
Multithreading and Dataflow Architectures CPSC 321 Andreas Klappenecker.
38
Multithreading and Dataflow Architectures CPSC 321 Andreas Klappenecker
-
date post
20-Dec-2015 -
Category
Documents
-
view
232 -
download
1
Transcript of Multithreading and Dataflow Architectures CPSC 321 Andreas Klappenecker.

Multithreading and Dataflow Architectures
CPSC 321
Andreas Klappenecker

Plan
• T November 16: Multithreading• R November 18: Quantum Computing• T November 23: QC + Exam prep• R November 25: Thanksgiving
• M November 29: Review ???
• T November 30: Exam• R December 02: Summary and Outlook• T December 07: move to November 29?

Announcements
• Office hours 2:00pm-3:00pm• Bonfire memorial

Parallelism
• Hardware parallelism• all current architectures
• Instruction-level parallelism• superscalar processor, VLIW processor
• Thread-level parallelism• Niagara, Pentium 4, ...
• Process parallelism• MIMD computer

What is a Thread?
A thread is a sequence of instructions that can be executed in parallel with other sequences.
Threads typically share the same resources and have a minimal context.

Threads
• Definition 1 Different threads within the same process share the same address space, but have separate copies of the register file, PC, and stack
• Definition 2 Alternatively, different threads have separate copies of the register file, PC, and page table (more relaxed than previous definition).
• One can use a multiple issue, out-of-order, execution engine.

Why Thread-Level Parallelism?
Extracting instruction-level parallelism is non-trivial:
•hazards and stalls•data dependencies•structural limitations•static optimization limits
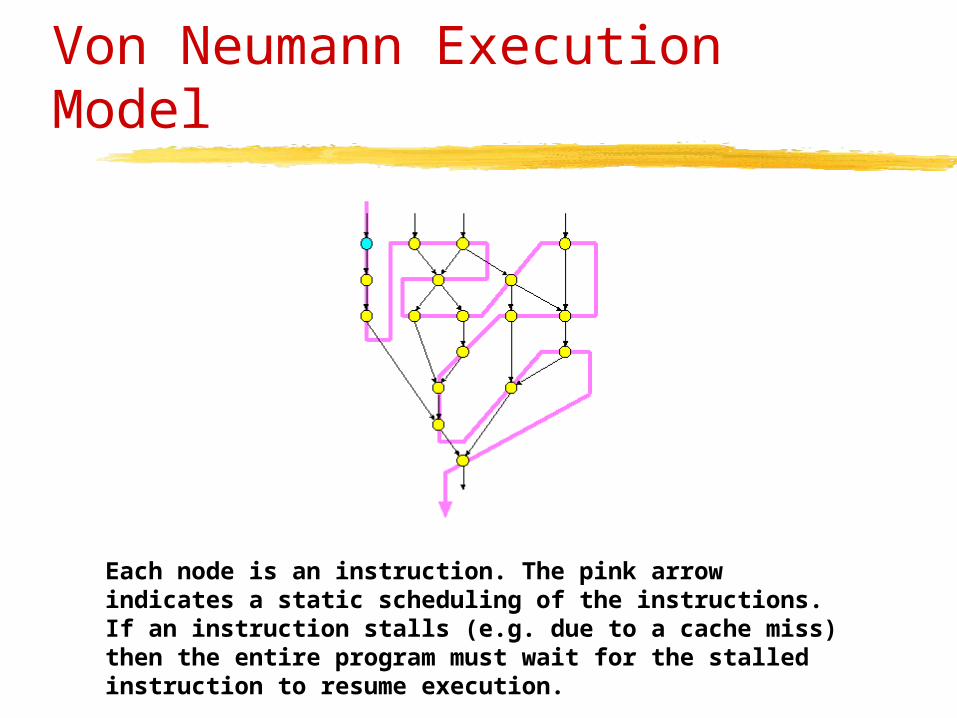
Von Neumann Execution Model
Each node is an instruction. The pink arrow indicates a static scheduling of the instructions. If an instruction stalls (e.g. due to a cache miss) then the entire program must wait for the stalled instruction to resume execution.
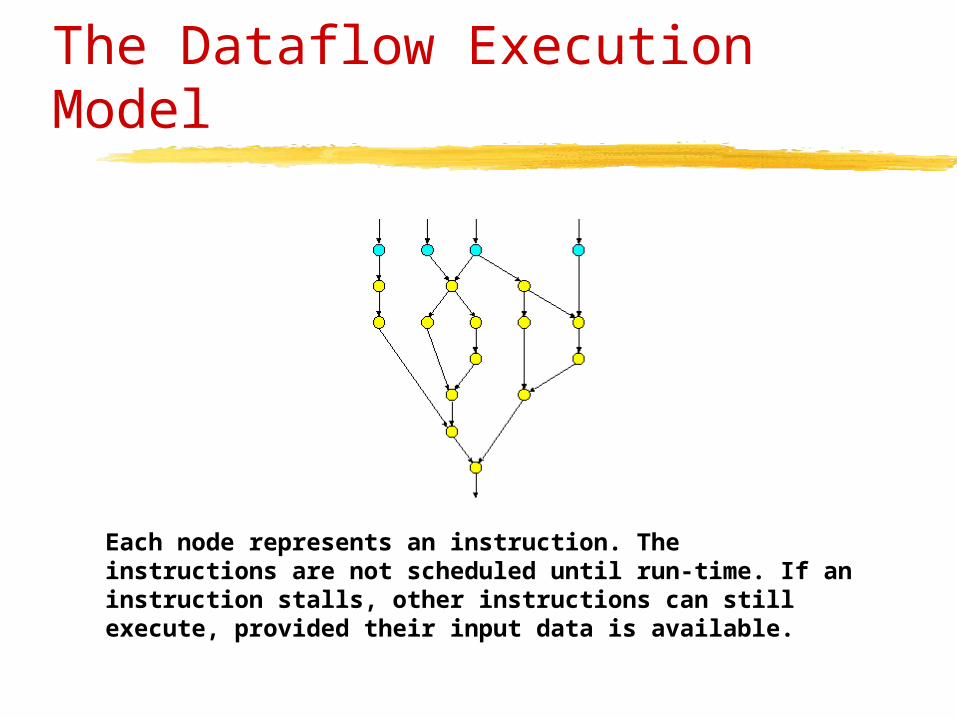
The Dataflow Execution Model
Each node represents an instruction. The instructions are not scheduled until run-time. If an instruction stalls, other instructions can still execute, provided their input data is available.

The Multithreaded Execution Model
Each node represents an instruction and each gray region represents a thread. The instructions within each thread are statically scheduled while the threads themselves are dynamically scheduled.
If an instruction stalls, the thread stalls but other threads can continue execution.

Single-Threaded Processors
Memory access latency can dominate the processing time, because each time a cache miss occurs hundreds of clock cycles can be lost when a single-threaded processor is waiting for the memory.
Top: Increasing the clock speed improves the processing time, but does not affect the memory access time.
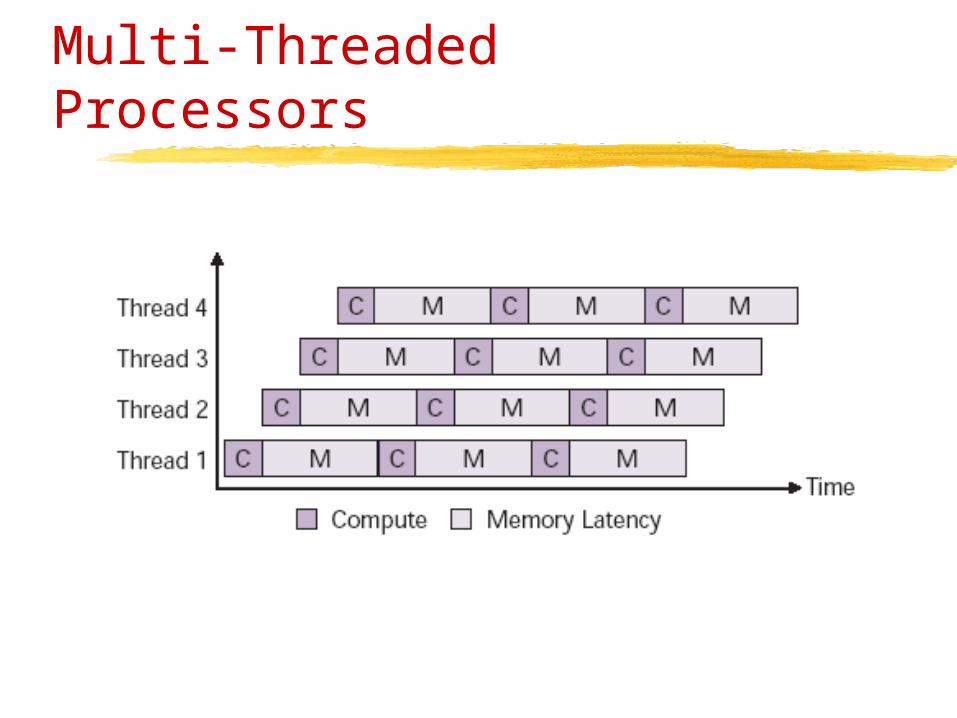
Multi-Threaded Processors

Multithreading Types
Coarse-grained multithreadingIf a thread faces a costly stall, switch to another thread. Usually flushes the pipe before switching threads.
Fine-grained multithreading interleave the issue of instruction from multiple threads (cycle-by-cycle), skipping the threads that are stalled. Instructions issued in any given cycle comes from the same thread.

Scalar Execution
Dependencies reduce throughput and utilization.

Superscalar Execution
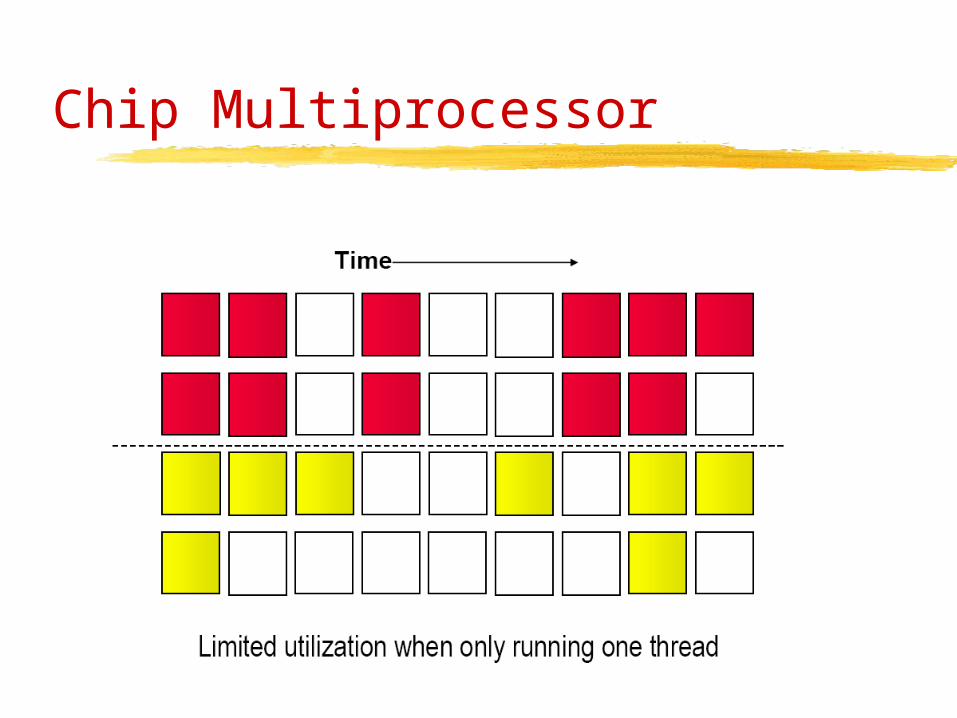
Chip Multiprocessor

Fine-Grained Multithreading
Instructions issues in the same cycle come from the same thread

Fine-Grained Multithreading
• Threads are switched every clock cycle, in round robin fashion, among active threads
• Throughput is improved, instructions can be issued every cycle
• Single-thread performance is decreased, because one thread is expected to get just every n-th clock cycle among n processes
• Fine-grained multithreading requires hardware modifications to keep track of threads (separate register files, renaming tables and commit buffers)

Multithreading Types
A single thread cannot effectively use all functional units of a multiple issue processor
Simultaneous multithreadinguses multiple issue slots in each clock cycle for different threads. More flexible than fine grained MT.

Simultaneous Multithreading

Comparison
• Superscalar: • looks at multiple instructions from same
process, both horizontal and vertical waste.
• Multithreaded: • minimizes vertical waste: tolerate long latency
operations
• Simultaneous Multithreading • Selects instructions from any "ready" thread

Tim
e (P
roce
ssor
cyc
le)
Unuti l i zed Thread 1 Thread 2 Thread 3 Thread 4 Thread 5
Superscalar Multithreaded SMT
Issue slots

SMT Issues

A Glance at a Pentium 4 Chip
Picture courtesy of Tom’s hardware guide

The Pipeline
Trace cache
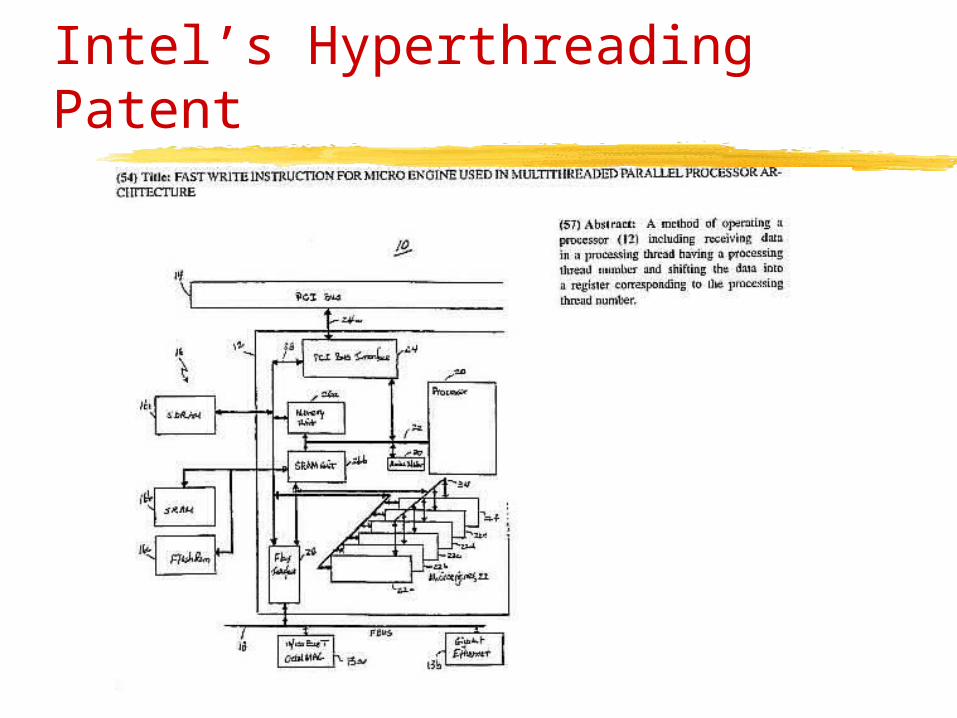
Intel’s Hyperthreading Patent

Pentium 4 Pipeline
1. Trace cache access, predictor 5 clock cycles• Microoperation queue
2. Reorder buffer allocation, register renaming 4 clock cycles
• functional unit queues
3. Scheduling and dispatch unit 5 clock cycles4. Register file access 2 clock cycles5. Execution 1 clock cycle
• reorder buffer
6. Commit 3 clock cycles (total: 20 clock cycles)

PACT XPP
The XPP processes a stream of data using configurable arithmetic-logic units.
The architecture owes much to dataflow processing.

A Matrix-Vector Multiplication
Graphic courtesy of PACT

Basic Idea
• Replace the von Neumann instruction stream with fixed instruction scheduling by a configuration stream.
• Process streams of data as opposed to processing of small data entities.

von Neumann vs. XPP

Basic Components of XPP
• Processing Arrays• Packet oriented communication network• Hierarchical configuration manager tree• A set of I/O modules
Supports the execution of multiple data flow applications running in parallel.

Four Processing Arrays
Graphics courtesy of PACT. SCM is short for supervising configuration manager
Data Processing

Event Packets


XPP 64-A

Further Reading
• PACT XPP – A Reconfigurable Data Processing Architecture by Baumgarte, May, Nueckel, Vorbach and Weinhardt


















