
Model answer for Data Structure using C PART-A O(1) and Answer- BTCS1206 Data Structures... ·...
26
Model answer for Data Structure using C PART-A 1. a) The best case and wrst case time complexity of binary search is O(1) and O(log 2 n ). b) The following structure is ued to implement a node in a linked list struct node { int data; struct node *link; }first; c) Queue and Stack data structures are used for implementation of BFS and DFS algorithms. d) The address of a[3][3] is 1098. e) Five different trees are possible with 3 nodes . The figures are given below f) In Double ended queue data structure the elements can be inserted or removed only at either end but not in the middle. g) The maximum number of nodes in a binary tree of height ―h‖ is 2 h+1 -1. h) Array data struture is used for implementing heap sort. i) The minimum number of fields in a doubly linked list are 3 . j) The given Prefix expression is *+AB-CD. Its postfix form is AB+CD-* .
-
Upload
phungquynh -
Category
Documents
-
view
220 -
download
2
Transcript of Model answer for Data Structure using C PART-A O(1) and Answer- BTCS1206 Data Structures... ·...

Model answer for Data Structure using C PART-A
1.
a) The best case and wrst case time complexity of binary search is O(1) and
O(log2 n ).
b) The following structure is ued to implement a node in a linked list
struct node
{
int data;
struct node *link;
}first;
c) Queue and Stack data structures are used for implementation of BFS and DFS
algorithms.
d) The address of a[3][3] is 1098.
e) Five different trees are possible with 3 nodes . The figures are given below
f) In Double ended queue data structure the elements can be inserted or
removed only at either end but not in the middle.
g) The maximum number of nodes in a binary tree of height ―h‖ is 2h+1 -1.
h) Array data struture is used for implementing heap sort.
i) The minimum number of fields in a doubly linked list are 3 .
j) The given Prefix expression is *+AB-CD. Its postfix form is AB+CD-* .

PART-B
2 a) Algorithm for PUSH operation using array
PUSH(STACK,TOP,MAX,ITEM)
This procedure add an item on to a stack
1.If TOP=MAX then print OVERFLOW and EXIT
2.Set TOP=TOP+1
3.Set STACK[TOP]=ITEM
4.EXIT
POP(STACK,TOP,ITEM)
This procedure delete the top element of STACK
1.If Top=0,then print “Underflow” and exit
2.Set ITEM=STACK[TOP]
3.Set TOP=TOP-1
4.Exit
b) Given infix expressiion Q = ((A+B) *C-(D-E)) ^ (F+G)
Intially we insert a '(' in to stack and add ')' to Q. so
Q =((A+B) *C-(D-E)) ^ (F+G) )
Symbol Scanned STACK Postfix Expression
(
1.( ((
2.( (((

3.A ((( A
4.+ (((+ A
5.B (((+ AB
6.) (( AB+
7.* ((* AB+
8.C ((* AB+C
9.- ((- AB+C*
10.( ((-( AB+C*
11.D ((-( AB+C*D
12.- ((-(- AB+C*D
13.E ((-(- AB+C*DE
14.) ((- AB+C*DE-
15.) ( AB+C*DE--
16.^ (^ AB+C*DE--
17.( (^( AB+C*DE--
18.F (^( AB+C*DE—F
19.+ (^(+ AB+C*DE—F
20.G (^(+ AB+C*DE—FG
21.) (^ AB+C*DE—FG+
22.) AB+C*DE—FG+^
The equivalent postfix expression is AB+C*DE—FG+^
3. a) Algorithm for ENQUEUE (insert element in Queue)
Input : An element say ITEM that has to be inserted.
Output : ITEM is at the REAR of the Queue.
Data structure : Que is an array representation of queue structure with two pointer FRONT and
REAR.
Steps:
1. If ( REAR = size ) then //Queue is full

2. print "Queue is full"
3. Exit
4. Else
5. If ( FRONT = 0 ) and ( REAR = 0 ) then //Queue is empty
6. FRONT = 1
7. End if
8. REAR = REAR + 1 // increment REAR
9. Que[ REAR ] = ITEM
10. End if
11. Stop
Algorithm for DEQUEUE (delete element from Queue)
Steps:
1. If ( FRONT = 0 ) then
2. print "Queue is empty"
3. Exit
4. Else
5. ITEM = Que [ FRONT ]
6. If ( FRONT = REAR )
7. REAR = 0
8. FRONT = 0
9. Else
10. FRONT = FRONT + 1
11. End if
12. End if
13. Stop
b) C function to count the number of nodes in a single linked list

void count()
{
struct node *temp;
int length = 0;
temp = start;
while(temp!=NULL)
{
length++;
temp=temp->next;
}
printf("nLength of Linked List : %d",length);
}
C function to reverse a single linked list
void reverse() {
if(head == null)
;
Node p = head.next, q = head, r;
while ( p != null ) {
r = q; // r follows q
q = p; // q follows p
p = p.next; // p moves to next node
q.next = r; // link q to preceding node
}
head.next = null;
head = q;
}

4 a)



b)

5 a)




5. b)
C function to delete a node from a binary search tree.
The way a node N is deleted from the tree depends primarly on the number of children of node
N.
There are three such cases :
case-1 : N has no children. Then N is deletetd from tree by simply replacing the location of N in
the parent node P(N) by the null pointer.
Case-2 : N has exactly one child. Then N is deleted from tree by simply replacing the location of
N in P(N) by the location of the only child of N.
Case-3 : N has two children. Let S(N) denote the inorder successor of N. Then N is deleted from
tree by first deleting S(N) from tree ( by using case 1 and case 2) and then replacing node n in T
by the node S(N).
All the three casses are cosidered in the follwing C program snippet .
/* delete( tree, p, parent) deletes node p from the binary search tree
(first argument). The third argument to delete()is the parent of p (or
NULL if p is the root). If the parent is not already known, it may be
found by traversing the path from the root to p. The parent is the last
node before p on this path. */
void delete( BinarySearchTree *tree, TreeNode *p, TreeNode *parent)
{
TreeNode *successor; /* Successor of p. */
TreeNode *successor_parent; /* Parent of successor. */
/* Case in which node to be deleted (node p) has no left child. */
if ( p->left == NULL ) {
if ( parent == NULL )
tree->root = p->right;
else if ( p == parent->left )

parent->left = p->right;
else
parent->right = p->right;
}
/* Case in which node to be deleted (node p) has no right child. */
else if ( p->right == NULL ) {
if ( parent == NULL )
tree->root = p->left;
else if ( p == parent->left )
parent->left = p->left;
else
parent->right = p->left;
return;
}
/* Case in which node to be deleted (node p) has two children. In this
case, the successor of node p cannot have a left child. */
else {
successor = p->right;
successor_parent = p;
while ( successor->left != NULL ) {
successor_parent = successor;
successor = successor->left;
}
/* At this point, node successor is the successor of node p. We remove
node successor from its current position and link it into the position
of node p. Then node p is deleted. An alternative would be to copy
the data in node successor to node p, and then delete node successor. */
if ( parent == NULL )
tree->root = successor;
else if ( p == parent->left )
parent->left = successor;
else

parent->right = successor;
if ( successor == successor_parent->left )
successor_parent->left = successor->right;
else
successor_parent->right = successor->right;
successor->left = p->left;
successor->right = p->right;
}
free(p);
--tree->size;
}
6. a) Hashing is an efficient searching technique . Here the serching time is independent of the
input data size . It also support easy insertion and deletion in average case constant time.
Let T is the hash table of m memory locations and L is the set of memory addresses of the
locations in T.
K is the set of keys . Each element is associted with a key that helps in determine the address in
table T.
A function H maps the key to a particular address in L set. The function H is called as hash
function.
H:K----->L
Popularly used hash functions are 1) Division method 2) MidSquare Method 3) Folding method
Division Method : Choose a number m larger than the number n of keys in K . Then the hash
function H is defined by H(k) = (k mod m).

Midsquare Method: Here the key k is squared. Then the hash function is defined by H(k)=l
where l is obtained by deleting digits from both the ends of k2 . The same position of k2 must be
used for all of the keys.
Folding Method: The key k is partitioned into anumber of parts k1,k2......kr, where each part ,
except possibly the last, has the same number of digits as the required address . Then the parts
are added together , ignoring the last carry.
H(k)=k1+k2+....+kr where the leading digit carries are ignored.
Example: Let we hava a hash table of size 100 . Each location is addressed by two digit number
00,01...,99
we will apply above hash function to map an employee code 3205 with the table.
Division Method : H(3205) = 3205 mod 100 = 5 . so the employee code is mapped in to
location with address 5.
Midsquare Method : k=3205 and k2 = 10 272 025 so H(k) determined as 72 after deleting 3
digits form both the sides of k2 . so the employee code is mapped in to location with address 72.
Folding Method : chopping the key 3205 in to two parts will get 32 + 05 = 37
Hence H(3205)= 37 . so the employee code is mapped in to location with address 37.


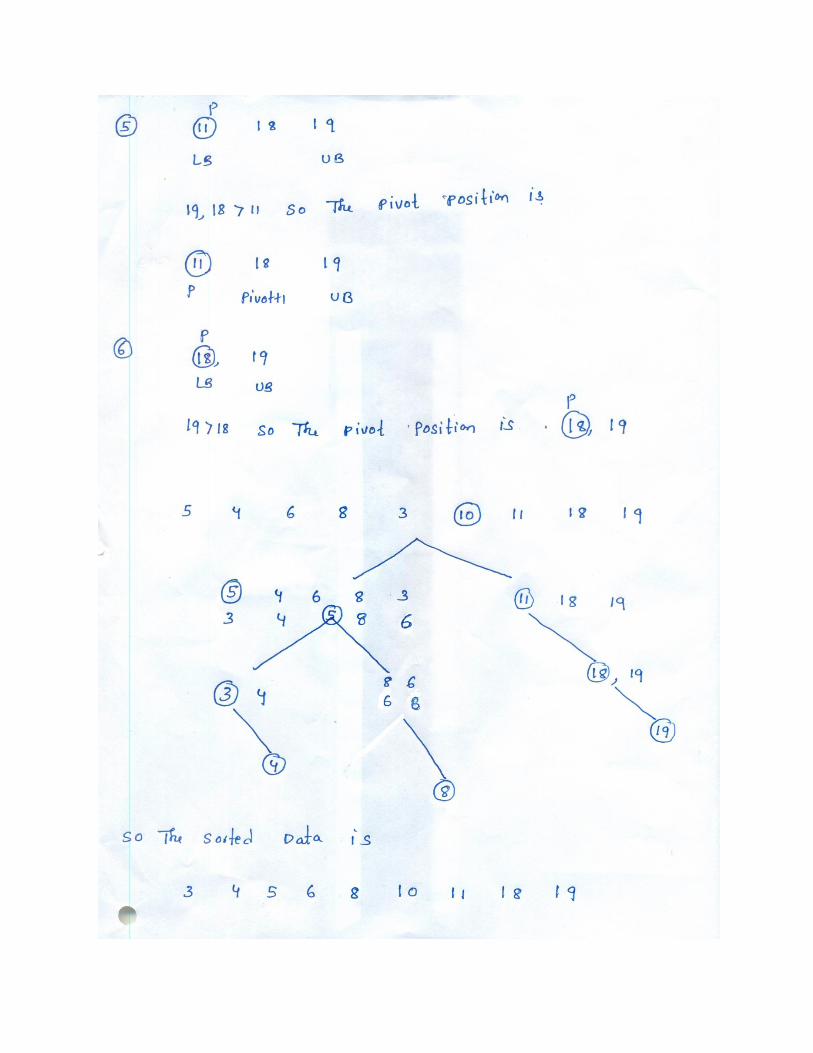

7 a)
Algorithm of DFS: Algorithm for depth-first search on a graph G beginning at a starting node A
Step1. Initialize all nodes to the ready state
Step2. Push the starting node A onto STACK and change its status to the waiting state
Step3. Repeat Step4 and Step5 until STACK is empty.
Step4. Pop the top node N of STACK. Process N and change its status to the processed state
Step5. Push onto STACK all the neighbors of N that are still in the ready state and change their status to the waiting state
[End of Step3 loop]
Step6. Exit.
DFS for the given graph: 1-3-6-7-4-8-2-5 7 b)
Sparse matrix is a matrix in which most of the elements are zero. The natural method of representing matrices in memory as two-dimensional arrays may not be suitable foe sparse matrices. One may save space by storing for only non zero entries.
Sparse matrix form = (non zero elements +1) * 3
Where first row represent the dimension of matrix and last column tells the number of non zero values; second row onwards it is giving the position and value of non zero number.
3 columns: row position, column position, value in that position

example matrix A (4*4 matrix) represented below
Matrix A:
0 0 0 8 0 0 0 0 4 0 0 0 0 2 0 0
Here the memory required is 16 elements X 2 bytes = 32 bytes
The above matrix can be written in sparse matrix form as follows:
Sparse matrix form :
4 4 3
0 3 8
2 0 4
3 1 2
Here the memory required is 12elements X 2 bytes = 24 bytes
8 ) write short note on any three
a) A directed graph (or digraph) is a set of vertices and a collection of directed edges that each connects an ordered pair of vertices.
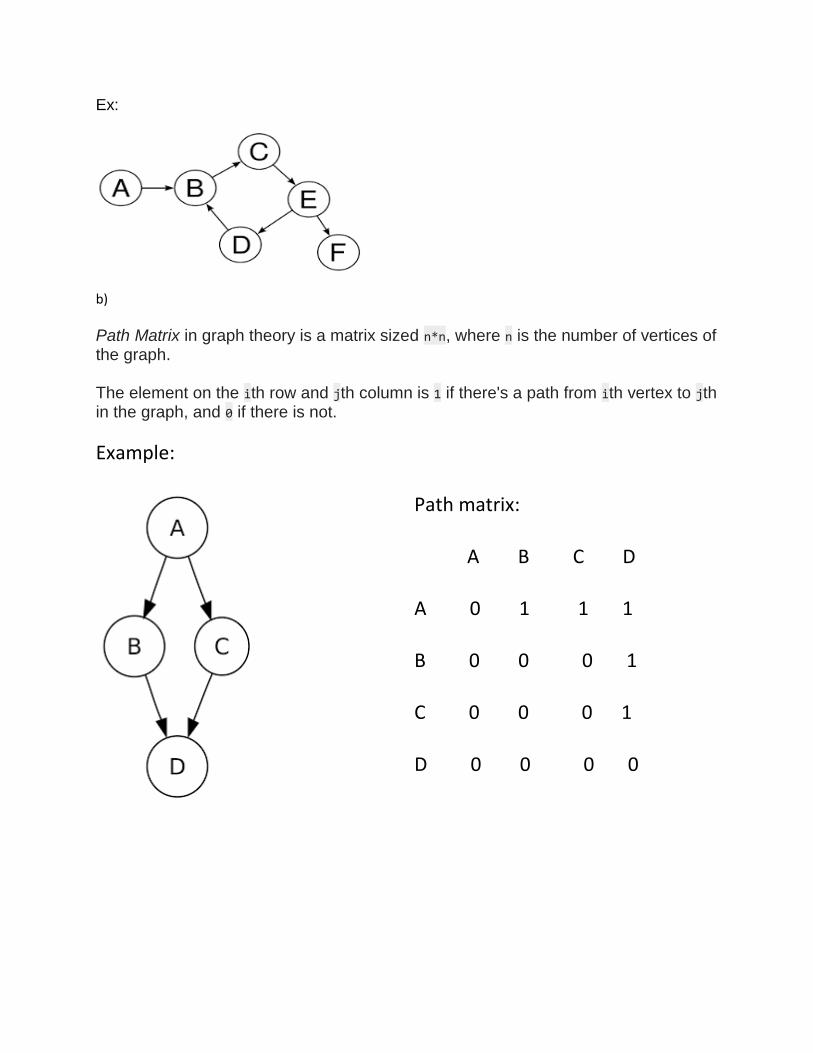
Ex:
b)
Path Matrix in graph theory is a matrix sized n*n, where n is the number of vertices of the graph. The element on the ith row and jth column is 1 if there's a path from ith vertex to jth in the graph, and 0 if there is not.
Example:
Path matrix: A B C D A 0 1 1 1 B 0 0 0 1 C 0 0 0 1 D 0 0 0 0

c)
Representation of a Polynomial: A polynomial is an expression that contains more than two terms. A term is made up of coefficient and exponent. An example of polynomial is
P(x) = 4x3+6x2+7x+9
A polynomial thus may be represented using arrays or linked lists. Array representation assumes that the exponents of the given expression are arranged from 0 to the highest value (degree), which is represented by the subscript of the array beginning with 0. The coefficients of the respective exponent are placed at an appropriate index in the array. The array representation for the above polynomial expression is given below:
A polynomial may also be represented using a linked list. A structure may be defined such that it contains two parts- one is the coefficient and second is the corresponding exponent.
Thus the above polynomial may be represented using linked list as shown below:
d)
expression trees are a special kind of binary tree. A binary tree is a tree in which all nodes contain zero or two children.

Opearator act as a parent and opearnds act as a leaf nodes. Ex: (50 + 25 * 3) / (8 – 3)
e) pattern matching It is used to search a pattern in a given text.
Given a text txt[0..n-1] and a pattern pat[0..m-1], write a function search(char pat[], char txt[]) that prints all occurrences of pat[] in txt[]. You may assume that n > m.
Examples: 1) Input:
txt[] = "THIS IS A TEST TEXT"
pat[] = "TEST"
Output:
Pattern found at index 10
2) Input:
txt[] = "AABAACAADAABAAABAA"
pat[] = "AABA"

Output:
Pattern found at index 0
Pattern found at index 9
Pattern found at index 13


















