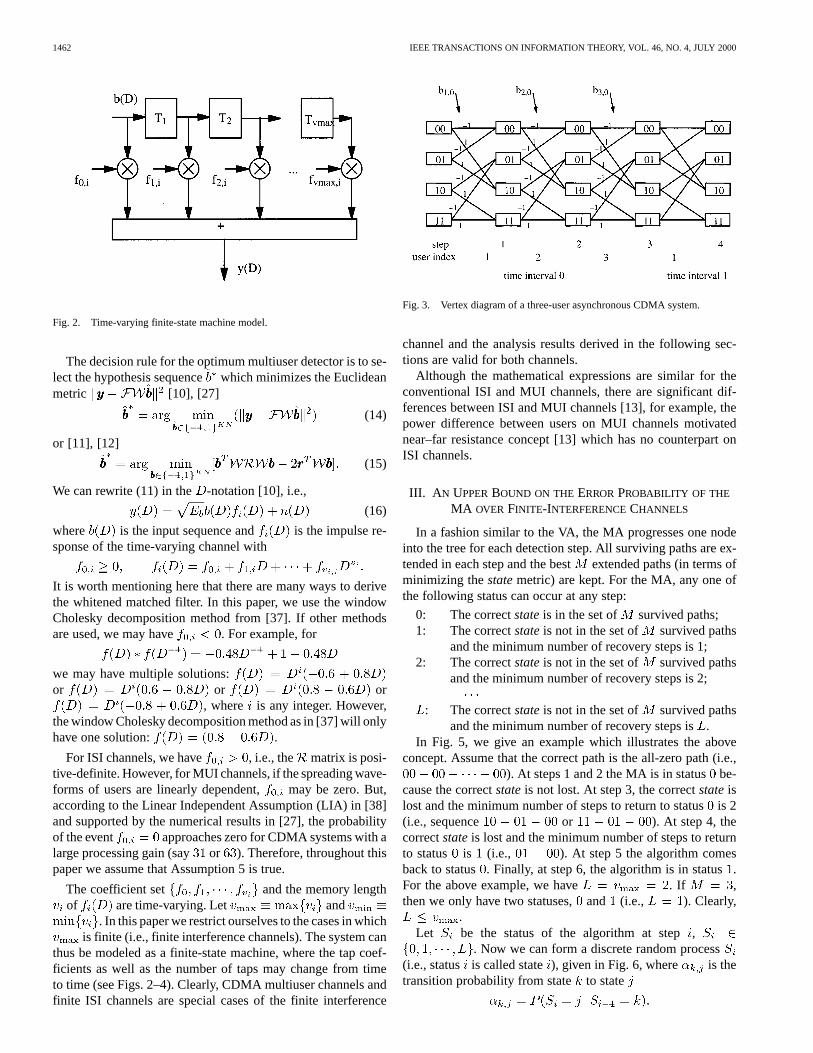
1462 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
Fig. 2. Time-varying finite-state machine model.
The decision rule for the optimum multiuser detector is to se-lect the hypothesis sequencewhich minimizes the Euclideanmetric [10], [27]
(14)
or [11], [12]
(15)
We can rewrite (11) in the -notation [10], i.e.,
(16)
where is the input sequence and is the impulse re-sponse of the time-varying channel with
It is worth mentioning here that there are many ways to derivethe whitened matched filter. In this paper, we use the windowCholesky decomposition method from [37]. If other methodsare used, we may have . For example, for
we may have multiple solutions:or or or
, where is any integer. However,the window Cholesky decomposition method as in [37] will onlyhave one solution: .
For ISI channels, we have , i.e., the matrix is posi-tive-definite. However, for MUI channels, if the spreading wave-forms of users are linearly dependent, may be zero. But,according to the Linear Independent Assumption (LIA) in [38]and supported by the numerical results in [27], the probabilityof the event approaches zero for CDMA systems with alarge processing gain (say or ). Therefore, throughout thispaper we assume that Assumption 5 is true.
The coefficient set and the memory lengthof are time-varying. Let and
. In this paper we restrict ourselves to the cases in whichis finite (i.e., finite interference channels). The system can
thus be modeled as a finite-state machine, where the tap coef-ficients as well as the number of taps may change from timeto time (see Figs. 2–4). Clearly, CDMA multiuser channels andfinite ISI channels are special cases of the finite interference
Fig. 3. Vertex diagram of a three-user asynchronous CDMA system.
channel and the analysis results derived in the following sec-tions are valid for both channels.
Although the mathematical expressions are similar for theconventional ISI and MUI channels, there are significant dif-ferences between ISI and MUI channels [13], for example, thepower difference between users on MUI channels motivatednear–far resistance concept [13] which has no counterpart onISI channels.
III. A N UPPERBOUND ON THE ERRORPROBABILITY OF THE
MA OVER FINITE-INTERFERENCECHANNELS
In a fashion similar to the VA, the MA progresses one nodeinto the tree for each detection step. All surviving paths are ex-tended in each step and the bestextended paths (in terms ofminimizing thestatemetric) are kept. For the MA, any one ofthe following status can occur at any step:
0: The correctstateis in the set of survived paths;1: The correctstateis not in the set of survived paths
and the minimum number of recovery steps is 1;2: The correctstateis not in the set of survived paths
and the minimum number of recovery steps is 2;
: The correctstateis not in the set of survived pathsand the minimum number of recovery steps is.
In Fig. 5, we give an example which illustrates the aboveconcept. Assume that the correct path is the all-zero path (i.e.,
). At steps 1 and 2 the MA is in statusbe-cause the correctstateis not lost. At step 3, the correctstateislost and the minimum number of steps to return to statusis 2(i.e., sequence or ). At step 4, thecorrectstateis lost and the minimum number of steps to returnto status is 1 (i.e., ). At step 5 the algorithm comesback to status . Finally, at step 6, the algorithm is in status.For the above example, we have . If ,then we only have two statuses,and (i.e., ). Clearly,
.Let be the status of the algorithm at step,
. Now we can form a discrete random process(i.e., status is called state), given in Fig. 6, where is thetransition probability from state to state

WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1463
Fig. 4. Vertex diagram of a four-user asynchronous CDMA system.
Fig. 5. Survived vertices for a three-user asynchronous CDMA system, in which we assume that the correct path is the all-zero path andM = 2.
Fig. 6. State-transition diagram ofS process.
The transition from state to any other state represents the cor-rect stateloss (CSL) event and the probability of correctstateloss (denoted as ) is equal to . Letthe term “recovery” denote the process whereby the algorithm
moves from nonzero states back to the zero state. Statecanonly be reached by statethrough states and. Process is not a Markov chain [31], [32]. However, we can
model process as a Markov process with a large state space (a

1464 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
Fig. 7. State-transition diagram of a reduced process.
typical example can be found in [46], [47]). Such a large-scaleMarkov process is often too complicated to deal with, however,we may find a simple and appropriate Markov process whichcan bound the error probability of the MA from above.
In the next section we study the process for time-invariantinterference channels.
A. Time-Invariant Interference Channels
In this section, assume the processis stationary. This isjustified in Appendix A. The error probability for the MA canthen be computed as
(17)
where is the error probability of the information bit asso-ciated with the transition path from stateto state and
, is the steady-state occupancy probability of statefor process . Since , andreplacing by for all , except ,we have
(18)
By replacing the transition from stateto state for , bythe transition from state to state , the above process (givenin Fig. 6) can be further simplified to the process givenin Fig. 7. Let be the steady-state occupancy probability ofstate for the reduced process . We can now obtain an errorprobability bound based on the process.
Proposition 1: If Assumption 6 is true, the bit-error proba-bility of information bits for the MA satisfies
(19)
Proof: According to (18), it suffices to show .Since the Markov chains ( and ) are stationary, we have
(20)
The proof now proceeds by contradiction. Assuming ,since
and
we have .Letting for , we obtain
(21)
Thus
which contradicts the fact that . (Q.E.D.)
We noted that process , similar to the processes in [31]and [32], was used for decision feedback detection. The majordifferences are as follows. The states are defined differently. In[31], the process took account of the case of ISI channels withinfinite length, while the process in this paper is only validfor finite-interference channels. Furthermore, no erroneous de-cision of information bits will be made if the transition is fromstate to for or from state to state for theprocesses in [31] and [32], while in our case, an erroneous de-cision could be made for these transitions. For example, in Fig.5, at steps 1, 2, and 5, the final survived paths could be paths
, , or , respectively. Thus for these tran-sition paths the MA, with , can still make an erroneous

WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1465
decision about the information bit. The parameters weretherefore introduced to take into account the probability of er-roneous decision associated with these transitions.
It may be very difficult to exactly determine the probabilitiesand . However, if we obtain bounds on these prob-
abilities, then we can still bound from above as in (19) aswe will now show.
Proposition 2: If a set of probabilities, forand satisfy
for (22)
and (23)
then
(24)
where is the steady-state occupancy probability of stateforthe reduced process in which all transition probabilitiesare replaced by .
Proof: Similarly to [31], we have
(25)
for
(26)
(27)
(28)
Then we obtain
(29)
Replacing by , we obtain . Inequality (24) followsdirectly. (Q.E.D.)
This proposition seems trivial. But it is not, since the Markovprocess is a dynamic process and bounds on transition probabil-ities may not necessarily always result in a bound on error prob-ability. This proposition shows that an upper bound on the BEPcan be obtained for conventional finite ISI channels if boundson several transition probabilities satisfies (22) and (23). In thenext section, we show that similar results are also true for time-variant interference channels.
B. Time-Variant Interference Channels
For time-variant finite interference channels is nonhomo-geneous and nonstationary. In general, the average error proba-bility of the MA is then
(30)
Following the steps of (18), we then have
(31)It is extremely difficult to deal with time-varying stochastic
processes [41]. However, through the following analysis we gainsome insight into the problem.
In the following proposition, we show that a process like thatgiven in Fig. 7 (but with different transition probabilities) canalso be used to obtain an upper bound on for time-variantinterference channels.
Proposition 3: The error probability of information bits forthe MA over time-variant interference channels can be boundedfrom above by
(32)
where is the state occupancy probability of stateofthe process given in Fig. 7 at step, in which and
is replaced by which is the transition prob-ability from state to state when the decision feedbackdetector is used.
Proof: Following the method of [40], if we modify theMA by adding a constraint which forces the system to havemore decision errors, then the error probability of the MA can bebounded from above by that of the algorithm with the constraint.The constraint we impose is that the MA switches to the DFDalgorithm, starting with the occurrence of an initial transitionfrom state to state and ending when the system comes backto state for the first time. After the system comes back to state
for the first time, it switches back to the MA. The recoveryof the MA with can be achieved if any of individualpaths lead to the correctstate, while the DFD algorithm can onlyfollow one path. Thus the MA with is more likely to findthe correctstatethan the DFD algorithm. Since the recovery ofthe MA with is faster than the DFD algorithm, the errorprobability of the MA is bounded from above by that of the al-gorithm with the constraint, which is further bounded by theright-hand side of (32). (Q.E.D.)
In order to proceed we need a lower bound on the transitionprobabilities or .
C. Bounds on Transition Probability and RecoveryAnalysis
Although the probabilities are difficult to determineexactly, the following proposition provides a lower bound on
.
Proposition 4: For the MA on finite length interferencechannels
for for the time-invariant channel
for and all
for the time-variant channel(33)

1466 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
Fig. 8. State-transition diagram for recovery analysis.
The proof can be found in Appendix B.
Proposition 4 shows that transition probabilities forany finite length interference channel are bounded from belowby . For time-invariant channels, substituting ,we obtain
According to (24), the BEP is then bounded by
(34)
For the time-variant case, we could not compute steady-stateprobability . Thus we have to find a different way to obtainan upper bound on .
Let us consider now an error burst length statistic, the meanrecovery step number (MRSN), defined as the average numberof steps from the occurrence of an initial transition from stateto state to the instance when the system comes back to stateat the first time. Fig. 8 shows the state diagram for recovery anal-ysis. In Proposition 5, we will present an upper bound (called anerror propagation factor) on the MRSN for the time-invariantand time-variant channels.
Proposition 5: The MRSN is bounded by
MRSN (35)
where the error propagation factor is given by
for time-invariant casesfor time-variant cases
(36)
Proof: For time-invariant systems, following the proce-dure in [32], we have
MRSN (37)
For time-variant systems, when the transition from statetostate occurs (say at step), the state occupancy probability
vector is . Let denote the probabilityof the transition from state to state at step . We then have
MRSN
Obviously,
for
(38)
Since (Proposition 4) and forand , we have
(39)
In order to obtain an upper bound for the MRSN, we introducea new set
for
for
otherwise(40)
Since satisfies
and
for (41)
it is easy to show that
MRSN
(Q.E.D.)

WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1467
Proposition 5 shows that for time-variant systems the errorpropagation factor, which is an upper bound on the MRSN, isabout times larger than that for time-invariant systems.
Substituting in (37) into (34) and , wehave
(42)
For time-variant systems, based on the process in Fig. 7, wehave analogously
(43)
Letting
and
we then have
(44)
for time-variant systems, which is identical to (42).In general, it is difficult to compute the exact values of
and , but if we can establish two upper-bound values onthem (say and ), then the upperbounds given in (42) and (44) can be further simplified to
(45)
Clearly, if , then the bound is essentially de-termined by the correctstate loss probability and if
, then the bound is determined by the average errorprobability given that the correctstateis not lost. Note that both
and are functions of . When .When is equal to the number of states, and
, where denotes the BEP of the VA.
D. Correct State Loss Probability and
In this section we first study some bounds and then .The correctstate loss probability has been well studied in
[17], [18], [20], [34], and [36]. In this paper, we will extend thework of [18], [20], [34] to interference channels.
Consider an MA decoder starting from time slot andending at time slot . Assume that the received sequence is
and the transmitted sequence is . Let be aset of paths, i.e.,
and be the largest radius of a sphere with centersuch that the number of paths fromin the sphere is less
than or equal to . Define the normalized minimum distanceof (calledlist minimum weightin [34])
(46)
Thus the correctstatewill not be forced outside the survivedpaths, if is within a sphere with center and ra-dius for all . In the other words, the correctstateloss proba-
bility for a given set is bounded from above by ,
where
When contains paths, it is easy to show that
(47)
where is the normalized and squared Euclidean distance, i.e.,
Now we can prove the following proposition based on theForney method in [10].
Proposition 6: The probability of CSL is bounded by
(48)
where
for time-invariant cases
for time-variant cases(49)
and
(50)
denotes the Hamming distance,denotes the set whichcomprises all sets of , and comprises all sets of whichending at time slot.
Proof: The subevents determining the occurrence of cor-rectstateloss for a given set are
: At step the sequences start to diverge.: Set is comprised of allowable paths (see [10] for
the definition of allowable sequences).: There are paths survived from step to .: The likelihoods of the error paths are greater than the
likelihood of the correct path at step.
The probability of subevent is
(51)

1468 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
Subevent is independent of all other subevents and
(52)
Therefore, an upper bound on can be obtained by
(53)
Finally, applying the union bound technique over allsets andputting (52)–(53) together, we have the upper bound of (48).(Q.E.D.)
Now we derive an upper bound on . An error event isdefined in the traditional way such that it starts when the errorpath differs from the correct path and ends when the two pathsagree again for the first time. Letbe the set of all error events.
In Proposition 7, we show that is bounded by the sumof the Forney upper bound for the BEP of the VA and an upperbound related to the correctstateloss event.
Proposition 7: satisfies
(54)
where
for time-invariant cases
for time-variant cases(55)
for time-invariant cases
for time-variant cases
(56)
and are the Hamming distance of input bit sequencesand the normalized and squared Euclidean distance of errorevent , respectively, and denotes the maximum Ham-ming distance between the correct input bit sequence and one ofthe error sequences in .
Proof: Similarly to the VA, the MA progresses one nodeinto the trellis for each detection step. All surviving paths areextended in each step. Unlike the VA, of the MA with lessthan the total number ofstates, only the best nonmergingpaths (in terms of maximizing the likelihood) are kept. Thus thecorrectstatecan be lost before time slot . Let denote theevent that the correct path is not lost from stepto stepbut is lost at step and denote the event that the correct pathis lost at one of the steps from to . Obviously,
, where and are the error
probabilities of the information bit associated with the transitionfrom state to state given events and , respectively. Thuswe only need to find and to obtainan upper bound on .
Since the correct path and the error path can be lost beforethey merge, the subevents which determine the occurrence ofan error event are
: At step the error event starts.: The error event is allowable.: The error path survives from step to step .: The likelihood of the error path is greater than the likeli-
hood of at least paths in all extended paths atstep . (In the other words, the error path will survive atstep .)
: The correct path survives from step to step .: The correct path is lost at one of the steps fromto .: The likelihood of the error path is no less than that of the
correct path at step .
The probability of the occurrence of this error event is then
(57)
where the first and the second terms are the probabilities of theerror event given events and , respectively. For , we have
(58)
Applying the method in [10] over all error events, we have (55).To analyze , it is not sufficient to consider only a
single error event, since the likelihood of the correct path mustbe compared with the likelihoods of all other paths. Wemake use of again. For a given , since is independent of
, we have
(59)
where is the Hamming distance between the correct se-quence and the final survived sequence and we make use of theknown fact that . Applying the technique in[10] again, we have (56). (Q.E.D.)
It is worth mentioning that for we have .Since only one path can be kept, the suberror eventsand
never happen simultaneously, thus . Since thecorrect path is the only survived path, we have .
Substituting the results of (48) and (54) into (45), our upperbound becomes
(60)
Clearly, the correctstateloss event causes two types of bit er-rors. The first type is the erroneous decision on previous bitsdue to tracing back from an erroneous path. The second is theerroneous decision on consequent bits due to error propagation.
In the next section, we will draw a useful general conclusion,especially for channels satisfying mild conditions, the asymp-

WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1469
totic performance of the MA is identical to the Viterbi algorithmif
where is the minimum squared Euclidean distance, i.e.,
(61)
IV. A SYMPTOTICBEHAVIOR OF THEUPPERBOUND IN (60)
To study the asymptotic behavior, we need to study the con-vergence of the three term in (60), or the bound series (49),(55) and (56). For time-invariant cases, Forney showed in [10](proven by Foschini in [39]) that for , the boundgiven in (55) is convergent and the error probability of the VAis bounded by
(62)
where and are two constants. In [12], Verdú showedthat if a multiuser interference channel satisfies certain con-ditions, the BEP of the VA for the multiuser system can bebounded in the same fashion as (62) (replacing by ,i.e., the minimum Euclidean distance of user). In the followingproposition we follow the procedure in [39] and show that theBEP of the VA can be bounded in the same fashion as (62)when , if Assumption 5 is true (i.e., for
).
Proposition 8: If Assumption 5 is true, then the BEP of theVA (i.e., ) for the finite interference channel is bounded by
(63)
Proof: Since the proof is very similar to that in [10] and[39], we only present a sketch.
Analogous to the steps taken by Forney [10], we can rewritethe upper bound of (54) in the format identical to that in [1], i.e.,
(64)
where is the set of all possible and for each andis the subset of error events for which . Following thesteps of [39] and replacing in [39] by the vector
and in [39] by
where denotes inner product and the minimum is definedover all possible nonzero vectors that are notorthogonal to (i.e., ), it is then easily shown that theForney bound series of (64) converges if
Further, following the procedure in [39], we can show that thebound series converges to the right-hand side of (63) where
(65)
The left-hand side inequality of (63) can be obtained analo-gously to the method in [40]. (Q.E.D.)
The above proposition shows that for time-variant interfer-ence channels, the Forney bound series is also convergent if thecorrelation matrix is nonsingular.
Since the series given in (48) is bounded from above by thatin (56), we only need to show the convergence of the series in(56). It is difficult to prove the convergence of the series givenin (56) for arbitrary finite interference channels. However, for achannel which satisfies Assumption 7, we can show the seriesis convergent.
Proposition 9: If a channel satisfies Assumption 7, we have
(66)
where
and is a subset of for which .Proof: Without loss of generality, let us study the
set, i.e., all paths start from and end at . For, we have
(67)
where is the set of paths starting from step andending at step .
For a set there is at least one pair of paths in theset which does not merge from step to . Therefore, theHamming distance between the two input bit sequences is noless than , i.e., . Also wehave and the squared Euclidean distance be-tween the two paths is then no less than , where
is the maximum interval in which at least a pair of paths hasno Euclidean distance increment. Since is no less than themaximum squared Euclidean distance between any two vertexsequences in the set (see (47)), we have .

1470 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
Replacing by its upper bound ,we have
(68)
where
The total number of possible paths from stepsto is. The total number of sets of paths which can
be formed is , since each element in a set of pathscould be the correct sequence. The number of possible sets in
is then no larger than
Now, we have
(69)
If , the series onthe right-hand side of (69) is convergent. Clearly, the convergentregion is nontrivial, if Assumption 7 is true.
The rest of the proof is identical to [39, Proof (2)] and hastherefore been omitted. (Q.E.D.)
We could find a channel which does not satisfy Assumption 7.For example, . But in practice, many chan-nels satisfy Assumption 7. A simple algorithm similar to thatin [45] can be used to check whether a channel satisfies As-sumption 7. Through simulation we examined MUI chan-nels with binary random codes of length. We did not en-counter any channel which did not satisfy Assumption 7. Forconvolutional codes, Assumption 7 simply means that there isno infinite-length codeword with finite weight. Assumption 7is a sufficient, but not necessary condition for noncatastrophiccodes. Noncatastrophic codes which have some infinite-lengthcodewords with finite weight but corresponding to finite-weightinformation sequences will not satisfy Assumption 7. Further-more, if the short packet transmission is used, Assumption 7 isvalid for all codes and all channels.
For the channels satisfying Assumption 7, the MA withhas the same asymptotic behavior as the VA
(proven in the following proposition). Thus it is referred to asthe asymptotically optimal MA.
Proposition 10: If a channel satisfies and, then is bounded by the same upper and lower bounds
which bound the error probability of the VA, i.e.,
(70)
Proof: Let
According to the upper bound of (60), we have
Since the MA is nonoptimal and the VA is optimal, we havefor any . Therefore, (70) is true. (Q.E.D.)
If we can find a minimum value of (say ) which satis-fies , then the MA kept paths are asymp-totically optimal. An efficient algorithm to compute can befound in [30]. For multiuser systems [27], [37] and for many ISIchannels [18], is often much smaller than the total numberof vertices and the MA with a small can achieve near-op-timum performance.
There are two important factors which make the MA so at-tractive for finite-length interference channels. One is that formany interference channels the MRSN is bounded (i.e., the MAcan recover from error propagation within a finite number ofsteps [18]). The other is that the minimum ED is reasonablysmall , thus is often a small number. However, whenthe MA is applied to decode error-control codes, we often findthat the MA does not provide good performance, even with alarge value of [18], except when using systematic feed-for-ward codes [19]. This is due to the following two reasons: a)for powerful codes is a large value and b) recovery forerror-control codes could be much more difficult than that forinterference channels. We might improve the error performanceof the MA by using error-control codes with a good recoverycapability or modifying the structure or the algorithm to over-come error propagation. This is, in fact, the starting point for therest part of the paper.
V. PROPERTIES FORNEAR-OPTIMAL DECODING
Consider a rate convolutional code with memory length. The input bit sequenceis grouped and fed into the encoderbits at a time. The encoder then producesbits at each slot,
say . After that, the transmitter maps the bit into aBPSK signal and transmits the signal over an AWGN channel,i.e., . After the matched-filter receiver,we obtain a sequence of sampled valueswhere , where is a zero-mean independentGaussian variable with variance . Clearly, the concepts oferror event , set and associated parameters , , ,
, , , and are still valid here. So do themain results of (54)–(60), if we replace by . In the

WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1471
coding literature of a convolutional code, defined in (61),is called free distance of the code, denoted as . Now letus study properties of the minimum list weight . We willfocus on rate codes.
A. Minimum for Near-Optimal Decoding
Bounds on the list minimum weight and the correctstateloss probability were given in [34] for binary-symmetric chan-nels (BSC). Similar work was reported in [17], [18], and [20].In [36], the vector Euclidean distance (VED) concept was in-troduced to compute the correctstateloss probability. In [30],we presented an algorithm to compute the correctstate lossprobability for finite interference channels. However, we foundthe algorithm described in [30] is too complicated to computethe correctstateloss probability for convolutional codes when
on a standard computer. In this section, we will studythe problem from a different angle. The method used here issimilar to that for the first symbol decoder in [17], [18], [34],and [36].
Proposition 11: For rate codes, if , then, for .
Proof: Supposing that the all-zero path is transmitted,starting from time and ending at time. The received path isthen , where . Clearly,after extension of steps, the number of surviving paths reaches
. According to the MA, we can only store (i.e., )paths. Thus at step, we have to delete one path, which couldbe the correct one and cause correctstateloss event.
Let denote the transmitted bit sequenceof the th path of a total of paths (i.e., ). Let
be theHamming weightof the set, defined as the numberof nonzero columns in the matrix
(71)
It is easy to show that and
(72)
Finally, according to (47), we obtain
(Q.E.D.)
The above proof shows the following results.
a) By increasing the column distance function (CDF), we canincrease , where the CDF at stepis defined in [42]as
b) The early growth of the column distance function is im-portant for minimizing the correctstateloss probability(it was shown in [19] from a different angle).
c) is upper-bounded by , which approximatelyequals .
In the pervious section we have shown that ifand error propagation is not severe (i.e., is a small
number), then the MA is near-optimal for asymptotical cases.Thus we can state the following corollary.
Corollary: If error propagation is not severe (i.e., is asmall number), then in the asymptotic case a code with
can be near-optimally decoded by an MA decoderwith .
Proof: For asymptotically optimal decoding, we need. If a code has , then
and . (Q.E.D.)
Consider the rate codes listed in [42, p. 330]. If the VA isused, the number ofstatesis . The value of is roughlyproportional to for large . Thus if we find a structure thateliminates error propagation, then the MA with isable to approach the error performance of thestateVA. Inother words, we can achieve near-optimal decoding with
, i.e., a square-root complexity saving can be achieved. Asimilar conclusion can be found in [20], [36]. But the formu-lation in the present paper allows us to make further progresson the problem. For example, the above result shows that thereis no case in which we can achieve asymptotically optimal de-coding with .
B. Minimum for Near-Optimal Decoding
In the VA and the MA, some highly unlikely paths can bedeleted without sacrificing error performance. The-algorithmwas proposed by Simmons [28] to cut those highly unlikelypaths. In the -algorithm, all extended paths whose metric iswithin a fixed threshold of the best path metric are storedin memory. The following proposition shows the existence ofa minimal (say, ) which guarantees that for asymptoticcases the correctstateloss probability of the -algorithm with
is less than the error probability of the VA. In the fol-lowing analysis thelist minimum weightconcept is used.
Proposition 12: The asymptotic correctstateloss probabilitywill be no larger than
if (73)
Proof: Let be the distance betweenthe th and th paths in a set of paths . Suppose thatthe all-zero path is transmitted.
If
is true for any , then the correct path will belost. This condition is equivalent to
for
(74)

1472 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
Fig. 9. A recovery instance for the MA.
Let , which is a Gaussian variable with zero meanand variance . The correctstateloss probability due to path
is then
path
(75)
Therefore, if
then the asymptotic correctstate loss probability is no larger
than . Since , we have
(76)
Therefore, if , then
(Q.E.D.)
Clearly, in (73) is a simple choice in practice. The-al-gorithm with (strictly we say that must be equal to
where is an arbitrary small positive value) is asymp-totically optimal for all codes.
VI. HIERARCHICAL DECODING
In this section, we will study near-optimal decoding for shortpackets (typically a few hundred bits). The packet starts from aknownstate(say ) and ends at a knownstate(say ). Thus thedecoding procedure can start from both ends of the packet.
A bidirectional decoding algorithm was first proposedby Forney [48]. Bidirectional algorithms were applied inconstructing convolutional codes [49], [50] in the 1970’s. Inthe 1990’s, the bidirectional algorithm has been applied todecoding the information transmitted in a packet format [9],[29]. In this section we will present a hierarchical decodingalgorithm.
First, we present a bidirectional, nonsorting, and combinedalgorithm.
The Bidirectional, Nonsorting, and Combined -Algorithm.
Step 1) Initialize the decoders at both ends of the packet.Step 2) Advance each decoder until each keeps paths.Step 3) Select paths with smallest metrics from all ex-
tended paths. If the number of surviving extendedpaths is less than , select all extended paths.
Step 4) Evaluate each decoder’s probability of having thecorrect path in its surviving paths. This is done bycomparison between a) the maximum metric differ-ence among the paths kept in the decoders if bothdecoders keep paths, or b) the number of pathskept in the decoders if the number of paths kept inone of the decoders is less than.
Step 5) Advance the decoder with the highest probabilityof containing the correct path and keep the pathswhose metrics are within a fixed threshold (i.e.,
) of the best pathmetric.
Step 6) Go to Step 3) until all bits in the packet have beendecoded.
Step 7) Join the sequence and recover the packet.
The algorithm is largely based on the bidirectional MA [29].A few modifications are made: a) replacing “sorting” by “selec-tion” [17], which can significantly cut down the computationtime for a large value of ; b) the -algorithm has been usedto cut down the average complexity.
As shown in the previous section, andare needed for asymptotically optimal decoding of
a code. Thus the peak complexity could be very large. For ex-ample, to near-optimally decode a code with , we

WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1473
TABLE IIVALUES OFd AND D FOR THETHREE SYSTEMS
need an MA decoder with . However, the averagedecoding complexity might be further cut down.
The key observation is that not all packets are corrupted bystrong noise components. If the packet is corrupted by strongnoise components, there is probably nothing we can do exceptuse a more complicated decoder. But, those packets which arenot corrupted by strong noise components, may be successfullydecoded by a low-complexity decoder.
Since two decoders are used in the bidirectional algorithm,it is obvious that if both decoders fail to join naturally, thenthe decoders know that at least one decoder has lost the correctstate. Thus the natural joint event can be used as an indicator towhether the packet has been decoded correctly.
The Hierarchical Decoding Algorithm (HDA):Step a): Preset a set of allowable number of paths to be
kept. For example, we can set. This set represents the allowable complexity
of the decoder. For a particular design, the particularset chosen can be optimized.
Step b): Decode the packet based on the nonsorting bidirec-tional MA with the smallest number of paths (i.e.,
) first.
Step c): Check whether the natural joint event occurs.
Step d): If the natural joint event does not occur, repeat Stepsb) and c) based on the algorithm with the secondsmallest number of paths (e.g., for theabove example). Repeat this process until reachingthe maximum allowable complexity (e.g.,
).
Step e): If the natural joint event occurs at Step c), the de-coder decodes the packet based on the MA [16],[29].
Step f): If the natural joint event does not occur and the de-coder reaches the maximum complexity, then bothdecoders decode the packet by tracing back, fol-lowing the paths with minimum metrics.
Obviously, if the natural joint event is at a correctstate, thenthe decoder makes a correct decision. However, if the naturaljoint event is at astatewhich is not the correct vertex (called afalse joint), then the decoder will make a wrong decision. Whenthe number of paths kept is a large fraction of the total number ofstates, the false joint event will often happen, therefore the aboveindication method will suffer. Consequently, some simple linearblock codes such as parity check or cyclic codes can be used toeliminate the false joint event. When the number of paths kept
is a very small fraction of the total number ofstates, the aboveindication method will perform extremely well.
VII. N UMERICAL RESULTS
A. Interference Channels
In this section, we study three systems: a) an ISI channelwith ,
, b) the four-user synchronous CDMA system given in[14, Example 2], c) the four-user asynchronous CDMA systemgiven in [15, Example 4]. For all cases, the optimum detector isthe eeight-stateVA detector.
It is difficult to compute the exact upper bounds of (49), (55)and (56) which cover the whole distance spectrum. In practice,we often compute an approximated upper bound based on a par-tial distance spectrum up to a threshold. Since we have provedthat all bounds are convergent, the approximated upper boundsare close to the true bounds in a high region. A total of
simulations or 500 bit errors were used as a stop criterionfor each simulation point.
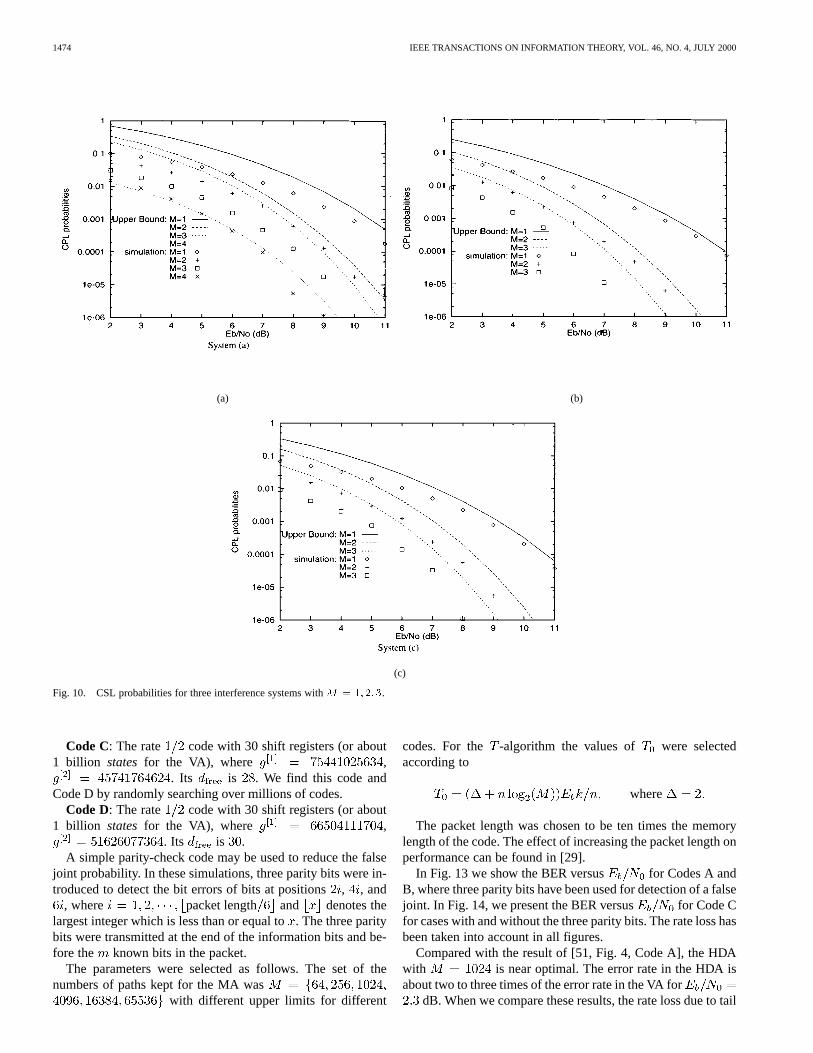
Using the method in [30], we can compute the values ofand , listed in Table II, for the above systems. Clearly,
, for systems a), b) and c), respectively, wheredenotes the minimum value of which has . InFig. 10, we present as a function of bit energy to noise ratiofor the MA. In Fig. 11, we show as a function of .Clearly, these bounds are reasonably tight.
In Fig. 12, we show the bit-error probability of the MA as afunction of . The figures show that for , theupper bounds could be very loose due to the fact thatis theupper bound for all interference channels, thus for a particularchannel it can be very loose. However, all figures show that for
, the upper bounds are tight at large . This isdue to the fact that when , is the dominating termin the upper bound.
B. Decoding Convolutional Codes
In this section we present simulation results for four ratehalf convolutional codes. The codes used in this section are asfollows:
Code A: The rate code with 14 shift registers (orstates), where (in octal
form as shown in [42, Table 11.1(c)]). Its is .Code B: The rate code with 25 shift registers (or
states), where, and its . This code is listed in Table II,
[43].
1474 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
(a) (b)
(c)
Fig. 10. CSL probabilities for three interference systems withM = 1; 2; 3.
Code C: The rate code with 30 shift registers (or about1 billion states for the VA), where ,
. Its is . We find this code andCode D by randomly searching over millions of codes.
Code D: The rate code with 30 shift registers (or about1 billion states for the VA), where ,
. Its is .A simple parity-check code may be used to reduce the false
joint probability. In these simulations, three parity bits were in-troduced to detect the bit errors of bits at positions, , and
, where packet length and denotes thelargest integer which is less than or equal to. The three paritybits were transmitted at the end of the information bits and be-fore the known bits in the packet.
The parameters were selected as follows. The set of thenumbers of paths kept for the MA was
with different upper limits for different
codes. For the -algorithm the values of were selectedaccording to
where
The packet length was chosen to be ten times the memorylength of the code. The effect of increasing the packet length onperformance can be found in [29].
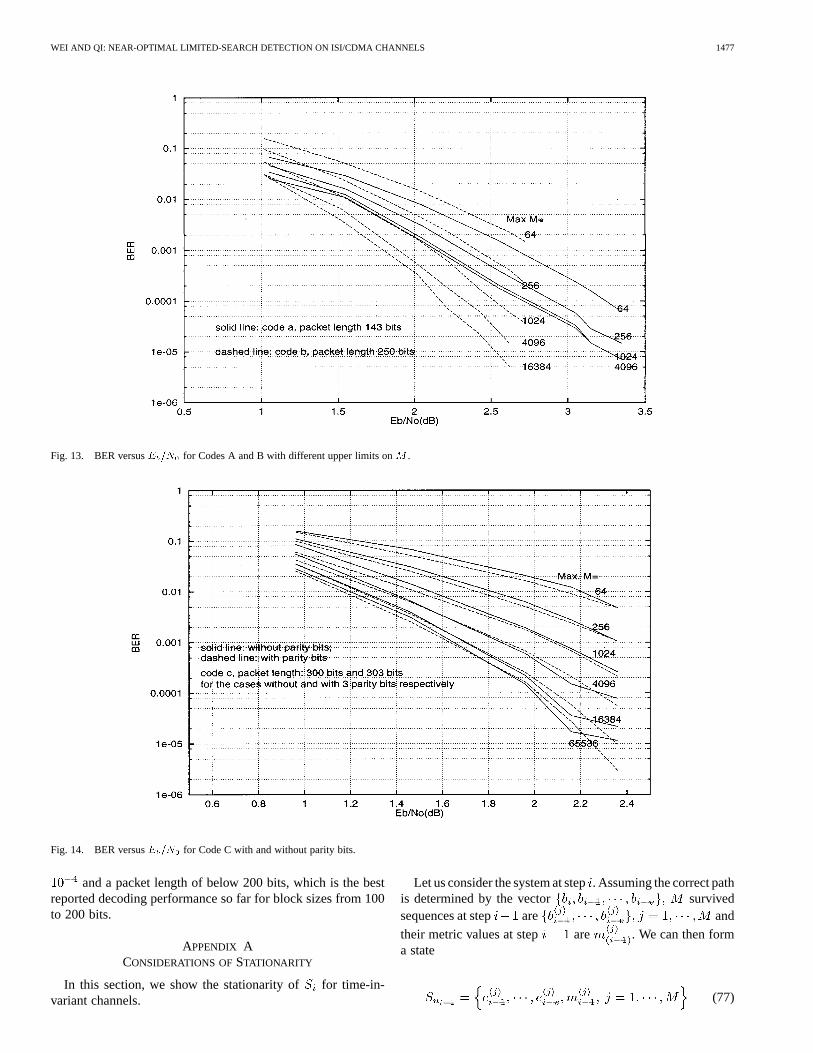
In Fig. 13 we show the BER versus for Codes A andB, where three parity bits have been used for detection of a falsejoint. In Fig. 14, we present the BER versus for Code Cfor cases with and without the three parity bits. The rate loss hasbeen taken into account in all figures.
Compared with the result of [51, Fig. 4, Code A], the HDAwith is near optimal. The error rate in the HDA isabout two to three times of the error rate in the VA for
dB. When we compare these results, the rate loss due to tail

WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1475
(a) (b)
(c)
Fig. 11. Probabilities of� for four systems.
and parity bits (0.55 dB) needs to be considered. The secondevidence which shows the near optimality of the HDA is thatwhen reaches , the bit error rate will not reduce sig-nificantly even if we further increase .
Figs. 15 and 16 show the average complexity (in terms ofaverage number of paths kept in the decoding procedure) andthe percentage of time for which each decoding procedure isused, respectively.
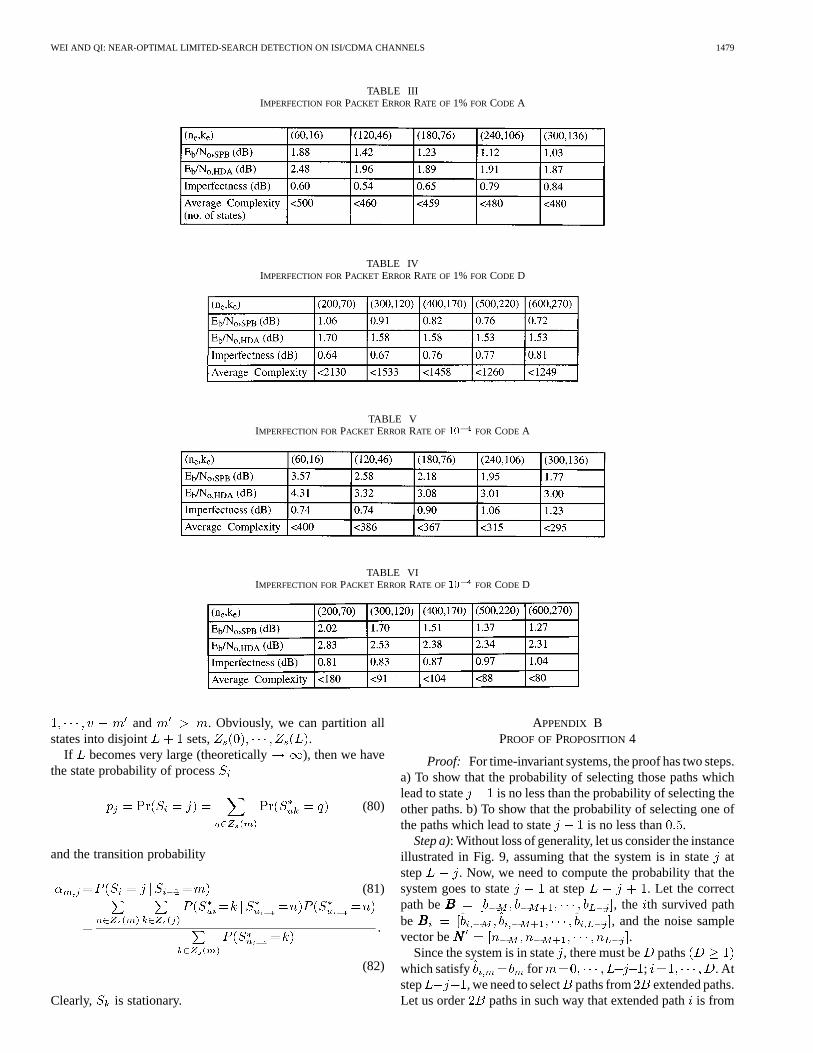
In Tables III–VI, we present the imperfections of the HDfor packet error rates of 1% and . Imperfection is definedas the difference between and , where
and denote required for a givenpacket error rate based on the sphere-packing lower bound[52] and based on simulations for the HDA, respectively.Codes A and D are decoded by the HDA with
, respectively. The resultsshow that the HDA is about 0.8 dB away from the bound for ablock size of less than 200 information bits. Thus the HDA can
achieve the best possible decoding performance known so farfor block sizes of from 100 to 200 bits.
VIII. D ISCUSSION ANDCONCLUSION
We have studied an upper bound on the BEP in breadth-firstlimited-search detection over a finite interference channel. Aunified channel model has been given, which includes finite-length intersymbol interference channels and multiuser CDMAchannels as two special cases. We have shown that the BEP canbe analyzed by a discrete random process. We have also shownthat error propagation (in terms of the MRSN) is finite for allfinite-length interference channels.
The error probability of the information bit of the MA can bebounded by the sum of three terms: the Forney upper bound onthe error probability of the VA detection, and two upper boundsrelated to the correctstateloss event. The correctstateloss eventcauses two types of erroneous decision: erroneous decision on

1476 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
(a) (b)
(c)
Fig. 12. BER upper bounds as a function ofE =N for all three systems.
previous bits due to tracing back from a wrong path and erro-neous decision on consequent bits due to error propagation. Theerror probabilities of the two types of erroneous decision can bebounded by two upper bounds respectively.
The convergence and the asymptotic behavior of the upperbounds has been studied. The results show that if a channel sat-isfies mild conditions all series in the bounds are convergent innontrivial regions. One of the most important results is that forany finite interference channel, satisfying certain conditions, theasymptotic BEP of the breadth-first search algorithm is boundedby the same upper and lower bounds as those for the Viterbi al-gorithm if a) the maximum interval in which at least a pair ofpaths has no Euclidean distance increment is bounded (Assump-tion 7) and b) (i.e., the minimum list weight [34]is larger than the minimum Euclidean distance).
In practice, the MA with a very small can often performclose to the VA for finite interference channels. In [17], [18], itwas pointed out that error propagation is not significant on ISI
channels. In this paper we have shown theoretically that, on theaverage, the MA can regain the correctstatein a finite lengthfor all finite interference channels.
In this paper we further extended the above results for near-optimal decoding of long convolutional codes in short packet(about 200–300 bits) transmission. We presented a nonsortingcombined algorithm and showed that if a rate con-volutional code has good early growth of the column distancefunction, then the algorithm with and
can near-optimally decode the code. The most disap-pointed result was that no code can be near-optimally decodedby an MA with , i.e., the peak complexity is noless than . But we can further cut down the average de-coding complexity. Consequently, a hierarchical decoding algo-rithm was proposed.
The numerical results showed that the bounds are reasonablytight. The HDA can achieve a performance within about 0.8 dBof the sphere-packing lower bound for a packet error rate of
WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1477
Fig. 13. BER versusE =N for Codes A and B with different upper limits onM .
Fig. 14. BER versusE =N for Code C with and without parity bits.
and a packet length of below 200 bits, which is the bestreported decoding performance so far for block sizes from 100to 200 bits.
APPENDIX ACONSIDERATIONS OFSTATIONARITY
In this section, we show the stationarity of for time-in-variant channels.
Let us consider the system at step. Assuming the correct pathis determined by the vector survivedsequences at step are and
their metric values at step are . We can then forma state
(77)

1478 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
Fig. 15. Average complexity (in terms of the number of states kept) versusE =N for Codes B and C.
Fig. 16. Percentage time which the decoding procedures are used versusE =N for Codes B and C.
where
(78)
Let us subtract all metric values by the smallest metric andthen quantize it into levels. Now the state is simplified to
(79)
It is easy to show that is a homogenous, aperiodic,and recurrent Markov chain (i.e., an ergodic chain) with
states. Thus it is a stationary distribution on thesteady-state probability of state [44].
Let denote the set of states in which there is at leastone sequence satisfying for
and there is no sequence satisfying for
WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1479
TABLE IIIIMPERFECTION FORPACKET ERRORRATE OF 1% FOR CODE A
TABLE IVIMPERFECTION FORPACKET ERRORRATE OF 1% FOR CODE D
TABLE VIMPERFECTION FORPACKET ERRORRATE OF 10 FOR CODE A
TABLE VIIMPERFECTION FORPACKET ERRORRATE OF 10 FOR CODE D
and . Obviously, we can partition allstates into disjoint sets, .
If becomes very large (theoretically ), then we havethe state probability of process
(80)
and the transition probability
(81)
(82)
Clearly, is stationary.
APPENDIX BPROOF OFPROPOSITION4
Proof: For time-invariant systems, the proof has two steps.a) To show that the probability of selecting those paths whichlead to state is no less than the probability of selecting theother paths. b) To show that the probability of selecting one ofthe paths which lead to state is no less than .
Step a): Without loss of generality, let us consider the instanceillustrated in Fig. 9, assuming that the system is in stateatstep . Now, we need to compute the probability that thesystem goes to state at step . Let the correctpath be , the th survived pathbe , and the noise samplevector be .
Since the system is in state, there must be pathswhich satisfy for ; . Atstep , we need to select paths from extended paths.Let us order paths in such way that extended pathis from

1480 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
survived path and even paths haveand odd paths have , where denotes thelargest integer which is less than or equal to. is thenthe probability of that at least one of theextended paths (i.e.,paths ) has survived at step .
The metric of extended pathis then given by
(83)
where and for . Therefore, thedifference between metrics of pathand is
(84)
where
and
We are then able to compute the probability
(85)
i.e., the probability of selecting path rather than path . First,let us consider the case where and
, i.e., two paths start to diverge at . Clearly, wehave for , and
. Thus
(86)
Since , ,and
(87)
where
for
for
Thus we obtain
where and (88)
That is, the possibility of selecting pathis no less than that ofselecting path .
The second case is for
and
For this case we have for , andfor at least one of . Therefore,
(89)
where
and
Since is symmetric, it is easy to showthat is a random variable with zero meanand symmetric probability density function. Since
we have
if
The above two cases show that extended pathsare more likely to survive than the other extended paths. Fol-lowing a similar procedure, we haveif and , or and ,

WEI AND QI: NEAR-OPTIMAL LIMITED-SEARCH DETECTION ON ISI/CDMA CHANNELS 1481
or and , or and.
In summary, extended path whichleads to state , is more likely to survive at step than ex-tended path . Theprobability is then no less than the probability (denotedas ) that at least one of the extended paths
has survived at step when all extended paths are equallylikely to survive (i.e., ).
Step b): For the MA, we need to select paths fromextended paths. The probability is then the minimumprobability of selecting one of the paths aspart of this selection of paths. The value of is easilycomputed as
(90)
where the th term of the right-hand side of (90) is the prob-ability that in the previous selections none of the paths
have been selected and in theth selection,one of the paths has been selected. Since
, we have , where equality holds for .For time-variant channels, since is the transition
probability from state to state of the process when thedecision feedback detector is used, the proof is identical to thatin [31] and has therefore been omitted. (Q.E.D.)
ACKNOWLEDGMENT
The authors wish to thank Dr. G. D. Forney, Jr. for manyhelpful discussions, Dr. R. C. Williamson for carefully readingthe manuscript and many suggestions, Prof. J. B. Anderson andProf. R. Johannesson for providing to us many of their closelyrelated works, Dr. R. A. Kennedy for a discussion on the re-covery problem of the DFD, and Prof. S. Verdú for a short dis-cussion on the problem during ISIT’95.
REFERENCES
[1] A. J. Viterbi, “Error bounds for convolutional codes and an asymptoti-cally optimum decoding algorithm,”IEEE Trans. Inform. Theory, vol.IT-13, no. 2, pp. 260–269, Apr. 1967.
[2] G. D. Forney Jr., “The Viterbi algorithm,”Proc. IEEE, vol. 61, pp.268–278, Mar. 1973.
[3] R. M. Fano, “A heuristic discussion of probabilistic coding,”IEEETrans. Inform. Theory, vol. IT-9, pp. 64–74, Apr. 1963.
[4] J. L. Massey, “Variable-length codes and the fano metric,”IEEE Trans.Inform. Theory, vol. IT-18, pp. 196–202, Jan. 1972.
[5] G. D. Forney Jr., “Convolutional codes III: Sequential decoding,”In-form. Contr., vol. 25, pp. 267–297, July 1974.
[6] G. D. Forney Jr. and E. K. Bower, “A high-speed sequential decoder:Prototype design and test,”IEEE Trans. Commun. Technol., vol.COM-19, pp. 821–835, Oct. 1971.
[7] F. Jelinek, “A fast sequential decoding algorithm using a stack,”IBM J.Res. Develop., vol. 13, pp. 675–685, Nov. 1969.
[8] J. L. Massey and D. J. Costello Jr., “Nonsystematic convolutional codesfor sequential decoding in space applications,”IEEE Trans. Commun.Technol., vol. COM-19, pp. 806–813, Oct. 1971.
[9] S. Kallel and K. Li, “Bidirectional sequential decoding,”IEEE Trans.Inform. Theory, vol. 43, pp. 1319–1326, July 1997.
[10] G. D. Forney Jr., “Maximum-likelihood sequence estimation of digitalsequences in the presence of intersymbol interference,”IEEE Trans. In-form. Theory, vol. IT-18, pp. 363–378, May 1972.
[11] G. Ungerboeck, “Adaptive maximum-likelihood receiver for car-rier-modulated data-transmission systems,”IEEE Trans. Commun., vol.COM-22, no. 5, pp. 624–636, May 1974.
[12] S. Verdú, “Minimum probability of error for asynchronous Gaussianmultiple-access channels,”IEEE Trans. Inform. Theory, vol. IT-32, pp.85–96, Jan. 1986.
[13] , “Demodulation in the presence of multiuser interference: Progressand misconceptions,” inIntelligent Methods in Signal Processing andCommunications, D. Docampo, A. Figueira-Vidal, and F. Perez-Gon-zalez, Eds. Boston, MA: Birkhauser, 1997, pp. 15–44.
[14] A. Duel-Hallen, “Decorrelating decision-feedback multiuser detectorfor synchronous code-division multiple-access channel,”IEEE Trans.Commun., vol. 41, pp. 285–290, Feb. 1993.
[15] , “A family of multiuser decision-feedback detectors for asyn-chronous code-division multiple-access channels,”IEEE Trans.Commun., vol. 43, no. 2/3/4, pp. 421–434, Feb./Mar./Apr. 1995.
[16] J. B. Anderson and S. Mohan, “Sequential coding algorithms: A surveyand cost analysis,”IEEE Trans. Commun., vol. COM-32, pp. 169–176,Feb. 1984.
[17] T. Hashimoto, “A list-type reduced-constraint generalization of theViterbi algorithm,” IEEE Trans. Inform. Theory, vol. IT-33, pp.866–876, Nov. 1987.
[18] J. B. Anderson and S. Mohan,Source and Channel Coding. Boston,MA: Kluwer, 1991.
[19] H. Osthoff, J. B. Anderson, R. Johannesson, and C. F. Lim, “System-atic feed-forward convolutional encoders are better than other encoderswith an M-algorithm decoder,”IEEE Trans. Inform. Theory, vol. 44, pp.831–838, Mar. 1998.
[20] J. B. Anderson, “Limited search trellis decoding of convolutionalcodes,”IEEE Trans. Inform. Theory, vol. 35, pp. 944–955, Sept. 1989.
[21] J. B. Anderson and E. Offer, “Reduced-state sequence detection withconvolutional codes,”IEEE Trans. Inform. Theory, vol. 40, pp. 965–972,May 1994.
[22] G. J. Pottie and D. P. Taylor, “A comparison of reduced complexity de-coding algorithms for trellis codes,”IEEE J. Select. Areas Commun.,vol. 7, pp. 1369–1380, Dec. 1989.
[23] M. V. Eyuboglu and S. Qureshi, “Reduced-state sequence estimationfor coded modulation on interference channels,”IEEE J. Select. AreasCommun., vol. 35, pp. 944–955, Sept. 1989.
[24] P. R. Chevillat and E. Elephtheriou, “Decoding of trellis-encoded sig-nals in the presence of intersymbol interference and noise,”IEEE Trans.Commun., vol. 37, pp. 669–676, July 1989.
[25] A. Duel-Hallen and C. Heegard, “Delayed decision-feedback sequenceestimation,”IEEE Trans. Commun., vol. 37, pp. 428–436, May 1989.
[26] L. Wei and C. Schlegel, “Synchronous DS-SSMA with improveddecorrelating decision-feedback multiuser detector,”IEEE Trans. Veh.Technol., pp. 767–772, Aug. 1994.
[27] L. Wei, L. K. Rasmussen, and R. Wyrwas, “Near optimum tree-searchdetection schemes for bit synchronous multiuser CDMA systemsover Gaussian and two-path Rayleigh fading channels,”IEEE Trans.Commun., vol. 45, pp. 691–701, June 1997.
[28] S. T. Simmons, “Breadth-first trellis decoding with adaptive effort,”IEEE Trans. Commun., vol. 38, pp. 3–12, Jan. 1990.
[29] J. Belzile and D. Haccoun, “Bidirectional breadth-first algorithms forthe decoding of convolutional codes,”IEEE Trans. Commun., vol. 41,pp. 451–457, Feb. 1993.
[30] L. Wei, “An upper bound for correct path loss probability of theM -algo-rithm over ISI channels,” inProc. IEEE Information Theory Workshop(ITW’97), Longyearbyen, Norway, July 6–12, 1997, pp. 31–32.
[31] D. L. Duttweiler, J. E. Mazo, and D. G. Messerschmitt, “An upper boundon the error probability in decision-feedback equalization,”IEEE Trans.Inform. Theory, vol. IT-20, pp. 490–497, July 1974.
[32] J. J. O’Reilly and A. M. de Oliveira Duarte, “Error propagation in de-cision feedback receivers and simplified technique for bounding errorstatistics for DFD receivers,”Proc. Inst. Elec. Eng., pt. F, vol. 132, no.7, pp. 561–575, Dec. 1985.
[33] R. A. Kennedy, B. O. Anderson, and R. R. Bitmead, “Channels leadingto rapid error recovery for decision feedback equalizers,”IEEE Trans.Commun., vol. 37, pp. 1126–1135, Nov. 1989.

1482 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 46, NO. 4, JULY 2000
[34] R. Johannesson and K. S. Zigangirov, “Upper bounds on the probabilityof the correct path loss for list decoding of fixed convolutional codes,”in Proc. IEEE Int. Symp. Information theory (ISIT’95), BC, Canada,1996, p. 163. “Toward a theory for list decoding of convolutional codes,”Probl. Inform. Transm.,no. 1, 1996.
[35] T. Aulin, “A fractional Viterbi-type trellis decoding algorithm,” inProc.IEEE Int. Symp. Information Theory (ISIT’86), Ann Arbor, MI, Oct.1986, p. 41.
[36] , “Optimal trellis decoding at given complexity,” inProc. IEEEInt. Symp. Information Theory (ISIT’93}, San Antonio, TX, Jan. 17–22,1993, p. 272. “Breadth first maximum likelihood sequence detection:Basics,”IEEE Trans. Commun., vol. 47, pp. 209–216, Feb. 1999..
[37] L. Wei and L. K. Rasmussen, “A near-ideal whitening filter for an asyn-chronous time-variant CDMA system,”IEEE Trans. Commun., vol. 44,pp. 1355–1362, Oct. 1996.
[38] R. Lupas and S. Verdú, “Near-far resistance of multiuser detectors inasynchronous channels,”IEEE Trans. Commun., vol. 38, pp. 496–508,Apr. 1990.
[39] G. J. Foschini, “Performance bound of maximum-likelihood receptionof digital data,”IEEE Trans. Inform. Theory, vol. IT-21, pp. 47–50, Jan.1974.
[40] G. D. Forney Jr., “Lower bounds on error probability in the presenceof large intersymbol interference,”IEEE Trans. Commun. Technol., vol.COM-20, pp. 76–77, Feb. 1972.
[41] S. P. Meyn and R. L. Tweedie,Markov Chains and Stochastic Sta-bility. Berlin, Germany: Springer-Verlag, 1993.
[42] S. Lin and D. Costello,Error Control Coding: Fundamentals and Ap-plications. Englewood Cliffs, NJ: Prentice-Hall, 1983.
[43] M. Cedervall and R. Johannesson, “A fast algorithm for computing dis-tance spectrum of convolutional codes,”IEEE Trans. Inform. Theory,vol. IT-35, pp. 1146–1159, Nov. 1989.
[44] R. G. Gallager,Discrete Stochastic Processes. Boston, MA: KluwerAcademic, 1996.
[45] C. Schlegel and L. Wei, “A simple way to compute the minimum dis-tance in multiuser CDMA systems,”IEEE Trans. Commun., vol. 45, pp.532–536, May 1997.
[46] M. R. Best, M. V. Burnashev, Y. Lévy, A. Rabinovich, P. C. Fishburn,A. R. Calderbank, and D. J. Costello Jr., “On a technique to calculatethe exact performance of a convolutional code,”IEEE Trans. Inform.Theory, vol. 41, pp. 441–447, Mar. 1995.
[47] L. Wei, T. Aulin, and H. Qi, “On the effect of truncation length onthe exact performance of a convolutional code,”IEEE Trans. Inform.Theory, vol. 43, pp. 1678–1681, Sept. 1997.
[48] G. D. Forney Jr., “Final Report on a Coding System Design for AdvanceSolar Missions,” NASA Ames Res. Ctr., Moffett Field, CA, Rep. NAS2-3637, Contract NASA CR73167, 1967.
[49] L. R. Bahl, C. D. Cullum, W. D. Frazer, and F. Jelinek, “An efficientalgorithm for computing free distance,”IEEE Trans. Inform.Theory, vol.IT-18, pp. 437–439, May 1972.
[50] K. J. Lassen, “Comments on ‘An efficient algorithm for computing freedistance’,”IEEE Trans. Inform. Theory, vol. IT-19, pp. 577–579, July1973.
[51] L. C. Perez, J. Seghers, and D. J. Costello Jr., “A distance spectruminterpretation of turbo codes,”IEEE Trans. Inform. Theory, vol. 42, pp.1698–1709, Nov. 1996.
[52] S. J. MacMullan and O. M. Collins, “A comparison of known codes,random codes and the best codes,”IEEE Trans. Inform. Theory, vol. 44,pp. 3009–3022, Nov. 1998.




![1 Sequential Decoding of Convolutional Codes - ntpuweb.ntpu.edu.tw/~yshan/book_chapter.pdf · 2 IncontrasttothelimitationoftheViterbialgorithm,sequentialdecodingisrenowned foritscomputationalcomplexitybeingindependentofthecodeconstraintlength[1].](https://static.fdocuments.in/doc/165x107/5e08b7acda112278e327d004/1-sequential-decoding-of-convolutional-codes-yshanbookchapterpdf-2-incontrasttothelimitationoftheviterbialgorithmsequentialdecodingisrenowned.jpg)









![arXiv:1703.05051v4 [cs.LG] 8 Aug 2017 learning with convolutional neural networks for brain mapping and decoding of movement-related information from the human EEG Short title: Convolutional](https://static.fdocuments.in/doc/165x107/5b022b357f8b9a89598f3af0/arxiv170305051v4-cslg-8-aug-2017-learning-with-convolutional-neural-networks.jpg)


