MDL Keys Revisited Joseph L. Durant, Burton A. Leland, Douglas R. Henry and James G. Nourse MDL...
38
MDL Keys Revisited Joseph L. Durant, Burton A. Leland, Douglas R. Henry and James G. Nourse MDL Information Systems
Transcript of MDL Keys Revisited Joseph L. Durant, Burton A. Leland, Douglas R. Henry and James G. Nourse MDL...

MDL Keys Revisited
Joseph L. Durant, Burton A. Leland, Douglas R. Henry and
James G. NourseMDL Information Systems

Overview
• What are MDL Keys?
• Constructing better keys– metrics– optimization by "educated guesswork"– optimization by Genetic Algorithms
• Conclusions

What are MDL Keys
• a.k.a. SSKeys
• Originally designed to support sub-structure searching
• Bits encoding molecular features
• Most follow the structure of:– a property on atom A– a property on atom B– A and B are separated by N bonds (0<=N<=4)– this pattern is encountered M or more times

MDL Keys - What Are They?
• Some keys code for specific bonds (C-Cl, S-P)
• Other keys code for a property in an atomic neighborhood (C-CCO, Q-OO)
• Still others are custom properties– Sgroup properties– rings– atom types

MDL Keys - Standard Implementation
• MDL’s SSKeys are encountered in 2 flavors:– a 960 keybitset– a 166 keybitset (Subset or User Keys)

The 960 Keybitset
• Created to support substructure searching
• Encodes 1387 molecule features
• Encodes features with >0, >1, >2 and >4 occurrences
• Features can turn on 1, 2 or 3 keybits
• many of the keybits can be set by multiple features

The 166 Keybitset
• Originally created to embody an earlier MDL keybitset
• Largely correspond to “chemist-meaningful” features

166 Keybitset Definitions
1 - isotope
2 - 103<atomic number<256
.
84 - NH2
85 - CN(C)C
86 - CH2QCH2
.
165 - ring
166 - fragments

Current Uses for MDL Keys• Clustering/diversity
– Brown & Martin, JCICS, 1996, 36, 572-584.
– McGregor & Pallai, JCICS, 1997, 37, 443-448.
• Library generation/evaluation– Brown & Martin, J. Med. Chem., 1997, 40, 2304-2313.
– Koehler, Dixon, & Villar, J. Med. Chem.,1999, 42, 4695-4704.
– Ajay, Bemis, & Murcko, J. Med. Chem., 1999, 42, 4942-4951.
– Koehler & Villar, J. Comp. Chem., 2000, 21, 1145-1152.
• Information content/comparison– Brown & Martin, JCICS, 1997, 37, 1-9.
– Jamois, Hassan, & Waldman, JCICS, 2000, 40, 63-70.
– Briem & Lessel, Perspect. Drug Disc. Des., 2000, 20, 231-244.

Can We Construct Better Keys?
• Keybitsets optimized for substructure searching
• Keybitsets constructed to minimize memory/storage footprint
• But they work remarkably well already

But...
• bit-setting algorithm has untapped power
• algorithm defines ~3200 unique features
• algorithm allows keybit to be set for "N or more occurrences"

Find a Metric

Success Measure
• Defined by Briem and Lessel, Perspect. Drug Disc. Des., 20, 231 (2000).
• Modified to account for ties
• Evaluates the ability to differentiate classes of activity

Test Set
• 134 PAF antagonists
• 49 5-HT3 antagonists
• 49 TXA2 antagonists
• 40 ACE inhibitors
• 111 HMG-CoA reductase inhibitors
• 574 "random" MDDR compounds

Success Measure - Evaluation
• Calculate the 10 nearest neighbors for each "active" molecule
• Calculate the fraction of nearest neighbors in the same activity class as the target
• Allow for ties; expand the number of neighbors until the tie is broken

Success Measure

Starting Points...
• 166 keybitset
• 960 keybitset
• 3234 keybitset

Modifying the 960 Keybitset
• all the "singly mapped" keybits – 726 keybitset
• all the 960 keybitset features, one feature per bit– 1387 keybitset

Initial Success Measures

Optimization?
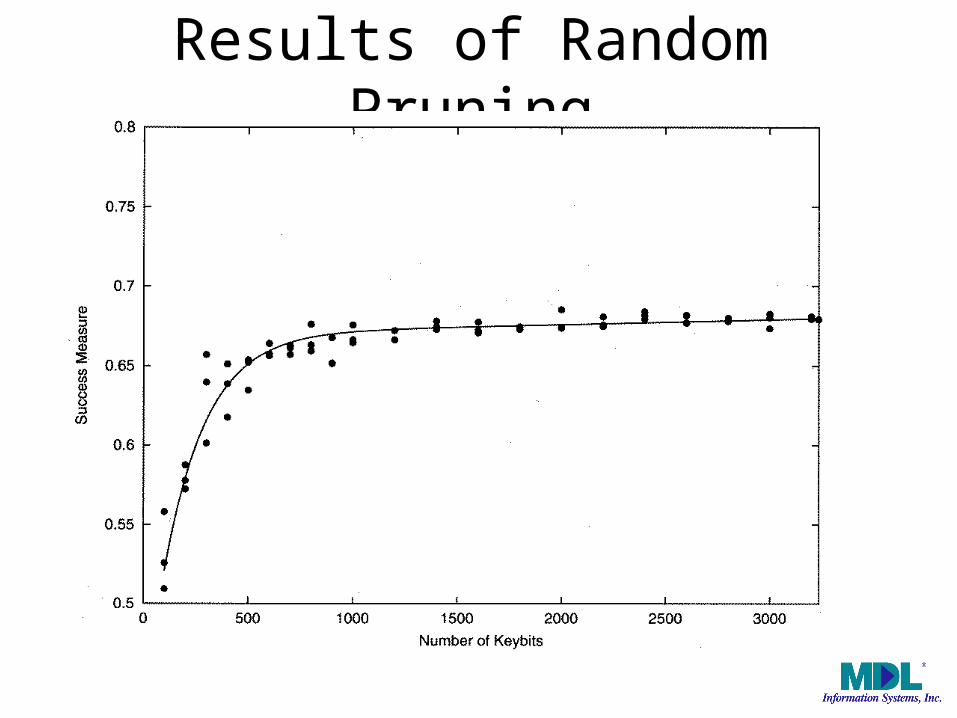
Results of Random Pruning

Intelligent Selection(Educated Guesswork)
• Differentiating compounds– active from inactive– active from other actives

Surprisal Analysis
• Surprisal = log ( probability 1 / probability 2)probability 1 = "active" molecules
probability 2 = "inactive" molecules
• assume Poisson-distributed errors
• | Surprisal S/N | = | Surprisal / surprisal |

Surprisals for 166 Keybitset

Surprisal S/N for 166 Keybitset

Surprisal Pruning

Success Measure vs. Surprisal S/N
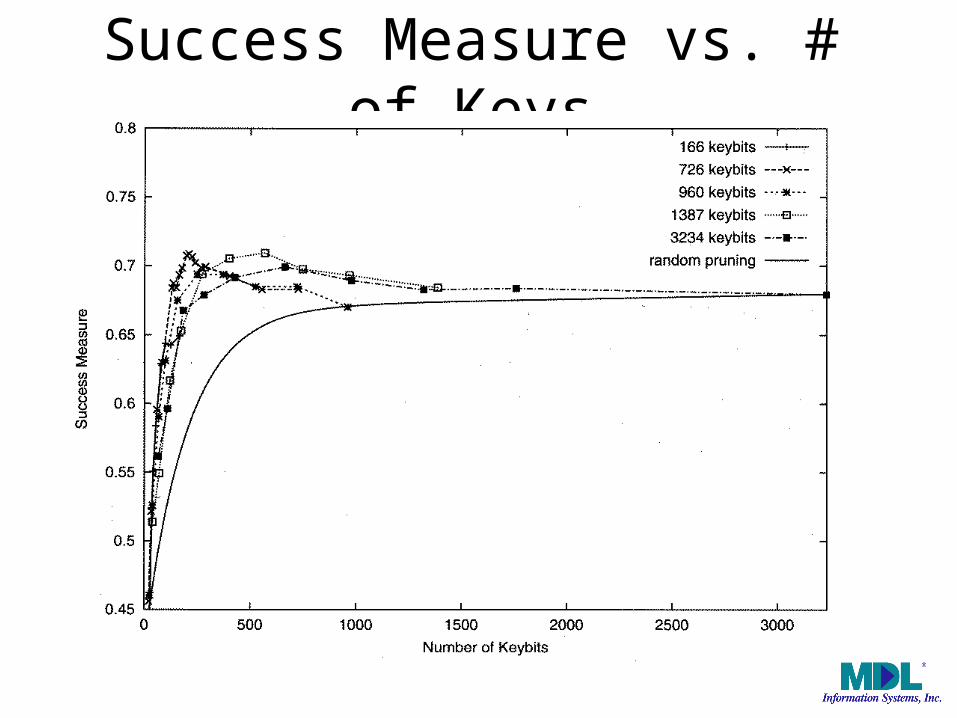
Success Measure vs. # of Keys

Success Measure vs. # of Keys

Success Measures
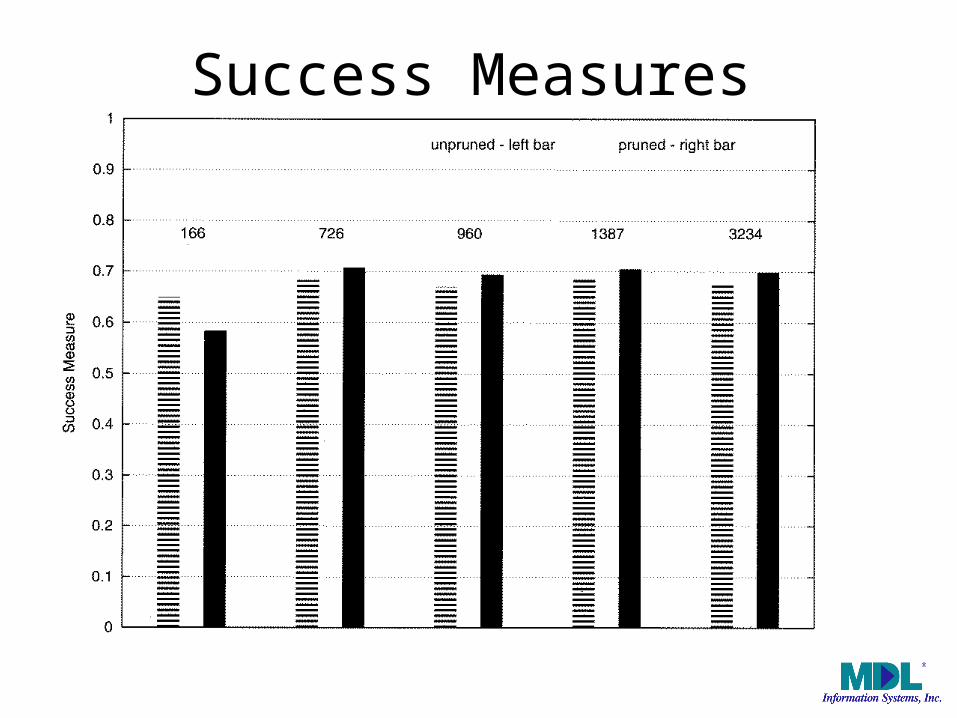
Success Measures

What About Multiple Occurrences?
• Keybits can be set for >0, >1, >2,... occurrences of features
• Inclusion of multiple occurrence keybits enhances performance for substructure searching

Assembling a Composite Keybitset
• Construct keybitsets for >0, >1, >2, >3... occurrences
• Surprisal prune to the 2-sigma level
• Concatenate the resulting keybitsets– only add keybits for new features

Success Measure
• Success Measure increases until "7 or more" occurrences
• 1283 keybits in final set
• Final success measure = 71.26%

Genetic Algorithm
• We used the SUGAL genetic algorithm package– written by Dr. Andrew Hunter at University of
Sunderland, UK
• Identification of local minima is straightforward
• Small keybitsets with good performance can be identified
• The global minimum is elusive

Final Success Measures

Conclusions
• Key performance can be substantially improved by reoptimizing keybitsets
• Key performance is not substantially improved for MDL keybitsets longer than ~500 bits

Acknowledgements
• use of SUGAL Genetic Algorithm Package, written by Dr. Andrew Hunter at University of Sunderland, UK
• correspondence with and MDDR extregs from Dr. Hans Briem, Boehringer Ingelheim Pharma KG