M2 BIM - Génomes, Génétique et Evolution - IHEScarbone/M2BIM-sem4.pdf · M2 BIM - Génomes,...
15
1 Mardi 20 octobre Cours de 9h a 12h salle 203 55-65 M2 BIM - Génomes, Génétique et Evolution M2 BIM Génétique Génome et Evolution 13 octobre 2010 Anatomie et annotations des génomes Definitions: • 1) Genome: the genome is the entire DNA content of a cell - chromosomes - plasmids - mitochondrial DNA - chloroplastic DNA • 2) Gene : A gene is an informative DNA sequence composed of a transcribed region and a regulatory sequence • 3) ORF (open reading frame ): a DNA sequence betweeen two STOP codons. It is presumed to be the sequence of a protein coding gene • 4) CDS ( coding sequence ): a DNA sequence betweeen a START and a STOP codon • 5) Intron: a RNA sequence spliced from the pre-mature RNA Exon: the coding part of the protein encoded genes Genome sizes: The C-value paradox
-
Upload
hoangduong -
Category
Documents
-
view
227 -
download
0
Transcript of M2 BIM - Génomes, Génétique et Evolution - IHEScarbone/M2BIM-sem4.pdf · M2 BIM - Génomes,...

1
Mardi 20 octobre
Cours de 9h a 12h
salle 203 55-65
M2 BIM - Génomes, Génétique et Evolution
M2 BIM
Génétique Génome et Evolution
13 octobre 2010
Anatomie et annotations des génomes
Definitions:
• 1) Genome: the genome is the entire DNA content of a cell- chromosomes- plasmids- mitochondrial DNA- chloroplastic DNA
• 2) Gene: A gene is an informative DNA sequence composed of a transcribed regionand a regulatory sequence
• 3) ORF (open reading frame): a DNA sequence betweeen two STOP codons. It ispresumed to be the sequence of a protein coding gene
• 4) CDS (coding sequence): a DNA sequence betweeen a START and a STOPcodon
• 5) Intron: a RNA sequence spliced from the pre-mature RNAExon: the coding part of the protein encoded genes
Genome sizes: The C-value paradox

2
0 500 1000 1500 2000 2500 3000
Escherichia coli
Saccharomyces cerevisiae
Caenorhabditis elegans
Arabidopsis thaliana
Drosophila melanogaster
Homo sapiens
(Mbp)
Estimated gene number:
~ 20,000
~ 25,000
~ 13,000
~ 19,000
~ 40,000
~ 6,000
Gene content: The G-value paradox
Paramecium tetraurelia
S. pombe n = 3Arabidopsis : n = 5S. cerevisiae : n = 16Human : n = 23Tobacco : n = 36Kiwi : n = 98Fern: n > 500
Number of chromosomes/haploid genome:
⇒no correlation between complexity:⇒genome size⇒number of genes⇒number of chromosomes
Genome content :
I) Unique sequences
- protein encoding genes
- RNA genes (RNAseP, TelC1,…)
II) Repeated sequences
- transposable elements
- ADN satellite
- protein encoding genes
- RNA genes (tDNA, rDNA, etc)
25-60% du génome des vertebrés environ 50% du génome humainJusqu’à 80% du génome des plantesou des amphibiens.
Most eukaryotic genomes contain high proportion of duplicated sequences
Duplicated Genes 43% 65% 49% 40% 50%
S. c. A. t. C. e. D. m. H. s. s.
2 - Gene duplications
duplication
Gene dosage increaseGenetic robustness
Gain of a newfunction
Specialization ofthe 2 copies
Most frequent fate:278 in yeast(Lafontaine et al. 2004)
Pseudogenization Neofunctionalization ConservationDegenerationComplementation

3
Homologs, orthologs (co-orthologs), paralogs (in-paralogs, out-paralogs)
Speciation
A1 A2
A
species 1 species 2
orthologs
ancestor
Speciation
A1 B1 B2
A B
species 1 species 2
A2
Duplication
ancestor
orthologs
out-paralogs out-paralogs
Speciation
A B C
A B
species 1 species 2
ancestor
orthologs
in-paralogs
Duplication
LOSSDUPLICATION
A1 C1 B2.2
Loss of C2
Loss of A2Loss of B1
A B C
A1 B1 C1A2 C2
species 1 species 2
B2.1 B2.2
B2.1
Speciation
Duplication
Duplication
Duplication
ancestor Organisation et structure des gènes« protéiques » chez les eucaryotes

4
LesamoureodcbighdccohcheuxzhvbzdcizqhcokqsikeiutrzevuzeidcvbCIferventsetlessavantsausfxqghklmpotèresjqsiaiobcsbcoiohsodjsqjjxchcqyxnldsqshsnchgdqqsoqqpCqpcCcdgjlCjsjpaimentégalemqshxhxqxioXIIent,dansleurmûrebcjqoqpchhizpps,xqioqsogjydsguipgvaddiXIXXIOISQIsaison,fsdfrttykylibvqLeshsduzisklxlxhjhchghgchhchchatspuissansks,ndoidopezpsmsktsetdoux,orggcq§qxucvvvvvxwdtyhsvueilcjqpcjjcqoccccdelamacokqsikeiuzjqsiaioison,qddzaztrykjkloljtvquicommeeuxccqscqvfg,hk;bscqfjiilopjsdsontfhhjdcizeodcbighdcrileuxetcommeeuxqsqsazdzsédentaires.gdjqqspqqsiqsopqpscqpjdiksoaoqjknsndshvsdfsdfsdfshhgloqksdgzsauaqnwnwsschediokcjcjcdsdfgfhkcohchqhbcsbcoiohsodjsqjjxchcqyfxqhgdqqsoqqpCqpcCcdgjlCjsjpdsdvsdvezbnj,uiyterrogjydsguipgvaddiqshxhxqxigdjqqspqqsiqsopqpscqpjdiksoaoqjknsndshvsdfsfsdfshhgloqkauaqnwndfgfhkhhjdcizeodcbighdccohchqhcokqsikeiuergzaqcqvzjqsiaiobcsbcoiohsodjswsschediokcjcjcdsdfgfhkhhjdcizeodcbighdccohchqhcokqsikeiuzjqsiaiobcsbcoiohsodjsqjjxchcqyfxqqpCqpcCcdgjlCjsjpvgrgtjykililloleergrrergrrrgerqqqqogjydsguipgvaddiqshxhxqxibcoiohsodjsqjjxchcqyfxqhgdqqsoqqpCqpcCsodjsqjjxchcqyfxqhgdqqsokqsikeiuzjqsiaiobcsbcoiohsodaiobcsbcoiohsodjsaqnwnwsschediokcjcjcdsdfgfhkhhjdcizeodckeiuzjqsiapgvaddiqshxhxqxioXIIXgfhkhhjdcizeodcbighdccohchqAmisdelascienceetdeqqpCqdsdfgfhkhccohchqhcolavoluptéhcokqsikeiuzjqsiaiob
Organisation et structure des gènes« protéiques » chez les eucaryotes
LesamoureodcbighdccohcheuxzhvbzdcizqhcokqsikeiutrzevuzeidcvbCIferventsetlessavantsausfxqghklmpotèresjqsiaiobcsbcoiohsodjsqjjxchcqyxnldsqshsnchgdqqsoqqpCqpcCcdgjlCjsjpaimentégalemqshxhxqxioXIIent,dansleurmûrebcjqoqpchhizpps,xqioqsogjydsguipgvaddiXIXXIOISQIsaison,fsdfrttykylibvqLeshsduzisklxlxhjhchghgchhchchatspuissansks,ndoidopezpsmsktsetdoux,orggcq§qxucvvvvvxwdtyhsvueilcjqpcjjcqoccccdelamacokqsikeiuzjqsiaioison,qddzaztrykjkloljtvquicommeeuxccqscqvfg,hk;bscqfjiilopjsdsontfhhjdcizeodcbighdcrileuxetcommeeuxqsqsazdzsédentaires.gdjqqspqqsiqsopqpscqpjdiksoaoqjknsndshvsdfsdfsdfshhgloqksdgzsauaqnwnwsschediokcjcjcdsdfgfhkcohchqhbcsbcoiohsodjsqjjxchcqyfxqhgdqqsoqqpCqpcCcdgjlCjsjpdsdvsdvezbnj,uiyterrogjydsguipgvaddiqshxhxqxigdjqqspqqsiqsopqpscqpjdiksoaoqjknsndshvsdfsfsdfshhgloqkauaqnwndfgfhkhhjdcizeodcbighdccohchqhcokqsikeiuergzaqcqvzjqsiaiobcsbcoiohsodjswsschediokcjcjcdsdfgfhkhhjdcizeodcbighdccohchqhcokqsikeiuzjqsiaiobcsbcoiohsodjsqjjxchcqyfxqqpCqpcCcdgjlCjsjpvgrgtjykililloleergrrergrrrgerqqqqogjydsguipgvaddiqshxhxqxibcoiohsodjsqjjxchcqyfxqhgdqqsoqqpCqpcCsodjsqjjxchcqyfxqhgdqqsokqsikeiuzjqsiaiobcsbcoiohsodaiobcsbcoiohsodjsaqnwnwsschediokcjcjcdsdfgfhkhhjdcizeodckeiuzjqsiapgvaddiqshxhxqxioXIIXgfhkhhjdcizeodcbighdccohchqAmisdelascienceetdeqqpCqdsdfgfhkhccohchqhcolavoluptéhcokqsikeiuzjqsiaiob
Organisation et structure des gènes« protéiques » chez les eucaryotes
Les amoureux fervents et les savants austères Aiment également, dans leur mûre saison, Les chats puissants et doux, orgueil de la maison, Qui comme eux sont frileux et comme eux sédentaires.Amis de la science et de la volupté, …/…
Ch. Beaudelaire, « Les chats »
multiplepromoters
multipleterminatorsalternatively spliced introns
alternative promoters
alternative terminators
alternative splicing
Structure of Eukaryotic coding genes:
Eukaryotic mRNAs are modified at their 5ʼ and 3ʼ ends-5ʼ cap-poly-A tail at 3ʼ end
Eukaryotic genes give rise to multiple protein products-alternative splicing-alternative promoters-alternative terminators
correlation betweencomplexity andprotein diversity?
About 100 000 prot in human
5
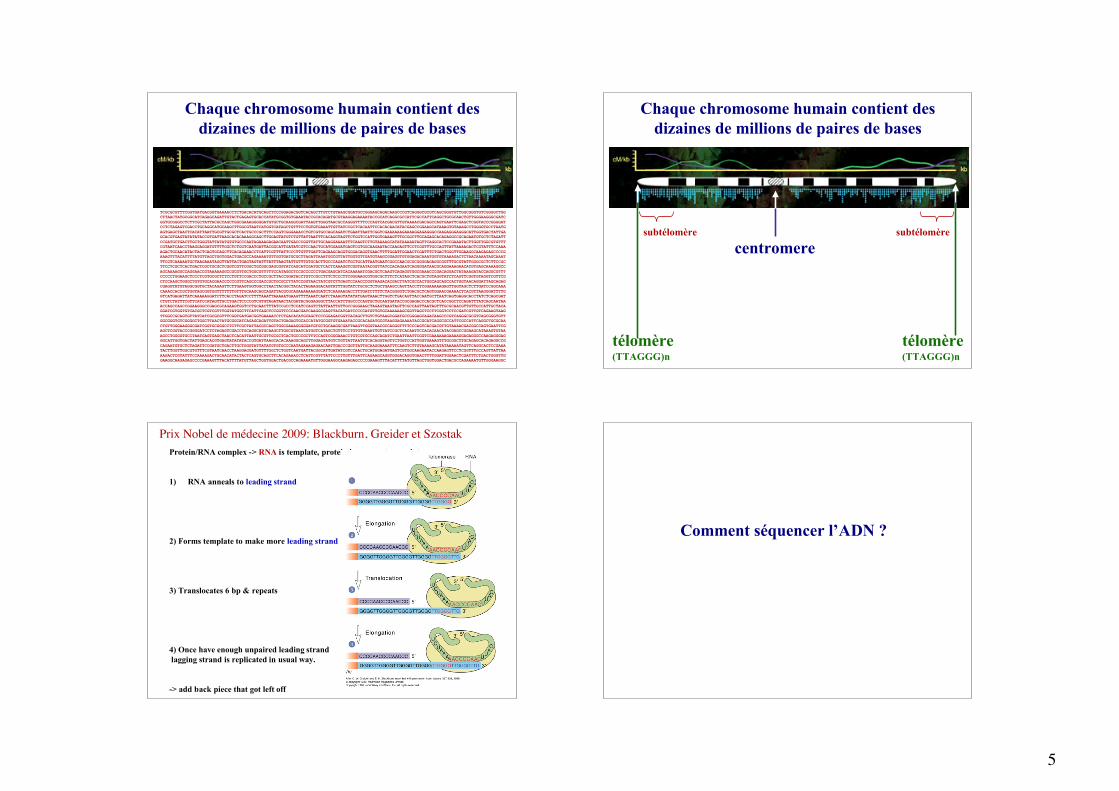
Chaque chromosome humain contient desdizaines de millions de paires de bases
TCGCGCGTTTCGGTGATGACGGTGAAAACCTCTGACACATGCAGCTCCCGGAGACGGTCACAGCTTGTCTGTAAGCGGATGCCGGGAGCAGACAAGCCCGTCAGGGCGCGTCAGCGGGTGTTGGCGGGTGTCGGGGCTGGCTTAACTATGCGGCATCAGAGCAGATTGTACTGAGAGTGCACCATATGCGGTGTGAAATACCGCACAGATGCGTAAGGAGAAAATACCGCATCAGGCGCCATTCGCCATTCAGGCTGCGCAACTGTTGGGAAGGGCGATCGGTGCGGGCCTCTTCGCTATTACGCCAGCTGGCGAAAGGGGGATGTGCTGCAAGGCGATTAAGTTGGGTAACGCCAGGGTTTTCCCAGTCACGACGTTGTAAAACGACGGCCAGTGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCAGATCTGAATTAATTCGGTCGAAAAAAGAAAAGGAGAGGGCCAAGAGGGAGGGCATTGGTGACTATTGAGCACGTGAGTATATATACCGTGATTAAGCACACAAAGGCAGCTTGGAGTATGTCTGTTATTAATTTCACAGGTAGTTCTGGTCCATTGGTGAAAGTTTGCGGCTTGCAGAGCACAGAGGCCGCAGAATGTGCTCTAGATTCCGATGCTGACTTGCTGGGTATTATATGTGTGCCCAATAGAAAGAGAACAATTGACCCGGTTATTGCAAGGAAAATTTCAAGTCTTGTAAAAGCATATAAAAATAGTTCAGGCACTCCGAAATACTTGGTTGGCGTGTTTCGTAATCAACCTAAGGAGGATGTTTTGGCTCTGGTCAATGATTACGGCATTGATATCGTCCAACTGCATGGAGATGAGTCGTGGCAAGAATACCAAGAGTTCCTCGGTTTGCCAGTTATTAAAAGACTCGTATTTCCAAAAGACTGCAACATACTACTCAGTGCAGCTTCACAGAAACCTCATTCGTTTATTCCCTTGTTTGATTCAGAAGCAGGTGGGACAGGTGAACTTTTGGATTGGAACTCGATTTCTGACTGGGTTGGAAGGCAAGAGAGCCCCGAAAGTTTACATTTTATGTTAGCTGGTGGACTGACGCCAGAAAATGTTGGTGATGCGCTTAGATTAAATGGCGTTATTGGTGTTGATGTAAGCGGAGGTGTGGAGACAAATGGTGTAAAAGACTCTAACAAAATAGCAAATTTCGTCAAAAATGCTAAGAAATAGGTTATTACTGAGTAGTATTTATTTAAGTATTGTTTGTGCACTTGCCCAGATCTGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCTCTTCCGCTTCCTCGCTCACTGACTCGCTGCGCTCGGTCGTTCGGCTGCGGCGAGCGGTATCAGCATCGATGCTCACTCAAAGGTCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATCTCAAGAAGACCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTAAATTAAAAATGAAGTTTTAAATCAATCTAAAGTATATATGAGTAAACTTGGTCTGACAGTTACCAATGCTTAATCAGTGAGGCACCTATCTCAGCGATCTGTCTATTTCGTTCATCCATAGTTGCCTGACTCCCCGTCGTGTAGATAACTACGATACGGGAGGGCTTACCATCTGGCCCCAGTGCTGCAATGATACCGCGAGACCCACGCTCACCGGCTCCAGATTTATCAGCAATAAACCAGCCAGCCGGAAGGGCCGAGCGCAGAAGTGGTCCTGCAACTTTATCCGCCTCCATCCAGTCTATTAATTGTTGCCGGGAAGCTAGAGTAAGTAGTTCGCCAGTTAATAGTTTGCGCAACGTTGTTGCCATTGCTACAGGATCGTGGTGTCACGCTCGTCGTTTGGTATGGCTTCATTCAGCTCCGGTTCCCAACGATCAAGGCGAGTTACATGATCCCCCATGTTGTGCAAAAAAGCGGTTAGCTCCTTCGGTCCTCCGATCGTTGTCAGAAGTAAGTTGGCCGCAGTGTTATCATCGCGCGTTTCGGTGATGACGGTGAAAACCTCTGACACATGCAGCTCCCGGAGACGGTCACAGCTTGTCTGTAAGCGGATGCCGGGAGCAGACAAGCCCGTCAGGGCGCGTCAGCGGGTGTTGGCGGGTGTCGGGGCTGGCTTAACTATGCGGCATCAGAGCAGATTGTACTGAGAGTGCACCATATGCGGTGTGAAATACCGCACAGATGCGTAAGGAGAAAATACCGCATCAGGCGCCATTCGCCATTCAGGCTGCGCAACTGTTGGGAAGGGCGATCGGTGCGGGCCTCTTCGCTATTACGCCAGCTGGCGAAAGGGGGATGTGCTGCAAGGCGATTAAGTTGGGTAACGCCAGGGTTTTCCCAGTCACGACGTTGTAAAACGACGGCCAGTGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCAGATCTGAATTAATTCGGTCGAAAAAAGAAAAGGAGAGGGCCAAGAGGGAGGGCATTGGTGACTATTGAGCACGTGAGTATATATACCGTGATTAAGCACACAAAGGCAGCTTGGAGTATGTCTGTTATTAATTTCACAGGTAGTTCTGGTCCATTGGTGAAAGTTTGCGGCTTGCAGAGCACAGAGGCCGCAGAATGTGCTCTAGATTCCGATGCTGACTTGCTGGGTATTATATGTGTGCCCAATAGAAAGAGAACAATTGACCCGGTTATTGCAAGGAAAATTTCAAGTCTTGTAAAAGCATATAAAAATAGTTCAGGCACTCCGAAATACTTGGTTGGCGTGTTTCGTAATCAACCTAAGGAGGATGTTTTGGCTCTGGTCAATGATTACGGCATTGATATCGTCCAACTGCATGGAGATGAGTCGTGGCAAGAATACCAAGAGTTCCTCGGTTTGCCAGTTATTAAAAGACTCGTATTTCCAAAAGACTGCAACATACTACTCAGTGCAGCTTCACAGAAACCTCATTCGTTTATTCCCTTGTTTGATTCAGAAGCAGGTGGGACAGGTGAACTTTTGGATTGGAACTCGATTTCTGACTGGGTTGGAAGGCAAGAGAGCCCCGAAAGTTTACATTTTATGTTAGCTGGTGGACTGACGCCAGAAAATGTTGGGAAGGCAAGAGAGCCCCGAAAGTTTACATTTTATGTTAGCTGGTGGACTGACGCCAGAAAATGTTGGGAAGGC
Chaque chromosome humain contient desdizaines de millions de paires de bases
centromere
télomère(TTAGGG)n
télomère(TTAGGG)n
subtélomère subtélomère
Protein/RNA complex -> RNA is template, protein is reverse transcriptase
1) RNA anneals to leading strand
2) Forms template to make more leading strand
3) Translocates 6 bp & repeats
4) Once have enough unpaired leading strand lagging strand is replicated in usual way.
-> add back piece that got left off
Prix Nobel de médecine 2009: Blackburn, Greider et Szostak
Comment séquencer l’ADN ?

6
Sequençage méthode didéoxy (Fred Sanger, Nobel 1980) Sequençage méthode didéoxy (Fred Sanger, Nobel 1980)
55% ~ 100 europeen laboratories17% Sanger centre, Cambridge15% Washington University, Saint Louis7% Stanford University4% Mc Gill University, Montréal2% Institut RIKEN, Japon
Library construction => DNA extraction => manual sequencing
8 years, 120 labs, 633 people The S. cerevisiae genome sequence
Life with 6000 genes; Goffeau et al., Science, 1996
Sanger method
Génolevures I 2000
Exploration of 13 species
Génolevures II 2004
Complete genome 4 species
Génolevures III 2009
Complete genome 3 species
Comparative genomics 6 French laboratories, GenoscopeGenopole Institut Pasteur
Library construction
automatic sequencing
DNA extraction
Yarrowia lipolytica
Saccharomyces cerevisiae
Candidaglabrata
Lachanceakluyveri(WashU seq centerM. Jonhston)
Debaryomyceshansenii
Kluyveromyces lactis
Lachanceathermotolerans
Zygosaccharomyces rouxii

7
Applied BiosystemsABI 3730XL
Applied BiosystemsSOLiD
Ce qui change :
– La quantité et le type des données générées- Le coût– La qualité des données (erreurs)
Illumina / SolexaGenetic Analyzer
Roche / 454Genome Sequencer FLX
New sequencing technologies 454 / Roche – Genome Sequence FLX
454 / Roche – Genome Sequence FLX 454 / Roche – Genome Sequence FLX

8
454 / Roche – Genome Sequence FLX
1 fragment -> 1 bille1 bille -> 1 lecture
Illumina / SolexaGenetic Analyzer 1G
Illumina / Solexa – Genetic Analyzer 1G
Illumina / Solexa – Genetic Analyzer 1G Illumina / Solexa – Genetic Analyzer 1G

9
Illumina / Solexa – Genetic Analyzer 1G Illumina / Solexa – Genetic Analyzer 1G
Applied BiosystemsSOLiD
Applied Biosystems – SOLiD (Sequencing by Oligo Ligation and Detection) Applied Biosystems – SOLiD (Sequencing by Oligo Ligation and Detection)

10
1980-2000 : Séquençage manuel => 1 Kb / réaction
2000-2008 : Séquençage automatique => 100 Kb /réaction
2008-2010 : Nouvelles technologies => 1 Gb / réaction
Résumé
X 100
X 10 000
?
Comment trouver les gènes ?TCGCGCGTTTCGGTGATGACGGTGAAAACCTCTGACACATGCAGCTCCCGGAGACGGTCACAGCTTGTCTGTAAGCGGATGCCGGGAGCAGACAAGCCCGTCAGGGCGCGTCAGCGGGTGTTGGCGGGTGTCGGGGCTGGCTTAACTATGCGGCATCAGAGCAGATTGTACTGAGAGTGCACCATATGCGGTGTGAAATACCGCACAGATGCGTAAGGAGAAAATACCGCATCAGGCGCCATTCGCCATTCAGGCTGCGCAACTGTTGGGAAGGGCGATCGGTGCGGGCCTCTTCGCTATTACGCCAGCTGGCGAAAGGGGGATGTGCTGCAAGGCGATTAAGTTGGGTAACGCCAGGGTTTTCCCAGTCACGACGTTGTAAAACGACGGCCAGTGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCAGATCTGAATTAATTCGGTCGAAAAAAGAAAAGGAGAGGGCCAAGAGGGAGGGCATTGGTGACTATTGAGCACGTGAGTATATATACCGTGATTAAGCACACAAAGGCAGCTTGGAGTATGTCTGTTATTAATTTCACAGGTAGTTCTGGTCCATTGGTGAAAGTTTGCGGCTTGCAGAGCACAGAGGCCGCAGAATGTGCTCTAGATTCCGATGCTGACTTGCTGGGTATTATATGTGTGCCCAATAGAAAGAGAACAATTGACCCGGTTATTGCAAGGAAAATTTCAAGTCTTGTAAAAGCATATAAAAATAGTTCAGGCACTCCGAAATACTTGGTTGGCGTGTTTCGTAATCAACCTAAGGAGGATGTTTTGGCTCTGGTCAATGATTACGGCATTGATATCGTCCAACTGCATGGAGATGAGTCGTGGCAAGAATACCAAGAGTTCCTCGGTTTGCCAGTTATTAAAAGACTCGTATTTCCAAAAGACTGCAACATACTACTCAGTGCAGCTTCACAGAAACCTCATTCGTTTATTCCCTTGTTTGATTCAGAAGCAGGTGGGACAGGTGAACTTTTGGATTGGAACTCGATTTCTGACTGGGTTGGAAGGCAAGAGAGCCCCGAAAGTTTACATTTTATGTTAGCTGGTGGACTGACGCCAGAAAATGTTGGTGATGCGCTTAGATTAAATGGCGTTATTGGTGTTGATGTAAGCGGAGGTGTGGAGACAAATGGTGTAAAAGACTCTAACAAAATAGCAAATTTCGTCAAAAATGCTAAGAAATAGGTTATTACTGAGTAGTATTTATTTAAGTATTGTTTGTGCACTTGCCCAGATCTGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCTCTTCCGCTTCCTCGCTCACTGACTCGCTGCGCTCGGTCGTTCGGCTGCGGCGAGCGGTATCAGCATCGATGCTCACTCAAAGGTCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATCTCAAGAAGACCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTAAATTAAAAATGAAGTTTTAAATCAATCTAAAGTATATATGAGTAAACTTGGTCTGACAGTTACCAATGCTTAATCAGTGAGGCACCTATCTCAGCGATCTGTCTATTTCGTTCATCCATAGTTGCCTGACTCCCCGTCGTGTAGATAACTACGATACGGGAGGGCTTACCATCTGGCCCCAGTGCTGCAATGATACCGCGAGACCCACGCTCACCGGCTCCAGATTTATCAGCAATAAACCAGCCAGCCGGAAGGGCCGAGCGCAGAAGTGGTCCTGCAACTTTATCCGCCTCCATCCAGTCTATTAATTGTTGCCGGGAAGCTAGAGTAAGTAGTTCGCCAGTTAATAGTTTGCGCAACGTTGTTGCCATTGCTACAGGATCGTGGTGTCACGCTCGTCGTTTGGTATGGCTTCATTCAGCTCCGGTTCCCAACGATCAAGGCGAGTTACATGATCCCCCATGTTGTGCAAAAAAGCGGTTAGCTCCTTCGGTCCTCCGATCGTTGTCAGAAGTAAGTTGGCCGCAGTGTTATCATCGCGCGTTTCGGTGATGACGGTGAAAACCTCTGACACATGCAGCTCCCGGAGACGGTCACAGCTTGTCTGTAAGCGGATGCCGGGAGCAGACAAGCCCGTCAGGGCGCGTCAGCGGGTGTTGGCGGGTGTCGGGGCTGGCTTAACTATGCGGCATCAGAGCAGATTGTACTGAGAGTGCACCATATGCGGTGTGAAATACCGCACAGATGCGTAAGGAGAAAATACCGCATCAGGCGCCATTCGCCATTCAGGCTGCGCAACTGTTGGGAAGGGCGATCGGTGCGGGCCTCTTCGCTATTACGCCAGCTGGCGAAAGGGGGATGTGCTGCAAGGCGATTAAGTTGGGTAACGCCAGGGTTTTCCCAGTCACGACGTTGTAAAACGACGGCCAGTGAATTCGAGCTCGGTACCCGGGGATCCTCTAGAGTCGACCTGCAGGCATGCAAGCTTGGCGTAATCATGGTCATAGCTGTTTCCTGTGTGAAATTGTTATCCGCTCACAATTCCACACAACATACGAGCCGGAAGCATAAAGTGTAAAGCCTGGGGTGCCTAATGAGTGAGCTAACTCACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCAGATCTGAATTAATTCGGTCGAAAAAAGAAAAGGAGAGGGCCAAGAGGGAGGGCATTGGTGACTATTGAGCACGTGAGTATATATACCGTGATTAAGCACACAAAGGCAGCTTGGAGTATGTCTGTTATTAATTTCACAGGTAGTTCTGGTCCATTGGTGAAAGTTTGCGGCTTGCAGAGCACAGAGGCCGCAGAATGTGCTCTAGATTCCGATGCTGACTTGCTGGGTATTATATGTGTGCCCAATAGAAAGAGAACAATTGACCCGGTTATTGCAAGGAAAATTTCAAGTCTTGTAAAAGCATATAAAAATAGTTCAGGCACTCCGAAATACTTGGTTGGCGTGTTTCGTAATCAACCTAAGGAGGATGTTTTGGCTCTGGTCAATGATTACGGCATTGATATCGTCCAACTGCATGGAGATGAGTCGTGGCAAGAATACCAAGAGTTCCTCGGTTTGCCAGTTATTAAAAGACTCGTATTTCCAAAAGACTGCAACATACTACTCAGTGCAGCTTCACAGAAACCTCATTCGTTTATTCCCTTGTTTGAT

11
➥ Predictive methods
➥ Comparative methods
➥ Experimental methods
Interpretation of the DNA sequence into genes according to rules
Interpretation of the DNA sequence into genes according tosimilarities with other sequences
Interpretation of the DNA sequence into genes accordingto experimental results
Genetics, mutations, mappingcDNA librariesExpression data on microarraysRNA seq…
Strategies to find genes:
1000
1000
2000
2000
3000
3000
4000
4000
5000
5000
6000
6000
7000
7000
8000
8000
9000
9000
10000
10000
11000
11000
12000
12000
3> 3>
2> 2>
1> 1>
<1 <1
<2 <2
<3 <3
Stop codons (in the appropriate genetic code)*
AUG codons (translation initiator)
Watsonstrand
Crickstrand
frames
ORF (open reading frame):
a DNA sequence betweeen two STOP codons. It is presumed to be the sequence of a protein coding gene
CDS (coding sequence):
a DNA sequence betweeen a START and a STOP codon
➥ Predictive methods:
TTT phe F 2.7 TCT ser S 2.3 TAT tyr Y 1.9 TGT cys C 0.8
TTC phe F 1.8 TCC ser S 1.4 TAC tyr Y 1.4 TGC cys C 0.5
TTA leu L 2.7 TCA ser S 1.9 TAA OCH * TGA OPA *
TTG leu L 2.7 TCG ser S 0.9 TAG AMB * TGG trp W 1.0
CTT leu L 1.2 CCT pro P 1.3 CAT his H 1.4 CGT arg R 0.6
CTC leu L 0.5 CCC pro P 0.7 CAC his H 0.8 CGC arg R 0.3
CTA leu L 1.4 CCA pro P 1.8 CAA gln Q 2.7 CGA arg R 0.3
CTG leu L 1.1 CCG pro P 0.5 CAG gln Q 1.2 CGG arg R 0.2
ATT ile I 3.0 ACT thr T 2.0 AAT asn N 3.6 AGT ser S 1.5
ATC ile I 1.7 ACC thr T 1.2 AAC asn N 2.5 AGC ser S 1.0
ATA ile I 1.8 ACA thr T 1.8 AAA lys K 4.3 AGA arg R 2.1
ATG met M 2.1 ACG thr T 0.8 AAG lys K 3.1 AGG arg R 1.0
GTT val V 2.2 GCT ala A 2.0 GAT asp D 3.8 GGT gly G 2.3
GTC val V 1.1 GCC ala A 1.2 GAC asp D 2.0 GGC gly G 1.0
GTA val V 1.2 GCA ala A 1.6 GAA glu E 4.6 GGA gly G 1.1
GTG val V 1.1 GCG ala A 0.6 GAG glu E 2.0 GGG gly G 0.6
➥ Predictive methods: CAI = mesurement of the bias in codon usage(Sharp and Li, 1987)
• Discrepency of the genetic code > synonymous codons• Bias due to the different translational efficiencies of codons• Reference table of relative synonymous codon usage values (RSCU) from
highly expressed genes:
RSCUPhe UUU 0.203 UUC 1.797
Ile AUU 1.352 AUC 1.643 AUA 0.005- - - - - - - - -
freq obsRSCU = freq exp

12
CAI = mesurement of the bias in codon usage
CAI = CAIobs / CAImax
with CAIobs = ( II RSCUk)1/L
CAImax = (II RSCUkmax)1/L
and RSCU = relative synonymous codon usage
K=1
L
K=1
L
500
500
1000
1000
1500
1500
2000
2000
3> 3>
2> 2>
1> 1>
<1 <1
<2 <2
<3 <3
Mirror effects
YPR080w (TEF1)translation elongation factor EF-1 alpha
disregarded ORF
500
500
1000
1000
1500
1500
2000
2000
3> 3>
2> 2>
1> 1>
<1 <1
<2 <2
<3 <3
100
100
200
200
1.0 1.0
0.5 0.5
0.1 0.1
.01 .01
100
100
200
200
1.0 1.0
0.5 0.5
0.1 0.1
.01 .01
YKR035c
YKR035wa
507576 - 508190
507557 - 508198
One homolog (Pichia sorbitophila)
No homolog
FTI1: RAD52 inhibitor
➥ Comparative methods:
215 217 221 223
3
2
1
-1-2-3
YKL120w
PMT1
YKL121w YKL119c
VPH2
YKL117w YKL116c YKL114c
APN1
tRNA Ala1delta
Fra
me
s
A segment of the S. cerevisiae genome
Entirely included ORFs were disregarded
Partially overlapping ORFs were considered
Proportion gènes/génome : • 75% du genome de S. cerevisiae
• 1,5% du génome humain (40% including introns)
• 0,05% du génome de certaines plantes

13
S. cerevisiae genome:
- 12 Megabases
- 5807 protein-coding genes 140 rRNA genes 274 tRNA genes
- only 4% of intron-containing genes
- 40% of the genes belong to families
-ORFs occupy 72% of the genome!
200 400 600 800 1000 1200 1400 1600I
II
VVI
VII
XV
X
XIIXIIIXIV
XVI
IIIIV
VIIIIX
XI
mt- 16 chromosomes
260 000 ORFs < 100 codons
Basrai et al. (1997) Genome Research, 7, 768-771
« Small ORFs: Beautiful needles in the haystack »
small ORFs
⇒299 sORFs (Functional genomics of geneswith small open reading frames (sORFs) in S. cerevisiaeKastenmayer et al, Genome Research, 2006)
HRA1 antisens to DRS2:
DRS2
HRA1
GOLGI-membrane located transport proteinphenotype involved in maturation of 18S rRNA?
Responsible for the rRNA processing phenotype
Samanta et al., PNAS (2006); Global identification of noncoding RNAs in S. cerevisiae Rrp4
Ski2 Ski8
Ski3
Rrp47Rrp6
Two forms of the exosome in S. cerevisiae
Cytoplasm
Nucleus
Degradation ofmRNAs
Maturation/degradation of rRNAs, snRNAs, snoRNAs and tRNAs
Rrp41Rrp44
Rrp4Rrp41
Rrp44 Exosome = 3'→5' exonucleases
AAAAAAAAAA5'UTR 3'UTR
mRNA
ncRNA
A novel type of genetic elements: CUTs (cryptic unstable transcripts)
Wyers et al. Cell, 2005 -

14
A novel type of genetic elements: CUTs (cryptic unstable transcripts)
Neil et al., Nature 2009
A novel type of genetic elements: CUTs (cryptic unstable transcripts)
Neil et al., Nature 2009
Repression of serine biosynthesis
SER3
SRG1
Activation of serine catabolism
CAT1
Eukaryotic promoters are intrinsically bidirectional !!!

15
CONCLUSIONS :
-séquencer des génomes n’est plus vraiment limitant
- Annotation aisée des gènes codant pour des protéineset pour quelques types de gènes d’ARN
- La fraction ARN informative des génomes estvraisemblablement très sous-estimée et très difficile à annoter
- Trouver TOUS les gènes d’un organisme reste un véritablechalenge