
Multi-GPU System Design with Memory Networks Gwangsun Kim, Minseok Lee, Jiyun Jeong, John Kim...
21
Multi-GPU System Design with Memory Networks Gwangsun Kim, Minseok Lee, Jiyun Jeong, John Kim Department of Computer Science Korea Advanced Institute of Science and Technology
-
Upload
abbigail-axford -
Category
Documents
-
view
215 -
download
0
Transcript of Multi-GPU System Design with Memory Networks Gwangsun Kim, Minseok Lee, Jiyun Jeong, John Kim...

Multi-GPU System Design withMemory Networks
Gwangsun Kim, Minseok Lee, Jiyun Jeong, John Kim
Department of Computer Science
Korea Advanced Institute of Science and Technology

Single-GPU Programming Pattern
GPU
DeviceMemor
y
2/21
HostMemor
y
Data
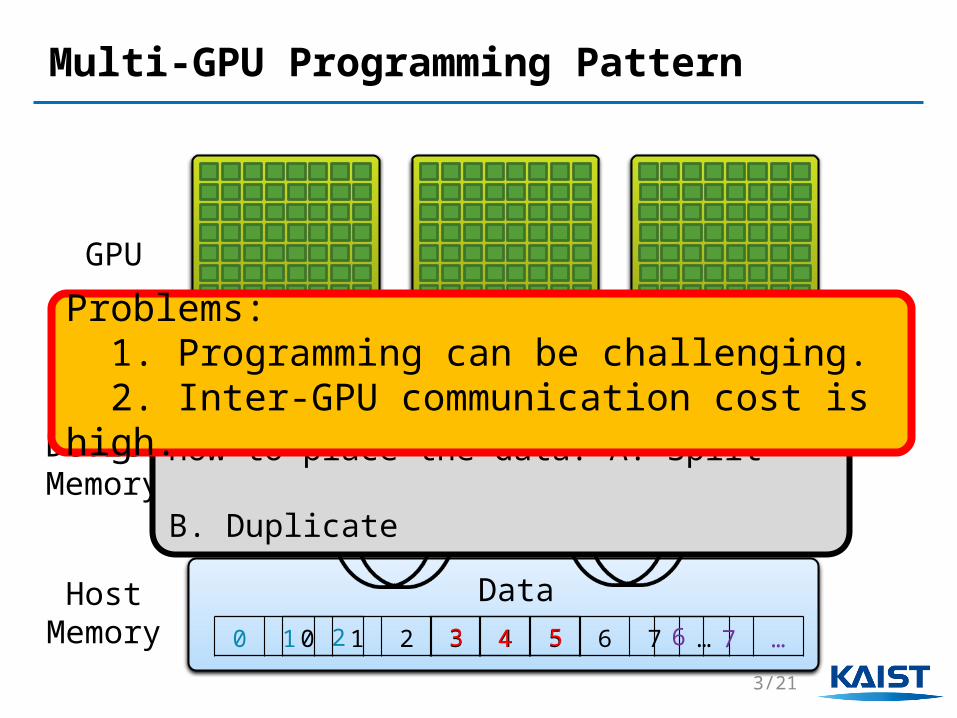
Multi-GPU Programming Pattern
GPU…
0 1 2 3 4 5 6 7 …
Data0 1 4 7 …2 3 5 6
DeviceMemor
y
3/21
HostMemor
y
How to place the data? A. Split B. Duplicate
Problems: 1. Programming can be challenging. 2. Inter-GPU communication cost is high.

Hybrid Memory Cube (HMC)
Logic layer
High-speed link
DRAM layers
I/O port
…Vaultcon-
troller
I/O port
Intra-HMC Network
Vaultcon-
troller
…
Packet 4/21
Vault

Memory Network
GPU
GPU
GPU
CPU
Logic layer
High-speed link
DRAM layers
I/O port
…Vaultcon-
troller
I/O port
Intra-HMC Network
Vaultcon-
troller
…
Memory network for multi-CPU [Kim et al., PACT’13]
5/21
… …NVLink
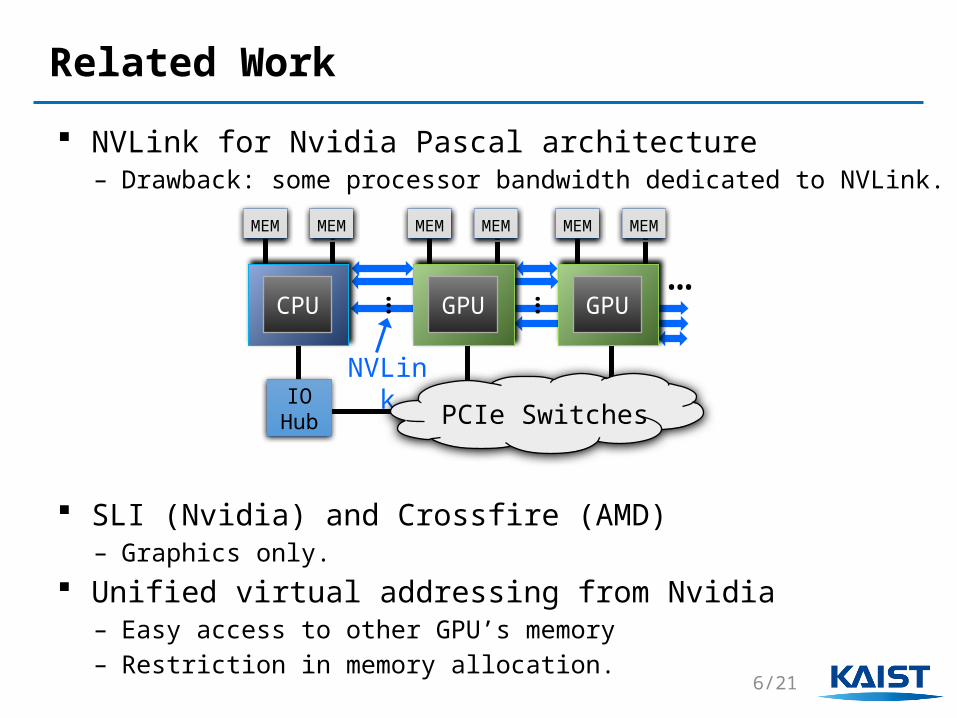
Related Work
NVLink for Nvidia Pascal architecture– Drawback: some processor bandwidth dedicated to NVLink.
SLI (Nvidia) and Crossfire (AMD) – Graphics only.
Unified virtual addressing from Nvidia– Easy access to other GPU’s memory– Restriction in memory allocation.
MEMMEM MEM MEMMEM MEM MEMMEM MEM
GPU
…GPU
IOHub
CPU
PCIe Switches
6/21

Contents
Motivation Related work
Inter-GPU communication– Scalable kernel execution (SKE)– GPU memory network (GMN) design
CPU-GPU communication – Unified memory network (UMN)– Overlay network architecture
Evaluation Conclusion
7/21

Memory Network
GPU Memory Network Advantage
GPUPCIe
Separate physical address spaces
DeviceMemor
y
288 GB/s
15.75 GB/s
PCIe
(optional)
8/21
Unified physical address space

Scalable Kernel Execution (SKE)
Executes an unmodified kernel on multiple GPUs. GPUs need to support partial execution of a kernel.
Single-GPU
GPU
GPU
GPU
Original Kernel
Virtual GPU
Multi-GPU with SKE
GPU
GPU
Source transformation[Kim et al., PPoPP’11][Lee et al., PACT’13]
[Cabezas et al., PACT’14]
KernelPartitioned
KernelKernel
9/21

Scalable Kernel Execution Implementa-tion
1D Kernel
Thread block
ThreadBlock rangefor GPU 0
Block rangefor GPU 1
Block rangefor GPU 2
...
Virtual GPU command queue
Virtual GPU
Application(unmodifiedsingle-GPU
version)
Original kernel meta data
Original kernel
meta data+ Block range
SKERun-time
GPU command queue
GPU0
GPU1…
10/21

Memory Address Space Organization
Page A GPU X
Page B GPU Y
Page C GPU Z
…
…
Fine-grained interleaving
GPU
Load-balanced
Cache line 0
Cache line 1
Cache line 2
Cache line 3
Cache line 4
Cache line 5
… …
GPU virtual address space
Minim
al pathNon-minimal path
11/21

Multi-GPU Memory Network Topology
Load-balanced GPU channelsRemove path diversity among local HMCs
Slicedflattened butterfly
(sFBFLY)
2D Flattened butterflyw/o concentration [ISCA’07]
(FBFLY)
GPUHMC
Distributor-based flattened butterfly [PACT’13]
(dFBFLY)
Load-balanced
2 4 8 160
50
100
150
200
250
300dFBFLY sFBFLY
# of GPUs
# of channels in mem-
orynetwork
50%43%
33%
12/21

Contents
Motivation Related work
Inter-GPU communication– Scalable kernel execution (SKE)– GPU memory network (GMN) design
CPU-GPU communication – Unified memory network (UMN)– Overlay network architecture
Evaluation Conclusion
13/21

Data Transfer Overhead
CPU GPU
Device memory
Host memory
0 1 2 …
Data PCIe
Problems: 1. CPU-GPU communication BW is low. 2. Data transfer (or memory copy) overhead.
LowBW
14/21
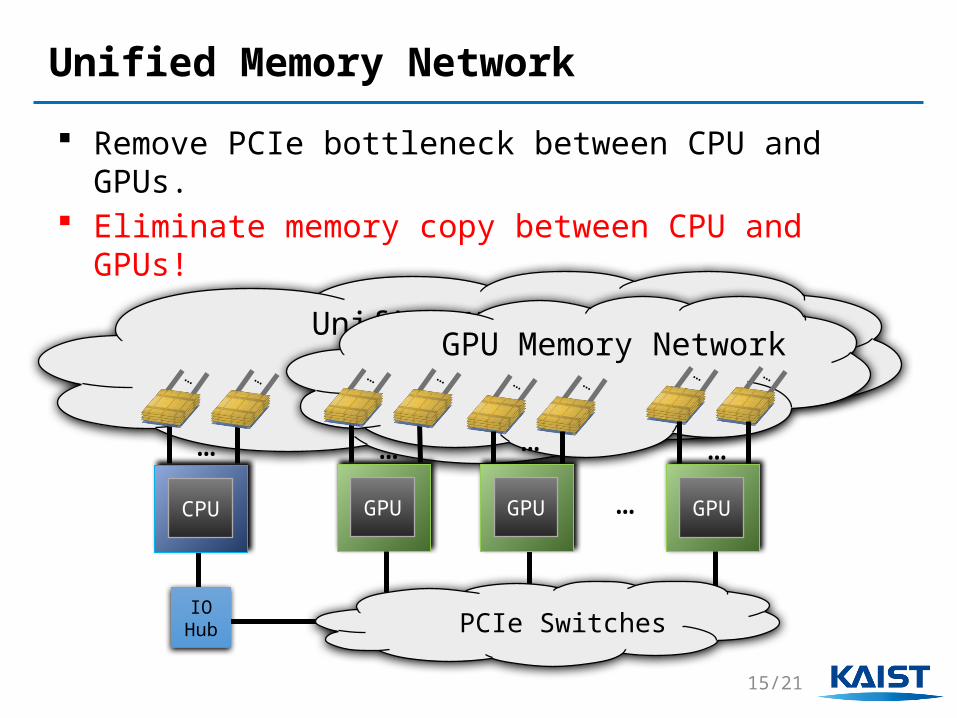
Unified Memory Network
Unified Memory Network
Remove PCIe bottleneck between CPU and GPUs. Eliminate memory copy between CPU and GPUs!
15/21
GPU … GPU
GPU Memory Network… … … …
… …
PCIe SwitchesIO
Hub
CPU
…
… …
… … …
GPU

Overlay Network Architecture
CPUs are latency-sensitive. GPUs are bandwidth-sensitive.
Off-chip linkOn-chip pass-thru path[PACT’13, FB-DIMM spec.]
CPU
GPU
GPU
GPU
16/21

Methodology
GPGPU-sim version 3.2 Assume SKE for evaluation Configuration
– 4 HMCs per CPU/GPU– 8 bidirectional channels per CPU/GPU/HMC– PCIe BW: 15.75 GB/s, latency: 600 ns– HMC: 4 GB, 8 layers, 16 vaults, 16 banks/vault, FR-FCFS– Assume 1CPU-4GPU unless otherwise mentioned.
Abbreviation Configuration
PCIe PCIe-based system with memcpy
GMN GPU memory network-based system with memcpy
UMN Unified memory network-based system (no copy)
17/21
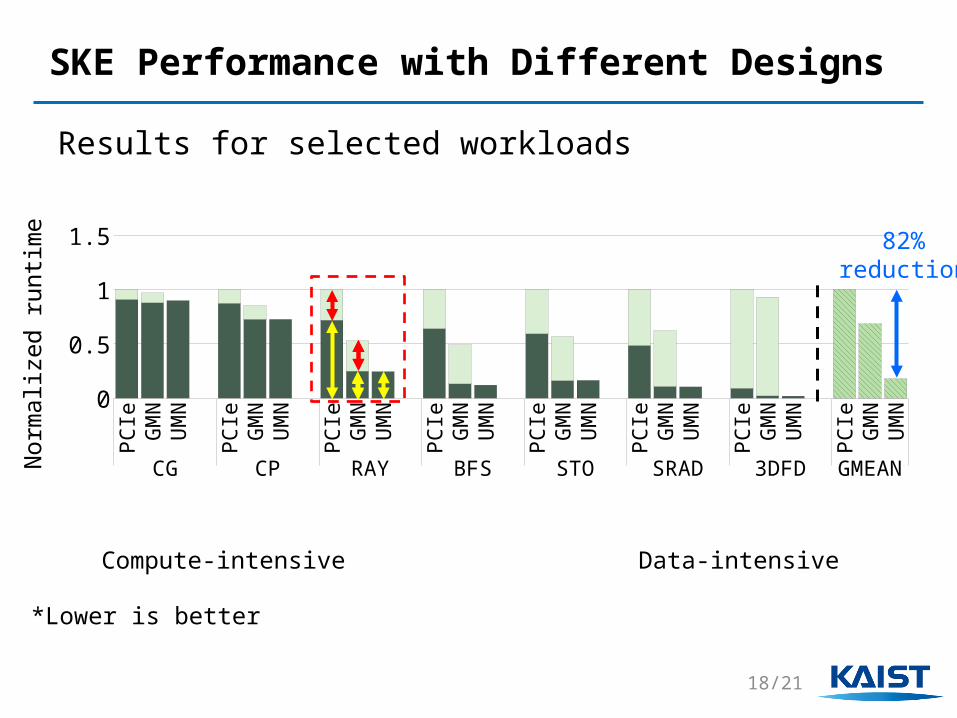
SKE Performance with Different Designs
Results for selected workloads
Compute-intensive Data-intensive
18/21
PC
IeG
MN
UM
N
PC
IeG
MN
UM
N
PC
IeG
MN
UM
N
PC
IeG
MN
UM
N
PC
IeG
MN
UM
N
PC
IeG
MN
UM
N
PC
IeG
MN
UM
N
PC
IeG
MN
UM
N
CG CP RAY BFS STO SRAD 3DFD GMEAN
0
0.5
1
1.5Kernel time Memcpy time Total runtime
Norm
alize
d r
unti
me
*Lower is better
82%reduction
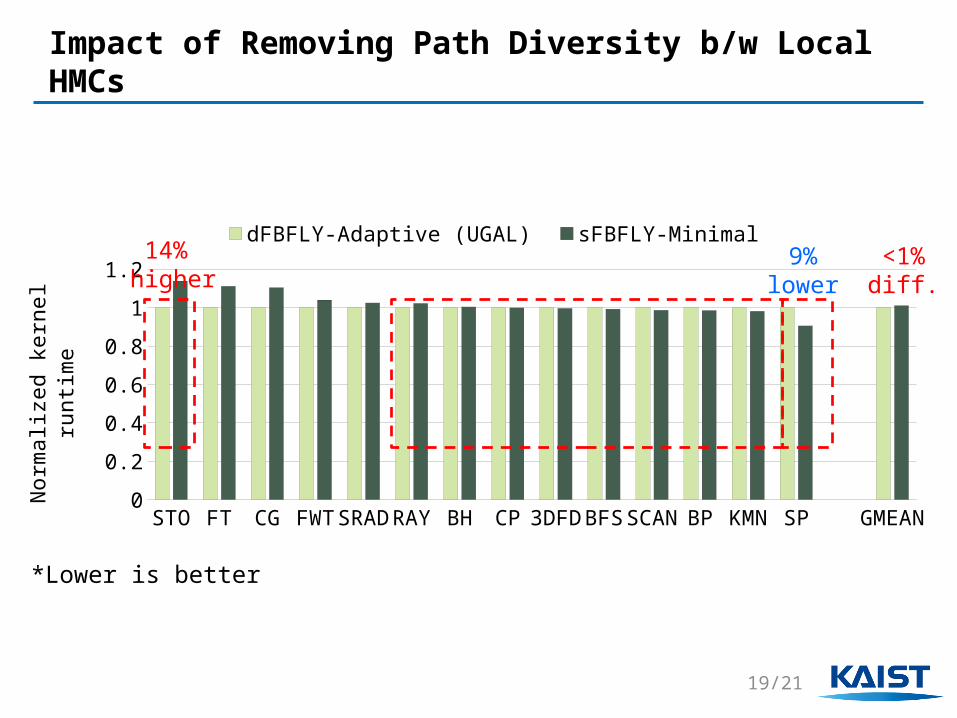
Impact of Removing Path Diversity b/w Local HMCs
STO FT CG
FWT
SRAD RAY BH CP
3DFD BF
S
SCAN BP
KMN SP
GMEA
N0
0.2
0.4
0.6
0.8
1
1.2dFBFLY-Adaptive (UGAL) sFBFLY-Minimal
Norm
aliz
ed k
ern
el ru
n-
tim
e
14% higher
9%lower
<1%diff.
19/21
*Lower is better

Scalability1 2 4 8
16 1 2 4 8
16 1 2 4 8
16 1 2 4 8
16 1 2 4 8
16 1 2 4 8
16 1 2 4 8
16 1 2 4 8
16
CP SCAN RAY 3DFD BP FWT SRAD GMEAN
0
4
8
12
16
Kern
el ru
nti
me
speedup
13.5x
20/21
*Higher is better
# GPUs
Compute-intensive Input sizenot large enough

Conclusion
We addressed two critical problems in multi-GPU systems with memory networks.
Inter-GPU communication- Improved bandwidth with GPU memory network- Scalable Kernel Execution Improved Programmability
CPU-GPU communication- Unified memory network Eliminate data transfer- Overlay network architecture
Our proposed designs improve both performance and programmability of multi-GPU systems.
21/21


















