
Modeling Expressive Performances of the Singing Voice Maria-Cristina Marinescu (Universidad Carlos...
23
Modeling Expressive Performances of the Singing Voice Maria-Cristina Marinescu (Universidad Carlos III de Madrid) Rafael Ramirez (Universitat Pompeu Fabra)
-
Upload
rodger-goodwin -
Category
Documents
-
view
218 -
download
0
Transcript of Modeling Expressive Performances of the Singing Voice Maria-Cristina Marinescu (Universidad Carlos...

Modeling Expressive Performances of the Singing Voice
Maria-Cristina Marinescu (Universidad Carlos III de Madrid)
Rafael Ramirez (Universitat Pompeu Fabra)
voice
style
timbre
interpretation
musicality
resonance
technique
color
fluidity
The human singing voice
voice
style
timbre
interpretation
musicality
resonance
technique
color
fluidity
Acoustic Features:• Pitch• Timing• Timbre• Articulation• Spectral energy distribution
Verbal Features:Intonational phrasing
The human singing voice

Our long-term goal
Develop models of operatic singers…and generate expressive performances similar in voice
quality and interpretation• Why opera?
– Constrained environment (score, libretto) makes comparison between singers and classification of expressive content easier
– Better voice and technique make singers more effective in performing expressively
1. Entertainment tool – generate interpretations of songs never recorded
2. Learning tool – use by professionals to learn different aspects of expressive singing
3. Re-mastering old records4. Understand evolution of classical singing in terms of
impact and inspiration of singers

Our long-term goal
Develop models of operatic singers…and generate expressive performances similar in voice
quality and interpretation

In this work
Develop models of operatic singers…and generate expressive performances similar in voice
quality and interpretation
Acoustic Features:• Pitch• Timing• Timbre• Articulation• Spectral energy distribution

Timing models of expressive performance
commercial audio recordings
high-level descriptors
singer-specific models
extract
train
• Properties of musical events• Musical event = note
• Inter-note features – context of musical events
Learn predictions for note duration based on h-l descriptor patterns.
expressive performance
evaluate
Predict duration of each note in test melody.How close are performed / predicted values?

High-level descriptors
• Characterize the melody based on:– Score– Performance

High-level descriptors
• Characterize the melody based on:– Score:
• Note properties: pitch, duration, meter strength, note density
EH M L H

High-level descriptors
• Characterize the melody based on:– Score:
• Note properties: pitch, duration, meter strength, note density
• Context: neighbours’ relative pitch and interval length, Narmour structures

High-level descriptors
• Characterize the melody based on:– Score:
• Note properties: pitch, duration, meter strength, note density
• Context: neighbours’ relative pitch and interval length, Narmour structures
– Performance: note onset and duration OUT

High-level descriptors
• Characterize the melody based on:– Score:
• Note properties: pitch, duration, meter strength, note density
• Context: neighbours’ relative pitch and interval length, Narmour structures
– Performance: note onset and duration– Score + performance: actual tempo

Timing models of expressive performance – extracting descriptors
commercial audio recordings
high-level descriptors
singer-specific models
extract
train
expressive performance
evaluate
Score pitch, duration: manuallyNote onset and duration: sound analysis techniques
based on spectral modelsMeter strength: automatically computed
based on note lengthNote density: manually computed for whole melodyNarmour structure: automatically generate I/R
analysis based on scoreActual tempo: manually computed based on
score and melody duration
.wav files

Timing models of expressive performance – learning and validation
commercial audio recordings
high-level descriptors
singer-specific models
extract
train
expressive performance
WEKA – model trees:
- Generate decision list for regression problem using separate-and-conquer- Build model tree and make best leaf into rule
– test set evaluation:- Predict note durations for test cases
evaluate

Our data set
6 tenor arias by Verdi – 415 notes1. Operatic
2. A cappella
3. Consistent composition style
4. Consistent interpretation style
5. Live

Our data set
6 tenor arias by Verdi – 415 notes1. Operatic
2. A cappella
3. Consistent composition style– Verdi’s middle years (1840-1855)– … maybe with exception of Rigoletto
4. Consistent interpretation style
5. Live

Our data set
6 tenor arias by Verdi – 415 notes1. Operatic
2. A cappella
3. Consistent composition style– Verdi’s middle years (1840-1855)– … maybe with exception of Rigoletto
4. Consistent interpretation style– Josep Carreras mid 70s – beginning 80s
5. Live

Experimental results – training and testing per aria
• Predict note duration as a function of h-l descriptors• Compare predicted with actual (performed)• Training/testing task: 80% percentage split evaluation
Aria Correl coeffElla mi fu rapita! 0.74Un di, felice, eterea 0.72De miei bollenti spiriti 0.46Forse la soglia attinse 0.57Oh fede negar potessi! 0.29La pia materna mano 0.20All arias (4/4) 0.56
no correlation
Widely diverse actual tempos and note densities!110 / 89 / 54 / 76 / 59 4.62 / 5.66 / 3.6 / 3.47 / 4.71
1 2 3 4 5 6 7 8
Note number
Rel
ativ
e d
ura
tio
n
0
1
2
3
2.5
1.5
0.5
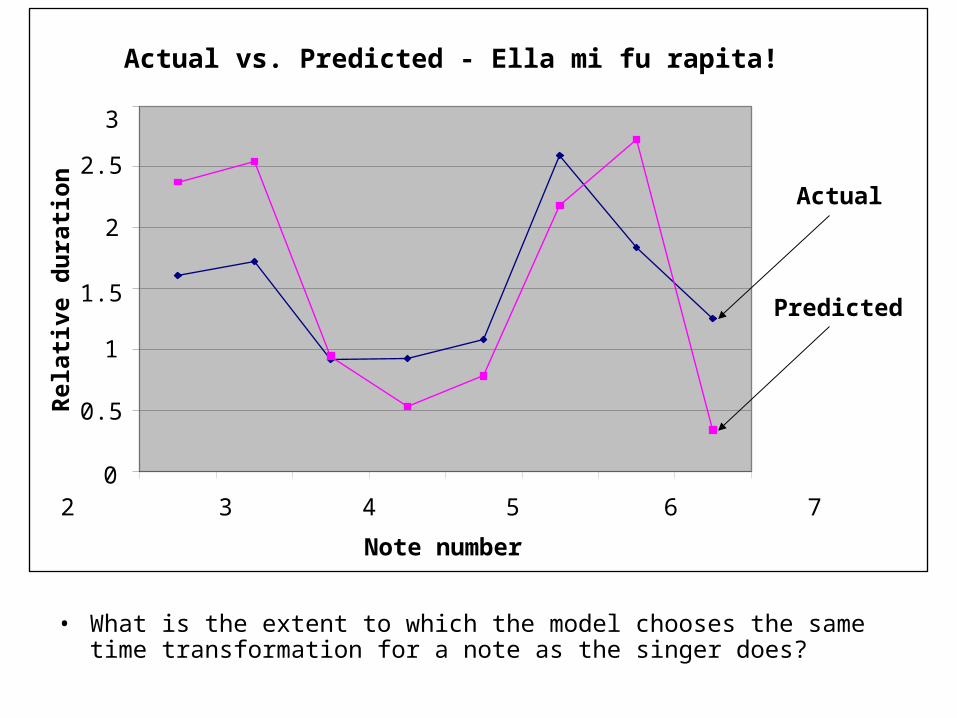
Actual vs. Predicted - Ella mi fu rapita!
Actual
Predicted
• What is the extent to which the model chooses the same time transformation for a note as the singer does?
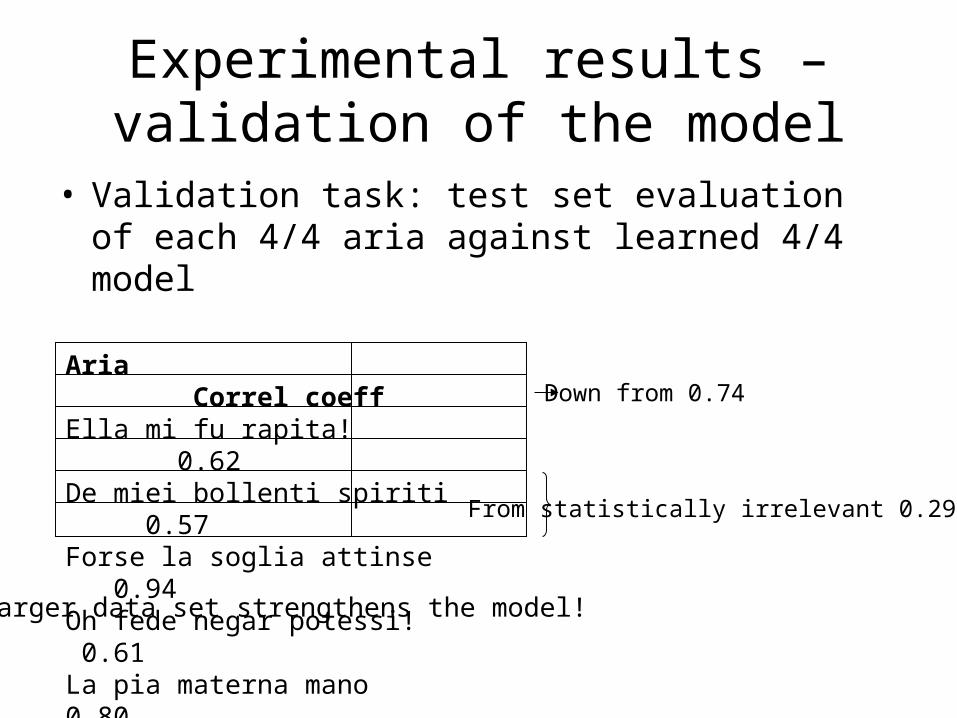
Experimental results – validation of the model
• Validation task: test set evaluation of each 4/4 aria against learned 4/4 model
Aria Correl coeffElla mi fu rapita! 0.62De miei bollenti spiriti 0.57Forse la soglia attinse 0.94Oh fede negar potessi! 0.61La pia materna mano 0.80
Larger data set strengthens the model!
From statistically irrelevant 0.29 / 0.2
Down from 0.74
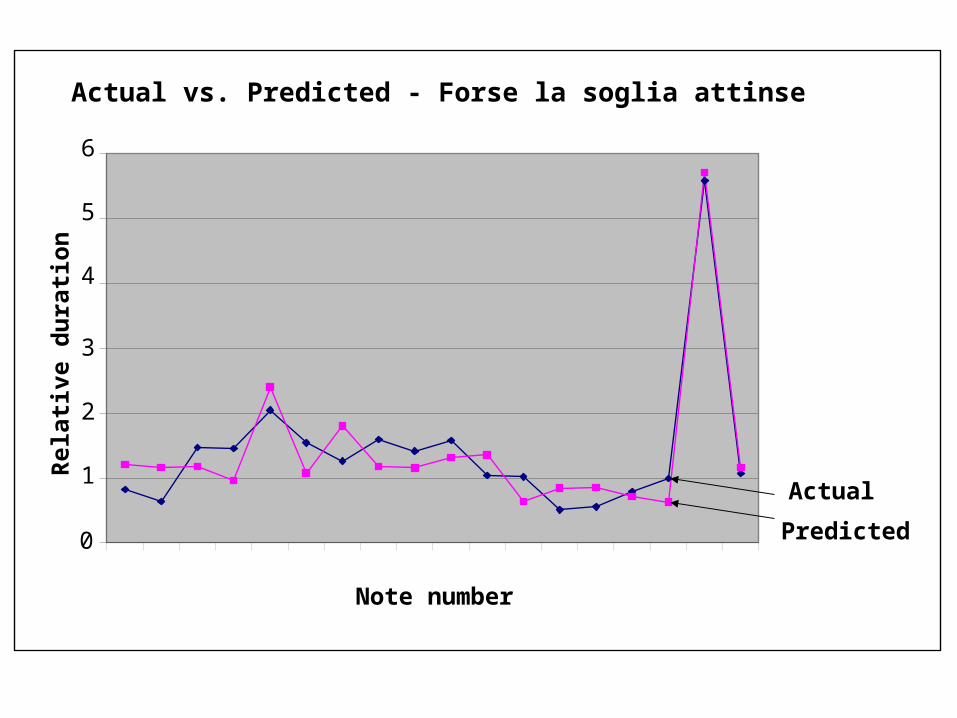
Rel
ativ
e d
ura
tio
n
Note number
Actual
Predicted
Actual vs. Predicted - Forse la soglia attinse
0
1
2
3
4
5
6

Work in progress and future work
• Add more arias• Add more acoustic features to singer-specific
model– Currently: energy model– Future: timbre, exagerration, pitch range, accent shape,
articulation
• Add more input parameters– Currently: syllable information (open/closed,
stressed/unstressed)– Future: intonational phrasing

Questions?


















