
NaBIC 2013 presentation
13
Social insect inspired approach for identification and dynamic tracking of news stories on the Web Štefan Sabo and Pavol Návrat [email protected], [email protected]
-
Upload
stefan-sabo -
Category
News & Politics
-
view
24 -
download
0
Transcript of NaBIC 2013 presentation

Social insect inspired approach for
identification and dynamic tracking
of news stories on the Web
Štefan Sabo and Pavol Návrat

General overview
• Method for dynamic identification and tracking of currently
unfolding news stories is proposed.
• Multiple agents inspired by honey bees foraging for food
are used.
• Connections between articles are explored one story word
at a time, most promising story words that provide links
between articles are propagated.
• Graph of connection between articles and story words is
constructed and analyzed in order to obtain distinct news
stories.

Motivation
• News stories are often represented by terms that identify
the story by providing an easily recognizable label for it.
• These story words are interesting for navigation in the
space of news stories.
• Dynamic system is needed to follow new articles and
account for the changes in the old ones.
• Corpus of all the articles in unavailable.

Method overview – story word extraction
• Story word is a term related to a group of articles, which
connects the articles on a basis of their mutual relevance
to a single news story.
• Instead of identifying stories relevant to news articles
directly, we try to identify individual story words relevant to
an article.
• Advantage of this approach lies in the fact, that in order to
compare two articles based on a single story word, no
global analysis is needed.
• Stories are result of an emergent behavior of the swarm.

Method overview – story word extraction
• Agents move between articles and try to establish most
prominent story words in explored set of articles.
• If a story word is identified based on its relevance to
multiple articles a link is established between the articles.
• Comparison between every two articles regarding every
keyword would be impractical, therefore a selection
strategy based on behavior of honey bees is utilized.
• Modifications, allowing for continuous run have been
introduced.

Method overview – story identification
• Main contribution of presented approach.
• Utilizes a graph representation of obtained data, with
articles and story words as nodes and relevance
relationships as edges.

Method overview – story identification
• Graph is dynamically constructed by agents, as new
articles are explored.
• Articles are grouped into stories through Louvain algorithm
for community detection.
• Once the stories have been established, it is possible to
classify new articles on-the-fly by adding the new articles
to the topics which maximize the modularity of the graph.
• It is however necessary to rerun story identification
periodically from the start, so that the story set is updated
as well.

Results
• Goal to evaluate the precision of topic identification
mechanism.
• Experimental run of 50 agents on Reuters web page for
2000 iterations.
• After obtaining the articles, 11 news stories have been
manually identified and labeled, based on the article
content.
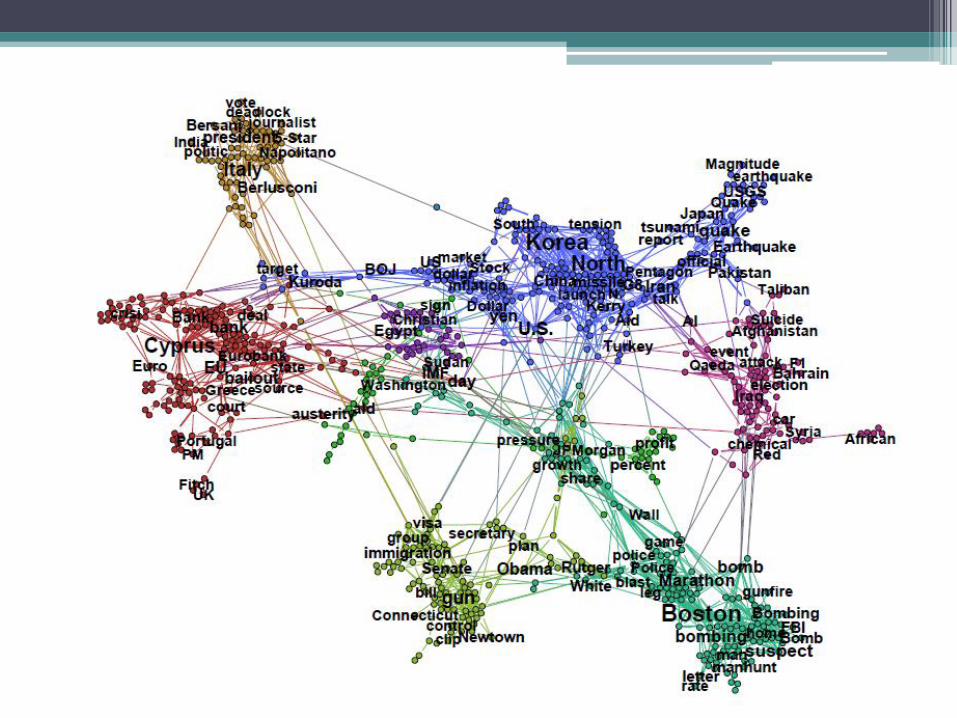
• Afterwards the Louvain algorithm was used to identify
communities within the graph resulting from the
experimental run.
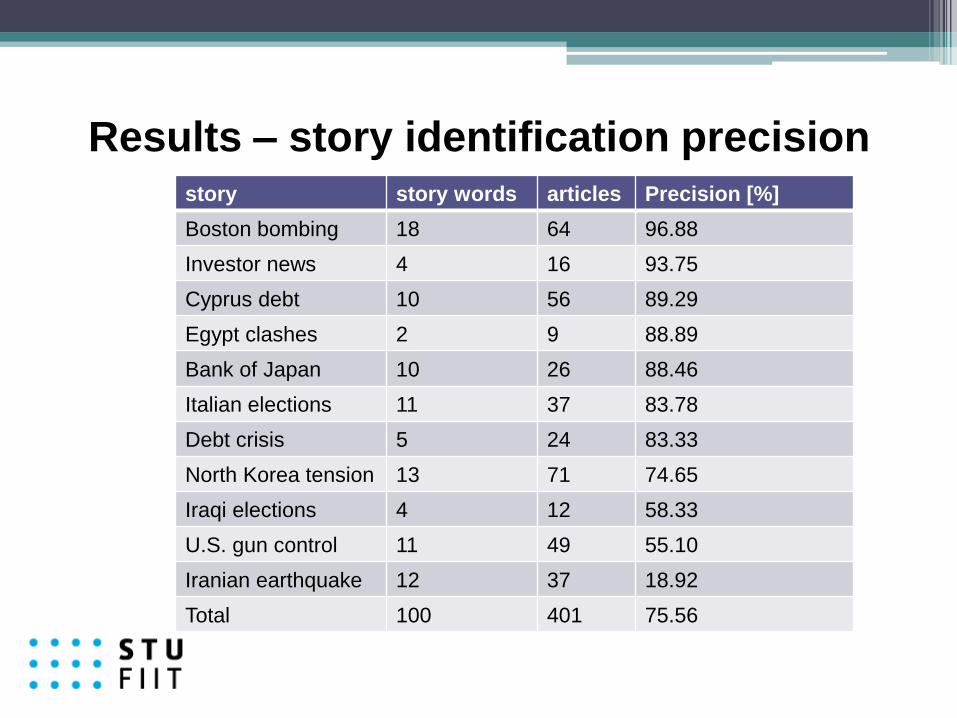
story story words articles Precision [%]
Boston bombing 18 64 96.88
Investor news 4 16 93.75
Cyprus debt 10 56 89.29
Egypt clashes 2 9 88.89
Bank of Japan 10 26 88.46
Italian elections 11 37 83.78
Debt crisis 5 24 83.33
North Korea tension 13 71 74.65
Iraqi elections 4 12 58.33
U.S. gun control 11 49 55.10
Iranian earthquake 12 37 18.92
Total 100 401 75.56
Results – story identification precision


Summary
• Proposed approach utilizes agents to extract story related terms from a set of news articles.
• Articles are compared and their proximity is evaluated multiple times with regard to various story words, using a selection strategy based on Beehive Metaphor.
• Dynamic nature of the process enables agents to react to new articles as well as to changes in the old ones without need for article corpus or machine learning.
• Stories are identified on-the-fly, based on the communities identified within article graph.
• No prior training of agents, or static corpus is required.

Thank you for you attention


















