
MLconf seattle 2015 presentation
65
-
Upload
ehtshamelahi -
Category
Data & Analytics
-
view
243 -
download
0
Transcript of MLconf seattle 2015 presentation


Spark and GraphX in the Netflix Recommender System
Ehtsham Elahi and Yves Raimond
Algorithms EngineeringNetflix
MLconf Seattle 2015

Machine Learning @ Netflix

Introduction● Goal: Help members find
content that they’ll enjoy to maximize satisfaction and retention
● Core part of product○ Every impression is a
recommendation
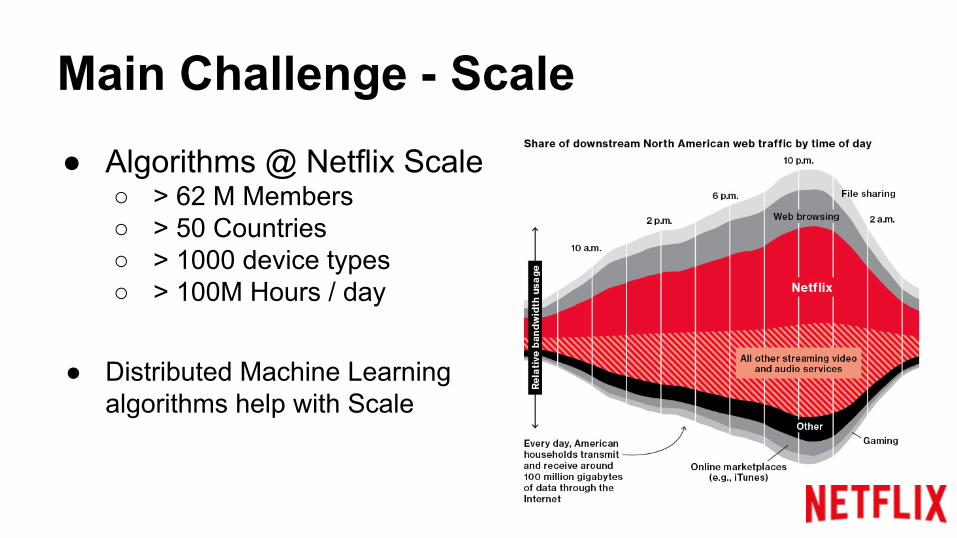
Main Challenge - Scale● Algorithms @ Netflix Scale
○ > 62 M Members○ > 50 Countries○ > 1000 device types○ > 100M Hours / day
● Distributed Machine Learning algorithms help with Scale
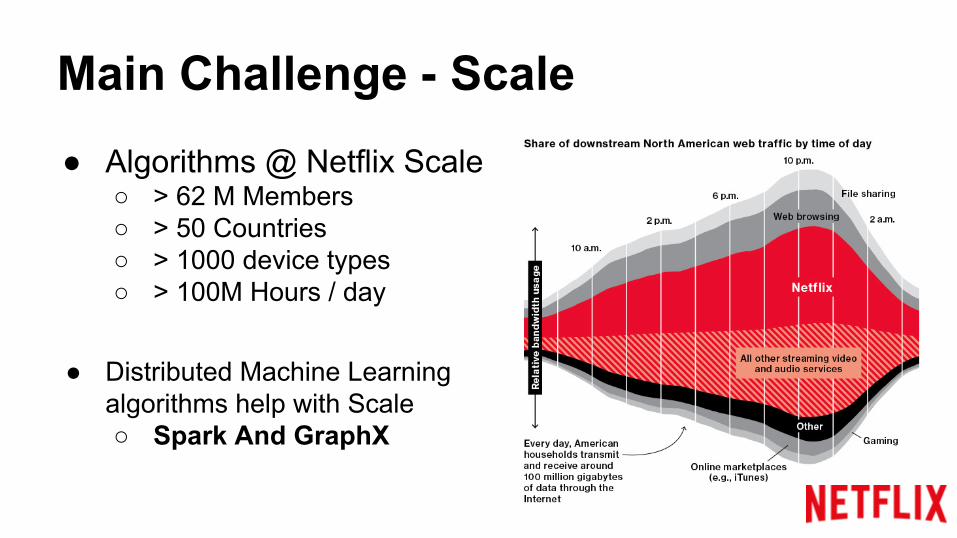
Main Challenge - Scale● Algorithms @ Netflix Scale
○ > 62 M Members○ > 50 Countries○ > 1000 device types○ > 100M Hours / day
● Distributed Machine Learning algorithms help with Scale○ Spark And GraphX

Spark and GraphX

Spark And GraphX● Spark- Distributed in-memory computational engine
using Resilient Distributed Datasets (RDDs)
● GraphX - extends RDDs to Multigraphs and provides graph analytics
● Convenient and fast, all the way from prototyping (iSpark, Zeppelin) to Production

Two Machine Learning Problems● Generate ranking of items with respect to a given item
from an interaction graph
○ Graph Diffusion algorithms (e.g. Topic Sensitive Pagerank)
● Find Clusters of related items using co-occurrence data
○ Probabilistic Graphical Models (Latent Dirichlet Allocation)
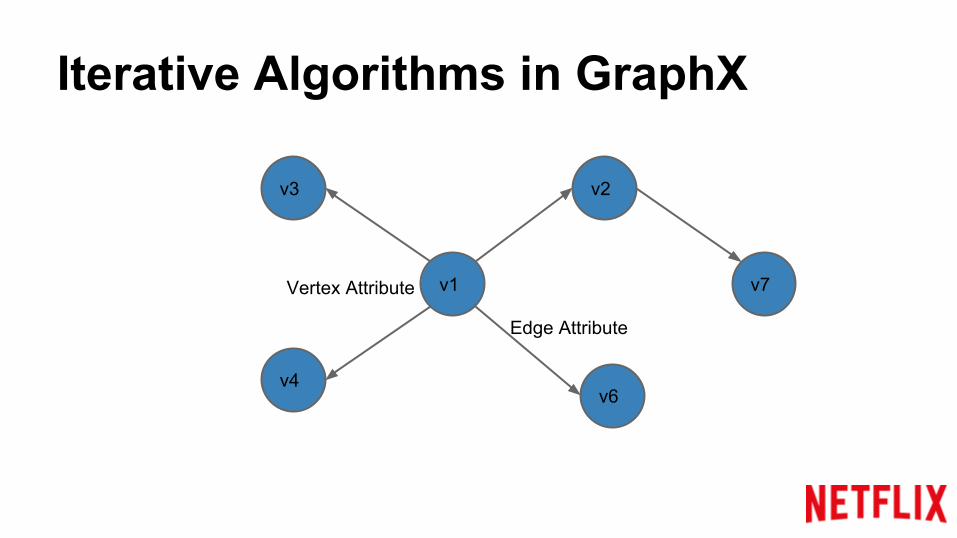
Iterative Algorithms in GraphX
v1
v2v3
v4v6
v7Vertex Attribute
Edge Attribute
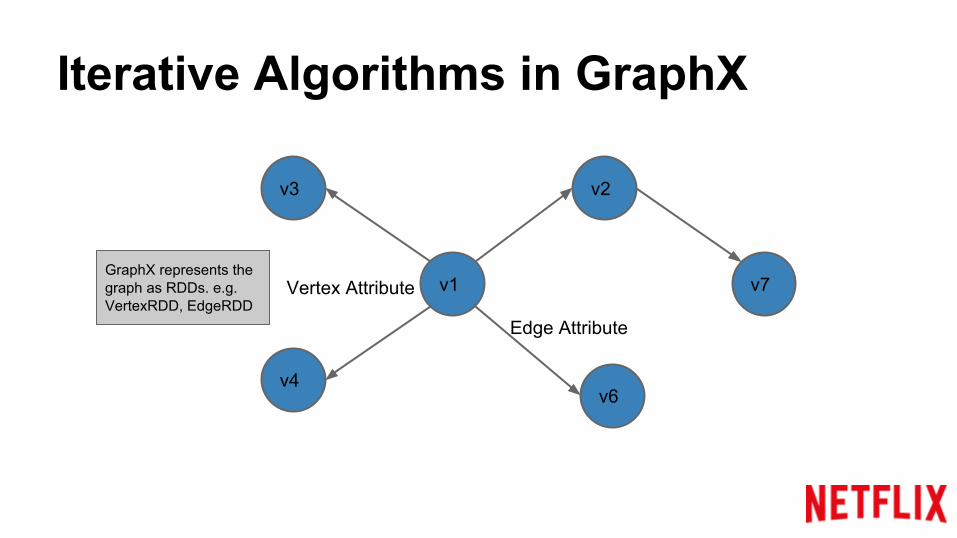
Iterative Algorithms in GraphX
v1
v2v3
v4v6
v7Vertex Attribute
Edge Attribute
GraphX represents the graph as RDDs. e.g. VertexRDD, EdgeRDD
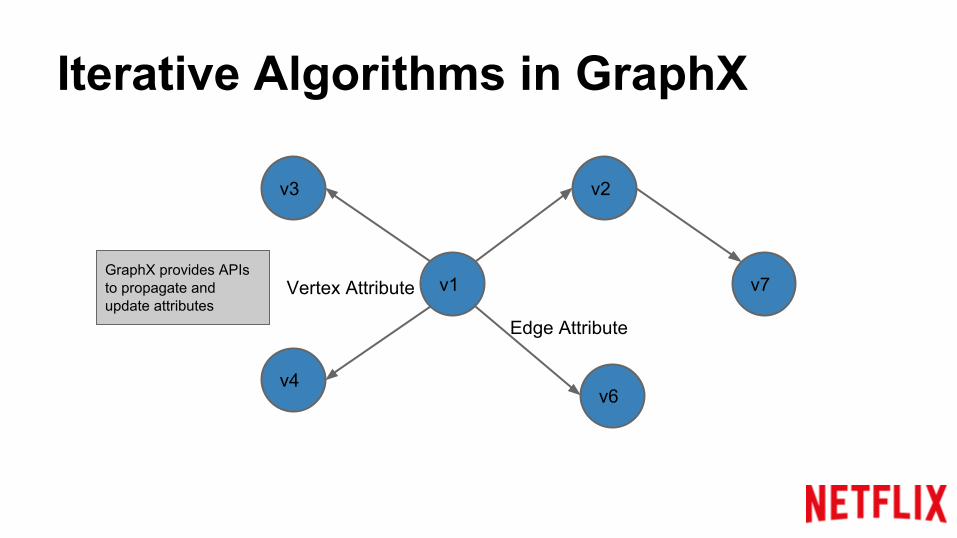
Iterative Algorithms in GraphX
v1
v2v3
v4v6
v7Vertex Attribute
Edge Attribute
GraphX provides APIs to propagate and update attributes

Iterative Algorithms in GraphX
v1
v2v3
v4v6
v7Vertex Attribute
Edge Attribute
Iterative Algorithm proceeds by creating updated graphs

Graph Diffusion algorithms

● Popular graph diffusion algorithm
● Capturing vertex importance with regards to a particular vertex
● e.g. for the topic “Seattle”
Topic Sensitive Pagerank @ Netflix
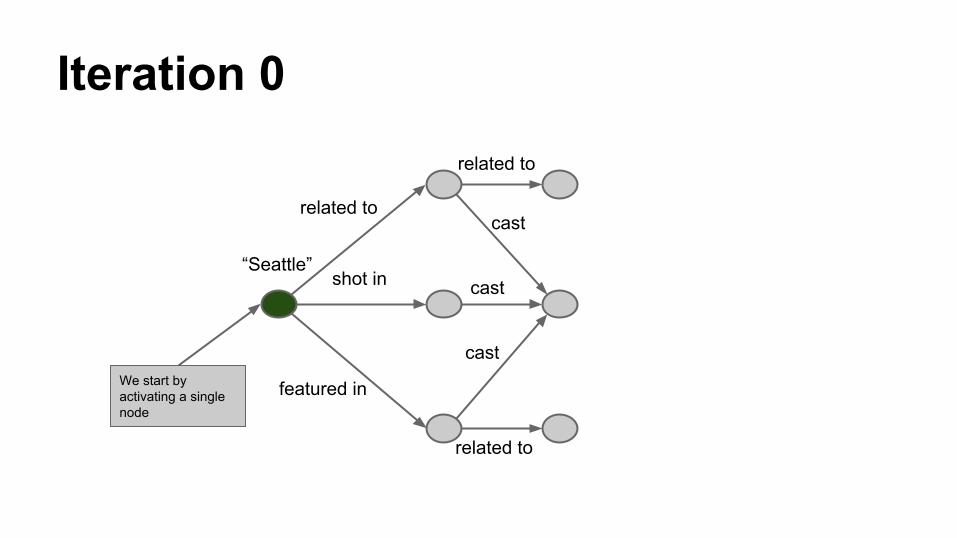
Iteration 0
We start by activating a single node
“Seattle”
related to
shot in
featured in
related to
cast
cast
cast
related to

Iteration 1
With some probability, we follow outbound edges, otherwise we go back to the origin.
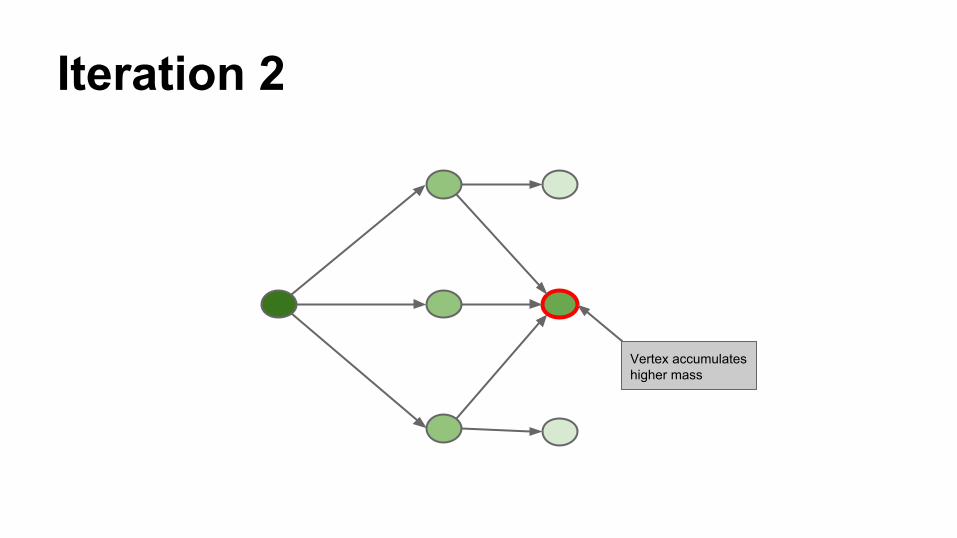
Iteration 2
Vertex accumulates higher mass
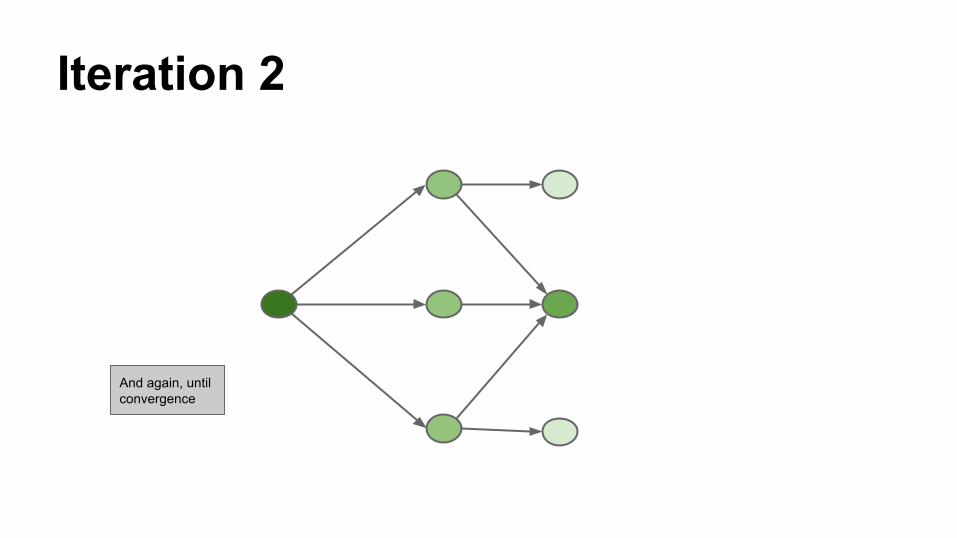
Iteration 2
And again, until convergence

GraphX implementation● Running one propagation for each possible starting
node would be slow
● Keep a vector of activation probabilities at each vertex
● Use GraphX to run all propagations in parallel

Topic Sensitive Pagerank in GraphX
activation probability, starting from vertex 1
activation probability, starting from vertex 2
activation probability, starting from vertex 3
...
Activation probabilities as vertex attributes
...
...
... ...
...
...

Example graph diffusion results
“Matrix”
“Zombies”
“Seattle”

Distributed Clustering algorithms

LDA @ Netflix● A popular clustering/latent factors model● Discovers clusters/topics of related videos from Netflix
data● e.g, a topic of Animal Documentaries

LDA - Graphical Model
Question: How to parallelize inference?

LDA - Graphical Model
Question: How to parallelize inference?Answer: Read conditional independenciesin the model

Gibbs Sampler 1 (Semi Collapsed)

Gibbs Sampler 1 (Semi Collapsed)
Sample Topic Labels in a given document SequentiallySample Topic Labels in different documents In parallel
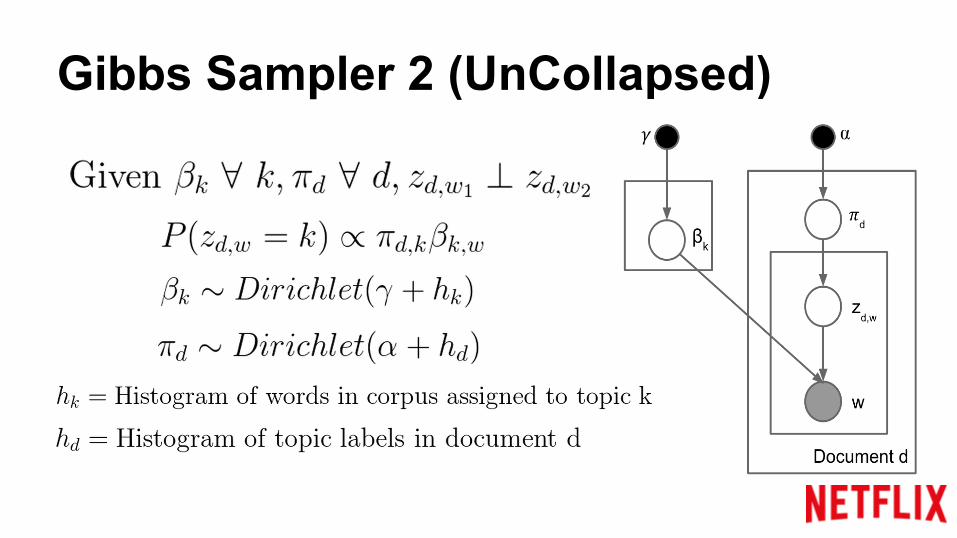
Gibbs Sampler 2 (UnCollapsed)
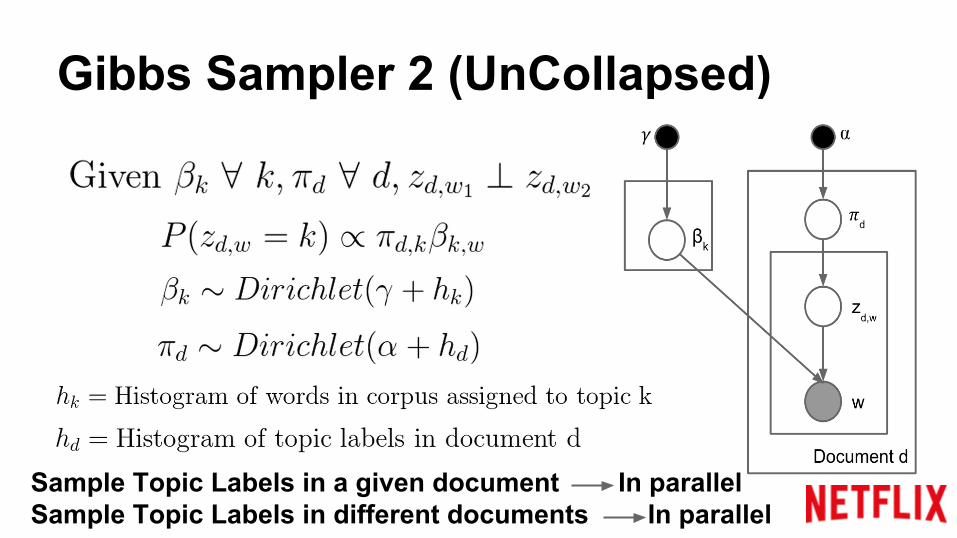
Gibbs Sampler 2 (UnCollapsed)
Sample Topic Labels in a given document In parallelSample Topic Labels in different documents In parallel

Gibbs Sampler 2 (UnCollapsed)
Suitable For GraphX
Sample Topic Labels in a given document In parallelSample Topic Labels in different documents In parallel
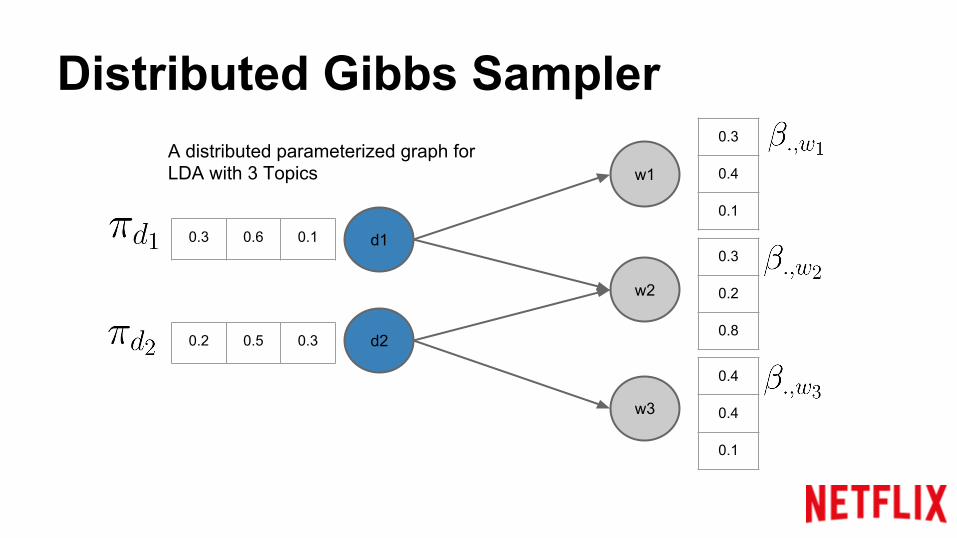
Distributed Gibbs Sampler
w1
w2
w3
d1
d2
0.3
0.4
0.1
0.3
0.2
0.8
0.4
0.4
0.1
0.3 0.6 0.1
0.2 0.5 0.3
A distributed parameterized graph for LDA with 3 Topics
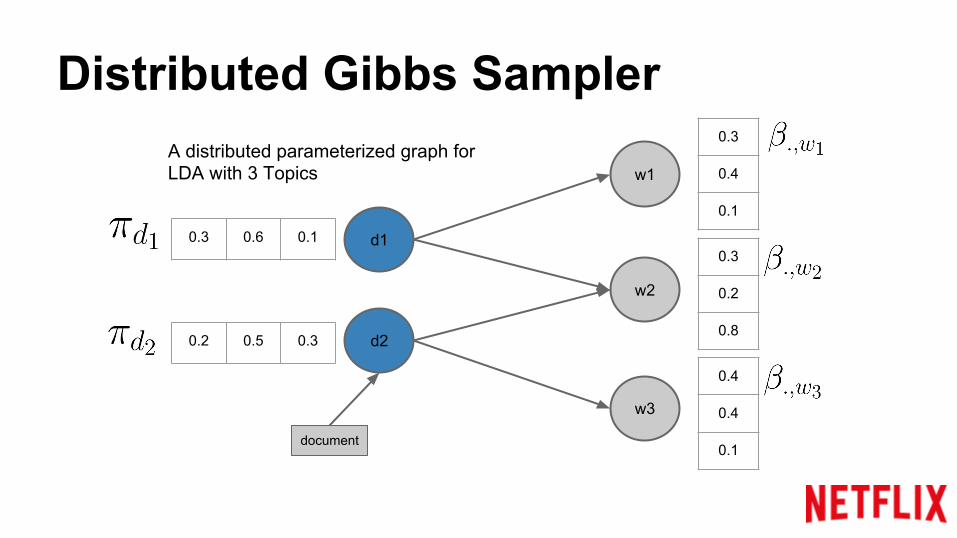
Distributed Gibbs Sampler
w1
w2
w3
d1
d2
0.3
0.4
0.1
0.3
0.2
0.8
0.4
0.4
0.1
0.3 0.6 0.1
0.2 0.5 0.3
A distributed parameterized graph for LDA with 3 Topics
document
Distributed Gibbs Sampler
w1
w2
w3
d1
d2
0.3
0.4
0.1
0.3
0.2
0.8
0.4
0.4
0.1
0.3 0.6 0.1
0.2 0.5 0.3
A distributed parameterized graph for LDA with 3 Topics
word

Distributed Gibbs Sampler
w1
w2
w3
d1
d2
0.3
0.4
0.1
0.3
0.2
0.8
0.4
0.4
0.1
0.3 0.6 0.1
0.2 0.5 0.3
A distributed parameterized graph for LDA with 3 Topics
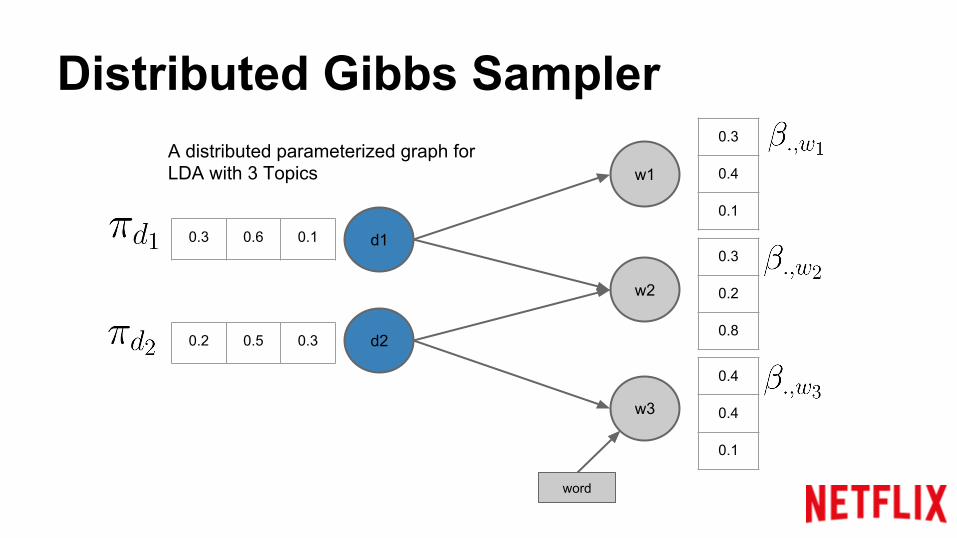
Edge: if word appeared in the document
Distributed Gibbs Sampler
w1
w2
w3
d1
d2
0.3
0.4
0.1
0.3
0.2
0.8
0.4
0.4
0.1
0.3 0.6 0.1
0.2 0.5 0.3
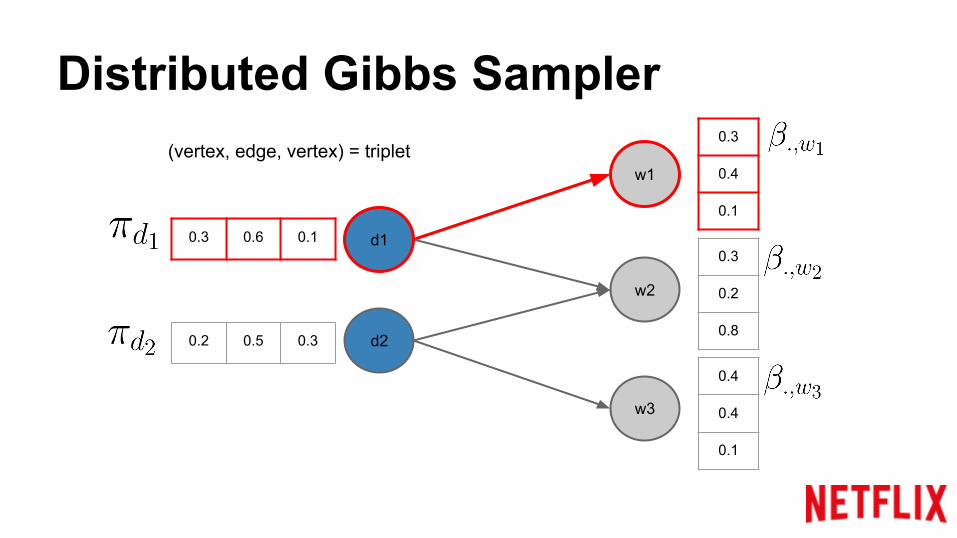
(vertex, edge, vertex) = triplet
Distributed Gibbs Sampler
w1
w2
w3
d1
d2
0.3
0.4
0.1
0.3
0.2
0.8
0.4
0.4
0.1
0.3 0.6 0.1
0.2 0.5 0.3
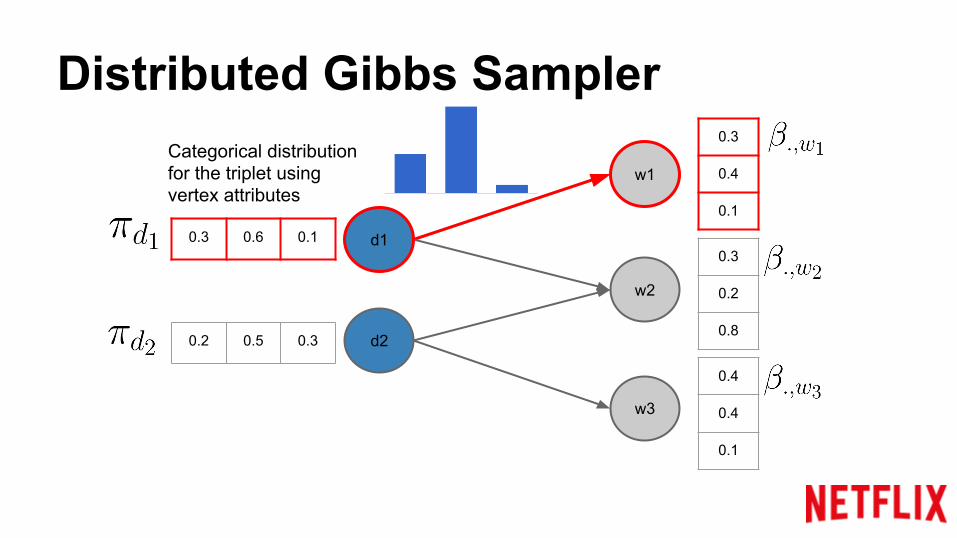
Categorical distributionfor the triplet usingvertex attributes
Distributed Gibbs Sampler
w1
w2
w3
d1
d2
0.3
0.4
0.1
0.3
0.2
0.8
0.4
0.4
0.1
0.3 0.6 0.1
0.2 0.5 0.3
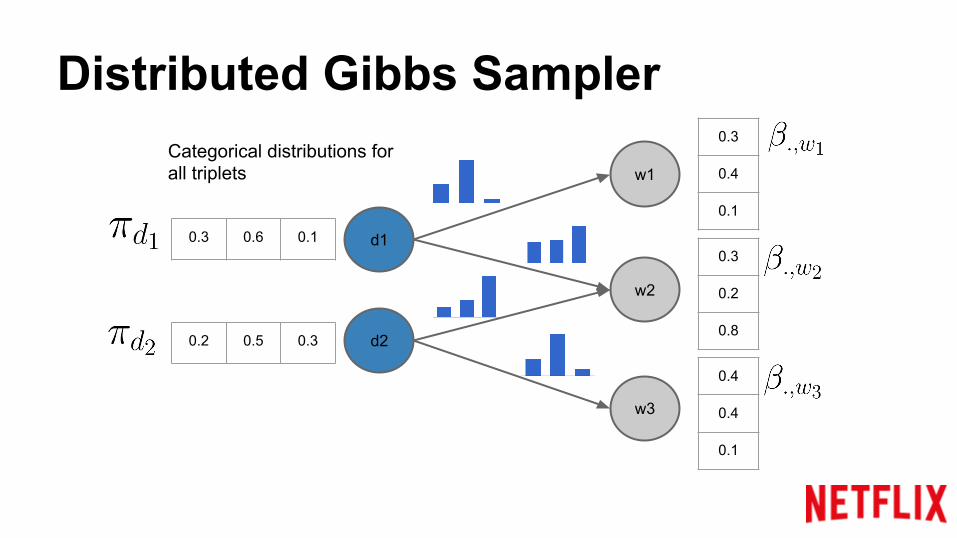
Categorical distributions forall triplets
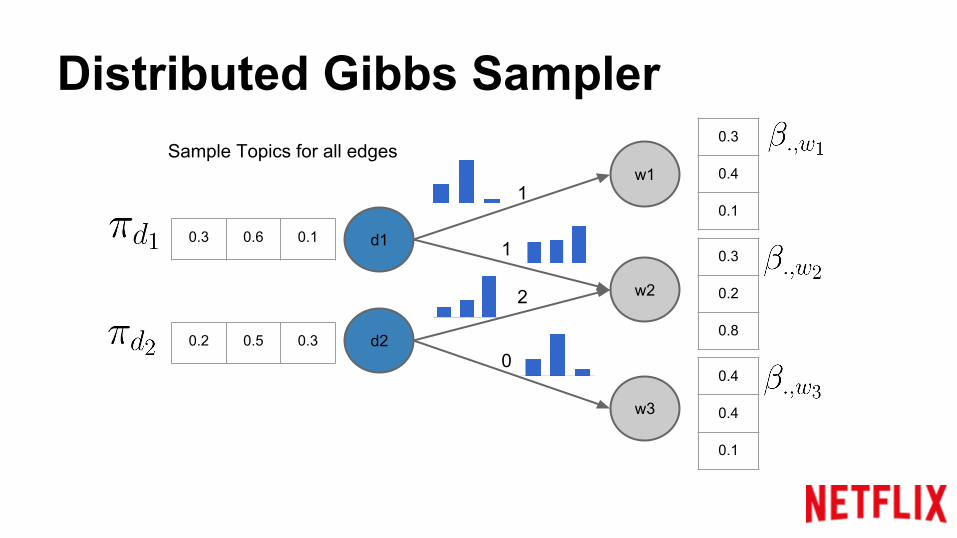
Distributed Gibbs Sampler
w1
w2
w3
d1
d2
0.3
0.4
0.1
0.3
0.2
0.8
0.4
0.4
0.1
0.3 0.6 0.1
0.2 0.5 0.3
1
1
2
0
Sample Topics for all edges
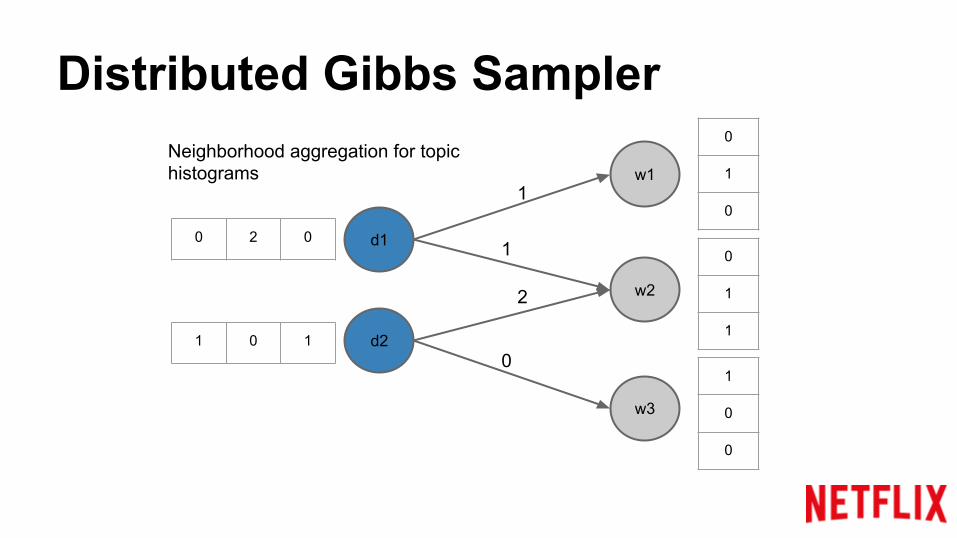
Distributed Gibbs Sampler
w1
w2
w3
d1
d2
0
1
0
0
1
1
1
0
0
0 2 0
1 0 1
1
1
2
0
Neighborhood aggregation for topic histograms
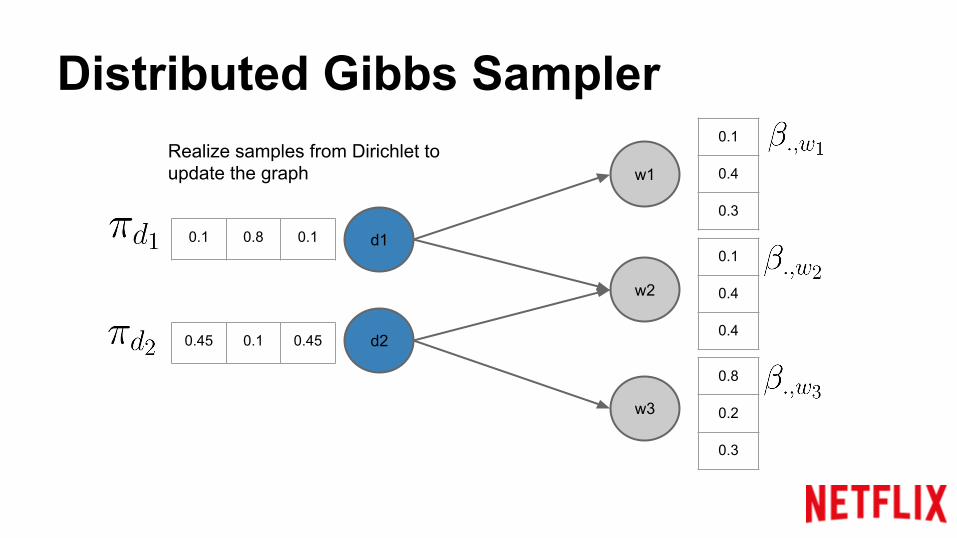
Distributed Gibbs Sampler
w1
w2
w3
d1
d2
0.1
0.4
0.3
0.1
0.4
0.4
0.8
0.2
0.3
0.1 0.8 0.1
0.45 0.1 0.45
Realize samples from Dirichlet to update the graph

Example LDA Results
Cluster of Bollywood Movies
Cluster of Kids shows
Cluster of Western movies

GraphX performance comparison

Algorithm Implementations● Topic Sensitive Pagerank
○ Distributed GraphX implementation○ Alternative Implementation: Broadcast graph adjacency matrix,
Scala/Breeze code, triggered by Spark
● LDA○ Distributed GraphX implementation○ Alternative Implementation: Single machine, Multi-threaded Java code
● All implementations are Netflix Internal Code
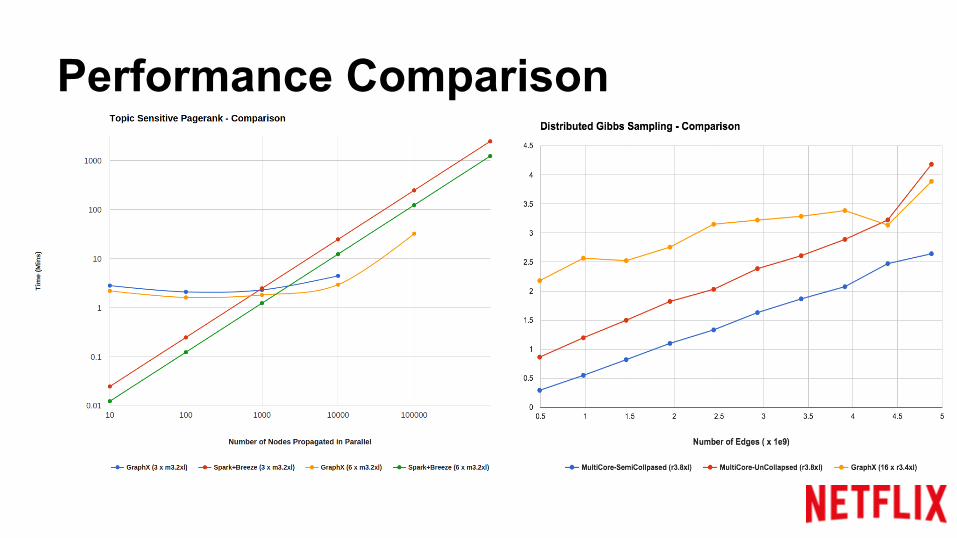
Performance Comparison
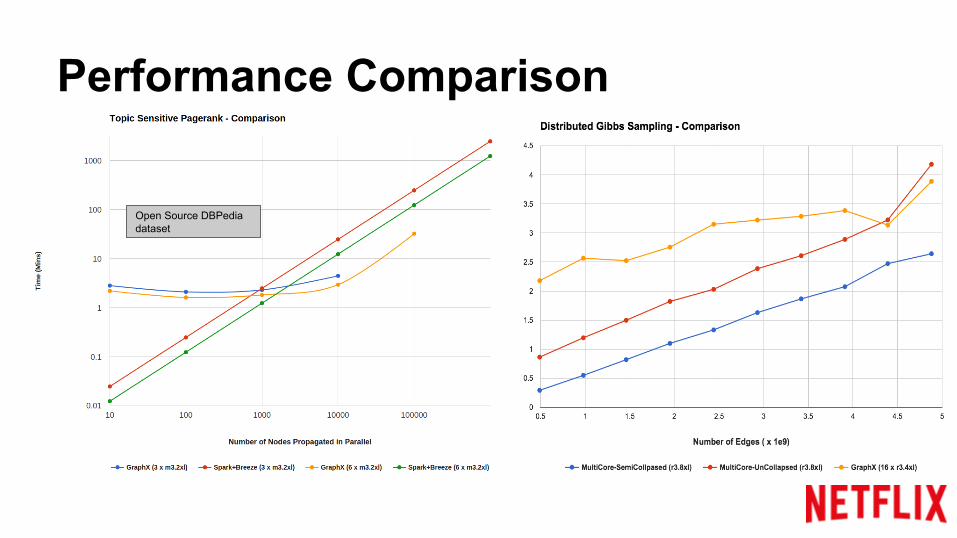
Performance Comparison
Open Source DBPedia dataset
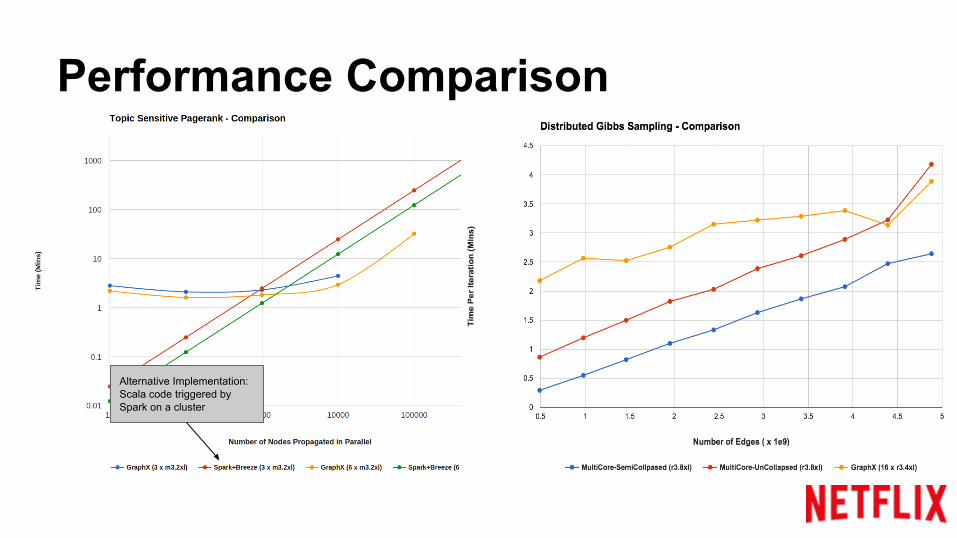
Performance Comparison
Alternative Implementation: Scala code triggered by Spark on a cluster
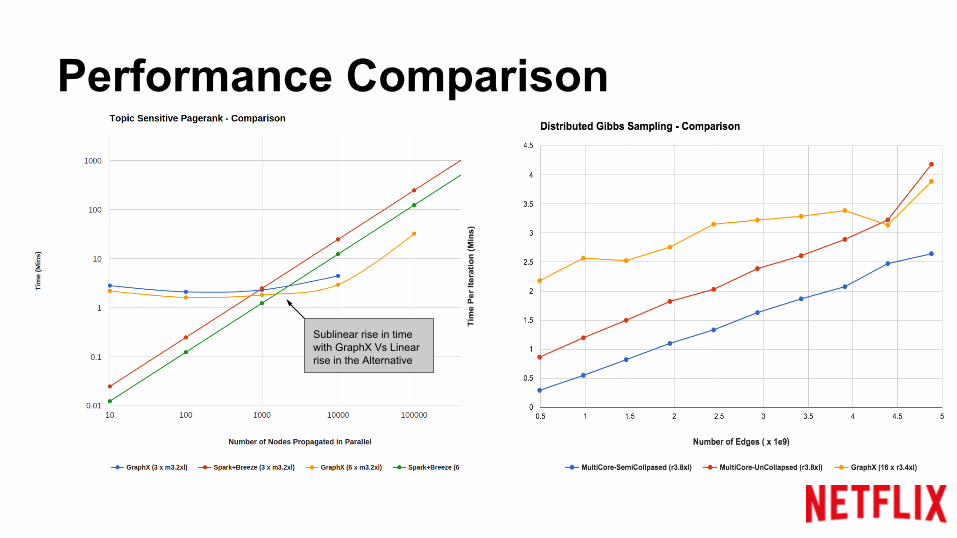
Performance Comparison
Sublinear rise in time with GraphX Vs Linear rise in the Alternative
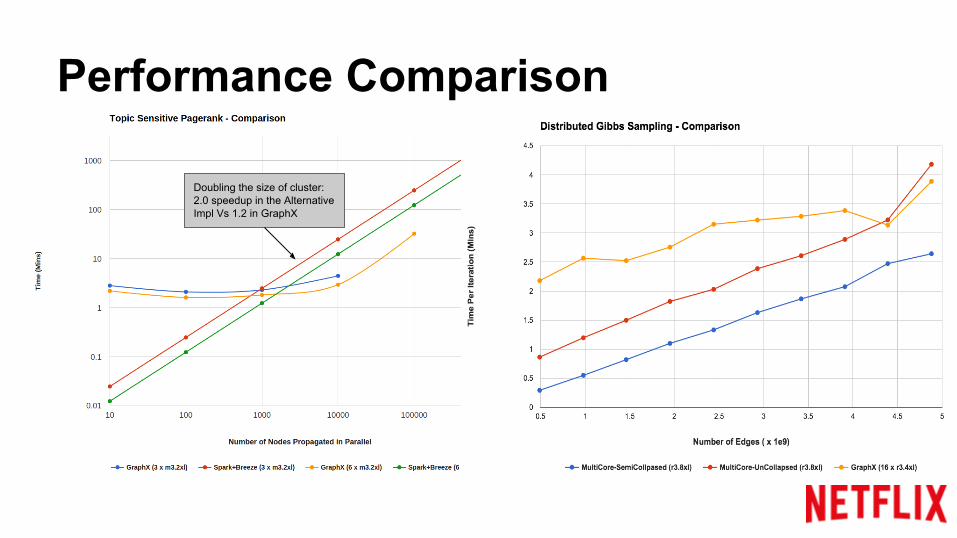
Performance Comparison
Doubling the size of cluster:2.0 speedup in the Alternative Impl Vs 1.2 in GraphX
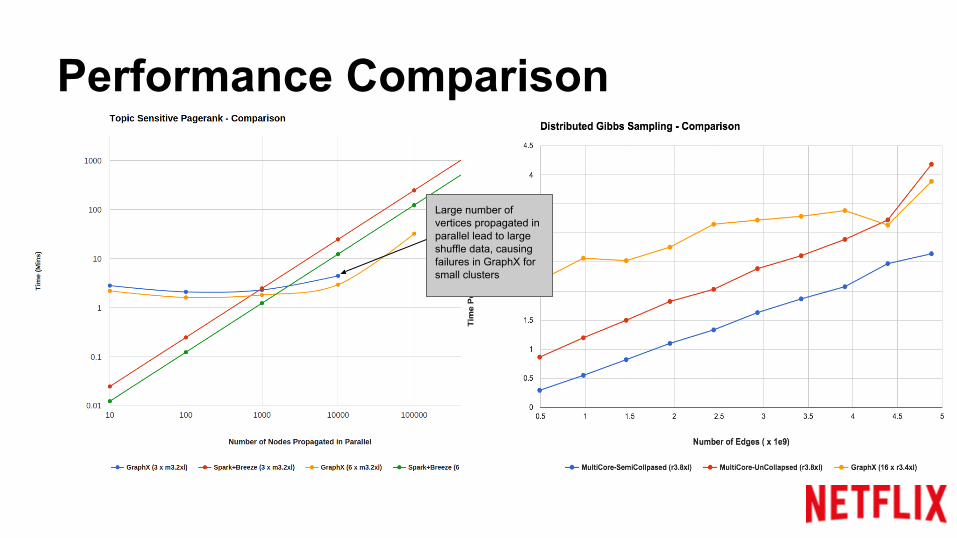
Performance Comparison
Large number of vertices propagated in parallel lead to large shuffle data, causing failures in GraphX for small clusters

Performance Comparison
Netflix datasetNumber of Topics = 100

Performance Comparison
Multi-core implementation:Single machine Multi-threaded Java Code
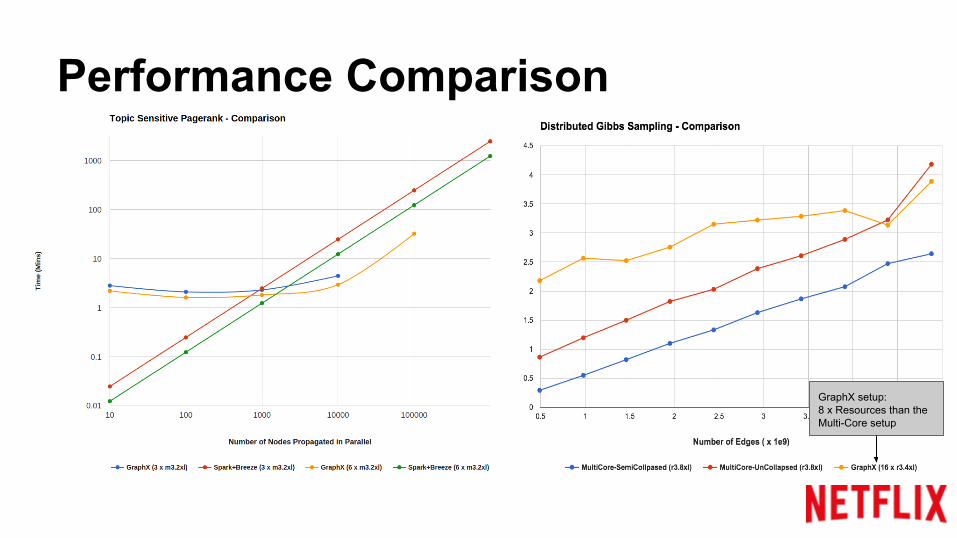
Performance Comparison
GraphX setup:8 x Resources than the Multi-Core setup
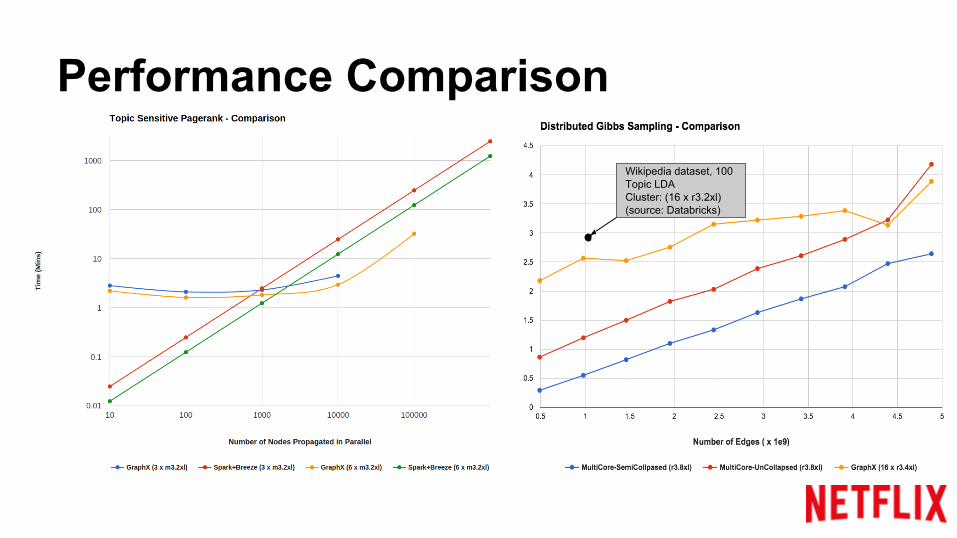
Performance Comparison
Wikipedia dataset, 100 Topic LDACluster: (16 x r3.2xl)(source: Databricks)
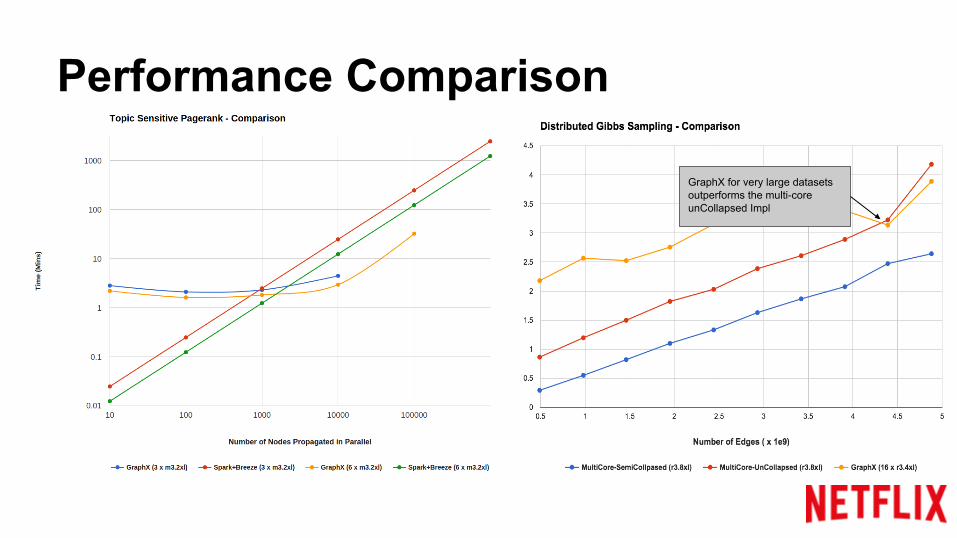
Performance Comparison
GraphX for very large datasets outperforms the multi-core unCollapsed Impl

Lessons Learned

What we learned so far ...
● Where is the cross-over point for your iterative ML algorithm?○ GraphX brings performance benefits if you’re on the right side of that
point○ GraphX lets you easily throw more hardware at a problem
● GraphX very useful (and fast) for other graph processing tasks○ Data pre-processing○ Efficient joins

What we learned so far ...
● Regularly save the state○ With a 99.9% success rate, what’s the probability of successfully
running 1,000 iterations?
● Multi-Core Machine learning (r3.8xl, 32 threads, 220 GB) is very efficient○ if your data fits in memory of single machine !

What we learned so far ...
● Regularly save the state○ With a 99.9% success rate, what’s the probability of successfully
running 1,000 iterations?○ ~36%
● Multi-Core Machine learning (r3.8xl, 32 threads, 220 GB) is very efficient○ if your data fits in memory of single machine !

We’re hiring!(come talk to us)
https://jobs.netflix.com/

Appendix

Using GraphXscala> val edgesFile = "/data/mlconf-graphx/edges.txt"
scala> sc.textFile(edgesFile).take(5).foreach(println)
0 12 32 42 52 6
scala> val mapping = sc.textFile("/data/mlconf-graphx/uri-mapping.csv")
scala> mapping.take(5).foreach(println)
http://dbpedia.org/resource/Drew_Finerty,3663393http://dbpedia.org/resource/1998_JGTC_season,4148403http://dbpedia.org/resource/Eucalyptus_bosistoana,3473416http://dbpedia.org/resource/Wilmington,234049http://dbpedia.org/resource/Wetter_(Ruhr),884940

Creating a GraphX graphscala> val graph = GraphLoader.edgeListFile(sc, edgesFile, false, 100)
graph: org.apache.spark.graphx.Graph[Int,Int] = org.apache.spark.graphx.impl.GraphImpl@547a8dc1
scala> graph.edges.count
res3: Long = 16090021
scala> graph.vertices.count
res4: Long = 4548083

Pagerank in GraphXscala> val ranks = graph.staticPageRank(10, 0.15).vertices
scala> val resources = mapping.map { row =>
val fields = row.split(",")
(fields.last.toLong, fields.first)
}
scala> val ranksByResource = resources.join(ranks).map {
case (id, (resource, rank)) => (resource, rank)
}
scala> ranksByResource.top(3)(Ordering.by(_._2)).foreach(println)
(http://dbpedia.org/resource/United_States,15686.671749384182)
(http://dbpedia.org/resource/Animal,6530.621240073025)
(http://dbpedia.org/resource/United_Kingdom,5780.806077968981)

References
● Topic Sensitive Pagerank [Haveliwala, 2002]● Latent Dirichlet Allocation [Blei, 2003]


















