
MongoDB
52
MongoDB (for Java Developers) Anthony Slabinck
-
Upload
anthony-slabinck -
Category
Technology
-
view
79 -
download
0
Transcript of MongoDB

MongoDB (for Java Developers)
Anthony Slabinck

Who am I?
• Internship at Provikmo
• 3 years 6 months
• Competitive cyclist

What is MongoDB?
• The leading NoSQL database (http://db-engines.com/en/)
• Open source
• Non-relational JSON document store
• BSON (Binary JSON)
• Dynamic schema
• Agile
• Scalable through replicaton and sharding
3

The leading NoSQL database
4
• LinkedIn Job Skills
• Google Search
• Indeed.com Trends

MongoDB relative to relational databases
5

Who uses MongoDB?
6

By use case
• Single View
• Internet of Things
• Mobile
• Real-Time Analytics
• Personalization
• Content Management
• Catalog
7

From relational databases to MongoDB
8
{
first_name: "Anthony",
surname: "Slabinck",
city: "Bruges",
location: [45.123,47.232],
cars: [
{ model: "Bentley",
year: 1973,
value: 100000 },
{ mode: "Rolls Royce",
year: 1965,
value: 330000 } ]
}

MongoDB is full featured
9

MongoDB CRUD Operations
10
Documents

MongoDB CRUD Operations
11
Collections

MongoDB CRUD Operations
12
Read operations

MongoDB CRUD Operations
13
Read operations

MongoDB CRUD Operations
14
Write operations - insert

MongoDB CRUD Operations
15
Write operations - update

MongoDB CRUD Operations
16
Write operations - remove

Installation
• Download MongoDB from http://www.mongodb.org/downloads
• Download the Java Driver (maven)
• mongod
• Daemon process
• mongo
• Interactive JavaScript shell interface
• Robomongo
• Cross-platform management tool
17
Getting started with MongoDB
18
Demo

Data Models
• Flexible schema
• Collections do not enforce document structure
• Consider how applications will use your database
• No foreign keys, no joins
• Relationships between data
• Embedded documents
• References
• Documents require a unique _id field that acts as a primary key
19

Data Models
• Denormalized
• Better read performance
• Single atomic write operation
• Document growth
• Dot notation
20
Embedded Data Models

Data Model
• One-to-One Relationship
21
Embedded Data Models
{
_id: "infasla",
name: "Anthony Slabinck",
address: {
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
}

Data Model
• One-to-Many Relationship
22
Embedded Data Models
{
_id: "infasla",
name: "Anthony Slabinck",
addresses: [
{ street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345" },
{ street: "1 Other Street",
city: "Boston",
state: "MA",
zip: "12345"
}
]
}

Data Model
• Normalized
• Duplication of data
• Complex many-to-many
relationships
• Follow-up queries
23
References

Data Model
• One-to-Many Relationship
{ _id: "oreilly",
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
{ _id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly"
}
{ _id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher_id: "oreilly"
}
24
References
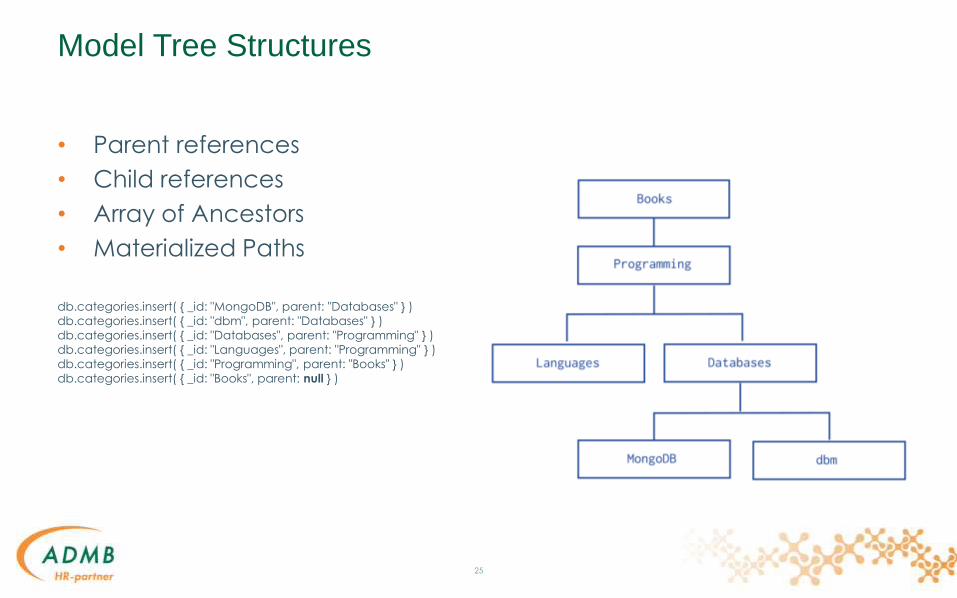
Model Tree Structures
• Parent references
• Child references
• Array of Ancestors
• Materialized Paths
db.categories.insert( { _id: "MongoDB", parent: "Databases" } )
db.categories.insert( { _id: "dbm", parent: "Databases" } )
db.categories.insert( { _id: "Databases", parent: "Programming" } )
db.categories.insert( { _id: "Languages", parent: "Programming" } )
db.categories.insert( { _id: "Programming", parent: "Books" } )
db.categories.insert( { _id: "Books", parent: null } )
25

GridFS
• BSON-document size limit of 16MB
• Divides a file into parts, or chunks and stores each of those chunks as
a separate document
• Two collections
• File chunks
• File metadata
• Reassemble chunks as needed
26

Capped Collections
• Fixed-size collections
• Insert and retrieve documents based on insertion order
• Automatically removes the oldest document
• Ideal for logging
27

Aggregation
• Operations that process data records and return computed results
• Simplifies application code
• Limits resource requirements
• Aggregation modalities
• Aggregation pipelines
• Map-Reduce
• Single purpose aggregation operations
28

Aggregation
• Stages
• Preferred method
29
Aggregation pipelines

Aggregation
• Two phases
• JavaScript functions
• Less efficient and more
complex than the aggregation
pipeline
30
Map-Reduce
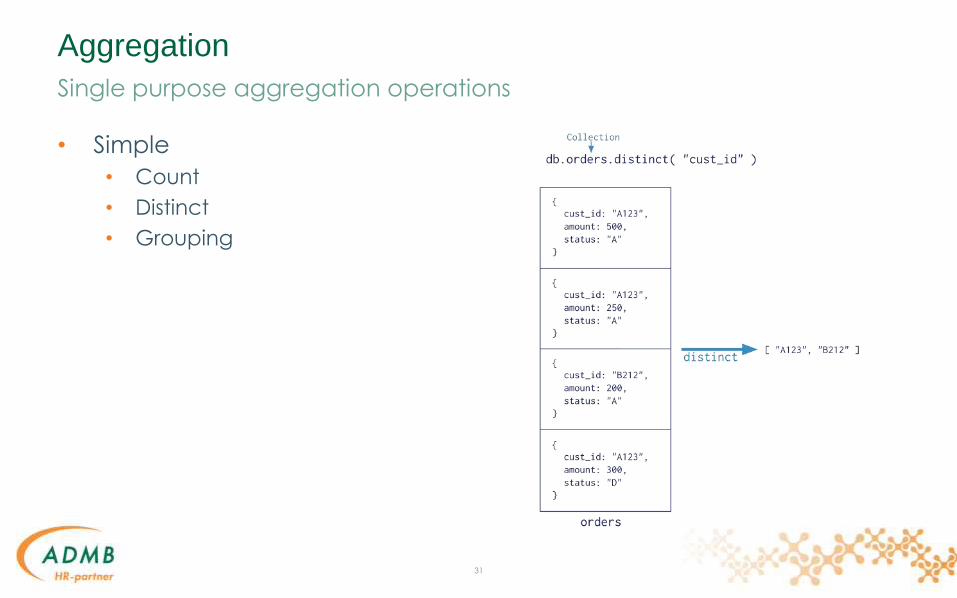
Aggregation
• Simple
• Count
• Distinct
• Grouping
31
Single purpose aggregation operations

Indexes
• Efficient execution of queries
• Data structure
• Stores the value of a specific
field or set of fields, ordered by
value the field
• Create indexes that support
your common and user-facing
queries
32

Indexes
• Default _id
• Single Field
• Compound Index
• Multikey Index
• Geospatial Index
• Text Indexes
• Hashed Indexes
33
Types

Indexes
• Unique Indexes
• Sparse Indexes
• TTL Indexes
34
Properties

Indexes
• db.people.ensureIndex( { zipcode: 1 } )
• db.people.ensureIndex( { zipcode: 1 }, { background: true } )
• db.people.ensureIndex( { zipcode: 1 }, { background: true, sparse: true } )
• db.accounts.ensureIndex( { username: 1 }, { unique: true, dropDups: true } )
35
Creation

Replication
• What?
• Synchronizing data across multiple servers
• Purpose?
• Provides redundancy and increases data availability
36

Replication
• A group of mongod instances
that host the same data set
• Primary receives all write
operations
• Primary logs all changes in its
oplog
• Secondaries apply operations
from the primary
37
Replica set
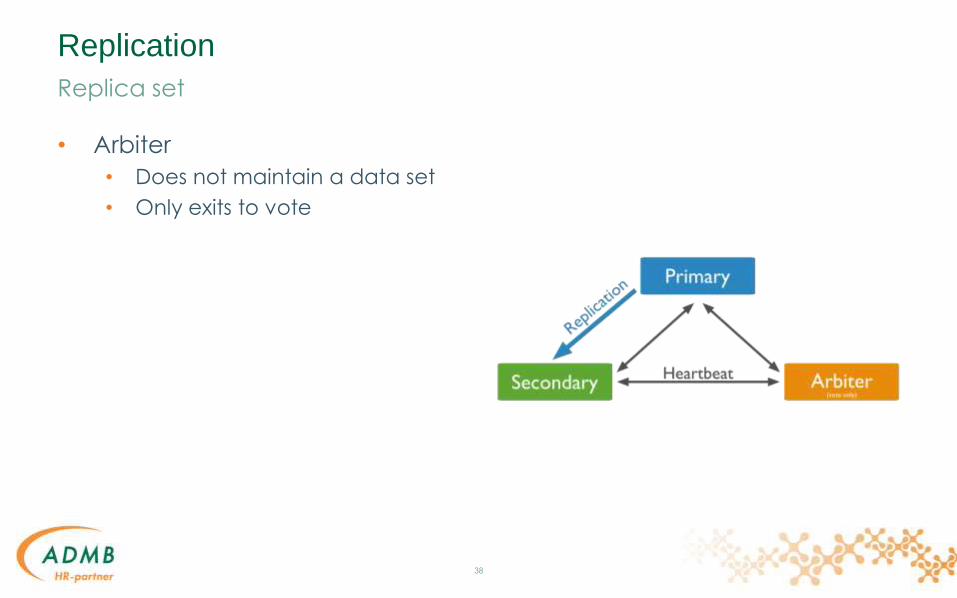
Replication
• Arbiter
• Does not maintain a data set
• Only exits to vote
38
Replica set

Replication
39
Replica set
• Automatic failover

Replication
• Additional features:
• Read preference
• Priority
• Hidden members
• Delayed members
40
Replica set

Sharding
• What?
• Storing data across multiple machines
• When?
• High query rates exhaust the CPU capacity of the server
• Larger data sets exceed the storage capacity of a single machine
• Working set sizes larger than the system’s RAM stress the I/O capacity of disk drives
41

Sharding
• Adds more CPU and storage
42
Vertical scaling – scale up
Scale
Pri
ce

Sharding
• Distributes the data
43
Horizontal scaling – scale outP
ric
e
Scale

Sharding
• Shards store the data
• Query Routers interface with
client applications and direct
operations
• Config servers store the
cluster’s metadata
44
Sharded cluster

Sharding
• Collection level
• Shard key
• Indexed field or an indexed
compound field that exists in
every document
• Chunks
• Range based partitioning
• Hash based partitioning
• Automatic balancing
45
Data partitioning

MongoDB Architecture
46

MongoDB at scale
• Cluster scale
• Distributing across 100+ nodes in multiple data centers
• Performance scale
• 100K+ database reads and writes per second while maintaining strict SLAs
• Data scale
• Storing 1B+ documents in the database
47
Metrics
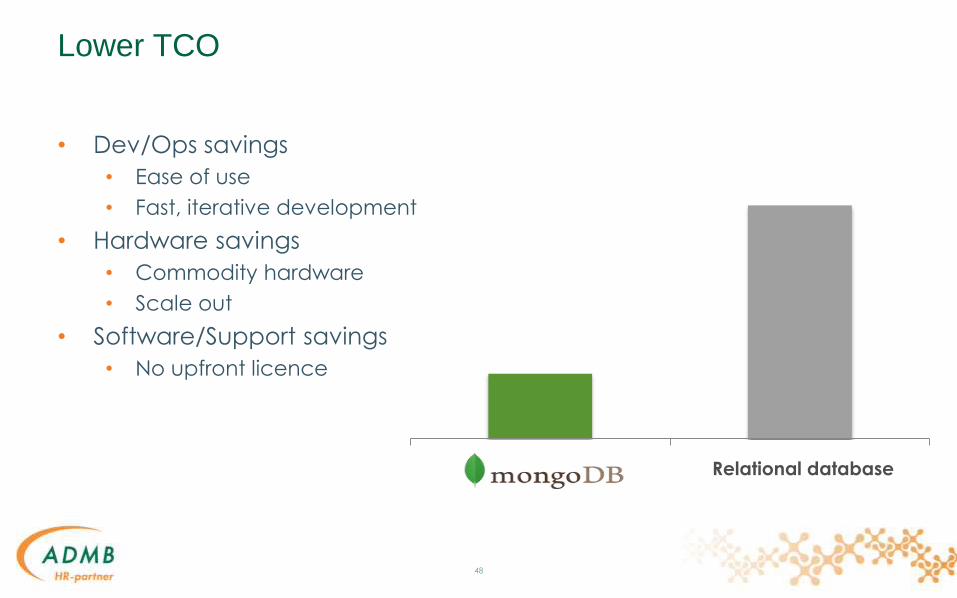
Lower TCO
• Dev/Ops savings
• Ease of use
• Fast, iterative development
• Hardware savings
• Commodity hardware
• Scale out
• Software/Support savings
• No upfront licence
48
Relational database

POJO Mappers
• Morphia
• Spring Data MongoDB
• Hibernate OGM
49

Resources
• http://docs.mongodb.org/manual/
• https://university.mongodb.com/
• M101J: MongoDB for Java Developers
• M102: MongoDB for DBAs
50

Building an App with MongoDB
51
Demo

Questions?
52


















