
Machine learning for biomedical science
31
Machine learning for biomedical science @kordinglab
Transcript of Machine learning for biomedical science

Machine learning for biomedical science
@kordinglab

ML is getting popular in biomedical science
01992 2000 2008 2016
PublicationsPatents
10
100
1000
Trends in using ML for biomedical sciences
Year
Num
ber o
f occ
urre
nces

Typical Supervised ML setting
label
Model
Training
features predictions
sam
ples
sam
ples
features

Solve real problems
UPMC, Schwartz lab

Understand data
e.g. Bialek

Provide a benchmark
Your Model
Machine learning
See Jonas and Kording, Could a neuroscientist understand a microprocessor 2017
Being better than another model does not make a model true.

Model for brain
see Marblestone, Wayne, Kording, 2017

Use standard ML first
• Countless possibilities
• Biomedical scientists do not know how to do it well
• (Most) Machine learning scientists don’t either
• Kaggle competition winners do

State of the art ML
• Feature engineering based on domain knowledge, e.g. spike counts
• Handful of ML methods
• Ensemble method (xgboost) on top
• Or deep learning for other kinds of problems

Auto-ML is coming
• Approaches are sufficiently standard that this part can easily be automated, e.g. auto-SKlearn, auto-WEKA
• Implication: knowledge about details of ML techniques will become less relevant for biomedical scientists

Example uses of ML in Neuroscience
Bensmaia, Miller, 2014
DecodingEncoding

Decoding (Neurons-> movement)
SVRKalman Filt. XGBoost
Feedfrwrd NNSimple RNNGRU
LSTMEnsembleWiener Casc.
Wiener Filter
R2
1.0
0.6
Motor Cortex
WF WC KF SVR XGB FNN RNN GRU LSTM Ens
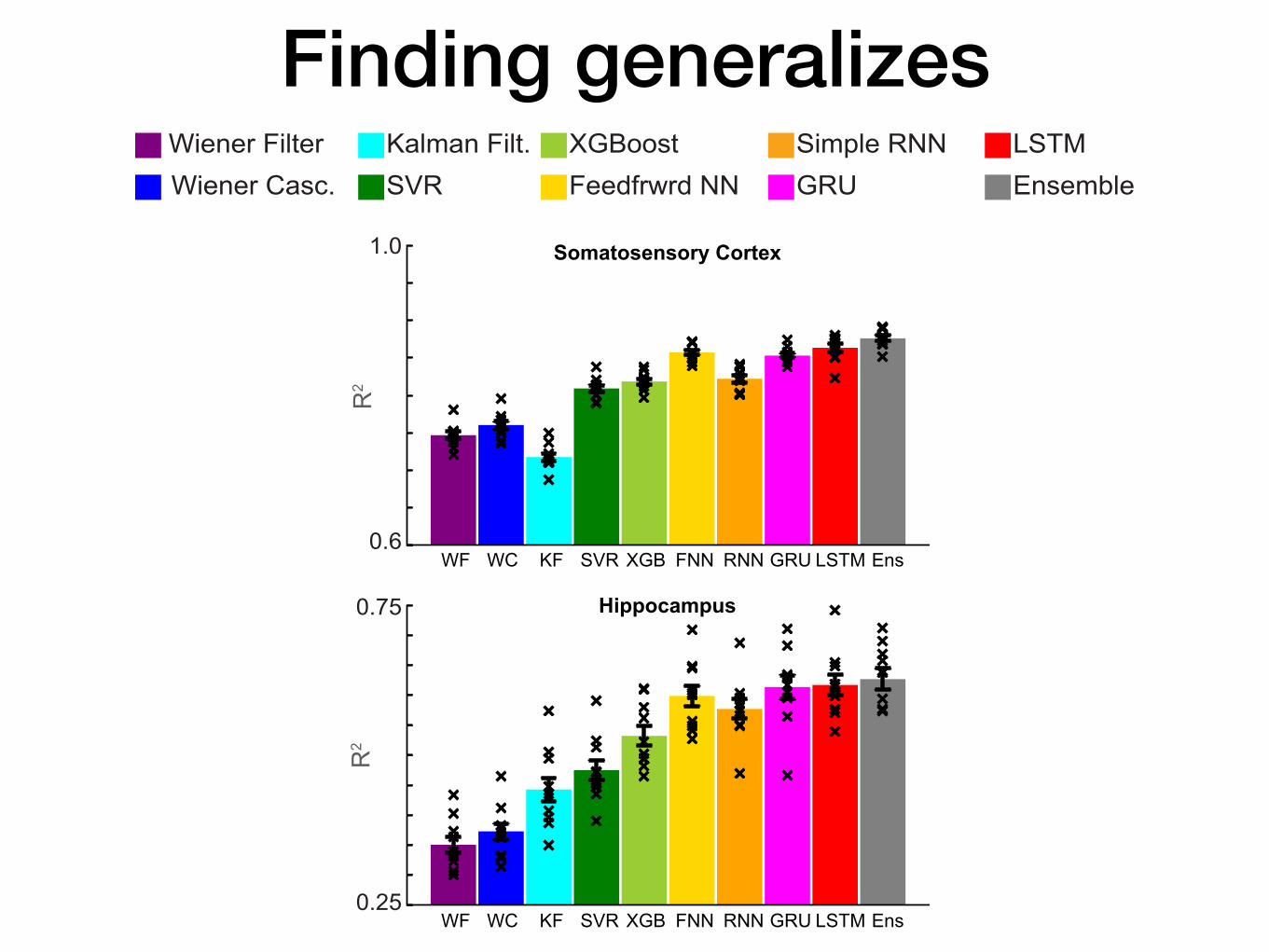
Finding generalizes
R2
1.0
0.6
R2
0.75
0.25
Somatosensory Cortex
Hippocampus
WF WC KF SVR XGB FNN RNN GRU LSTM Ens
WF WC KF SVR XGB FNN RNN GRU LSTM Ens
SVRKalman Filt. XGBoost
Feedfrwrd NNSimple RNNGRU
LSTMEnsembleWiener Casc.
Wiener Filter
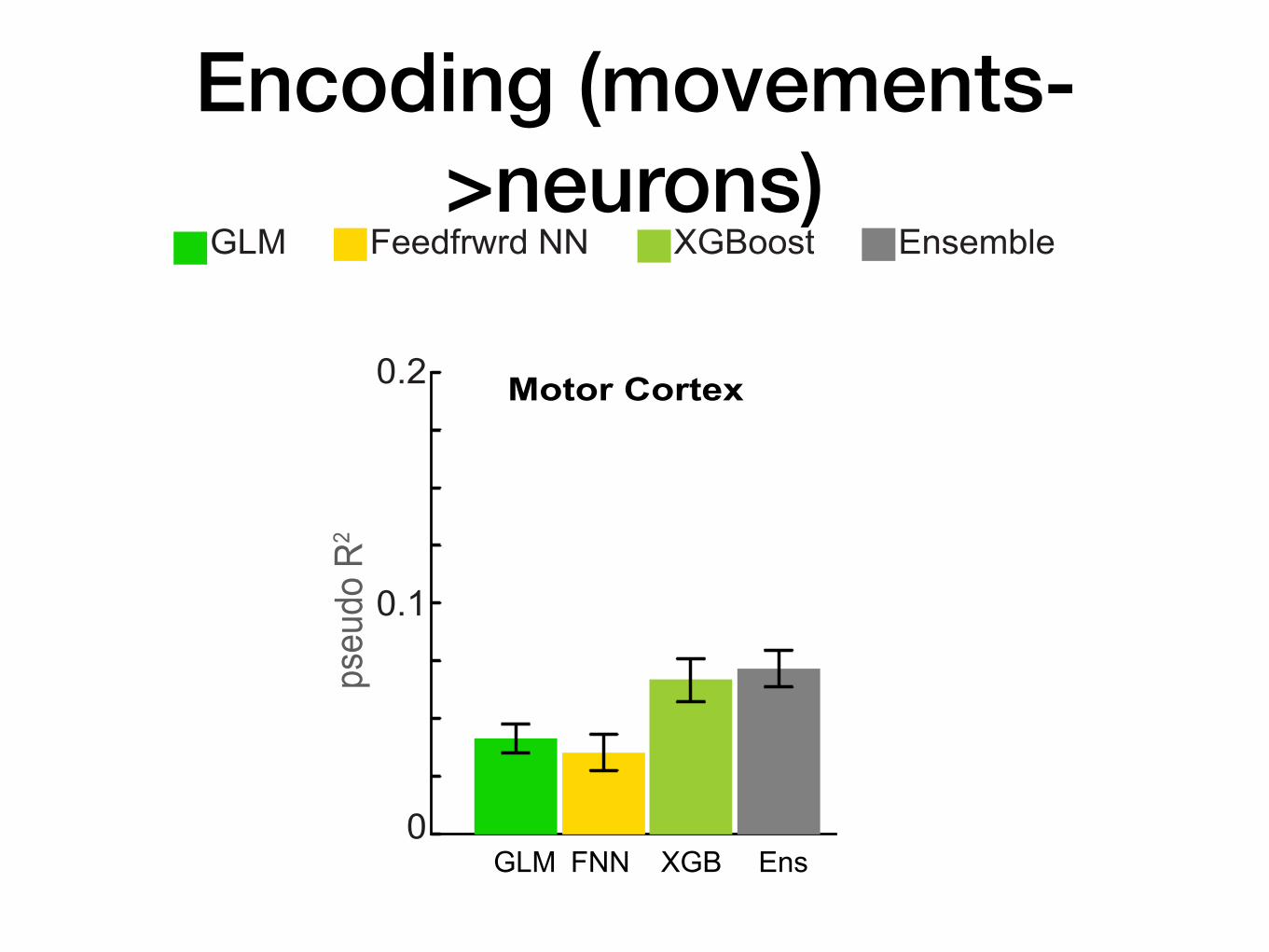
Encoding (movements->neurons)
GLM Feedfrwrd NN XGBoost Ensemble
pseu
do R
20.2
0
Motor Cortex
GLM XGBFNN Ens
0.1

Finding Generalizesps
eudo
R2
0.2
0
Rat Hippocampus
GLM XGBFNN Ens
0.1
pseu
do R
2
0.2
0
Macaque S1
GLM XGBFNN Ens
0.1

Take home: Standard ML
• Work really well, fast
• Challenge people to get better results with brain intuitions
• Set baseline
• Ok, lets talk about non-standard now

Cryptography
Hello Bob h23nf9$bX
Plaintext m Ciphertext Ek(m)
h23nf9$bXHello Bob
m=Dk(Ek(m)) Dk=Ek-1

Ciphertext only attackWe can estimate p(m) from text
We know samples from c=El(m)
Generic solution strategy
P
For hypothesized decryption q=Dk(c)
D̂k = argminKL(P ||Q)

• Instructions change signals
• Instructions disturb subjects
• Brain changes
• Internal state not observable
Hard to get plaintext/supervised data from brain

typical distribution of movements
Use ciphertext only
P

Measured
With Daniel Wolpert, James Ingram, EBR

mis-aligned decodertypical movementdistribution distribution
mis-aligned decoder typical movement
Intuition
Qk P

neural data
Y
prior knowledge (kinematics)V

neural data
dimensionality reductionstep 1
Y
prior knowledge (kinematics)V

neural data
distribution alignment
dimensionality reductionstep 1
step 2
Y
Y` prior knowledge (kinematics)V

Estimating distributions
let . Then for every the density
• K-Nearest Neighbors (KNN) estimator:
V = [v1,v2, . . . ,vT ] vi
where is the distance between and its k-nearest neighbor in
⇢k(vi,V) vi
V
p(vi) /k
T⇢2k(vi,V)
See Poczos and Schneider, 2011, Loftsgaarden et al 1965
• the same approach can be used for estimating

rotation angle [o]
ground truth
KL-d
iver
genc
e [a
.u.]
0.9
1
180900-90-180
1.1
1.2
prior
no reflectionwith reflection
prediction
estim
ated
dens
ityki
nem
atic
s
examples of transformations of projected neural data
best alignment
Alignment

5 100time [s]
v x [a.
u.]
supervised within-subject DADground truth
-4
0
4
5 100time [s]
v y [a.
u.]
-4
0
4
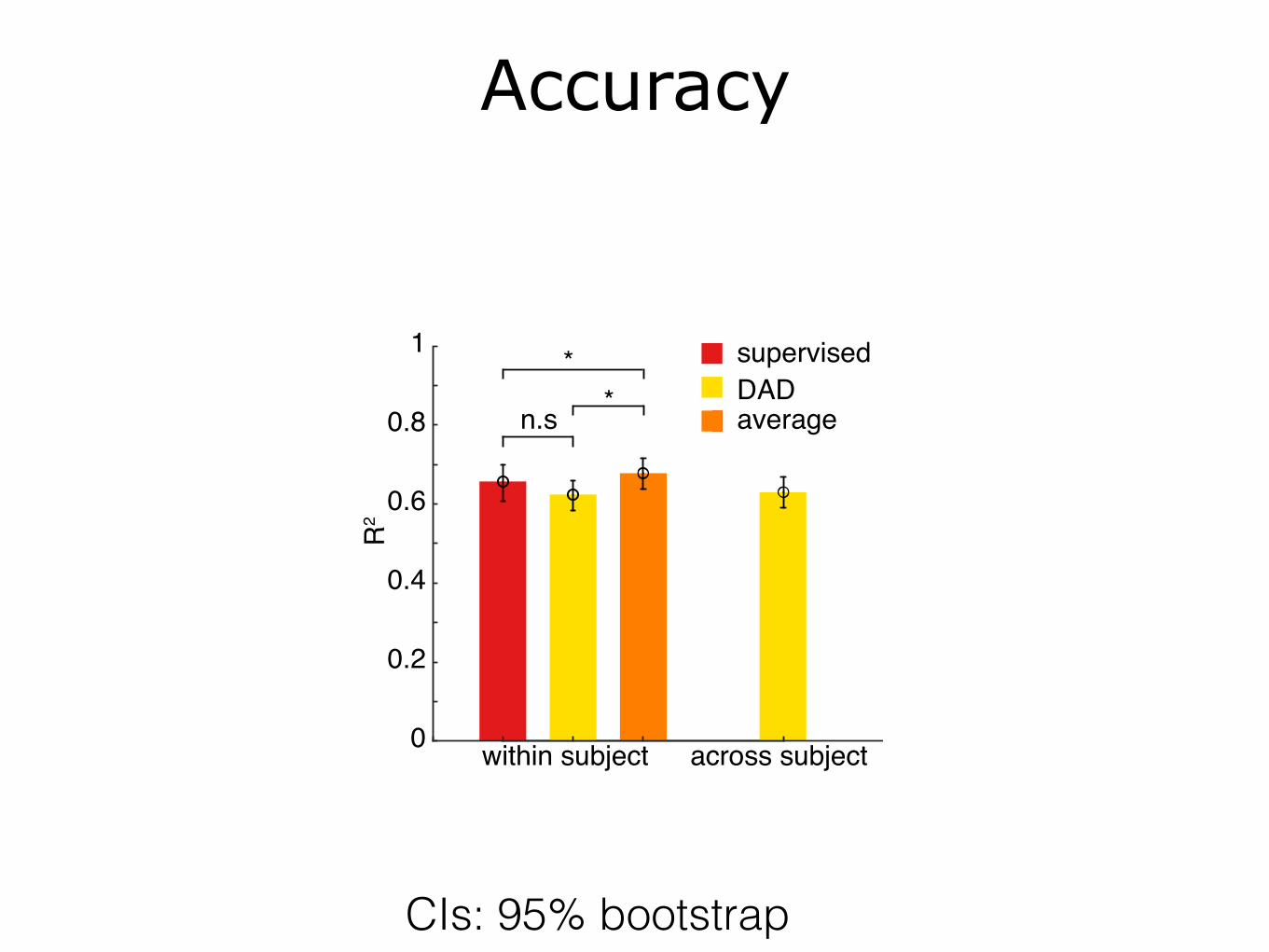
Accuracy
0
0.2
0.4
0.6
0.8
1
across subjectwithin subject
DADsupervised
n.s
*R
2
* average
CIs: 95% bootstrap

• A ciphertext only decoder (unsupervised)
• uses no simultaneous recording of neural data and kinematics
• only requires a prior distribution over the kinematics
• Alignment compares well to a supervised decoder which has access to the supervised data
• Need more data!
• Next, a cipher text only attack. On your brain.
Take home: neural cryptography

Acknowledgements
• Ari Benjamin
• Joshua Glaser
• Mohammad Azar
• Eva Dyer
• Pavan Ramkumar
• Lee Miller
• Matt Perich
• Tucker Tomlinson
• Chris Versteeg
• Raeed Choudhury
Funding: NIH


















