
Mobility Presented by: Mohamed Elhawary. Mobility Distributed file systems increase availability...
33
Mobility Presented by: Mohamed Elhawary
-
date post
22-Dec-2015 -
Category
Documents
-
view
215 -
download
0
Transcript of Mobility Presented by: Mohamed Elhawary. Mobility Distributed file systems increase availability...

Mobility
Presented by:Mohamed Elhawary

Mobility Distributed file systems increase
availability Remote failures may cause serious
troubles Server replication (higher quality) Client replication, inferior, needs periodic
revalidation Cache coherence to combine
performance, availability and quality
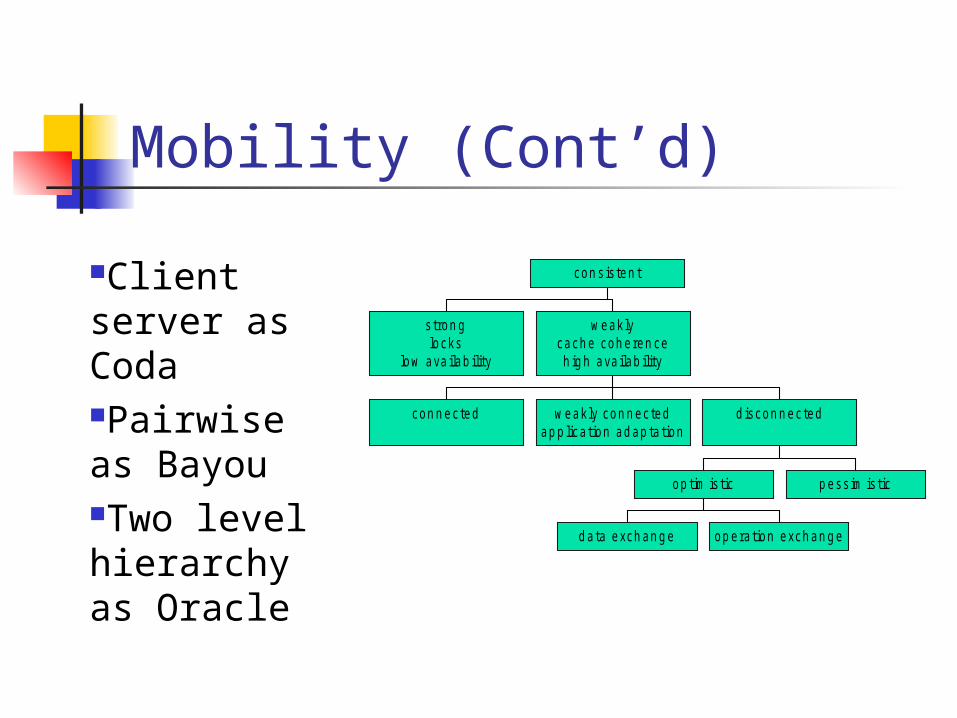
Mobility (Cont’d)
s tron glocks
low ava ilab ility
con n ec ted w eak ly con n ec tedap p lica tion ad ap ta tion
d a ta exch an g e op era tion exch an g e
op tim is tic p ess im is tic
d iscon n ec ted
w eak lycach e coh eren ceh ig h ava ilab ility
con s is ten tClient server as CodaPairwise as BayouTwo level hierarchy as Oracle

Disconnected Operation in Coda Enable clients to continue accessing
data during failures Cashing data on the clients with
right back upon reconnection Designed for a large num. of clients
and a smaller num. of servers Server replication and call back
break Preserve transparency

Scalability Whole file cashing, cash miss on
open only Simple but involve communication
overhead Placing functionality on the clients
unless violating security or integrity Avoids system wide rapid change

Optimistic replica control Disconnection is involuntary Extended disconnections Leases place time bound on locks
but disconnected client loses control after expiration
Low degree of write sharing in Unix Applied to server replication for
transparency
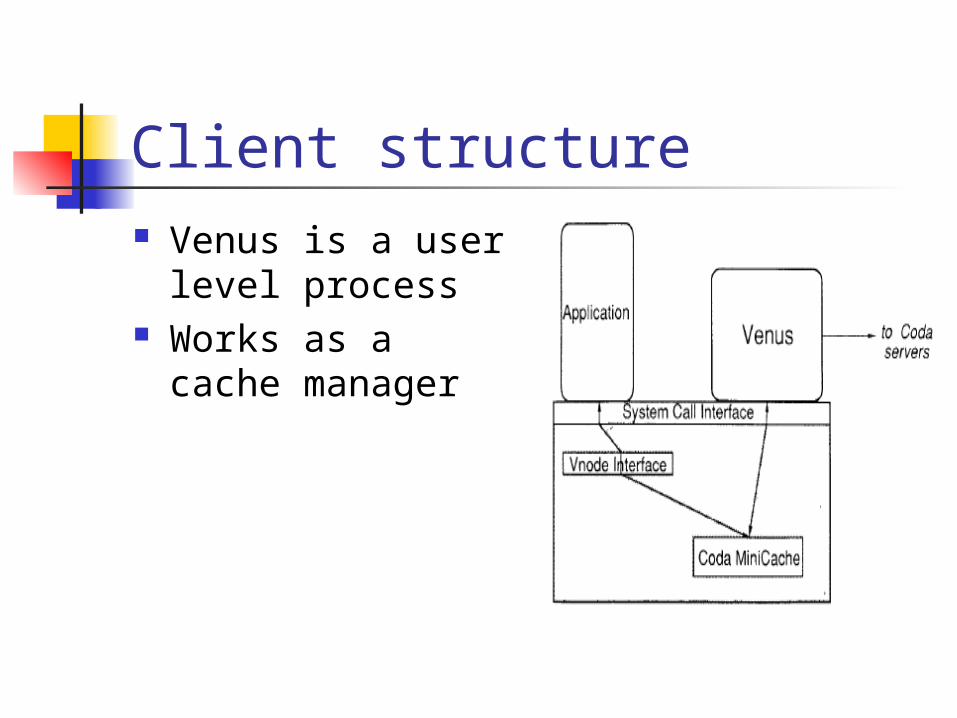
Client structure Venus is a user
level process Works as a cache
manager
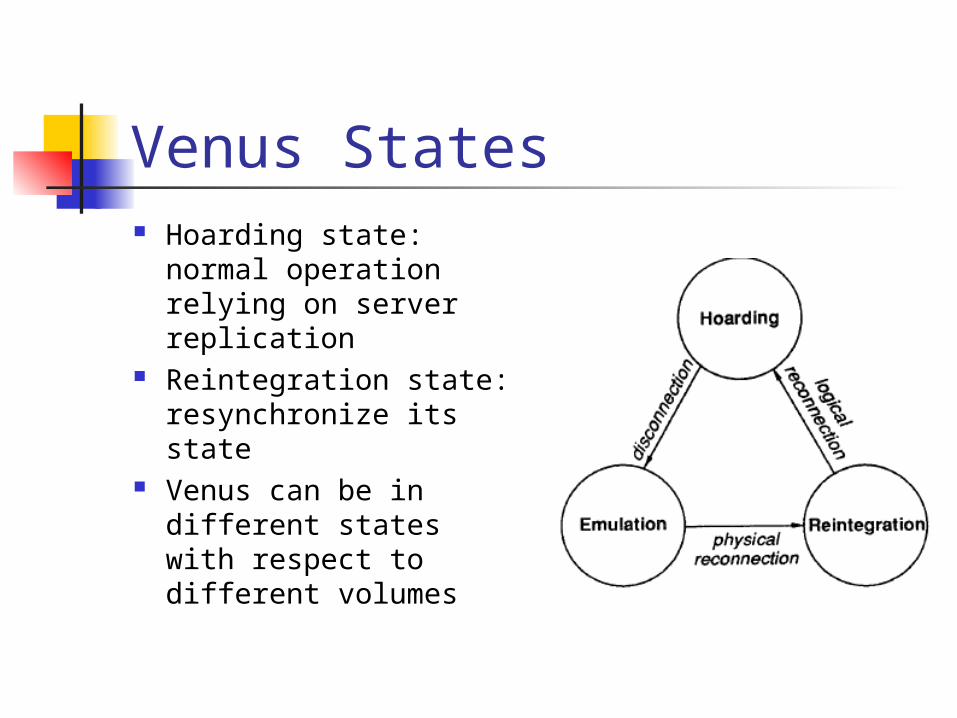
Venus States Hoarding state:
normal operation relying on server replication
Reintegration state: resynchronize its state
Venus can be in different states with respect to different volumes

Hoarding Hoard useful data in anticipation of
disconnection Combines implicit and explicit source of
information File reference behavior can’t be predicted Disconnections are unpredictable Priority of cached objects is a function of
user given priority (unsafe) and recent usage (hard to manage)
Hierarchical cache management

Hoard walking Periodically restores cache
equilibrium Unexpected disconnection before a
scheduled walk is a problem Revaluate name bindings Revaluate priorities of all entries Solve the callback break problem Policies for directories and files

Emulation Venus functions as a pseudo server Generates temporary file identifiers Behaves as faithful as possible, but no
guarantee Cache entries of modified assume infinite
priority, except when cache is full Use a replay log Use nonvolatile storage Meta data changes through atomic
transactions

Reintegration Venus propagates changes made in
emulation Update suspended in the volume being
integrated until completion, it may take time!
Replace temporary ids with permanent ones, but may be avoided
Ship replay log Execute replay as a single transaction,
is that fair?

Replay algorithm Log is parsed Log is validated using store id Store create a shadow file and data
transfer is deferred Data transfer Commits and release locks In case of failures, user can replay
selectively Using dependence graphs may enhance
reintegration

Evaluation

Evaluation (cont’d)

Evaluation (cont’d)

Flexible update propagation in Bayou Weekly consistent replication can
accommodate propagation policies Don’t assume client server as in Coda Exchange update operations and not
the changes, suite low B/W networks Relies on the theory of epidemics Storage vs. bandwidth

Basic Anti-entropy Storage consists of an ordered log of
updates and a database Two replicas bring each other up-to-date by
agreeing on the set of writes in their logs Servers assigns monotonically increasing
accept stamp to new writes Write propagates with stamps and server id Partial accept order to maintain the prefix
property Needs to be implemented over TCP

Basic Anti-entropy (Cont’d)

Effective write-log Each replica discard stable writes as a
pruned prefix from write log They may have not fully propagated
and may require full database transfer Storage bandwidth tradeoff Assigns monotonically increasing CSN to
committed writes and infinity to tentative writes
Write A precedes write B if…

Anti-entropy with com. writes

Write log truncation To test if a server is missing writes,
S.O version vector Penalty involve database transfer
and roll back

Write log truncation (Cont’d)

Session guarantees Causal order as a refinement of
accept order Each server maintains a logical
clock that advances with new writes
Total order through <CSN, accept order, server id>

Light weight creation and retirement Versions vectors are updated to
include or exclude servers Creation and retirement are handled
as a write that propagates via anti-entropy
<Tk,i , Sk> is Si ’s server id Tk,i + 1 initialize accept stamp counter Linearly creation increase id’s and
version vectors dramatically

Disadvantages When num of replicas is larger
than update rate, cost of exchanging version vectors is high
If the update rate is larger than the commit rate, the write log will grow large

Policies When to reconcile Which replicas to reconcile How to truncate the write log Selecting a server to create a new
replica Depend on network characteristics
and threshold values

Evaluation Experiments were taken for an e-mail
application, how far is that really represent the general dist. File system
Only committed writes are propagated Sparc running SunOS (SS) 486 laptops running linux (486) 3000 and 100 byte messages between 3
replicas 520 public key overheads and 1316 bytes
update schema and padding

Execution vs. writes propagated
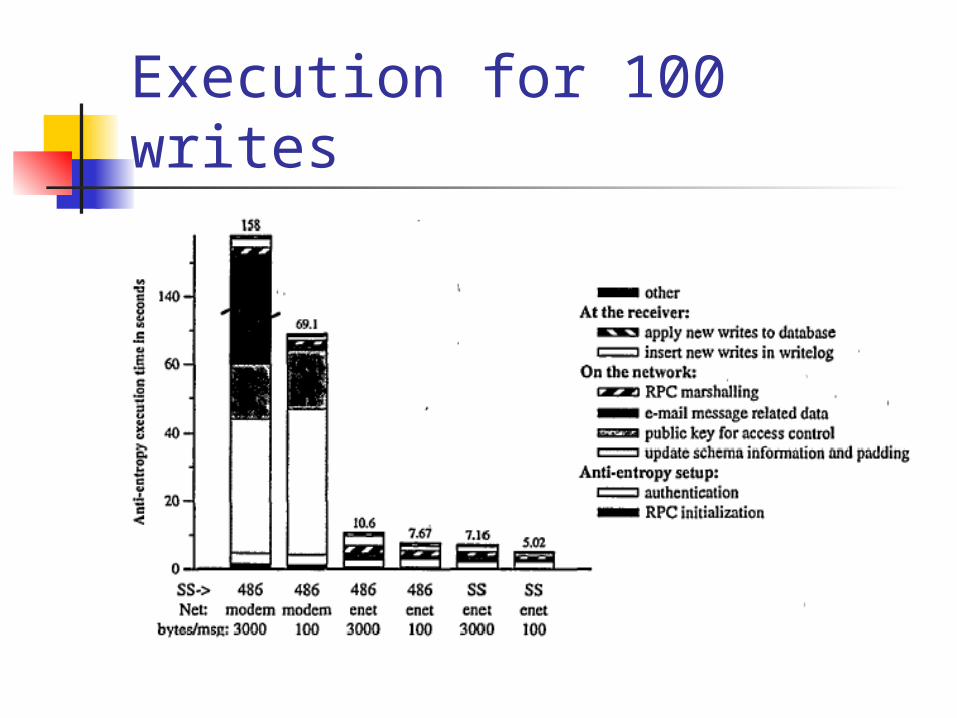
Execution for 100 writes

Network independent

Effect of server creations When servers created from initial
one, 20K version vector for 1000 servers
When linearly created, 4 MB version vectors for 1000 servers
Time to test if a write is among those represented by version vector may grow cubically if linearly created

Conclusion Disconnected operation through
Cedar and PCMAIL is less transparent than Coda
Golding’s time stamped anti entropy protocol is similar to bayou, with heavier weight mechanism to create replicas and less aggressive to claim storage


















