
Melanie Warrick, Deep Learning Engineer, Skymind.io at MLconf SF - 11/13/15
29
Attention Models Melanie Warrick @nyghtowl
-
Upload
mlconf -
Category
Technology
-
view
1.943 -
download
2
Transcript of Melanie Warrick, Deep Learning Engineer, Skymind.io at MLconf SF - 11/13/15

Attention Models
Melanie Warrick@nyghtowl

@nyghtowl
Overview
- Attention
- Soft vs Hard
- Hard Attention for Computer Vision
- Learning Rule
- Example Performance

@nyghtowl
Attention ~ Selective

@nyghtowl
Attention Mechanism
input focus
sequential | context
weights

@nyghtowl
Zoom-lens adds changing filter size
Attention Techniques
Spotlight varying resolution

@nyghtowl
Where to look?
Attention Decision

@nyghtowl
Soft- read all input & weighted average of all expected output- standard loss derivative
Hard- samples input & weighted average of estimated output - policy gradient & variance reduction
Model Types

@nyghtowl
Soft vs Hard Focus Examples
Soft
Hard
@nyghtowl
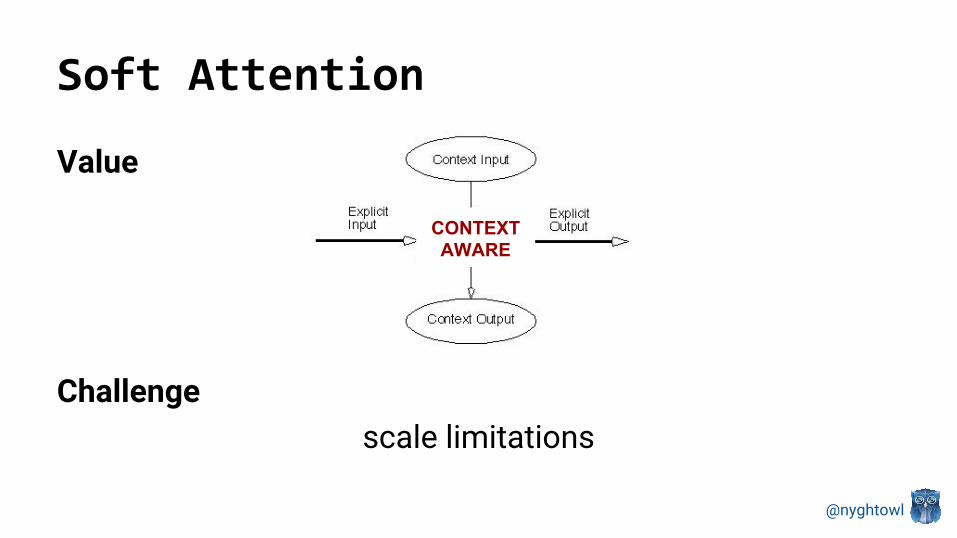
Soft Attention
Value
Challengescale limitations
CONTEXT AWARE

@nyghtowl
Valuedata size # computations
Challengecontext & training time
Hard Attention

@nyghtowl
Model Variations
Soft- NTM Neural Turing Machine- Memory Network- DRAW Deep Recurrent Attention Writer (“Differentiable”)- Stacked-Augmented Recurrent Nets
Hard- RAM Recurrent Attention Model- DRAM Deep Recurrent Attention Model - RL-NTM Reinforce Neural Turing Machine

@nyghtowl
- Memory - Reading / Writing - Language generation- Picture generation- Classifying image objects- Image search- Describing images / videos
Applications

@nyghtowl
Hard Model & Computer Vision
@nyghtowl
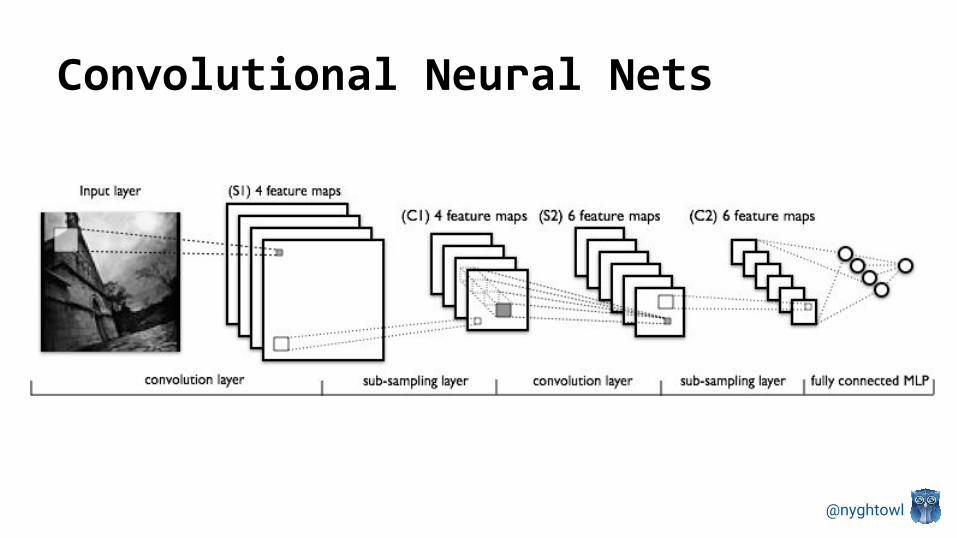
Convolutional Neural Nets

@nyghtowl
Linear Complexity Growth

@nyghtowl
Constrained Computations

@nyghtowl
Recurrent Neural Nets

@nyghtowl
General Goal
- min error | max reward
- reward can be sparse & delayed

@nyghtowl
Deep Recurrent Attention Model

@nyghtowl
REINFORCE Learning Rule
weight change = reward change given glimpse

@nyghtowl
Performance Comparison
SVHN - Street View House Number data-set

@nyghtowl
Performance Comparison
DRAM vs CNN - Computation Complexity

@nyghtowl
Last Points
- adaptive selection & context
- constrained computations
- accuracy

@nyghtowl
● Neural Turing Machines http://arxiv.org/pdf/1410.5401v2.pdf (Graves et al., 2014)● Reinforcement Learning NTM http://arxiv.org/pdf/1505.00521v1.pdf (Zaremba et al., 2015)● End-To-End Memory Network http://arxiv.org/pdf/1503.08895v4.pdf (Sukhbaatar et al., 2015)● Recurrent Models of Visual Attention http://arxiv.org/pdf/1406.6247v1.pdf (Mnih et al., 2014)● Multiple Object Recognition with Visual Attention http://arxiv.org/pdf/1412.7755v2.pdf (Ba et al., 2014)● Show, Attend and Tell http://arxiv.org/pdf/1502.03044v2.pdf (Xu et al., 2015)● DRAW http://arxiv.org/pdf/1502.04623v2.pdf (Gregor et al., 2015)● Neural Machine Translation by Jointly Learning to Align and Translate http://arxiv.org/pdf/1409.
0473v6.pdf (Bahdanau et al., 2014)● Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets http://arxiv.org/pdf/1503.
01007v4.pdf (Joulin et al., 2015)● Deep Learning Theory & Applicaitons: https://www.youtube.com/watch?v=aUTHdgh1OjI● The Unreasonable Effectiveness of Recurrent Neural Networks https://karpathy.github.
io/2015/05/21/rnn-effectiveness/● Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning http://www-
anw.cs.umass.edu/~barto/courses/cs687/williams92simple.pdf (Williams, 1992)
References

@nyghtowl
● Spatial Transformer Networks http://arxiv.org/pdf/1506.02025v1.pdf (Jaderberg et al., 2015)● Recurrent Spatial Transformer Networks http://arxiv.org/pdf/1509.05329v1.pdf (Sønderby et al., 2015)● Spatial Transformer Networks Video https://youtu.be/yGFVO2B8gok● Learning Stochastic Feedforward Neural Networks http://www.cs.toronto.edu/~tang/papers/sfnn.pdf
(Tang & Salakhutdinov, 2013)● Learning Stochastic Recurrent Networks http://arxiv.org/pdf/1411.7610v3.pdf (Bayer & Osendorfer
2015)● Learning Generative Models with Visual Attention http://www.cs.toronto.edu/~tang/papers/sfnn.pdf
(Tang et al., 2014)
References

@nyghtowl
Special Thanks
● Mark Ettinger● Rewon Child● Diogo Almeida● Stanislav Nikolov● Adam Gibson● Tarin Ziyaee● Charlie Tang● Dave Kammeyer

@nyghtowl
References: Images● http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/● http://deeplearning.net/tutorial/lenet.html● https://stats.stackexchange.com/questions/114385/what-is-the-difference-between-
convolutional-neural-networks-restricted-boltzma● http://myndset.com/2011/12/15/making-the-switch-where-to-find-the-money-for-your-digital-
marketing-strategy/● http://blog.archerhotel.com/spyglass-rooftop-bar-nyc-making-manhattan-look-twice/● http://www.serps-invaders.com/blog/how-to-find-broken-links-on-your-site/● http://arxiv.org/pdf/1502.04623v2.pdf● https://en.wikipedia.org/wiki/Attention● http://web.media.mit.edu/~lieber/Teaching/Context/

@nyghtowl
Attention Models
Melanie Warrick
skymind.io (company)
gitter.im/deeplearning4j/deeplearning4j
@nyghtowl
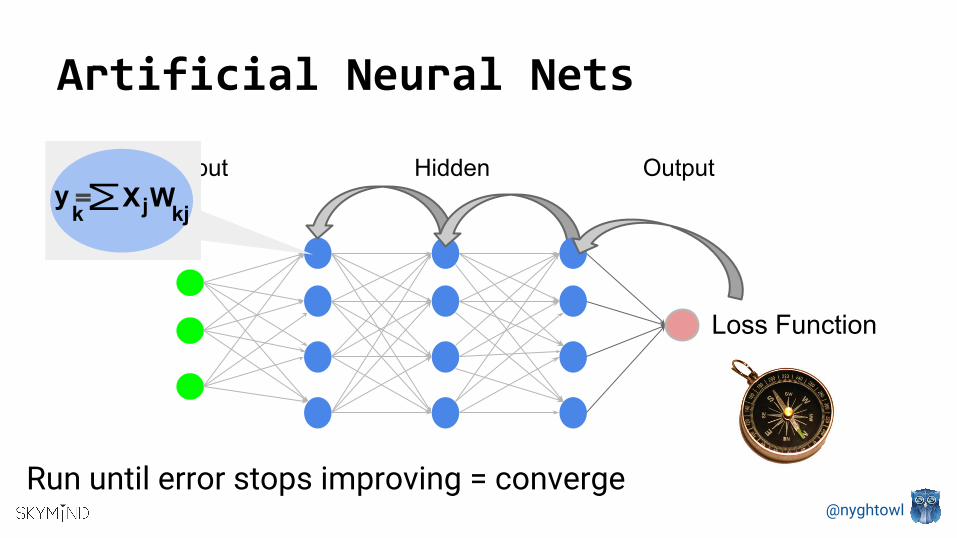
Artificial Neural Nets
Input OutputHidden
Run until error stops improving = converge
Loss Function
Outputk jXM kjWy


















