

Natural language processing (NLP) introduction
35
Natural language processing (NLP) introduction Robert Lujo
-
Upload
robert-lujo -
Category
Software
-
view
367 -
download
5
Transcript of Natural language processing (NLP) introduction

Natural language processing (NLP)
introduction!
Robert Lujo

About me
• software
• professionally 18 g.
• python >= 2.0, django >= 0.96
• freelancer
• … (linkedin)

NLP is …

NLPNatural language processing (NLP)
a field of computer science … concerned with the interactions
between computers and human (natural) languages.
!
https://en.wikipedia.org/wiki/Natural_language_processing

NLP
“between computers and human (natural) languages”
1. computer -> human language
2. human language -> computer

NLP trend• Internet is huge and easily accessible resource
of information
• BUT - information is mainly unstructured
• usually simple scraping (scrapy) is sufficient, but sometimes it is not
• NLP solves or helps in converting free text (unstructured information) to structural form

NLP goalssome examples

NLP goals - group 1• cleanup, tokenization
• stemming
• lemmatization
• part-of-speach tagging
• query expansion
• sentence segmentation

NLP goals - group 2
• information extraction
• named entity recognition (NER)
• sentiment analysis
• word sense disambiguation
• text similarity

NLP goals - group 3
• machine translation
• automatic summarisation
• natural language generation
• question answering

NLP goals - group 4
• optical character recognition (OCR)
• speech processing
• speech recognition
• text-to-speech

NLP theory

Word, term, feature• word <> term
• document or text chunk is an unit / entity / object!
• terms are features of the document!
• each term has properties:
• normalized form -> term.baseform + term.transformation
• position(s) in the document -> term.position(s)
• frequency -> term.frequency

Text, document, chunk
• what is document?
• text segmentation
• hard problem
• usually we consider whole document as one unit (entity)

Terms, features• converting words -> terms
• term frequency is usually the most important feature!
• how to get the list of terms with frequencies:
• preprocessing - e.g. remove all but words, remove stopwords, tokenization (regexp)
• word normalization
dog ~ dogs zeleno ~ najzelenijih
• .tolower(), regexp, stemming, lemmatization
• much harder for inflectional languages, e.g. Croatian, see text-hr :)

Term weight - TF-IDF• term frequency – inverse document frequency
• variables:
• t - term,
• d - one document
• D - all documents
• TF - is term frequency in a document function - i.e. measure on how much information the term brings in one document
• IDF - is inverse document frequency of the term function - i.e. inversed measure on how much information the term brings in all documents (corpus)

Terms position, syntax
• sometimes term position is important
• neighbours, collocation, phrase extraction, NER
• from regexp to parsers
• syntax trees
• complex, cpu intensive

Terms position, syntaxIn their public lectures they have even claimed that the only evidence that Khufu built the pyramid is the graffiti found in the five chambers.

Bag of words

Bag of words
• simplified and effective way to process documents by:
• disregarding grammar (term.baseform?)
• disregarding word order (term.position)
• keeping only multiplicity (term.frequency)

Bag of words
• sparse matrix
• numbers can be:
• binary - 0/1
• simple term frequency
• weight - e.g. TF-IDF

Bag of words• very simple -> very fast
• frequently used:
• in index servers
• in database for simple full-text-search operations
• for processing of large datasets

NLP techniques

Machine learning
• one of the Machine learning application is NLP
• after text is converted to entities with features, machine learning techniques can be applied

Machine learning• ML algorithm families categorisation
• supervised - classification (distinct), regression (numerical)
• unsupervised - clustering
• A lot of various methods/algorithm families, statistical, probabilistic, …
decision trees, neural networks / deep learning,
support vector machines, bayesian networks,
markov models, genetic algorithms
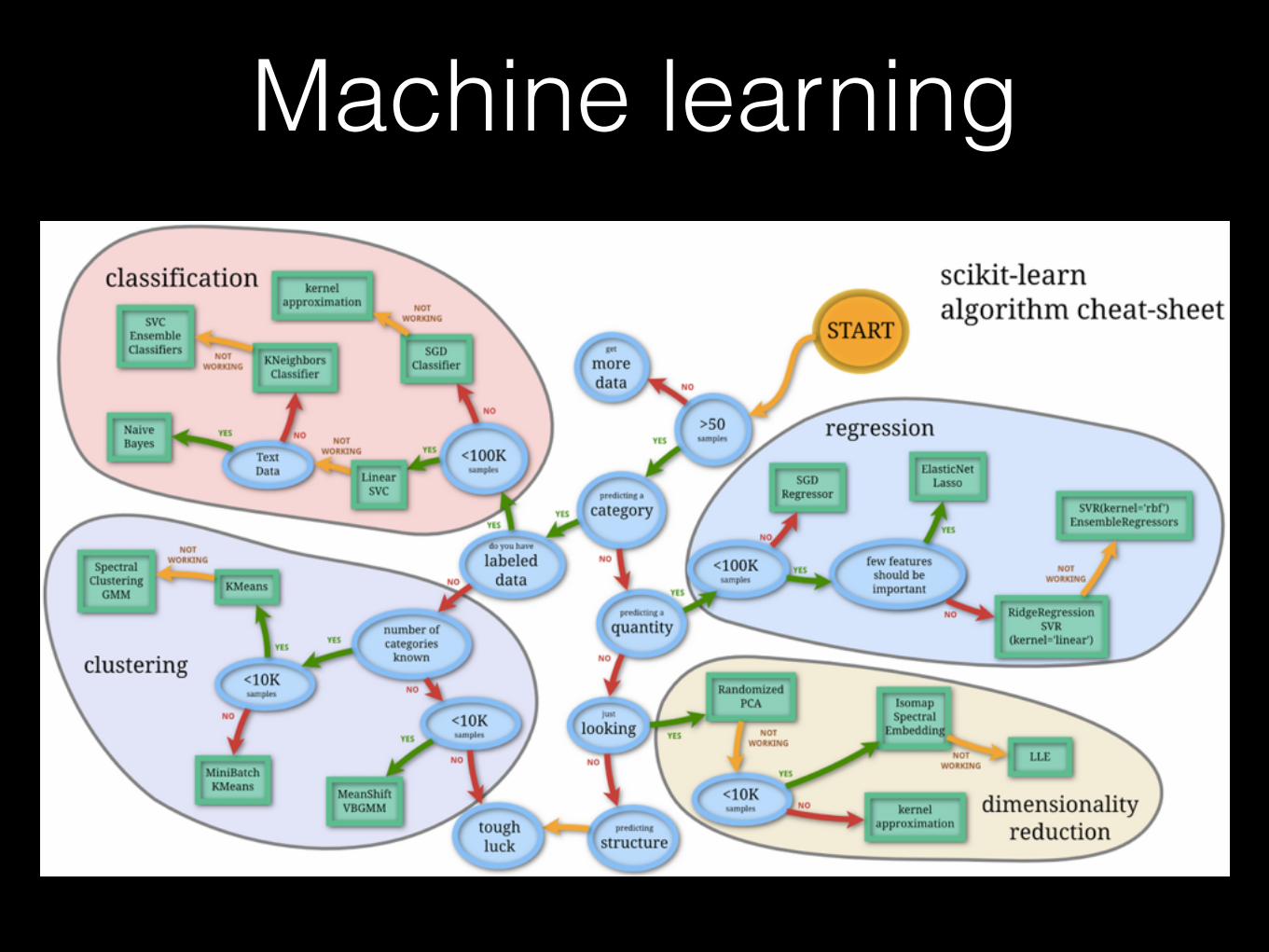
Machine learning

Usual NLP methods
• Naive Bayes
• Markov models
• SVM
• Neural networks / Deep learning

NLP libraries !
mainly python

Basic string manipulation• keep it simple and stupid
.lower(), .strip(), .split(), .join(), iterators, …
• regexp
• not only match, but transformation, extraction (\1), backreferences etc.
• re.options, re.multiline, repl can be function:
def repl(m): …
re.sub(“pattern”, repl, “string”)

NLTKhttp://www.nltk.org/
the biggest, the most popular, the most comprehensive, free book:
!
!
!

Scikit-Learnhttp://scikit-learn.org/stable/index.html
machine learning in python
!
!
!

spaCy
http://honnibal.github.io/spaCy/
new kid on the block - 2015-01
text processing in Python and Cython
“… industrial-strength NLP …
… the fastest NLP software …”

Stanford NLP
• http://nlp.stanford.edu/software/index.shtml
• statistical NLP, deep learning NLP, and rule-based NLP tools for major computational linguistics problems
• famous
• Java

Misc …• data analysis libraries - numpy, pandas, matplotlib,
shapely …
• parsers - BLIPP, pyparsing, parserator
• MonkeyLearn service …
• Java, C/C++
• effective memory representation, permanent storage etc.
• lot of free resources - books, reddit, blogs, etc.


















