
Multipliers
27
EE241 - Spring 2004 Advanced Digital Integrated Circuits Borivoje Nikolić Lecture 20 Multipliers 2 Announcements Feedback on midterm mailed to you Homework #4 posted, due next Thursday
-
Upload
jacob-chako -
Category
Documents
-
view
212 -
download
0
Transcript of Multipliers

1
EE241 - Spring 2004Advanced Digital Integrated Circuits
Borivoje Nikolić
Lecture 20Multipliers
2
AnnouncementsFeedback on midterm mailed to youHomework #4 posted, due next Thursday

2
3
Ling Adder
Variation of CLA
Ling, IBM J. Res. Dev, 5/81
1−⋅+= iiii GpgG
1−⊕= iii GpS
iii bap ⊕=
iii bag ⋅=
11 −− ⋅+= iiii HtgH
11 −−+⊕= iiiiii HtgHtS
iii bat +=
iii bag ⋅=
Ling’s equations
4
Ling Adder
1−⋅+= iiii GpgG
1−⋅+= iiii GtgG 11 −− ⋅+= iiii GtgH
Ling’s equation shifts the index ofpseudo carry
Doran, Trans on Comp 9/88
Propagates informationon two bits
Conventional CLA:
Also:

3
5
Ling Adder
01231232333 gtttgttgtgG +++=
0121223
00121122233gttgtgg
gtttgttgtgH+++=
+++=
Conventional radix-4
Ling radix-4
Reduces the stack height (or width)Reduces input loading
6
Ling vs. CLA
1015202530354045505560
6 7 8 9 10 11Delay [FO4]
Ener
gy [p
J]
R2 Ling
R2 CLA
R4 Ling
R4 CLA
R. Zlatanovici, ESSCIRC’03

4
7
Static vs. Dynamic
8
13
18
23
28
33
38
5 7 9 11 13 15Delay [FO4]
Ener
gy [p
J]Compound Domino R2Domino R2Domino R4Static R2
8
Stack Height LimitingTransform conventional G, P
Park, VLSI Circ’00

5
9
HP Adder
Naffziger, ISSCC’96
01234 ppppi =
10
HP Adder – Differential Domino
Carry rippleSum select

6
11
Hybrid Adders
Dobberpuhl, JSSC 11/92 DEC Aplha 21064
12
DEC AdderCombination:
8-bit tapered pre-discharged Manchester carry chains, with Cin = 0 and Cin = 132-bit LSB carry-lookahead32-bit MSB conditional sum adderCarry-select on most significant bitsLatch-based timing

7
13
Z X·· Y× Zk2k
k 0=
M N 1–+
∑= =
Xi2i
i 0=
M 1–
∑
Yj2j
j 0=
N 1–
∑
=
XiYj2i j+
j 0=
N 1–
∑
i 0=
M 1–
∑=
X Xi2i
i 0=
M 1–
∑=
Y Yj2j
j 0=
N 1–
∑=
with
Binary Multiplication
14
1 0 1 1
1 0 1 0 1 0
0 0 0 0 0 0
1 0 1 0 1 0
1 0 1 0 1 0
1 0 1 0 1 0
×
1 1 1 0 0 1 1 1 0
+
Partial Products
AND operation
Binary Multiplication
N+ M bits in the final sum
N bits
M bits

8
15
Shift-and-Add MultiplierStandard adder and shift-in the multiplicandShift the result as well and addN cyclesParallel adders add more hardware (adders) instead.
16
HA FA FA HA
FA FA FA HA
FA FA FA HA
X0X1X2X3 Y1
X0X1X2X3 Y2
X0X1X2X3 Y3
Z1
Z2
Z3Z4Z5Z6
Z0
Z7
Array Multiplier

9
17
HA FA FA HA
HAFAFAFA
FAFA FA HA
Critical Path 1
Critical Path 2
Critical Path 1 & 2
MxN Array Multiplier— Critical Path
18
A
B
P
Ci
VDD A
A A
VDD
Ci
A
P
AB
VDD
VDD
Ci
Ci
Co
S
Ci
P
P
P
P
P
Identical Delays for Carry and Sum
Adder Cells in Array Multiplier

10
19
HA HA HA HA
FAFAFAHA
FAHA FA FA
FAHA FA HA
Vector Merging Adder
Carry-Save Multiplier
20
SCSCSCSC
SCSCSCSC
SCSCSCSC
SC
SC
SC
SC
Z0
Z1
Z2
Z3Z4Z5Z6Z7
X0X1X2X3
Y1
Y2
Y3
Y0
Vector Merging Cell
HA Multiplier Cell
FA Multiplier Cell
X and Y signals are broadcastedthrough the complete array.( )
Multiplier Floorplan

11
21
MultipliersPartial product generationPartial product accumulationFinal summation
22
Generating Partial ProductsAll partial products: AND
Booth’s recoding – reduction of partial product count
X7
PP7
X6
PP6
X5
PP5
X4
PP4
X3
PP3
X2
PP2
X1
PP1
X0
PP0

12
23
Booth RecodingInstead of generating all the partial products0 * x = 0 1 * x = x x={0,1}Reduce the number of partial productsby grouping
0 0 00 1 1*1 0 2* (shift)1 1 3* (or 4* -1)
Booth’51
24
Booth RecodingInstead of using set {0, 1*Y, 2*Y, 3*Y}Use {0, 1*Y, 2*Y, 4*Y, -Y}Shifting and complementing3*Y = 4*Y – YCan be simplified by looking into three bits –modified Booth recoding

13
25
Modified Booth Recoding
Two bits and the MSB of previous two
26
Accumulating Partial Products
Partial product matrix Reorganized matrix

14
27
FA
FA
FA
FA
y0 y1 y2
y3
y4
y5
S
Ci-1
Ci-1
Ci-1
Ci
Ci
Ci
FA
y0 y1 y2
FA
y3 y4 y5
FA
FA
CC S
Ci-1
Ci-1
Ci-1
Ci
Ci
Ci
Wallace-Tree Multiplier
28
Wallace-Tree Multiplier

15
29
Wallace-Tree Multiplier
Wallace,Trans on Comp. 2/64
30
Tree MultipliersTime is proportional to log NWiring is complicatedDifferent wire lengthsOptional pipeliningWallace tree: reduce the number of operands at earliest opportunityDadda tree: reduce the number of operands with fewest adders

16
31
Minimum Number of Stages
Dadda,`65
32
Generalized Counters
Stenzel,Trans on Comp 10/77

17
33
Generalized Counters
34
Generalized Counters
32x32busing (5,5,4)with (3,2) inthe last stage

18
35
4:2 Counters (Compressors)
Weinberger, IBM J. ResDev 1/81Santoro, Horowitz, JSSC 4/89
4-2 carry-save module
36
4:2 Compressors
Built of CSAsPipelined version compresses8 partial products per cycle

19
37
4:2 Compressors
Interconnect can be more regular than in Wallace tree
38
Three Dimensional Optimization
Oklobdzija, Villeger, Liu, Trans on Comp 3/96

20
39
Vertical Slices in TDM
40
Final Addition

21
41
Final Addition
42
Final Addition
22
43
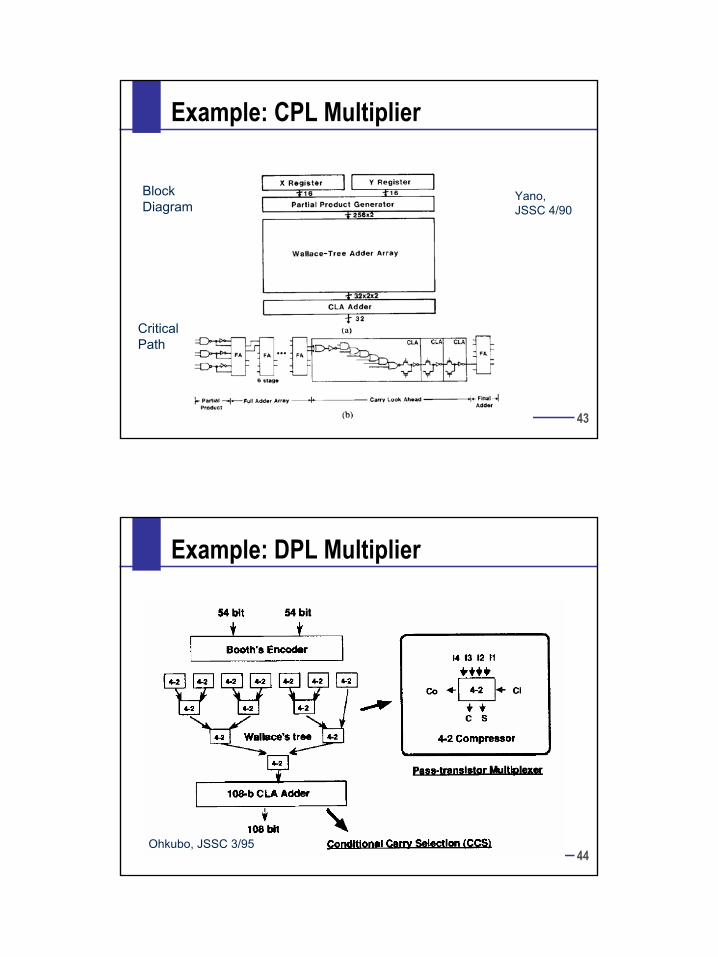
Example: CPL Multiplier
BlockDiagram
CriticalPath
Yano,JSSC 4/90
44
Example: DPL Multiplier
Ohkubo, JSSC 3/95

23
45
Example: DPL Multiplier
Booth encoder Partial product generator
46
Example: DPL Multiplier
FA-based 4:2 Modified 4:2

24
47
Example: DPL Multiplier
Tree construction
48
Example: DPL Multiplier
Final adder
25
49
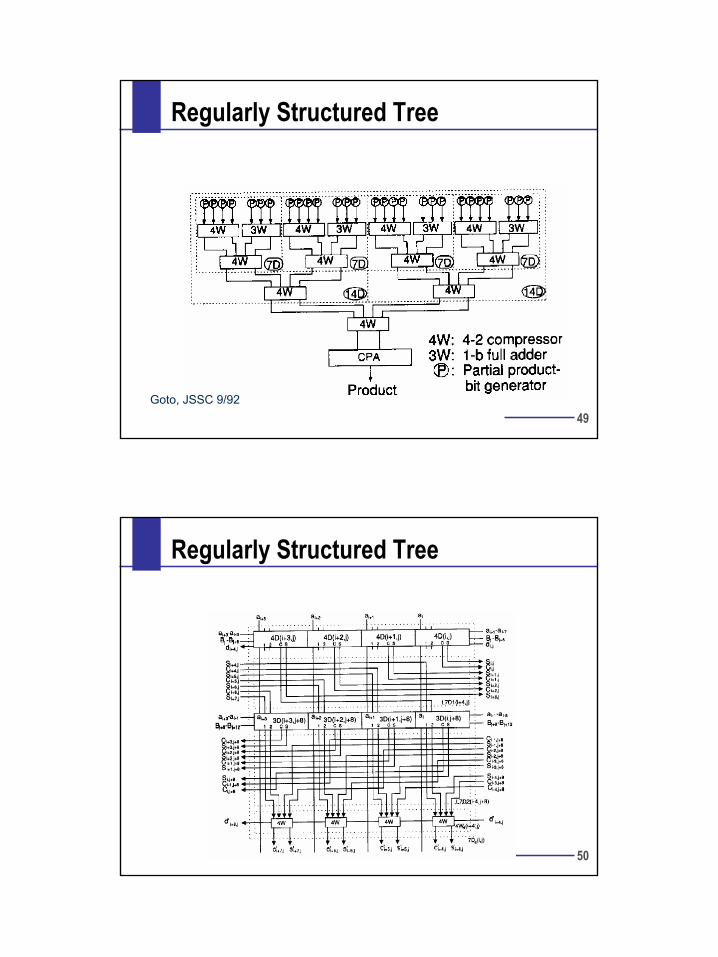
Regularly Structured Tree
Goto, JSSC 9/92
50
Regularly Structured Tree

26
51
Regularly Structured Tree
52
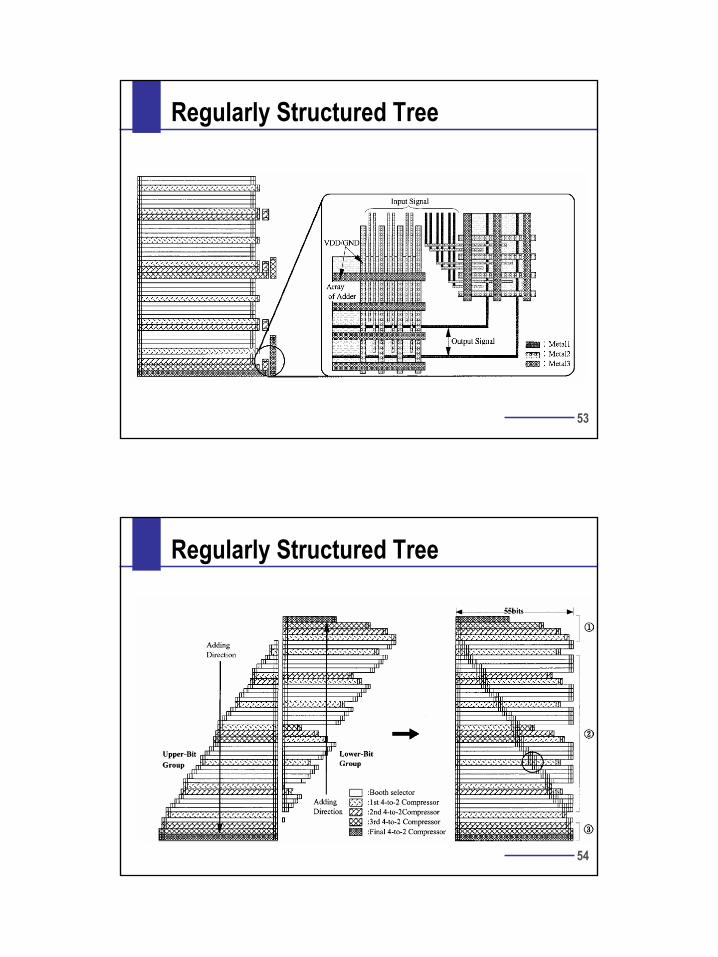
Regularly Structured Tree
Itoh, JSSC 2/01
27
53
Regularly Structured Tree
54
Regularly Structured Tree


















