
Meet Hadoop Family: part 3
16
MAP REDUCE & SPARK Meet Hadoop Family: part 3
-
Upload
caizerx -
Category
Data & Analytics
-
view
176 -
download
1
Transcript of Meet Hadoop Family: part 3

MAP REDUCE&
SPARK
Meet Hadoop Family: part 3
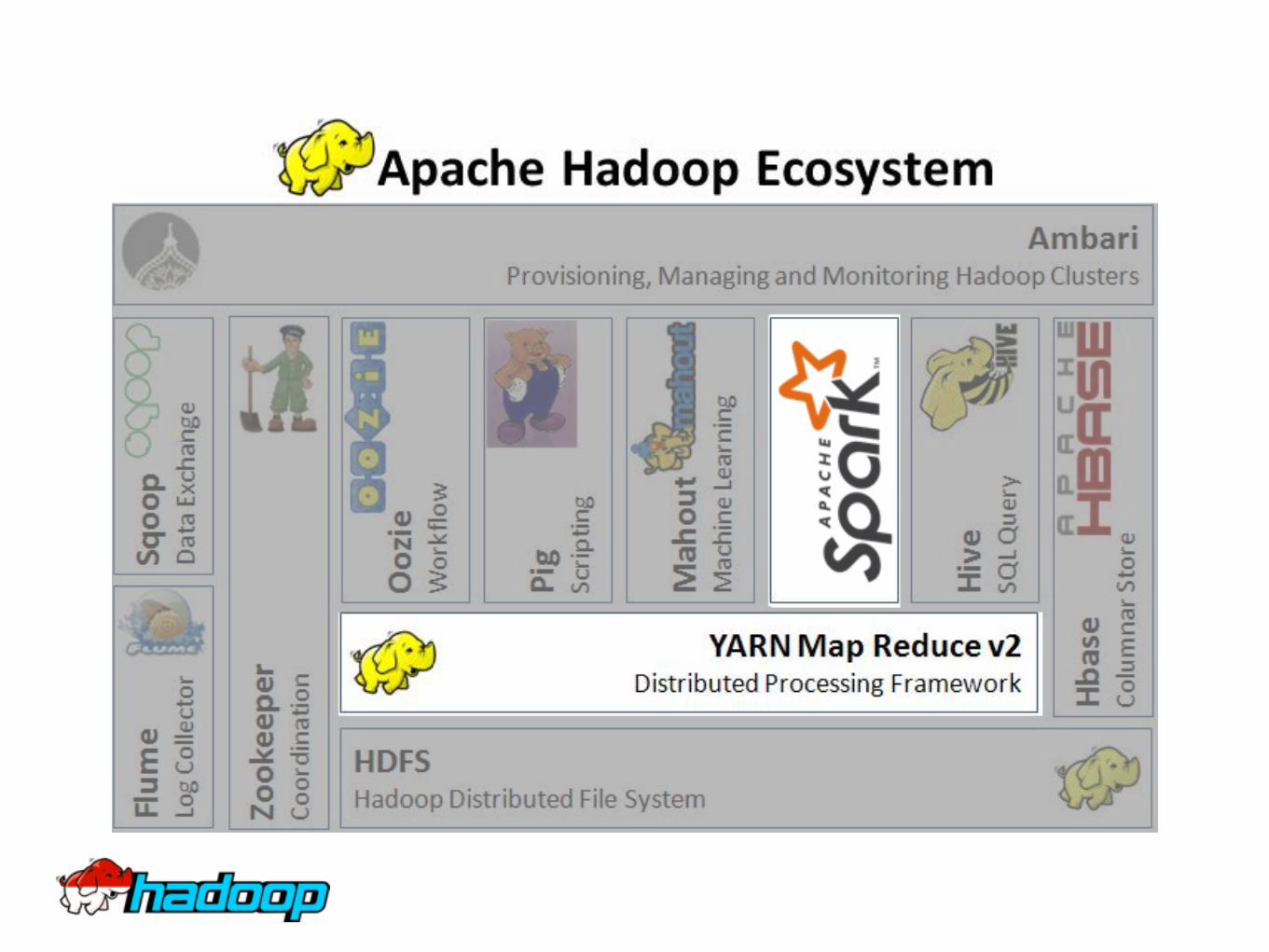

• What are they? Programming framework to write Hadoop applications. MapReduce: original, batch based, used by other applications such as Hive, Sqoop, etc Spark: newer, memory bound, generally faster than MapReduce, best for iteration intensive processes
such as machine learning
• Both work on top of YARNMapReduce was native framework of YARN Spark can work on top of YARN or as a stand alone processes

• MapperSplits the input from HDFSMost likely one split per HDFS blockEach split has a key and value
• ReducerSimillar as an aggregator in common SQL Output of reducer written to HDFS Default reducer = 2
• Sort and Shuffle phaseGenerally most demanding phase
Map Reduce
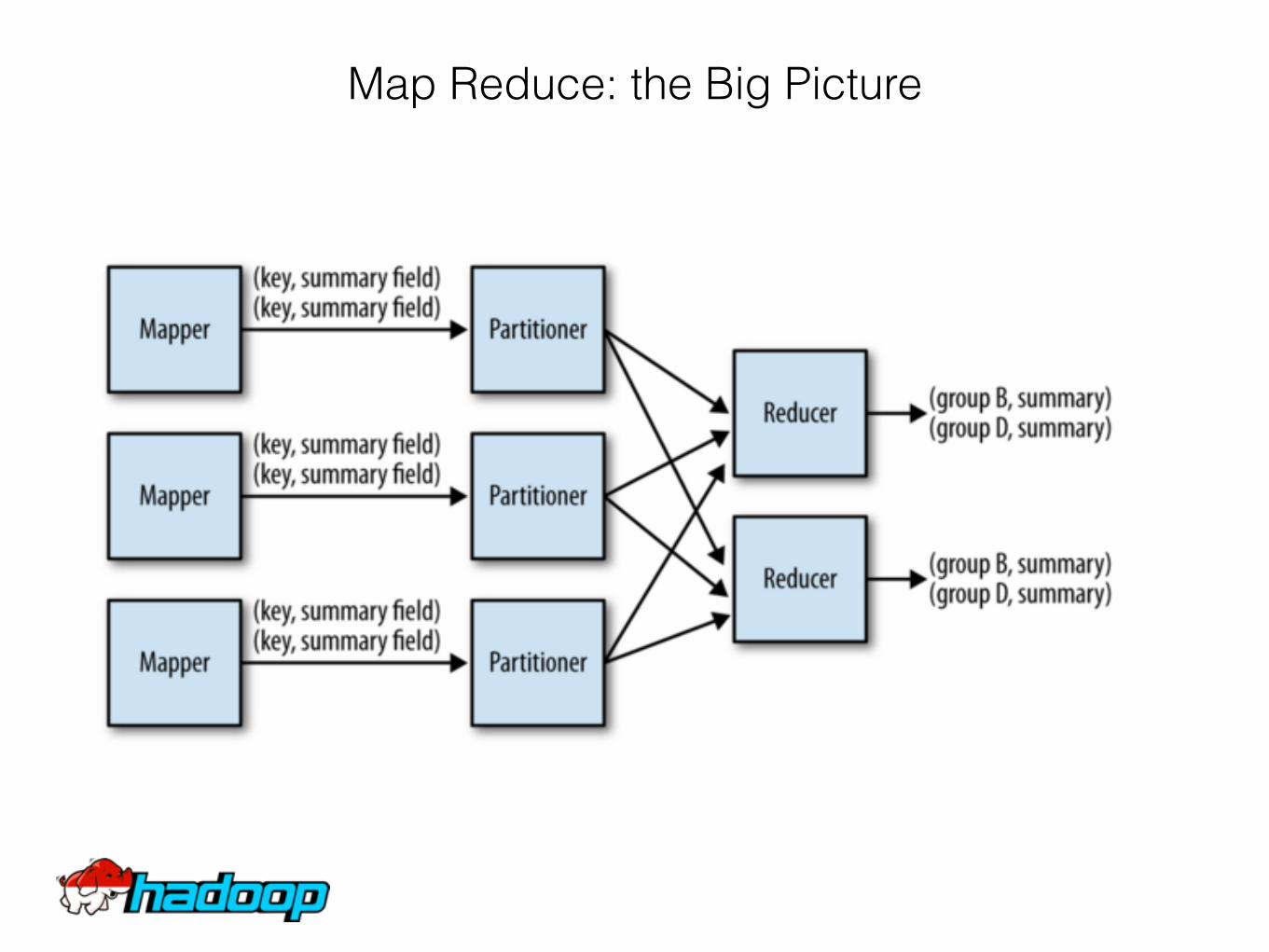
Map Reduce: the Big Picture

• DAG (Directed Acyclic Graph) scheduler engine
• RDDImmutable structure stored in memory accross the cluster Can be created from a file, data in memory or another RDDResilient, if data in memory lost, it can be recreated Distributed, stored in memory across the clusterDataset, contains data initially from HDFS or another RDD
• OperationsTransformation, recreate another RDD out of existing RDD, lazy operatorAction, return value of any type but RDD
• Some Spark modules Spark streaming, mlib, graphx
Spark

Spark Driver and Worker

Spark: the Big Picture
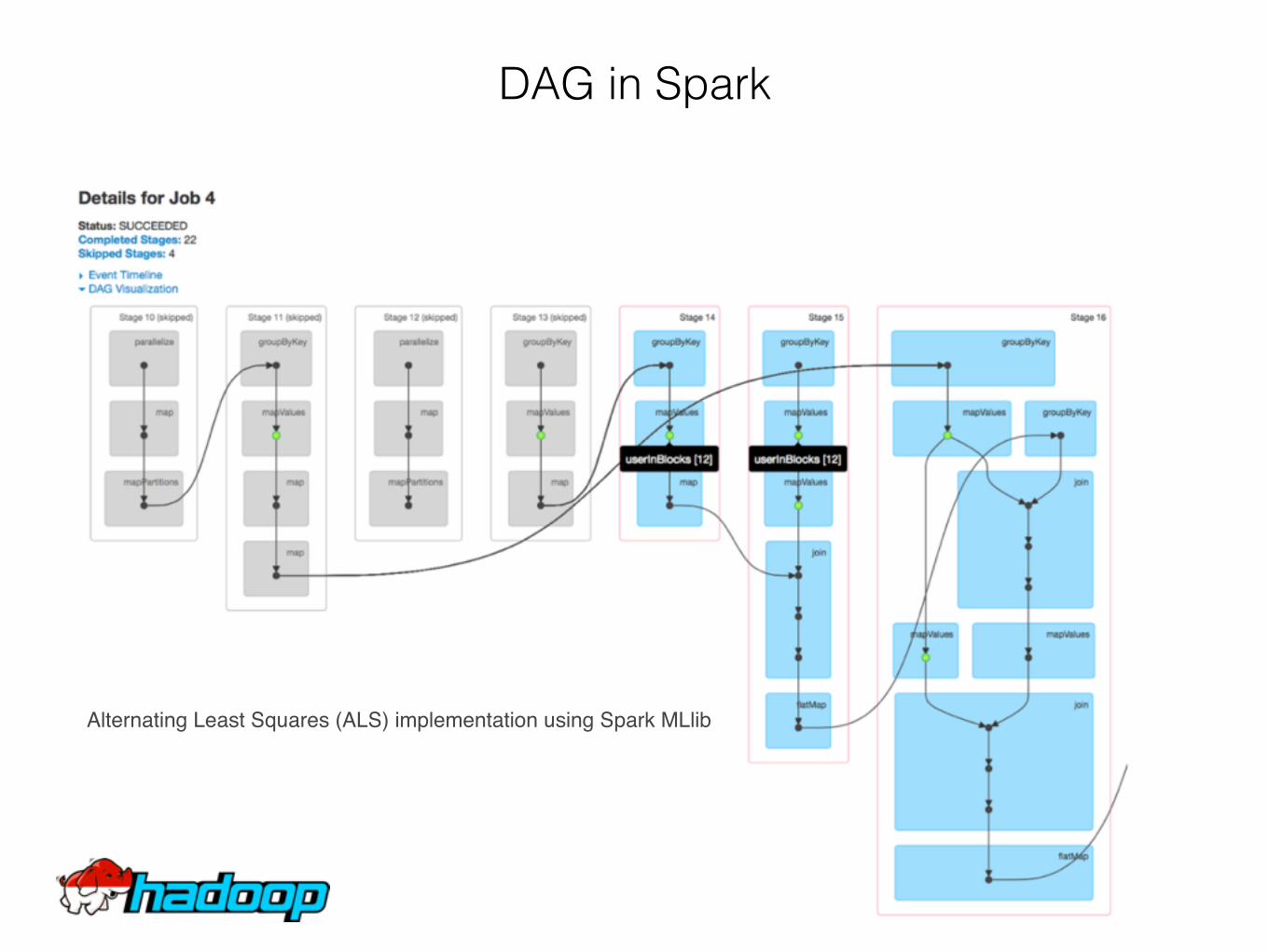
DAG in Spark
Alternating Least Squares (ALS) implementation using Spark MLlib

Spark Run Mode
• Stand alone Simple distributed FIFO
• On YARNTwo Deploy mode: client and cluster
• On MesosWider partitioning capability (with other framework and between Spark instances)
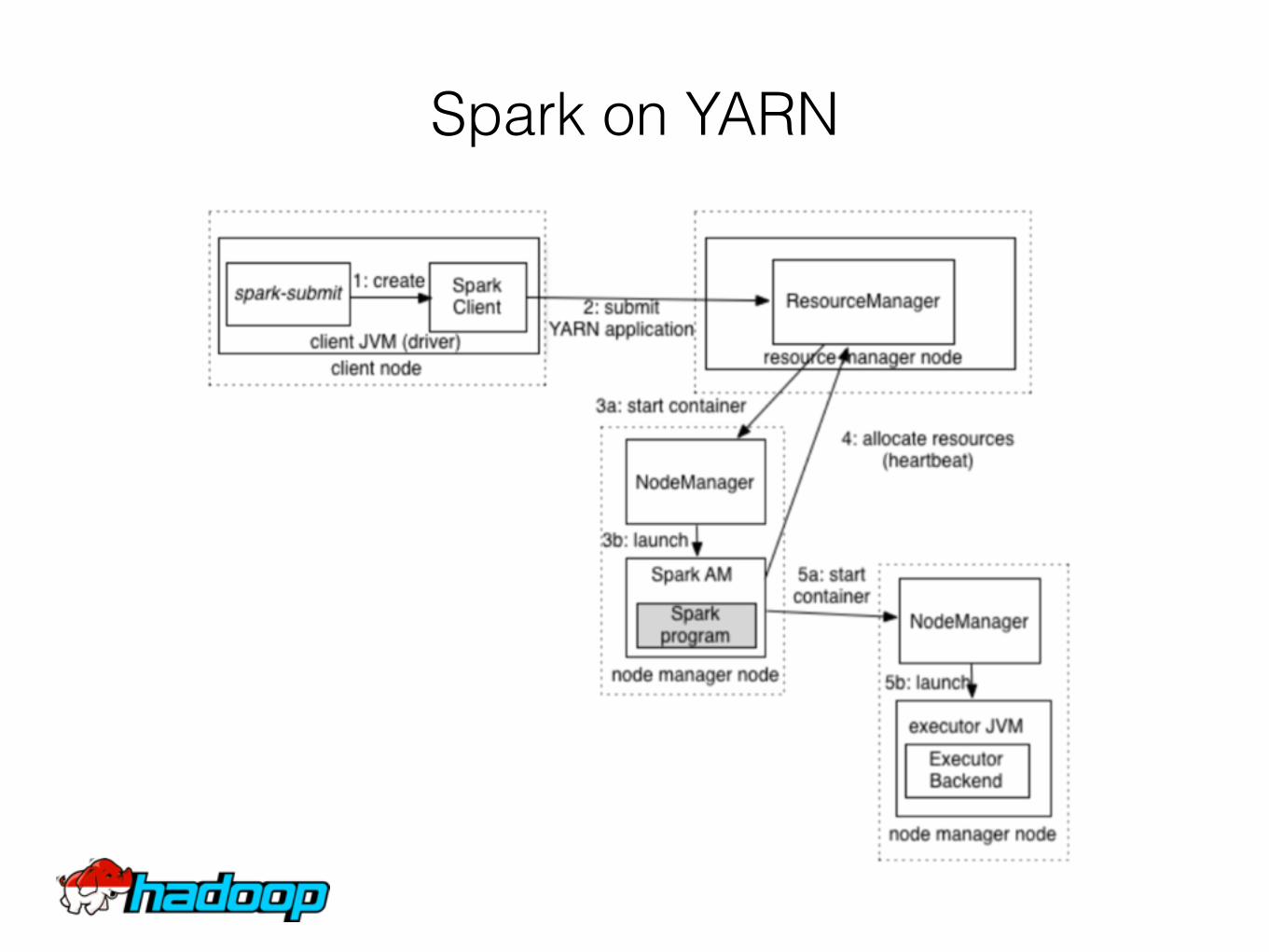
Spark on YARN

MapReduce vs Spark
MapReduce Spark
Disk bound Memory bound
Mapper Reducer DAG scheduler
One YARN container per task One YARN container per application
Great for batch programs Great for iterative programs

Map Reduce Program Example: Word Counts
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }

Spark Program Example: Word Counts
scala> var file = sc.textFile(“hdfs://sabtu:8020/rawdata/emails.csv”);
scala> var counts = file.flatMap(line => line.split(“ “)). map(word => (word, 1)).reduceByKey( _ + _).sortByKey();
scala> counts.saveAsTextFile( "hdfs://sabtu:8020/tmp/sparkcount");
scala> sc.stop();
scala> sys.exit();

• Resource manager web interface, port 8088
• Job history web interface, port 19888

Questions?https://www.meetup.com/Jakarta-Hadoop-Big-Data/


















