
MIRACLE Multilingual Information RetrievAl for the CLEF campaign DAEDALUS – Data, Decisions and...
13
MIRACLE M ultilingual I nformation R etrievA l for the CLE F campaign DAEDALUS – Data, Decisions and Language, S.A. www.daedalus.es Universidad Carlos III de Madrid (UC3M) www.uc3m.es Universidad Politécnica de Madrid (UPM) www.upm.es Partially funded by IST-2001-32174 (OmniPaper) and CAM 07T/0055/2003 projects
-
Upload
brice-preston -
Category
Documents
-
view
214 -
download
0
Transcript of MIRACLE Multilingual Information RetrievAl for the CLEF campaign DAEDALUS – Data, Decisions and...

MIRACLEMultilingual Information RetrievAl for the CLEF campaign
DAEDALUS – Data, Decisions and Language, S.A.www.daedalus.es
Universidad Carlos III de Madrid (UC3M)www.uc3m.es
Universidad Politécnica de Madrid (UPM)www.upm.es
Partially funded by IST-2001-32174 (OmniPaper) and CAM 07T/0055/2003 projects

MIRACLE – ImageCLEF 2003 2
ImageCLEF 2003
Participation in:
Monolingual task: English -> English: 5 different runs
Bilingual tasks: Spanish->English: 6 runs German->English: 6 runs French->English: 4 runs Italian->English: 4 runs
TOTAL: 25 runs

MIRACLE – ImageCLEF 2003 3
System Architecture
IR engine: XAPIAN (based on Probabilistic IR model) Filtering components: text and word extraction,
topic extraction, word count, statistic calculations Linguistic components: tokenizers, stemmers
(based on Porter algorithm), German word decompounding module, stopword filters
Translation components: API to FreeTranslation.com (full text) and ERGANE dictionary (word by word)
Semantic components: Synonym expansion for English (WordNet)
Our idea is to couple these components in different ways to evaluate different approaches and compare the influence of each one in the P/R of the IR process for each language
MIRACLE – ImageCLEF 2003 4
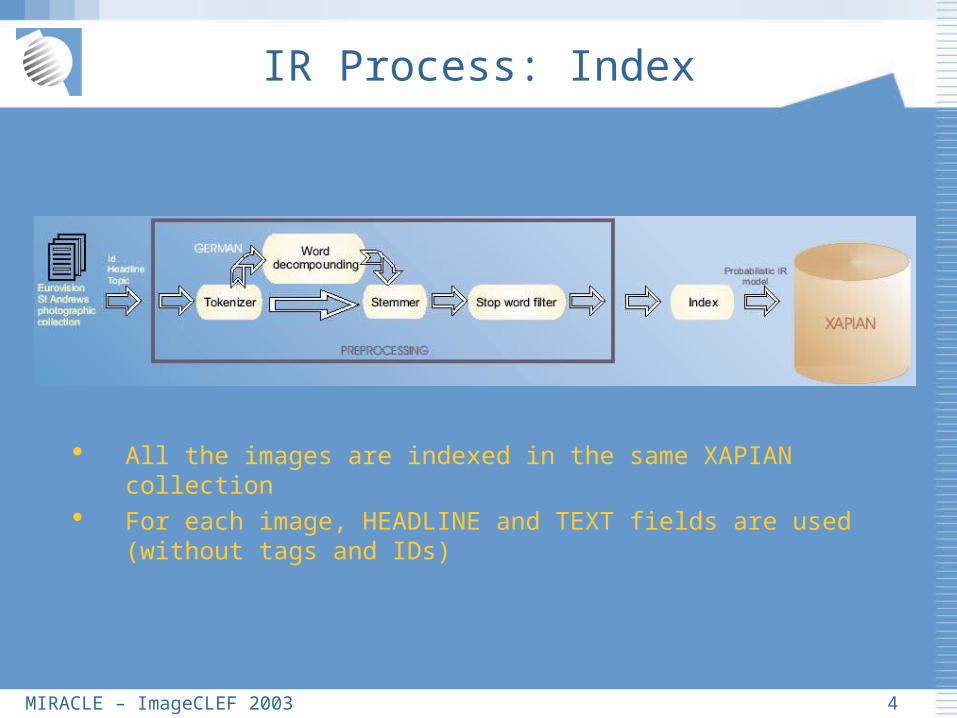
IR Process: Index
All the images are indexed in the same XAPIAN collection For each image, HEADLINE and TEXT fields are used
(without tags and IDs)

MIRACLE – ImageCLEF 2003 5
IR Process: Retrieval
Different runs, basically consisting on:1. Create the query from the topic2. Execute the query in XAPIAN system3. Retrieve 1000 best results (ranked list)
For each topic, only the TITLE field and the 1st translation variant are used
Evaluation: four relevance sets (2 judges) Union (any assessor) / Intersection (both assessors) Strict (relevant only) / Relaxed (also partially relevant)
In our evaluation, we have considered the intersection-strict, which is the most restrictive

MIRACLE – ImageCLEF 2003 6
Monolingual Runs (en->en)
OR: Word extraction in topic title stop word filtering stemming
weighted OR operator with stems Intended as the baseline run
ORlem: Word extraction in topic title stop word filtering stemming
weighted OR operator with stems and original words Idea: measure the effect of stemming
ORlemexp: Word extraction in topic title stop word filtering synonym
expansion stemming weighted OR operator with stems and original words and synonyms
Idea: measure the effect of increasing the recall despite the penalization in precision
Doc: Index topic title as document retrieve similar docs Idea: Confirm that this is a similar approach to vector space model
ORrf: Query with OR operator with stems Top 25 docs 250 most
important terms new weighted OR query Idea: measure the effect of simplest blind relevance feedback
MIRACLE – ImageCLEF 2003 7
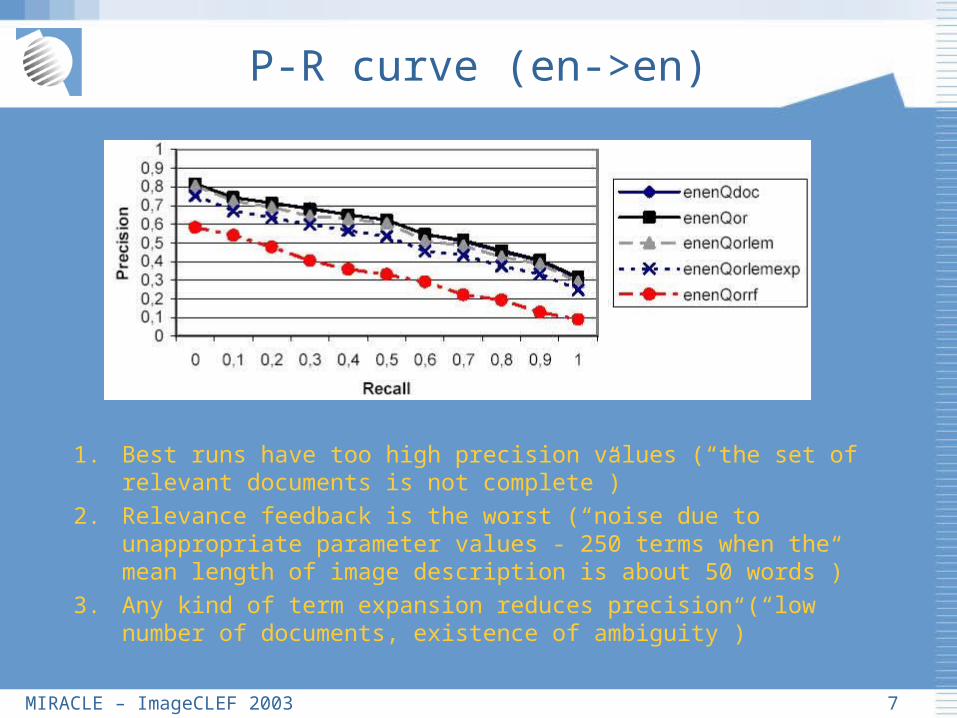
P-R curve (en->en)
1. Best runs have too high precision values (“the set of relevant documents is not complete”)
2. Relevance feedback is the worst (“noise due to unappropriate parameter values - 250 terms when the mean length of image description is about 50 words”)
3. Any kind of term expansion reduces precision (“low number of documents, existence of ambiguity”)

MIRACLE – ImageCLEF 2003 8
Average Precision (en->en)
1. Best run is weighted OR query and Doc (“in Probabilistic IR model, weighted OR is like term weights in Vector Space Model”)
2. The evaluation with other relevance sets gives a slight increase in overall precision

MIRACLE – ImageCLEF 2003 9
Bilingual Runs (fr,ge,it,sp->en)
TOR1: Topic title FreeTranslation Word extraction stop word filtering
stemming weighted OR operator with stems Similar to monolingual OR, intended as the baseline run
TOR3: Topic title FreeTranslation + ERGANE Word extraction stop
word filtering stemming weighted OR operator with stems Idea: improve translation by combining different sources
Tdoc: Topic title FreeTranslation Index as document retrieve similar
docs TOR3exp:
Topic title FreeTranslation + ERGANE Word extraction stop word filtering synonym expansion stemming weighted OR operator with stems and original words and synonyms
TOR3full: The same as TOR3 but also including topic title in original language Idea: evaluate the effect of text that cannot be or is incorrectly
translated TOR3fullexp:
Combination of TOR3exp and TOR3full
MIRACLE – ImageCLEF 2003 10
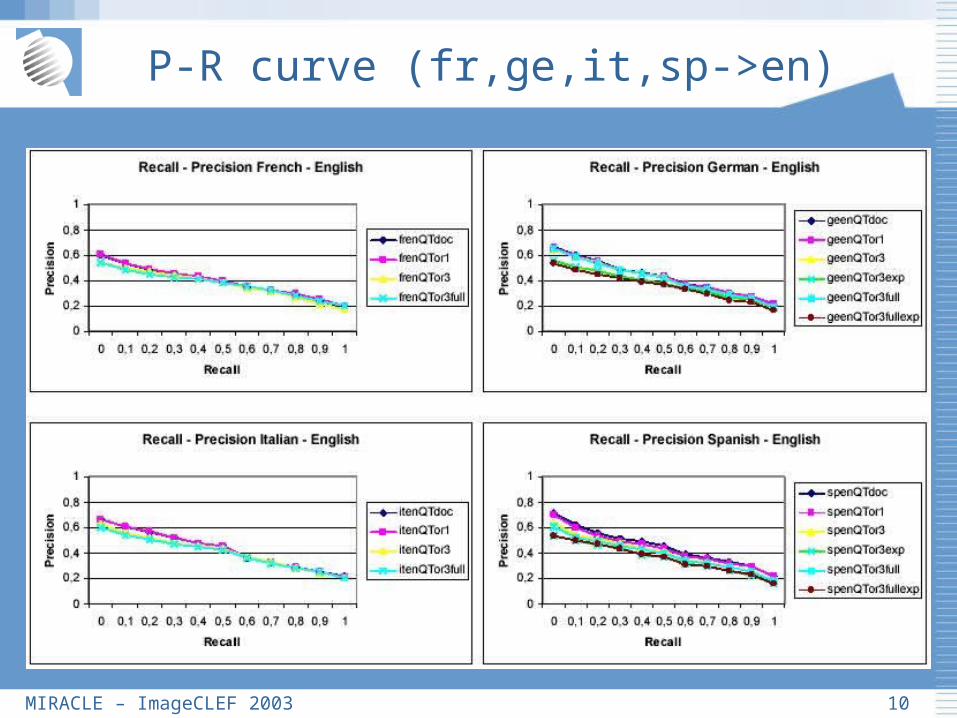
P-R curve (fr,ge,it,sp->en)

MIRACLE – ImageCLEF 2003 11
P-R curve (fr,ge,it,sp->en)
1. Although all results are similar, TOR1 and Tdoc are the best ones in all cases
2. Using word by word translation with ERGANE has proved to be worse: translation is not adequate or the expansion of the query makes wider queries thus reducing precision
3. Again, as in monolingual task, any kind of term expansion reduces precision, if not coping with ambiguity
4. Spanish, German and Italian have similar results, but French is slightly worse: FreeTranslation is worse for French or the French topics are harder to translate
5. Spanish->English gives our best individual results !!!
6. Comparing bilingual/monolingual results, a difference of about 10-15% arises (similar to our participation in CLEF tasks this year)
MIRACLE – ImageCLEF 2003 12
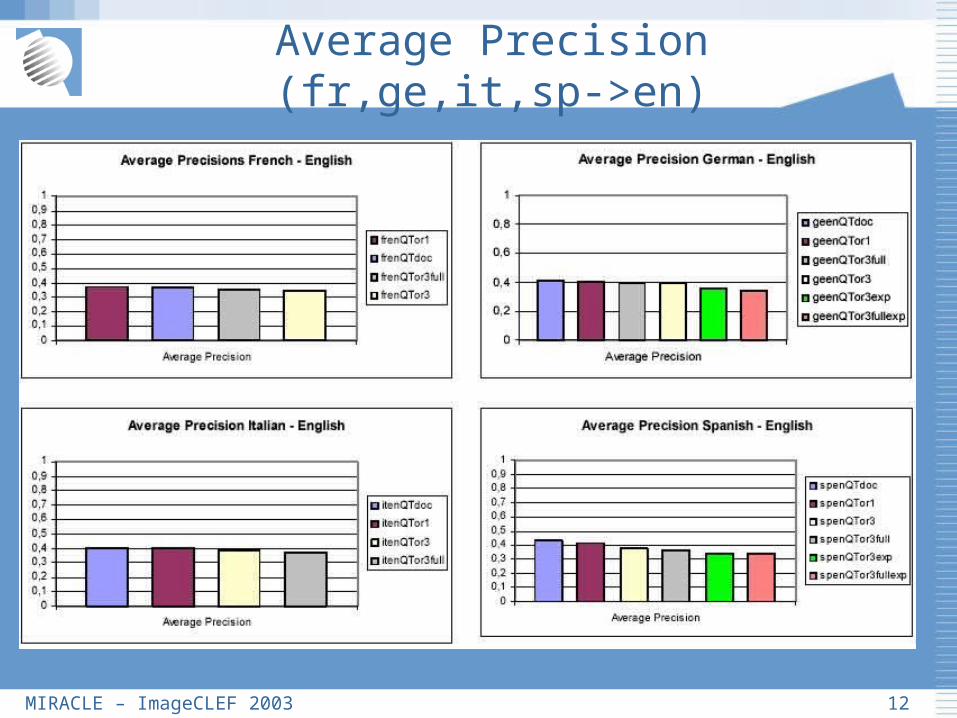
Average Precision (fr,ge,it,sp->en)

MIRACLE – ImageCLEF 2003 13
Conclusions and Future Work
As new-comers to CLEF, we have worked hard to build the infrastructure to be able to easily execute different runs
Simplest approaches have proved to be the best if not handling ambiguity caused by term expansion
Next time…: POS filtering for syntactic disambiguation to handle
ambiguity Evaluate the effect of using stemming (and its quality)
or not in high flexible languages like Spanish/French/Italian
More focus on Spanish: better stemmer, better synonym expansion (directly in Spanish)
Evaluate the quality of translation engines with respect to the IR process

















![SafeChania Daedalus [Poster]](https://static.fdocuments.in/doc/165x107/55d255abbb61eb9d638b45d9/safechania-daedalus-poster.jpg)
