
Marcel Kornacker, Software Enginner at Cloudera - "Data modeling for data science: Simplify your...
31
1 © Cloudera, Inc. All rights reserved. Simplifying Analytic Workloads via Complex Schemas Marcel Kornacker Data Modeling for Data Science
-
Upload
dataconomy-media -
Category
Technology
-
view
172 -
download
0
Transcript of Marcel Kornacker, Software Enginner at Cloudera - "Data modeling for data science: Simplify your...

1© Cloudera, Inc. All rights reserved.
Simplifying Analytic Workloads via Complex Schemas
Marcel Kornacker
Data Modeling for Data Science

2© Cloudera, Inc. All rights reserved.
• Relational databases are optimized
to work with flat schemas
• Much of the useful information in
the world is stored using complex
schemas (a.k.a., the “document
model”)
• Log files
• NoSQL data stores
• REST APIs
On Complex Schemas

3© Cloudera, Inc. All rights reserved.
Handling Complex Schemas in SQL

4© Cloudera, Inc. All rights reserved.
Complex Schemas and Data Science

5© Cloudera, Inc. All rights reserved.
Think Like A Data Scientist

6© Cloudera, Inc. All rights reserved.
Building Data Science Teams: A Moneyball Approach

7© Cloudera, Inc. All rights reserved.
Leveraging The Power of SQL Engines…

8© Cloudera, Inc. All rights reserved.
…While Managing the Cost of SQL Engines

9© Cloudera, Inc. All rights reserved.
Intentional Complex Schemas

10© Cloudera, Inc. All rights reserved.
Better Resource Utilization

11© Cloudera, Inc. All rights reserved.
Higher Data Quality

12© Cloudera, Inc. All rights reserved.
Simplifying Analytic Queries

13© Cloudera, Inc. All rights reserved.
Data Science For Everyone

14© Cloudera, Inc. All rights reserved.
Nested Types in Impala
Support for Nested Data Types: STRUCT, MAP, ARRAY
Natural Extensions to SQL
Full Expressiveness of SQL with Nested Types

15© Cloudera, Inc. All rights reserved.
Example TPCH-like SchemaCREATE TABLE Customers {
id BIGINT,
address STRUCT<
city: STRING,
zip: INT
>
orders ARRAY<STRUCT<
date: TIMESTAMP,
price: DECIMAL(12,2),
cc: BIGINT,
items: ARRAY<STRUCT<
item_no: STRING,
price: DECIMAL(9,2)
>>
>>
}

16© Cloudera, Inc. All rights reserved.
Impala Syntax Extensions
• Path expressions extend column references to scalars (nested structs)
• Can appear anywhere a conventional column reference is used
• Collections (maps and arrays) are exposed like sub-tables
• Use FROM clause to specify which collections to read like conventional tables
• Can use JOIN conditions to express join relationship (default is INNER JOIN)
Find the ids and city of customers who live in the zip code 94305:
SELECT id, address.city FROM customers WHERE address.zip = 94305
Find all orders that were paid for with a customer’s preferred credit card:
SELECT o.txn_id FROM customers c, c.orders o WHERE o.cc = c.preferred_cc
17© Cloudera, Inc. All rights reserved.
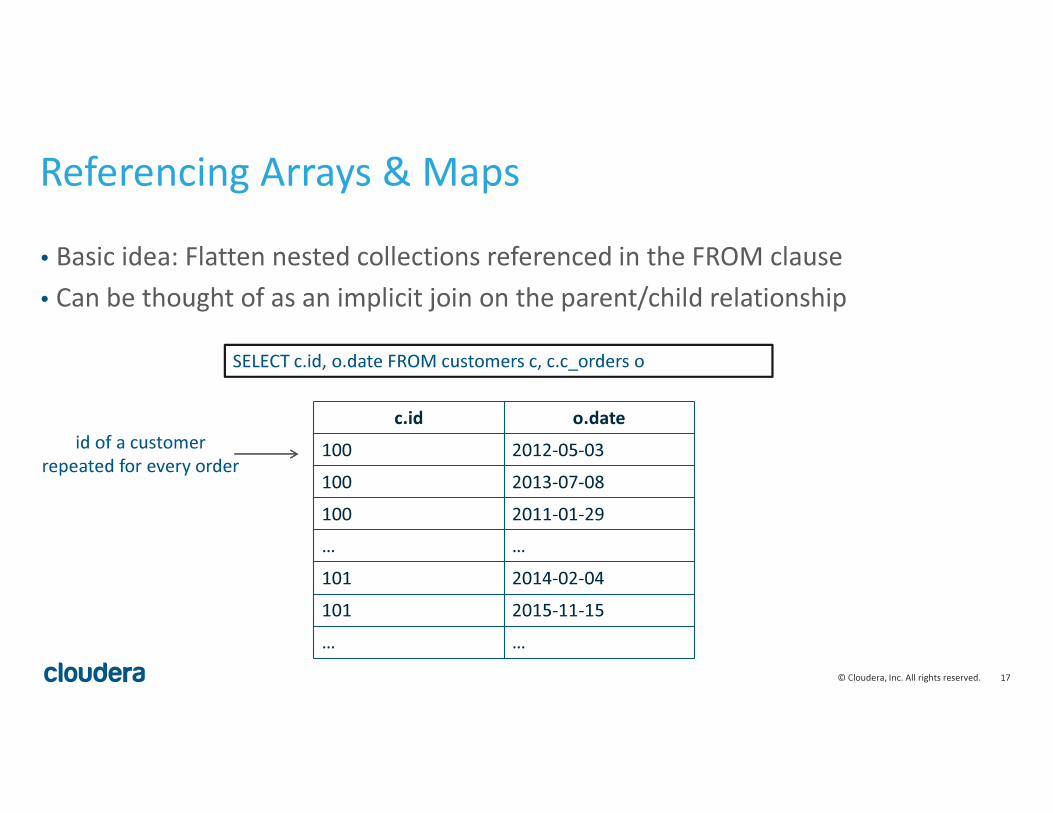
Referencing Arrays & Maps
• Basic idea: Flatten nested collections referenced in the FROM clause
• Can be thought of as an implicit join on the parent/child relationship
SELECT c.id, o.date FROM customers c, c.c_orders o
c.id o.date
100 2012-05-03
100 2013-07-08
100 2011-01-29
… …
101 2014-02-04
101 2015-11-15
… …
id of a customer
repeated for every order
18© Cloudera, Inc. All rights reserved.
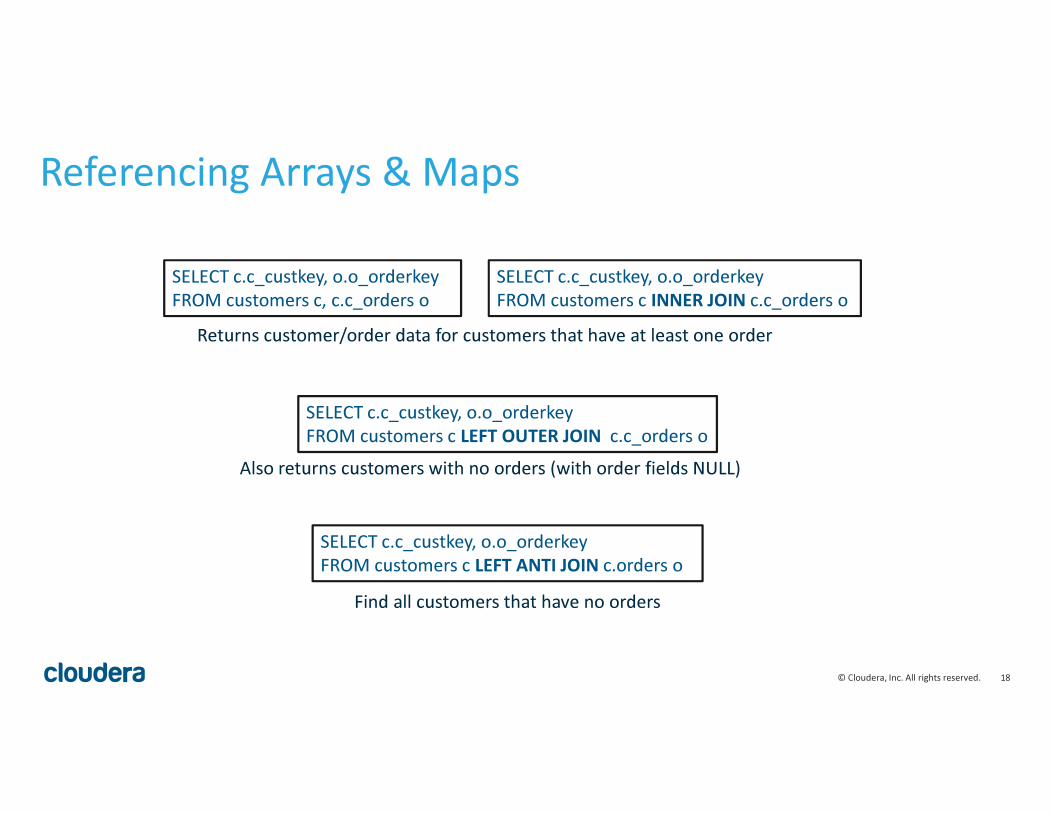
Referencing Arrays & Maps
SELECT c.c_custkey, o.o_orderkey
FROM customers c, c.c_orders o
Returns customer/order data for customers that have at least one order
SELECT c.c_custkey, o.o_orderkey
FROM customers c LEFT OUTER JOIN c.c_orders o
Also returns customers with no orders (with order fields NULL)
SELECT c.c_custkey, o.o_orderkey
FROM customers c LEFT ANTI JOIN c.orders o
Find all customers that have no orders
SELECT c.c_custkey, o.o_orderkey
FROM customers c INNER JOIN c.c_orders o

19© Cloudera, Inc. All rights reserved.
Motivation for Advanced Querying Capabilities
• Count the number of orders per customer
• Count the number of items per order
• Impractical � Requires unique id at every nesting level
• Information is already expressed in nesting relationship!
• What about even more interesting queries?
• Get the number of orders and the average item price per customer?
• “Group by” multiple nesting levels at the same time
SELECT COUNT(*) FROM customers c, c.orders o GROUP BY c.id
SELECT COUNT(*) FROM customers.orders o, o.items GROUP BY ???
Must be unique

20© Cloudera, Inc. All rights reserved.
Advanced Querying: Aggregates over Nested Collections
• Count the number of orders per customer
• Count the number of items per order
• Get the number of orders and the average item price per customer
SELECT id, COUNT(orders) FROM customers
SELECT date, COUNT(items) FROM customers.orders
SELECT id, COUNT(orders), AVG(orders.items.price) FROM customers

21© Cloudera, Inc. All rights reserved.
Advanced Querying: Relative Table References
• Full expressibility of SQL with nested collections
• Arbitrary SQL allowed in inline views and subqueries with relative table refs
• Exploits nesting relationship
• No need for stored unique ids at all interesting levels
SELECT id FROM customers c
WHERE (SELECT AVG(price) FROM c.orders.items) > 1000
SELECT id FROM customers c JOIN
(SELECT price FROM c.orders ORDER BY date DESC LIMIT 2) v

22© Cloudera, Inc. All rights reserved.
Impala Nested Types in Action
Josh Wills’ Blog post on analyzing misspelled queries
http://blog.cloudera.com/blog/2014/08/how-to-count-events-like-a-data-scientist/
• Goal: Rudimentary spell checker based on counting query/click events
• Problem: Cross referencing items in multiple nested collections
• Representative of many machine learning tasks (Josh tells me)
• Goal was not naturally achievable with Hive
• Josh implemented a custom Hive extension “WITHIN”
• How can Impala serve this use case?

23© Cloudera, Inc. All rights reserved.
Impala Nested Types in Action
account_id: bigint
search_events:
array<struct<
event_id: bigint
query: string
tstamp_sec: bigint
...
>>
install_events:
array<struct<
event_id: bigint
search_event_id: bigint
app_id: bigint
...
>>
SELECT bad.query, good.query, count(*) as cnt
FROM sessions s,
s.search_events bad,
s.search_events good,
WHERE bad.tstamp_sec < good.tstamp_sec
AND good.tstamp_sec - bad.tstamp_sec < 30
AND bad.event_id NOT IN (select search_event_id FROM s.install_events)
AND good.event_id IN (select search_event_id FROM s.install_events),
GROUP BY bad.query, good.query
Schema

24© Cloudera, Inc. All rights reserved.
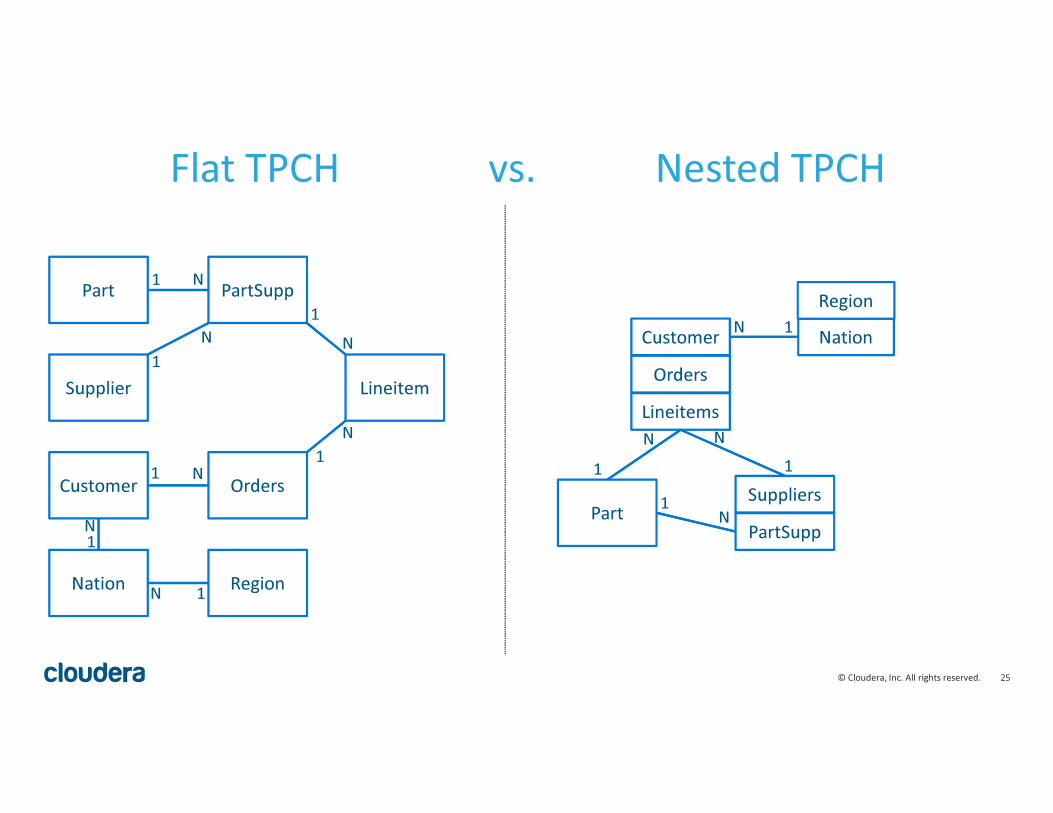
Design Considerations for Complex Schemas
• Turn parent-child hierarchies into nested collections
• logical hierarchy becomes physical hierarchy
• nested structure = join index
physical clustering of child with parent
• For distributed, big data systems, this matter:
distributed join turns into local join
25© Cloudera, Inc. All rights reserved.
Flat TPCH vs. Nested TPCH
Part PartSupp
Supplier Lineitem
Customer Orders
Nation Region
PartPartSupp
Suppliers
Lineitems
Customer
Orders
Nation
Region
1 N
1
N
1
N
1
N
N
1 N
1
N
1N 1
N
1
1
N
N
1

26© Cloudera, Inc. All rights reserved.
Columnar Storage for Complex Schemas
• Columnar storage: a necessity for processing nested data at speed
• complex schemas = really wide tables
• row-wise storage: read lots of data you don’t care about
• Columnar formats effectively store a join index
{id: 17
orders: [{date: 2014-01-29, price: 10.2}, {date: ….} …]
}
{id: 18
orders: [{date: 2015-04-10, price: 2000.0}, {date: ….} …]
}
17
18
10.2
22.1
100
200
id orders.price
…
…
…

27© Cloudera, Inc. All rights reserved.
Columnar Storage for Complex Schemas
• A “join” between parent and child is essentially free:
• coordinated scan of parent and child columns
• data effectively pre-sorted on parent PK
• merge join beats hash join!
• Aggregating child data is cheap:
• the data is already pre-grouped by the parent
• Amenable to vectorized execution
• Local non-grouping aggregation <<< distributed grouping aggregation

28© Cloudera, Inc. All rights reserved.
Analytics on Nested Data: Cheap & Easy!
SELECT c.id, AVG(orders.items.price) avg_price
FROM customer
ORDER BY avg_price DESC LIMIT 10
Query: Find the 10 customers that buy the most expensive items on average
SELECT c.id, AVG(i.price) avg_price
FROM customer c, order o, item i
WHERE c.id = o.cid and o.id = i.oid
GROUP BY c.id
ORDER BY avg_price DESC LIMIT 10
Flat Nested

29© Cloudera, Inc. All rights reserved.
Scan Scan
Xch Xch
Join
Scan
Xch
Join
Agg
Xch
Agg
Scan
Unnest
Agg
Top-n
Xch
Top-n
Top-n
Xch
Top-n
Analytics on Nested Data: Cheap & Easy!
$$$

30© Cloudera, Inc. All rights reserved.
A Note to BI Tool Vendors
Please support nested types, it’s not that hard!
• you already take advantage of declared PK/FK relationships
• a nested collection isn’t really that different
• except you don’t need a join predicate

31© Cloudera, Inc. All rights reserved.
Thank you


















