
Monte Carlo Tree Search in 2014 (MCMC days in Marseille)
114
Monte-Carlo Tree Search O. Teytaud & colleagues ENSL / ski 2014 In a nutshell: - the game of Go, a great AI-complete challenge - MCTS, a great recent tool for MDP-solving - UCT & other maths - unsolved stuff
-
Upload
olivier-teytaud -
Category
Engineering
-
view
51 -
download
0
Transcript of Monte Carlo Tree Search in 2014 (MCMC days in Marseille)

Monte-Carlo Tree Search
O. Teytaud & colleaguesENSL / ski 2014
In a nutshell:- the game of Go, a great AI-complete challenge- MCTS, a great recent tool for MDP-solving- UCT & other maths- unsolved stuff

Monte-Carlo Tree Search
O. Teytaud & colleaguesENSL / Ski 2014
In a nutshell:- the game of Go, a great AI-complete challenge- MCTS, a great recent tool for MDP-solving- UCT & other maths- unsolved stuff If someone solves these problems,
it justifies a whole life ofacademic salary :-)

Monte Carlo
Classical Monte Carlo first.● We want to know E f(x)● We generate x1,...,xn● Ef(x) ~ average of the f(xi)

Monte Carlo with Decisions
Classical Monte Carlo with multiple time steps, an example.
● x=one year of weather data● f(x) = electricity production during this year● Ill defined: f(x) depends on my decisions
(switch on / switch off).● So f(x,d) with d = argmin f(x,d)
(assuming I make optimal decisions)

Monte Carlo with Decisions
So f(x,d) with d = argmin f(x,d) ● Still incorrect;
● x is 365dimensional.● d is 365dimensional● I can not know d360 when I decide d1.
So f(x) = E min E min … E min E min
x1 d1 x2 d2 …......... x365 d365

Monte Carlo with Decisions
So f(x) = E min E min … E min E min
x1 d1 x2 d2 …............... x365 d365
How to compute that ?
Define an approximate di = π(i, xi) (possibly randomized).
==> Randomly draw both x and the di.

Monte Carlo with Decisions
So f(x) = E min E min … E min E min
x1 d1 x2 d2 …............... x365 d365
==> Randomly draw both x and the di.
Problem:● Classical MC is consistent. ● Decisional MC is not consistent
==> we would like the di to be optimal.

“Adaptive” Monte Carlo
f(x) = E min E min … E min E min
x1 d1 x2 d2 …............... x365 d365
Ok we generate the di heuristically.
But we keep statistics.
And we “update” the heuristic with these statistics.
==> consistency !
MCTS is something like that.
(and there might be several “decision makers”)

Part I. A success story in Computer Games Part II. Two unsolved problems in Computer Games
Part III. Bandits, UCT & other math. stuff
Part IV. Conclusion

Part I : The Success Story(less showing off in part II :-) )
The game of Go is a beautifulChallenge.

Part I : The Success Story(less showing off in part II :-) )
The game of Go is a beautifulchallenge.
We did the first wins againstprofessional playersin the game of Go
But with handicap!

Game o f Go (9x9 here )

Game o f Go

Game o f Go

Game o f Go
Game o f Go
Game o f Go

Game o f Go

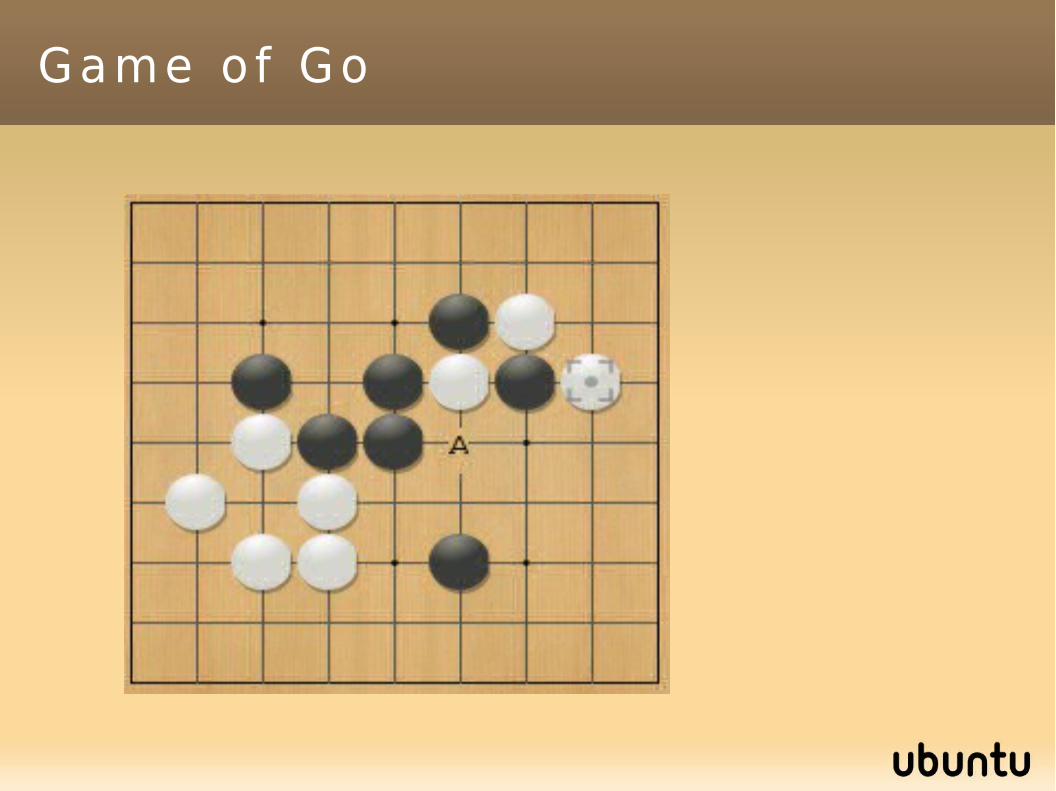
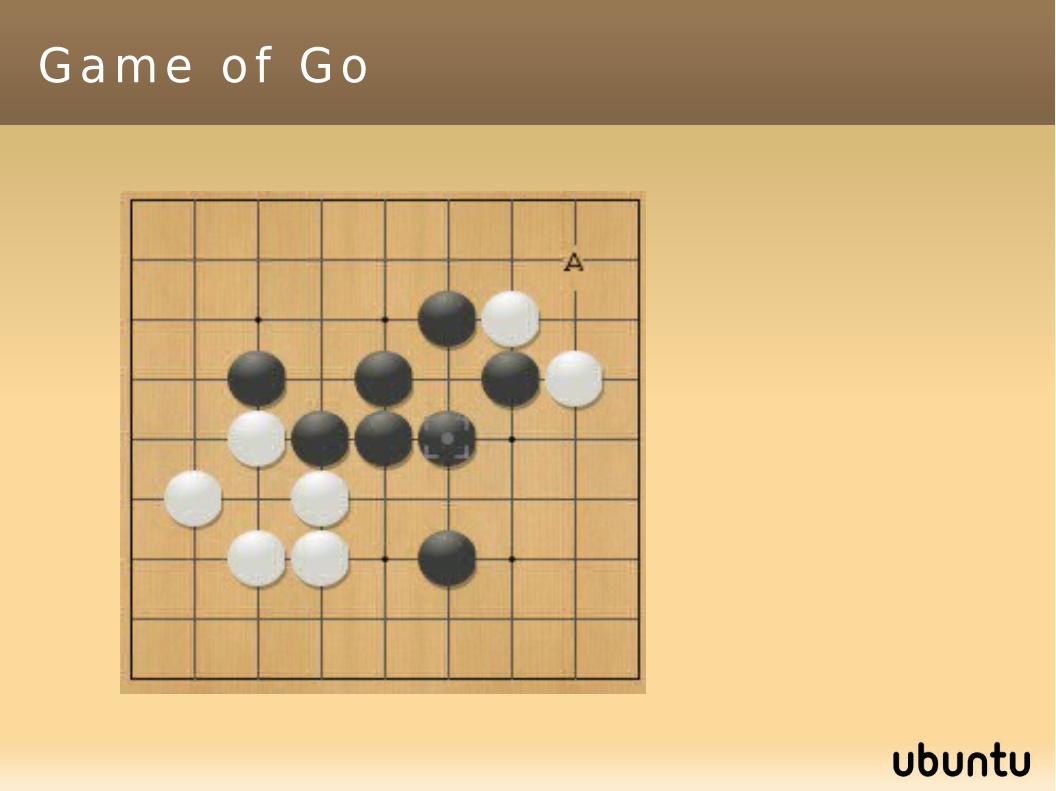
Game o f Go : count ing te r r i t o r ies( w h i t e h a s 7 . 5 “ b o n u s ” a s b l a c k s t a r t s )

Game of Go: the rulesBlack plays at the blue circle: the white group dies (it is removed)
It's impossible to kill white (two “eyes”).
“Superko” rule: we don't come back to the same situation.
(without superko: “PSPACE hard” with superko: “EXPTIME-hard”)
At the end, we count territories==> black starts, so +7.5 for white.

The rank of MCTS and classical programs in Go
(Source: Peter Shotwell+computer Go mailing list )
Stagnationaround 5D ?
MCTS
RAVE
MPI-parallelization
ML+Expertise, ...
Quasi-solvingof 7x7
Not overin 9x9...Alpha
beta

Coulom (06)Chaslot, Saito & Bouzy (06)Kocsis Szepesvari (06)
UCT (Upper Confidence Trees)(a variant of MCTS)
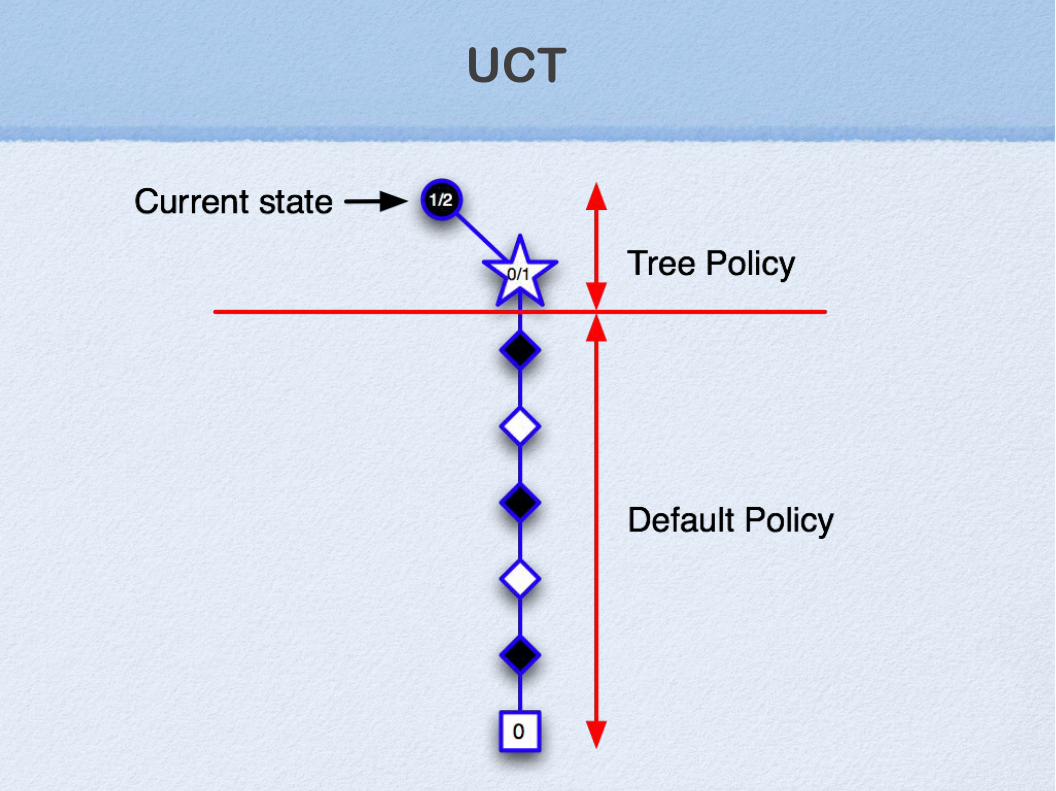
UCT

UCT

UCT
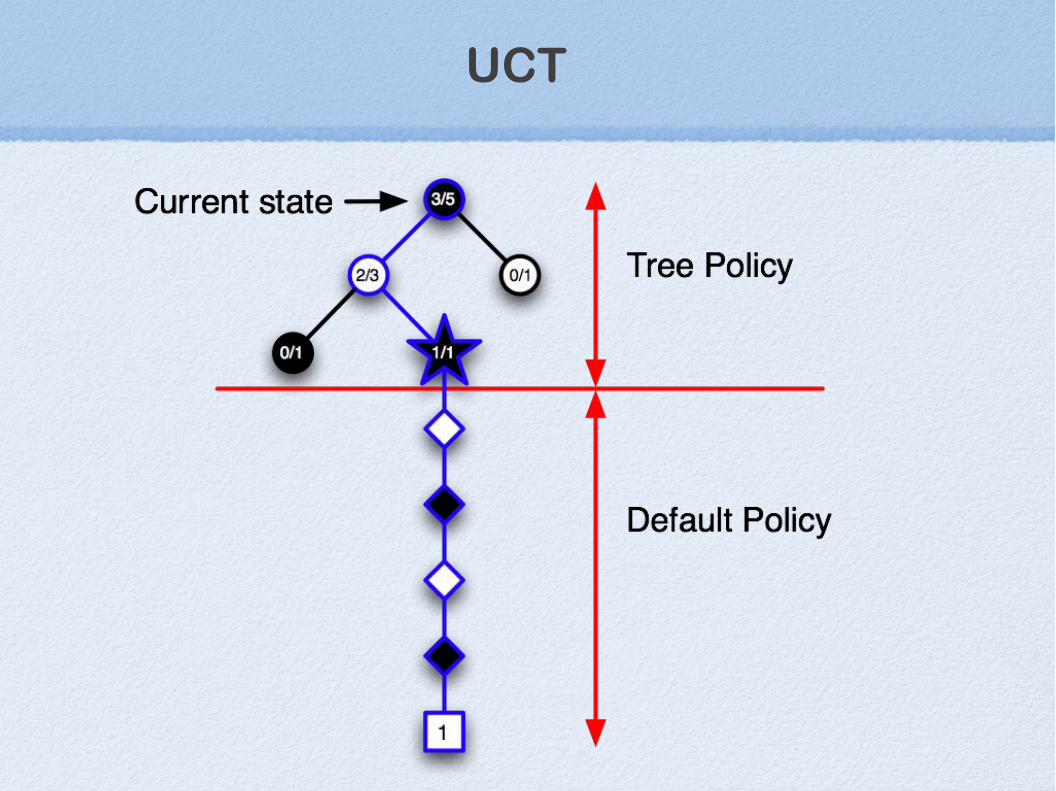
UCT

UCTKocsis & Szepesvari (06)

Exploitation ...

Exploitation ...
SCORE = 5/7 + k.sqrt( log(10)/7 )

Exploitation ...
SCORE = 5/7 + k.sqrt( log(10)/7 )

Exploitation ...
SCORE = 5/7 + k.sqrt( log(10)/7 )
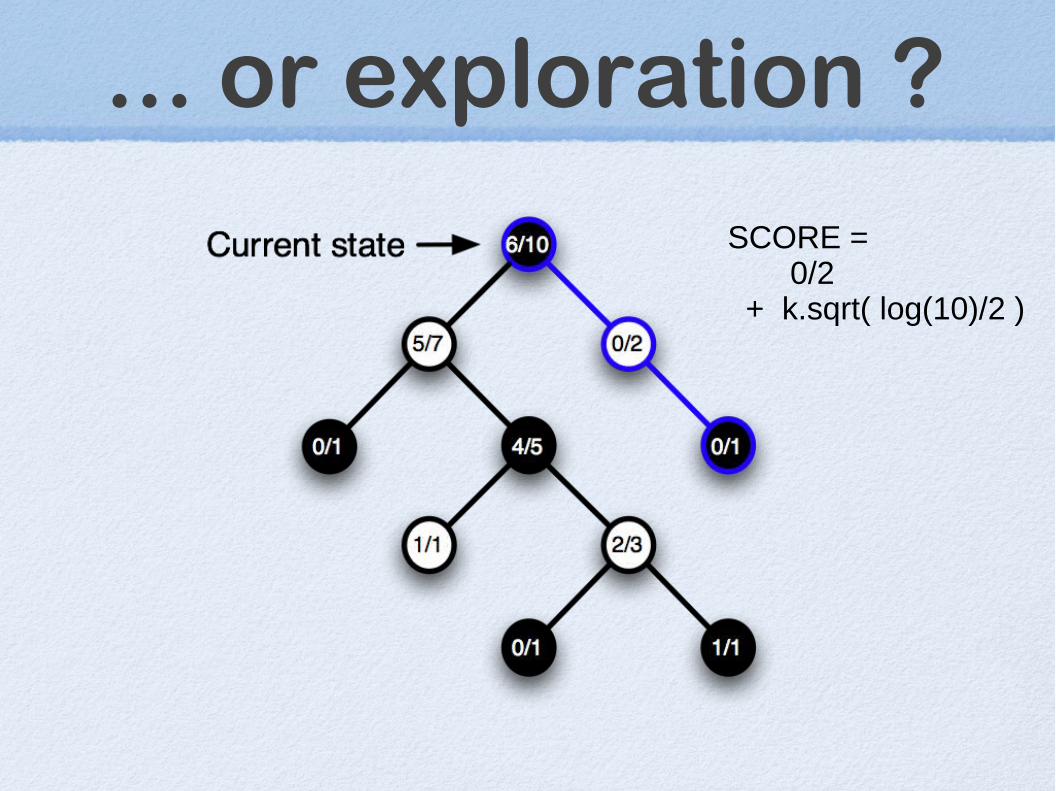
... or exploration ?
SCORE = 0/2 + k.sqrt( log(10)/2 )
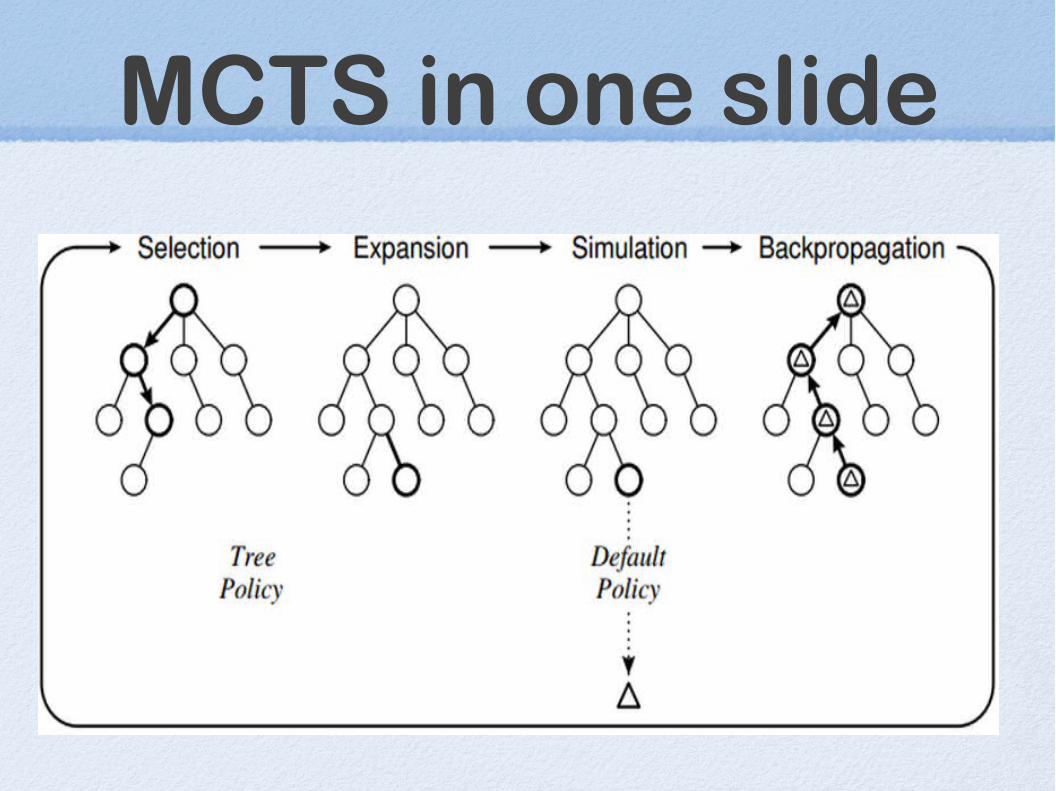
MCTS in one slide

Summary of MCTS• While ( we have time)
– S = state at which we need a decision
– Simulate randomly from S until end
– Update statistics
• Decision = most simulated in S
Using UCB

UCB and its variants
• We have seen the MCTS principle
• The most classical MCTS is UCT (i.e. MCTS with UCB)
• Let us see the UCB formula and its properties

Upper Confidence Bound
Problem specified by:- K arms- Probability distribution R1,...,RK- A budget T (# time steps)
During T time steps t=1,...,t=T, ( t=T+1 ):- we choose a
t in {1,...,K}
- we get a reward rt indep. drawn with distrib. R
at
We minimize a regret:- Cumulative regret R = T max
i E R
i -
- Simple regret maxi E R
i – R
a(T+1)
UCB: at=argmin averageReward(a) + sqrt( C log(t) / nb(a) )
==> reasonably good both for Simple & Cumulative

Stochastic bandit
Two main assumptions:● Stationary● Cumulative regret
Not true inMCTS
Average reward for arm k variance for arm k

“UCB” ?• I have shown the “UCB” formula (Lai, Robbins), which is
the difference between MCTS and UCT ( +sqrt(log t / nbSims) )

“UCB” ?• I have shown the “UCB” formula (Lai, Robbins), which is
the difference between MCTS and UCT
• The UCB formula has deep mathematical principles.

“UCB” ?• I have shown the “UCB” formula (Lai, Robbins), which is
the difference between MCTS and UCT
• The UCB formula has deep mathematical principles.
• But very far from the MCTS context.

“UCB” ?• I have shown the “UCB” formula (Lai, Robbins), which is
the difference between MCTS and UCT
• The UCB formula has deep mathematical principles.
• But very far from the MCTS context (indep, regret).
• Contrarily to what has often been claimed, UCB is not central in MCTS (but ok for proving convergence).

“UCB” ?• I have shown the “UCB” formula (Lai, Robbins), which is
the difference between MCTS and UCT
• The UCB formula has deep mathematical principles.
• But very far from the MCTS context.
• Contrarily to what has often been claimed, UCB is not central in MCTS (ok for proving convergence).
• But for publishing papers, relating MCTS to UCB is so beautiful, with plenty of maths papers in the bibliography :-)

Non stationary case
• Kocsis + Szepesvari 2006: UCB in non-stationary case
• Application to UCT:

Non stationary: Uct
• Kocsis + Szepesvari 2006: UCB in non-stationary case
• Application to UCT:
Huge problem-dependentconstant.
Only for finite MDP
B(D/2)iterations(Branching & Depth)Experiments (~ αβ)

Now variants
• ((( f(x) = noisy function, finding x such that E f(x) is minimum for x in [0,1]d )))
• Problem with infinite action space / state space
• And algorithms which work better than UCT in the discrete case

Infinite action space
• E.g. actions are continuous
• Infinite branching factor
• UCB meaningless in such a case
==> progressive widening: argmax UCBscore over n0.2 first options

Infinite MDP• Variant of UCT (Auger et al, 2013)
• Progressive widening: consider only a sublinear number of children nodes
• Exploration log(t) ==> te for some e>0
Error = O ( 1/n10D )
exponentially surely in n
Explicit rate, but itwill take time...

Without exploration
UcbScore(move) =
meanReward(move)
+ sqrt( log(t) / nbSims(move) )
Works very well in Go. Why ?

Binary rewards, without exploration(Berthier et al, 2009)
UcbScore(move) =
meanReward(move)
+ sqrt( log(t) / nbSims(move) )
mean = (numerator+K) / (denominator + 2K)

Adversarial banditDifferent framework:
the reward is M(k,k') where k' is chosen by an adversary(not aware or your choice).
Criteria are a bit different,algorithms are stochastic.
==> not for today.==> extends UCT to
simultaneous actions

The great news about the MCTS field:
● Not related to classical algorithms(no alpha-beta)
● Recent tools (Rémi Coulom's paper in 2006)
● Not at all specific from Go(now widely used in games,and beyond)

The great news:
● Not related to classical algorithms(no alpha-beta)
● Recent tools (Rémi Coulom's paper in 2006)
● Not at all specific from Go(now widely used in games,and beyond)
But great performance in Goneeds adaptations(of the MC part)...

Part II: challenges
Two main challenges:● Situations which require abstract thinking
(cf. Cazenave)● Situations which involve divide & conquer (cf Müller)

Part I. A success story on Computer Games
Part II. Two unsolved problems in Computer Games Part III. Some algorithms which do not solve them
Part IV. Conclusion
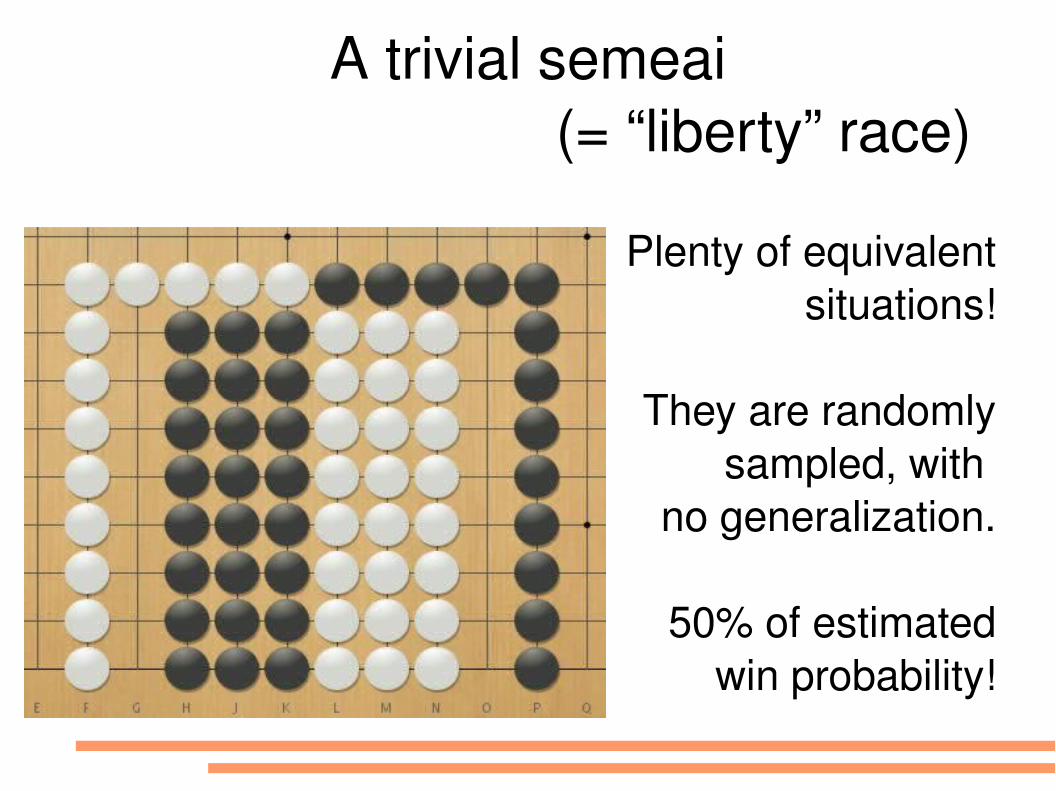
A trivial semeai(= “liberty” race)
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!

Semeai
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!

Semeai
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!

Semeai
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!

Semeai
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!

Semeai
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!

Semeai
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!

Semeai
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!

A trivial semeai
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!

A trivial semeai
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!

A trivial semeai
Plenty of equivalentsituations!
They are randomlysampled, with
no generalization.
50% of estimatedwin probability!
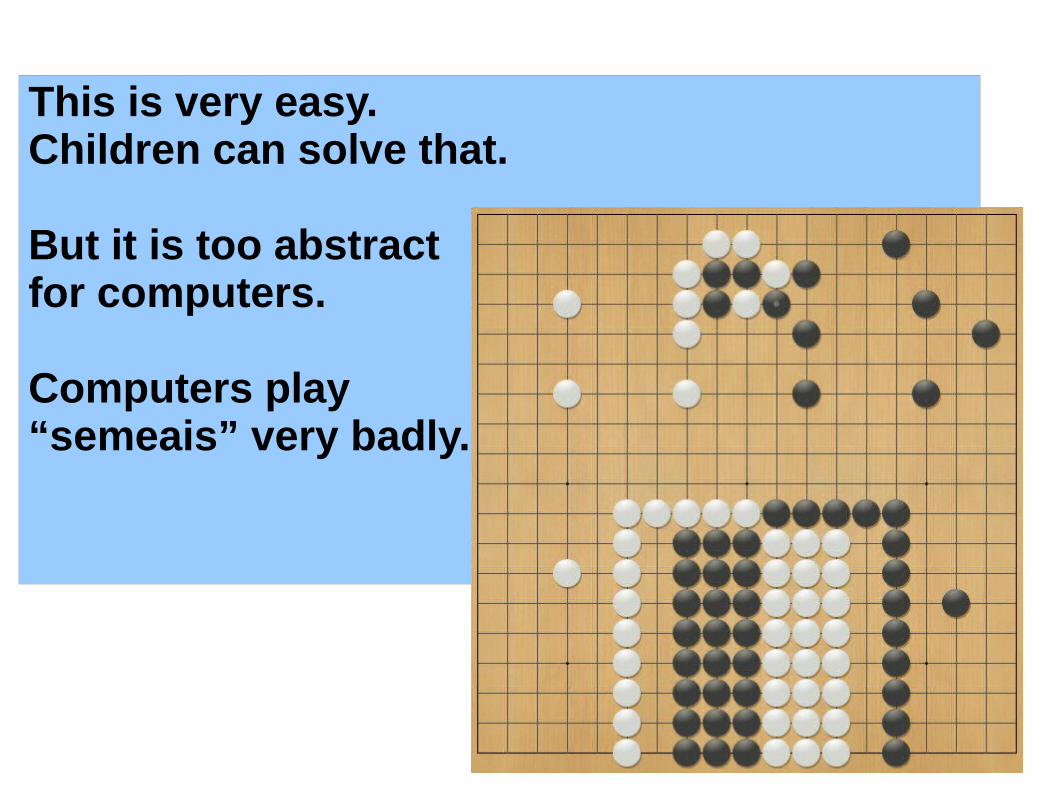
This is very easy.Children can solve that.
But it is too abstractfor computers.
Computers play“semeais” very badly.

It does not work. Why ?
50% of estimatedwin probability!
(~ 8! x 8! such nodes)

And the humans ?
Humans consider just one variation!

This was the first deceptive situation: plenty of symmetries
Another different context:problems that humans solve with
divide and conquer.

Requires more than local fighting.Requires combining several local fights.Children usually not so good at this.But strong adults really good.And computers very childish.
Looks like abad move,“locally”.
Lee Sedol (black)Vs
Hang Jansik (white)

Requires more than local fighting.Requires combining several local fights.Children usually not so good at this.But strong adults really good.And computers very childish.
Looks like abad move,“locally”.
Alive!

Part I. A success story on Computer Games
Part II. Two unsolved problems in Computer Games
Part III. Some algorithms which do not solve them (negatives results show that importance stuff is
really on II...)
Part IV. Conclusion

Part III: techniques for addressing these challenges
1. Parallelization
2. Machine Learning
3. Genetic Programming
4. Nested MCTS

Parallelizing MCTS• On a parallel machine with shared memory: just many
simulations in parallel, the same memory for all.
• On a parallel machine with no shared memory: one MCTS per comp. node, and 3 times per second:
– Select nodes with at least 5% of total sims (depth at most 3)
– Average all statistics on these nodes
==> comp cost = log(nb comp nodes)

Parallelizing MCTS• On a parallel machine with shared memory: just many
simulations in parallel, the same memory for all.
• On a parallel machine with no shared memory: one MCTS per comp. node, and 3 times per second:
– Select nodes with at least 5% of total sims (depth at most 3)
– Average all statistics on these nodes
==> comp cost = log(nb comp nodes)

Parallelizing MCTS• On a parallel machine with shared memory: just many
simulations in parallel, the same memory for all.
• On a parallel machine with no shared memory: one MCTS per comp. node, and 3 times per second:
– Select nodes with at least 5% of total sims (depth at most 3)
– Average all statistics on these nodes
==> comp cost = log(nb comp nodes)

Parallelizing MCTS• On a parallel machine with shared memory: just many
simulations in parallel, the same memory for all.
• On a parallel machine with no shared memory: one MCTS per comp. node, and 3 times per second:
– Select nodes with at least 5% of total sims (depth at most 3)
– Average all statistics on these nodes
==> comp cost = log(nb comp nodes)

Parallelizing MCTS• On a parallel machine with shared memory: just many
simulations in parallel, the same memory for all.
• On a parallel machine with no shared memory: one MCTS per comp. node, and 3 times per second:
– Select nodes with at least 5% of total sims (depth at most 3)
– Average all statistics on these nodes
==> comp cost = log(nb comp nodes)
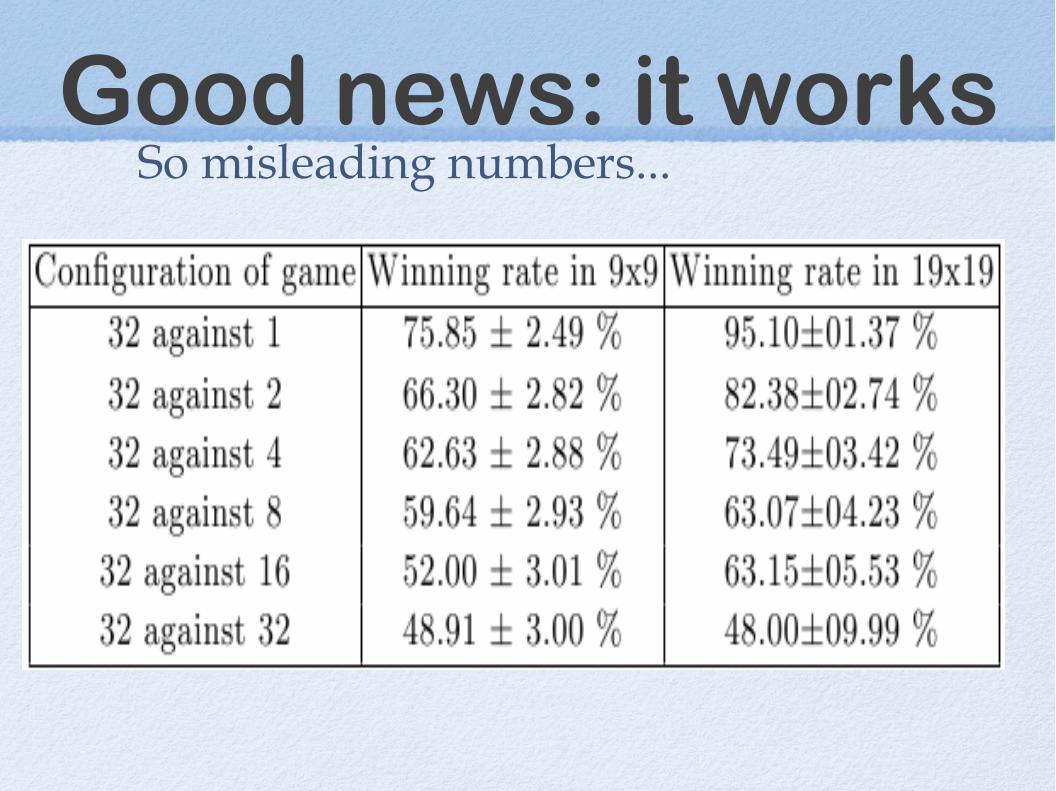
Good news: it worksSo misleading numbers...

Much better than voting schemes
But little difference with T. Cazenave (depth 0).
Every month, someone says:
Try with a biggermachine !
And win againsttop pros !
(I have believed that,at some point...)

In fact, “32” and “1”have almost the same level...
(against humans...)

Being faster is not the solution
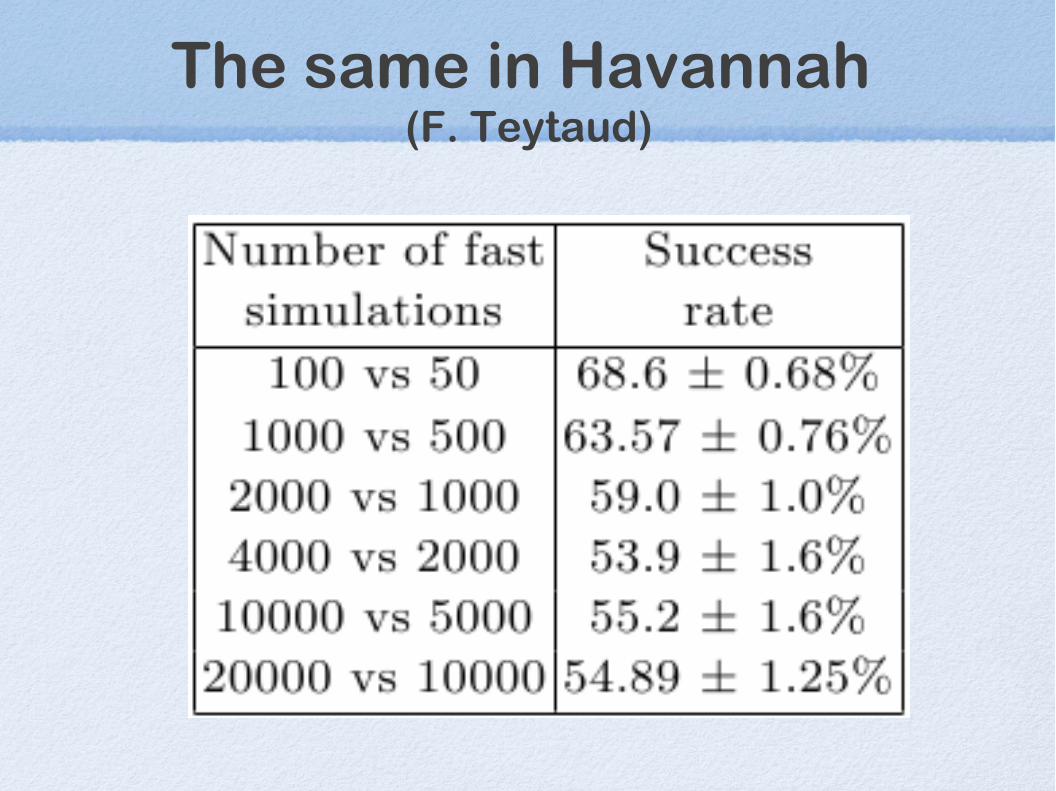
The same in Havannah (F. Teytaud)

More deeply, 1(R. Coulom)
Improvement in terms of performance against humans
<<
Improvement in terms of performance against computers
<<
Improvements in terms of self-play

More deeply, 2
No improvement in divide and conquer.
No improvement on situations
which require abstraction.

Part III: techniques for adressing these challenges
1. Parallelization
2. Machine Learning
3. Genetic Programming
4. Nested MCTS

What is machine learning ?
= using plenty of data
for deriving useful knowledge.

So it's statistics ?
Closely related to statistics
Just a bit more “geek”.

Machine learning
Good simulations are crucial.
It is a bit disappointing for thegenericity of the method.
Can we make thistuning automatic ?

MACHINE LEARNINGIN MCTS:
BIASING THETREE SEARCH

Rapid Action Value Estimates
ScoreUCB(m,s) = average reward whenplaying move m in situation ((( s + sqrt(...) )))
ScoreRAVE(m,s) = average reward whenplaying move m after situation s
==> asymptotically stupid (we want an estimate of m when it is played now, in s)
==> but non-asymptotically quite great

A classical machine learning trick in MCTS: RAVE (= rapid action value estimates)
score(move) = alpha UCB(move)
+ (1-alpha) RAVE(move) Alpha2 = nbSimulations / ( K + nbSimulations)
Usually works well, but performs weakly on some situations.
weakness: - brings information only from bottom to top of the tree - does not solve main problems - sometimes very harmful ==> extensions ?

A classical machine learning trick in MCTS: RAVE (= rapid action value estimates)
score(move,s) = alpha UCB(move,s)
+ (1-alpha) RAVE(move,s) Alpha2 = nbSimulations / ( K + nbSimulations)
Or better:● RAVE(m,s) = #cumRewardRAVE(m,s) / #simsRAVE(m,s)● #simsRAVE(m,s) initialized at 50● #cumRewardRAVE(m,s) initialized at 50 x expertise(m,s)
Currently, “expertise” is handcrafted.Can we do better with a neural network ?

Here B2 is the only good move for white.But B2 makes sense only as a first move, and nowhere else in subtrees ==> RAVE rejects B2.
==> extensions ?

Criticality: covariance between“succeeding at a location x”
and “global reward”

Criticality: how to use it ?
SimsCriticality = c x | Criticality |
● WinsCriticality= SimsCriticality if Criticality >0● WinsCriticality= 0 otherwise
==> Then, use WinsRAVE + WinsCriticality
and SimsRAVE + SimsCriticality

MACHINE LEARNINGIN MCTS:
BIASING THEMONTE CARLO PART
(well, trying to...)

Other Machine Learning tricks in MCTS
4 generic rules proposed recently: - Drake [ICGA 2009]: Last Good Reply- Silver and others: simulation balancing - poolRave [Rimmel et al, ACG 2011]- Contextual Monte-Carlo [Rimmel et al, E.G. 2010]- Decisive moves and anti-decisive moves
[Teytaud et al, CIG 2010]
==> significantly positive, but far less efficient than human expertise

Part III: techniques for adressing these challenges
1. Parallelization
2. Machine Learning
3. Genetic Programming
4. Nested MCTS

We don't want to use expert knowledge.We want automated solutions.
Developing biases by Genetic Programming ?
Genetic programming = optimizing programs.
E.g. optimizing the Monte Carlo simulator.
Typically by evolutionaryalgorithms.

We don't want to use expert knowledge.We want automated solutions.
Developing biases by Genetic Programming ?
Looks like a good idea.
But importantly:
A strong MC part(in terms of playing strength of the MC part),
does not imply (by far!)a stronger MCTS.
(except in 1P cases...)

We don't want to use expert knowledge.We want automated solutions.
Developing a MC by Genetic Programming ?
Hoock et alCazenave et al

Part III: techniques for addressing these challenges
1. Parallelization
2. Machine Learning
3. Genetic Programming
4. Nested MCTS

Nested MCTS in one slide(Cazenave, F. Teytaud, etc)
1) to a strategy, you can associate a value function
-Value(s) = expected reward when simulation with strategy
from state s

Nested MCTS in one slide(Cazenave, F. Teytaud, etc)
1) to a strategy, you can associate a value function
-Value(s) = expected reward when simulation with strategy
from state s
2) Then define: Nested-MC0(state)=MC(state) Nested-MC1(state)=decision maximizing
NestedMC0-value(next state)...
Nested-MC.42(state)=decision maximizing NestedMC.41-value(next state)

Nested MCTS in one slide(Cazenave, F. Teytaud, etc)
1) to a strategy, you can associate a value function
-Value(s) = expected reward when simulation with strategy
from state s
2) Then define: Nested-MC0(state)=MC(state) Nested-MC1(state)=decision maximizing
NestedMC0-value(next state)...
Nested-MC.42(state)=decision maximizing NestedMC.41-value(next state)
==> looks like a great idea==> not good in Go==> good on some less widely known testbeds (“morpion solitaire”, some hard scheduling pbs)

Part I. A success story on Computer Games
Part II. Two unsolved problems in Computer Games
Part III. Some algorithms which do not solve them
Part IV. Conclusion

Part IV: Conclusions
MCTS = algorithm from 2006● Born in AI for games● Slightly related to A* and αβ-iterative-deepening● Widely applicable.● UCT = one variant (try it first, then test)● RAVE & other statistics as a bias● Parallelization + expertise.● Some clearly identified problems:
- abstract thinking (AI complete ?)- divide & conquer

Part IV: Conclusions
Game of Go:
1- disappointingly, most recent progress = human expertise
2- UCB is not that much involved in MCTS (simple rules perform similarly) ==> publication bias

Part IV: Conclusions
Recent “generic” progress in MCTS:
1- application to GGP (general game playing): the program learns the rules of the game just before the competition, no last-minute development (fully automatized) ==> good model for genericity==> MCTS very good at this

Part IV: Conclusions
Recent “generic” progress in MCTS:
1- application to GGP (general game playing): the program learns the rules of the game just before the competition, no last-minute development (fully automatized)
2- one-player games: great ideas which do not work in 2P-games sometimes work in 1P games (e.g. optimizing the MC in a
DPS sense)

Part IV: Conclusions
3. Applications in video games (restricted state info)
4. PO games (Minesweeper)

ML techniques for
understandingfrom simulations
Abstractthinking (lookslike theorem
proving)
Understanding this “combination of local stuff”is impossible for computers
MCTS = versatile, somehow model-free,convenient, often great. What next ?
Can we compete with Alpha-Beta ine.g. Chess ?


















